
はじめに
こんにちは、東北大学大学院 情報科学研究科 修士1年の清水怜央です。
この度6週間の就業型インターンシップとしてAI Dev室ASPチームに所属し、タイトルにもあるような自然言語で話者性を操作できる音声合成モデルについての研究に取り組みました。
本記事では、その研究活動の内容について報告します。
音声と制御文の例
はじめに本研究で行なったことを簡単に知ってもらうために、提案法のモデルで合成した音声と話者性を制御するための文の例を示します。
制御文:「The speaker identity can be described as low-pitched, calm, slightly dark, very mature, cool, masculine.」
訳:「話者性は低い音高で、落ち着いた、やや暗い、とても渋い、かっこいい、男性的と表現できます。」
制御文:「The speaker identity can be described as slightly refreshing, weak, slightly clear, slightly relaxed, very young, very feminine, fluent, very cute.」
訳:「話者性は少し爽やか、細い、やや澄んだ、やや張りのない、とても若い、とても女性的な、流暢な、とても可愛いと表現できます。」
このように本研究では上のような話者性を説明する文章によって制御可能な音声合成を実現しています。
背景・目的
音声合成は文章から音声を生成する技術で、近年の音声合成システムによる合成音の品質は人間の音声と比較しても遜色ないレベルにまで達しています。
このように音声の品質に関しては高いレベルに達していますが、音声の「話者性」(音声が誰のものであるかを特定する特性)や「発話スタイル」(話す速度や音高など)の制御・操作については、未だ課題が残っています。
従来の制御可能な音声合成では、あらかじめ用意された話者を選択し、音高、話速のパラメータを数値的に操作することで音声の制御を行うことが一般的です。
このような音声合成モデルは高い制御性を実現できる一方で、制御の自由度については高くありません。
そのため、その自由度の問題に対処するために近年の生成モデルのような、制御を行うための自然言語による"プロンプト"を入力することで発話スタイルを制御するような音声合成モデルが発表されています [1-3]。
例えばPromptTTS [1]では、性別、音高、話速、ボリュームといった発話スタイルについて操作するプロンプト使って学習させることで、自然言語による発話スタイルの操作を可能にしています。
プロンプトの例としては「May I ask a man to say at a low volume at a normal tone and a lower speed of sound?」(訳:普通のトーンで、音の速度を少し下げて、男性に静かに話すように頼むことはできますか?)のように性別、ボリューム、音高、話速に関する情報が入ったプロンプトになっています。
このようにプロンプトによる発話スタイルの制御が提案されている一方で、話者性の制御については未だ課題として残っています。
実際、先のPromptTTSではほとんど性別でしか話者性を制御する術がなく、他のPromptStyle [2]やInstructTTS [3]でも話者IDの依存性から学習データにない未知話者の合成については課題が残っています。
そこで本研究では特に自然言語による話者性の制御に着目し、プロンプトによる入力で話者性と発話スタイルを制御できるような音声合成モデルの構築を目的としています。
手法
今回はPromptTTS[1]のモデル、使用されていたデータセットをベースにして改善を行いました。
以下ではその改善内容について説明していきます。
データセットの改善・作成
はじめはPromptTTSの著者らが公開しているデータセットであるPromptSpeechを用いてモデルの構築を行おうとしていました。
このデータセットはLibriTTS [4]と呼ばれるデータセットの一部(38.14 hours / 585 hours)に対して発話スタイルのプロンプト(以下スタイルプロンプト)を付与したデータセットになっています。
しかし、スタイルプロンプトの内訳を調べてみると、全26588発話のうちユニークなプロンプトが154個しか存在せず、ほとんど同じようなプロンプトが用いられていたことが判明しました。
また、プロンプトのミスも存在しており、パラメータとプロンプトに乖離があるものや、文法的におかしいプロンプトもありました。
例えば、男性話者に対して女性のプロンプトがつけられていたり、ところどころ「mehis」や「voicewomen」のように単語が繋がったままのもの、「A male bass said slowly and loudly.」(訳:男性の低音がゆっくりと大きな声で話しました。)のようになんとなく意味はわかりますが、文章としては不適なものが挙げられます。
このように少ない種類のプロンプトで学習を行うと確かに操作の忠実性は向上するかもしれませんが、目的であった自由度の高い操作性の実現は難しいと考えられます。
また、話者性の制御については、スタイルプロンプトを用いるだけでは実質性別でしか実現できないことが予想されます。
