
はじめに
こんにちは、王昊(オウコウ)と申します。現在、私は早稲田大学基幹理工学部情報理工学科4年で、河原研究室に在籍していて、自然言語処理の研究を行なっています。
私は特にマルチリンガルに関する研究に興味を持っていて、多言語BERTの構築、漢文の日本語書き下し文の生成などの研究に取り組んでいます。
2022年8月上旬から6週間、LINE夏インターンシップ技術職就業型コースに参加させていただき、AIカンパニーのNLP開発チームにて「6.7B日本語モデルに対するLoRAチューニング」という課題に取り組みました。本レポートではその内容について紹介します。
本レポートの内容は、2023年3月12日から沖縄で開催される、言語処理学会年次大会にて発表いたします。
6.7Bモデルのファインチューニングなどのより詳細な情報はそちらで発表いたしますので、年次大会にご参加の方はよろしくお願いいたします。
背景・目的
近年、Wikipediaなどのテキストデータを使用した大規模な事前学習と特定のタスクやドメインへの適応(ファインチューニング)が自然言語処理において重要なパラダイムとなっています。
GPT-3などの超大規模な言語モデルが相次ぎ発表され、様々なベンチマークでSOTAとなり、幅広い実世界への応用が期待されています。
このような背景から、LINEはNAVER社と共同でHyperCLOVAという日本語に特化した大規模汎用言語モデルを開発しています。
現在はパラメータ数が6.7B*、13B、39Bの三つが発表されており、82Bモデルの開発も進んでいます。
ですが、超大規模な言語モデルのファインチューニングは膨大な学習時間、GPUメモリ、そしてストレージコストがかかるものです。
175B GPT-3を例として、ファインチューニングするたびに800GBのストレージ空間が必要となるので、様々な下流タスクに対応する事前学習のメリットが薄くなっています。
全てのパラメータを更新するのではなく、一部のパラメータのみをチューニングする手法としてBitFit、Prefix-embeddingチューニング、Adapterチューニングなどが提案されています。
その中で本インターンはMicrosoftが2021年に発表した論文「LoRA: Low-Rank Adaption of Large Language Models」で提案された、LoRAチューニングについて検証を行いました。
日本語タスクにおいてLoRAの有効性を検証することで、LINEの幅広いサービスで超大規模な言語モデルの活用が加速すると期待されています。
以下で簡単にLoRAの手法について紹介します。
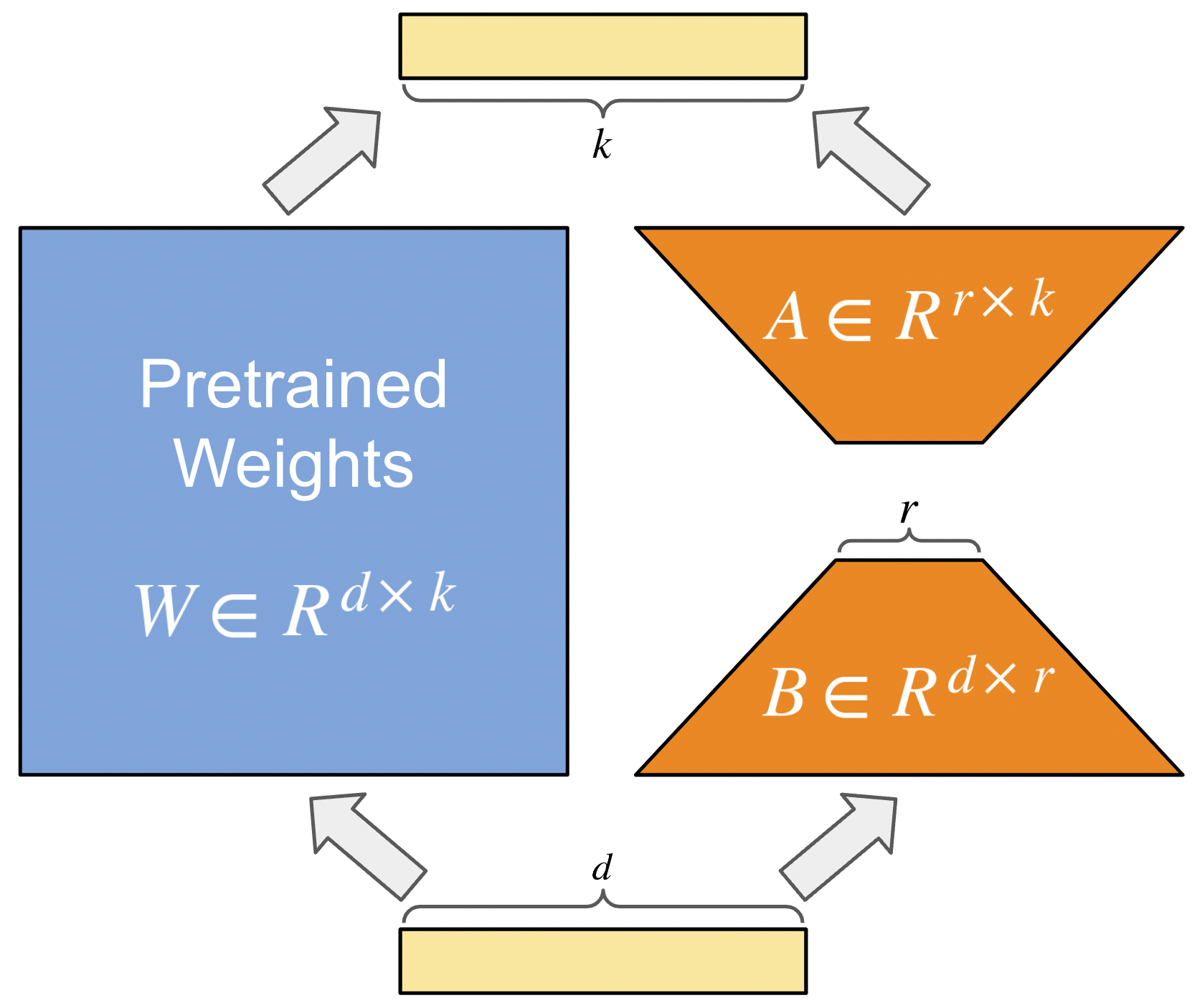
LoRAでは、以下の図に示すように、事前学習モデルの重み
