
はじめに
こんにちは、京都大学大学院情報学研究科知能情報学専攻修士1年生のイ ジェヨン (Lee Jaeyoung) と申します。今回は、2023年夏にLINEのData Science CenterのDSC PlanningチームでML PM (Program Manager) として技術職就業型コースのインターンシップに参加しました。本記事ではその内容についてお話ししたいと思います。
ML PMとは?
LINE Data Science CenterにはDSC Planningチームという組織があり、ML (Machine Learning) やDS (Data Science) に関わるPM (Program Manager) が働いています。MLは機械学習のプロダクト開発を、DSは事業プロジェクトにおけるデータ分析を支える役割になります。今回私はMLに方に関わるML PMとして参加させていただきました。
ML PM とは、MLプロダクトに紐づいて、問題発見から実装・デプロイまでのすべての開発サイクルをマネジメントする人です。LINEのような大きい開発組織となると、プロダクトのオーナーとMLエンジニアに加え、データ連携先の開発者、法務チーム、セキュリティチームなど、様々なステークホルダーが関わってくるため、その間のやりとりを担うことでエンジニアが開発に集中できるようにすることもML PMの重要な役割だと言えます。エンジニアの技術力を価値のあるプロダクトに繋げる人、とも言えると思います。
MLに関わる技術的な知識を活かしてプロダクトを回していく上に、様々なステークホルダーとのやりとりや、タスク・組織の複雑性に対応しないといけないため、技術力はもちろん、高いコミュニケーション能力と適応力が求められます。
携わった案件の紹介
数多くの案件に関わらせていただきましたが、いくつかピックアップしてお話しします。
社内向けWiki用要約ツール開発案件
背景
LINEでは、社内ドキュメンテーション用のツールとしてConfluenceというwikiサービスを採用しています。議事録の作成やプロダクトの仕様書など、多岐にわたる業務で使われており、LINEの全社員の日頃の業務を支えている必須的なサービスと言えます。
社内wikiには業務に関わる情報が全てまとまっている一方で、情報が広範にわたるために欲しい情報が探しにくい・まとめにくいという問題もあります。例えば、分量の長い議事録から自分と関係する部分を探す場面では、関連するキーワードを考えて全文検索を行わなければならず、大きなプロジェクトのドキュメントで知りたい情報を探す場面では、多数の下位文書を全て開いてみる必要があります。
近年、ChatGPTをはじめとする大規模言語モデルベースのツールが業務効率化を図るために用いられることが増えてきました。特に、文書の自動要約によって、情報を探しやすく・まとまりやすくすることができます。社内には既にChatGPTのWebUIやプロキシサーバなどが構築されており、これを活用して便利なツールを開発するという案件が構想されていました。まだ未着手の状態であったため、私がこのプロジェクトに取り組むことになりました。