そこで、今回は話者性を操作するプロンプト(話者プロンプト)と発話スタイルを操作するプロンプト(スタイルプロンプト)を新たに生成することで、話者性と発話スタイルの制御を実現する多様なプロンプトによる学習を可能にしています。
スタイルプロンプト(Style Prompt)
スタイルプロンプトは本来PromptSpeechにも存在していたような音高や話速、ボリュームに関するプロンプトになります。
今回はLibriTTSの全データを使いたかったため、まずデータ全体から音高、話速、ボリュームに関する値を計算し、それぞれ値に応じて(low/normal/high)のように3段階の値を割り振りました。
この時、性別ごとにlow、highの基準が異なることが考えられます。
特にその傾向が顕著な音高について、各発話のlogスケールの基本周波数を性別ごとにプロットした図を以下に示します。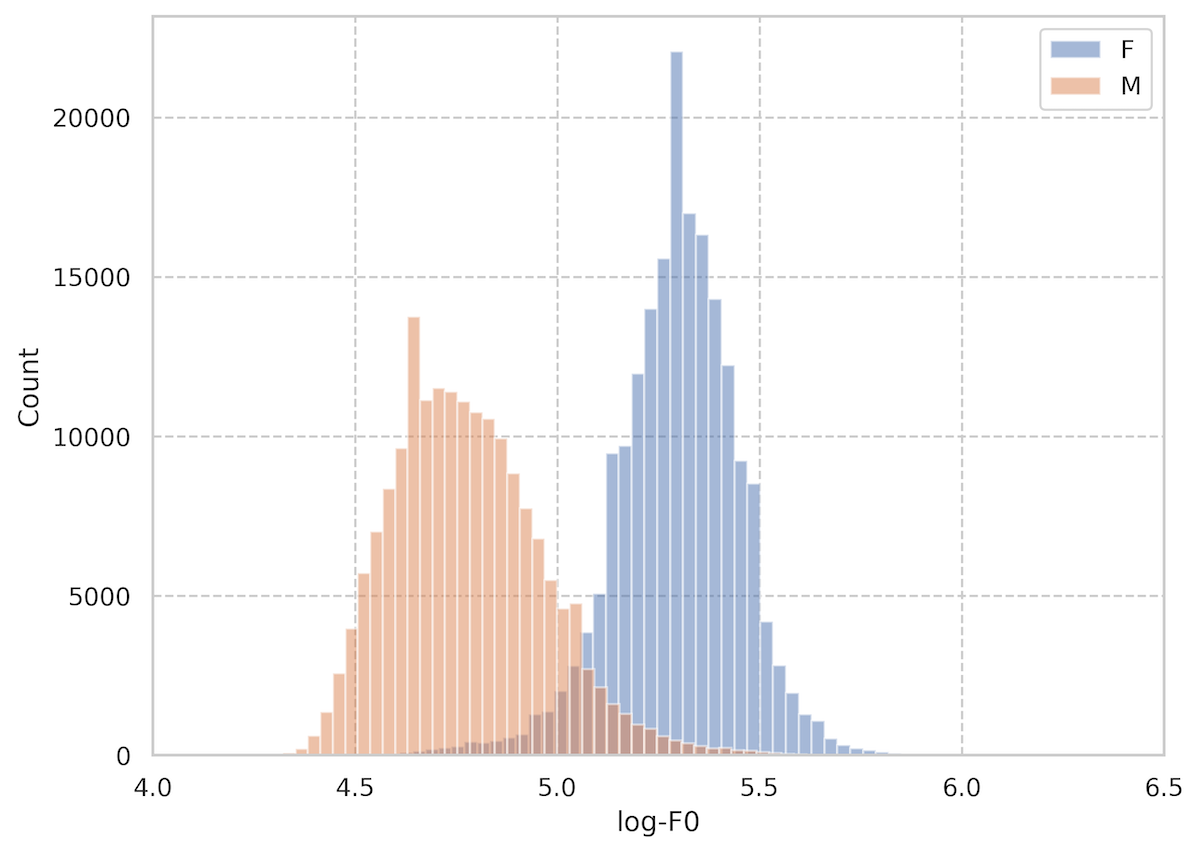
図より男性("M")と女性("F")のピークは異なっていることがわかります。
このように性別ごとに分布が違うことがあるため、それぞれ性別ごとに(low/normal/high)を分布の左側から(25%/50%/25%)というように割り振ることで値に基づいた割り当てを行っています。
その後、それらの値を使って大規模言語モデル(vicuna-13b)によりスタイルプロンプトの生成を行いました。
手順としては以下のようになります。
- 性別2種 x 音高3種 x 話速3種 x ボリューム3種の各値の組み合わせに対して、それぞれユニークなスタイルプロンプトを元のデータセットから抽出します。
- このとき、おかしなプロンプトを削除・修正し、ユニークプロンプトが少ない場合は手作業で追加します。
- その後各プロンプトに対して大規模言語モデルを使って5通りに増やします。
- ここで、増やしたプロンプトを目で確認し、明らかな嘘を含むプロンプトを削除します。
- 5通りなのは、10通りや100通りとしてしまうと言語モデルが嘘をつきやすくなってしまい、人手での確認が大変になってしまうためです。
- ここで、嘘というのは本来はlow pitchなのにnormal pitchになっていたりと元の文章から意味が変わってしまっているものを指します。
データ拡張の例として大規模言語モデルへの入力とその出力例を示します。
Input: ask a man to speak in low pitch, normal speed and normal energy
1. Ask a man to speak in a low pitch, normal speed, and normal energy
2. Request a man to speak with a low pitch, normal speed, and normal energy
3. Instruct a man to speak in a low pitch, normal speed, and normal energy
4. Tell a man to speak with a low pitch, normal speed, and normal energy
5. Command a man to speak in a low pitch, normal speed, and normal energyこのように同じ意味でも若干言い回しが異なるような文章を生成しています。
以上のように大規模言語モデルによってプロンプトのデータ拡張を行うことでスタイルプロンプトの多様性向上を図っています。
他の例に関しても「ask a female to speak with high pitch, fast talking and normal volume」(訳:女性に高い音程で、早口で、通常の音量で話すように頼む)のように性別、音高、話速、ボリュームに関する記述になっています。
話者プロンプト(Speaker Prompt)
話者プロンプトは元々PromptSpeechには存在していなかったプロンプトになります。
そのため、新たにデータに対して付与しないとならないわけですが、話者性の表現は自動生成が非常に難しく、人手でアノテーションを行わなくてはなりません。
ここで、スタイルプロンプトでは発話単位でプロンプトをつけていましたが、話者性は同じ話者の発話間で共通であるという考えのもと、話者ごとにアノテーションすることにしました。
方法としては、話者ごとに5つの音声を聞き、あらかじめ用意された話者を表現する知覚語と印象語 [5,6]を複数選択する形でアノテーションを行いました。
知覚語は性別、年齢、声の太さ、声の明るさなど計25種類、印象語はかわいい、かっこいい、優しいなど12種類が該当します。
また、それぞれの項目には「やや若い」や「かなり可愛い」といった強弱もつけられるようになっています。
話者ごととはいえ、LibriTTSには2456人もの話者が存在するため、他の方の協力を得たとしても限られたインターン期間で全話者に対するアノテーションを行うのは難しく、アノテーションできた404人の話者に関するデータを使いました(協力していただいた皆様ありがとうございました)。
プロンプトの例としては「The voice characteristics can be described as feminine, cute, soft.」(女性、かわいい、柔らかい)のように単語をカンマ区切りにして文章にした形をとっています。
このように生成した2種類のプロンプトを結合することで、話者性と発話スタイルを操作するプロンプトとしています。
