
はじめに
8/8から6週間の就業型インターンに参加しました、中村祥大と申します。私は東京工業大学大学院に所属する修士1年で、現在は深層学習の高速化に関する研究をしています。
今回のインターンではComputer Vision LabのOCRユニットに所属し、その中でも特に、テキスト認識タスクの性能向上に関連するテーマに取り組みました。本レポートではその成果について報告します。
背景
今回のインターンで私はテキスト認識に関連するタスクに取り組みました。テキスト認識とは、与えられた画像に書かれている文字列は何であるかを認識する処理です。
近年、深層学習モデルを用いたテキスト認識が台頭しています。しかしながら、そのようなアプローチには、学習時に登場していないテキストを含む画像に対する認識精度が低下するという問題(Vocabulary Reliance)が存在します。以降ではテキストの集合のことを「語彙」、「学習に用いる語彙」のことをIn Voc、「学習に用いておらず、実際の推論時に登場する語彙」のことをOut Vocと呼びます。実際のユースケースで登場しうるOut Vocの例として、「anatidaephobia」の様な専門的すぎる語、「LINE CLOVA」の様な一般的な辞書には含まれていない語などがあげられます(LINE CLOVAはLINEのAIテクノロジーブランドです)。このような語彙を全て列挙して学習に用いることは非現実的であるため、Vocabulary Relianceを緩和するような学習手法が求められています。
Vocabulary Relianceの存在について初めて報告した論文[1]では、ランダムな文字列からなる語彙を新たに用意し、それを用いてデータセットを増量することでOut Vocに対する精度が改善したという結果を報告しています。しかしながら、上記の手法には「Out Vocに対する性能は増加するものの、In Vocに対する精度が低下する」という課題がありました。そこで、今回のインターンでは「Out Vocに対する性能を上げつつ、In Vocの性能低下を緩和する、新たな追加用語彙生成手法の提案」に取り組みました。
使用したツール/データセット
今回の実験には以下のツールやデータセットを用いました。
