
Data Scienceセンターの谷川です。Data Scienceセンターは、LINEアプリをはじめとするLINEファミリーサービス向けにデータ活用を行う専門組織です。私はData Scientistとして、主にメッセージやスタンプなどコミュニケーション機能の分析を担当しています(LINE DEVELOPER DAY 2020で登壇しました)。コミュニケーション機能の分析においては、行動ログデータだけでは捉えられないユーザの感情についても考慮が必要です。この課題に取り組むべく、LINEでは定性調査(インタビューなど)と定量調査(アンケートや行動ログデータ分析)の両方を組み合わせる Mixed Method を活用しています(企画者が具体的な事例について発表しました)。このような業務を通じて、定量分析を専門とするData Scientist として UX Research など定性調査の知識も取り入れる必要性を感じていました。ちょうど Quant UX Con の開催を知り、開催概要で紹介されていた "Quantitative UX Researcher" という職名自体への興味もあって、オンラインにて聴講しました。
Overview
Quant UX Conは、Quantitative(定量的な)UX Research を主題とするカンファレンスで、2022/06/08 ~ 09 に初めて開催されました。コロナ禍ということもあり、アメリカでの現地開催とオンラインでの同時中継のハイブリッド形式でした。オンラインでの聴講のために「hopin」というオンライン会議システムが導入されており、聴講したい講演のみを選択して自分だけのスケジュールを組めたり、ZOOMのようなツールを通じて聴講やチャットができたりと、快適に講演を楽しむことができました。参加者は76カ国から約2500人いて、職種としては Quantitative UX Researcher、Data Scientist、Data Analyst、Marketerなど Quantitative UXに関連のあるポジションの方が多かったです。有名なTech企業で "Quantitative UX Researcher"という職名が採用されているからか、初開催にも関わらずスポンサーには有名企業が名を連ねていました。