モデルの改善
ベースとしているPromptTTSのモデルは発話内容(ContentPrompt)とスタイルプロンプトの2種類のプロンプトを入力することで以下のようなモデルで音声合成を行います。

スタイルプロンプトはBERT [7]に入力され、その出力を性別、音高等の各種パラメータに対する補助分類機でfine-tuneすることで、スタイルの埋め込みベクトル(図中赤いStyle)がそれらの情報を持つように誘導します。
ここで得られた埋め込みベクトルをContentEncoder、SpeechDecoderに入力することで発話スタイルを考慮した音声の生成を可能にします。
このような方法でも言語情報を音響モデルに入力することはできますが、音高や話速、ボリュームなどの発話スタイルや話者性についての表現を言語情報だけから得ることは難しいと考えられます。
実際に入力されるスタイルプロンプトは音高、話速などでそれぞれ(low/normal/high)3段階での値が入力されることが予想され、また話者プロンプトに関しても言語情報だけでは抽象的な表現から得ることになります。
そこで、音声に関する表現は音声から直接得た方がリッチな表現が得られるという考えのもと、ReferenceEncoderとGlobalStyleTokens(以下GSTs) [8]というモジュールを導入し、言語情報からではなく音声から表現を得ることにしました。
ReferenceEncoderはPromptStyle [2]内でも用いられているモジュールになっていて、違いとしてはPromptStyleでは発話スタイルの操作に注目しているため、話者の情報をリークしないように話者分類器とGradientRversalLayer [9]を導入しています。
また、1つの話者プロンプトが複数の話者に対応することが考えられ、基本的にReferenceEncoderの出力の分布は広いことが予想されます。
このような多様な分布を捉えるために、PromptEncoder側にMixtureDensityNetwork(MDN)を導入しました。
では、今回の提案モデルのアーキテクチャを以下に示します。
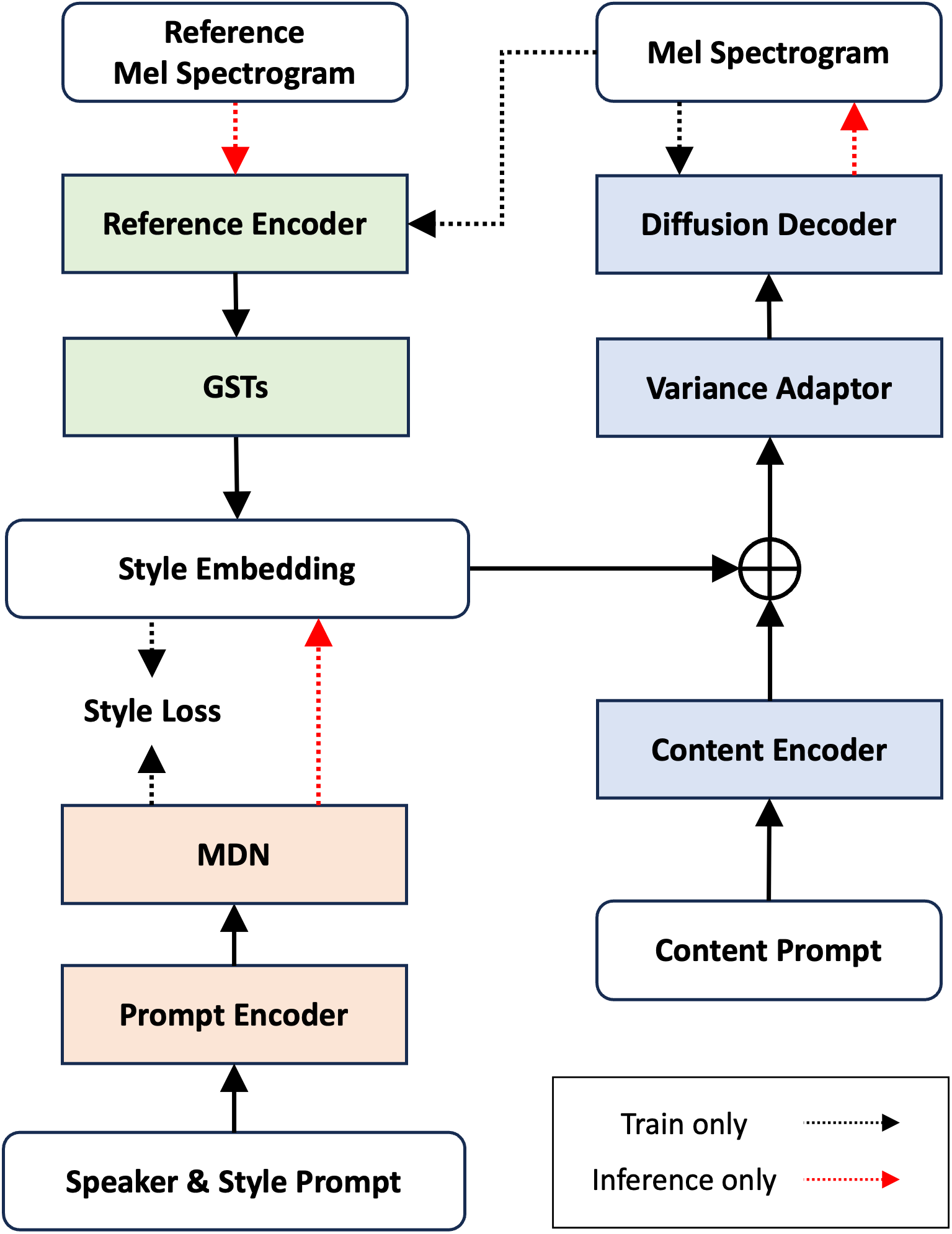
実線の矢印は訓練時、推論時どちらも通るデータフローを表しており、点線の矢印は色によってそれぞれ訓練、推論のデータフローを表しています。
訓練時にはデータのメルスペクトログラムをReferenceEncoder → GSTsに入力することでStyleEmbeddingを得ており、PromptEncoder → MDNにより得られる出力をそのStyleEmbeddingに近づけるように学習を行います。
一方、推論時には任意の音声のメルスペクトログラムをReferenceEncoderに入力しStyleEmbeddingを得るか、PromptEncoderによりプロンプトからStyleEmbeddingを得ることで、入力音声またはプロンプトのスタイルを考慮した音声の生成を可能にしています。
ここで、PromptTTSではSpeechDecoderとしてTransformerベースのモデルが使用されていましたが、出力されるメルスペクトログラムが平滑化して品質が悪くなる問題があったため、拡散モデル(Diffusion)ベースのデコーダに変更しました。
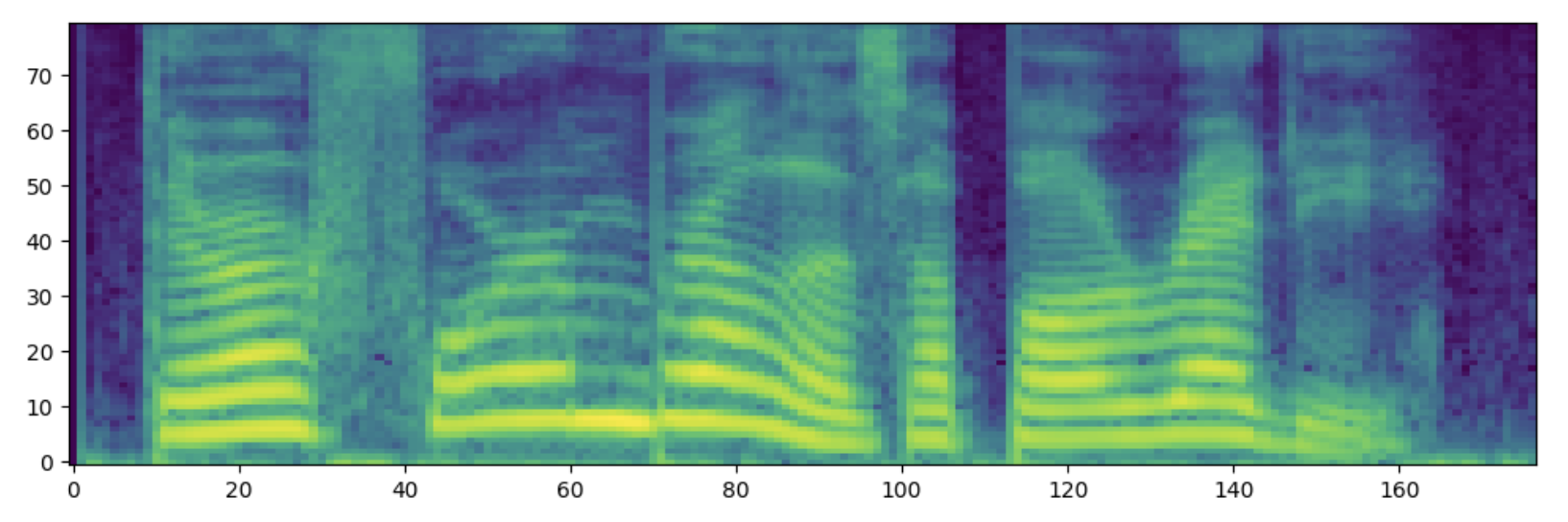
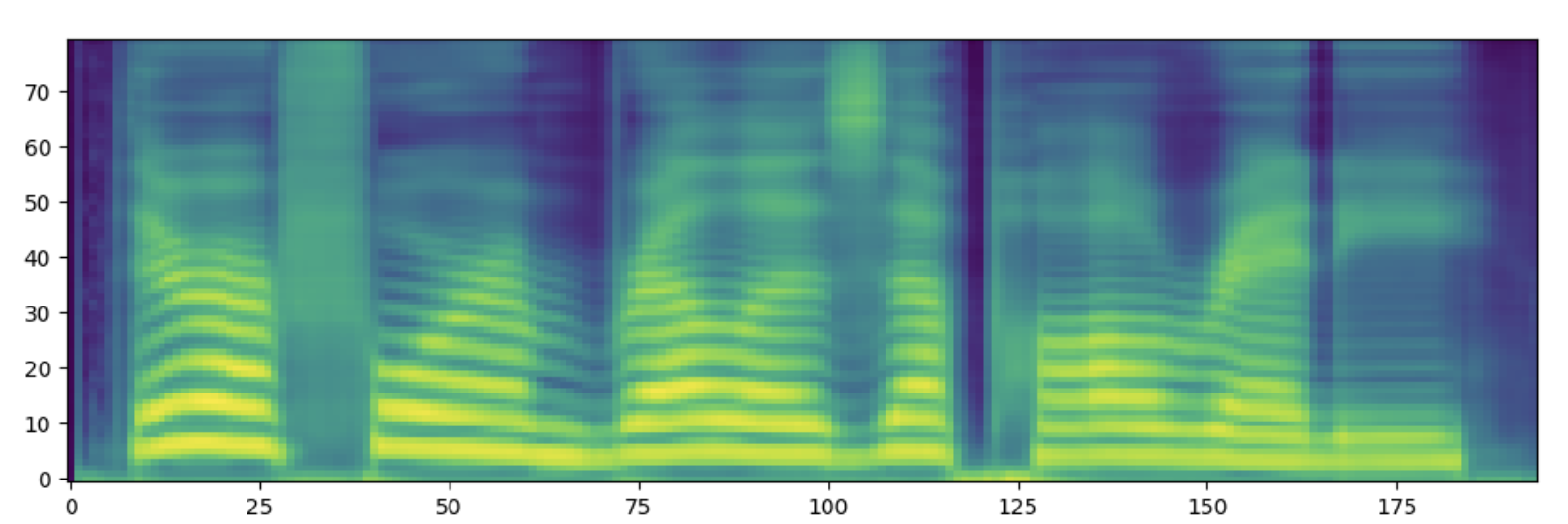
以下の表に示すようにTransformerによる出力に比べDiffusionによる出力の方が本物のメルスペクトログラムに近い結果が得られていることがわかります。
|
メルスペクトログラム
|
|
|---|---|
| 自然音声 |
|
| Transformerデコーダ |
|
| Diffusionデコーダ |
|
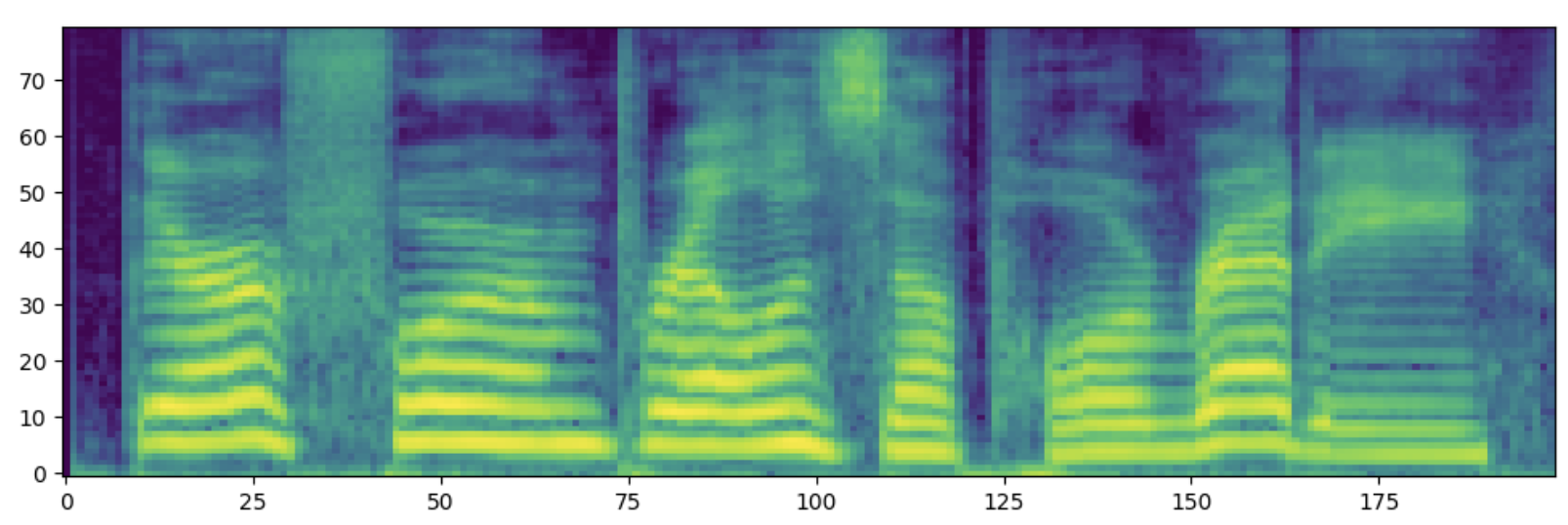
また、客観指標に関して以下の実験でも利用するUTMOS [8]で客観評価を行うと以下のような結果が得られました。
|
Transformerデコーダ
|
Diffusionデコーダ
|
|---|---|
| 3.601 | 4.122 |
このことから、デコーダについては明らかな有意差があると判断し、Diffusionによるデコーダを使用することにしました。
実験
比較対象
実験としては主に以下の4つの実験を比較する形で行いました。
- Baseline
ベースラインとしてはDecoderにConformerを使用し、"w/o MDN、話者プロンプト"の条件で学習 - 提案法
上の図のモデルと話者プロンプトありのデータセットで学習 - w/o MDN
話者の多様な分布を捉えるために導入したMDNの有無による検証 - w/o 話者プロンプト
話者プロンプトが話者の制御に有効か検証 - w/o MDN, 話者プロンプト
ベースラインとしてMDN、話者プロンプトどちらも使用しない場合
導入したMDNの有効性と話者プロンプトによる話者性制御を確かめるための実験設計になっています。
実験条件
データセット:LibriTTS-R [10] + 話者プロンプト、スタイルプロンプト
LibriTTS-Rは従来のLibriTTSの品質を向上させたデータセットになっており、データの品質は合成サンプルの品質に直接的に関わる部分のため、通常のLibriTTSではなくLibriTTS-Rを使用しました。
