
はじめに
自己紹介
初めまして、京都大学情報学研究科 修士1年の荒川健吾です。大学院では、HRI(ヒューマンロボットインタラクション)分野の研究室に所属し、アバターロボットの移動操作の困難性の解決に意図認識の手法を用いて取り組んでいます。また、普段はアルバイトとして医療現場での医師の負担軽減を目的としたカルテ要約ソフトのバックエンド開発を担当しています。
今回は6週間の就業型インターンで、Machine Learning Infrastructure2チームに配属され、Spark を用いた OFS(Online Feature Store)のデータインジェストジョブの開発に取り組みました。
Machine Learning Infrastructure2 チーム とは
Data Engineering センター/Machine Learning Platform室 に属し、4名のエンジニアが在籍しています。
社内のエンジニアがMLモデルの開発や利用のみに集中できるように、MLとその周辺環境を利用しやすいものにすることを目的として、たくさんのプロダクト・ツールの開発・運用を行っています。
取り組んだ課題
テーマ:Sparkを用いたOFS Syncerの開発
本インターンシップの課題は、初日に提示していただいた3つの候補から自分で選択しました。
提示いただいた候補の中で、他の2つはこれまで経験してきたWebアプリ開発に近い内容でした。それよりも、このインターンを通じて新しくデータ処理の技術に触れ、学びたいと考えたため、Sparkを用いたOFSのSyncer (データインジェストを行う機能)ジョブの開発に取り組むことに決めました。
背景
Online Feature Store (OFS) とは
OFSとは、主にMLでの使用を目的とした高スループット/低レイテンシ を志向したデータストアです。
OFSは、以下のような機能を提供しています。
- オンラインでの推論/学習のための特徴量ベクトルの保存
- ANN (Apporoximate Nearest Neibours: 近似最近傍)機能の提供
- MLの予測結果の保存とデータ提供
IUのデータストレージのデータをOFSに移しておく(この処理をIngestionと呼びます)ことで、データをさらに効率よく処理や分析に利用することができます。
※IU(Information Universe):分析に必要な全ての機能を単一の分析環境で提供するLINEの『データ統合管理プラットフォーム』。Hadoop エコシステムを使用している。
OFSは、Feature(特徴量)やANN IndexをEntityという単位で管理します。Entityには複数のversionのFeatureやANN Indexが属します。
OFSのIngestion処理
データインジェスト(Ingestion) とは
データソースからデータを収集し、特定の目的に応じてそれをデータストレージに保存するプロセスをデータインジェスト(Data Ingestion)といいます。