Quant UX Con が論文発表を行う形式の国際会議と大きく違うところは、実務よりの発表が多かった点です。実務における課題に対しての分析実例や、バイアス除去など分析の際に注意するポイントなどを取り上げている発表もあり、自分自身の日々の業務と照らし合わせながら、共感できる内容が多々ありました。おそらく "Quantitative UX Research" という言葉自体がまだ浸透していないために、基調講演では "Quantitative UX Researcher" の定義から始まり、講演・ワークショップ・企画セッションでもQuantitaive UX Researcherとしてのバックグラウンドやスキルについて熱く議論されていたのが印象的でした。


講演
Quant UX Con では、2日間で67件の講演(うち2件が基調講演)がありました。ほとんどの講演が発表と質疑応答で15分、長いものでも30分と全体的に短めの発表が多かったです。特にモデルの新規性が強調される通常の学会と比べて、Quant UX Con で紹介される事例は基本的に既存の統計モデルや機械学習モデルが適用されていて、手法自体の説明は簡略化されていました。また、UX Researcherの聴講者も多いので、Data Scienceの手法を適用していないUX Research中心の事例発表も多かったです。
以下では、(1) Quantitative UX Researcher という職種自体について議論していた講演2件と (2) Data Science や Mixed Methods の適用事例について解説していた講演3件を取り上げて紹介します。
1. Talks about Quantitative UX Researcher's role
1-1. Keynote: History of Quant UX
by Kerry Rodden from Code for America
講演スライド: https://drive.google.com/file/d/1mw7kGKE6qi0g01RBwt6HQWuL3G62WxV_/view?usp=sharing
講演者であるKerry Roddenが、Google在籍時に"Quantitative User Experience Researcher"という職名で求人を出した経緯や、Google社内での Quantitative UX Researcher の実際の働きについて話されていました。
Quantitative UX Researcherという職名はどのように誕生したか?