ここで、学習に必要な音素アライメントについてはMontreal forced aligner(GitHubのリンク)の「english_us_arpa」というモデルを用いて抽出し、音素アライメントに失敗した発話については学習データから除くことにしています。
このようにして残ったデータにアノテーションした話者プロンプトと生成したスタイルプロンプトを付与したものが使用するデータになります。
"データセット改善・作成"のところで話者プロンプトは全ての話者について付与できていないことを述べました。
実際に全2454話者360506発話のうち404話者59252発話が話者プロンプトのアノテーション済みデータになります。
ここで、実験としては2種類のデータセットを使うことが考えられます。
- Full:全てのデータを使うことにして、話者プロンプトがない話者の発話についてはスタイルプロンプトのみ用いることにする
- Subset:話者プロンプトが付与された話者の発話のみ使うことにする
Fullの利点としては多くの話者の音声を用いるため、ReferenceEncoderの出力の分布が非常に多様なものになることが挙げられます。
一方で、SubsetではReferenceEncoderの出力分布とPromptEncoderの出力の分布を近づけやすく、効率的な学習ができることが挙げられます。
予備実験の結果Fullを用いた方が良い結果が得られたため、以下の実験ではFullを用いて実験を行うことにしました。
評価用のデータについては訓練データに含まない未知話者を用いることにして、事前に決めた10名の話者(男女5名ずつ)のデータを使用することにしました。
具体的な話者IDについては[121, 237, 260, 908, 1089, 1188, 1284, 1580, 1995, 2300]になります。
モデル
提案法ではモデルの改善のところの図で示したモデルを使用しており、w/o MDNでは図のMDNを無くしてPromptEncoderの出力とReferenceEncoderの出力をコサイン類似度で最適化します。
つまり、提案法とw/o MDNの差分としては、ReferenceEncoderの出力を混合ガウス分布でモデリングするか、出力のベクトル同士をそのままコサイン類似度で最適化するかの違いです。
ここで、ReferenceEncoderとPromptEncoderの出力はノルム1に正規化しています。
次に、各種モジュールのアーキテクチャについては以下の通りです。
- ContentEncoder:4層のConformer [11]
- VarianceAdaptor:MDNを用いたDurationPredictor、PitchPredictor(EnergyPredictorはなし)で構成され、各PredictorのレイヤーはFastSpeech 2 [12]と同じ構造
- DiffusionDecoder:DiffSinger [13]と同じ構造をもつDDPM
- ReferenceEncoder:GlobalStyleTokens [8]と同様の畳み込み+GRUで構成されるEncoderとStyleTokens
- PromptEncoder:学習済みのBERTと3層の全結合層
なお、メルスペクトログラムから音声波形に変換するVocoderについてはF0特徴量も入力とするBigVGAN [15]をLibriTTS-R全体で学習したものを使用します。
評価方法
定量的な評価としては、StyleEmbeddingのプロット、話者類似度、単語誤り率、UTMOS [8]で測ります。
- StyleEmbeddingのプロット:学習データについてReferenceEncoderの出力の分布をPromptEncoderが捉えられているかをt-SNEを用いて2次元空間で可視化します。
- 話者類似度:WavLM [16]を用いて評価データの自然音声から得られる話者ベクトルと合成音声から得られる話者ベクトルとのコサイン類似度を測ります。話者ベクトルとしては、各話者ごとの発話に対してそれぞれ話者ベクトルを取得し、それを平均することで話者ごとにベクトルを取得します。
- 単語誤り率:Whisper [17](large-v2)を用いて合成音声から文字起こしをし、SCTK(GitHubのリンク)のscliteというツールを用いることで計算します。これにより、音声のintelligibility(発音の通じやすさ)を測ることができます。
- UTMOS:SpeechMOSというライブラリを利用することで合成音声のUTMOS評価を計算します。この評価では合成音声の自然性を測ることを目的としています。
実験結果
StyleEmbeddingのプロット
評価方法で述べたようにReferenceEncoderとPromptEncoderの分布の違いをt-SNEを用いて可視化します。
Baselineについては、Decoderの構造以外一番右の"w/o MDN, 話者プロンプト"と同じため、省略しています。
PromptEncoderへの入力としては話者プロンプト、スタイルプロンプトを結合したものを入力としています。
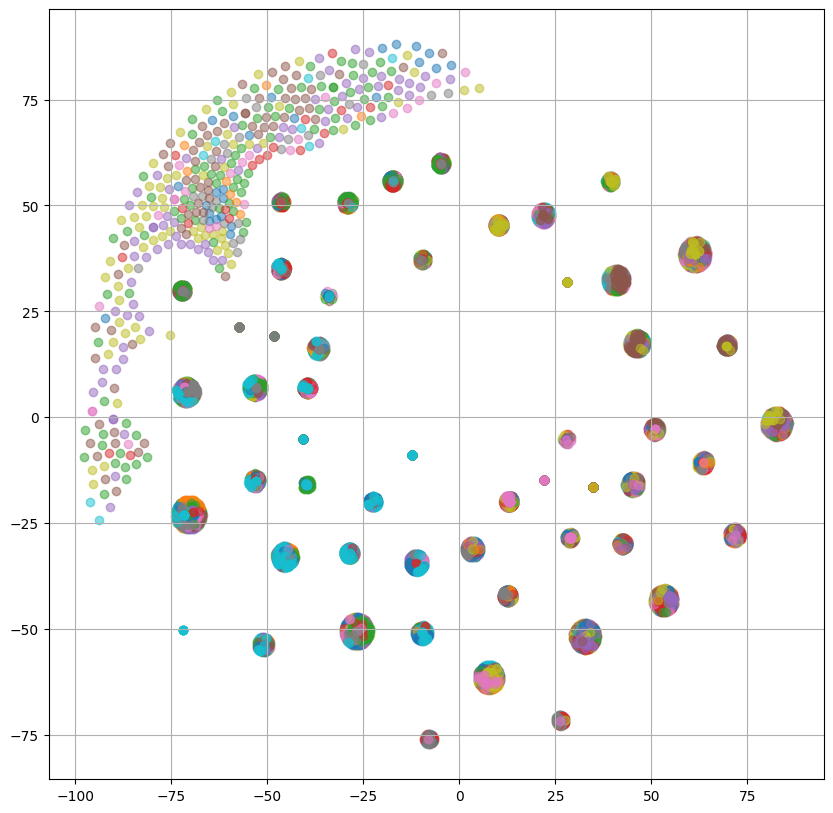
はじめに、訓練データに対するReferenceEncoderの出力(ref : 赤)とPromptEncoderの出力(prompt : 青)の各手法ごとのプロットを示します。
