
初めに
初めまして、東京大学大学院情報理工学系研究科創造情報学専攻修士1年の李博簡と申します。
8月7日から9月15日までの6週間、LINE データサイエンスセンター(DSC)のComputer Vision Labチーム(CVL) Virtual Human Labでインターンシップに参加させていただき、モーション生成関連の研究活動を行いました。
今回私が取り込んだ研究内容は、物理ベースの強化学習による、物理法則に沿った人間の動きの生成とその制御というテーマです。このレポートで、インターン期間中の研究と実験についてご紹介します。
課題
近年、Transformer、Diffusion modelやVariational Autoencoders (VAE)などを利用し多くの自由度が高いモーション生成や制御モデルが提案されつつある一方で、動いていないのに足が滑ったり、体の一部が中にめり込んだりなど、実際にはありえない現象が生じてしまう場合があります。その上に多様なモーションを生成するためにも、数多くのラベル付きモーションデータが必要で、高品質なモーションキャプチャーデータが多く公開されているにも関わらず、アノテーションは時間と費用がかかるタスクです。
これらの問題に対応するのは物理ベースのモーション生成であるとかんがえました。物理ベースとは物理の法則を基にした計算で、動きや挙動をシミュレートする技術です。これにより、リアルタイムでの反応や環境との相互作用、現実的な動きなど、より自然で現実に近いモーションを生成することが可能になります。環境との相互作用という点から、ロボット工学と同じくゴール条件付き強化学習がモーション生成においても広く使われてきました。人が幼い頃から長年にわたり、親など他人の動きから複雑な行動を学ぶのと似たように、エージェントに既存のモーションデータを模倣させることで、正しく体を動かす方法(ヒューマノイドの場合、関節ごとの回転と速度)を学習することができます。今回は既存の強化学習を使ったモーション生成モデルについて、より多様なスキルとタスクを達成するための改善に取り込みました。
背景知識
強化学習とは、エージェントが環境と相互作用しながら報酬を最大化するように行動を学ぶ方法です。ゴール条件付き強化学習は、特定のゴールや目的を達成するための行動を学ぶ強化学習の一種です。通常の強化学習では、エージェントは固定された報酬関数に基づいて行動します。しかし、ゴール条件付き強化学習では、エージェントは動的な報酬関数に基づいて行動します。この動的な報酬関数は、エージェントが達成しようとするゴールに基づいています。このアプローチの利点は、エージェントがさまざまなゴールや目的に対して柔軟に対応できることです。例えば、ロボットが部屋の異なる場所に物を持っていくタスクを学ぶ場合、ゴール条件付き強化学習を使用すると、ロボットは指定されたゴールに合わせて動き方を変えることができます。この方法は、多様なタスクを効率的に学ぶ能力が求められる場面で特に有効です。
関連研究