OFSでは、高スループット/ 低レイテンシ を実現するため、データをバイナリ形式であるProtocol Buffersでデータストレージに格納しています。そのため、Ingestionの際には、データのシリアライズが必要となります。OFSのIngestion処理を行う部分をSyncerと呼びます。
現在のOFS Syncer
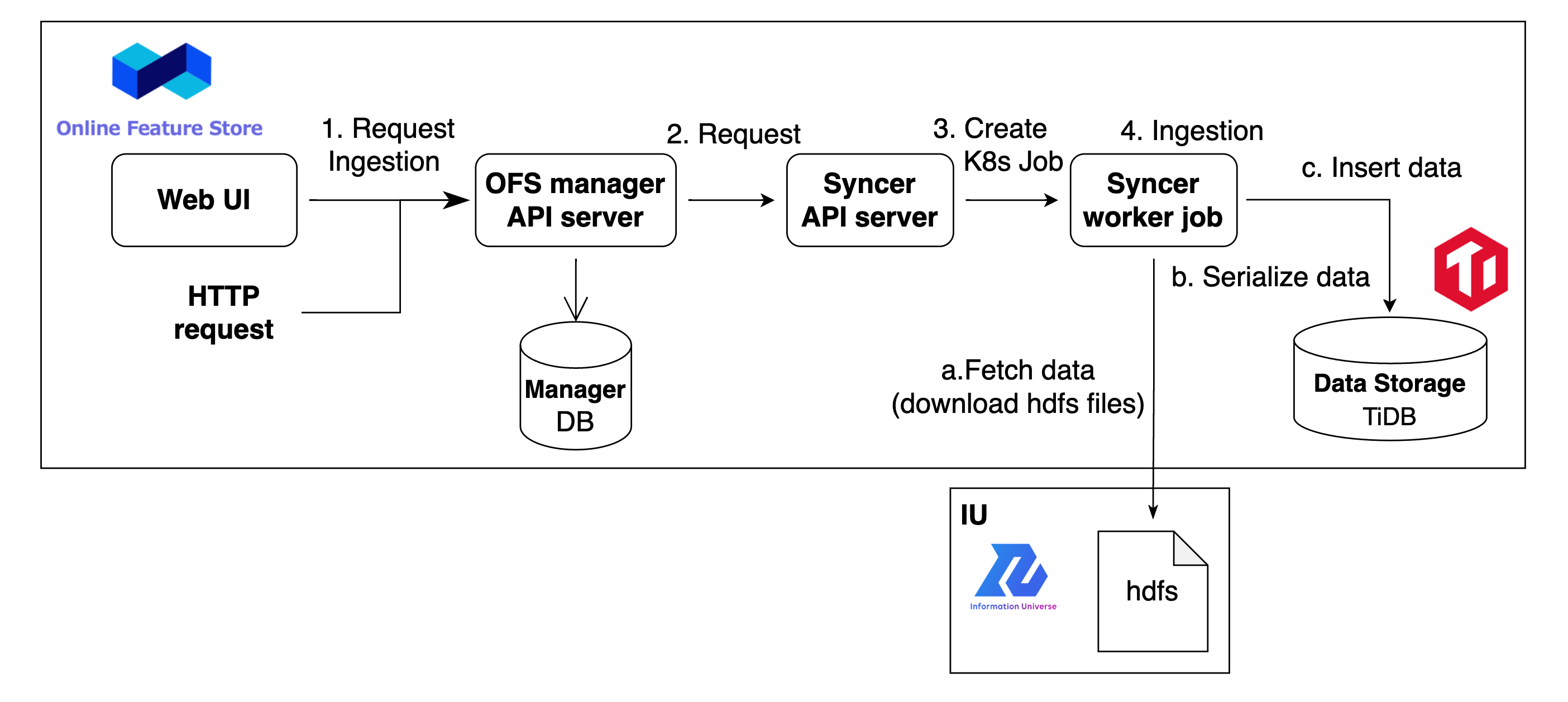
OFSでは、OFS全体を管理する Manager と Ingestion処理を管理する OFS Syncer の API serverが起動しています。Ingestion処理は以下のような流れで実行されます。
- OFSのWebUIやHTTP requestにて、OFSのManager serverにFeature作成が指示される。
- Manager serverがIngestion処理のリクエストを受け取ると、Entityやversionの情報と共にSyncerサーバにリクエストが送信される。
- リクエストを受け取ったSyncer serverは、Syncer workerのジョブを作成・起動する。
- Syncer workerがIngestion処理を実行する。
Ingestion処理:- IUのデータストレージからデータを取得してくる。
- hdfs ファイルを直接ダウンロードする
- Protocol Buffers 形式にデータをシリアライズする。
- OFS の Data Storageにデータを投入する。
- IUのデータストレージからデータを取得してくる。
問題点・実装の目的
問題点
現在のOFS Syncer workerはHiveテーブルに対応した実装となっており、IUからのデータ取得において次のように処理を行っています。
- IU上の指定されたテーブル/パーティションのhdfsファイルが入ったディレクトリのパスを受け取る。
- ディレクトリ下のhdfsファイルをダウンロードする。
- データファイルの形式(Parquet, ORC)に応じて、hdfsファイルの中身を読み出す。
この実装は、Hive テーブル形式でデータが管理される際、物理ストレージ上ではテーブルに対応するディレクトリが存在し、またパーティションが存在する場合は、テーブルディレクトリ下に各パーティションに対応したディレクトリが存在するため機能しています。
しかし、Icebergテーブル形式(詳細は後述)の場合、物理的なデータ配置がより抽象的であり、テーブルやパーティションに対応したディレクトリが存在せず、現在の処理方法のままでは対応できません。
まだ先の話ですが、LINE組織内ではデータ管理の効率化・コスト削減のために、IU Hadoop内の現在Hive テーブル形式のデータについても将来的にIcebergテーブルを導入していく方向性になっており、Icebergテーブル形式のデータについてもOFSへのIngestionができるようにしておく必要があります。
目的
