
京都大学情報学研究科 修士1年の松田有登です.8月7日から9月15日の6週間、LINE DSC(データサイエンスセンター)のComputer Vision Lab (CVL) Virtual Human Lab (VHL)チームでインターンシップに参加させていただきました。今回私が取り組んだ手の動きを含めた動作生成についてご紹介します。
背景
動作生成モデルは、アクションラベルや言語、音楽などを入力したときに、それに対応した動作、行動を出力するモデルです。既存の動作生成モデルには、Variational Autoencoder (VAE)のEncoder、Decoderに正解ラベルを付与したConditional Variational Autoencoder (CVAE)を用いて、動作の種類を示すラベルによる条件付き動作生成を行なったACTOR[1]や、Diffusion modelベースでtext-to-motionやaction-to-motionなどのタスクをこなすMLD[2]などが挙げられます。しかし、いずれのモデルにおいても手の動き・動作は考慮されておらず、常に手が開いた初期状態のままで、手が現在どのようなポーズを取っているのかがわかりません。実際、既存の動作データセットには、手を開いた状態で何かを掴むなどの動作が含まれており、動作としては不自然です。より自然な人間の動作を生成する上で、手の動きはあるべきだと考え、今回手の動きを含めた動作生成に取り組みました。
関連研究
手の動きを含めた動作生成としては、DSAG[3]が挙げられます。DSAG[3]は図1のようなネットワーク構造をしています。人間のポーズを体の成分と、手の部分の成分に分解して、Encoderに入力し、潜在空間上での分布パラメータを獲得し、Decoderで、潜在空間から抽出した情報からポーズを生成します。このモデルも、ACTOR[1]と同様にCVAEを用いて、手を含めた動作の種類を示すラベルによる条件付きの動作生成を行なっています。このモデルでは、手のポーズと体のポーズを別々のEncoderに入力していますが、手の動きは単体でなく、体の動きと関連していているため、まとめて符号化した方が良いと考え、今回私は手のポーズと体のポーズをまとめてEncoderに入力して、手の動きを含めた動作生成を行いました。
