
LINE株式会社 Business Platform開発室 DMP Devチームの石田です。
今回はLINE DMPにおけるHTTPでのファイルダウンロード処理で発生したパフォーマンス問題の改善の事例について紹介します。
はじめに
まず、DMPとはData Management Platformの略です。LINE DMPは、LINE外部からアップロードされたデータや、LINE内部サービスのデータをETL(Extract Transform Load)処理によって取り込んで、LINE広告やLINE公式アカウントをはじめとするLINEのB2Bプロダクトで活用できるプロダクトです。LINE DMPはPrivate DMPであり、LINE内部に閉じた活用に限定されているため、馴染みのない方も多いと思います。
以下の記事ではLINE DMPについて詳しい説明がありますので、ご参考にしてください。
LINE DMPは、そのプロダクトの性質から、様々な経路から取り込んだデータを様々な形式で提供します。
数あるフローの中でも今回は、LINEの広告主ウェブサイトへの訪問履歴データを蓄積し、集計した結果をHTTP経由でダウンロードする際に発生した問題について、その検知と改善の過程について紹介します。
フロー概観
今回の処理のイメージが湧きやすいように、ウェブサイトの訪問履歴を集計して取り込むフローの概観を記載します。
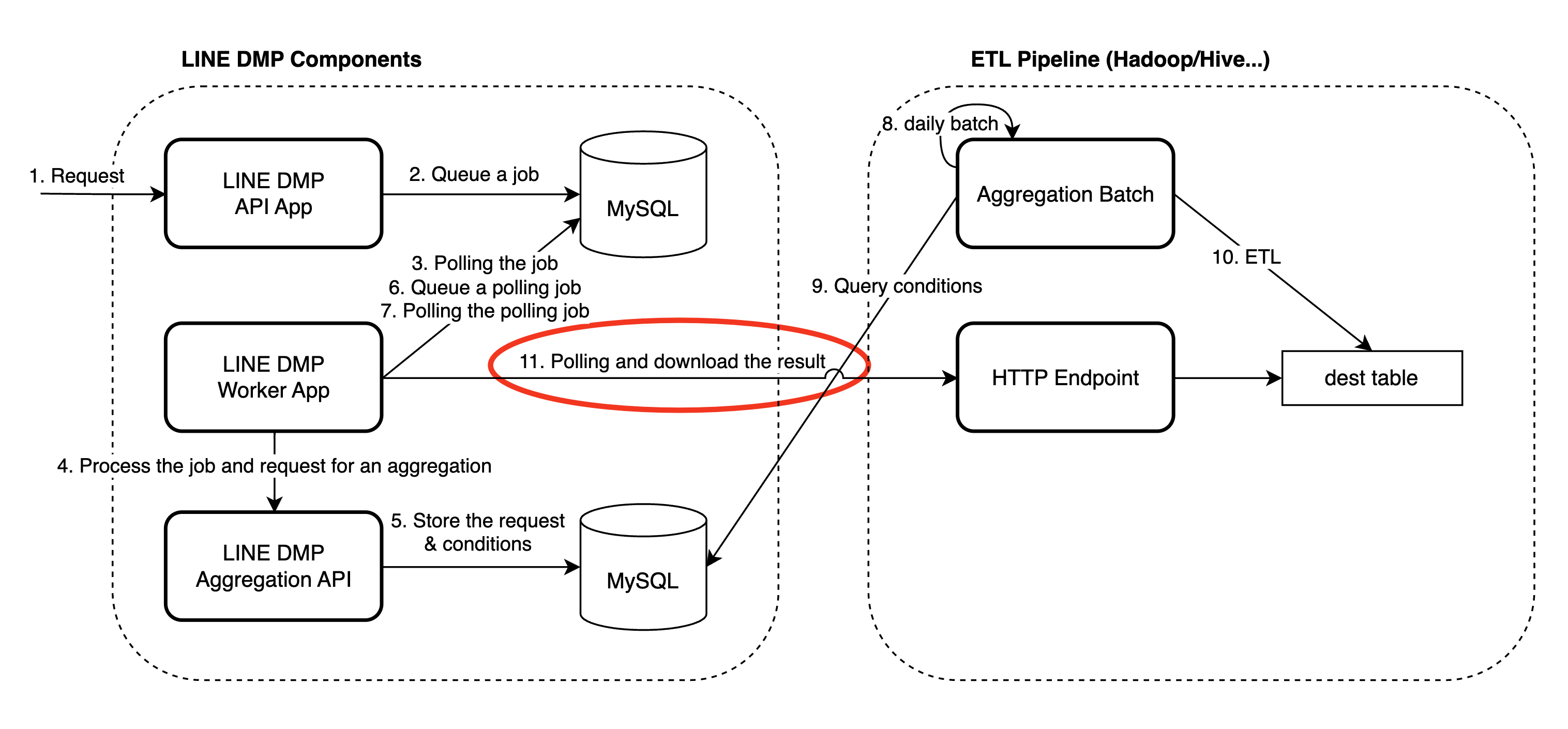
以下のような流れで処理が行われます。
- まず、集計のリクエストがLINE DMP APIに行われます。
- 次にDMP内部で集計をリクエストするためのWorker JobがMySQLにキューイングされます。
- Worker Jobがポーリングされて処理がWorker Jobで開始されます。
- DMP内部で集計を受け付けるAPIに、集計を依頼するリクエストを行います。
- 集計を受け付けるAPIでは、受け取ったリクエストを元に、集計条件などを専用のMySQLにストアします。
- 集計結果を取り込むためのジョブをMySQLにキューイングします。
- DMPのWorker Appでは、集計結果を取り込むためのジョブを定期的にポーリングして実行します。
- ETL Pipelineでは、Daily Batchで集計を行います。
- Daily Batchで専用のMySQLをクエリし、集計のための条件を取得します。
- ETLを行い、最終結果を圧縮されたテーブルに格納します。