Kerry Roddenは、Google在籍中の2006年に初めて"Quantitative User Experience Researcher"という職名で求人を出したそうです。当時は Data Scientist という職種すら存在しなかったため、Quantitative User Experience Researcher の必要なスキルにも Data Science という言葉は入っていませんでした。Googleでは2006年当時、現在のData Scientist のことを Quantitative Analyst と呼んでいたことから、その名前をとって、"Quantitative UX Researcher"という職種名が誕生したそうです。
Quantitive UX Researcherに必要なスキルとは?
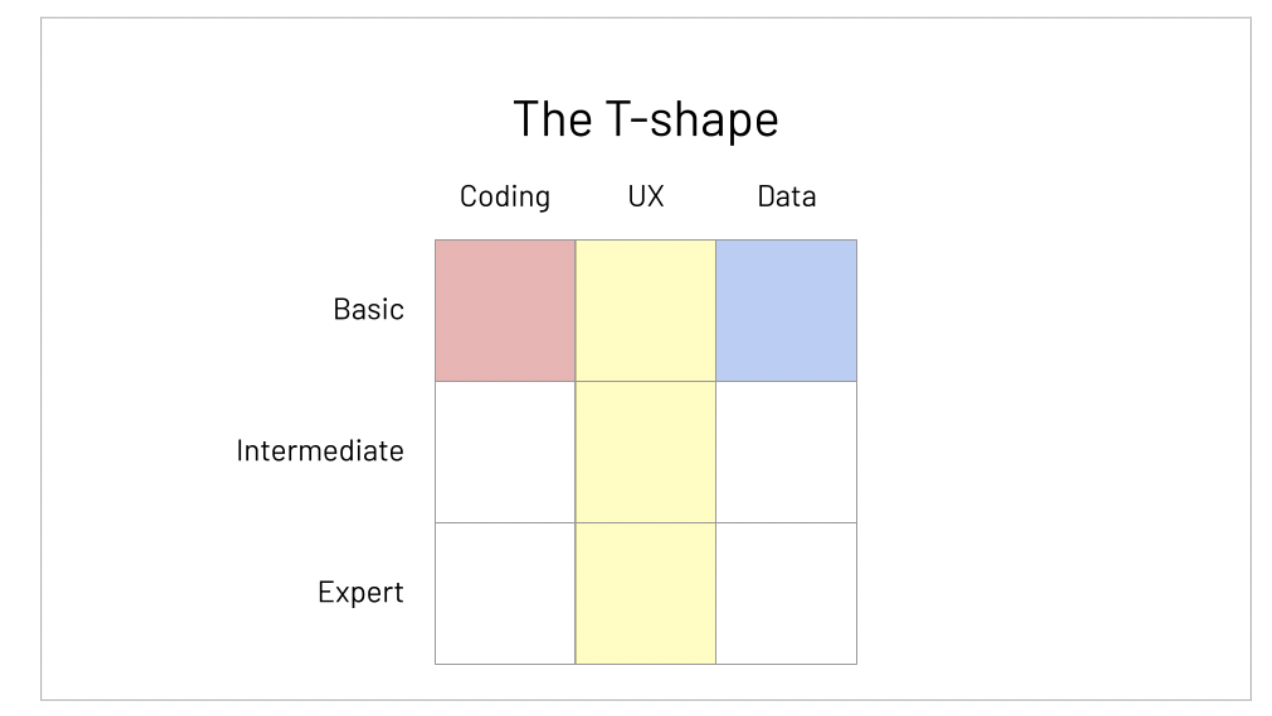
Quantitative UX Researcherに必要なスキルについても触れていて、Data Scientistに必要なスキルを表現する図とよく似た以下のようなベン図を使って説明していました。具体的には、Data Scientistのためのスキルでは domain knowledgeを表す円が、この職種のためのスキルでは UX になっている点(図中の黄色い円)が大きな違いであると話されていました。初めて"Quantitative User Experience Researcher"という職名で求人を出したときは、スキルが3要素と多岐に渡ることからそもそも候補者を見つけるのが難しい上に、3要素全てを専門家として極めることが難しく、採用が困難だったそうです。そのため、当時IDEOの採用で利用されていたT-sharped skillsを利用して、各スキルのレベルを判断できるようにしたそうです。採用の際には、少なくとも3要素の基本的知識があり、少なくとも一つの要素において専門家であることを重要視していたそうです。
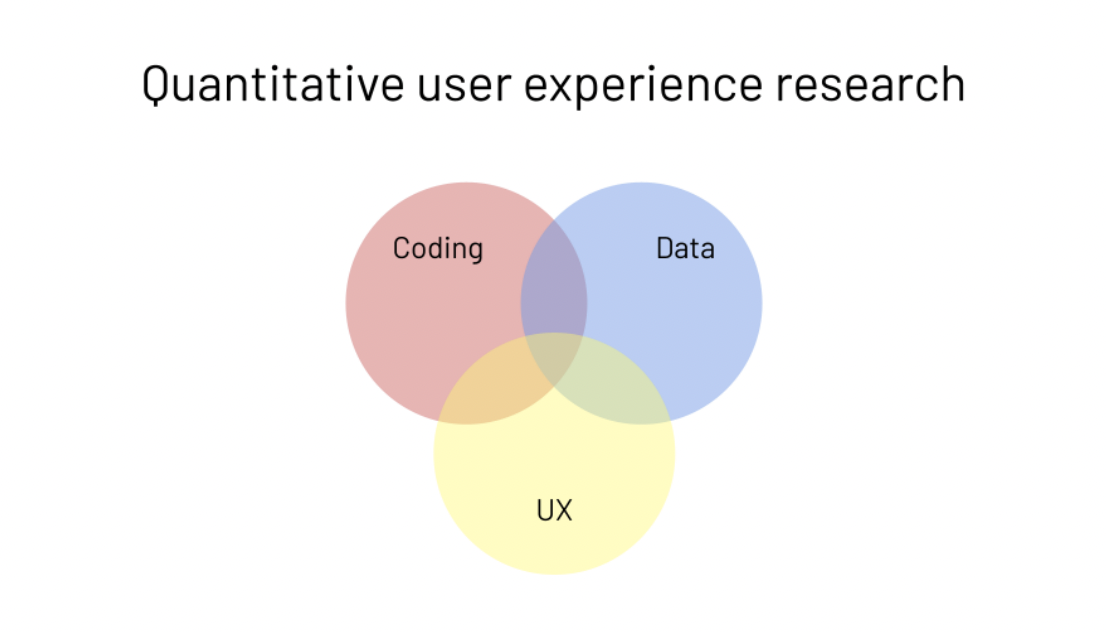
Google初のQuantitative UX Researcher5人によるチームでの実績例
Quantitative UX Researcherチームで取り組んだ、実際の事例についても紹介されていました。事例の中には、UXに関する有名なフレームワークとして知られているHEART Frameworkも含まれていて、Googleではかなり前からQuantitive UX Researcherが主体となって活動されていたことに驚きました。
