
LINE株式会社OA SREチームのhasebeです。
先日、私の担当するプロダクトにてPyroscopeというツールを導入しました。このブログではなぜPyroscopeを導入したのか、導入した結果どういった利点があったのかなどについてご紹介したいと思います。
Pyroscopeとは
Pyroscopeとは、Continuous Profilingを実施することができるOSSのツールです。
Profilingについては特に説明は不要でしょう。ざっくりいうと、CPUやメモリ等のリソースをプログラム中のどこが多く消費しているのか(= ボトルネック)を突き止める手法のことを意味します。
一般的には、なにか問題が起きたときに手動でProfilingツールをかけることが多いです。
Continuous Profilingとは、その名の通り継続的に常にProfilingをかけておく手法のことです。詳しくは以下のCNCFのブログをご覧ください。
https://www.cncf.io/blog/2022/05/31/what-is-continuous-profiling/
どういったメリットがあるのか
大規模/複雑なシステムでは意図せぬタイミングで問題が発生することがあります。再現性がある問題ならば、Profilingツールをかけた状態で問題を再現させることでProfilingの結果を得ることができます。しかし、中には再現手順が不明な問題があります。こういった場合だと調査が非常に難航してしまいます。
Continuous Profilingのように常にProfilingをかけておくことで、そういった難しさを解消することができます。
Pyroscopeの仕組み
言語ごとにPyroscope Agentと呼ばれるものがあります。このAgentが定期的にProfilingを実行し、その結果をPyroscope Serverに送信します。
我々開発者は、Profling結果をWEB UIからフレームグラフとして閲覧することができます。
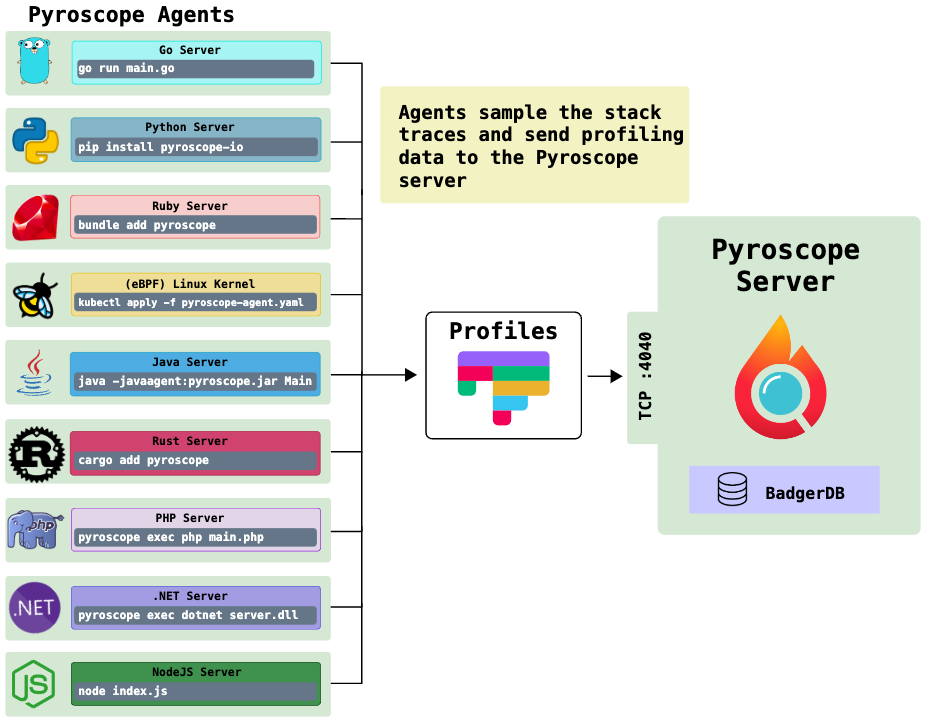
(引用: https://pyroscope.io/docs/)
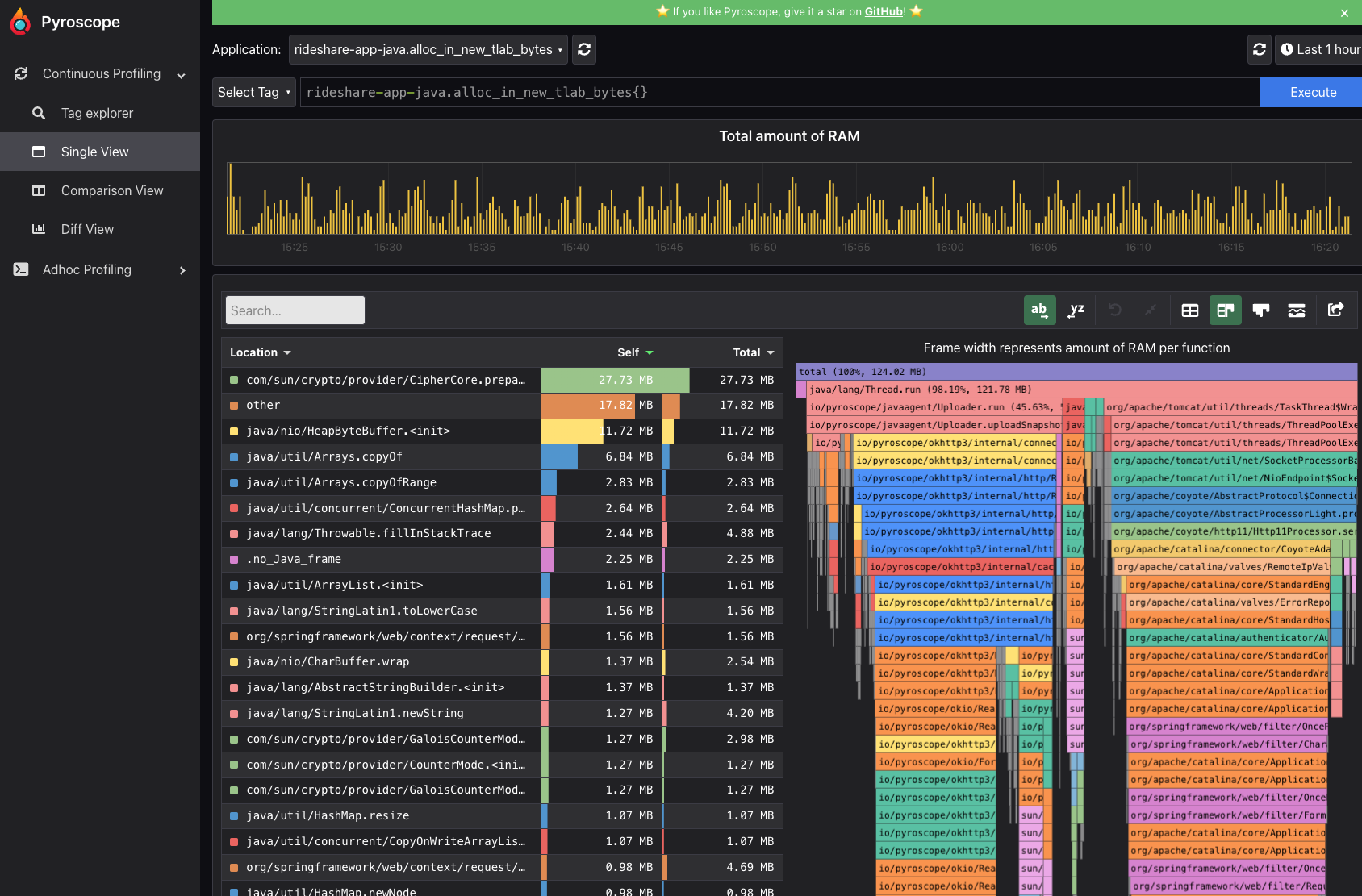
WEB UIについてはDEMOから挙動を確認することができます。ぜひ触ってみてください。
Pyroscope Agentについては各言語によって当然実装が違います。