IU内のIcebergテーブル形式のデータについても、OFSに取り込めるようにするため、Spark SQLを使用してOFS の Ingestion処理を実行するバッチジョブを作成します。
実装するバッチジョブは、現在のOFS実装のSyncer worker job に相当する処理を行います。
使用する技術
今回のインターンを通じて、これまで触れたことのなかった技術をいくつも学びました。その中から主なものを簡単に紹介します。
Apache Hadoop
Hadoopとは
Hadoopとは、大規模なデータセットを分散ストレージ環境で効率的に処理するためのオープンソースのフレームワークです。
Hadoopエコシステムの主要なコンポーネント
- HDFS(Hadoop Distributed File System): 分散ファイルシステム。Hadoopエコシステムではデータは物理的にはHDFS上に保存されます。
- Hive: Hadoop上で動作するデータウェアハウスコンポーネント。HiveQLという、SQLライクな言語によりクエリを実行します。
- YARN (Yet Another Resource Negotiator): リソース管理とジョブスケジューリングを行うフレームワークです。
Apache Spark
Sparkは、大規模なデータセットに対する分散データ処理を高速に行うためのクラスターコンピューティングフレームワークです。YARN上で動作することができ、Hadoopエコシステムと密に統合されています。インメモリ処理を使用し、Hiveがバックエンドで実行しているMapReduceでの処理よりも高速な実行が可能です。
今回のインターンシップでは、一連のデータIngestion処理をSparkを使用して実装しました。
Apache Iceberg
Icebergは、大規模なデータレイクにおけるより効率的なデータテーブルの管理を可能にする新しいテーブルフォーマットです。Icebergは、大規模なデータに対しても高速で効率的で信頼性が高く、また、各テーブルに対する変更をスナップショットとして保存することでバージョン管理を行うことができるなど、Apache Hiveのテーブルと比較してさまざまな優位性があります。メタデータストアとしては、Hive Metastoreを使用することで、Hiveのテーブルとデータの一元管理を行うことができます。
Apache Airflow
Airflowは、ワークフローやデータパイプラインのスケジューリングとモニタリングを行うワークフローエンジンです。タスクの依存関係を設定したDAG(Directed Acyclic Graph: 有向非巡回グラフ)を用いて、ワークフローを記述します。
今回のインターンシップでは、Ingestion処理のバッチジョブをAirflowを用いて作成しました。
TiDB
TiDBは、MySQLとの高度な互換性を持った分散SQLデータベースです。分散key-valueストアであるTiKVをデータストレージとして使用しています。