- HEART Frameworkの作成と浸透
- GmailのLabelのリデザイン
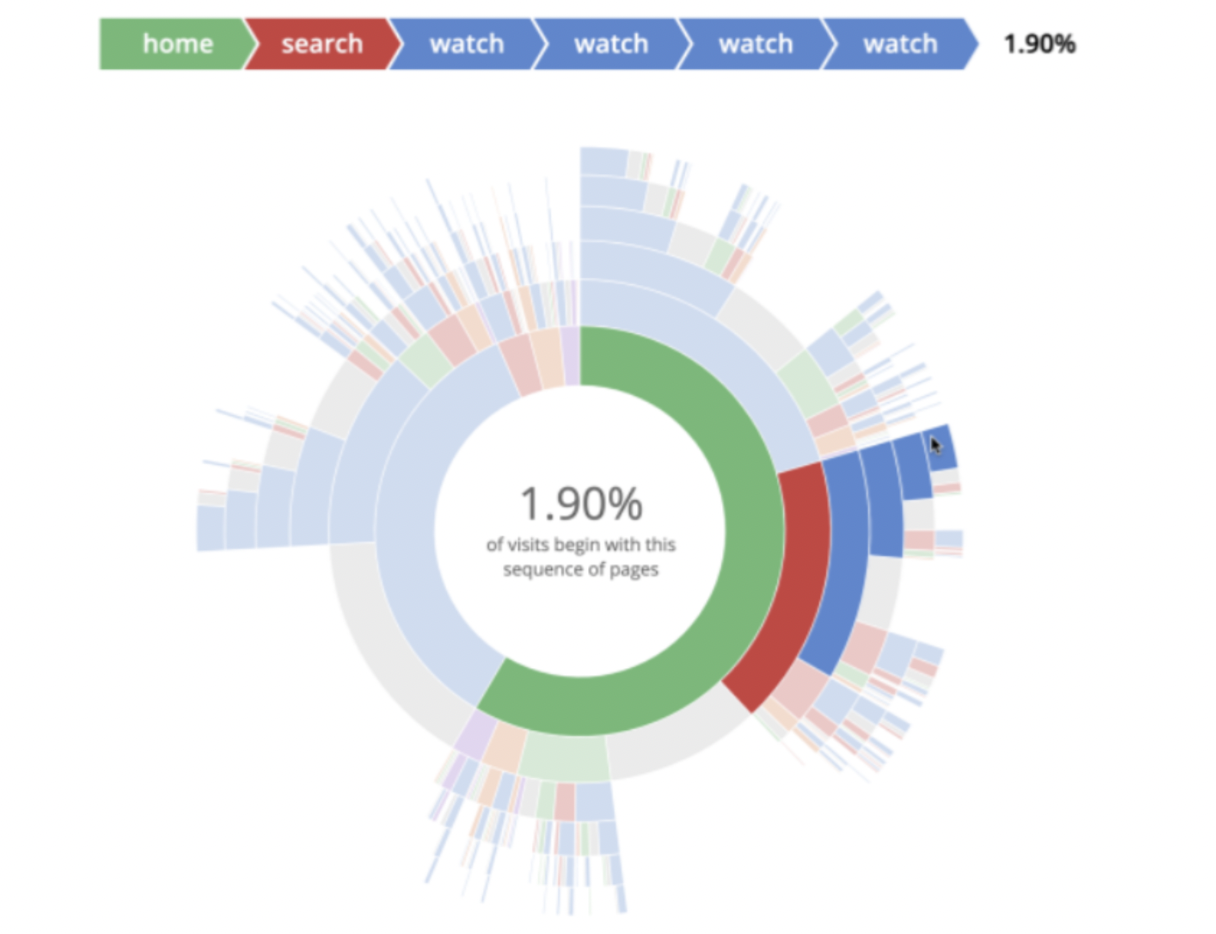
- Sunburst Visualization(下図)を使ったYoutube上のユーザ行動の可視化
1-2. How "Quant" are you ?
by Maria Cipollone, Senior UX Researcher at Spotify
講演スライド: https://drive.google.com/file/d/1NGrO77T439VuIEHMgH2dCvZnZTFkLB3Y/view?usp=sharing
この発表では、"Quantitative UX Researcher"という単語が含まれる22個の職務記述書の"responsibilities(職責)"や"requirement(必要条件)"のデータを取得し、atlas.tiを使って重要なテーマを表す単語やフレーズにラベルを割り当てて分析した結果を紹介していました。

多くの職務記述書で共通していたのが、"Survey"という単語を多く含んでいるという点で、Quant UX Researcherの職務において"Survey"はとても重要なものであることを示していると考えられます。また、特に頻出していたラベルを太文字にして紹介されていた図が以下です。太文字になっているラベルを見ると、"data science"や"Python", "Computer Science"というものも含まれていて、Quantitative UX Researcherという職業が、Data Scientistにも近しい部分があることを示唆しています。
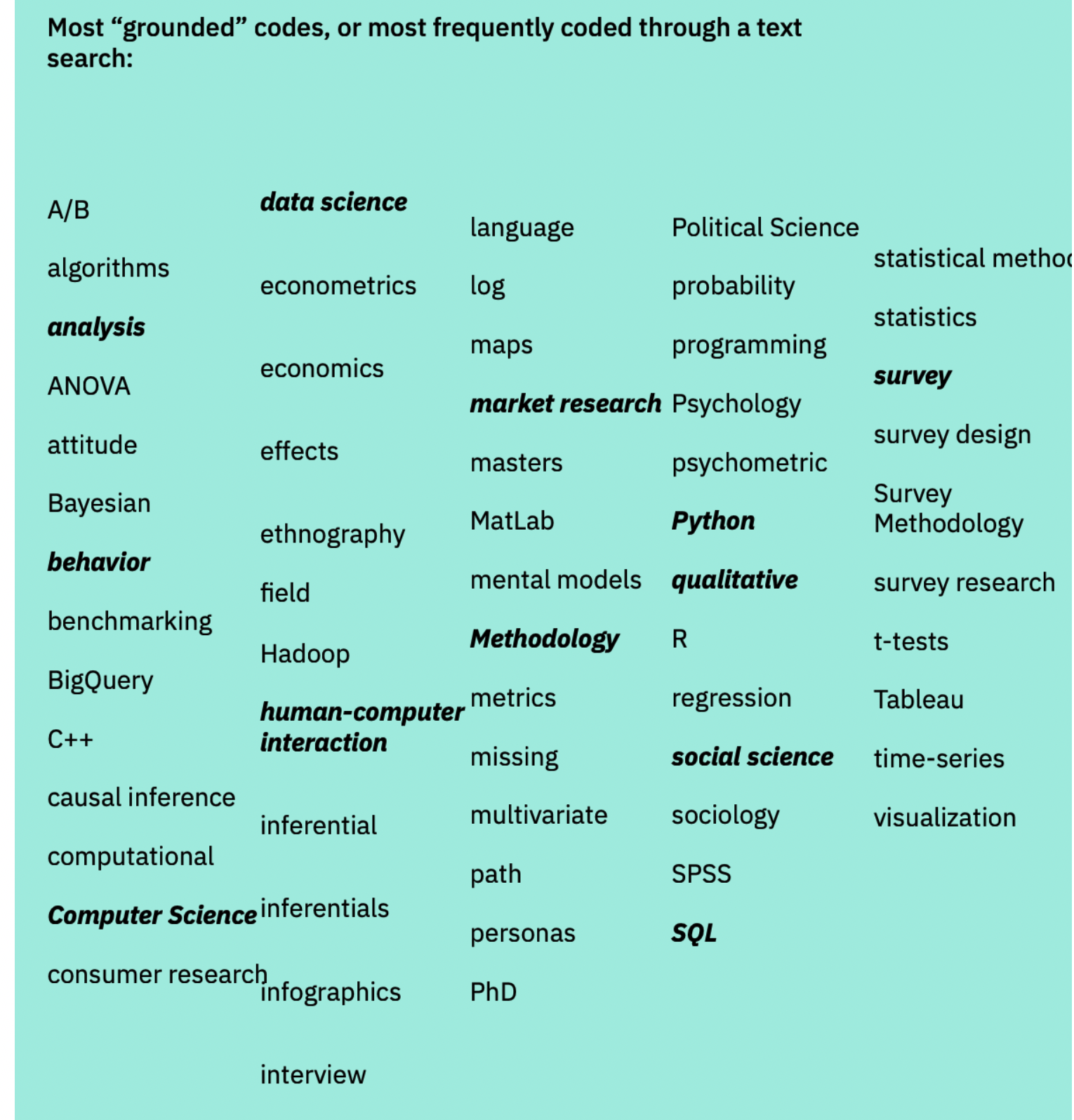
一方で、役割や必要なスキルに関する定義には、様々なバリエーションがあったことも指摘されていました。役割としては「ユーザ行動に関する分析を担う」と書かれている一方で、どのようにしてその役割を担うかという手段については言及していないものが多いようです。また、必要なスキルとしては、SQLやPythonのようなデータを扱える言語が書かれていることが多かったそうです。特にMetaやGoogleなどの大企業のQuantitative UX Researcherの定義は、他の企業と比較すると、"組織の意識やアプローチをユーザ行動に関するインサイトの創出に向けて変革することが求められるという点で異なっていた"と述べられていました。