取り組み事項
まずユーザーヒアリングでは、周りのエンジニア社員と雑談するときや、メンターに連れて行かれたエンジニア社員とのランチ会などで、「社内Wikiを使ってて辛い時ってありますか?」、「仮に社内WikiにChatGPTが組み込まれるとしたら何がしたいですか?」などと質問をしました。元々から想定されていた「議事録を要約したい」、「情報量の多いマニュアルなどで情報を探すのが大変」などに加え、「これまでの作業日誌に基づいて、自身の進捗や成果を効率的にまとめることが難しい」というニーズを確認することができました。このヒアリングを通じて、ユーザーニーズに応えるためには単に一個の文書の中身をChatGPTに渡して要約してもらうだけでなく、複数ページのリンクを渡して同時に処理できることが大事という知見が得られました。
競合調査では、社内で動いている他プロジェクトや、サードパーティーのサービスで本案件とスコープが被るものはないかについて確認を行いました。現時点でConfluenceとChatGPTに特化したようなサービスは見つからなかったので、このまま進めることとしました。
次は、具体的なツールの実装形態について検討を進めました。大きく分けて「社内Wiki画面上で呼び出せるChatbot UIにする」と「社内ChatGPTのWeb UIなど、既にあるシステムに埋め込む」の二つの選択肢がありました。前者ではWikiページ上での対話、後者ではWikiページのリンクをコピペして外部WebUIに貼り付けて対話をする形になります。議論を重ねた結果、開発コストとユーザーとしての取り入れやすさを考慮し、後者の方針を採用することにしました。
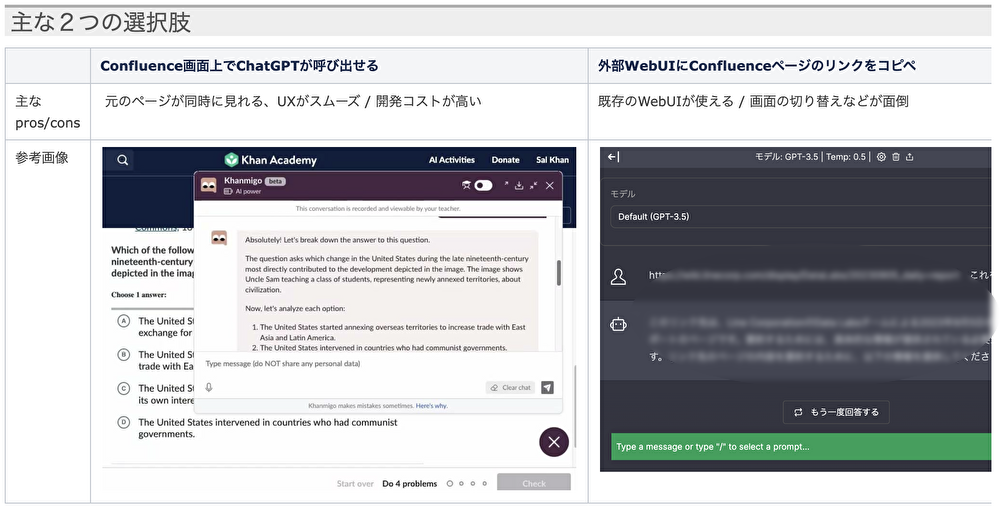
図1:社内Wiki要約ツール案件における実装形態の検討
外部WebUIに埋め込むという方針が立ったので、続けてツールの開発における要件定義(must, should, nice to have)を行いました。「ページのリンクを複数扱えるか」、「渡したページの下位の文書を自動で読み込んでくれるか」などが主な議論点となりました。

図2:要件定義の表(の一部)
今回はインターンの期間も限られており、本案件を本番実装まで見届けることは困難だったので、インターン終了時まではデモ版を作成して要約機能に関する検証を行うことを目標としました。現段階では、MLエンジニアの社員に協力していただき、LangChainを使ったstreamlitアプリを作成し、複数の社内Wikiページのリンクを扱えるか・議事録や日誌の内容を正確に要約できるかなど、要約機能の検証を進めています。
案件としての課題
本案件の最終目標はChatGPTを使った要約機能を検証し、社内ChatGPTの本番環境に実装することになりますので、まだ案件として完了していません。まず要約機能に関する技術的課題として、gpt-4とLangChainを使うには反応速度が遅すぎる・LangChain を使った複数リンクの扱い方の工夫が必要、などといった課題が残されました。要約機能の検証の結果次第、「今すぐ実装できる機能」、「近いうちできるようになりそうな機能」、「将来的な課題に残さざるを得ない機能」の三つに分けて開発フェーズを考えます。その後、「近いうちできるようになりそうな機能」について並行に研究しつつ、「今すぐ実装できる機能」を本番実装までどうもっていくかについて計画を立てていく予定です。