我々が使用しているpyroscope-javaにおいては、async-profiler をもとにした実装になっています。async-profilerはJVMにおいては良く使われるツール(Proflingにおけるオーバーヘッドも低い)で、我々も普段から使っているため、使用にあたってとくに懸念はありませんでした。
Pyroscope Serverの動かし方
いくつか方法があります。
- サーバー上で通常通りにProcessとして動かす方法
- サーバー上でDocker経由で動かす方法
- K8s上で動かす方法
我々の環境ではK8s上で動かしています。詳しい方法については、公式のdocumentをご覧ください。
https://pyroscope.io/docs/kubernetes-helm-chart/
設定に関しては、ほぼほぼデフォルトでのままで、データの保持期限(retention と exemplars-retention)を2週間にしています。
disk使用量はとても少なく済んでいます。Profilingをするアプリケーションの数やデータの保持期限に応じて変わってきますが、我々の環境では100GBほどで収まっています。以下の記事を見ると、とても工夫した設計をしていることがわかります。
https://pyroscope.io/docs/storage-design/
また、デフォルトだとflamegraph.comへのエクスポート機能が有効化されています。コードに関連する情報が社外にでることがないように、この機能は無効化して使用しています。(disable-export-to-flamegraph-dot-comを設定すると無効化できます)
これに関してはGithubのIssueにて要望を出したら、すぐに対応してくれました。
https://github.com/pyroscope-io/pyroscope/issues/1186
Pyroscope Agentの動かし方
java(kotlin)アプリケーションの場合、起動時のオプションにjavaagentとして追加するだけです。pyroscope.jarはここからダウンロードできます。
java -javaagent:pyroscope.jar -jar app.jar他にも、mainメソッド内にでPyroscopeAgent.start(...)を呼び出すことで起動することもできます。
Pyroscopeを活用したトラブルシューティング事例
先日、Pyroscopeを上手く活用することで解決できた問題があったので紹介します。