今回のインターンシップでは、OFSのデータストレージとして、TiDBが使用されています。
実装
インターンの最初の1週間では、環境構築、LINE社内で使用するツールの権限申請や理解を進めながら、チュートリアルとして単純なジョブ(Icebergテーブルのレコード数を表示するジョブ)をSpark、Airflowで実装しました。Sparkのコードの検証はJutopiaというLINE社内で使用しているJupyter Notebook環境で行いました。Jutopiaでは、IUクラスタに接続できるPySpark カーネルが提供されています。
2週目から、概念実証、設計、実装に入っていきました。実装は、次の順で行いました。
- Ingestion 処理を実行するSparkジョブの実装
- 実装したSpark ジョブをAirflowから実行するためのDAGの実装
1. Sparkジョブの実装
Spark ジョブ内では、大きく分けて以下の3つの処理を行います。それぞれの処理をJutopia上で実装して検証していきました。
- IUのデータストレージからデータを取得してくる。
- Protocol Buffers 形式にデータをシリアライズする。
- OFS の Data Storageにデータを投入する。
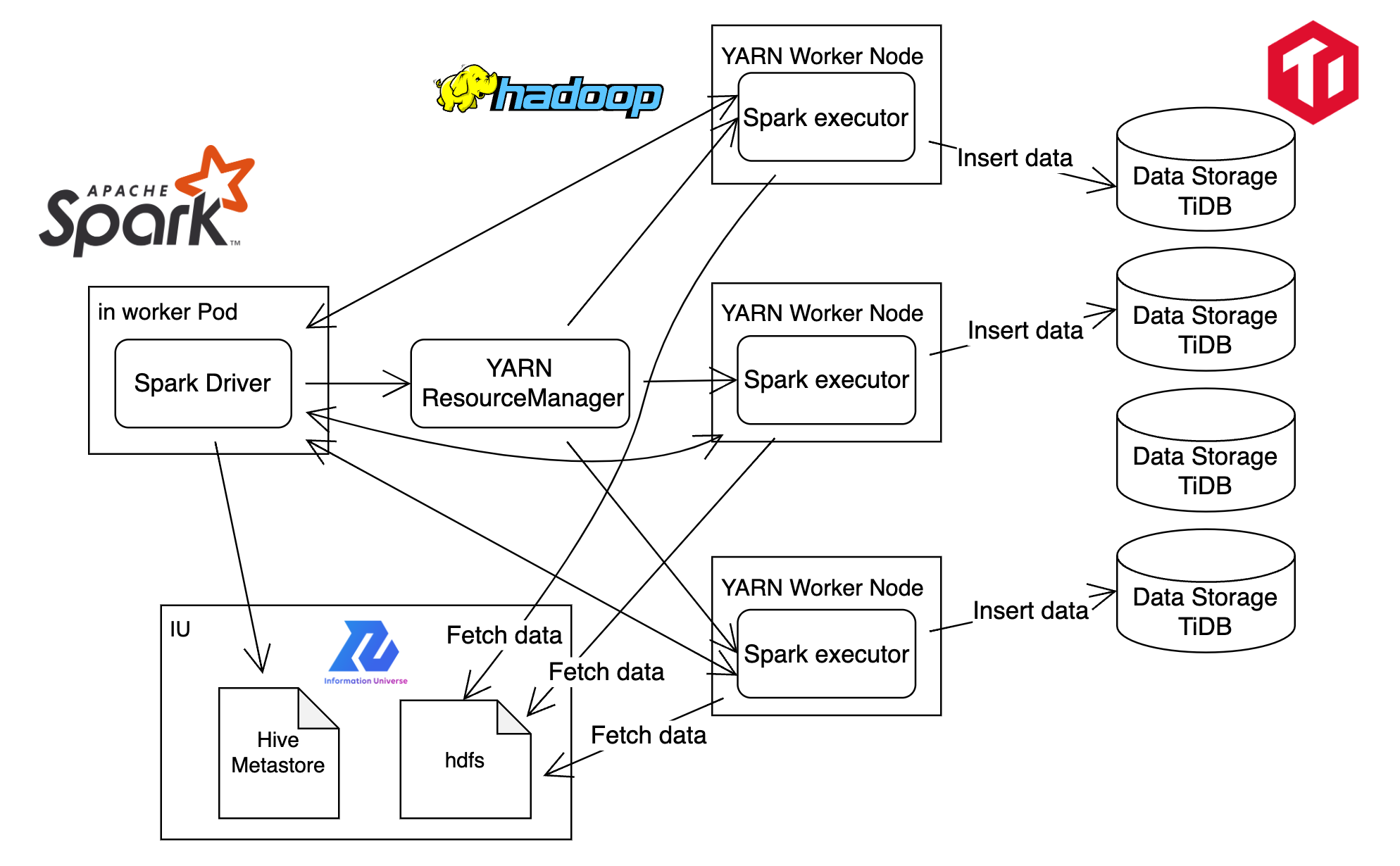
Sparkは分散処理のフレームワークであり、PySparkを用いて記述した処理が自動的に複数のノード上で分散処理されます。今回のIngestion処理では以下のような分散処理が行われます。
- SparkSessionの初期化:
- SparkのエントリーポイントであるSparkSessionを作成することで、DataFrame API、SQLクエリ、読み込み/書き込みの処理などが可能になります。
- リソースや使用パッケージに関するものなど様々なconfigがこの時点で設定されます。
-
コード解析とステージ生成:
-
PySparkで記述したプログラムは、最初にSpark Driverで解析されます。
-
この解析過程でプログラムは処理が最適化された上で、複数の「ステージ」に分割されます。
- 今回のジョブでは、後述するデータの取り出しからリパーティションがStage 1で、データのシリアライズからTiDBへの投入がStage 2で実行されます。
-
-
タスクのスケジューリング:
-
Spark Schedulerが、各ステージ内のタスクの実行順序とステージ間の依存関係を考慮してタスクのスケジューリングを行います。
- タスクとは、各ステージの処理を個別のパーティションごとに割り当てたものを指します。
-
- データのパーティション:
- Sparkでは、入力データを「パーティション」という小さい単位に分割します。各パーティションは独立したタスクによって処理されます。
- 最大でExecutorの数まで、タスクが並行して実行(i.e. パーティションが並行して処理)されます。