超大規模な言語モデルの完全なランクdは非常に大きく(175B GPT-3だと12,288)に対し、低ランクrは1でも2でも可能で、計算効率とストレージ効率が共に非常に高いです。
論文では、LoRAは175B GPT-3においてGPUメモリを三分の一、学習可能なパラメータ数を一万分の一に削減できたにも関わらず、精度はファインチューニングと同等以上であることが示されています。
*:Billionの略称で、1B=10億です。175Bは1750億パラメータを持つという意味です。以下モデルの説明についてもBの表現を使用します。
実験
今回の実験として、6.7Bモデルと1Bモデルをそれぞれ用意し、三つのタスクに対し、LoRAチューニングとファインチューニングをハイパーパラメータ探索で行い、精度や学習自動評価では時間、メモリ使用量などの比較を行いました。
なお6.7BモデルのファインチューニングはBatch Size 1でもA100上でメモリがオーバーしてしまいますので、本実験では主に6.7B-LoRAと1B-FT(ファインチューニング、以下同)の比較に重きを置きます。
以下の表で今回使用する6.7Bモデルと1Bモデルの概要を示します。両モデルはLINEが独自に構築したTB級サイズのJPLMコーパスを使って作られています。
|
Num Parameters |
Num Attention Heads |
Hidden Size |
Num Layers |
Max Position Embeddings |
Vocab Size |
|---|---|---|---|---|---|
|
6.7B |
32 |
4096 |
32 |
2048 |
50257 |
|
1B |
16 |
2048 |
24 |
2048 |
50257 |
以下で今回使用する三つのタスクについて紹介します。
- XL-Sum:2021年に公開された44言語を含むニュース要約データセットです。BBCの記事の本文やヘッドラインの要約文から作られていて、本文から要約文を生成するタスクです。
人手評価や自動評価で高品質であることが示されています。
日本語の部分は合計8891本文-要約ペアがあり、GPTの応用先として要約が期待されているためこのタスクを採用しています。
本実験ではROUGEを評価指標として自動評価を行います。 - JNLI:2022年に公開された日本語言語理解ベンチマークJGLUEのタスクです。
2つの文の間に含意関係があるかを含意/中立/矛盾の3段階で判定する自然言語推論(Natural Language Inference, NLI)タスクで、BERT系モデルの評価でよく使われています。
日本語GPTに対しては、入力の文ペアをモデルに与えて、含意/中立/矛盾のどれかを生成させることで、Accuracyで評価できます。 - JCommonsenseQA:同じくJGLUEのタスクです。