問題
gRPCサーバーのAPI Latencyが全てのエンドポイントで突然悪化するという問題が発生しました。(結果、呼び出し側ではtimeout errorとなる)
各種メトリクス等を眺めると、以下のような傾向がありました。
- 問題が発生するのは数秒から数十秒ほどの短い間
- 1日に数回ほど発生する
- 問題発生時に、問題が起きるサーバーからのMySQL, Redis, 他API呼び出し等のLatencyは悪化していない
- 問題発生時に、CPU利用率が20%から30%ほどには上がっている (が、大した増加ではない)
- GC等が悪化しているわけではない
今までにはあまりないタイプの問題で、頭を悩ませました。
Pyroscopeの導入
CPU利用率が若干上がっているのが気になったため、async-profilerを使ったCPU Proflingを行いたいところでしたが再現方法が不明でした。また、問題が不定期に発生するため、狙ってCPU Profilingを行うことができませんでした。
そこでPyroscopeを導入することにしました。
結果、問題が発生したときに無事にCPU Proflingの結果を取得することに成功しました。
CPU Profilingの結果
以下が得られた結果のフレームグラフです。
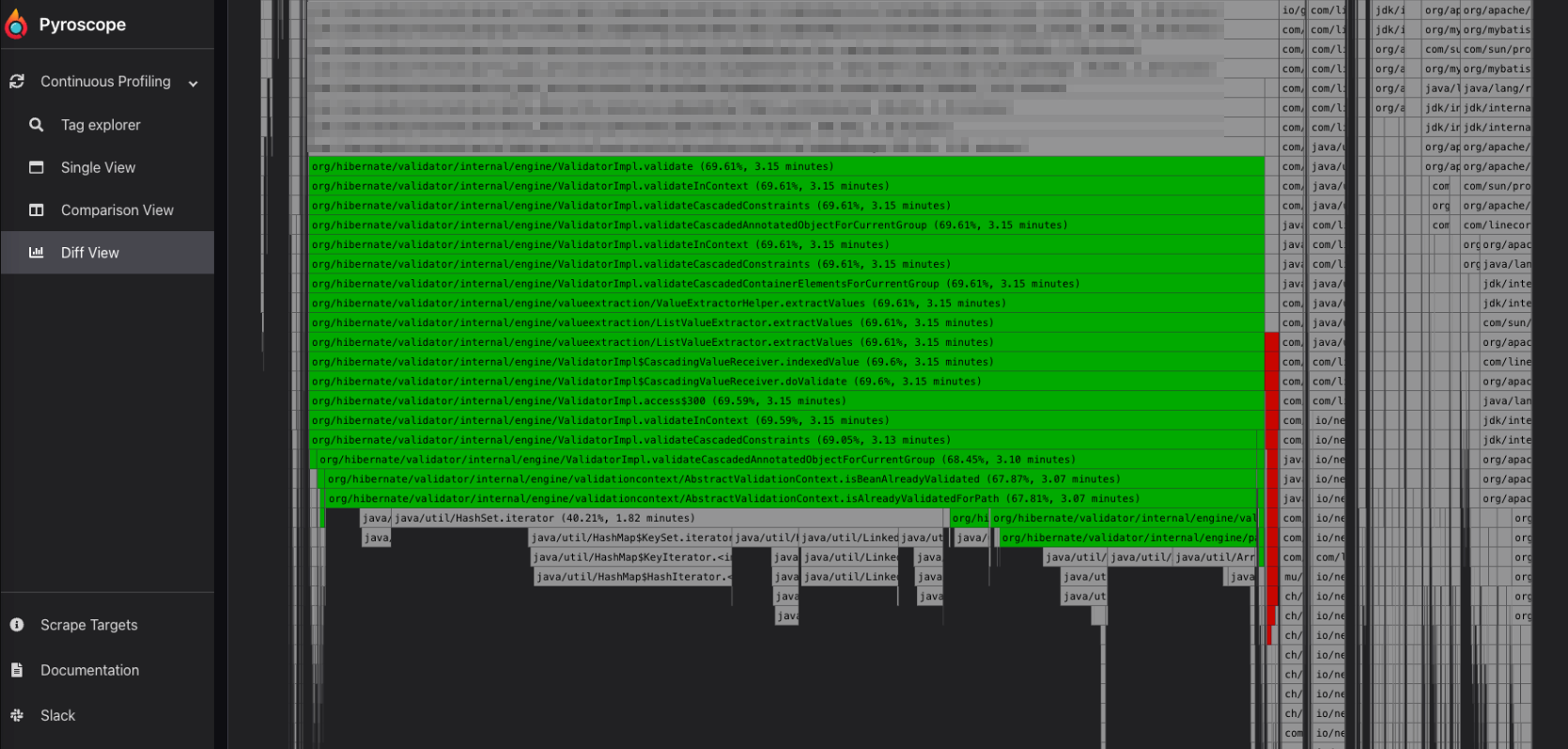
フレームグラフを眺めると、どうやらgRPC Service内で実行している Hibernate Validator で多くのCPUを消費しているようです。何かしらの理由(後述)で、該当箇所で長時間のバリデーションを実行しているようにみえます。
我々はgRPC-Kotlinを使っており、Kotlin CoroutinesのDispatchers.Default上にて該当コードは動作しています。Dispatchers.Defaultはいわゆるevent loopな処理を実行するためのものなので、1つの処理のためにスレッドを長時間専有してはいけません。
そういった処理があると、後続の処理が詰まってしまい、パフォーマンスに大きな影響を及ぼしてしまうことが知られています。
我々のアプリケーションもこの問題によって、Latencyが悪化していたようです。
なぜHibernate Validatorで問題となっていたのか