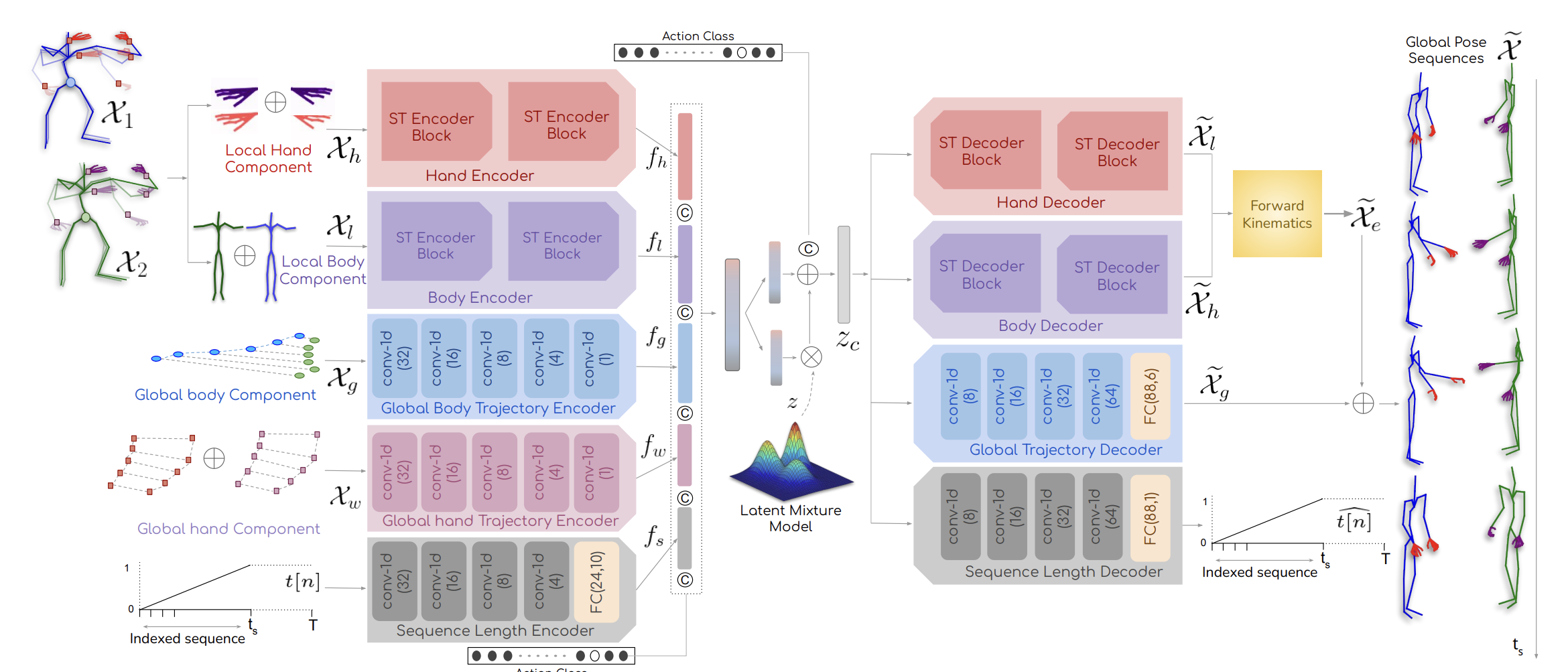
図1 DSAG[3]のネットワーク構造(参照:DSAG: A Scalable Deep Framework for Action-Conditioned Multi-Actor Full Body Motion Synthesis)
学習データ
手の動きも含めた既存の動作データセットは比較的少なく、体のポーズだけの動作データセットに適切な処理を施して新たな学習データセットを作成する必要があります。学習データとしては、HumanAct12[4]という12クラス(34サブクラス)の動作が含まれる1191シーン動作データセットを使用しました。HumanAct12[4]には、手の動きのデータが含まれないので、学習データに手の動きのデータを付加させる必要があります。今回は、2種類の学習データで手の動きを含めた動作生成を行いました。1つめは、すでに作成されていた、Expose[5]という手法を用いたHumanAct12-Xpose[3]という手の動き付きデータセットです。これは、Guptaら[3]によって作成され、DSAGの学習にも使用されたものであり、以下の図2に示すようなデータセットになります。
 |
 |
図2 HumanAct12-Xpose[3]のデータ例(左:Run、右:Drink)
2つめは、今回新たに作成した全身の動作データセットで、OSX[6]を用いて作成しました。OSX[6]は全身メッシュ復元を行う最新の手法です。以降、この学習データはHumanAct12-OSXposeと呼びます。HumanAct12-OSXposeの作成は、以下のように行いました。
- HumanAc12-OSXposeの作成
- HumanAct12[3]は3視点での撮影データが存在しますが、自身の体で、自身の体(手など)を遮蔽してしまうセルフオクルージョンを回避するため最も人を正面から写しているカメラの映像のみを使用します。
