
はじめに
こんにちは!2023年夏に就業型インターンに参加しました、東京大学大学院情報理工研究科コンピュータ科学修士1年生の賀恩沢です。今回は、CSI SRE (DevC) チームに配属され、Site Reliability Engineer(SRE)としてPyroscopeのスケールアウトを可能にするブローカーを開発しましたので、取り込んだ内容についてを紹介したいと思います。
背景
CSIとは、Communication & Service Integrationの略称であり、LINEスタンプ、着せかえ、ウォレットタブやホームタブなどのコンテンツやサービスの信頼性制御のためのエンジニアリングに取り組んでいます。
私たちは、1,000以上のサーバーを管理しており、現在は信頼性をさらに向上させるためにサービスのKubernetes移行をしています。
従来の仮想マシンと違って、アプリケーションで何か異常が発生した際、直ちにKurbenetesはそのアプリケーションを停止し、自動的に再デプロイします。壊れたアプリケーションとその関連するPodはすべて削除されるため、異常となる原因の究明は難しくなります。
この問題を解決するために、CSI SREチームはPyroscopeというContinuous Profilingツールを導入して、プロファイラーを常に実行し続け、壊れたPodが削除されても壊れた時点のプロファイリングデータを確認できるようにしたいと考えています。
しかし、Pyroscope v0.36の時点で、プロファイリングデータはすべてローカルストレージに保存されるため、Pyroscopeのスケールアウトは難しいという問題点があります。なぜなら、プロファイリングデータをいくつかのPyroscopeサーバーで共有することは難しく、Pyroscopeをアップデートしたり、再デプロイしたりしたとき、ローカルストレージに保存されたプロファイリングデータが削除されてしまうためです。