2. Talks related to Data Science methods
2-1. User's log tell their stories:Applying NLP to understand how users interact with our product
By Adam Brown at Google
講演スライド: https://drive.google.com/file/d/1dP2xKmdvN5kp9YbBIQSsVgk0OKr3yV6o/view?usp=sharing
この発表では、サービスの主要なユーザ行動の系列として定義されるセッションに対して、Word2Vecを適用することでセッション全体の特徴を把握した事例について説明されていました。Word2Vecは、本来は文中の単語の前後関係に注目して単語をベクトルで表現する方法の1つです。この事例では、各ユーザ行動を単語とみなし、1つのセッションを一文とみなして手法を適用しています。具体的には、"load Homepage"などのアクション(=単語)からなるセッションログ(=文)に対して Word2Vecを適用し、各アクションについてのベクトル表現を獲得します。その後、アクションのベクトル表現を元にセッションを表すベクトルを作成し、セッションの集合に対してベクトル表現に基づくクラスタリングを適用します。この手法を適用することで、「全セッションが6パターンに分類され、例えば1つのパターンはホーム画面の閲覧を中心とするパターンで全体の36%を占める」と行ったセッション単位でのユーザ行動の把握が可能になります。


LINEでも、機能の利用におけるユーザ行動の分析は需要が高いのですが、行動が複雑多岐に渡るため全体像を理解するのが困難な場合が多々あります。仮に定性調査の手法でこの課題に取り組む場合は、何人ものユーザにインタビューをする必要があり、時間がかかってしまいます。一方で、この発表で取り上げられている定量分析の手法だけを使っても、ベクトル表現の精度やクラスタ数によって結果が左右されるので、正確性に少し懸念が残ります。個人的には、この発表で紹介された手法でカスタマージャーニーのたたき台を作成して、それに基づいた追加の定性調査を行うことで、全体像をより正確かつ深く理解できるのではないかと思いました。
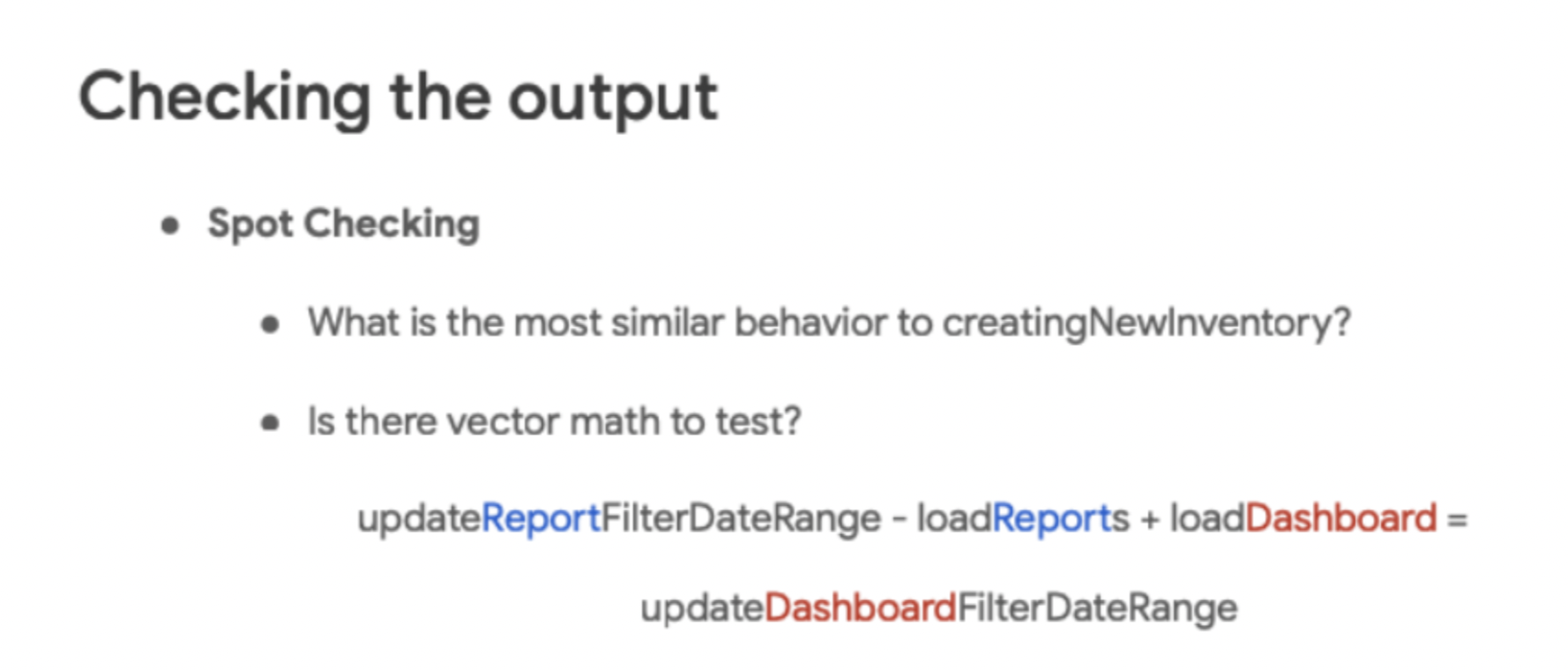