SynthText
SynthText[2]は人工的に生成されたテキスト画像のデータセットです。今回の実験ではこのデータセットに含まれるテキストの一部を語彙に使用しています。
high-frequency-vocabulary
high-frequency-vocabularyは英語の頻出単語3万語をまとめたリポジトリです。今回の実験ではこのリポジトリに含まれるテキストの一部を語彙に使用しています。
SynthTIGER
SynthTIGER[3]は NAVER が開発した人工テキスト画像の生成ツールです。生成に用いる語彙を与えることで、それらの語彙を用いたテキスト画像を生成できます。今回の実験で用いたデータセットは、このツールを用いて作成しています。
MMOCR
MMOCR[4]はOCRに関する実験を補助するライブラリです。モデルの学習や推論などを統一的なインタフェースで行えます。今回の実験はMMOCRを用いて実行しています。
問題設定
対象とする文字種
LINE CLOVAが提供する「CLOVA OCR」のように、実世界で用いられている文字認識システムでは多様な種類の文字種を扱うことができますが、今回のインターンでは問題を簡単にするため、扱う文字種を英小文字+数字の36種類としました。それにともない、実験で外部のコーパスを用いる際には「大文字を小文字に変換し、記号を削除する」という前処理をおこなっています。
In Voc/Out Vocの生成方法
Out Vocの要素として考えられる語は無限に存在しますが、今回のインターンでは手始めに「In VocとOut Vocが類似性を持つ」という(かなり強い)仮定を置きました。具体的には、以下の2つからなる6000語の語彙を、3000語ずつランダムに分割することでIn/Out Vocを構成しています。
- high-frequency-vocabularyの中から4000語
- 前処理後のSynthTextから「数字を含む25文字以下の語」を2000語
イメージとしては以下の通りです。

In/Out Vocには次の様な語が含まれます:training,143829,4ever,9072bluecispittedu
