
はじめに
初めまして!野﨑雄斗と申します。
現在、私は東京大学大学院情報理工学系研究科コンピュータ科学専攻修士課程1年で、杉山・横矢・石田研究室に所属し、機械学習についての研究をしています。特に現在は弱教師付き機械学習を軸に研究しています。
2023年8月上旬から6週間、LINE夏インターンシップ技術職就業型コースに参加させていただき、「Federated Fine-tuning of LLMs with Differential Privacy」という課題に取り組みました。
このレポートはそのテーマについて私が行ったことについて紹介いたします。
目標: 分散したデータから大規模言語モデル(LLMs)の訓練するプライバシー保護機械学習手法の実装
LLMは一般的なNLPタスクをうまく解くことができます。その一方で、スマートフォン上での予測変換などタスクには、スマートフォン上の機微なデータを用いてLLMを学習することが望ましいと考えられます。
その際、スマートフォン上のデータは個人のプライベートなものであると考えられるため、プライバシーに配慮した機械学習手法が必要です。
そこで、本インターンシップでは、連合学習(Federated Learning、FL)と差分プライバシー(Differential Privacy、DP)といったプライバシーテックを前提とする手法の実現可能性について研究開発に取り組みました。
背景知識
差分プライバシー(Differential Privacy)
差分プライバシーとは、プライバシーに関する統計的な基準です。簡潔に述べるとノイズなどを加えることによって個人識別性がどの程度困難であるかを表します。
差分プライバシーには