また、本題とはずれますが、Word2Vecには "king" - "man" + "woman" = "queen"のように、"king"という単語を表すベクトルに対して、他の単語("man", "woman")を表すベクトルの加算・減算を行うことで、異なる単語("queen")を表現できるという特徴があります。そのようなベクトルの加算・減算が、この分析事例におけるアクション間でも成り立っているかどうかを確認されていて、分析に対する質へのこだわりを感じました。
2-2. Representing the voice of Users at Scale:Text Analytics for Quant
by Ethel Zhang, Quant UXR at Google
講演スライド: https://drive.google.com/file/d/1YG0IX2UfAQbniw2ZdjGf7PVu9VGon_r_/view?usp=sharing
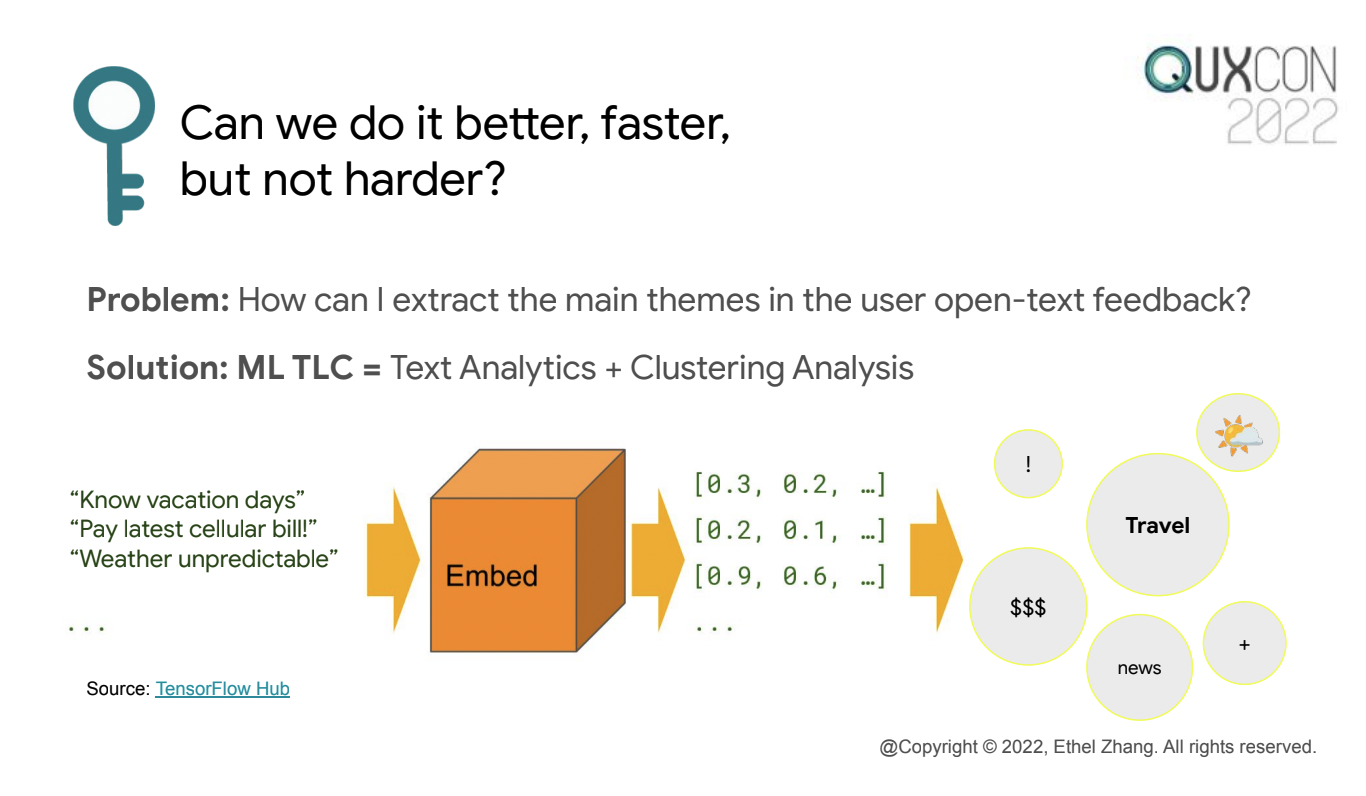
この発表では、ユーザのフィードバックからトピックを理解するために、フィードバック文中の単語からベクトル表現を獲得し、そのベクトルに基づいてフィードバックをクラスタリングした事例を簡潔に説明していました。この方法により、図のような "Weather unpredictable"や"Know vacation days"などの様々な自由回答のフィードバック文から、天気や旅行というトピックについて話されていることがわかり、全てのフィードバック件数に占める各トピックごとの割合を解釈するのに役立ちます。なお、1つ目の発表「User's log tell their stories:Applying NLP to understand how users interact with our product」と内容が類似しているように感じるかもしれませんが、1つ目ではセッションを文とみなしてベクトル表現を求めていたのに対して、この事例では標準的な自然言語処理のタスクとして手法を適用している点が異なります。私自身も、LINEの機能に関するアンケートを分析した際、アンケート項目の自由回答文に対してfastTextやtf-idfを使った重みづけを適用して回答内容の全体像の把握に利用したことがありました。似た手法で似た課題を解かれている事例が紹介されていたので、嬉しかったです。
2-3. Two UX Research Cases: Novel application of Conjoint Analysis