- HumanAct12に含まれる各動作データに対して、1で決めたカメラ視点の画像に対してOSX[6]を適用してSMPLX[7]におけるグローバル回転、体のポーズパラメータ、左手、右手のポーズパラメータを推定します。この際、HumanAct12[3]の元データとなるPHPSDatasetで定められた条件を満たす良いフレームのみに処理を行います。
- SMPLX[7]モデルを用いて、ポーズパラメータから関節点の座標を獲得します。
上記の手順で作成されたHumanAct12-OSXposeのデータを図3に示します。
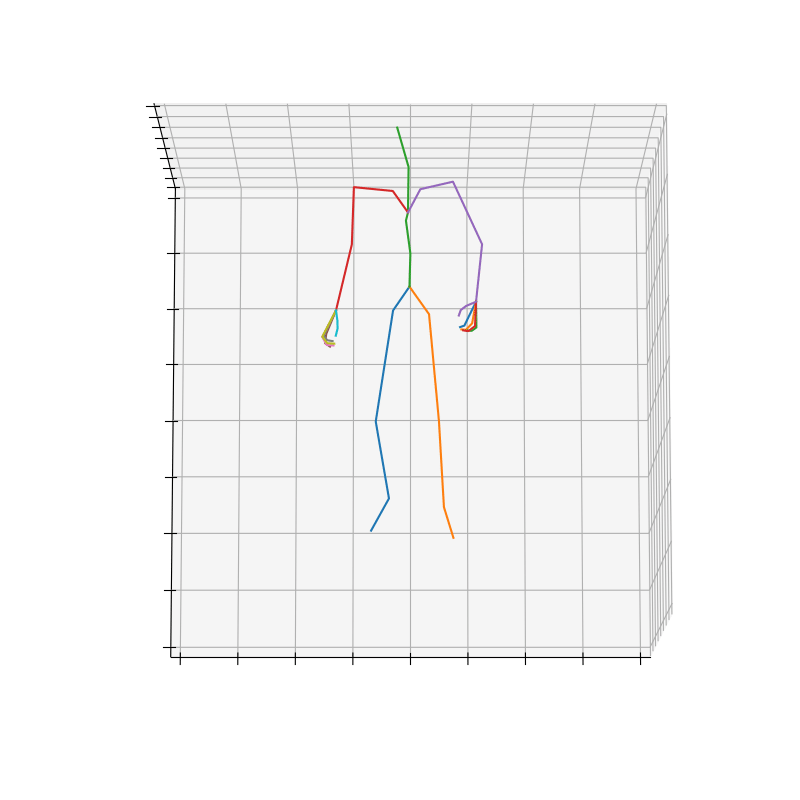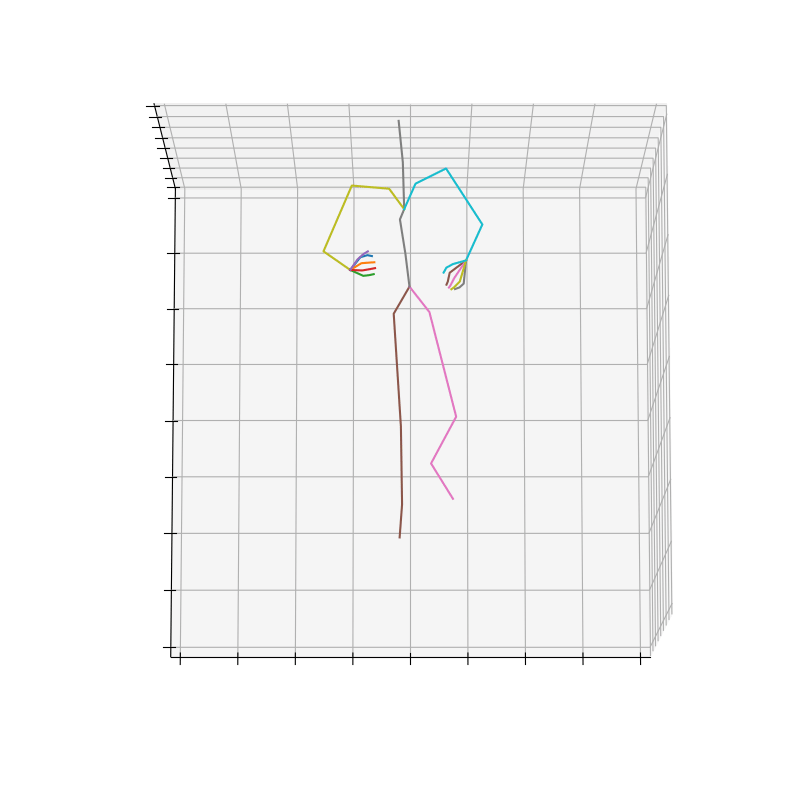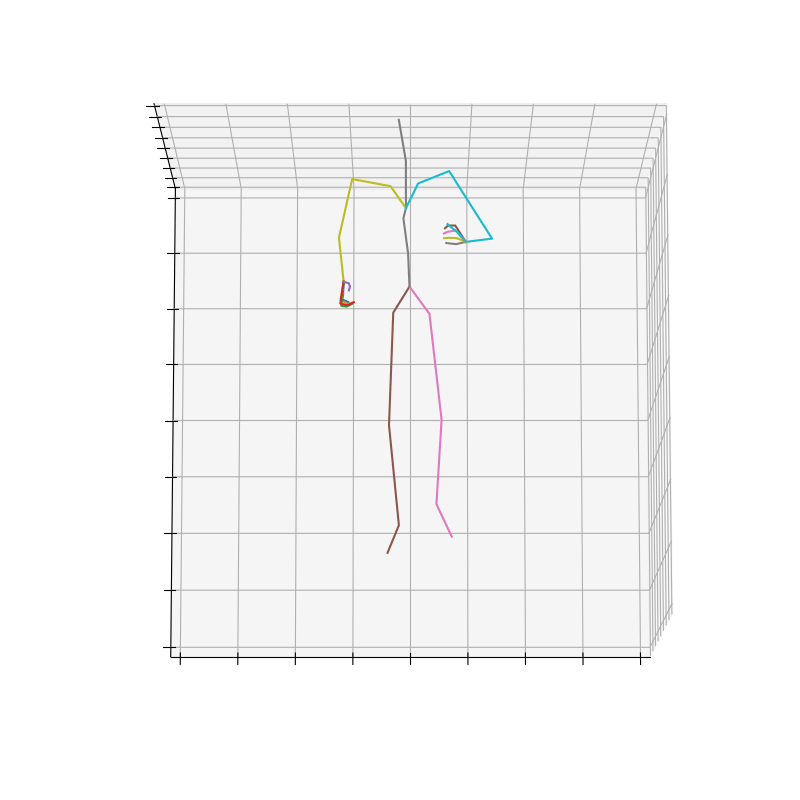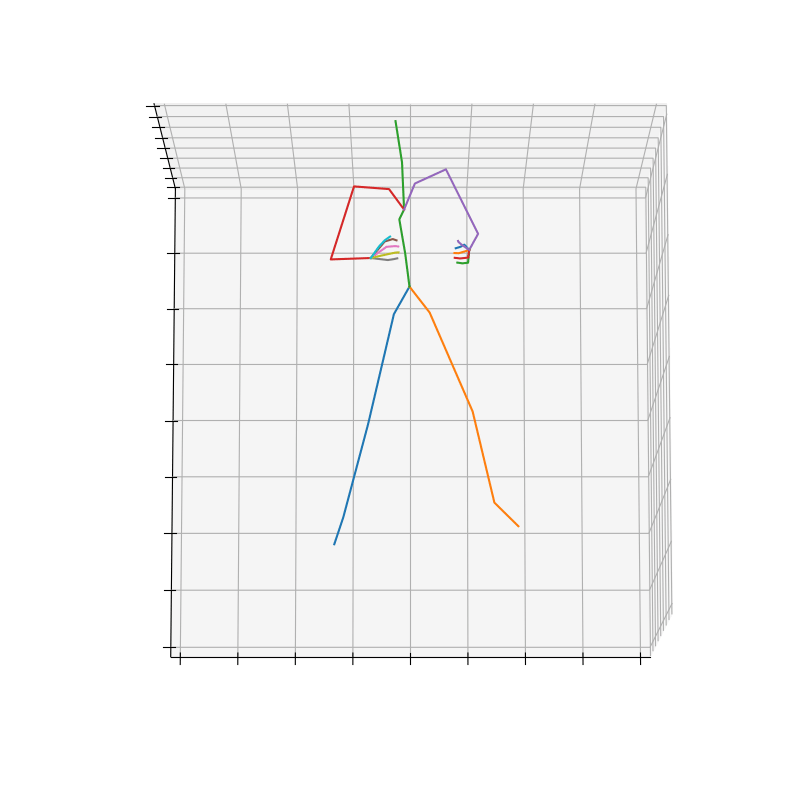 |
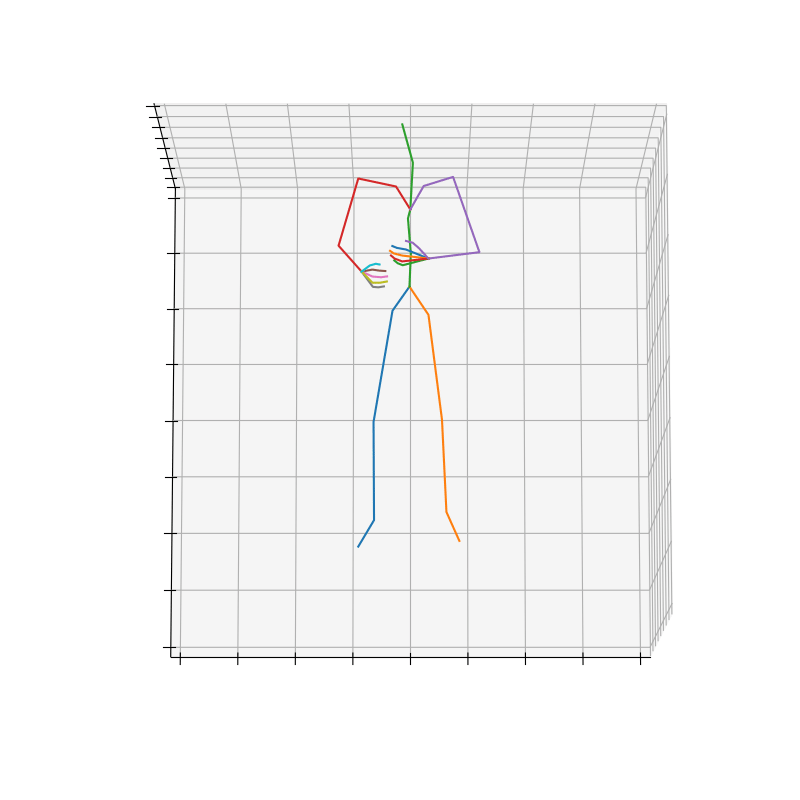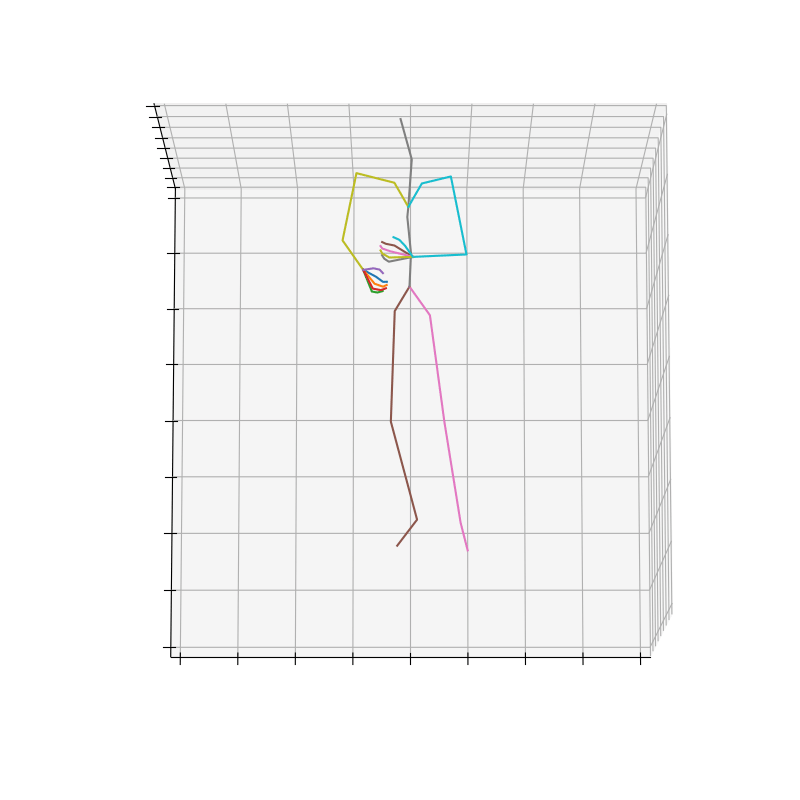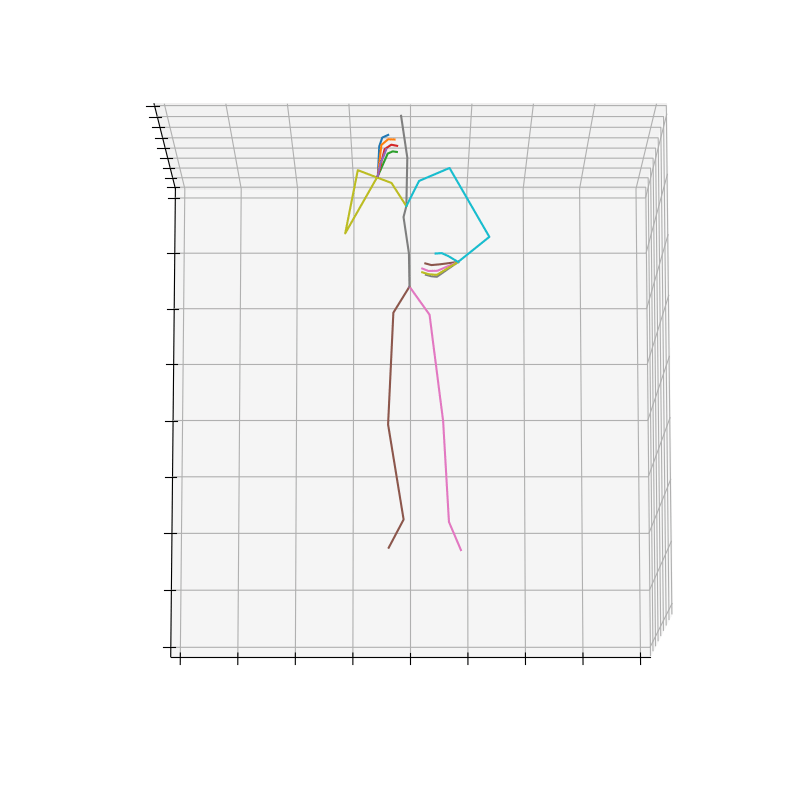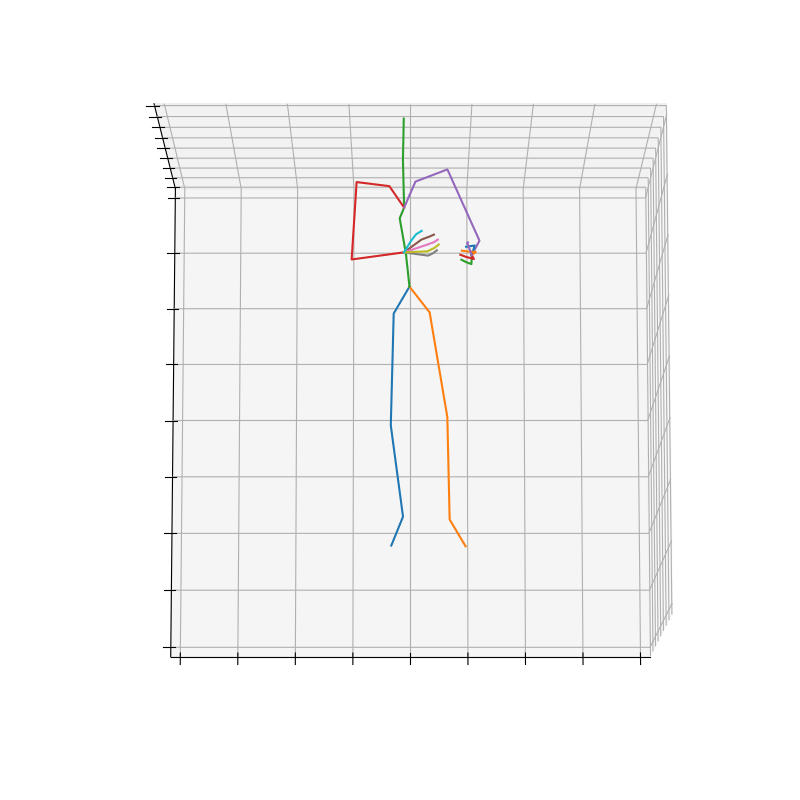 |
図3 HumanAct12-OSXposeのデータ例(左:Run、右Drink)
Runのラベルにおいて、HumanAct12-OSXposeの方がHumanAct12-Xposeに比べて、手首周りの回転が抑えられていそうです。これは、Expose[5]が体と手を別々に予測して、融合させているのに対し、OSX[6]は単一のEncoderとDecoderを使用してまとめることで、より正確に予測できていると考えられます。
動作生成モデル
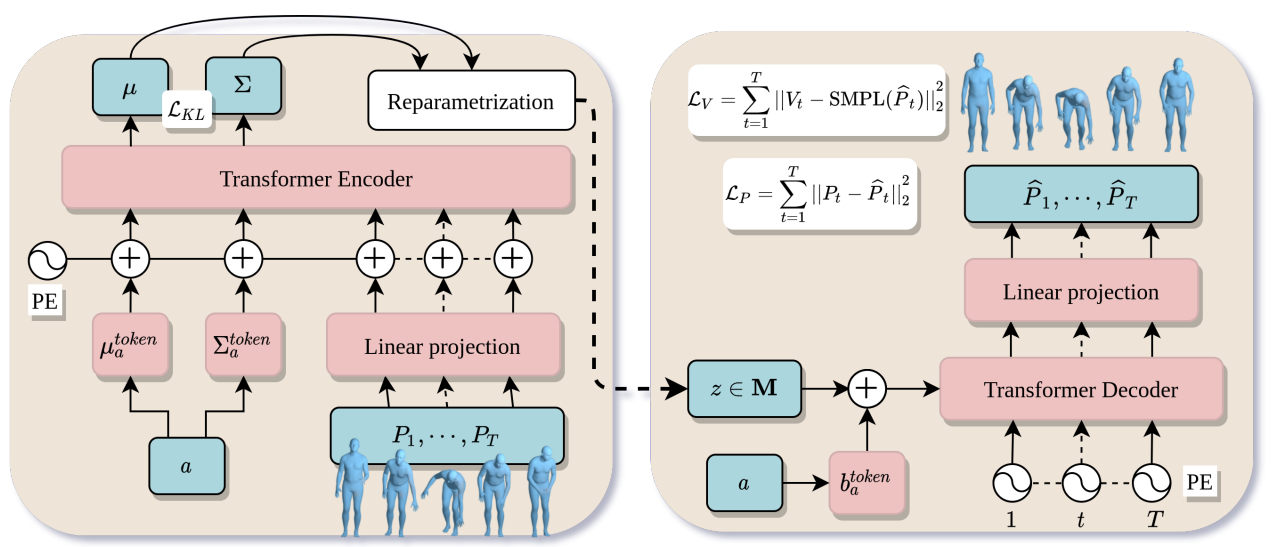
図4 ACTOR[1]のネットワーク構造(参照:Action-Conditioned 3D Human Motion Synthesis with Transformer VAE)