これらのPyroscopeのスケーラビリティとデータロス問題を解決するために、Pyroscope Brokerの開発を行いました。
ブローカー(Broker)とは
ブローカーは、データや処理要求、応答などのメッセージを伝達・交換する際に、やり取りの仲介役として用いられるソフトウェアのことです。
Pyroscope BrokerというブローカーをPyroscope agentとPyroscope serverの間に置くことで、Pyroscope agentから送ったプロライリングデータはブローカーを介して保存できます。そのデータが保存され次第、Pyroscope serverに転送します。
Pyroscope Brokerの仕組みは以下のようになっています。
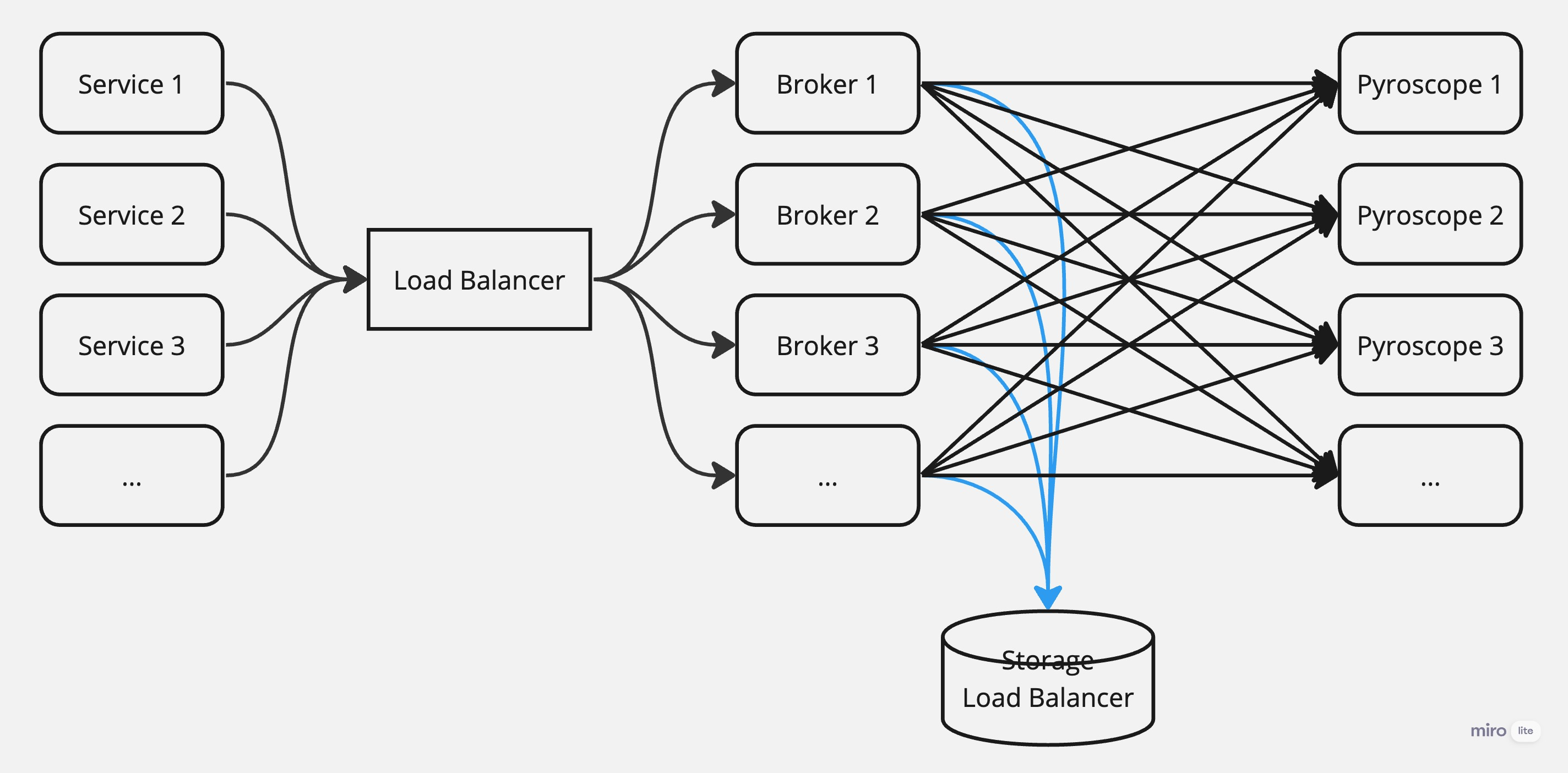
ご覧の通り、一つのPyroscope Brokerあたり複数のPyroscope serverに転送することを設定可能なので、データが同期されたPyroscope serverを複数持つことができます。
さらに、Pyroscope Broker自体は分散設計によって、スケールアウトが可能です。
Pyroscope Brokerのスケールアウトと宛先の設定によって、Pyroscopeのスケールアウト問題は解決しました。
Pyroscopeプロトコルの解析
Pyroscope Brokerを開発するには、まずはPyroscopeを使っているプロトコルを解析する必要がありました。
PyroscopeのContinuous Profilingは、以下のような仕組みで構成されています。
- Pyroscope agent を各サービスに組み込み、そのサービスのプロファイリングデータを継続的に収集します。
- Pyroscope agentは収集したデータをPyroscope serverの