by Chris Chapman, Quant UXR at Google
講演スライド: https://drive.google.com/file/d/1bdkujMafIHALsB9thqeWDSI0qWFev2qP/view?usp=sharing
この発表では、「Mixed Methodsに関するUser Profilesの事例」と「Quantitative methodsに関するMarket Estimationの事例」の2つについて話されていました。講演の中で、2つの事例は下図のような定量・定性分析の軸に位置付けて説明されていました。
(*共有されているスライドには赤枠はないのですが、わかりやすく伝えるために赤枠をつけています。)

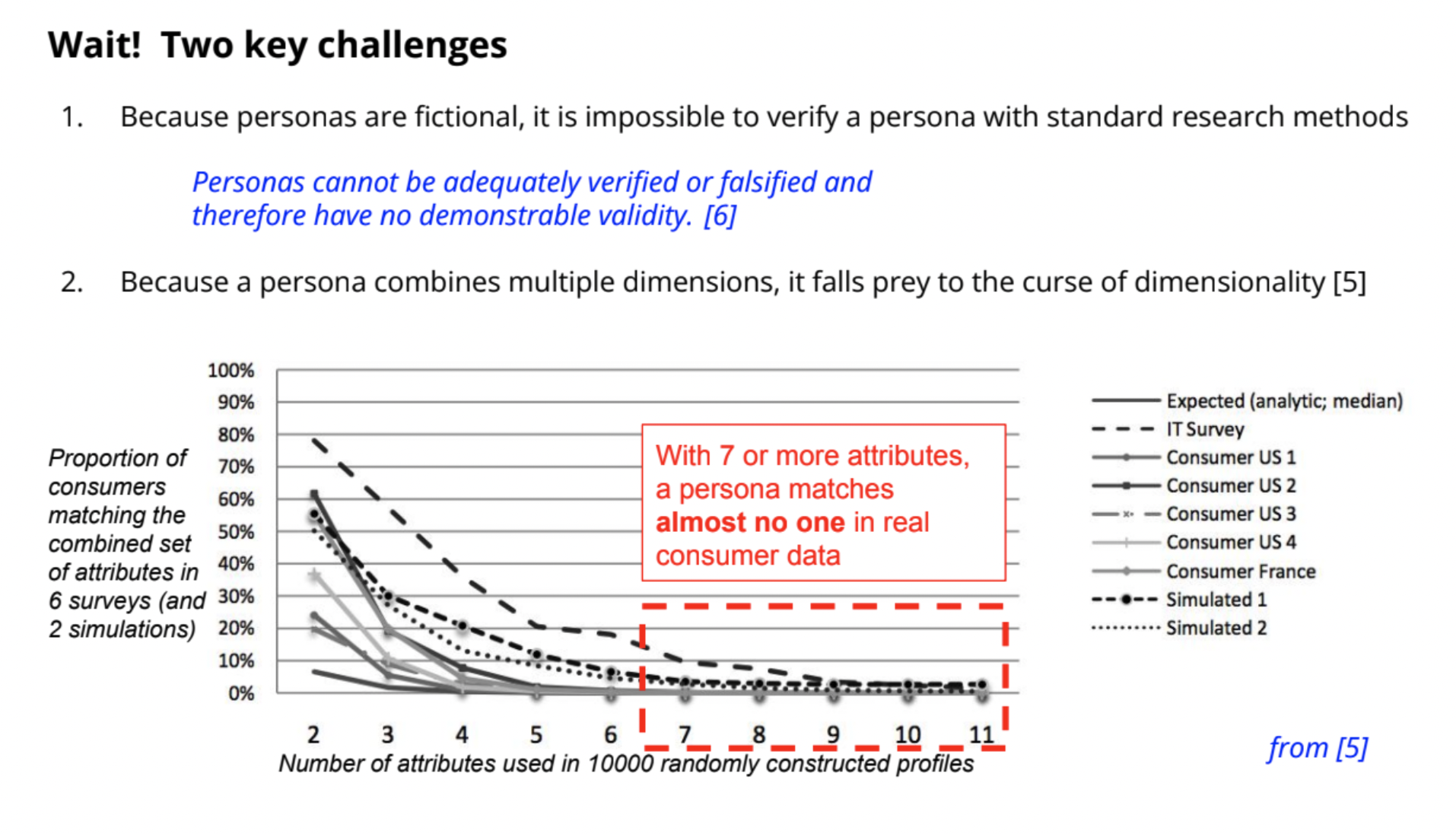
ここでは、発表の後半に紹介されていたMixed Methodsに関するUser Profilesの事例「Profile CBC: Using Choice Modeling to Find User Profiles」のみ紹介します。なお、この内容は今回が初出ではなく、2015年に発表済みの内容だそうです。当時Googleでは「アメリカの総選挙に関して、どのような情報がいつ必要とされているのか」に関する定性調査を実施し、ターゲットユーザに関する8つのペルソナを作成していました。ペルソナとは、ターゲットユーザの具体例についての仮想的な記述であり、プロダクトの改善において広く利用されています。ペルソナを設定する際、「各ペルソナに当てはまるユーザーが何人いるのか?」は、分析結果を利用する人にとっては重要な問題です。しかし、一般的な手法でペルソナの妥当性を検証することは不可能であることや、1つのペルソナを多くの変数で特徴付けた場合にペルソナにぴったり当てはまるユーザがほとんど存在しない状態(次元の呪い)が起こり得ます。
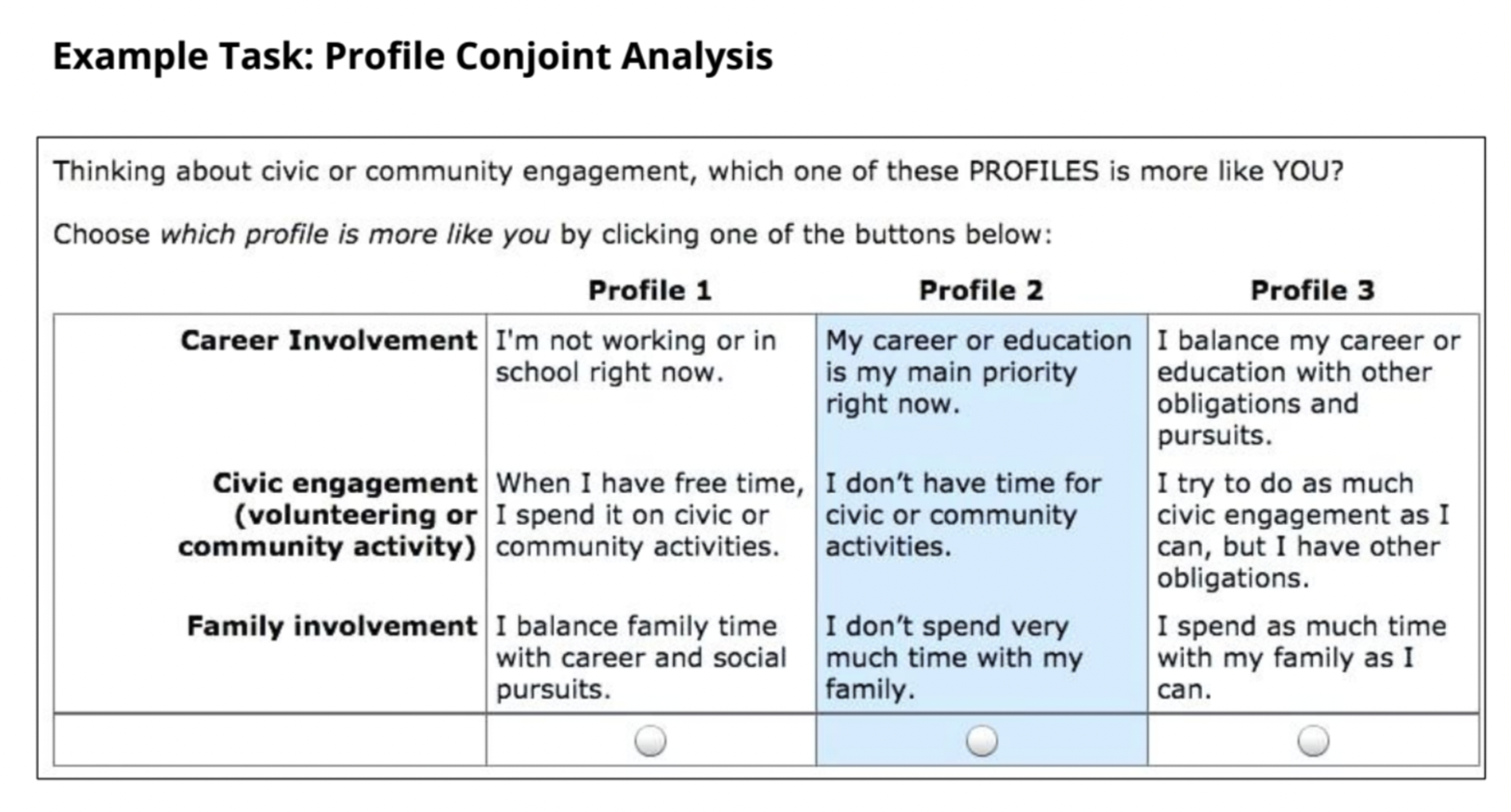
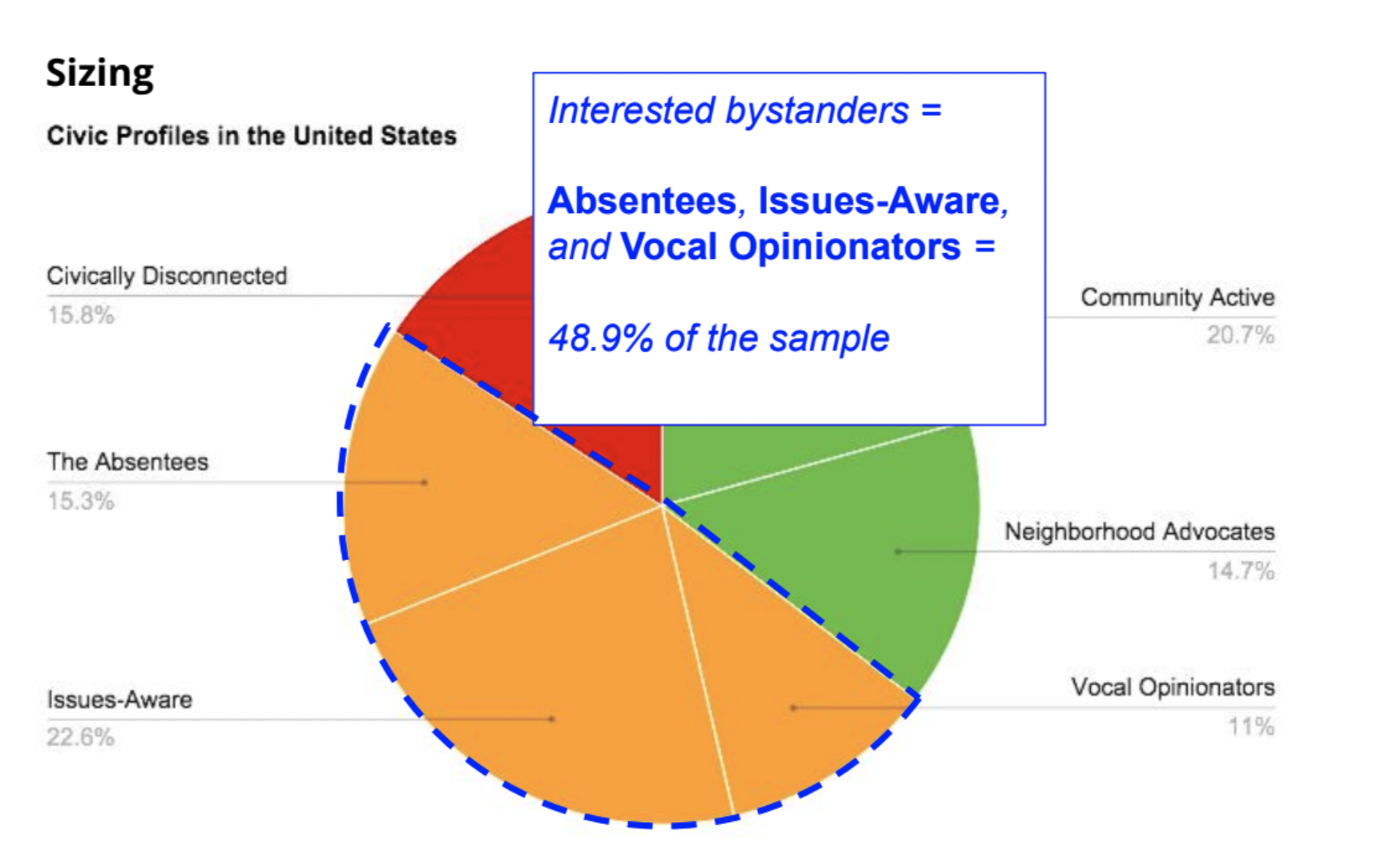
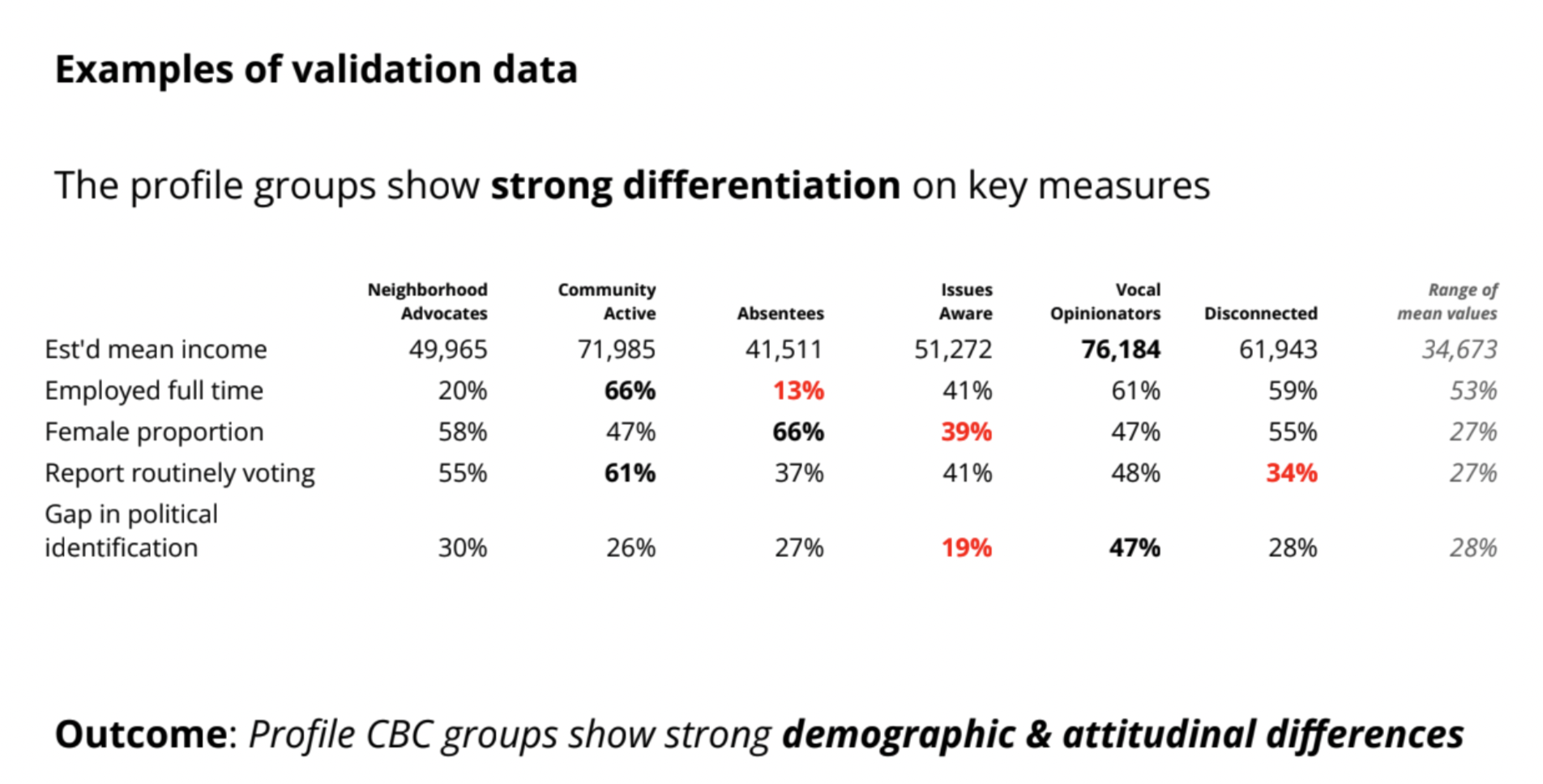