既存の動作生成モデルは、手のポーズは固定されているためネットワークを手のポーズも学習できるように拡張させる必要があります。今回は、動作の種類を示すラベルによる条件付き動作生成を行うモデルとして、ACTOR[1]のモデルをベースにして学習を行いました。図4にACTOR[1]のネットワーク構造を示します。ACTOR[1]は、CVAEとTransformerを組み合わせたモデルで、左側のEncoderで、動作ラベル、ポーズパラメータから各動作ラベルごとの潜在空間での分布パラメータを獲得し、右側のDecoderで、潜在空間から抽出された分布パラメータと動作ラベル、動作の継続時間からポーズパラメータを出力する構造となっています。損失関数としては、入力ポーズと出力ポーズのL2 loss、SMPLモデル[8]を使って関節点の頂点座標を求めた時の関節点のL2 loss、KL lossで学習されています。SMPLモデル[8]とは、人間の姿勢及び形状をパラメータとして表現したモデルです。ACTOR[1]ではSMPLモデル[8]が用いられているので、手の動きを含めた生成を行うために、SMPLモデル[8]を手のパラメータを含んだ人体モデルであるSMPLH[9]モデルに拡張して学習を行いました。
結果
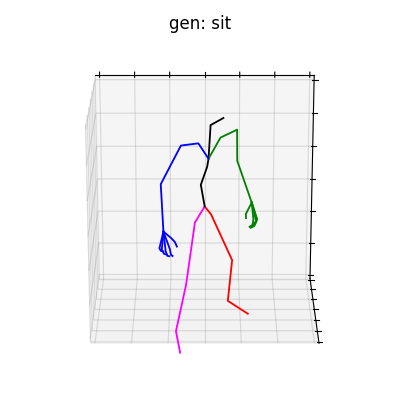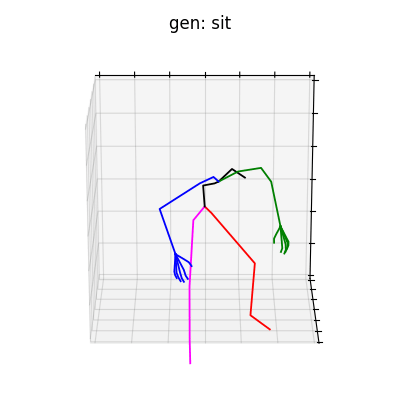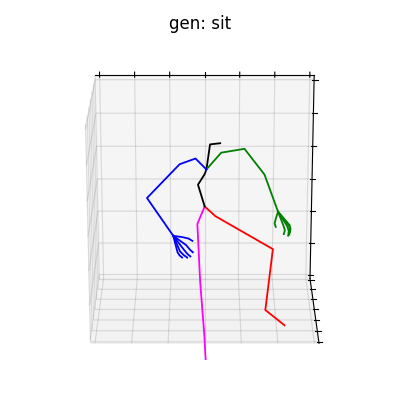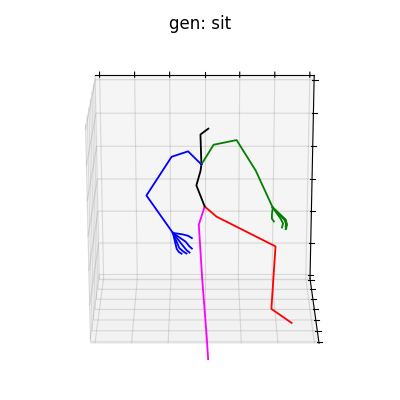
HumanAct12-Xposeを用いて学習を行なった結果を図5に、HumanAct12-OSXposeを用いて学習を行なった結果を図6に示します。
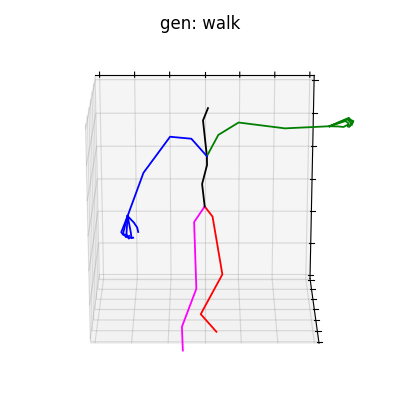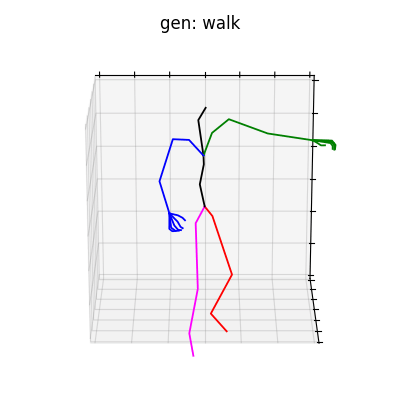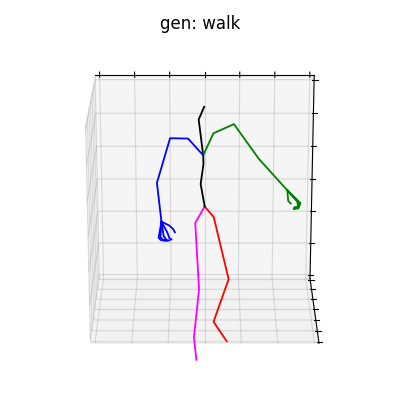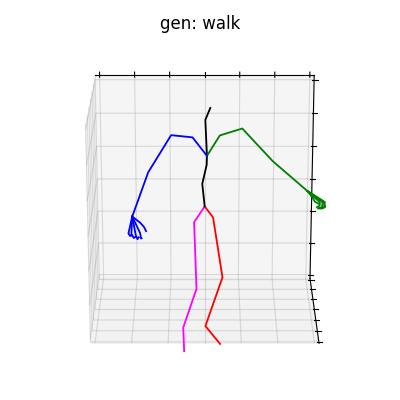 |