まずとローカル差分プライバシー(Local Differential Privacy)とセントラル差分プライバシー(Central Differential Privacy)、分散差分プライバシー(Distributed Differential Privacy)について説明します。
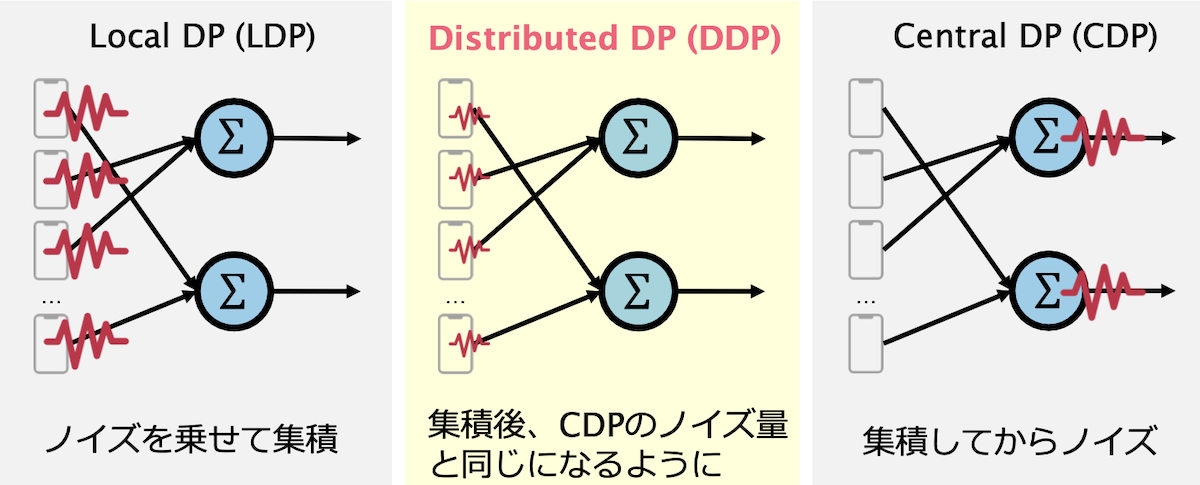
上図のようにローカル差分プライバシーは個々のクライアント(データ所持者)が差分プライバシーを保証するためにノイズを乗せます。セントラル差分プライバシーはサーバー(データ収集者)が個々のクライアントからの情報を集約してからノイズを乗せます。
ローカル差分プライバシーは個々のクライアントがノイズを乗せるのでノイズ量が多くなりがちで、セントラル差分プライバシーはクライアントがサーバにデータを渡す際のプライバシーについて考慮できていません。その問題点を解決するために分散差分プライバシー(Distributed Differential Privacy)があります。分散差分プライバシーではサーバー側で集約した時にセントラル差分プライバシーで加えるノイズと同等のノイズになるように個々のクライアントがノイズを乗せます。DDPではSecure Multi Party Computationなどのセキュアなプロトコルで集約が行われることを想定します。本研究ではDDPなFLの実現にのみ注力したため、SMPC上での実現は今後の課題です。
連合学習(Federated Learning)
連合学習は機械学習を分散して訓練する手法です。一つのサーバーと多数のクライアントを想定します。以下のプロセスを繰り返しモデルを学習します。
- サーバーがグローバルなモデルを多数のクライアントに配布します。
- 多数のクライアントが各々持っているデータを用いて学習します。