/ingestに対してリクエストします。- リクエストヘッダーは主にサービスの名前、タイムスタンプとプロファイリングデータのフォーマットなどを含まれています。
- リクエストボディーはプロファイリングデータのフォーマットによって違いますが、転送するにはフォーマットが分からなくても普通にできますので、そのままでボディーを転送すれば良いでしょう。
リクエストヘッダー (https://pyroscope.io/docs/server-api-reference/#ingestion):
|
フィールド
|
意味
|
|---|---|
name |
サービスの名前 |
from |
プロファイリングの開始時間 |
until |
プロファイリングの終了時間 |
format |
プロファイリングデータのフォーマット |
sampleRate |
サンプルレート |
spyName |
使っているスパイの名前 |
units |
プロファイリング単位の名前 |
aggregrationType |
プロファイルをマージするための集計のタイプ |
以上で、Pyroscopeプロトコルの解析は完了となります。
ブローカーの実装
機能と仕組み
Pyroscope Brokerには主に”転送 (Forward)”と”リプレイ (Replay)”という二つの機能が実装されています。
転送機能は、Pyroscope agentからデータを受け取り、MongoDBに保存して、そのデータをPyroscope serverに送るという機能です。
リプレイ機能は、ブローカーが収集されたすべてのデータを新しいPyroscope serverに送って、そのPyroscope serverのプロファイリングデータの記録を再構築するという機能です。
具体的には以下の画像より示されています。
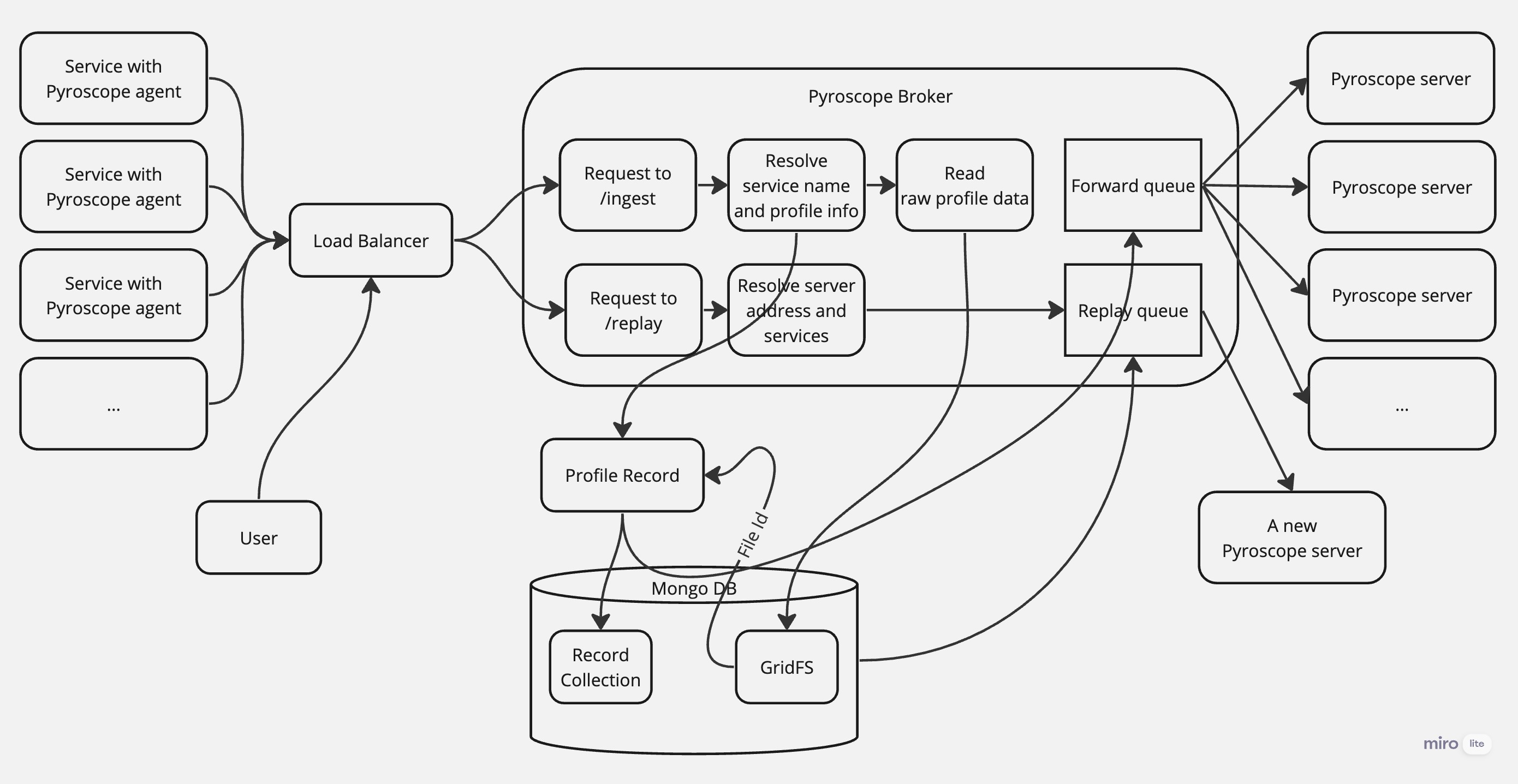