PMとして課題・振り返り
ここではPMとして私が感じた課題と振り返りについてお話しします。
業務を進める中で、一つの難しさと感じたのは、相談相手・仲間を見つけることです。ユーザーヒアリングをするにも、アイディアの壁打ちや技術面の相談をするにもそれに相応しい人を見つけて話しかけないといけませんが、誰に話しかけるべきかというのは明らかではありません。本案件では、技術的課題を検討するために、メンター・infraに詳しい先輩PM・LLMに詳しいMLエンジニア・社内ChatGPTを運用している部署の関係者など、色んな人に声をかけて相談させてもらいましたが、「何を誰と相談するべきか」を判断することが、常に課題に感じられていました。
もう一つの難しさは、ドキュメントの整理です。PMの書くドキュメントはプロジェクトの現況とこれからのスケジュール感が関係者誰が見ても一目で分かるように書かれるのが望ましいですが、時々刻々と変化するプロジェクトの状況に応じて、ドキュメントもだんだん汚くなりがちです。他のPM社員が作成したドキュメントの書き方を参考にし、自分のドキュメントも整理された形で・わかりやすく書くように心がけました。
本案件では、PMの業務において一連の(初期の)企画プロセスを体験できました。ふわっとしたニーズ・お気持ちを具体的に言語化し、要件定義を行い、技術的課題を検討した上に、デモ版作成に向けて取り組むという流れが経験でき、PMの業務への理解度が深まったのではないかと思います。
ユーザー属性推定プロダクトの改善案件
背景
LINEのUser Persona Systemは、閲覧ログなどを用いて年齢・興味などユーザーの属性を推定するMLプロダクトです。推定されたユーザー属性はレコメンドシステムや広告など、様々な下流アプリケーションで活用されます。今回は、このプロダクトの運用の一部に取り組むことになりました。
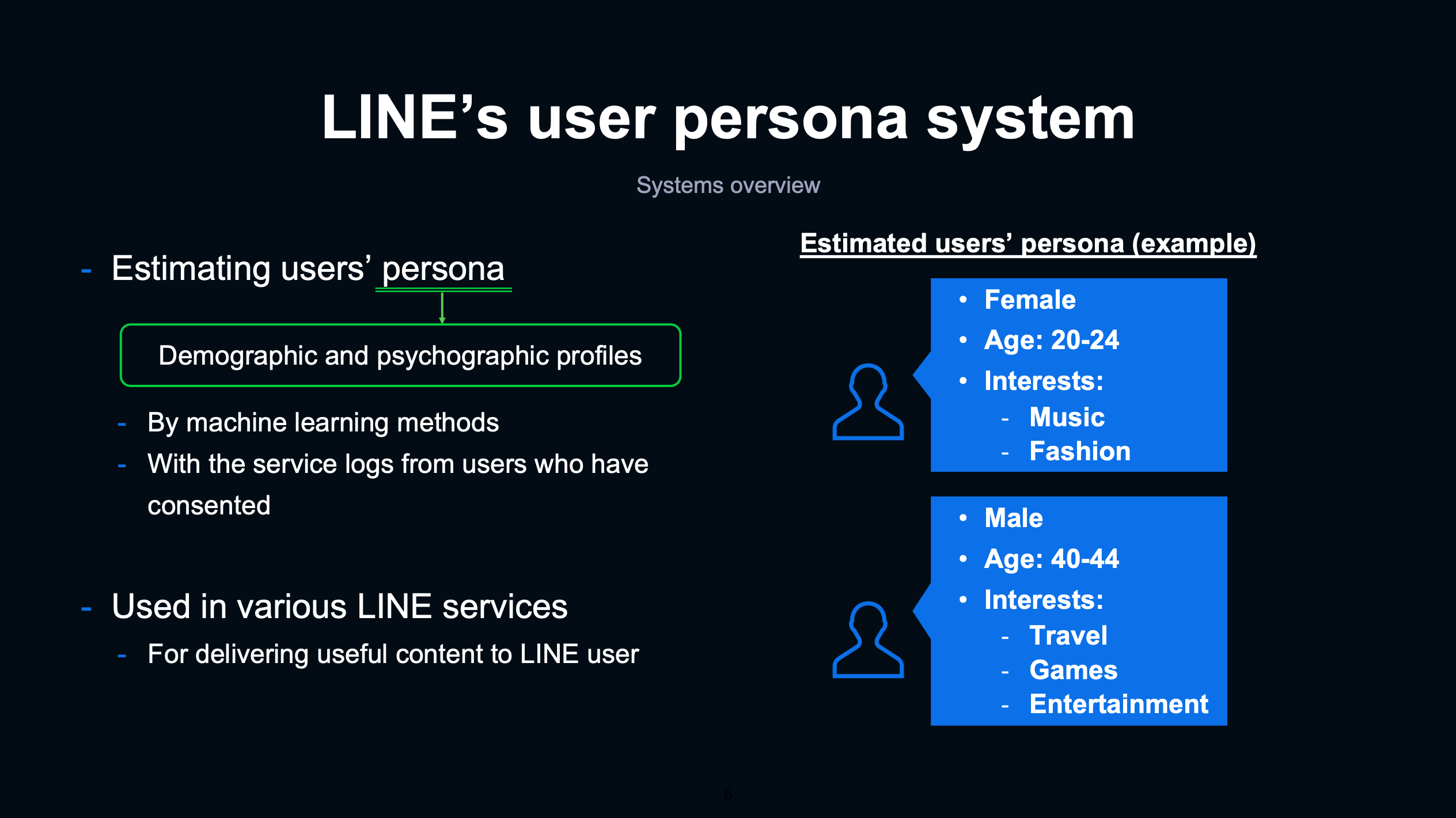
図3:User Persona Systemの紹介(参考)
取り組み事項
ユーザー属性の一つに対して、これまでより多量の正解データが得られたため、そのデータを活用して予測精度を改善するタスクにMLエンジニアとともに取り組みました。
具体的には正解データを追加し新しい学習モデルを構築し、正解データを持たないユーザに対しても予測を行うと精度が上がるかの検証を行いました。
予測を行った結果、「新モデルの予測分布が旧モデルとの予測分布と大きく異なる」というイシューが発生しました。この原因は、正解データのバイアスの影響が学習・予測に影響を与えたと考察されます。