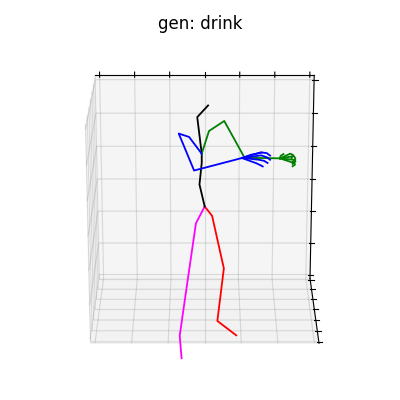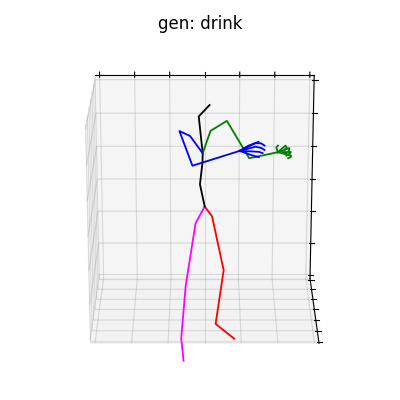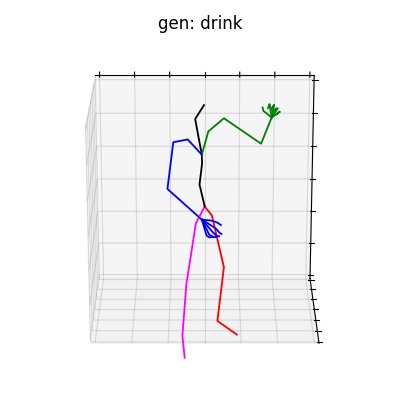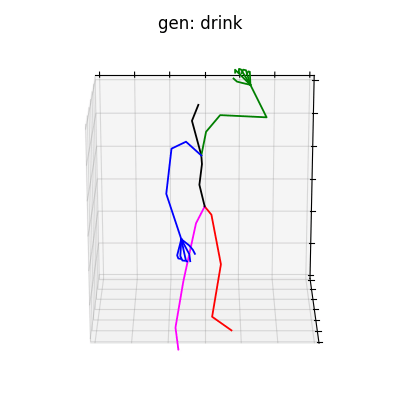 |
 |
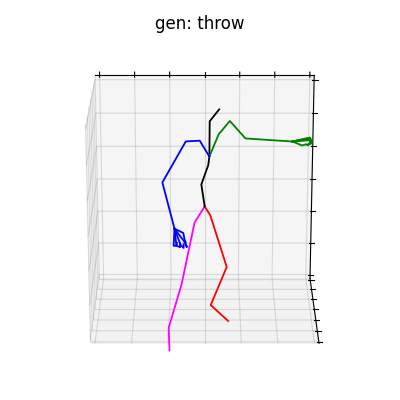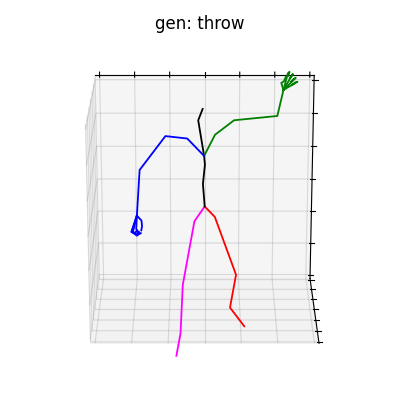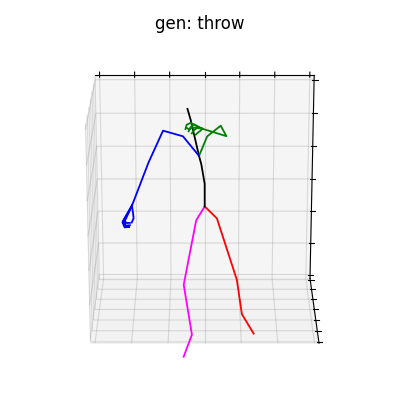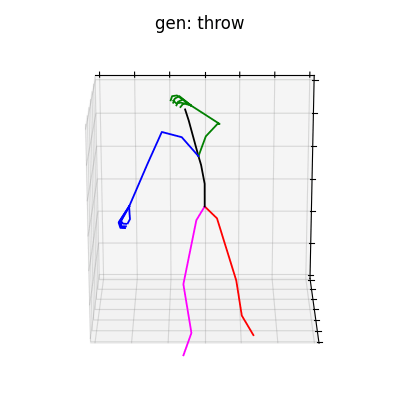 |
図5 HumanAct12-Xposeを学習データとして用いた時の生成結果
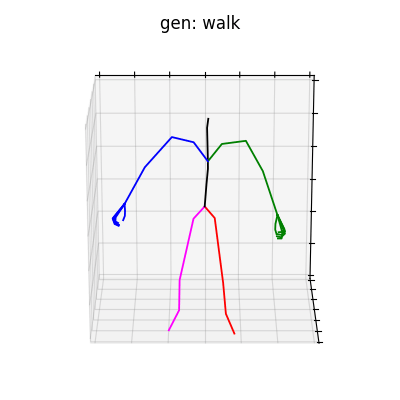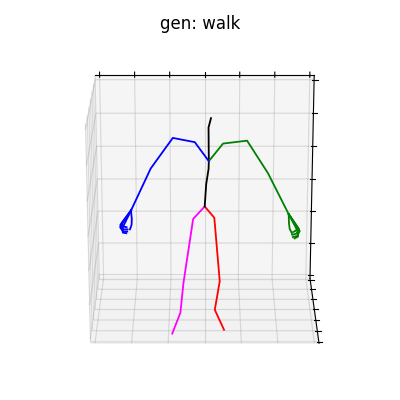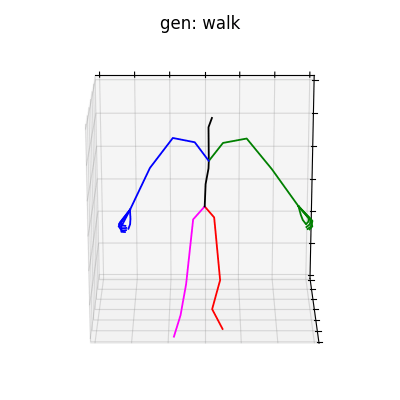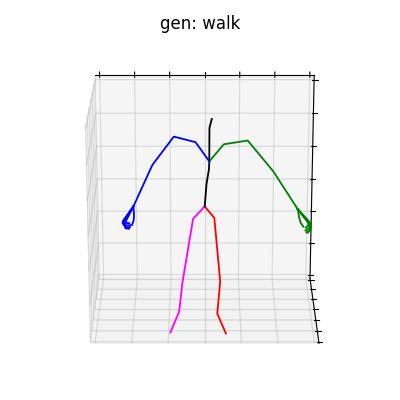 |
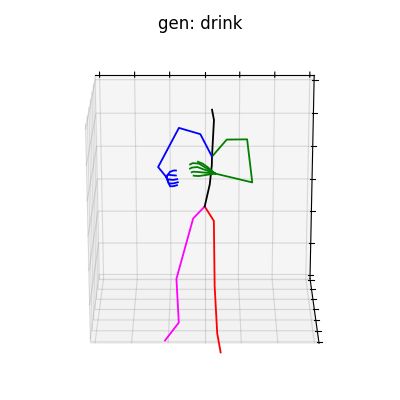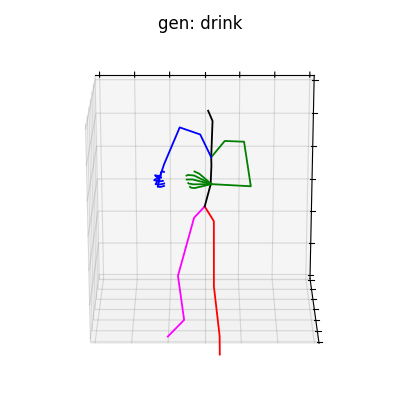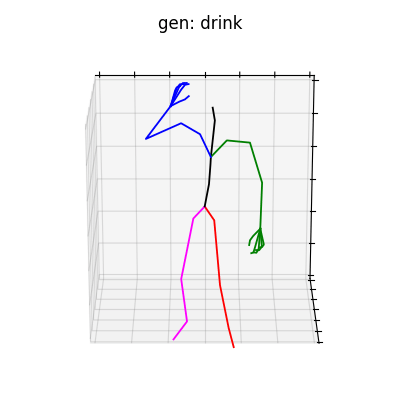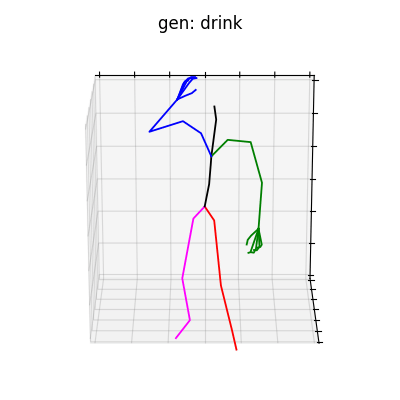 |
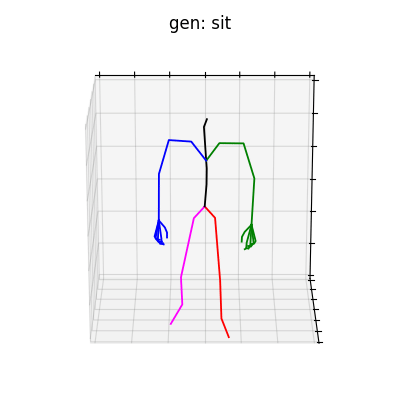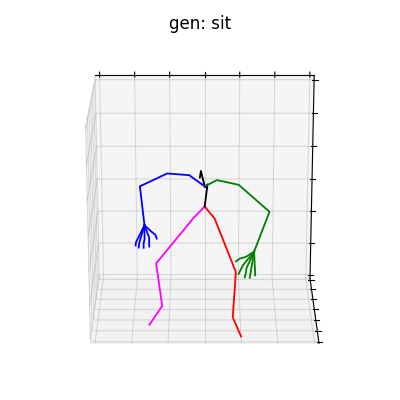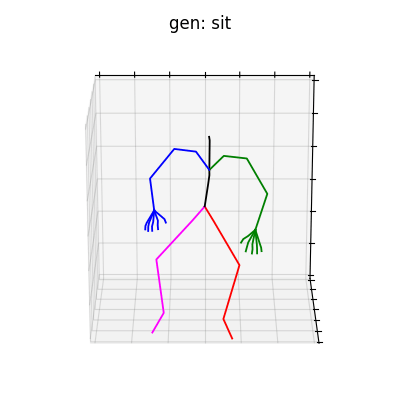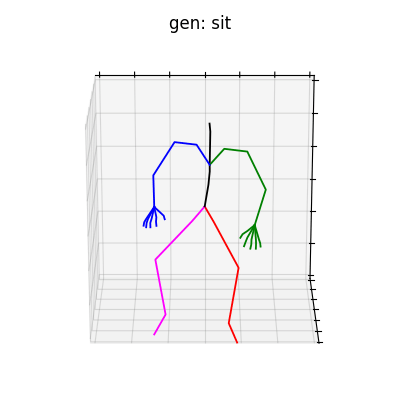 |
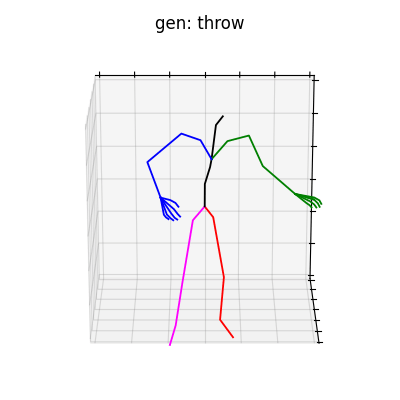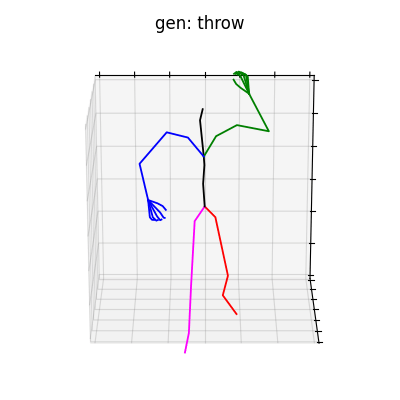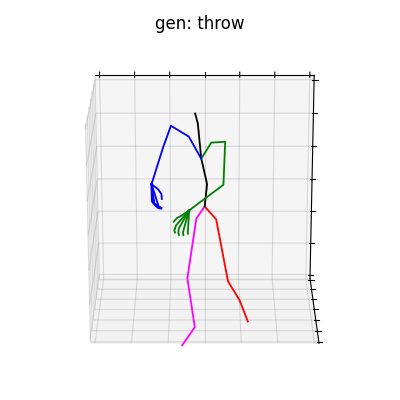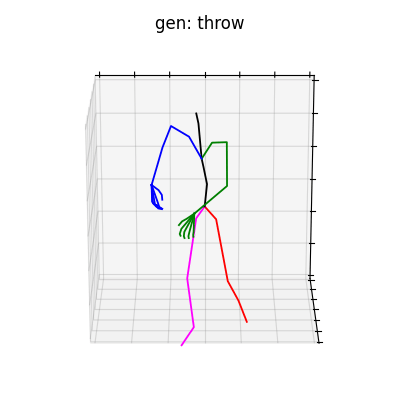 |