|
Proposed
|
w/o MDN
|
w/o 話者プロンプト
|
w/o MDN, 話者プロンプト
|
|---|---|---|---|
|
|
|
|
|
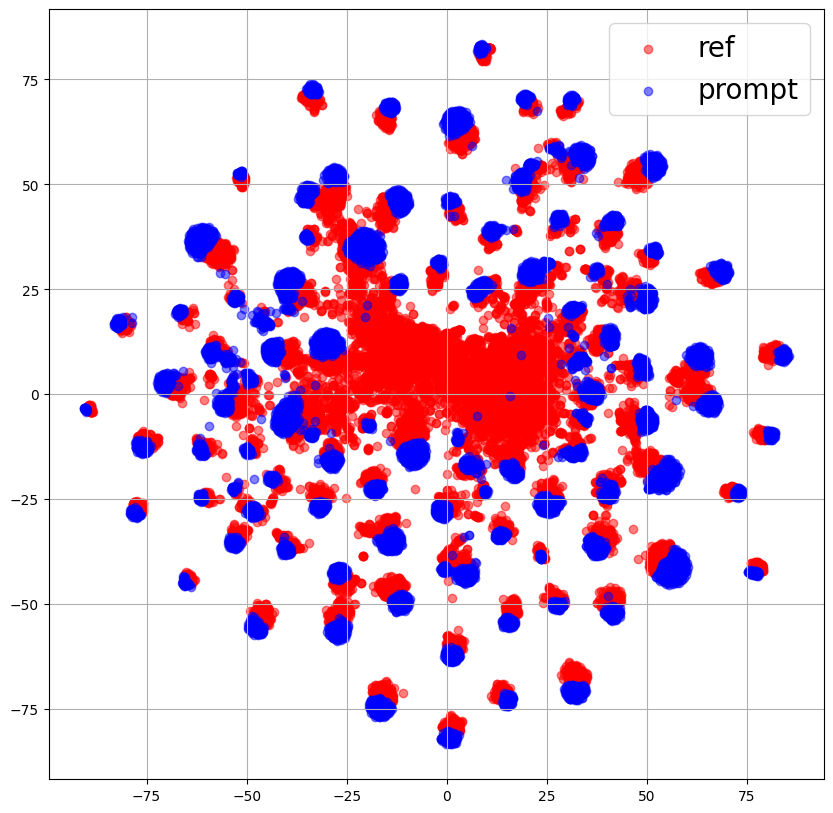
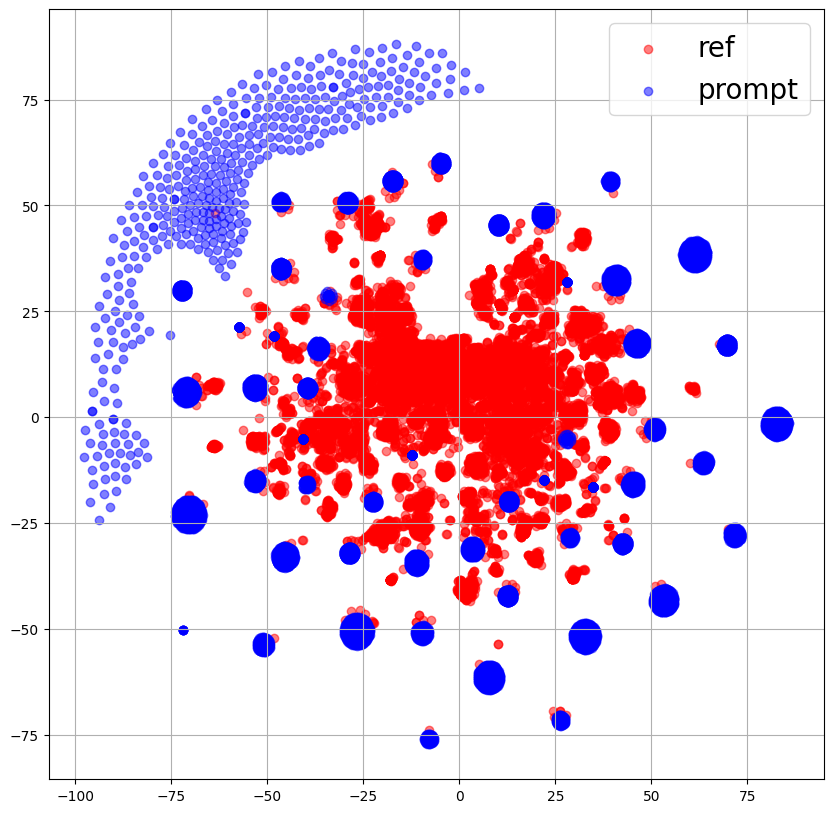
図より、左2つの話者プロンプトを使用して学習したモデルでは若干カバーできていない部分はあるものの、小さいクラスタについてカバーできていることがわかります。
特にMDNを使用しているProposedではクラスタを分布として捉えられているように見えます。
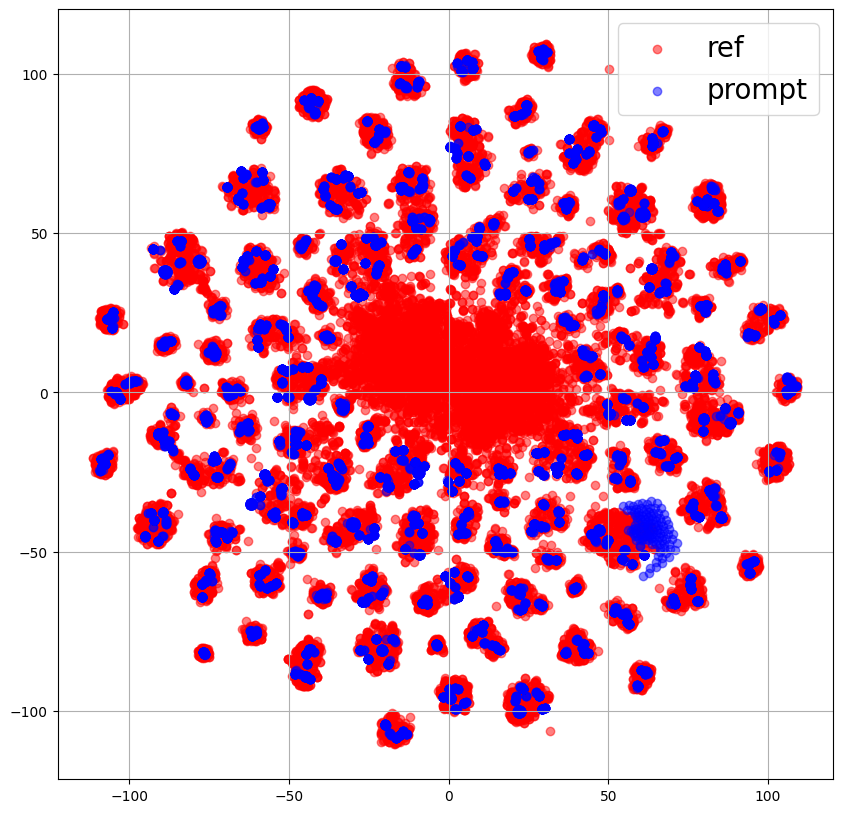
次に、w/o 話者プロンプトでは、一見重なりが大きいようにも見えますが、重なっていそうな部分はこれから示す図からも分かるようにReferenceEncoderの出力が少ない部分になっており、左2つの分布と比べると重なりは小さくなっています。
また、一番右の"w/o MDN、話者プロンプト"では、ほとんど重なっている部分が見られません。
これより、話者プロンプトを使用することでPromptEncoderはReferenceEncoderの分布をより良く表現することができると考えられます。
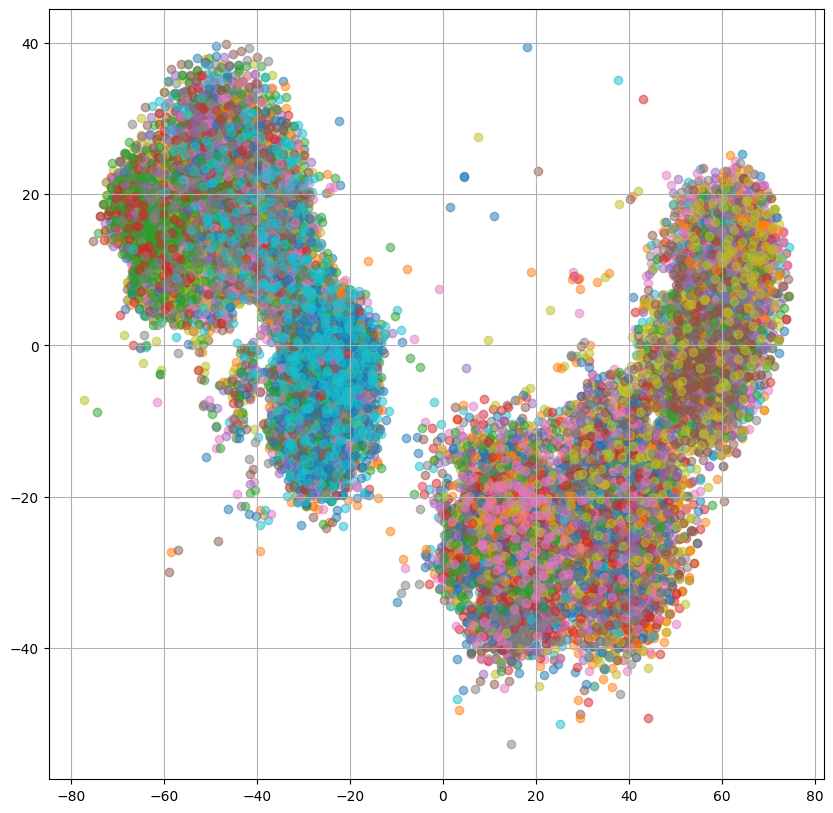
左2つの話者プロンプトを使用した場合のプロットでは複数の小さなクラスタが形成されていますが、何のクラスタなのか確認するために、話者IDごとに色分けした出力をReference Encoder、PromptEncoderそれぞれについてプロットしてみます。
|
Proposed
|
w/o MDN
|
w/o 話者プロンプト
|
w/o MDN, 話者プロンプト
|
|
|---|---|---|---|---|
| ReferenceEncoder |
|
|
|
|
| PromptEncoder |
|
|
 |
|
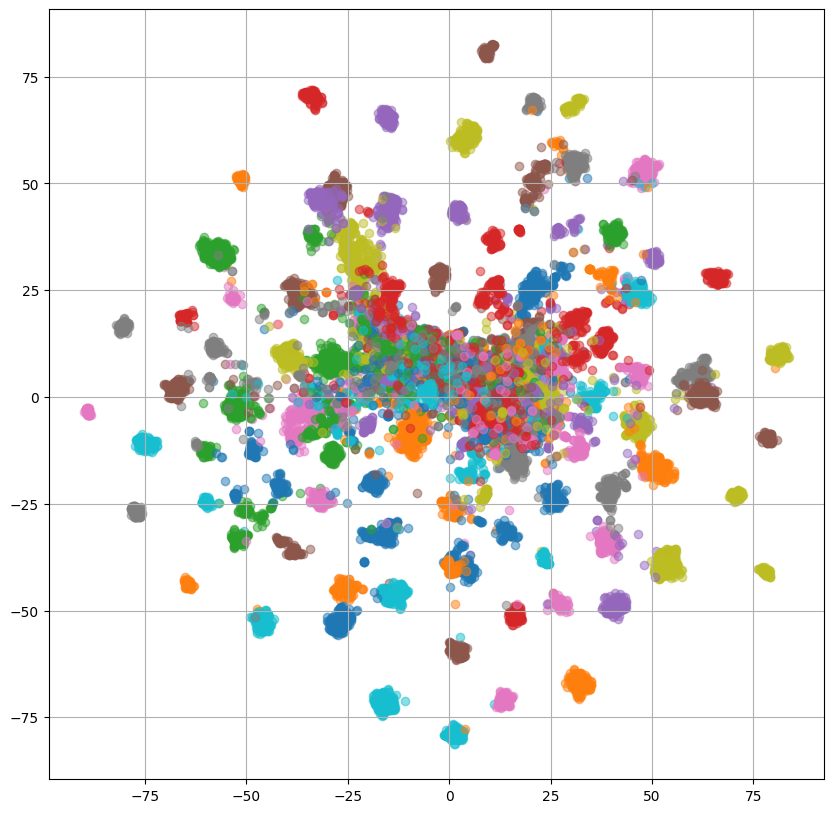
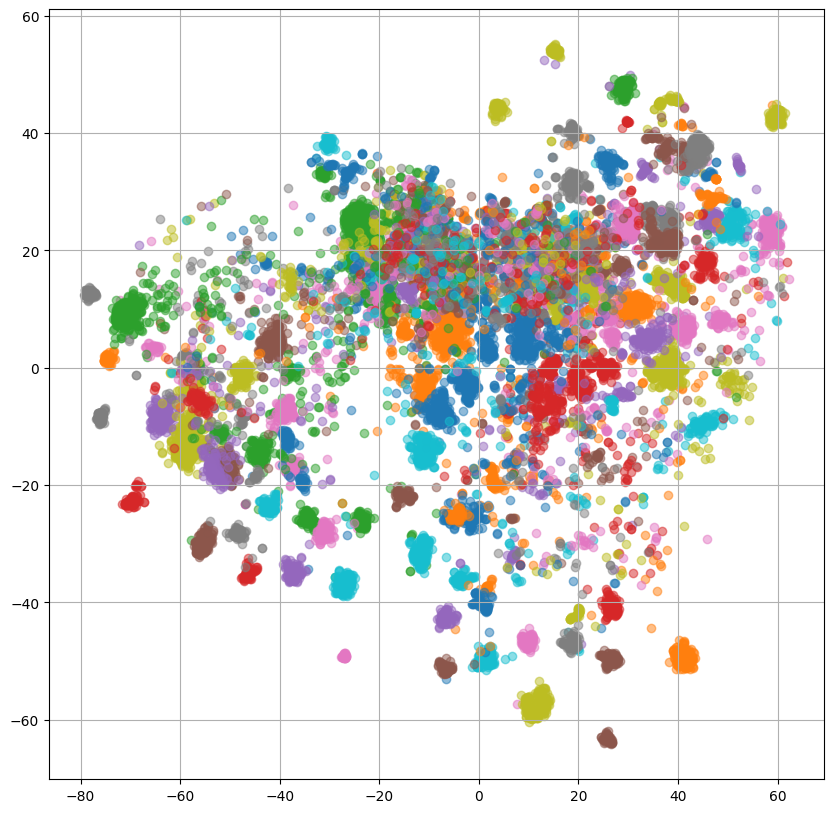
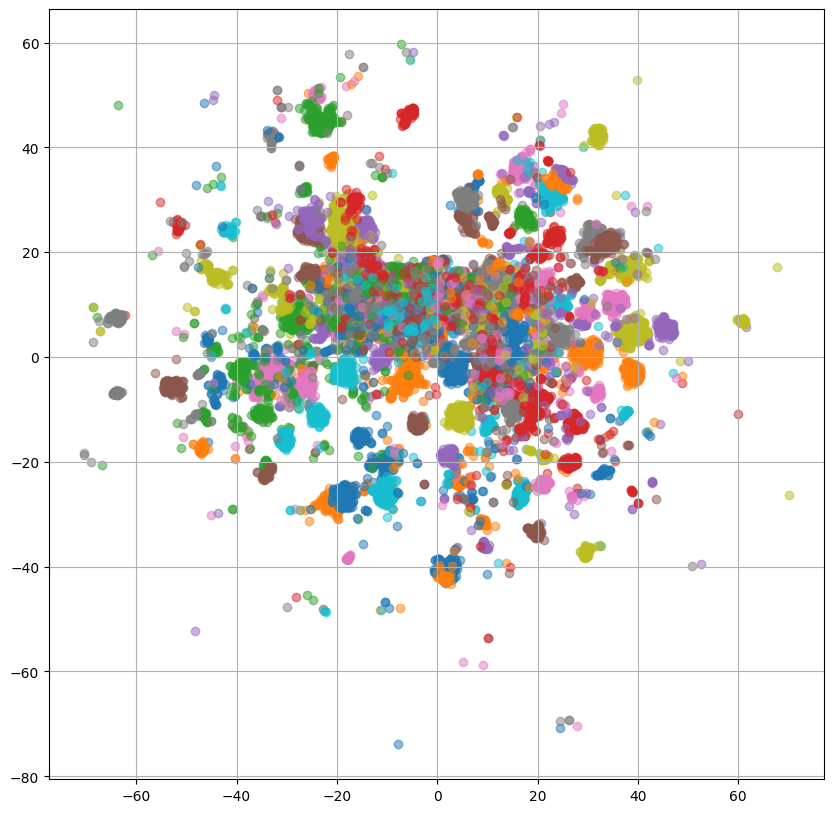
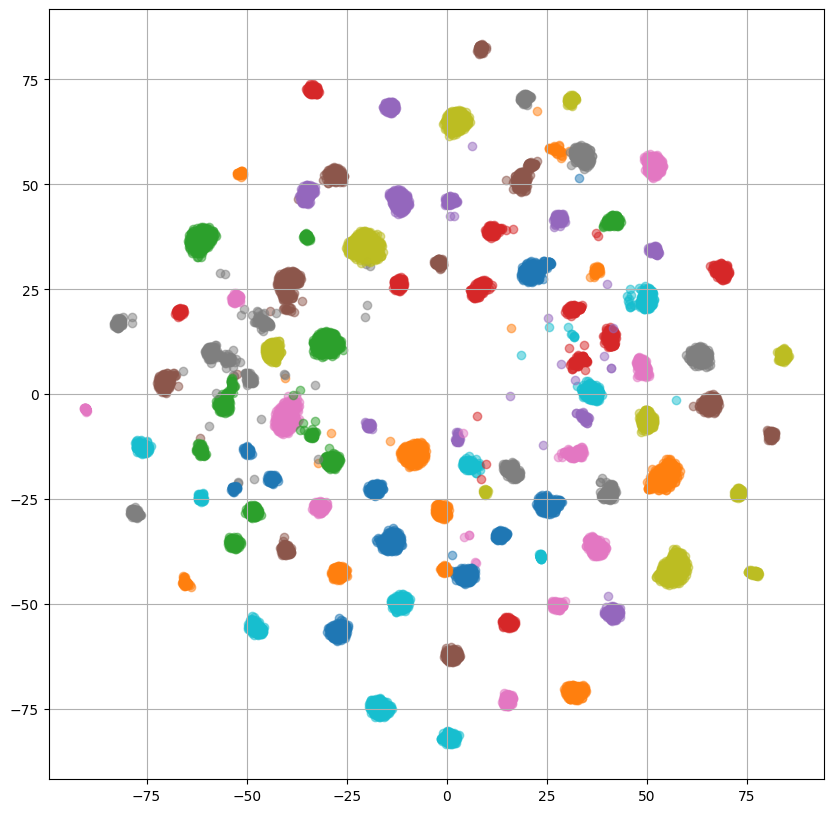
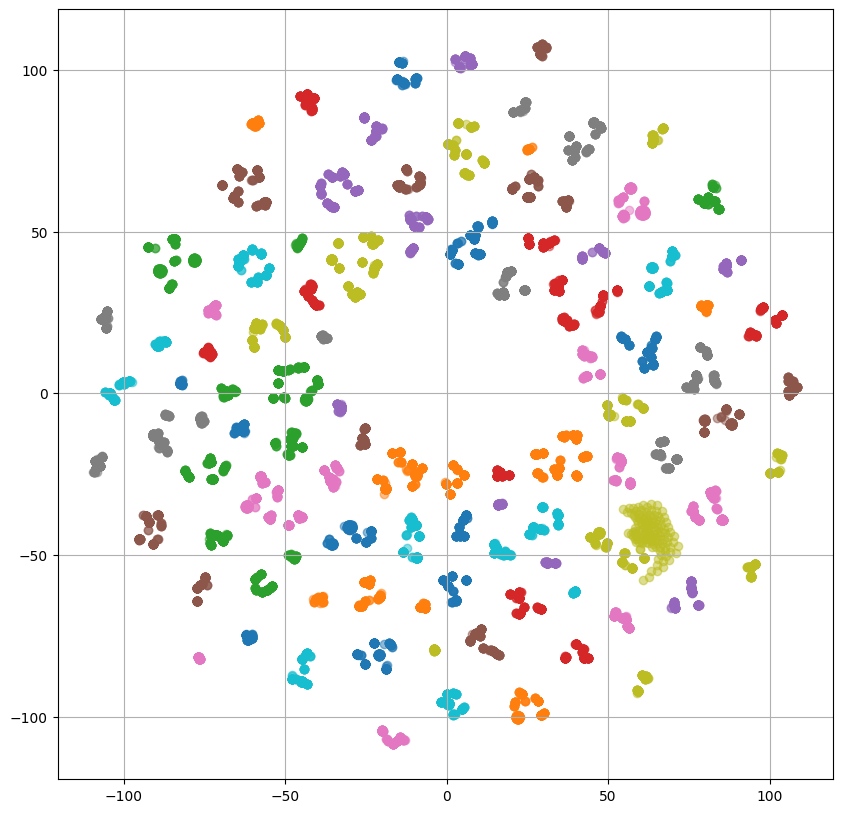
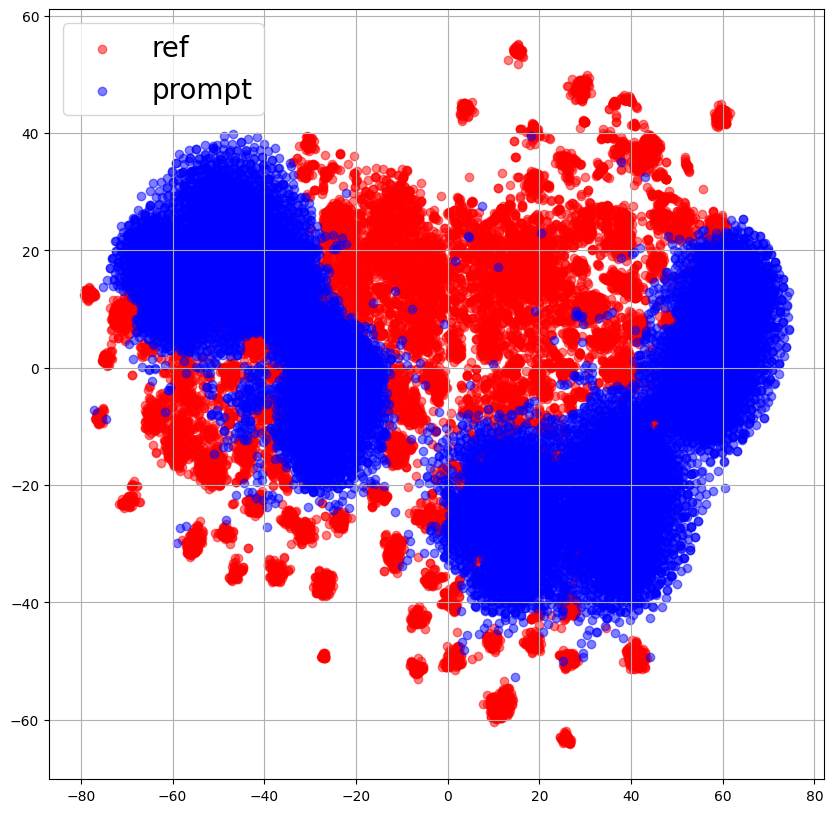
ReferenceEncoderのプロットを見ると、重なっている部分はあるものの大体話者ごとにクラスタを形成しているように見えます。
ここで、PromptEncoderについて左2つのプロットでは話者ごとににクラスタを形成しており、ReferenceEncoderとPromptEncoderの出力は重なっていたことから、PromptEncoderはReferenceEncoderの出力と話者プロンプトの関係を捉えられていると解釈することができます。
話者類似度
訓練データにない未知話者(評価データ)に対して話者類似度を測ります。
WavLM(Huggingfaceのリンク)を用いてデータの音声から得られた話者ベクトルと、ReferenceEncoder、PromptEncoderそれぞれから得られるStyleEmbeddingを用いて合成した音声から得られる話者ベクトルとのコサイン類似度を測ることで話者類似度を計算します。
その結果を以下の表に示します。
|
コサイン類似度
|
Baseline
|
Proposed
|
w/o MDN
|
w/o 話者プロンプト
|
w/o MDN, 話者プロンプト
|
|---|---|---|---|---|---|
| ReferenceEncoder | 0.957 |
0.977 |
0.974 |
0.981 |
0.977 |
| PromptEncoder | 0.892 |
0.922 |
0.916 |
0.897 |
0.906 |
表よりReferenceEncoderのStyleEmbeddingは手法に限らず、未知話者であっても音声の話者性を捉えることができており、高いコサイン類似度になっていることがわかります。
PromptEncoderの結果では、提案法であるProposedの結果が一番高いコサイン類似度になっており話者プロンプトとMDNにより、他の手法に比べて話者性をより良く表現できていると考えられます。
単語誤り率
訓練データにない未知話者(評価データ)の発話に対して単語誤り率(Word Error Rate: WER)を測ることでintelligibilityを評価します。
音声認識を行うWhisperの推論方法についてはFasterWhisper(GitHubのリンク)を用いて推論を行い、scliteで単語誤り率を計算しました。
各手法に対する結果を以下の表に示します。自然音声については手法間で変化がないため1つだけ示しています。
|
WER[%]
|
Baseline
|
Proposed
|
w/o MDN
|
w/o 話者プロンプト
|
w/o MDN, 話者プロンプト
|
|---|---|---|---|---|---|
| 自然音声 |
2.8 |
- |