- テーブルに結果が格納されたことをWorker Jobで確認できれば、HTTP Endpoint経由で結果をファイルとしてダウンロードします。
11番の処理で今回問題が発生したため、それ以降の処理については省略します。
事象の検知
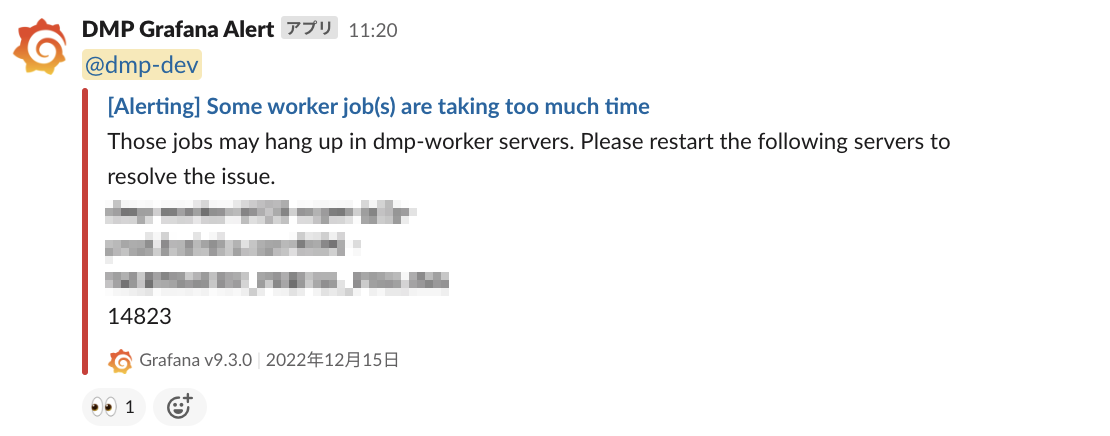
LINE DMPでは、Grafanaによるモニタリングを活用しており、アプリケーション固有の異常についてもGrafana Alertを使った検知を導入しています。
前述のWorker Appに関するメトリクスに対するアラートも設定されており、Worker Jobが長時間処理されているものが存在する場合に発生するアラートが設定されています。今回このアラートが発火し、Slackに通知が送信されたことで問題を検知しました。この通知によって、前述の11番の処理が長期間実行されているということがわかります。
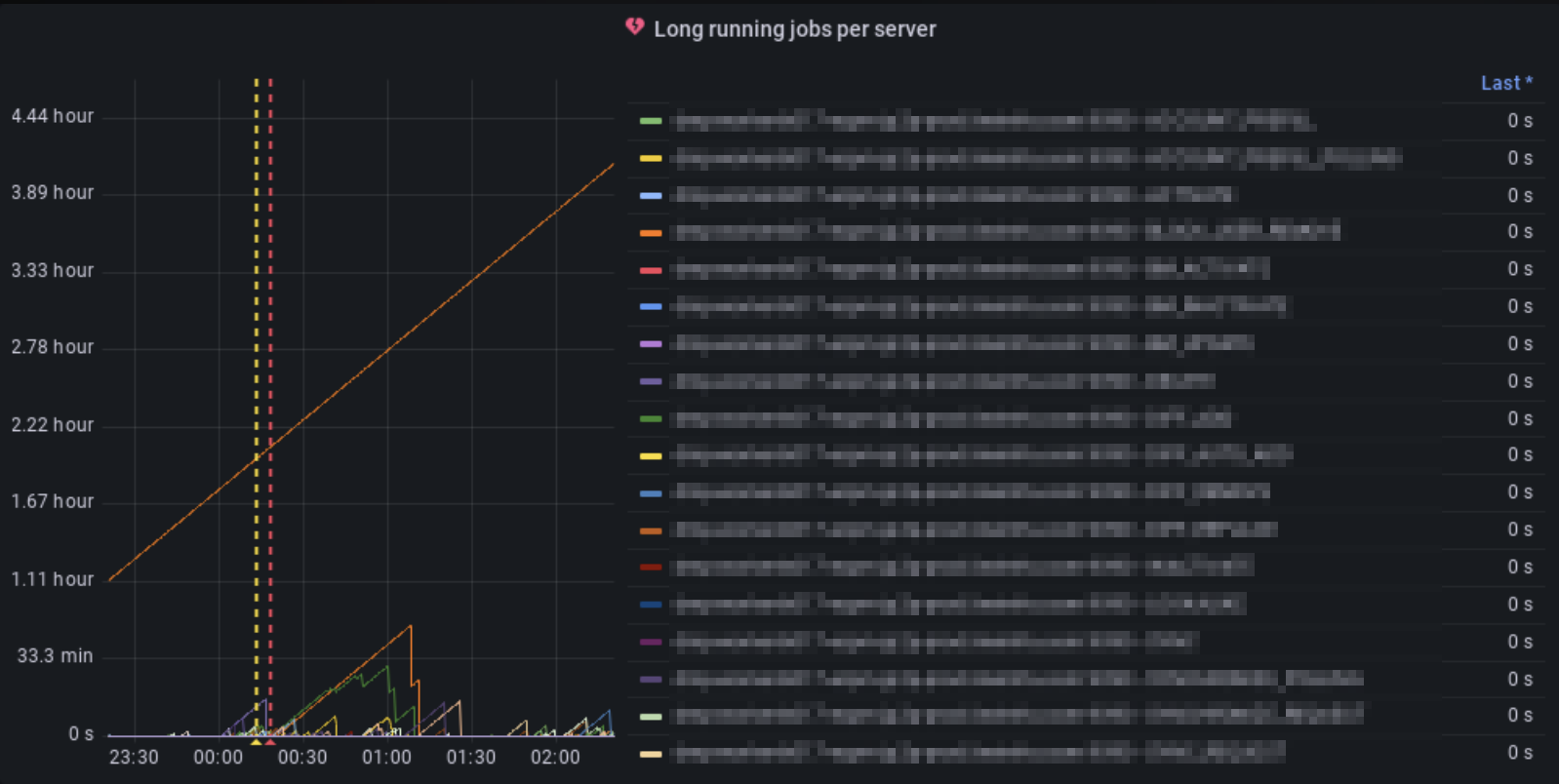
Grafana Dashboardを確認すると、Worker Jobが1つだけ飛び抜けて長期間実行されていることがわかります。
原因の切り分けと特定
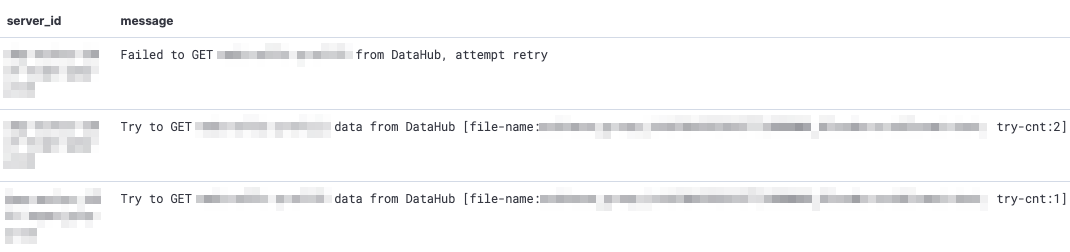
LINE DMPでは、アプリケーションのログをKibana上で見れるようになっており、まずは何らかのエラーが原因でこのような事象が起きているのかどうかをすぐに調べることができます。
その結果、どうやらダウンロード処理が30分以上の長期間に及んだ結果、タイムアウトによって途中で失敗し、処理が進まないために処理が終わらなくなっているということがわかりました。タイムアウトが発生した結果、 Premature end of chunk coded message body: closing chunk expected という途中でレスポンスが途切れてしまうエラーも確認できました。
そこで、対象のファイルを確認すると、展開後約1.7GB程度のファイルだったため他のWorker Jobが処理するファイルサイズよりも比較的大きなファイルサイズであることがわかりました。
しかし、curl経由でダウンロードする場合にはローカルマシンに1、2分程度でダウンロードができることが確認できたため、この問題はクライアント固有の問題であるというように切り分けることができます。
VisualVMでのProfiling
クライアント固有の問題で時間がかかっていそうだということは分かりましたが、出力されたログからは具体的にどの箇所が問題になっているかを特定するには粒度が足りませんでした。