質問文と正解が含められる五つの選択肢の入力を与え、モデルに一つ選ばせてAccuracyを計算するタスクです。
言語モデルの常識推論能力を評価するために使われています。
今回GPTに対する実験は質問文と選択肢を与え、生成された結果に対してEM(Excat Match, 出力と正解が完全一致の比率)を計算する設定を採用しています。
また、BERT系モデルと比較するために、ここではEMとAccuracyを同一視します。
なお、JNLIとJCommonsenseQAについては、BERT系モデルのように幾つかの選択肢の中で確率を計算して一つを選ぶものと異なり、回答のテキストを生成しています。
そのため、選択肢以外のものを生成する可能性があり(例えば、JNLIにおいて"含意"と"中立"じゃなく、"中意"を出力してしまう)、BERT系モデルとの厳密な比較はできません。
それぞれのタスクにおいて学習、検証、テストで使用するデータ件数を以下の表で示します。JNLIとJCommonsenseQAはTrainとValidationセットしか公開されていないため、ValidationセットをValidationとTestに再分割しています。
|
Train |
Validation |
Test |
|
|---|---|---|---|
|
XL-Sum |
7113 |
889 |
889 |
|
JNLI |
20073 |
1217 |
1217 |
|
JCommonsenseQA |
8939 |
560 |
559 |
以下の表で今回使用するハイパラ探索の設定を示します。
- LoRA Weight Typeはどの部分で新しいLoRAのAttentionの重みを作成し学習するのかを表します。例として、Wq+Wvはモデル中全てのTransformerのQとVの重みを新たに作ってLoRAの一部として学習する意味です。WoはMulti-Head Attentionの最後にConcatされたAttentionに対して掛ける重みを意味します。
- LoRA Adapter DimはLoRAで新しく作成される低ランク分解行列
A∈Rr×k とB∈Rd×r のrの大きさです。
|
Batch Size |
{8} |
|---|---|
|
Epoch |
{2,3,4} |
|
Learning Rate |
{1e-5, 2e-5, 5e-5, 2e-4} |
|
LoRA Weight Type |
{Wq+Wv, Wq+Wk+Wv+Wo} |
|
LoRA Adapter Dim |
{4,8,16} |
今回の実験は全てNVIDIA A100(80GB)上で行われました。
なお, 6.7Bモデルのファインチューニングは, 1枚のGPU上では行えなかったので本ブログには記載しておりません.