評価方法
上記で生成したIn Voc, Out Vocに対し「In Vocと一緒に学習に用いることで、Out Vocに対する精度を改善する(=Vocabulary Relianceを緩和する)語彙」を提案することが本実験の目的です。提案した語彙の評価は次の方法で行いました。
- In Vocから学習用データセット(a)と評価用データセット(b)を作成する。同様に、Out Vocから評価用データセット(c)を作成する
- 生成にはSynthTIGERを用いる
- In Vocに対する学習用データセットと評価用データセットは、データセットに含まれているテキストの集合(コーパス)こそ同一だが画像としての内容(背景、文字に対する加工など)が異なっている
- これらのデータセットは全ての実験で同一のものを用いる
- 提案した語彙から学習用データセット(d)を作成する
- (a)+(d)を用いてモデルを学習する。
- 学習したモデルを用いて(b)(c)に対する性能をそれぞれ評価する(評価の詳細は後述)
手法
モデル・学習手法
今回の実験では、モデルとしてSAR[5]を用いました。全ての実験でAdamを用いた10万イテレーションの学習を行っています。
語彙の構成方法
今回考えるOut VocはIn Vocと類似性を持ちます。そのため、「In Vocに類似した語彙」を作成することができれば、そのような語彙は間接的にOut Vocをも近似しており、それを用いることで性能向上が見込めるのではないかと考えました。「In Vocに類似した語彙」を構成しうる要素として、今回は「文字間の遷移確率」に注目しました。
また、元論文ではランダムな追加語彙について、その文字列長がIn Vocと同等の分布になるように生成しています。しかしながら、この分布を変更する(たとえば、In Vocにあまり含まれない長さの語を多くするなど)ことで、元の語彙に不足していたサンプルが補われ、性能が向上するのではないかと期待しました。
以上の理由から、学習データに追加する語彙を構成する要素として「文字間の遷移確率」「文字列長の分布」の2軸を考えました。具体的には、文字間の遷移確率2パターン、文字列長の分布3パターンで以下に示す6通りの追加用語彙を用いて実験を行いました。各語彙は、(In/Out Vocと同様に)3000個のユニークな語からなります。