転送機能について
各Pyroscope agentは収集したデータをPyroscope Brokerの /ingest に送ります。
Pyroscope Brokerはリクエストを受け次第、そのリクエストからプロファイリングデータの情報とボディーを抽出し、まずボディーのほうを GridFS に保存します。この際、File Idを取得できます。
そして、File Id と抽出されたプロファイリングデータの情報をまとめてデータベースに保存します。
データが保存できたら、転送キューに入れて、Pyroscope server に送ります。
リプレイ機能について
新しいPyroscope serverが設置された場合、そのPyroscope serverのアドレスとリプレイしたいサービスの名前をPyroscope Brokerの /replay にリクエストするだけで、Pyroscope Brokerはデータベースに保存されたデータを指定されたPyroscope server宛に送ります。
Pyroscope Brokerはリプレイリクエストを受けたら、バックグラウンドであるリプレイキューにリプレイタスクを追加し、順番に処理します。
信頼性ためのGraceful Shutdown
Podが解放される直前、Kubenetesはアプリケーションに SIGTERM というシグナルを送ります。SIGTERM は終了要求のシグナルで、プロセスはこれを受け取った後も動作することができます。
アプリケーションは SIGTERM を受け取ったら、Kubenetesから与えられた秒数(デフォルト30秒)以内に安全に終了します。このことをGraceful shutdownと呼びます。
Pyroscope Brokerは信頼性のためにGraceful shutdownを行います。これにより、データは終了する前に安全的に保存できます。