ASE[1]: Large-Scale Reusable Adversarial Skill Embeddings for Physically Simulated Characters
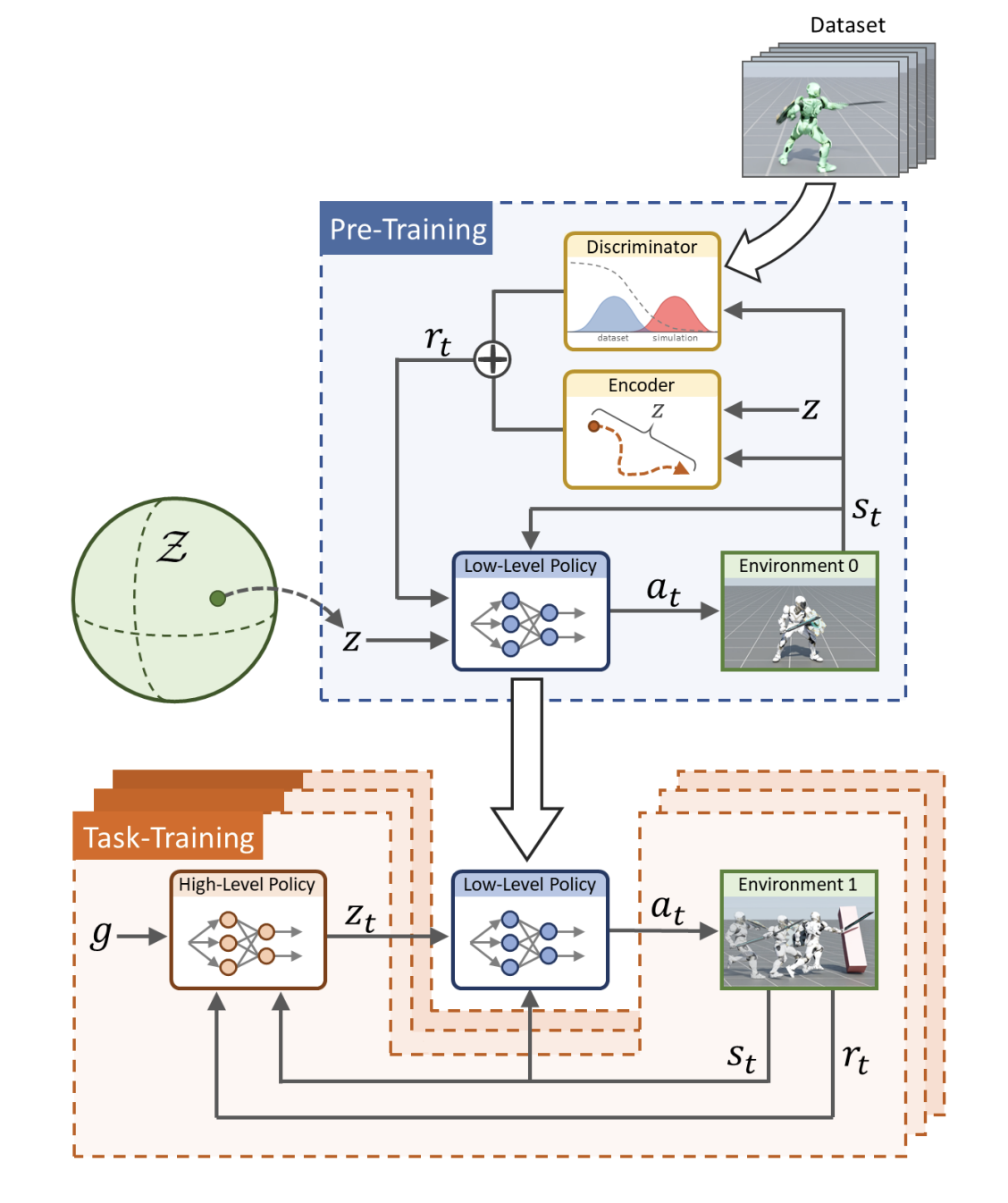
ラベルなしの構造化されていないモーションデータの模倣とスキルを学習するモデルは、近年多く提出されており、その中で、大規模なモーション入力に対処できるASEというフレームワークを紹介したいと思います。
提案されている方法は、事前トレーニングによるスキル学習と、転送トレーニングによるタスク学習に分けられています。事前トレーニングの段階では、スキル空間という潜在的空間に、入力されたデータセットの動きと似たような動作にマッピングするためのlow-levelポリシーがトレーニングされます。大規模データから学習していたスキルを忘れずに実行できる様にする方法としては、敵対的な模倣学習が使われています。low-levelポリシーがトレーニングされた後、ゴールとなるタスクごとに必要となるlow-levelポリシーを選択するhigh-levelポリシーのトレーニングをおこないます。今回の実験では、high-levelポリシーがlow-levelポリシーをうまく選択できていないということに気づき、それを改善する方向に拡張することにしました。
提案手法
前述したように、ASEのみならずほとんどの既存強化学習による物理ベースのモーション制御モデルには、敵対的なpriorや混合エキスパートなどディープラーニングの手法により、モード崩壊への対応が出来ていますが、一つのコントロールポリシーだけで大量の複雑なスキルを学習するには、一部のモーション入力が忘れられる、またはは学習できないという問題が挙げられる。
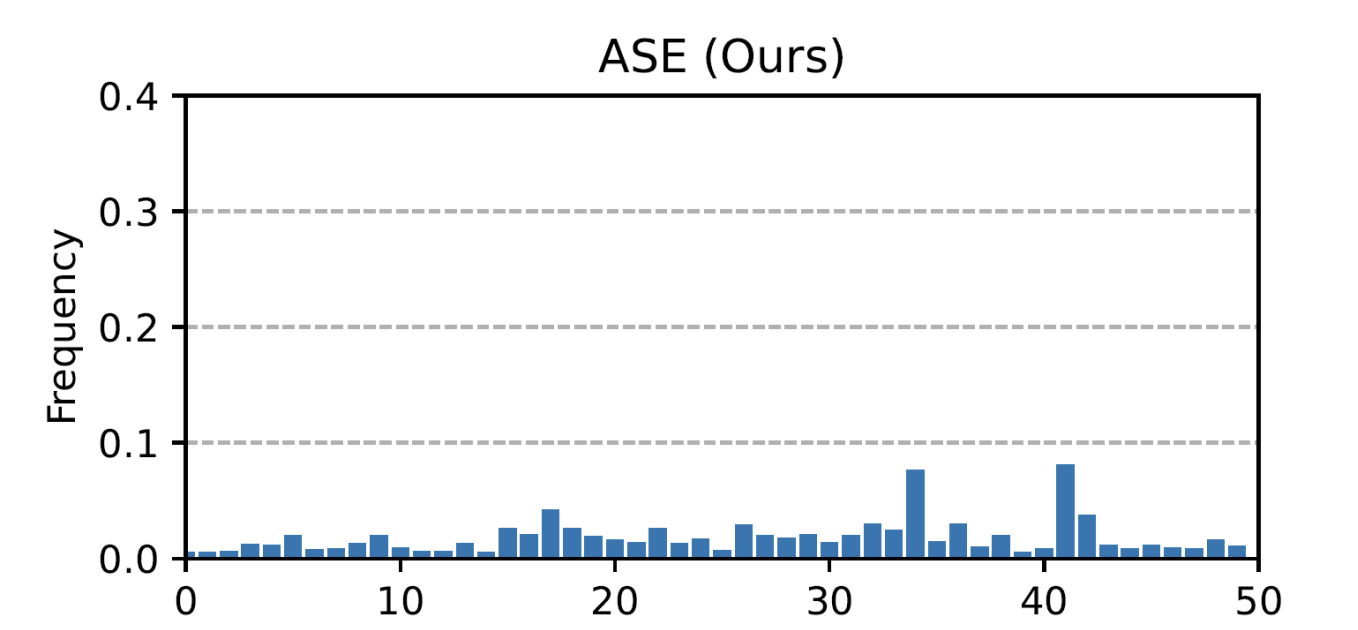
(Figure: ASEにおける各モーションの登場頻度。モーションによってはほぼ登場しないものも存在します。 ASE[1]: Large-Scale Reusable Adversarial Skill Embeddings for Physically Simulated Characters)
- 提案:
- 公開されているASEの学習済みモデルでは、Reallusion社のSWORD & SHIELD STUNTSモーションデータセット[4]を使っていましたが、キャラクターが戦うシーンのみでクリップ総数42で長さ合計5分の割と短いデータセットであるため、大規模でモーションのバラエティも上回るSFU Motion Capture Database[5]を用いての学習不足の改善効果を見ました
- SFU Motion Capture DatabaseのモーションデータをASEで用いられている形式に変換し、比較をしました
- 総数100クリップ、長さが30分のモーションキャプチャーデータセット
- Reallusionデータセットにおいて、attackなどの戦闘的なモーションにreward weightを高く設定していたが、こちらのデータセットにはモーションの種類が広く長さも同一ではないため、全部のクリップを同じreward weightを設定