|
語彙名 |
文字列長の分布 |
文字間の遷移確率 |
|---|---|---|
|
Fixed Random |
In Vocを近似 |
ランダム |
|
Uniform Random |
ランダム |
ランダム |
|
Reversed Random |
In Vocと対称 |
ランダム |
|
Fixed Markov |
In Vocを近似 |
In Vocを近似 |
|
Uniform Markov |
ランダム |
In Vocを近似 |
|
Reversed Markov |
In Vocと対称 |
In Vocを近似 |
各項目の詳しい説明は以下の通りです。
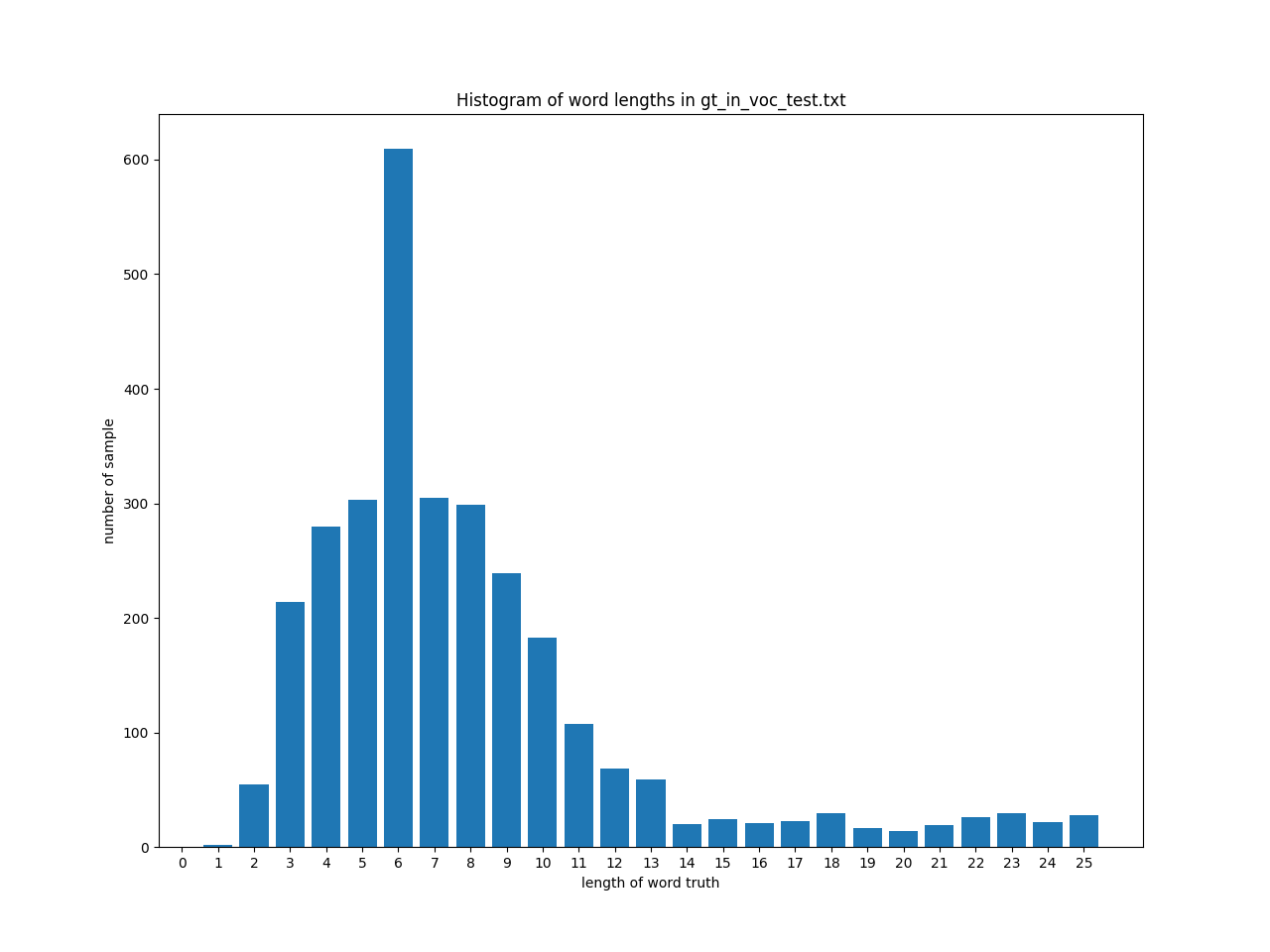
文字列長の分布
In Vocの文字列長は以下の様に分布しています。ここで、横軸は文字列長、縦軸は語彙に含まれているその文字列長の語数です。
追加で用いる語彙の文字列長の分布として、次の3通りの生成方法を考えました。
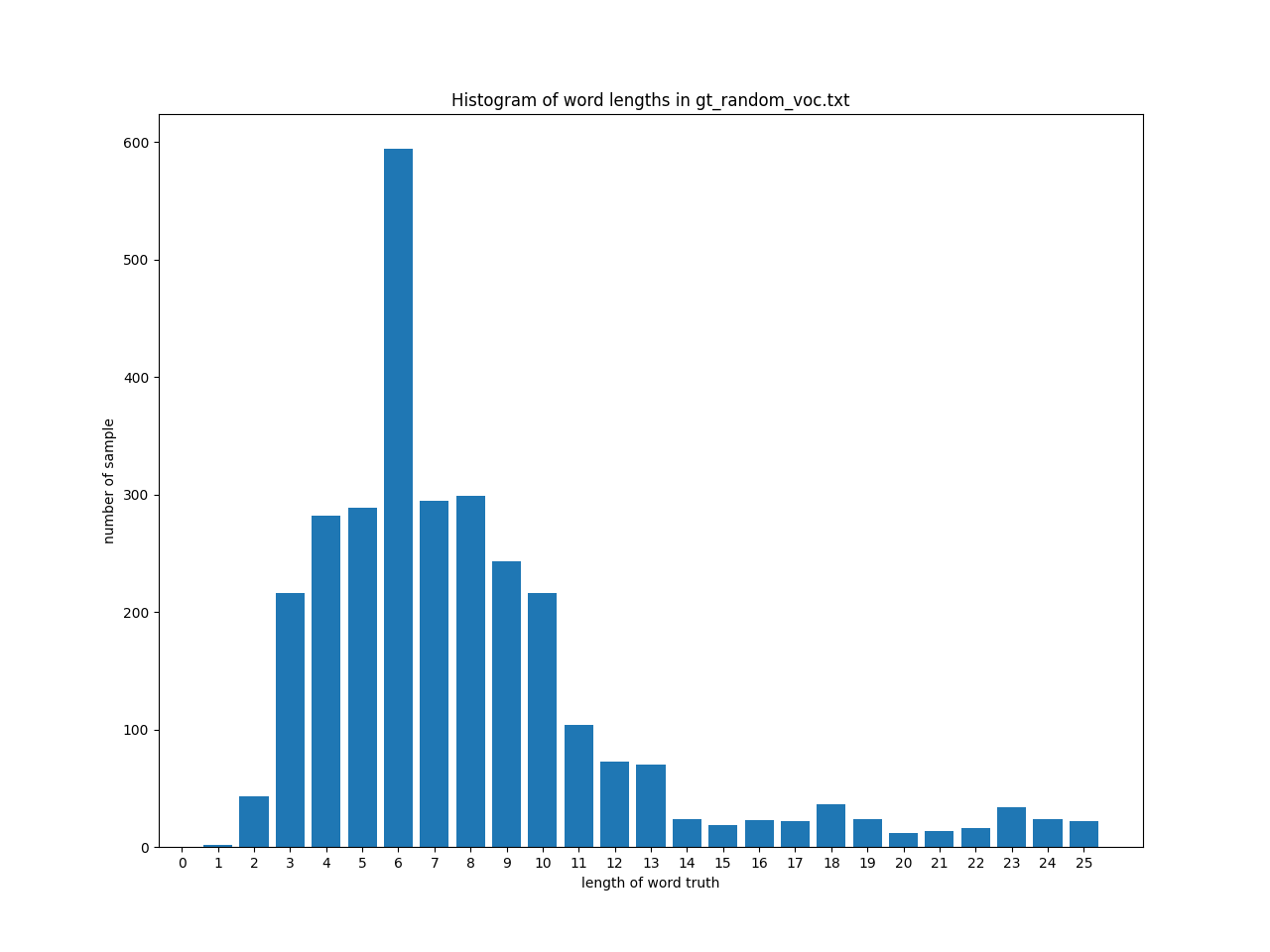
In Vocを近似 (Fixed)
In Vocの語の長さに近くなるように、語の長さを調整します。この設定は元論文[1]で採用されているものです。
次のような文字列長の分布になります。
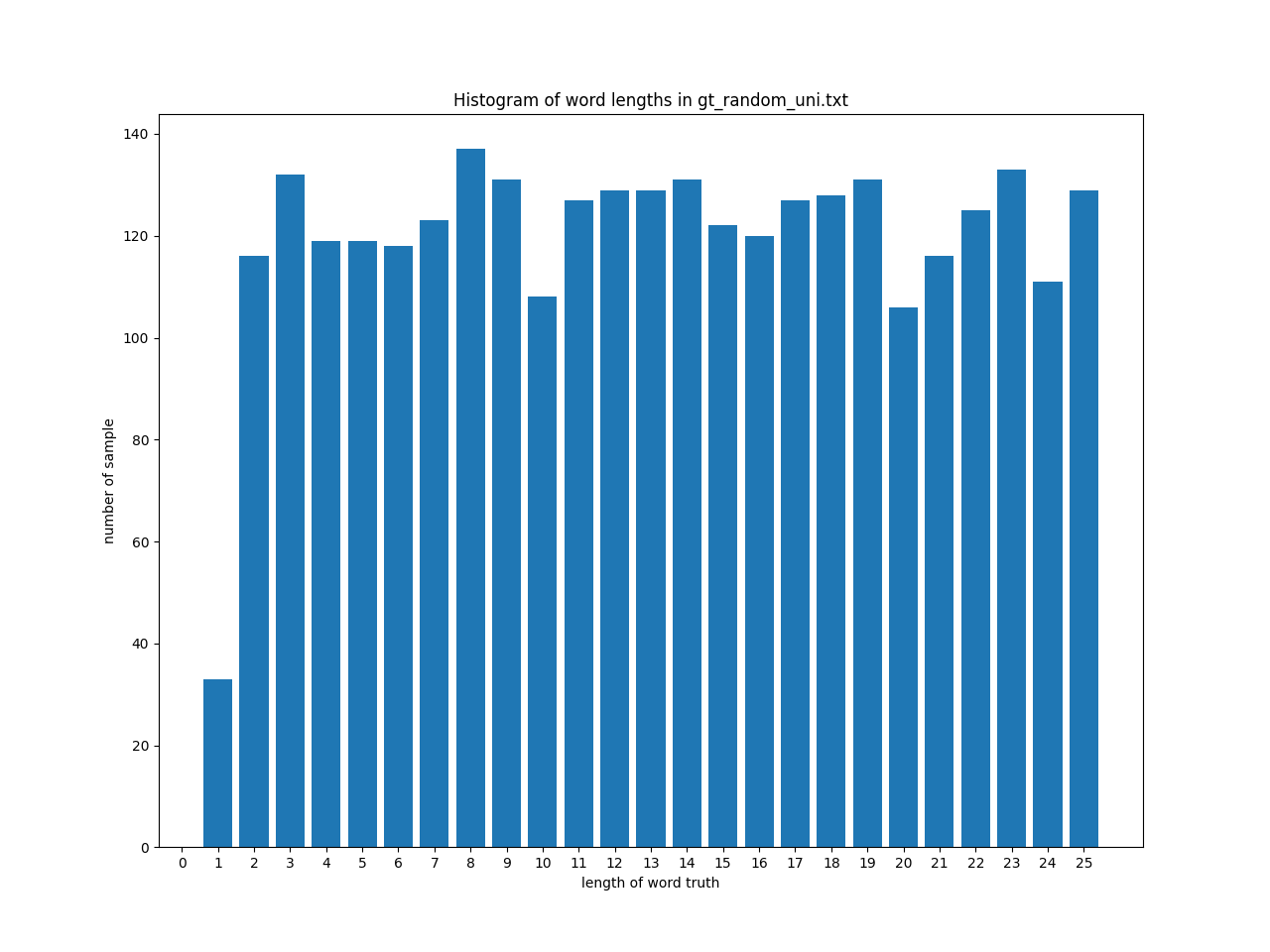
一様分布 (Uniform)
In Vocの文字列長の範囲(1~25)が一様になるように語の長さを調整します。この様な分布を用いることで、(今回のIn Vocに比較的少ない)長い文字列に対する学習が行われ、性能が向上することを期待しました。
次のような文字列長の分布になります。1文字の語は高々36通りしかないため、その部分のみ登場回数が少なくなっています。
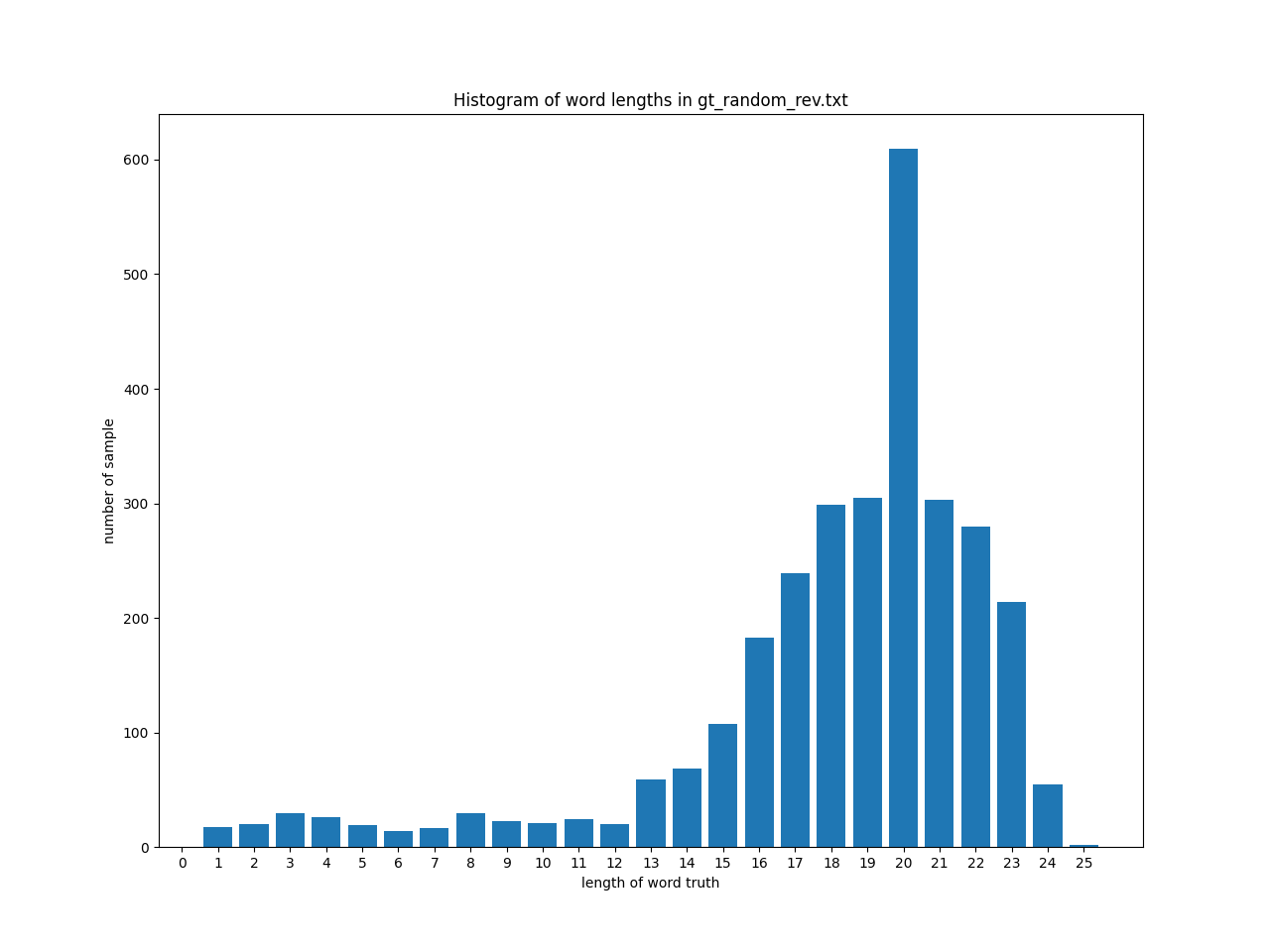
In Vocと対称 (Reversed)
長さaの文字がIn Vocの長さ26-a文字の語数と近くなるようにします。この様な元の分布とは大きく異なる分布の語彙を追加することで、性能が変化することを期待しました。