Pyroscope Brokerが SIGTERM を受け取ったら、以下のことを行います:
- すぐに新しいリクエストの受付をやめて、キューに新しいタスクが追加されないようにします。
- まだ保存されていないプロファイルレコードをデータベースにまとめて保存します。
- 現在進行中のタスクをすぐに停止して、データベースに中断されたことをマークします。
- キューにあるすべてのタスクを取り出して、それぞれに中断されたことをデータベースにマークします。
これによって、新しい Pod が作成された後に中断されたタスクを再開できるようになります。
Shutdownにより中止されたタスクの復元
新しいPyroscope Brokerが起動されたら、まずは中止されたタスクを復元しないといけません。そのため、まずデータベースで中断されたタスクを探して、再びタスクキューに追加します。
この処理の際に、1つの中断されたタスクが複数のPyroscope Brokerのキューに追加されないようにする必要があります。
これを実現するために、各中断されたタスクに対して以下のような処理を行い、ロックを取ります。
- データベースの
handlesクレクションをクエリして、TaskIdが現在処理してるタスクのIdと等しいレコードがあるかどうかを確認します。- なければ、
TaskIdをhandleとしてhandlesクレクションに追加し、現在のタスクの状態を保留中に更新します。そして、タスクをキューに追加したあと、handlesから先ほど追加したレコードを削除します。 - あれば何もしません。
- なければ、
重要:上記の「クエリと追加」のプロセスはAtomicな処理である必要があります。つまり、 upsert を使わないといけません。
これにより、handle を持っている間、他のPyroscope Brokerはこの handle に含まれているタスクを処理できません。つまり、どのタスクも一つのPyroscope Brokerにしか取り出されないようになります。