図6 HumanAct12-OSXposeを学習データとして用いた時の生成結果
単視点でのポーズパラメータ推定は非常に困難であり、データセットには手首周りの回転が激しいものが含まれるため、潜在空間から抽出される情報によっては、手首周りの回転が激しいものが生成される場合があります(図7参照)。これは学習データのクレンジング等で回避できると考えられます。
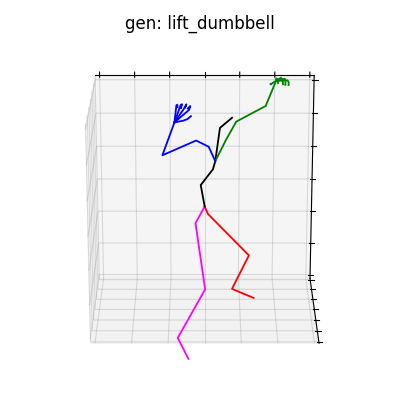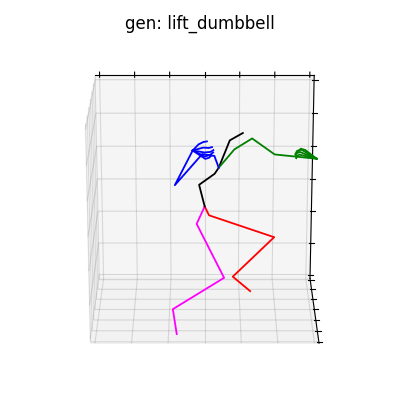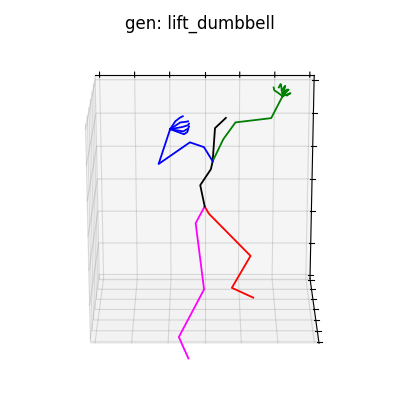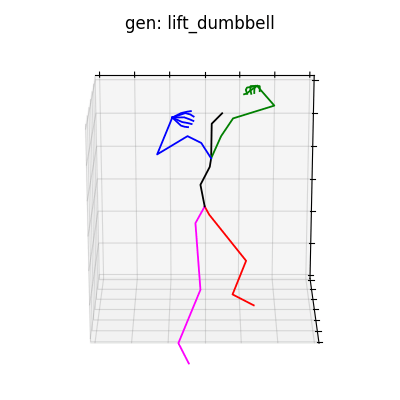
図7 手首周りが回転してしまう例
まとめ・感想
どちらのデータセットでも、手の動きを含めた動作を生成することができました。定量的な評価ではありませんが、HumanAct12-OSXposeを使って学習した方が、HumanAct12-Xposeで学習したものに比べ、より細かい手の動きまで生成されていると考えられます。今回は、動作の種類を示すラベルによる条件付きの手の動きを含めた動作生成を行いましたが、言語から動作を生成するtext-to-motionなどに発展させれば、より多様な全身動作生成を行うことができると思います。
今回、6週間という長期のインターンシップに参加させていただきましたが、振り返るとあっという間でした。自分に不足していることや、新たな知識などを得ることができ、非常に有意義な時間を過ごすことができました。今回の経験を糧に、今後に生かしていこうと思います。最後に、様々なサポートをして頂いた、メンターの藤原さんをはじめ、CVL VHLチームの皆様、ありがとうございました。
参考文献
- [1] Mathis Petrovich, Michael J. Black and Gul Varol, Action-Conditioned 3D Human Motion Synthesis with Transformer VAE, International Conference on Computer Vision (ICCV), 2021