次のような文字列長の分布になります。
文字間の遷移確率
ランダム (Random)
現在の文字に関係なく、英小文字+数字の36通りの中から等確率で文字を選択します。
この方法で生成した文字列の例: 6b8agk5m1q6x2, 25twpjcd0h1a, azwble3da
In Vocを近似 (Markov)
マルコフ連鎖を用いて語を順番に生成します。 具体的には、In Vocに含まれる語をもとに「ある文字からある文字に遷移する確率」を計算し、その遷移確率に従って文字を選択します。ここで、最初の文字は「ある文字が最初に登場する確率」を計算しておき、その確率をもとに選択します。また、語の長さは文字列長の分布で指定するため、途中で文字を打ち切ることはありません
この方法で生成した文字列の例: durtor, peter122060, zabong
データセットの作成
学習用データセット
SynthTIGERを用いて、各語彙から30000枚の人工画像を生成しました。参考として用いるため、Out Vocからなる学習用データセットも作成しました。
背景画像や文字に対する画像的な加工(ぼかし、スキューなど)はデフォルト設定のまま用いました。
以下が生成された画像の例です。




評価用データセット
In/Out Vocを元にSynthTIGERで30000枚ずつ生成しました。生成に用いた設定は学習用データセットと同様です。「評価方法」の項で述べたように、In Vocを用いたデータセットには学習用と評価用の両方が存在します。これらのデータセットは、コーパスとしては同一のものですが、画像としての内容は異なっています。Out Vocに対しても同様です。
実験結果
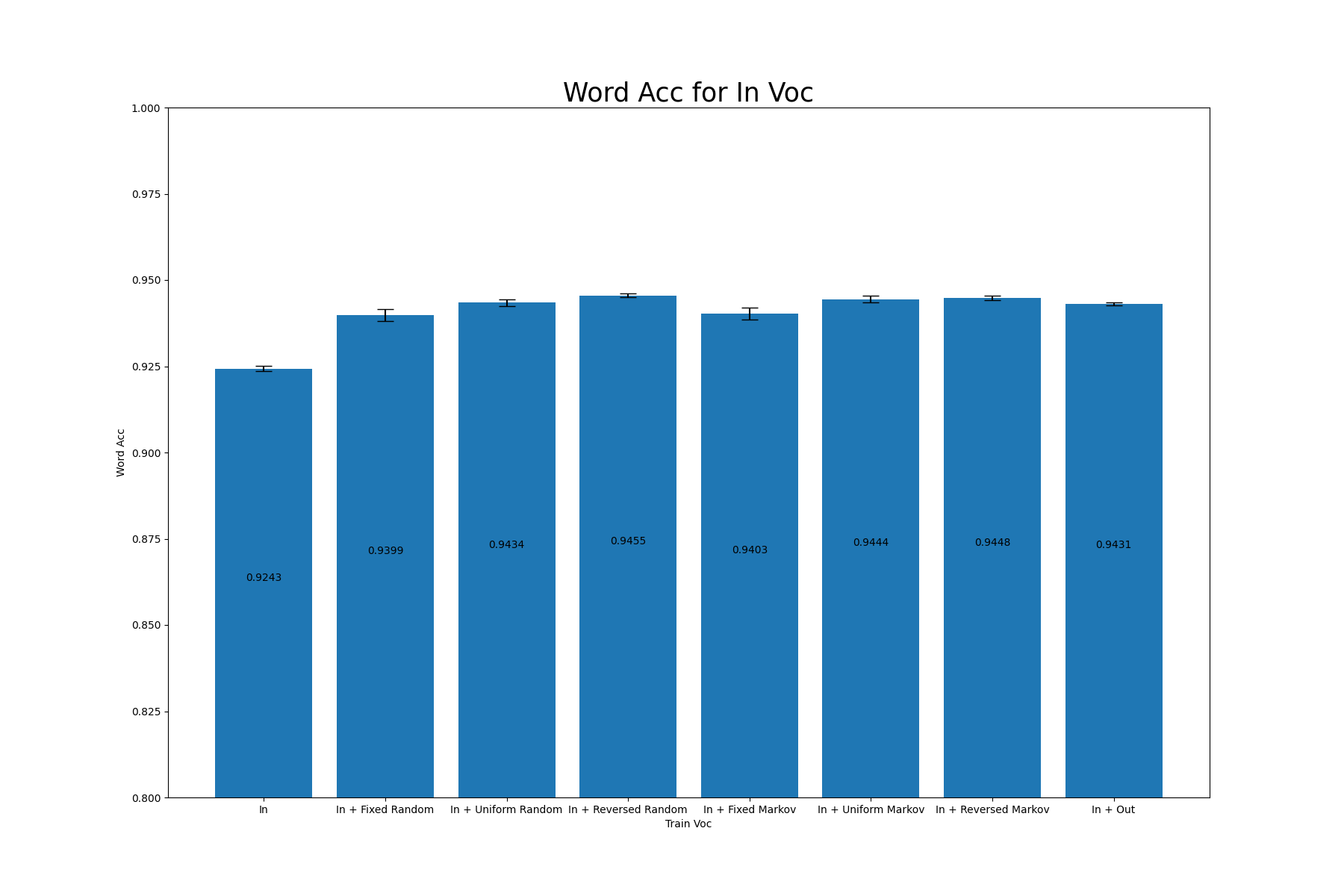
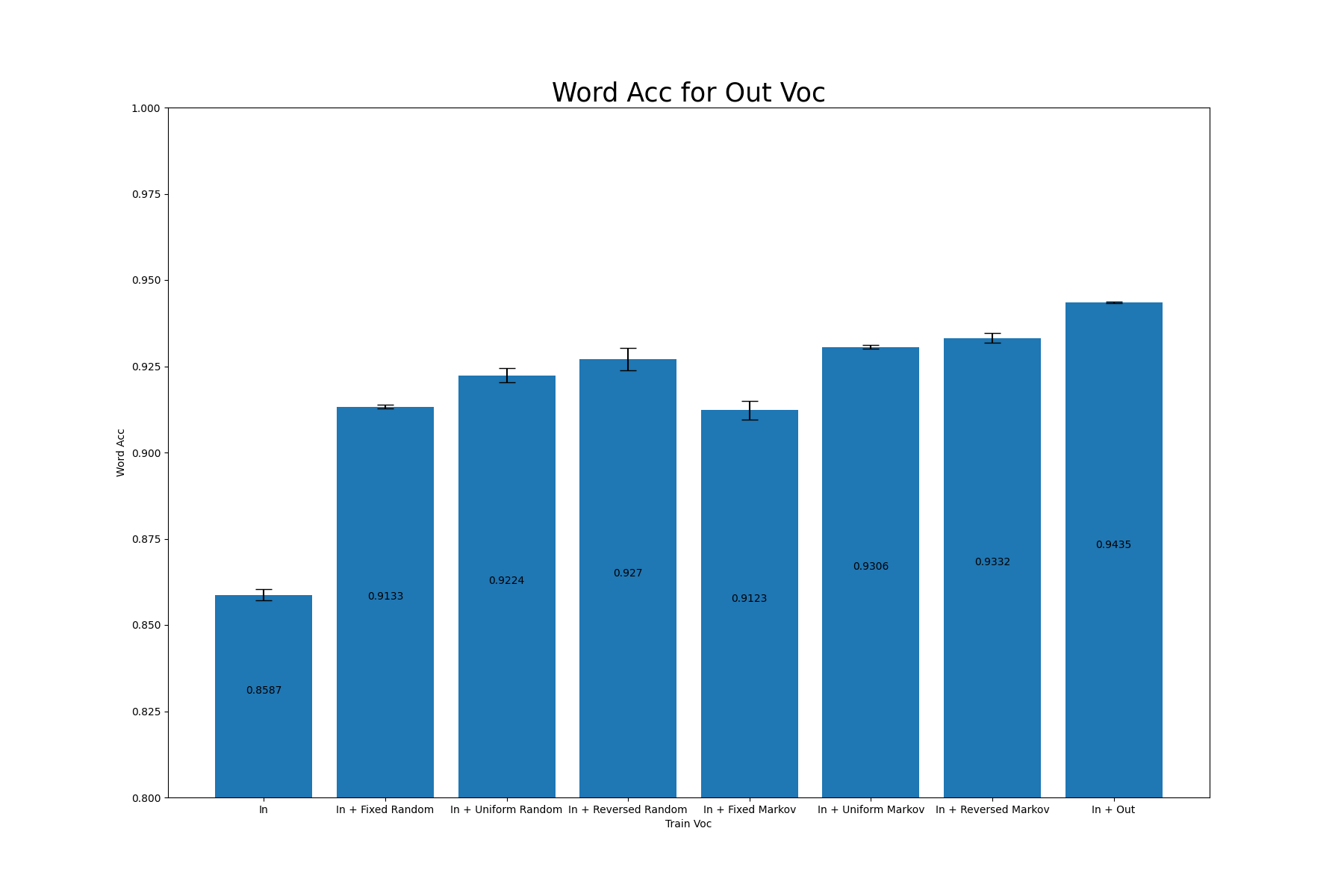
各語彙によって生成されたデータセットを用いたSARモデルの性能は以下の通りになりました。異なるシード値で3回学習を行なっています。ここで登場するWord Accは、(正しく認識できた画像数/評価データセットに含まれる総画像数)で計算される指標で、高いほどモデルが高性能であることを示しています。