- | - | - |
| ReferenceEncoder |
3.2 |
3.7 |
3.7 |
3.7 |
3.7 |
| PromptEncoder |
3.1 |
4.0 |
4.2 |
3.7 |
3.5 |
結果より、単語誤り率についてはBaselineが低い値を取っていることがわかります。
これは、話者性に関してコサイン類似度が低いことから発話の多様性がないことが考えられ、その多様性の低さがIntelligibilityに寄与していると考えられます。
これは"w/o MDN, 話者プロンプト"についても同じことが言え、StyleEmbeddingのプロットや話者類似度の結果から、StyleEmbeddingの多様性のなさが逆にIntelligibilityに寄与していると言えます。
UTMOS
訓練データにない未知話者(評価データ)の発話に対してUTMOSを測ることで音声の自然性を評価します。
SpeechMOSというライブラリを用いて各発話ごとにUTMOSを測り、その平均値を以下の表に示しています。
自然音声については手法間で変化がないため1つだけ示しています。
|
UTMOS
|
Baseline
|
Proposed
|
w/o MDN
|
w/o 話者プロンプト
|
w/o MDN, 話者プロンプト
|
|---|---|---|---|---|---|
| 自然音声 | 4.219 | - | - | - | - |
| ReferenceEncoder |
3.436 |
4.05 |
4.036 |
4.099 |
4.059 |
| PromptEncoder |
3.601 |
4.074 |
3.95 |
4.131 |
4.122 |
w/o MDNを除いて、ReferenceEncoderよりもPromptEncoderのUTMOSの方が高い結果が得られていることがわかります。
これはReferenceEncoderには全て異なる未知のメルスペクトログラムが入力されるためStyleEmbeddingの値がメルスペクトログラムに影響されるのに対して、PromptEncoderの入力は言語情報でありStyleEmbedding自体の大きな変化はないため、安定した生成ができていると考えられます。
PromptEncoderの中では話者プロンプトを使用しない右2つの結果の方が自然性の高い結果になっています。
これは、未知話者生成において、右2つはStyleEmbeddingの変化が小さいために、話者類似度は小さいが自然性の高い合成ができていると考えられます。
音声結果
ここでは音声結果として、話者プロンプトと各手法の音声を載せることにします。
掲載しているプロンプトについて、本研究では話者性に着目しているため話者プロンプトのみ載せていますが、入力としては話者プロンプト、スタイルプロンプトの両方を入力しています。
訓練データ
プロンプト:「The speaker identity can be described as slightly refreshing, weak, slightly clear, slightly relaxed, very young, very feminine, fluent, very cute.」
訳:「話者性は少し爽やか、細い、やや澄んだ、やや張りのない、とても若い、とても女性的な、流暢な、とても可愛いと表現できます。」
|
自然音声
|
Baseline
|
w/o MDN, 話者プロンプト
|
|---|---|---|
|
|
|
|
|
w/o 話者プロンプト
|
w/o MDN
|
Proposed
|
|---|---|---|
|
|
|
|
プロンプト:「The speaker identity can be described as low-pitched, calm, slightly middle-aged, slightly dark, adult-like, mature, cool, slightly intellectual, deep, masculine.」
訳:「話者性は低い、落ち着いた、やや中年の、やや暗い、大人っぽい、渋い、かっこいい、やや知的な、太い、男性的であると表現できます。」
|
自然音声
|
Baseline
|
w/o MDN, 話者プロンプト
|
|---|---|---|
|
|
|
|
|
w/o 話者プロンプト
|
w/o MDN
|
Proposed
|
|---|---|---|
|
|
|
|
訓練データの音声に関して、上の女性話者では明らかに右2つの"w/o MDN"、Proposedのモデルの音声が自然音声にも近い音声になっており、プロンプトにある"とても若い、とても可愛い"についても表現できているように感じます。
一方で、男性話者についてはどれも低い男性話者の音声になっており、上の音声ほどの差異は見られません。
これはプロンプトに該当するような男性話者は多いことが予想され、平均的な声でもそれっぽい音声になっていることにも起因するものと思われます。
評価データ
プロンプト:「The speaker identity can be described as low-pitched, feminine, slightly sexy, calm, adult-like, strong, intellectual, cool, slightly soft, young, slightly weak, sweet.」