処理のボトルネックの原因を詳細に絞り込むために、今回はVisual VMでのProfilingを使用しました。
Visual VMのSamplerのうちCPU Samplerを用いることで、現在実行されている処理のうち、どこにどれだけCPUが占有されているのかを調べることができます。確認したところ、 org.apache.http.util.ByteArrayBuffer.append() にほとんどの時間が費やされていることが分かりました。
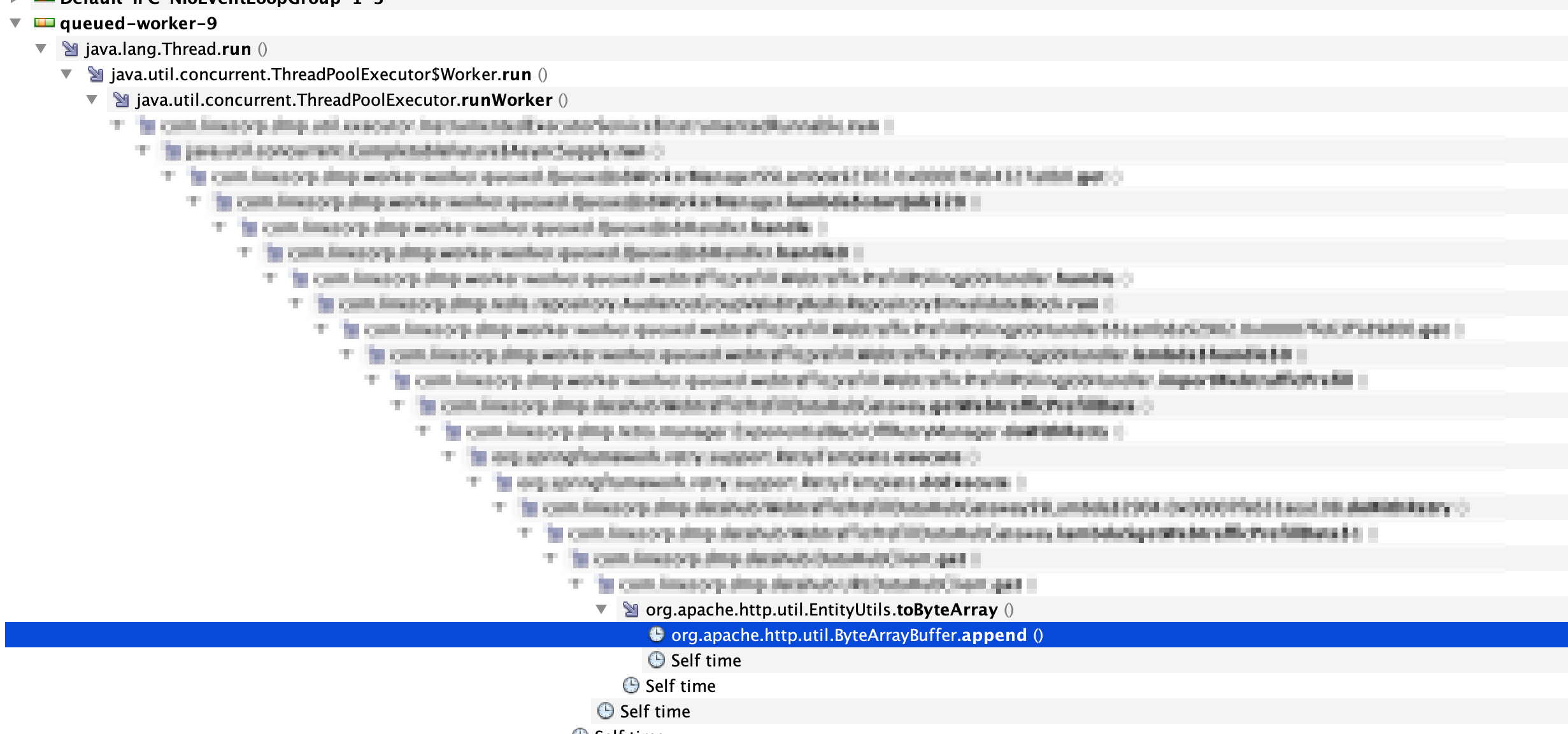
対象のクライアント実装は、初期に実装された2017年ごろから com.apache.http.util.EntityUtils.toByteArray() を使って、HTTPレスポンスからbyte配列でダウンロードするものになっていたため、直近の変更によって引き起こされた問題ではなさそうだということが考えられました。
そのため、EntityUtils自体の実装を確認する必要があります。
EntityUtils実装の確認
EntityUtilsは、「org.apache.httpcomponents:httpcore:4.4.15」のバージョンのものを利用していました。
コードを確認すると、レスポンスのContent-Lengthが分からなかった場合にはバッファのためのbyte配列の初期サイズとして、DEFAULT_BUFFER_SIZE定数の値が利用されることがわかります。DEFAULT_BUFFER_SIZEは4096byteとなっています。
問題となるファイルをHTTP1.1でダウンロードすると、Transfer-Encoding: chunkedでレスポンスが返るため、Content-Lengthが事前に分からないという条件に当てはまってしまい、ByteArrayBufferの初期サイズが4096 byteになってしまっているようでした。
public static byte[] toByteArray(final HttpEntity entity) throws IOException {
Args.notNull(entity, "Entity");
final InputStream inStream = entity.getContent();
if (inStream == null) {
return null;
}
try {
Args.check(entity.getContentLength() <= Integer.MAX_VALUE,