我々がバリデーションをしているオブジェクトは以下(単純化した例ではあるが)のようにListを保持するものでした。このListのサイズがある一定数をこえたとき、Hibernate Validatorの処理時間が急に増加していくという傾向が見られました。
// 単純化した例
data class OuterPojo(
val list: List<InnerPojo>
)
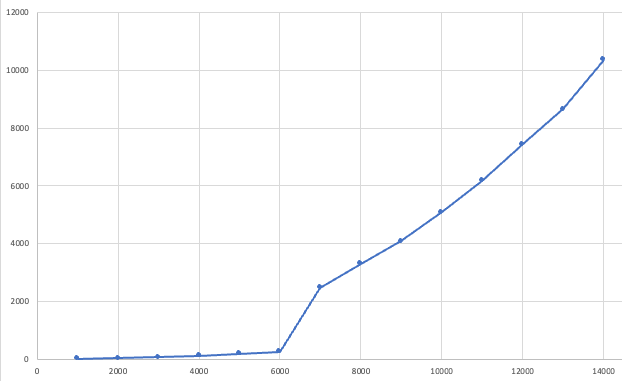
以下のグラフはList数(横軸)と処理時間(縦軸。単位はms)の相関関係を表しています。この例だとList数が7000になったタイミングで急激且つ異常に処理時間が増えています。
なお、オブジェクトがどういったfieldを持つのか&どういったバリデーションルールを定義しているかによってこの相関関係は変わってきます。単純なオブジェクトの場合はこういった傾向は見られませんでした。
我々のアプリケーションは、外部のシステムからとある種類の在庫データをAPIで受け付けています。1リクエスト内で大量の在庫データがリクエストされた結果、以下のような流れで問題が発生してしまいました。
- 1リクエスト内で大量の在庫データがリクエストされる
- ↓
- Hibernate Validatorが長時間、Dispatchers.Defaultのスレッドを専有してしまう
- ↓
- 後続の処理が詰まり、他のリクエストのLetencyが悪化する
結局どのように解決したかというと、Listを分割してからバリデーションし、バリデーション結果をマージするといったアプローチをとりました。非常に単純なアプローチではありましたが、結果として処理の時間を大幅に短縮し、問題を解決することができました。
// 例
val validationResults = outer.list.chunked(100).flatMap { validator.validate(it) }
if (validationResults.isNotEmpty()) {
return createErrorResponse(validationResults)
}以上が原因となります。Pyroscopeのおかげで原因究明がだいぶ捗りました。
まとめ
PyroscopeとContinuous Profilingについて紹介しました。また、Pyroscopeを活用したトラブルシューティングの事例についても紹介しました。
Continuous Profilingをしておくことで、問題がおきたときにすぐにProfiling結果を得ることができるため、調査が非常に捗りました。