実験
エージェントの頭をターゲットに触るという新しいタスクを設定し、既存のデータセットによるスキル埋め込みでタスクトレーニングされた結果と、提案手法によるタスクトレーニングを比較します。
Reallusion社モーションデータセットによるASEのlow-levelポリシー

ASEの学習済みモデルから跳ぶモーションを含む1分の長さのデータセットよりfine-tuningされたlow-levelポリシー

- ジャンプの動きは、ある程度、いくつかの動作によって記録され、模倣されていることが観察できます。
- キャラクターが飛んでいる動きは、モデルが既存のモーション(ジャンプ動作と走行動作)の間の新しいモーションを学ぼうとしているものである可能性がありますが、
これら二つのモーションはあまりにも離れています。
SFU Motion Capture DatabaseによりトレーニングされたASEのlow-levelポリシー
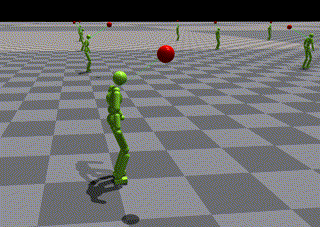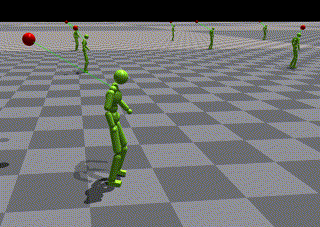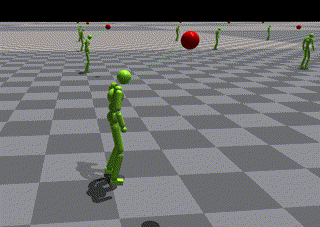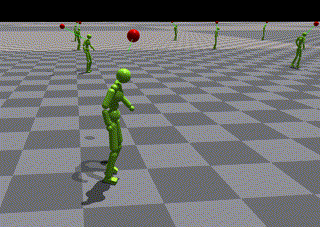
- 結果として、エージェントはジャンプを使用して目標に到達できませんでした。
- 入力から本当にジャンプスキルが学ばれたかを確認する必要があります。
- 一様サンプリングにより全てモーションが均一に学習される様に変更します。
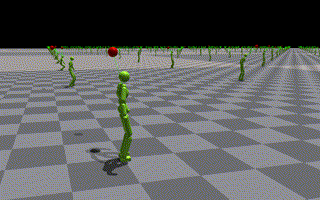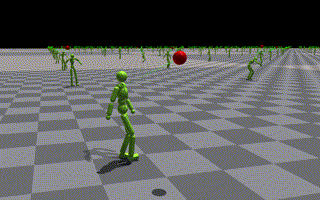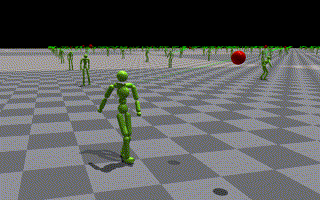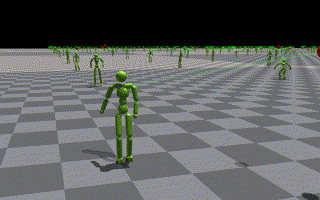
- 比較用にローカルでのトレーニング結果視覚化を伴ってタスクトレーニングを再実行する(下記に示す)
- いくつかのエージェントが積極的にジャンプを使用して目標に到達しようとしている様子が見えます
- 問題は、入力のジャンプ動作が十分な高さを持っていないことが考えられます
- さらなる多くのジャンプ動作入力で訓練します

- 単一モーションクリップを使うlow-levelコントローラーのfine-tuning.
- タスクトレーニングを行わなくても、エージェントはある程度ジャンプすることで目標に到達できることが観測できます
感想
自分の研究分野はモデルやモーションの融合なんですが、今回のインターンシップで主なテーマにあたる強化学習は新たな分野にあたり、メンターの藤原さんがもちろん、さらには、Generationチームの小坂さんにも多くなアドバイスのみではなく、研究に必要な基礎知識もたくさんいただき、とても感謝しています。インターンシップ全体の流れを振り返ると、前半は強化学習用の環境構築にはかなり時間がかかっており、様々な問題に対応することに時間が必要となり、研究自体には進捗があまり出なかったことが少し悔やまれます。リモートサーバーでの視覚化をこだわりすぎて、でも実験結果を見るには他にも方法があって、そちらの方が早めに次の段階に進むことができると思います。