- そのため、データやリソースに合わせて適切にパーティションの再分割(リパーティション)をするのが望ましいです。
- 今回のジョブでは、リパーティションの有無とパーティション数を指定できるように実装しました。
- データの分散:
- 分割されたデータ(パーティション)は、クラスター内の各ワーカーノードに分散されます。
- データは各Executorによってデータソースからロードされます。
-
タスクの分散と実行:
-
スケジューラーによって生成されたタスクは、各ワーカーノード上のSpark Executorに割り当てられて実行されます。
-
Executorはタスクごとに一つのパーティションを処理します。
- 今回のジョブでは、各Executorが割り当てられたパーティションのデータのシリアライズを行った後、それぞれTiDBと接続してデータの投入を行います。
-
-
フェイルオーバーとリトライ:
-
タスクが失敗した場合、Sparkは自動的にそのタスクを別のノードで再実行します。
-
- 結果の収集と返却:
- 全てのタスクとステージが完了した場合、実行結果はSpark Driverに集約されます。
パフォーマンスの検証と対応
一連のIngestion処理がJutopia上で正常に実行できることを確認した後、SparkによるIngestionのパフォーマンスの検証をしました。目標としては、現在のOFS Syncer と同程度の実行時間で Ingestionが行えることとしました。
最初の実装での検証結果
特定のデータ(約910000rows, 800MB)に対してIngestionを実行したところ、以下の処理時間となりました。
|
現在のOFS Syncer |
Spark Syncer Job |
|---|---|
|
1 min. 10 sec. |
8 min. 56 sec. |
書き込み先が検証用のTiDBを使用していることによる影響は多少考えられますが、実装したSpark Jobで処理したところ、現在のOFSの約8倍の処理時間がかかってしまいました。SparkのWeb UIからlogを確認したところ、TiDBへの書き込み処理に長時間がかかっていることが確認できました。
パフォーマンス向上のための対応
ここまで、TiDBへの書き込みについては、Spark DataFrameのdf.write.jdbcメソッドを使用したシンプルな方法で行っていたのですが、この部分の処理の方法を変えることにしました。df.write.jdbcメソッドは、JDBC(Java Database Connectivity)を使ってSpark DataframeをRDBに書き込む方法です。各パーティションごとに、独立した単一のデータトランザクションでRDBへの書き込みが行われます。