- 多数のクライアントがデータではなく、勾配や重みの差分などの情報をサーバーに送る。
- サーバーがそれらの情報を集約してそれを元に学習する。
以上からわかる通り、クライアントがそれぞれ持っているデータ自体を送信していないので、プライバシーの保護に繋がります。
Federated Learning with Distributed Differential Privacy
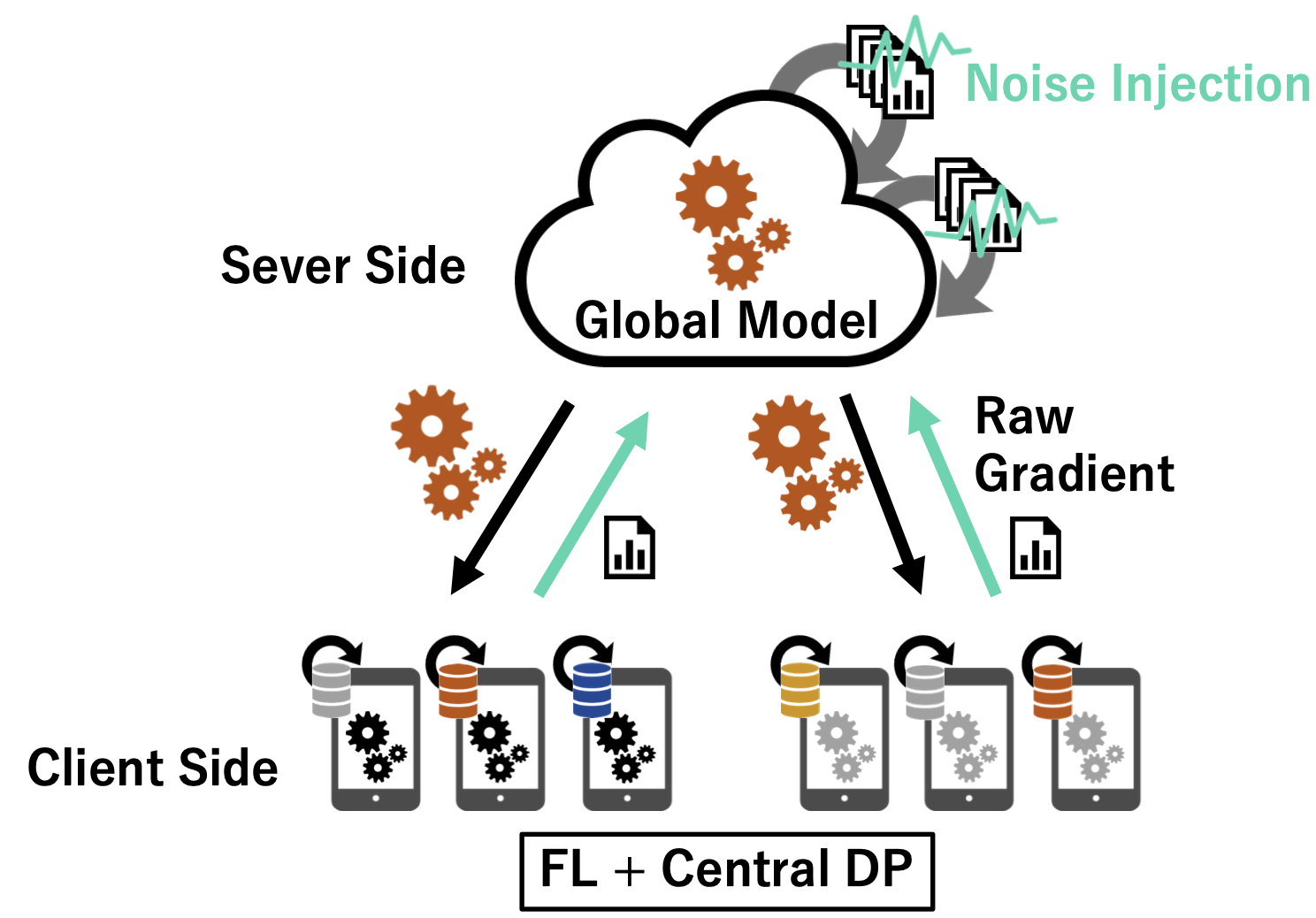
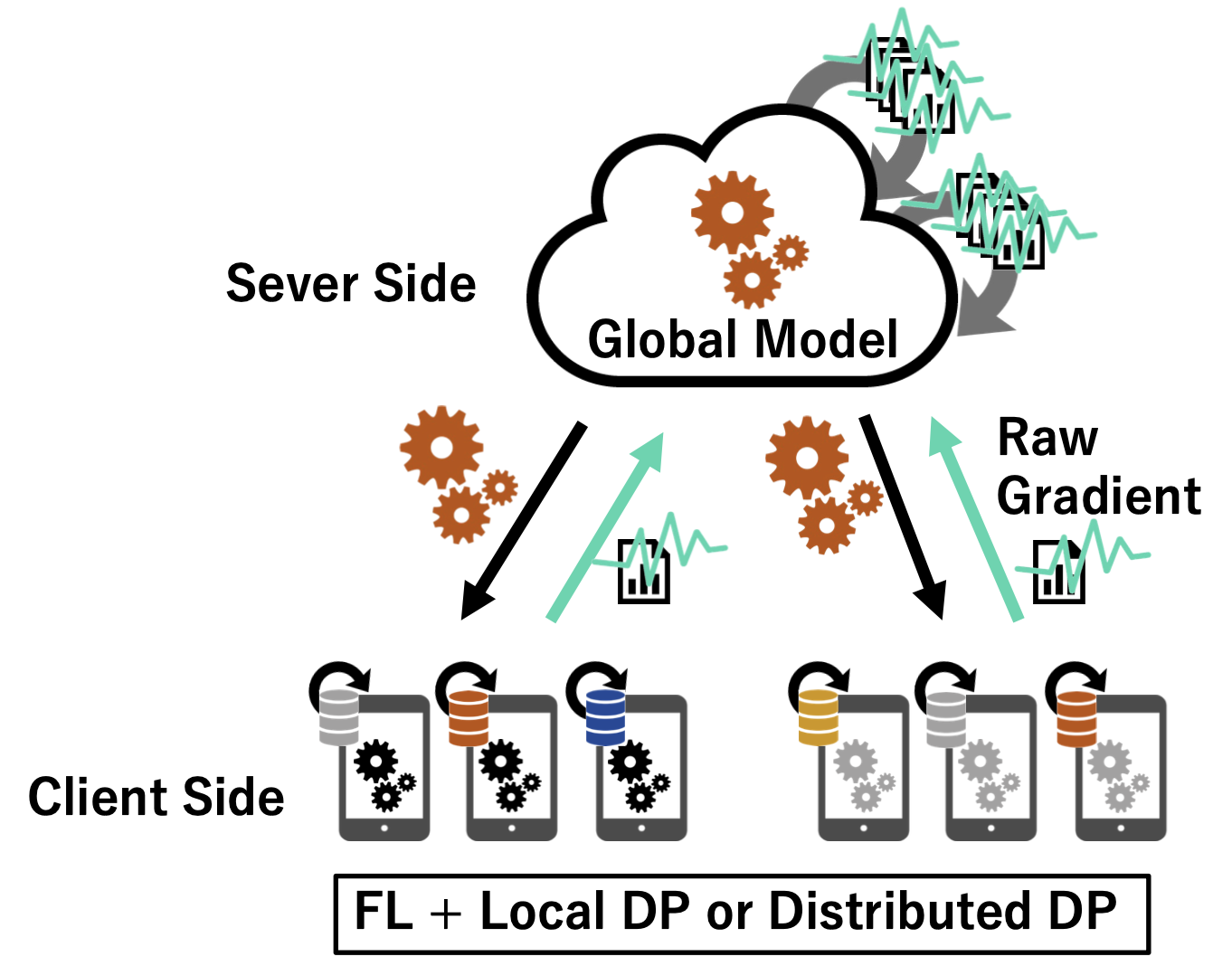
セントラル差分プライバシーを用いる場合は、以下のようにクライアントが送信した後、サーバーはそれらを集約してノイズを乗せて学習します。ローカル差分プライバシー、分散差分プライバシーを用いる場合は、以下のようにクライアントはノイズを乗せてからクライアントに送信し、クライアントはそれを集約して学習します。
手法: Federated Fine-tuning of LLMs with Differential Privacy
手法概要
先述したように、分散差分プライバシーを用いて連合学習する場合は、左図のようにクライアントはノイズを乗せてからクライアントに送信し、クライアントはそれを集約して学習します。右図は[2]より。
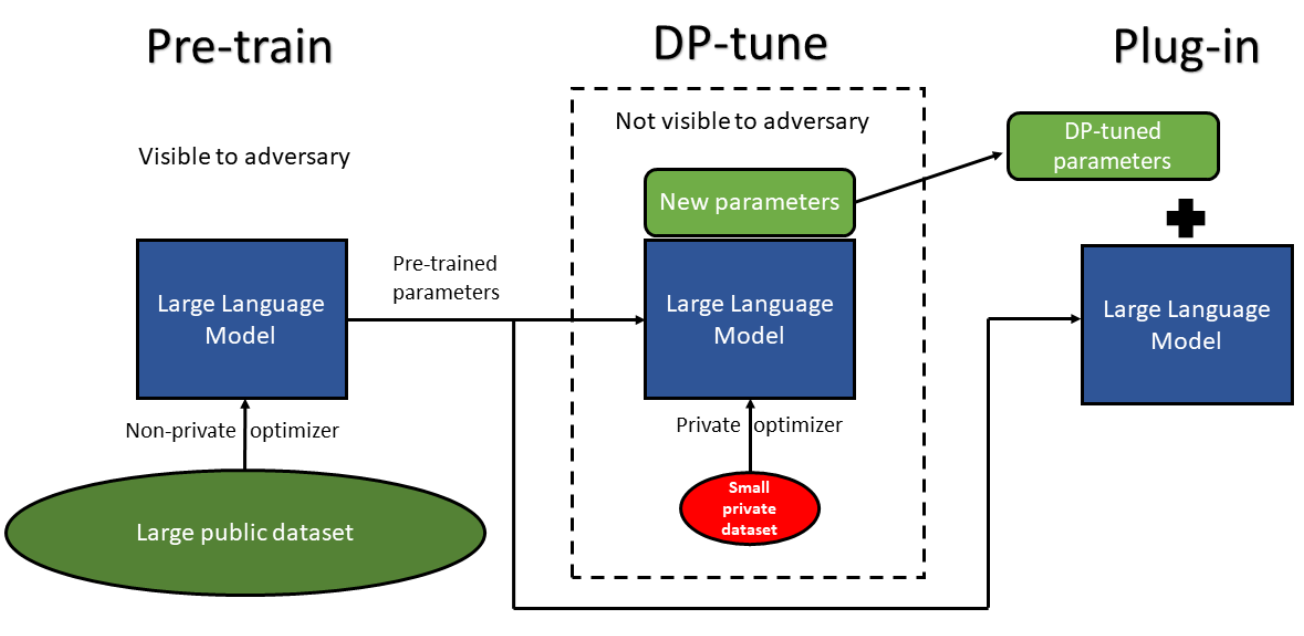
それでは今回用いた手法の手順を示します。
- 大規模の公開データ(プライバシーの問題が無い)によって大規模言語モデルを事前学習します。このモデルの重みは固定します。
- 次にFine-tuningするために追加で新たなパラメータ(このパラメータはLoRA[3]に基づく)を導入します。これがサーバーが初期に持つグローバルモデルになります。