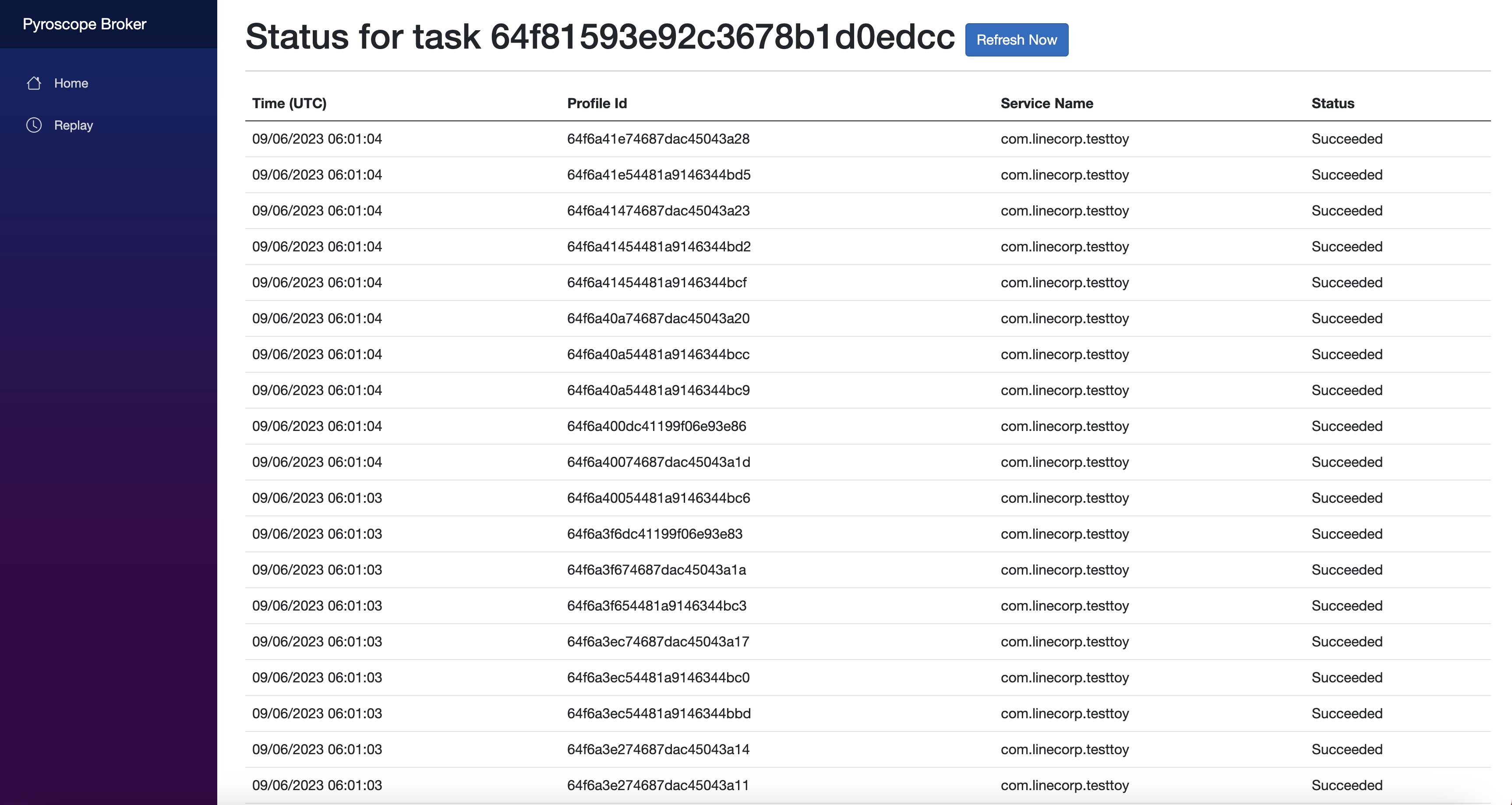
実際運用
以下はPyroscope BrokerのWebUIです。
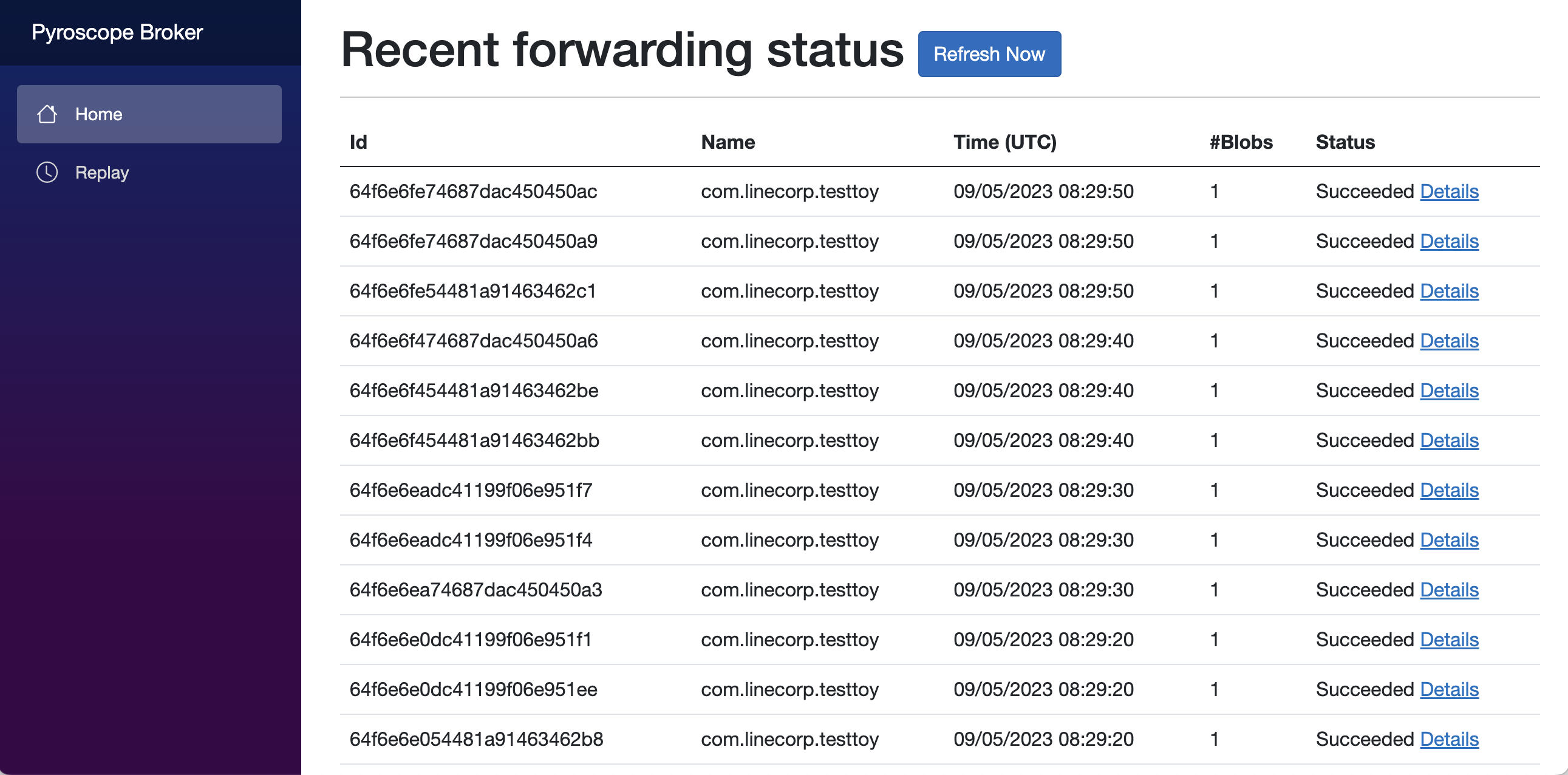
ご覧の通り、直近に転送したプロファイリングデータの情報とステータスを確認できます。
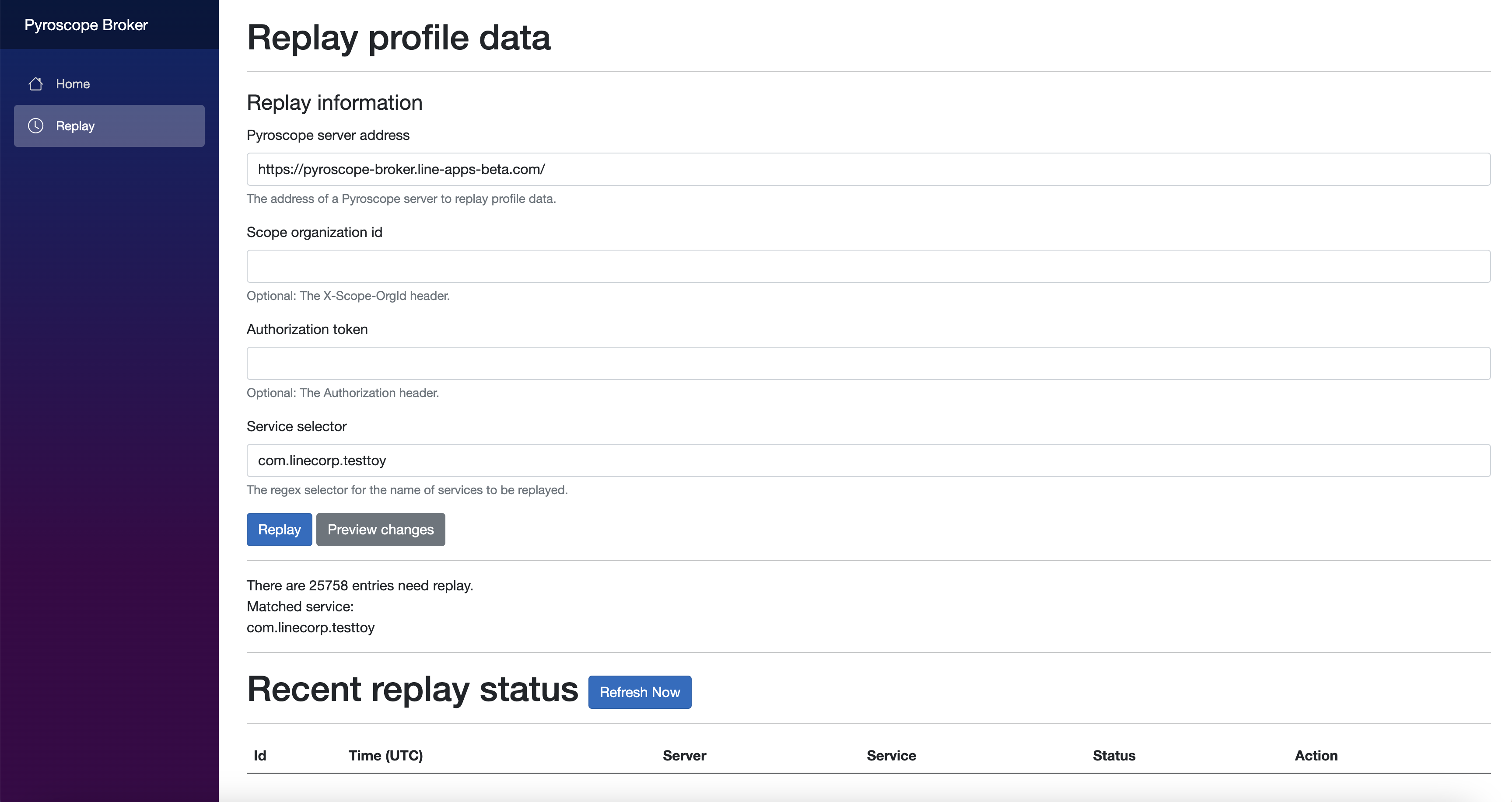
リプレイを開始する際には、Pyroscope serverのアドレスとサービス選択のためのセレクターを入力して、「Replay」をクリックしたら、リプレイプロセスはバックグラウンドで自動的に実行されます。
リプレイを開始したら、WebUIでステータスをチェックすることもできます。
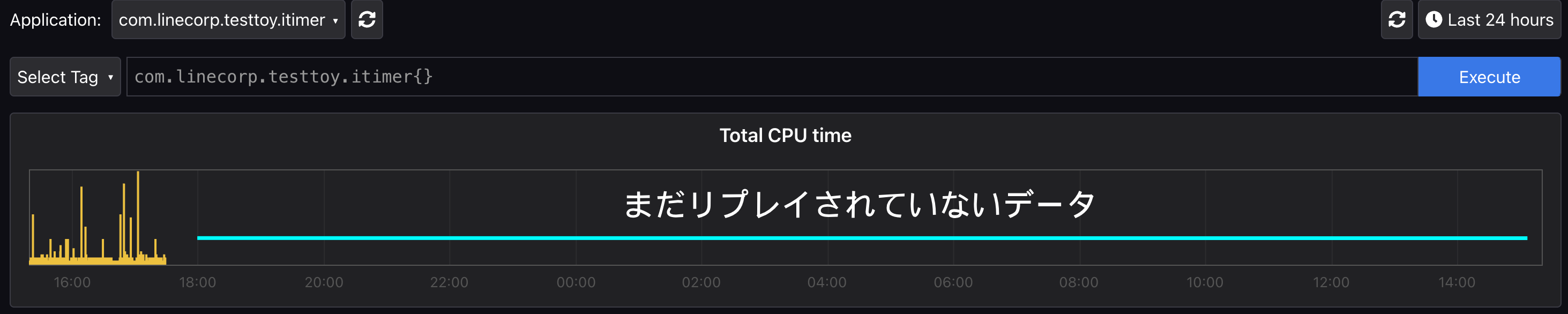
Pyroscope serverのWebUI上でもまだリプレイされていない部分を確認できます:
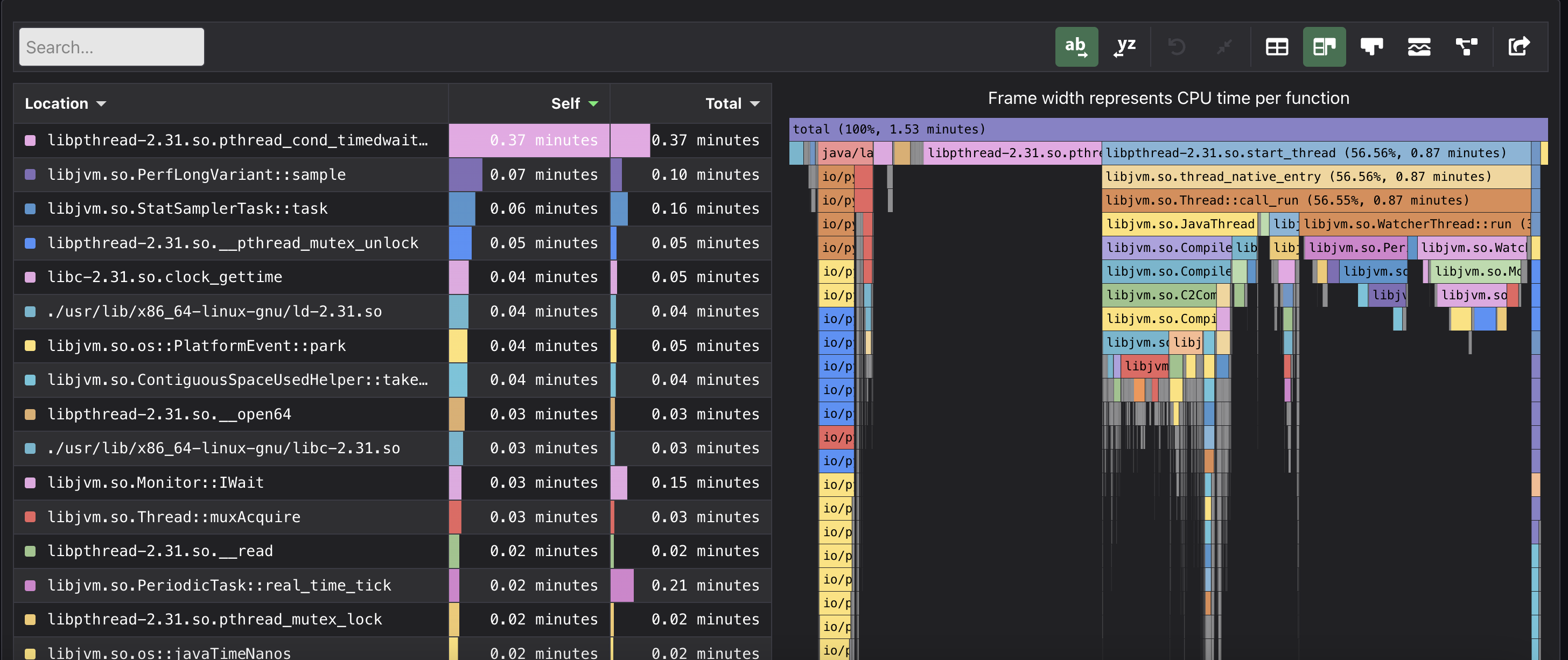
しばらく経つと、すべてのプロファイリングデータはどんどんリプレイされ、Pyroscope serverでも確認できます。

他の解決策候補
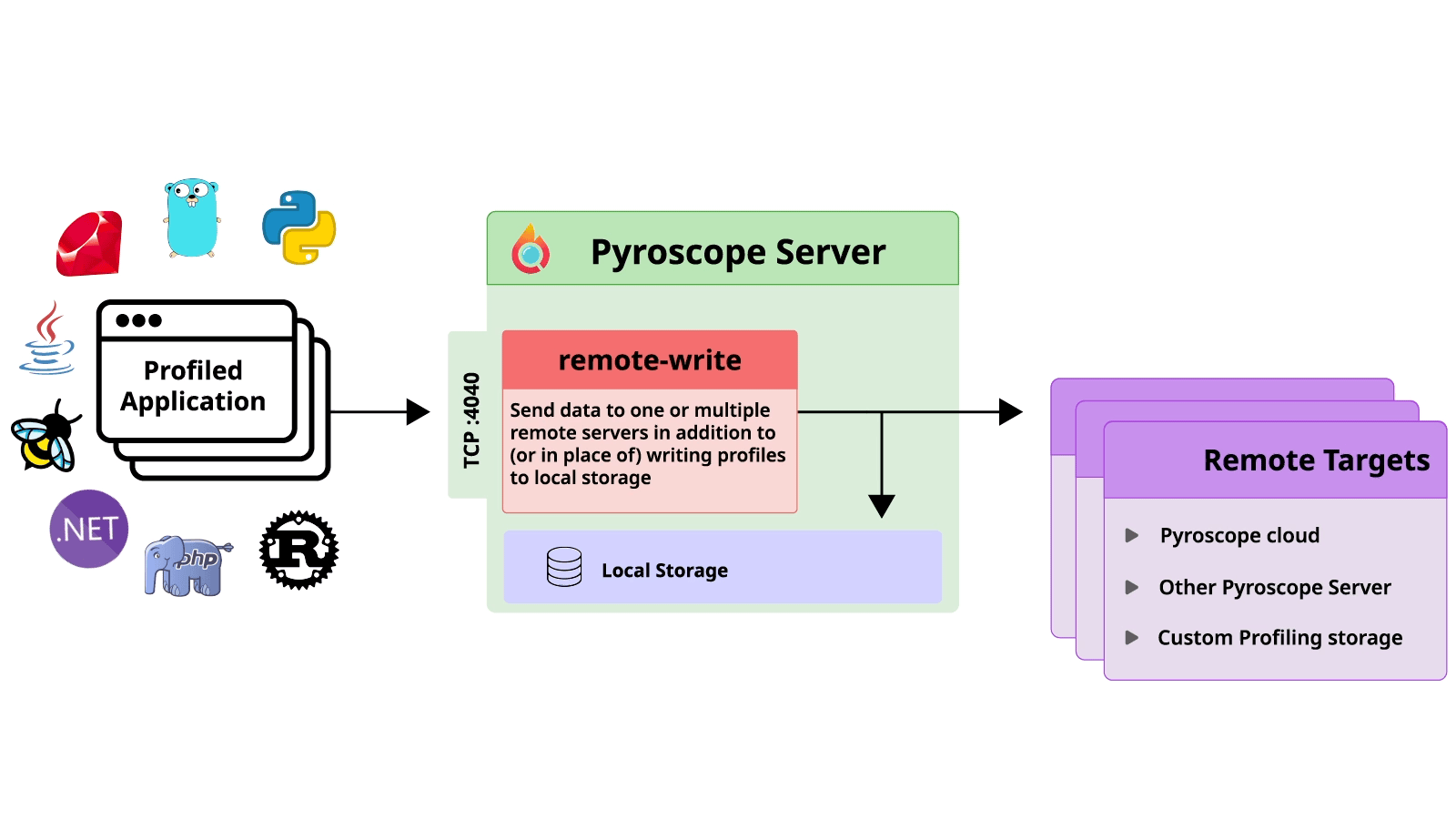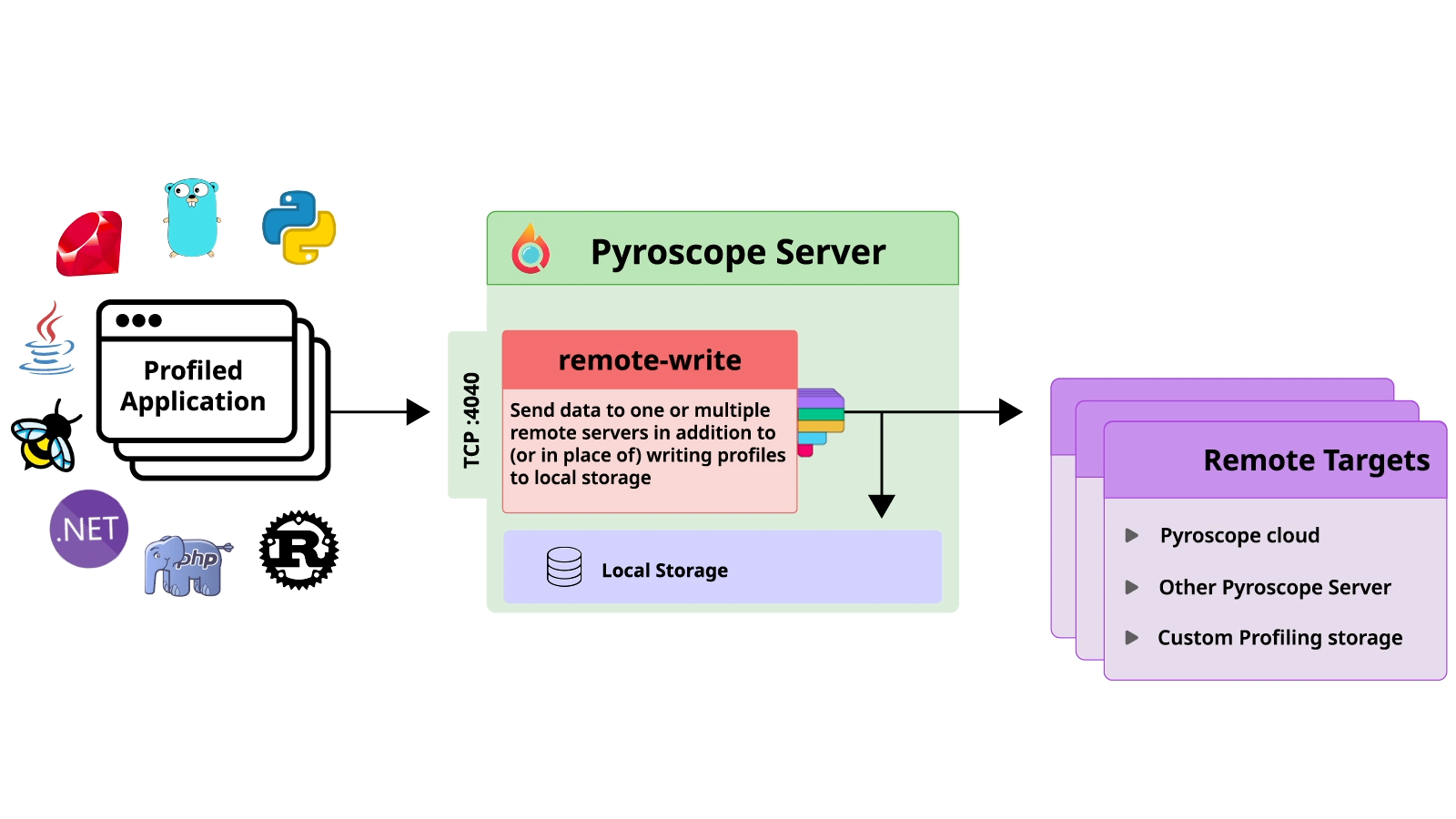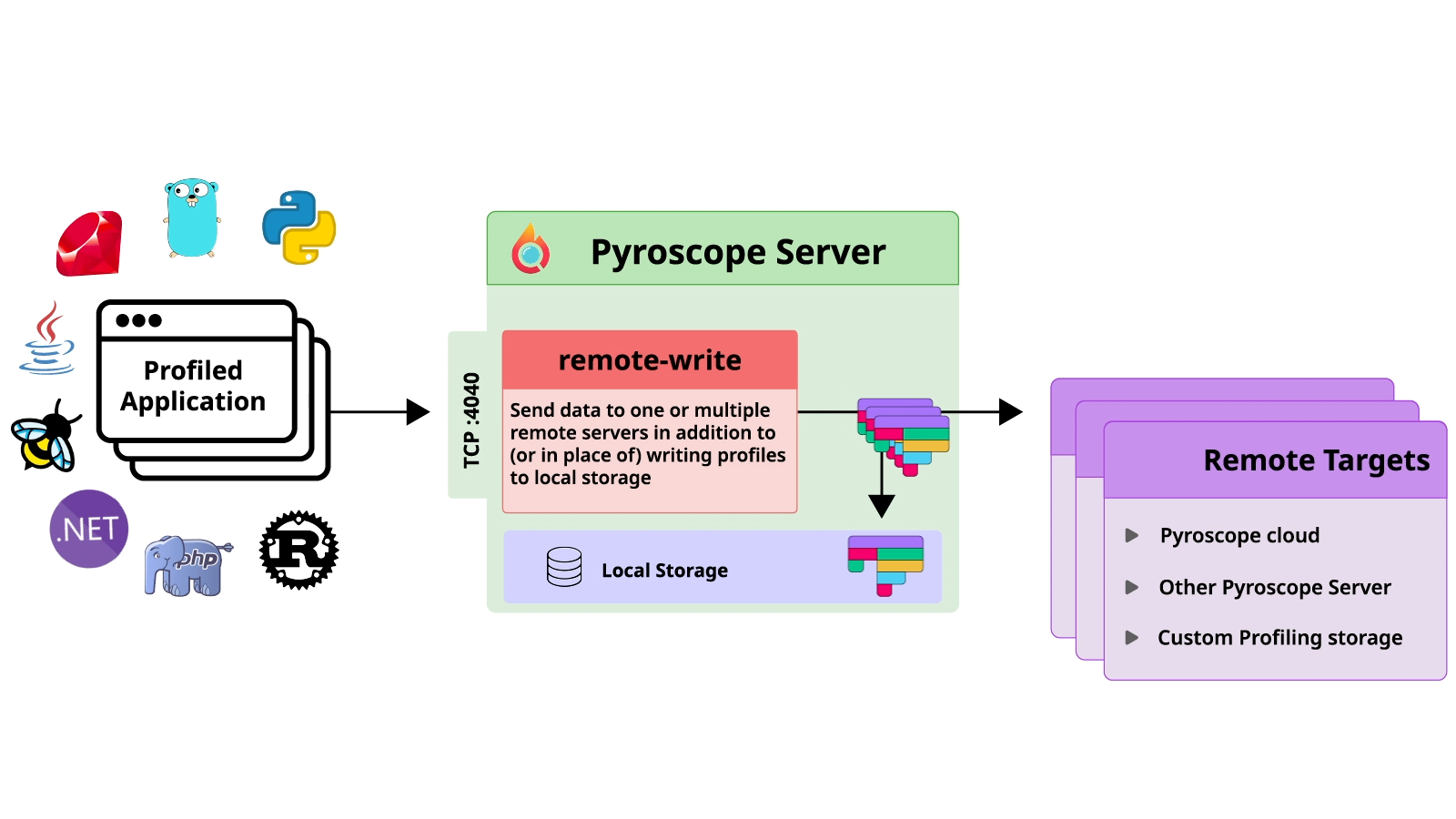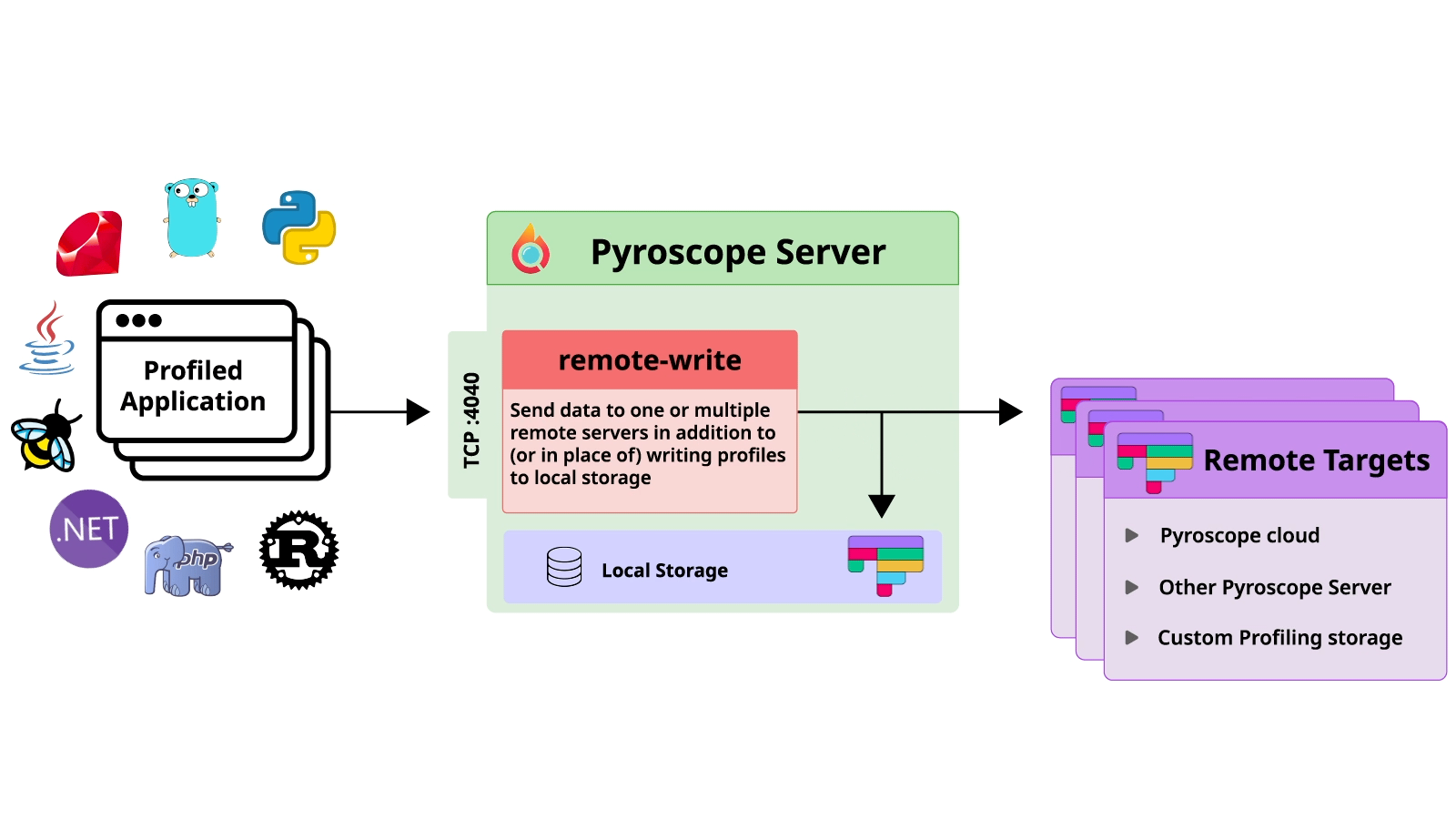
実は、Pyroscopeは「Remote Write」という機能があって、以下の画像の通り、この機能を使えばプロファイリングデータを指定されたところに書き込むことができます。