パフォーマンスを向上させるために、TiDBへのデータ挿入を、各パーティション内(タスク内)でさらに並行度をあげて行うことにしました。Sparkのタスクは1つのCPUに対して割り当てられ、またI/Oバウンドな処理であることから各タスク内で非同期処理でTiDBへの書き込みを行うようにしました。具体的には、SparkのforeachPartition()メソッドとPythonの非同期ライブラリaiomysqlを使用しました。
aiomysqlを使用して非同期処理を行うことにより、以下のようなメリットが考えられます。
- 処理速度: 各パーティションのデータがさらに並行して書き込み処理されるため、処理速度が向上すると考えられます。
- リソース効率: I/O待ち時間を有効に使えるため、CPUとメモリ使用率が低く抑えられます。
- 柔軟性: 自分で書き込みロジックをコントロールできるので、トランザクションサイズやエラーハンドリングを自由に実装できます。
非同期処理を行ったことによる効果
非同期処理による書き込みを実装した上で、書き込みのバッチサイズ(トランザクションサイズ)についても変動させて検証した結果、以下のようなパフォーマンス向上が確認されました。
|
現在のOFS Syncer |
Spark Syncer Job |
|||||
|---|---|---|---|---|---|---|
|
batchsize=100 |
batchsize=200 |
batchsize=500 |
batchsize=1000 |
batchsize=2000 |
batchsize=5000 |
|
|
1 min. 10 sec. |
3 min. 5 sec. |
2 min. 34 sec. |
2 min. 12 sec. |
2 min. 01 sec. |
1 min. 58 sec. |
1 min. 52 sec. |
現在のOFS Syncerよりは遅いですが、2分前後での処理が可能となり、当初の実装では8分56秒かかっていた処理が大幅に短縮されました。
Docker imageとして実装
Airflowのジョブとして実行する際、docker Imageをもとにk8s Podを作成するので、Ingestion処理を実行するスクリプトを含んだDocker Imageを作成しました。作成したイメージはコンテナレジストリ(Harbor)にPushして管理します。
2. Airflow DAG の実装
実装したSpark Syncerの実行をAirflowのジョブとして管理するため、AirflowのDAG fileを作成します。
ML室で使用しているAirflowは、Kubernetes Executorを使用しており、以下のような流れでdocker Image内の処理が実行されます。
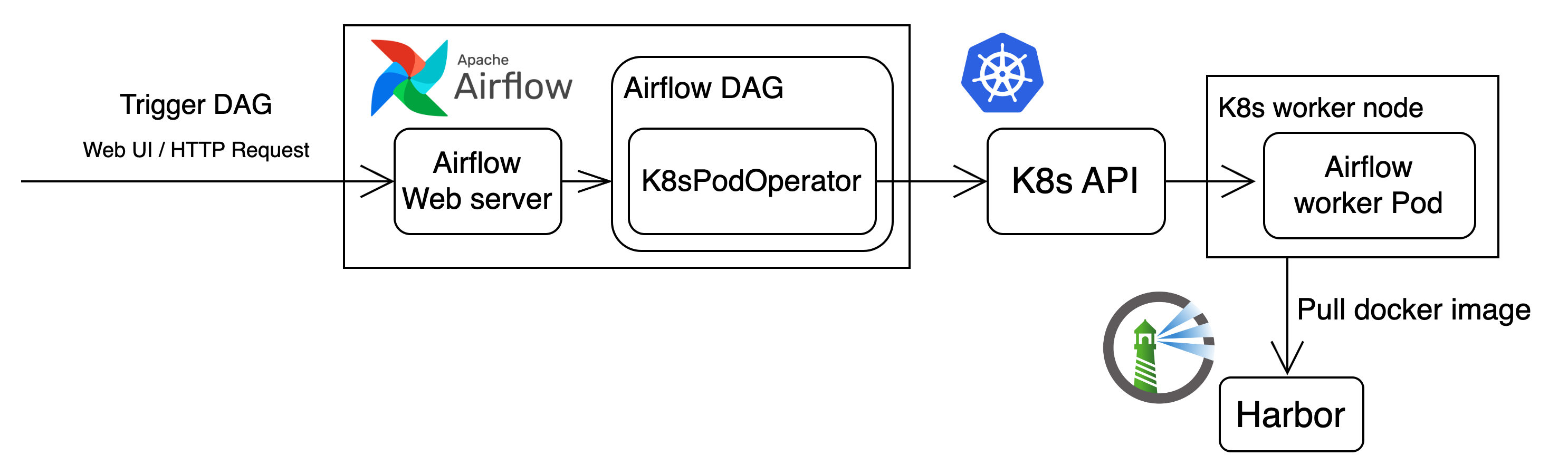
Figure 3. AirflowでJobが実行されるアーキテクチャ
Airflow Jobへのパラメータのインプット
AirflowのJobへは、トリガー時にJSON形式でパラメータを渡すことができます。Spark Syncer Jobは以下のパラメータを受け取り、必要に応じてKubernetesPodOperatorやContainer内のSpark Jobに渡します。