この発表では、次元の呪いを回避しながら、事前の定性調査で得た8つのペルソナを定量調査に活用し、その結果からペルソナを取捨選択しています。具体的には、Choice-based Conjoint(CBC) 分析のログ収集方法と潜在クラスモデルを利用することでペルソナを再作成し、1つ1つのペルソナに合致するユーザ数を推定しつつ、同時にペルソナを判別する上で重要な特徴を明確にしています。調査方法としては、ユーザに対して"8つのペルソナのうちランダムに選択された3つのペルソナ"を提示して、自分自身に最も近いペルソナを選択させています。さらに、このランダムなペルソナの提示と選択を12回繰り返すことで、各ペルソナを少なくとも3回はユーザに提示するような実験計画を組んでいます。このようなログ収集方法を利用することで、ユーザ自体が1つのペルソナのみに当てはまるのではなく、複数のペルソナに当てはまることを良しとし、適合度合いの高低も表現可能にしています。
分析結果では、潜在クラスモデルを適用してユーザを6つのペルソナ(以下の図にあるNeighborhood AdovocatesやCommunity Activeなど)に整理し直し、各ペルソナの規模感や特徴を確認していました。実務において、ペルソナ作成はよくあることだと思うのですが、Mixed Methodの観点で実験計画法やマーケティングリサーチ手法を応用することで、より深くユーザを理解することができる良い分析事例だなと思いました。
Closing Remarks
Quant UX Conは今回が初開催でしたが、盛り上がりや発表内容を見る限り、来年以降も実施されるのではないかと期待しています。特に巨大IT企業内で機械学習モデルやマーケティングリサーチ手法等を分析業務に応用している実例を知れる機会はとても貴重で、今後の業務に活かせる発表も多かったと思いました。なお、私の所属するData ScienceセンターでもMixed Methodsや機械学習モデルを使った分析事例が多々あるので、次回開催があれば登壇者として参加可能なのではないかという希望も見えました。
個人的には、統計モデルや機械学習モデルを使った定量分析もUX Researchなどの定性分析も分析における一手段であり、ユーザについての深い理解が得られるのであれば、手法の種類に限らず適宜利用していくのが望ましいと考えています。今後、Quantitative UX Researcherという職種がどのように発展していくのかはまだまだ分かりませんが、引き続き多くの知見を精度高く得られる分析を行うために、多様な分析手法やその実例に対してアンテナを張っていきたいです。
LINEでは、データサイエンティストとUXリサーチャーを募集しています。リサーチによってサービス改善を行うことに興味がある方は、ご応募お待ちしております。