結果
以下でタスクごとに結果を表で示します。そして、6.7B-LoRAと1B-FTの生成例をタスクごとに三つピックアップして示します。
XL-Sum
|
Trainable Parameters |
Model File Size |
GPU Memory† |
Training Time† / Epoch |
Best Parameter Combination |
ROUGE-1 |
ROUGE-2 |
ROUGE-L |
|
|---|---|---|---|---|---|---|---|---|
|
1B-FT |
1.3B |
2.5GB |
40GB/81GB |
35mins |
Epoch=4 LR=2e-4 |
0.417 |
0.154 |
0.299 |
|
1B-LoRA |
6M |
24MB |
19GB/81GB |
35mins |
Epoch=4 LR=2e-4 Weight Type=Wq+Wk+Wv+Wo Adapter Dim=16 |
0.153 |
0.034 |
0.134 |
|
6.7B-LoRA |
16M |
64MB |
54GB/81GB |
60mins |
Epoch=4 LR=2e-4 Weight Type=Wq+Wk+Wv+Wo Adapter Dim=16 |
0.457 |
0.213 |
0.348 |
†:XL-Sumの系列が長いため、Batch Size 8でA100一枚上で学習することができません。そのため、ここでのGPU MemoryとTraining TimeはBatch Size 1の時の値を載せています。
|
入力例 |
正解ラベル |
1B-FT |
1B-LoRA |
6.7B-LoRA |
|---|---|---|---|---|
|
辞任したマルコム・ターンブル首相(左)とスコット・モリソン氏 ターンブル首相はかねて、低い支持率や同首相自身が「反乱」と呼んだ与党議員からの圧力にさらされており、辞任に追い込まれた格好だ。 与党内の勢力争いで辞任した豪首相は、過去10年で4人目となる。 ターンブル氏は24日、「この偉大な国の指導者でいられたのは、実に光栄だった。オーストラリアを愛している。オーストラリア人を愛している」とコメントした。 一方のモリソン氏は、ターンブル氏を最も強く批判していたピーター・ダットン内相との一騎打ちを45対40の僅差で制した。 ターンブル氏が辞任に追い込まれた理由は? 2019年後半までに実施される総選挙を視野に、自由党議員は与党の低支持率や、7月末の補欠選挙敗退など、不安要素を抱えている。 ターンブル首相は先週、気候変動抑制のための排出量削減政策を打ち切ると発表し、党内での緊張が高まった。 党内保守派のダットン氏は21日に行われた自由党の党首選で辛くもターンブル首相に敗れたものの、この接戦がさらにあつれきを深めることになった。 モリソン氏は、ターンブル氏が主要な支持者を失った段階で党首に立候補した。24日に議員らが内閣の「人事異動」を求め、ターンブル氏は辞職を受け入れた。 このほかジュリー・ビショップ外相も立候補したものの、決選投票には食い込めなかった。 スコット・モリソン氏とは モリソン氏は元オーストラリア観光局の高官で、2007年に政界入り。これまでに3回、入閣した。主な経歴は以下の通り。 (英語記事 Australia gets new PM in brutal party coup)[SEP] |
与党・自由党党首選をめぐって紛糾していたオーストラリアで24日、マルコム・ターンブル首相が辞任し、その後行われた党首選でスコット・モリソン財務相が勝利した。モリソン氏は自動的に首相となる。 |
オーストラリアのスコット・モリソン首相は24日、辞意を表明した。5人目の国首相となる。 |
フランス大統領選出されている。 |
オーストラリアの与党自由党は24日、党首選でスコット・モリソン前外相を新首相に選出した。 |
|
ワシントン州キング郡のアウトブレイクはひとつの介護施設に集中している 死者6人のうち5人は、シアトルのあるキング郡に住んでいた。この地域ではこれまでに18人の感染が確認されており、今後の増加が懸念されている。 同州で最初に確認された死者2人について調べていた専門家によると、新型ウイルスは州内で数週間前から拡散し、これまでに最大1500人が感染している可能性があると指摘した。 <関連記事> ワシントン州のキャシー・ローファイ保健担当官は、感染はキング郡とスノホミッシュ郡に限定されているものの、ウイルスは「活発に」流行していると述べた。また、他地域でも感染している可能性もあると指摘した。 キング郡で確認された患者14人のうち8人と死者4人が、特定の介護施設に関連している。亡くなったほとんどは高齢者か、基礎疾患のある人だったという。 同郡当局は感染者の隔離施設として、ホテルを購入する方針。