つまり、Pyroscope を適当に設定したら、別にPyroscope Brokerがなくてもプロファイリングデータは他のPyroscope serverなどに保存できます。
では、なぜ「Remote Write」という機能を使わなかったのでしょうか?
その一つの理由として、「Remote Write」はプロファイリングデータのデリバリー保証はないということです。
つまり、何かの原因で、例えばネットワーク関連する障害などでプロファイリングデータが届かなかったとしても、「Remote Write」は再試行をしないという問題があります。
さらに「Remote Write」機能を使っても、ロードバランサーによって、スケールアウトされたそれぞれのPyroscope serverは一部のプロファイリングデータしか受けられないので、すべてのプロファイリングデータの保存はできないということです。
Pyroscope v1.0 と展望
このインターンシップの期間中である2023/8/30(水)に、Pyroscope は新しいv1.0バージョンをリリースしました (https://github.com/grafana/pyroscope/releases/tag/v1.0.0)。
このバージョンでは、以下のような改善が行われました。
- スケーラビリティ:Pyroscope v1.0では、memberlistプロトコルを用いたハッシュリングのサポートが開始されました。ハッシュリングとは、分散一貫性ハッシュ法と呼ばれる分散システムで用いられるシャーディングやレプリケーションのための仕組みです。これにより、Pyroscopeは水平方向にスケールアウトすることが可能になりました。
- データロス:Pyroscope v1.0では、オブジェクトストレージサービスとの統合サポートが導入されました。これにより、プロファイリングデータをAWS S3やS3互換のストレージサービスに保存することができます。