"HTTP entity too large to be buffered in memory");
int capacity = (int)entity.getContentLength();
if (capacity < 0) {
capacity = DEFAULT_BUFFER_SIZE;
}
final ByteArrayBuffer buffer = new ByteArrayBuffer(capacity);
final byte[] tmp = new byte[DEFAULT_BUFFER_SIZE];
int l;
while((l = inStream.read(tmp)) != -1) {
buffer.append(tmp, 0, l);
}
return buffer.toByteArray();
} finally {
inStream.close();
}
}
L139のbuffer.apppendの実装をさらに深く見てみます。
すると、初期バッファサイズが小さいために、L86の条件に毎回ヒットしてしまい、新しくInputStreamから読み取った後に毎回バッファサイズを拡張してしまうということがわかります。
public void append(final byte[] b, final int off, final int len) {
if (b == null) {
return;
}
if ((off < 0) || (off > b.length) || (len < 0) ||
((off + len) < 0) || ((off + len) > b.length)) {
throw new IndexOutOfBoundsException("off: "+off+" len: "+len+" b.length: "+b.length);
}
if (len == 0) {
return;
}
final int newlen = this.len + len;
if (newlen > this.buffer.length) {
expand(newlen);
}
System.arraycopy(b, off, this.buffer, this.len, len);
this.len = newlen;
}
そして、L87のexpandの実装を見ると、呼び出されるたびに毎回新しいサイズのbyte配列を割り当てし、古いbyte配列から新しいbyte配列にコピーを行なっていることがわかります。