訳:「話者性は低い、女性的な、ややセクシーな、落ち着いた、大人っぽい、張りのある、知的な、かっこいい、やや柔らかい、若い、やや弱々しい、甘いと表現できます。」
|
自然音声
|
Baseline
|
w/o MDN, 話者プロンプト
|
|---|---|---|
|
|
|
|
|
w/o 話者プロンプト
|
w/o MDN
|
Proposed
|
|---|---|---|
|
|
|
|
プロンプト:「The speaker identity can be described as low-pitched, wild, middle-aged, strong, mature, cool, deep, fluent, masculine, powerful, lively.」
訳:「話者性は低い、ワイルドな、中年の、張りのある、渋い、かっこいい、太い、流暢な、男性的な、迫力のある、生き生きしていると表現できます。」
|
自然音声
|
Baseline
|
w/o MDN, 話者プロンプト
|
|---|---|---|
|
|
|
|
|
w/o 話者プロンプト
|
w/o MDN
|
Proposed
|
|---|---|---|
|
|
|
評価データについて上の女性話者の音声では、"w/o 話者プロンプト"、"w/o MDN, 話者プロンプト"の音声でもそれっぽく感じる一方で、男性話者についてはProposed含む右2つの音声の方が流暢で生き生きした男性の音声が生成できています。
少ない音声サンプルしか載せていませんが、話者性についてはStyleEmbeddingの分布やコサイン類似度でも見たように話者プロンプトを使用した場合の方が多様な話者を生成できると考えられます。
上手くいかなかったこと
ReferenceEncoderの多様な分布を捉えるために、本研究ではMDNを用いることにしていますが、MDNに辿り着くまでにDiffusionやFlowによるモデリングを試していました。
方法としては、Diffusion/FlowにおいてPromptEncoderの出力を条件づけして、ガウスノイズからStyleEmbeddingを生成することを考えます。
初めの実験としては、Diffusion/Flow以外は学習済みのモデルを使用することにして、Diffusion/Flowのみ学習させることを行いました。
しかし、Diffusion/Flowを用いて生成したStyleEmbeddingは値のスケールがおかしくなっていたり、それを用いて合成した音声は発話内容すら聞き取れないほどのノイズになっていました。
合成したメルスペクトログラムも以下の図のようになっており、モデルのところで示したメルスペクトログラムと比べても、明らかにおかしくなっていることがわかります。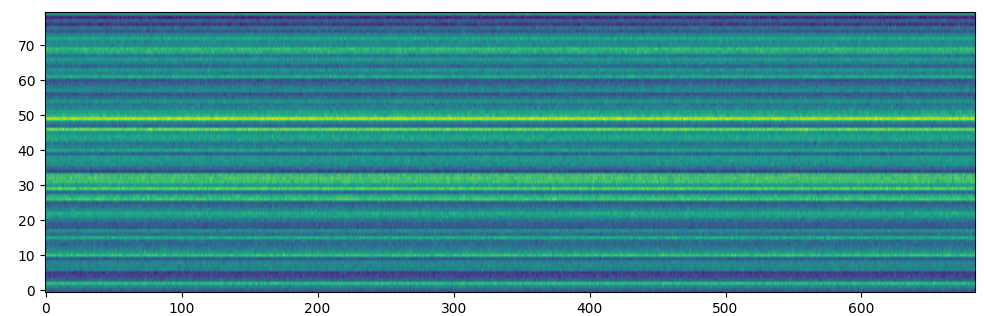
Diffusion/Flowそれ単体では非常に強力なモデルではありますが、今回のStyleEmbeddingの生成では上手くいかなかったため、実験的に上手くいったMDNを使用しています。
まとめと課題
本研究では主に音声の話者性を自然言語により制御することに着目し、データセットの作成から音声合成モデルの構築を行いました。
StyleEmbeddingのプロットの結果から、新たにアノテーションで作成した話者プロンプトを導入することで、話者性の分布を言語情報から捉えられることがわかりました。
実際音声サンプルを聞いても話者プロンプトに沿った音声が生成されており、そこに音高のプロンプトを付与しても(low/normal/high)に沿った音声が生成されていることを確認できています。
このように、話者性や音高については比較的うまくいっているものの、話速やボリュームの制御の正確性については未だ課題として残っています。
StyleEmbeddingのプロットを確認すると、話速やボリュームについては(low/normal/high)関係なく重なったような分布が得られているため、それらの関係性についてはうまく学習できていない可能性があり、スタイルプロンプトを再度確認する必要がありそうです。
感想
改めて今回のインターンシップでは「話者性を自然言語で制御可能な音声合成」というテーマで研究を行いました。
先行研究をベースにした実験から始まり、データセットの問題発見、その後新たにデータセットの作成からモデルの構築まで非常に密度の濃い6週間だったように思います。
また、音声の分野でトップレベルの企業で研究を行っている方々のもとで研究活動を行えたことはとても貴重な経験でした。
最後になりますが、ASPチームの皆様、人事の皆様、そして特に毎日のように議論していただいた山本さん、川村さんには大変お世話になりました。
メンターの山本さんには議論以外にもデータ周りの処理や実装・実験についてのアドバイスなど挙げたらきりがないほどサポートしていただき非常に助かりました。
色々と未熟な自分を最後まで手厚くサポートしていただき、毎日濃密でかつ楽しい時間を過ごすことができました。
6週間と短い間でしたが、本当にありがとうざいました。
メンター追記
本研究の内容をまとめた論文を音声・音響信号処理における世界最大の国際学会である ICASSP 2024 に投稿しました。
論文: https://arxiv.org/abs/2309.08140
デモサイト: https://reppy4620.github.io/demo.promptttspp/