シアトルでは休校が相次いでいる。 シアトルおよびキング郡公衆衛生庁のジェフ・ドゥチン博士は「事態を深刻に捉えている」とした上で、、現時点では広範囲での休校措置や大規模集会の中止などは考えていないと述べた。その一方、感染者の数は今後も増えるだろうとの見方を示した。 これまでに100人近くが感染 アメリカではこの週末に感染者の数が急増し、懸念が広がっている。これまでにアメリカ全土で91人の感染が確認されたが、このうち一部は感染多発地域に渡航していた。一方で、アメリカ国内で感染したとみられる事例もある。 ワシントン州、カリフォルニア州、オレゴン州など西海岸の州当局は、感染地域への渡航歴や感染者との接触がない人からもウイルスが検出されたことに、懸念を示している。 その他のアメリカでの状況は以下の通り・ (英語記事 Four more coronavirus deaths declared in US)[SEP] |
米ワシントン州で2日、新型コロナウイルスによる感染症(COVID-19)による新たな死者が4人報告された。アメリカでの死者は6人となった。ワシントン州は週末に非常事態宣言を発令している。 |
新型コロナウイルスのためアメリカ全土で死者が4人増え、最大324人になったことが13日、明らかになった。 |
米フロリダ州で初めて確認された。 |
米ワシントン州で新型コロナウイルスの感染者が急増している問題で、同州当局は13日、新たに4人が死亡したと発表した。 |
|
米トリップアドバイザーのアプリも排除されたが、理由は明らかにされていない 排除されたアプリの大半は中国製。サイバースペース管理当局は対象のアプリについて、国内の3つのサイバー関連法のどれかに違反しているとしたが、詳細は明らかにしなかった。 この排除は、アメリカで中国の動画共有アプリTikTokに対して予定されていた利用禁止措置を一時差し止める、2つ目の司法判断が出たタイミングで実施された。 アメリカでは、ドナルド・トランプ大統領が安全保障上の理由を挙げてTikTokを禁止しようとしたことについて、連邦地裁のカール・ニコルズ裁判官が、行き過ぎた大統領権限の行使だとの判断を示した。TikTokに有利な判断をした裁判官は2人目。 <関連記事> トリップアドバイザーが排除された理由は不明。BBCは同社にコメントを求めたが、返答を得られていない。 サイバー分野で緊張高まる アメリカと中国の関係はここ数カ月、サイバースペースの分野で緊張が高まっている。 トランプ氏が今夏、TikTokを禁止する方針を発表した際には、中国当局はアメリカが「弱い者いじめ戦略」を取っていると非難。中国企業の利益を守るため、「必要な措置」を取るとした。 中国ではインターネットは厳しく規制されている。グーグル、フェイスブック、ツイッターの米企業のサービスはすべてブロックされている。 (英語記事 China bans 105 apps including TripAdvisor)[SEP] |
中国当局は8日、米トリップアドバイザーなど105種のアプリを国内のアプリストアから排除したと発表した。ポルノや売春、ギャンブル、暴力に関係するものを無くすのが狙いだとしている。 |
米テクノロジー大手の米旅行口コミサイト「トリップ」は20日、中国企業が運営する旅行の検索・予約サービスが対象に含まれている105のアプリを削除したと発表した。 |
米政府は10日、米国務省は26日、米アップル)は27日、米中の捜査局(CEO)は29日、米通知財務省は5日、米司法省は20日、米司法省は25日、米司法省は7日、米司法省は、米司法省は、米司法省は、米司法省は、米司法省は、米司法省は、米司法省は、米司法省は、米司法省は、米司法省は、国家安全保障措置法案を受けた。 |
中国政府は19日、旅行サイト大手の米トリップアドバイザーなど、外国のアプリ100以上を禁止したと発表した。 |
JNLI
|
Trainable Parameters |
Model File Size |
GPU Memory |
Training Time / Epoch |
Best Parameter Combination |
Accuracy |
|
|---|---|---|---|---|---|---|
|
1B-FT |
1.3B |
2.5GB |
26GB/81GB |
7mins |
Epoch=2 LR=1e-5 |
0.732 |
|
1B-LoRA |
1.5M |
6MB |
7GB/81GB |
4mins |
Epoch=3 LR=2e-4 Weight Type=Wq+Wk+Wv+Wo Adapter Dim=4 |
0.731 |
|
6.7B-LoRA |
2M |
8MB |
20GB/81GB |
5mins |
Epoch=3 LR=2e-4 Weight Type=Wq+Wv Adapter Dim=4 |