- [2] Xin Chen, Biao Jiang, Wen Liu, Zilong Huang, Bin Fu, Tao Chen and Gang Yu, MLD: Motion Latent Diffusion Models, Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition(CVPR), pp. 18000-18010, 2023
- [3]Debtanu Gupta, Shubh Maheshwari, Sai Shashank Kalakonda, Manasvi Vaidyula, Ravi Kiran Sarvadevabhatla, DSAG: A Scalable Deep Framework for Action-Conditioned Multi-Actor Full Body Motion Synthesis, Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision (WACV), 2023
- [4] Chuan Guo, Xinxin Zuo, Sen Wang, Shihao Zou, Qingyao Sun, Annan Deng, Minglun Gong and Li Cheng, Action2Motion: Conditioned Generation of 3D Human Motions, Proceedings of the 28th ACM International Conference on Multimedia, pp. 2021-2029, 2020
- [5] Vasileios Choutas, Georgios Pavlakos, Timo Bolkart, Dimitrios Tzionas, and Michael J. Black, Monocular Expressive Body Regression through Body-Driven Attention, European Conference on Computer Vision (ECCV), 2020
- [6] Jing Lin, Ailing Zeng, Haoqian Wang, Lei Zhang, Yu Li, One-Stage 3D Whole-Body Mesh Recovery with Component Aware Transformer, Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2023
- [7] Georgios Pavlakos, Vasileios Choutas, Nima Ghorbani, Timo Bolkart, Ahmed A. A. Osman, Dimitrios Tzionas, and Michael J. Black, Expressive Body Capture: 3D Hands, Face, and Body from a Single Image, Proceedings IEEE Conf. on Computer Vision and Pattern Recognition (CVPR), 2019
- [8] Matthew Loper, Naureen Mahmood, Javier Romero, Gerard Pons-Moll and Michael J. Black, SMPL: A Skinned Multi-Person Linear Model, ACM Trans. Graphics (Proc. SIGGRAPH Asia), pp. 248:1-248-16, 2015
- [9] Javier Romero, Dimitrios Tzionas and Michael J. Black, Embodied Hands: Modeling and Capturing Hands and Bodies Together, ACM Transactions on Graphics, (Proc. SIGGRAPH Asia), pp. 245:1-245:17, 2017