- 以下の4~7stepを繰り返します。
- サーバーがグローバルなモデルの重みを多数のクライアントに配布します。
- 多数のクライアントがローカルでそれぞれ個人が持っているデータ(プライバシーの考慮が必要)を用いて追加した新たなパラメータのみを更新します。
- その後、多数のクライアントがデータではなく、勾配や重みの差分などの情報をサーバーに送ります。この時に勾配や重みの差分などの情報に分散差分プライバシーの概念に基づきノイズを加えてDPを保証できるようにします。
- サーバーがそれらの情報を集約してそれを元に学習します。
各々のクライアントのノイズの入れ方について
DP-SGD[4] (Differentially private stochastic gradient descent)を適用します。これは差分プライバシーを保証する機械学習モデルを訓練するための最適化手法です。
DP-SGDの直感的なイメージは確率的勾配降下法(Stochastic gradient descent)をベースとして、訓練の際に用いる勾配にノイズを加算することで、差分プライバシーを保証する機械学習モデルを訓練しようとします。
効率化に向けた検討
新規性としては、知る限りでは初めて連合学習と分散差分プライバシー、LoRA[3] などの効率的なFine-tuning手法を組み合わせたことです。
LoRA[3]は、実用性、計算コスト、通信量などを顧慮して効率よくFine-tuningする手法として知られています。
Fine-tuneした後の重みを
今紹介した分散したデータからLLMsを訓練する連合学習、差分プライバシー、LoRAを組み合わせたプライバシー保護機械学習手法の実装と検討に今回のインターンのほとんどの時間を費やしました。
実験