つまり、Pyroscope v1.0までバージョンアップすれば、今回の課題であったスケーラビリティとデータロスの問題は解決し、Pyroscope Brokerを使わなくて済むようになります。
Pyroscope Broker自体はほかのサービスとPyroscope serverに対して透過的に振る舞うサービスであるため、Pyroscope v1.0までバージョンアップしたら、既に配置されたPyroscope Brokerは削除することができます。
おわりに
Pyroscope Brokerを開発することで、Pyroscopeのスケールアウトを可能にしました。Pyroscope Brokerを使えば、プロファイリングデータはブローカーを経由して保存され、適切なPyroscope serverに送られるようになります。
これはあくまでPyroscope v1.0以前の解決策ですが、すべての既存のPyroscopeインスタンスをv1.0にアップデートし、設定や評価や移行を完了したら、またPyroscope Brokerを削除し、Pyroscope agentの設定を直接サーバーに送るように変更することもよいでしょう。
本インターンでは、スケールアウト問題を解決するためのサービスをゼロからデザイン、実装と運用するとともに、Kubernetesに対する理解を深めることができ、スケールアウトやプロファイリングの重要性も改めて認識しました。また、レポート、成果のプレゼン方法や、Wikiの書き方など、技術面以外での学びもあり、短い6週間ですが、大きな知識と経験を得られました。
最後になりますが、メンターの北村さんとSREチームの加藤さん、石島さんとマネージャーのヤッシュさんには、この短い間で未熟な私を色々サポートしていただき、大変お世話になりました。
ありがとうございました。