private void expand(final int newlen) {
final byte newbuffer[] = new byte[Math.max(this.buffer.length << 1, newlen)];
System.arraycopy(this.buffer, 0, newbuffer, 0, this.len);
this.buffer = newbuffer;
}このexpandの処理で行われる過剰なbyte配列の割り当てと配列コピー処理が、問題のファイルでダウンロード時間が極端に延びてしまう原因であることが推測できます。
この時のEntityUtils.toByteArrayの処理の流れは、まずDEFAULT_BUFFER_SIZEをNとおくと、
- 初回はbyte[N]の割り当てと、N回の要素コピーが発生する。
- 次は、byte[2N]の割り当てと、2N回の要素コピーが発生する。
- 次は、byte[3N]の割り当てと、3N回の要素コピーが発生する。
- そしてM回目は、byte[M * N]の割り当てと、M * N回の要素コピーが発生する。
というように、合計の要素コピー回数は、これら全ての足し合わせとなります。
つまり以下のように要素コピー回数が二次関数的に増加するということになります。
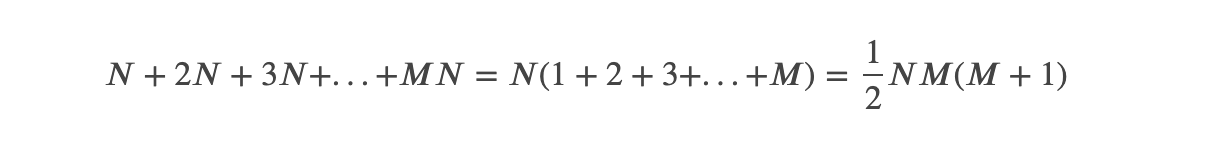
DEFAULT_BUFFER_SIZEを増加させれば、Mが小さくなるため、効率化を見込むことができますが、二次関数的に増加するということ自体には変わりありません。
なお、最新バージョンでも、この部分は修正が特に行われていませんでした。httpcomponents:httpcoreは他のライブラリによる推移的な依存ということもあり、バージョンアップでの対応という選択肢を取ることはこの時点では難しいということになります。
代替案を調べる
HTTPレスポンスから取得できるInputStreamに実装されているreadAllBytesメソッドがすぐに代替として利用できそうだったため、同様の問題がないかを調べる必要があります。
JDK11のInputStreamのreadAllBytesはreadNBytesを内部で呼び出しており、こちらもDEFAULT_BUFFER_SIZE = 4096が常に利用されるようになっているものの、実装が異なります。
public byte[] readNBytes(int len) throws IOException {
if (len < 0) {