0.935 |
|
Human‡ |
-- |
-- |
-- |
-- |
-- |
0.925 |
|
Waseda RoBERTa large‡ |
336M |
1.35GB |
-- |
-- |
-- |
0.924 |
‡:HumanとWaseda RoBERT largeのスコアはJGLUEのベンチマークから引用しています。ただし、JGLUEのスコアはValidationセットをチューニング、テストの両方で使用しているため、あくまで参考目的で厳密な比較ではないとご了承ください。以下のJCommonsenseQAも同じ状況となっています。
|
入力例 |
正解ラベル |
1B-FT |
1B-LoRA |
6.7B-LoRA |
|---|---|---|---|---|
|
文1:キリンが、木の中から首を出しています。[SEP]文2:キリンが木々のあいだから顔を出しています。[SEP] |
含意 |
含意 |
中意 |
含意 |
|
文1:プロペラが取り付けられた飛行機が停められています。[SEP]文2:飛行場に、飛行機が停まっています。[SEP] |
中立 |
中立 |
中立 |
中立 |
|
文1:飛行場に、飛行機が停まっています。[SEP]文2:プロペラが取り付けられた飛行機が停められています。[SEP] |
中立 |
中立 |
中立 |
中立 |
JCommonsenseQA
|
Trainable Parameters |
Model File Size |
GPU Memory |
Training Time / Epoch |
Best Parameter Combination |
EM(Accuracy) |
|
|---|---|---|---|---|---|---|
|
1B-FT |
1.3B |
2.5GB |
25GB/81GB |
3mins |
Epoch=3 LR=1e-5 |
0.627 |
|
1B-LoRA |
1.5M |
6MB |
6GB/81GB |
2mins |
Epoch=4 LR=2e-4 Weight Type=Wq+Wk+Wv+Wo Adapter Dim=4 |
0.012 |
|
6.7B-LoRA |
2M |
8MB |
17GB/81GB |
2mins |
Epoch=4 LR=2e-4 Weight Type=Wq+Wv Adapter Dim=4 |
0.935 |
|
Human |
-- |
-- |
-- |
-- |
-- |
0.986 |
|
Waseda RoBERTa large |
336M |
1.35GB |
-- |
-- |
-- |
0.901 |
|
入力例 |
正解ラベル |
1B-FT |
1B-LoRA |
6.7B-LoRA |
|---|---|---|---|---|
|
質問:田んぼが広がる風景を何という?[SEP]畑[SEP]海[SEP]田園[SEP]地方[SEP]牧場[SEP] |
田園 |
田園 |
森 |
田園 |
|
質問:水を出すときに捻るものは?[SEP]蛇口[SEP]ハンドル[SEP]流し[SEP]釘[SEP]食器棚[SEP] |
蛇口 |
utilty:¥flour:サウジアラビア |
箱 |
蛇口 |
|
質問:地中にある一定の大きさの空間のこと?[SEP]麓[SEP]山頂[SEP]中腹[SEP]山腹[SEP]洞窟[SEP] |
洞窟 |
洞窟 |
大地面 |
洞窟 |
考察
今回は、1B-FT、1B-LoRA、6.7B-LoRAをそれぞれ三つのタスクで実施しました。
まず1B-FTと1B-LoRAを見ていきますと、全タスクにおいて1B-LoRAは1B-FTと比べて200倍以上の学習可能パラメータの削減、100倍以上のモデルファイルサイズの削減、2倍以上のGPUメモリの削減を実現できました。
JNLIにおいて1B-LoRAは1B-FTと同等の性能を出してる一方、他のタスク(特にはJCommonsenseQA)においては使えない性能でした。
バグじゃない?と疑いたくなるものですが、rinna-1BモデルとLoRA公式実装を使って検証した結果、どうやら1BモデルのLoRAはどうしてもJCommonsenseQAとXLSumをうまく学習できないようです。
JCommonSenseQAの生成例を見ても、1B-LoRAは「五つの選択肢から一つ選ぶ」という問題設定すら理解できていないようです。
XLSumの生成例を見ると、文章になっていないものが多いです。以上の結果から、LoRAの適用範囲は結構タスクの難易度に左右されるではないかと考察しています。
JNLIは比較的簡単な三択問題で1B-LoRAが1B-FT同等の精度を出せている一方、入力文の中から答えを探すJCommonsenseQAやゼロから要約を生成するXLSumにおいて1B-LoRAは使えない精度でした。