このイシューに由来し、何を持って予測精度が改善したかどうかの判断すべきかという議論になりました。そこで、公開されている統計データを調査し、予測結果の分布と比較するアプローチを取ることにしました。その結果、元の学習データと統計データとは大きな分布の違いがあるにも関わらず、元の予測結果と統計データとは分布が概ね一致していることが明らかになりました。つまり、元の学習データを使ったモデルが、学習データの分布の偏りに関わらず現実の分布に近い予測をしていたという判断が立ちました。この指標に対し、予測精度をあげる手法として、undersampling を行うことなどが検討されました。実は属性推定プロダクトは明確な正解指標がないプロダクトなので「予測の正しさを評価する指標をどうするか」という議論は度々生じます。明確な指標がない課題に対しMLでアプローチすることの難しさを痛感しました。
同じプロダクトの別案件として、精度向上のためのモデル更新のリリースがありました。本リリースでは予測分布が大きく変化するのもでした。例えば、広告のセグメント配信数が突如変わるなど下流アプリケーションへの大きな影響を及ぼす可能性があります。そこで、全ユーザーの中から一部を選び、段階的にリリースする gradual rollout 方式でリリースを行いました。その中で、リリース対象となる二つの地域でコンフリクトが起き、2地域の gradual rollout の開始時期が重ならないように日程調整するなどの課題もありました。
メンターと一緒に本案件を進めていくうちに、Personaにおいて学習と予測の job が全ユーザーに対して毎日走っているが、予測分布が毎日大きく変化しないのであれば、毎日走らせる必要はないのではないかという議論が生じました。PersonaはLINEの全ユーザーに対して実行されるため、その計算量のスケールは非常に大きいです。そのため、job の頻度を減らすことができれば、それにより他の案件にリソースを振り分けたり、メンテナンスにかかる人的リソースを節約できるメリットがあると考えました。実は、これはPersonaだけでなく全MLプロダクトにおいて長期的な課題として存在していたものの、取り組まれていませんでした。特にPersonaの場合、毎日分布が大きく変わることはないため、この問題と相性が良かったと言えます。これを新たな案件として扱い、検討すべき事項の洗い出しやエンジニアとの相談を通じて調査を進める作業に着手しました。
PMとしての課題・振り返り
PMとして、プロダクトを深く理解することの重要性を切実に感じました。Personaはすでに運用が進んでいた大型プロジェクトであったため、そのキャッチアップは特に難易度が高かったです。プロダクト運用に関する技術的な知識はもちろん、データフロー(データがどのように生成され、どのユーザーに使用されるか)などを理解することが求められました。このプロダクトは全社向けに提供されているため、その全体像を把握することが重要でした。
最後に取り組んだ計算リソースに関する案件では、計算リソースやML基盤についての知識が全くなかったため、無知の状態からのスタートとなりました。MLエンジニアや有識者のPM社員の協力を得て調査を開始しました。一方で、プロダクトや社内特有の知識も、HadoopやYARNなど一般的なソフトウェア開発知識も不足していましたが、まずは一般的な知識を自分で調査し補い、有識者とのやり取りをじっくりと読み解き、理解し、知らないことを質問しました。そして、その情報を案件に活かせる形で整理することができました。これらの経験は、未知の案件にどのようにアプローチすべきかを理解するために非常に有意義だったと感じています。