今回の6週間の割と短い間で、このようなやり残し的なことも他にありましたが、研究の進め方や実装経験はもちろん、留学生として、日本語と英語両方でチームメンバーと交流をしていただき、コミュニケーション方と言語力も共にすごく勉強になっており、今後いろんな場面でのの力になると思います。
References
[1] Peng, Xue Bin and Guo, Yunrong and Halper, Lina and Levine, Sergey and Fidler, Sanja, ASE: Large-scale Reusable Adversarial Skill Embeddings for Physically Simulated Characters, ACM Trans. Graph.Volume 41, pp 1–17.
[2] Jordan Juravsky and Yunrong Guo and Sanja Fidler and Xue Bin Peng, PADL: Language-Directed Physics-Based Character Control, SIGGRAPH Asia 2022 Conference Papers, 2022
[3] Tevet, Guy and Gordon, Brian and Hertz, Amir and Bermano, Amit H and Cohen-Or, Daniel, MotionCLIP: Exposing Human Motion Generation to CLIP Space, Computer Vision--ECCV 2022: 17th European Conference, Tel Aviv, Israel, October 23--27, 2022, Proceedings, Part XXII, 2022
[4] Reallusion, https://actorcore.reallusion.com/3d-motion/pack/studio-mocap-sword-and-shield-stunts
[5] SFU Motion Capture Database, Simon Fraser University & National University of Singapore, https://mocap.cs.sfu.ca/
[6] Zhengyi Luo and Jinkun Cao, Alexander Winkler abd Kris Kitani and Weipeng Xu, Perpetual Humanoid Control for Real-time Simulated Avatars, ICCV 2023