どのようなタスクであればLoRAは安定な性能を出せるのか、入力文の長さによってLoRAの性能は影響されるのかなど、追加の検証が必要です。
6.7B-FTの実験は今回メモリ不足の問題で行わなかったため、6.7B-LoRAと1B-FTの比較を見ていきます。
1B-LoRAと異なり、6.7B-LoRAは全てのタスクにおいて安定かつ優れる性能を出しました。
タスクの難易度の他に、LoRAの安定さはモデルのパラメータ数にも依存するとわかりました。
1B-FTと比べ、6.7B-LoRAはJNLIにおいて約25%、JCommonsenseQAにおいて約50%の性能向上があったにもかかわらず、600倍の学習可能パラメータの削減、300倍のモデルファイルサイズの削減を実現しました。
XLSumにおいてもROUGE-1で4ポイントの上昇など、素晴らしい性能を出せています。
XLSumは系列長などの原因で他のタスクと比べて若干メモリと学習時間が多く取られていますが、学習不可能の6.7B-FTに対し十分効率が高いと言えるでしょう。
さらにJNLIとJCommonsenseQAにおいて、6.7B-LoRAはおそらく現環境最強のBERT系モデルWaseda RoBERTa largeを超える精度を出していて、超大規模な言語モデルの威厳を見せてくれました。
続いてLoRAのハイパーパラメータ探索について見ていきます。
LoRAの論文では全実験で学習率を2e-4に設定しているため、本実験も2e-4を探索に入れています。
グリッドサーチの結果、やはりLoRAは普通のFTよりも大きい学習率を設定する必要があるとわかりました。
LoRAのAttentionの重みタイプと低ランク分解行列の次元rについては、JNLIとJCommonsenseQAの両タスクにおいて一番コストが小さい組み合わせ(Weight Type=Wq+Wv, Adapter Dim=4)が最適となっている一方、XLSumにおいて一番コストが高い組み合わせ(Weight Type=Wq+Wk+Wv+Wo, Adapter Dim=16)が最適となっています。XLSumの要約はこの中一番難しいため、KとOの重みの学習や大きい次元rを通じてより高い表現能力を得ていると考察しています。
さいごに
本レポートでは、6.7B日本語言語モデルに対するLoRAチューニングの検証について紹介しました。
6.7BモデルにおいてLoRAは素晴らしい精度や省メモリの性能を魅せてくれました。
一方、6週間という短い期間の中で検証し切れていないところがまだ沢山あります。
XLSumタスクにおいての人手評価の実施、6.7Bモデルのファインチューニングの実施、13B以上の超大規模モデルに対するLoRAの検証などが、これからの課題となっています。
短い間でしたが、自由な働き環境、綺麗なオフィス、美味しいカフェなど、どれも魅力的でした。
自分は今年初めて自然言語処理を勉強し始めた初心者ですが、何でも教えてくださるNLP開発チームのメンバー達のおかげで頑張れました。
特にメンターの中町さんからは様々なことをご教授いただきました。
今後も、今回のインターンシップで得た経験を研究で活かしていければと思います。本当にありがとうございました!
参考文献
-
Hu, Edward and Shen, Yelong and Wallis, Phil and Allen-Zhu, Zeyuan and Li, Yuanzhi and Wang, Lu and Chen, Weizhu, LoRA: Low-Rank Adaptation of Large Language Models
-
Boseop Kim, HyoungSeok Kim, Sang-Woo Lee, Gichang Lee, Donghyun Kwak, et al.. What Changes Can Large-scale Language Models Bring? Intensive Study on HyperCLOVA: Billions-scale Korean Generative Pretrained Transformers.
-
Kentaro Kurihara, Daisuke Kawahara, and Tomohide Shibata. JGLUE: Japanese General Language Understanding Evaluation.
-
Hasan, Tahmid and Bhattacharjee, Abhik and Islam, Md. Saiful and Mubasshir, et al.. XL-Sum: Large-Scale Multilingual Abstractive Summarization for 44 Languages