- OFSでの情報
- Entity ID, version
- IU resourceの情報
- db名, table名, カラム名, パーティション
- Jobの挙動の設定
- リパーティションの有無, Sparkのパーティション数, 書き込みのバッチサイズ, 並列数
- Spark の設定
- executor数, executor/driver の core数/memoryサイズ など
- k8s PodのResource設定
DAGファイルはトリガーされる前からAirflowのスケジューラによって読み込まれているため、トリガー時にJSONで入力されるパラメータや直前のタスクの出力をタスクの入力として使用する際には、Jinjaテンプレートを使用した動的な値の解釈を行います。
ジョブの実行
実際に実装した Airflow Jobの実行を、Airflow Web UI上から以下のように確認することができます。
終わりに
今回のインターンでは6週間の期間で、社内ツールであるOnline Feature StoreのSyncerをSparkを用いて開発しました。課題を提示していただいた当初は、実装までに6週間もかかるのだろうかと少し考えていました。しかし、インターンが進行する中で、全く触れたことのない技術を理解して使用することや、社内で使用されるたくさんのツールに慣れることには思ったよりも時間がかかり、あっという間に時間が過ぎて、終わってみればまだまだ時間が足りないという状況で、濃い6週間を送ることができました。
今回インターンで開発したOFSのSyncerはデータの処理を行う機能でした。データ周りの技術については、私自身経験が少ないという自覚があって、経験、勉強したい分野だったため、今回のインターンシップは非常に良い経験になりました。開発の中で実際に処理したデータが1億レコードを超えるユーザの特徴量であり、大きなデータを処理する貴重な経験になったの同時に、LINEの規模の大きさを非常に感じました。また、これまで実行速度等のパフォーマンスを意識した開発の経験もなかったため、その点でも非常に勉強になりました。
今回配属されたML Infra 2 チームのエンジニアの方々は、4名(お隣のML Infra 1チームを合わせても8名)という非常に少ない人数で大規模なLINEの社内で使用される多くのツールを開発・運用をされていて、LINEのエンジニアの方の技術力の高さに驚かされました。
この6週間のインターンを通じて、メンターのIsmailさん、マネージャーの櫻打さんをはじめとしたML Infra 2チームのエンジニアの方々にたくさんサポートしていただき、このような非常に貴重な経験ができました。深く感謝申し上げます。このインターンシップで得た貴重な経験と知識を、今後のエンジニアとしてのキャリアに生かしていきたいと思います。
以上、インターンレポートを終わります。最後までお読みいただきありがとうございました。