参考のために、In Vocの語彙のみで学習させたモデル、In Voc+Out Vocの語彙で学習させたモデルの結果も示します。これらの学習に用いたデータセットは評価に用いたものとは異なります。
|
Word Acc |
||
|---|---|---|
|
Train Voc |
In Voc |
Out Voc |
|
In |
0.9243±0.0008 |
0.8587±0.0016 |
|
In + Fixed Random |
0.9399±0.0017 |
0.9133±0.0005 |
|
In + Uniform Random |
0.9434±0.0010 |
0.9224±0.0020 |
|
In + Reversed Random |
0.9455±0.0005 |
0.9270±0.0032 |
|
In + Fixed Markov |
0.9403±0.0017 |
0.9123±0.0027 |
|
In + Uniform Markov |
0.9444±0.0010 |
0.9306±0.0006 |
|
In + Reversed Markov |
0.9448±0.0006 |
0.9332±0.0014 |
|
In + Out |
0.9431±0.0004 |
0.9435±0.0002 |
この結果をグラフで示したものは以下の通りです。
考察
Vocabulary Relianceは発生したか
今回の実験では、In + Outを学習に用いた場合を除く全ケースにおいて、「In Vocに対するWord Acc」>「Out Vocに対するWord Acc」となりました。よって、Vocabulary Relianceは確かに発生していると言えます。
語彙の追加によってIn Vocに対する性能は悪化したか
語彙を追加した全てのケースにおいて、In Vocに対するWord Accが上昇しました。この現象は[1]で報告されていた「Random Vocを加えることによってIn Vocに対する認識精度が低下する」という結果と異なります。今回の実験設定では、語彙の抽出方法や学習データセットの枚数、データセットの生成に用いたツールなどが[1]とは異なっており、これらの違いがこの結果を引き起こしたのだと考えられます。具体的にどの違いがこの差異を生んでいるのかを突き止めることは今後の課題です。