先ほど紹介した手法を実装し、2つのデータセットにおいて実験したのでその結果を示します。
LoRAの実装はPRFT[5]と呼ばれるLoRAなどの効率的に言語モデルを訓練する手法が簡単に使えるライブラリを使用しました。
画像識別のデータセットMNISTと自然言語処理タスク向けデータセットのStack Overflowを用いました。MNISTを用いる際は、事前学習としてFashion-MNISTというデータセットを用いました。本来の目的はLLMsの訓練ですが、実装が上手くいっているか確認するために画像認識のタスクでも実験しました。
MNISTでの実験は画像識別、Stack Overflowでの実験は次単語予測のタスクで評価しました。
MNISTに対する実験で使用したモデルは2層の畳み込み層と1層の全結合層からなる簡単なモデルです。PEFTを用いてLoRAを実現した時、2次元の畳み込み層に対して追加のパラメータを導入することが出来ないので1層の全結合層に対してだけ追加のパラメータを導入しました。
Stack Overflowに対する実験では、モデルとしてはDistligpt2[8]を使用しました。Distligpt2はGPT2[9]を蒸留したモデルです。パラメータは88.2millionです。
実験結果
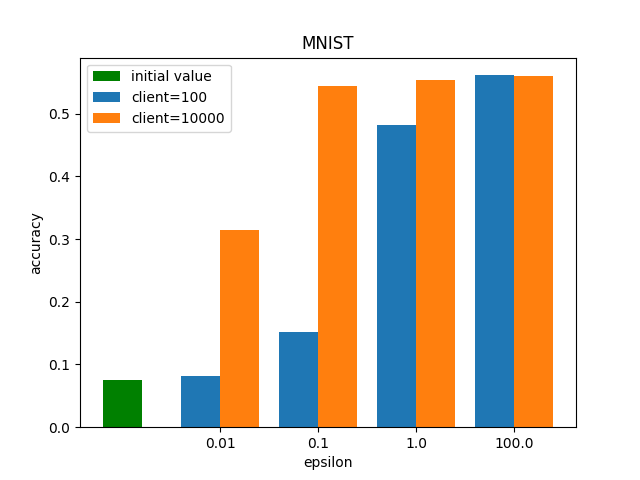
MNIST (左図)
クライアントの数と
まず事前学習だけしたモデルでの精度(図でのinitial value)は0.075であったので、
背景知識で紹介した通り、分散差分プライバシーではサーバー側で集約した時にセントラル差分プライバシーで加えるノイズと同等のノイズになるように個々のクライアントがノイズを乗せます。このようなノイズの乗せ方をするとクライアントの数が多ければ多いほど一つのクラアントで加えるノイズの量が小さくなります。クライント数が100の時と10000の時を比較します。クライアント数が10000の時は