throw new IllegalArgumentException("len < 0");
}
List<byte[]> bufs = null;
byte[] result = null;
int total = 0;
int remaining = len;
int n;
do {
byte[] buf = new byte[Math.min(remaining, DEFAULT_BUFFER_SIZE)];
int nread = 0;
// read to EOF which may read more or less than buffer size
while ((n = read(buf, nread,
Math.min(buf.length - nread, remaining))) > 0) {
nread += n;
remaining -= n;
}
if (nread > 0) {
if (MAX_BUFFER_SIZE - total < nread) {
throw new OutOfMemoryError("Required array size too large");
}
total += nread;
if (result == null) {
result = buf;
} else {
if (bufs == null) {
bufs = new ArrayList<>();
bufs.add(result);
}
bufs.add(buf);
}
}
// if the last call to read returned -1 or the number of bytes
// requested have been read then break
} while (n >= 0 && remaining > 0);
if (bufs == null) {
if (result == null) {
return new byte[0];
}
return result.length == total ?
result : Arrays.copyOf(result, total);
}
result = new byte[total];
int offset = 0;
remaining = total;
for (byte[] b : bufs) {
int count = Math.min(b.length, remaining);
System.arraycopy(b, 0, result, offset, count);
offset += count;
remaining -= count;
}
return result;
}DEFAULT_BUFFER_SIZEのサイズで割り当てられたbyte配列をArrayListに追加していき、最後に合計のサイズで割り当てたbyte配列を用意して、ArrayListに追加したbyte配列から順番にコピーする実装になっています。
つまり、DEFAULT_BUFFER_SIZEをN、ArrayListにbyte配列を追加する回数をMとすると、要素のコピー回数が2NM回程度しか発生しないことがわかります。結果として、二次関数的な増加を回避することができることが分かります。
例えば、今回の1.7GBのファイルであれば、おおよそ 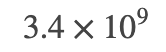 回程度の配列コピーに絞ることができるため、現実的な時間内で処理を完了させることができるということになります。
回程度の配列コピーに絞ることができるため、現実的な時間内で処理を完了させることができるということになります。
この結果を踏まえ、実装をInputStream.readAllBytesに切り替えることで、実際に対象のファイルの処理については数分で完了することができました。
結論として、HTTPで大きなファイルをダウンロードするようなユースケースでは、Content-Lengthが事前にわからない場合にEntityUtils.toByteArrayを使うのではなく、InputStream.readAllBytesを使うことで効率よくダウンロードを行うことができるということがわかりました。
まとめ
本稿では、LINE DMPにおけるパフォーマンス問題の検知から改善まで、実際のケースを取り上げてどのように行なっているのかということについて紹介しました。
数年間大きな問題なく動作しているような処理でも、サービスの成長とともにエラーに直面するようになることがあります。メトリクスやログを適切に取得し、プロファイルツールを用いて原因を切り分け、必要があれば利用しているライブラリのソースコードを読んで分析することで、根本原因の調査に大きく役立ちます。
本稿を通じて、LINE DMPにおけるトラブルシュートの雰囲気を少しでも感じていただけたら幸いです。
補足
この内容について、Apache HttpComponents Mailing Listにフィードバックを行ったところ、EntityUtils.toByteArrayについては1MB以上のレスポンスを処理することを想定していないという回答がありましたため、補足といたします。