文字列間の遷移確率の変化が性能に影響を与えたか
In + (Fixed/Unifrom/Reversed) RandomとIn + (Fixed/Unifrom/Reversed) Markovの性能を見ると、概ねMarkovを用いた方が良い結果となっているものの、その差はRandomと比べ僅か(1%未満)であることがわかります。
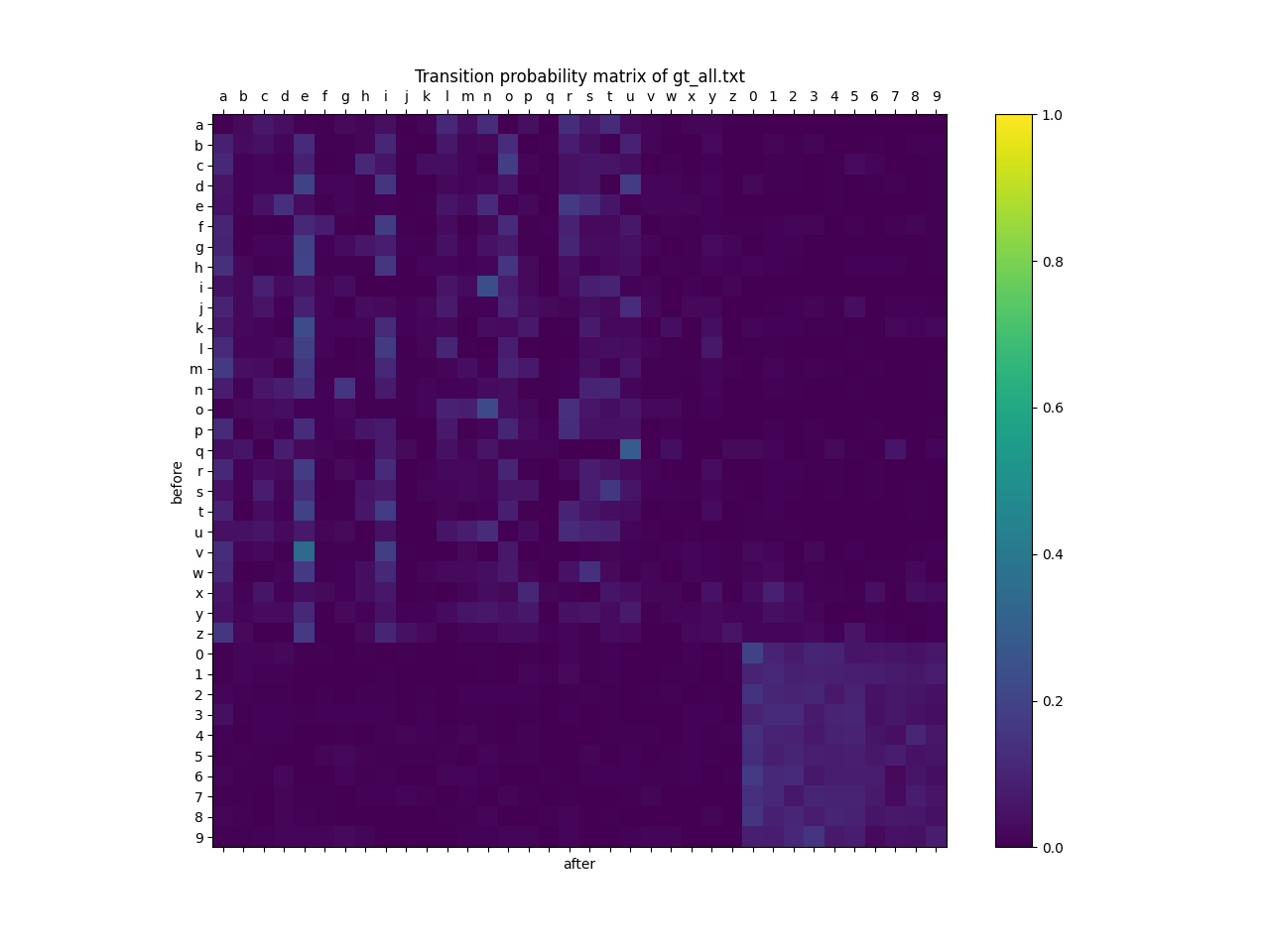
今回のIn + Fixed Markov によって生成したデータセットから、文字間の遷移確率を計算したものが以下の図です。縦軸が遷移前の文字、横軸が遷移後の文字を表しています。
また、同様の可視化をIn + Fixed Randomによって行った結果が以下の図になります。
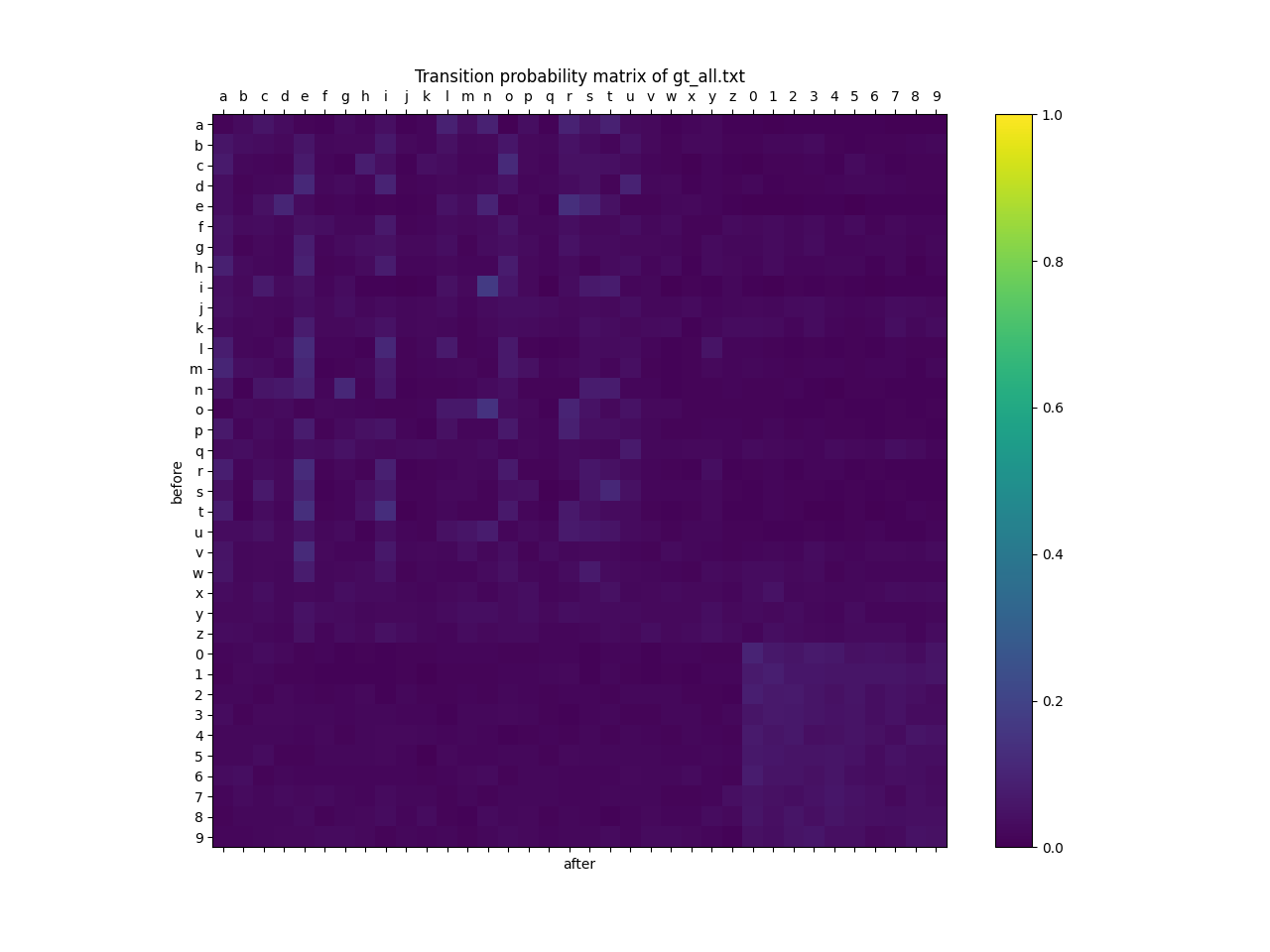
これを見ると、In + Randomの遷移確率は、In + Markovに比べランダムに近くなっているものの、それでもなお文字間の遷移確率に差があることがわかります。ここから、今回の実験において文字間の遷移確率が性能に与える影響が軽微だった原因の一つとして、In + MarkovとIn + Randomの遷移確率の差が性能に大きく影響を与えるレベルにまで至っていなかった可能性が考えられます。
文字列長の分布の変化が性能に影響を与えたか
「文字列長の分布」という軸に注目した場合、今回の実験では分布をFixedからReversed/Uniformに変化させることで、Out Vocに対して概ね1~2%程度改善しました。この結果から、新たな語彙を生成する際に文字列長の分布を考慮する重要性が示唆されます
今回の実験の結果を一般化できるか(任意のIn Vocに対し、Reversed/Uniformな分布が有効であるか)はまだ判明していません。しかしながら、文字列長の分布をIn Vocのものから変化させることで、(少なくとも今回の実験においては)性能が向上したという結果は新しく得られた知見です。