本記事の内容とあわせてご覧ください。
参考文献
- Z. Guo, Y. Leng, Y. Wu, et al., “PromptTTS: Controllable text-to-speech with text descriptions,” in Proc. ICASSP, 2023.
- G. Liu, Y. Zhang, Y. Lei, et al., “PromptStyle: Controllable style transfer for text-to-speech with natural language descriptions,” arXiv preprint arXiv:2305.19522, 2023.
- D. Yang, S. Liu, R. Huang, et al., “InstructTTS: Modelling expressive tts in discrete latent space with natural language style prompt,” arXiv preprint arXiv:2301.13662, 2023.
- H. Zen, V. Dang, R. Clark, et al., “LibriTTS: A Corpus Derived from LibriSpeech for Text-to-Speech,” in Proc. Interspeech, 2019, pp. 1526–1530.
- 大谷 大和, 森 紘一郎 "話者の声の特徴を直感的な言葉で制御できる音声合成技術." 東芝レビュー 71, 2016, pp. 80-83.
- 木戸博, 粕谷英樹. "通常発話の声質に関連した日常表現語の抽出." 日本音響学会誌 55.6 , 1999, pp. 405-411.
- J. Devlin, M.-W. Chang, K. Lee, et al., “BERT: Pre-training of deep bidirectional transformers for language understanding,” in Proc. NAACL-HLT, 2019, pp. 4171–4186.
- W. Yuxuan, S. Daisy, et al. "Style Tokens: Unsupervised style modeling, control and transfer in end-to-end speech synthesis." International conference on machine learning. PMLR, 2018.
- Y. Ganin, E. Ustinova, H. Ajakan, et al., “Domain-adversarial training of neural networks,” J. Mach. Learn. Res., vol. 17, no. 1, pp. 2096–2030, 2016.
- Y. Koizumi, H. Zen, S. Karita, et al., “LibriTTS-R: A Restored Multi-Speaker Text-to-Speech Corpus,” in Proc. Interspeech, 2023, pp. 5496–5500.
- G. Anmol, Q. James, et al. "Conformer: Convolution-augmented transformer for speech recognition." arXiv preprint arXiv:2005.08100, 2020.
- R. Yi, H. Chenxu, et al. "Fastspeech 2: Fast and high-quality end-to-end text to speech." arXiv preprint arXiv:2006.04558, 2020.
- J. Liu, C. Li, Y. Ren, et al., “DiffSinger: Singing voice synthe- sis via shallow diffusion mechanism,” AAAI, vol. 36, no. 10, pp. 11 020–11 028, 2022.
- T. Saeki, D. Xin, W. Nakata, et al., “UTMOS: UTokyo- SaruLab System for VoiceMOS Challenge 2022,” in Proc. Interspeech, 2022, pp. 4521–4525.
- S. Chen, C. Wang, Z. Chen, et al., “WavLM: Large-scale self-supervised pre-training for full stack speech processing,” IEEE Journal of Selected Topics in Signal Processing, vol. 16, no. 6, pp. 1505–1518, 2022.
- A. Radford, J. W. Kim, T. Xu, et al., “Robust speech recognition via large-scale weak supervision,” in Proc. ICML, vol. 202, 2023, pp. 28 492–28 518.