ML PMの業務で学んだこと・感じたこと
学んだこと・感じたこと
初めてのML PMとしての仕事は、以前のエンジニアリングに集中した経験とは異なる楽しさがありました。技術の深化だけでは解決できない問題に対して、全体的な解決策を模索する経験を有意義に感じました。特に社内Wiki要約ツールのプロジェクトでは、自ら共感できるユーザーニーズの部分から始め、プロダクトの設計を主導することができ、刺激的な経験でした。
今回のインターンで得た重学びの一つは、未知の案件や前提知識の不足に対して恐れないことです。特に、初めての仕事や短期間のインターンシップのような場合、前提知識がないことで不安を感じることが多いです。PMとしては、プロジェクトを管理する役割からくるプレッシャーも大きいです。しかし、初めてのことについて理解できないのは当然です。何がわからないかを認識して、汎用的な知識と組織特有の知識を見分け、前者は自ら・後者はチームメンバーから学んでいけば、PMとしての成長にもつながることを実感しました。
インターンでの経験を踏まえ、ML PMに求められると感じたものを以下の図にまとめてみました。

図4:ML PMに求められる4つのこと
1on1 で知った、ML PMの真相
DSC Planningチームのメンバーとの1on1を通じて、ML PMの仕事について色々とお話を聞くことができました。
いわゆるPjM (Project Manager) 寄りのPMもいれば、PdM (Product Manager) 寄りのPMもいて、ML PMにも色んなあり方が存在するということが分かりました。そのあり方によってステークホルダー(企画部、エンジニア、etc)との関係の築き方も変わりますし、求められるスキルセットもそれぞれ違ってきます。一般的に、PjM寄りのPMはエンジニアと、PdM寄りのPMは企画部の人とウェットな関係になりがちです。
なぜML PMをやるのか、仕事のモチベについてもお話を聞くと、「技術を社会実装して生活を便利にしたいから」、「プロジェクトを成功させるのに必要なのはエンジニアの技術力だけじゃないと感じたから」といったモチベが共通していることが分かりました。自分の手を動かしてエンジニアリングをやる、とは異なる方法で、技術の社会実装に貢献するのがML PMの役割だと感じました。
最後に
今回のインターンでは、自らML PMとして案件に着手し、メンターと先輩PMたちから仕事を学びながら進める貴重な経験ができました。LINEは社員たちの熱意が高く、手厚いサポートももらえるため、PMとして刺激されながら成長するにいい環境だと感じました。皆さんもぜひML PM職に興味を持っていただけたらと思います。
最後に、メンターの仁ノ平さんをはじめ、関わってくださったDSC Planningチームの皆さんとMLエンジニアの皆さん、短い期間でしたが、ありがとうございました!