おわりに
インターンを開始する前は無限にあると感じられた6週間という期間ですが、蓋を開けてみれば想像以上に短く、本当にあっという間でした。
実験の面でも今後の課題とせざるを得なかった部分があり、「もう少し時間があれば…」「もう少し手際よく実験を進められれば…」と少なからず感じる部分もありました。
それでも、僅かながらでも新しい点を発見し、それをこの様な形でまとめられたことは、今後の糧になる貴重な経験だと感じています。
支えていただいたメンターの長内さん、CVLチームの皆さま、本当にありがとうございました。
参考文献
- Zhaoyi Wan et al., "On Vocabulary Reliance in Scene Text Recognition", in Proceedings of CVPR, 2020
- Ankush Gupta et al., "Synthetic data for text localisation in natural images", Proceedings of IEEE conference on computer vision and pattern recognition, 2016
- Moonbin Yim et al.,"SynthTIGER: Synthetic Text Image GEneratoR Towards Better Text Recognition Models", Proceedings of ICDAR, 2021
- Zhanghui Kuang et al., "MMOCR: A Comprehensive Toolbox for Text Detection, Recognition and Understanding", Proceedings of ACM MM, 2021
- Hui Li et al., "Show, Attend and Read: A Simple and Strong Baseline for Irregular Text Recognition", in Proceedings of AAAI, 2019