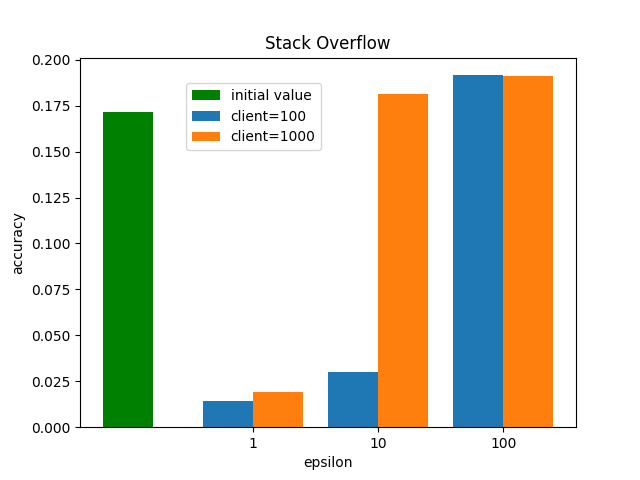
Stack Overflow (右図)
クライアントの数と
先ほどの実験と同様に
またクライント数が100の時と1000の時を比較します。クライアント数100の時は
まとめ
連合学習を用いて大規模言語モデルを訓練することを考えました。特に、プライバシー保護機械学習を実現するための手段として連合学習や差分プライバシーを用いたり、実用性、計算コスト、通信量などを顧慮して効率よくFine-tuningする手法であるLoRAを分散差分プライベートな連合学習の上に実装し、実験によってそれが正しく実装できたことを確かめました。
最後に
私はこの夏のインターン以前にBeyond AIというプロジェクトの一環で今回と同じチームでインターンさせていただいておりました。この夏、再度プライバシーチームでインターンしたいと考えたのは、プライバシーチームというプライバシーに関する技術の経験・実績が豊富な方々から頻繁に的確なアドバイスがいただけた恵まれた環境でもう一度研究・開発したいと思ったのと、何よりもこのチームでしか出来ないこと(他社のインターンでは体験できない)があると感じたからです。実際に配属していただき、その考えは間違いではなかったとインターン期間中は常に実感することばかりでした。例えば詳しくは言えませんが、テーマやその先の展望をメンターの方に説明したいただいた時、本当にLINEのこのチームでしか出来ないと雷に打たれたように強く感じました。また差分プライバシー、連合学習、自然言語処理の各々の分野のエキスバートに気軽に疑問点を伺える最高の環境でした。
6週間という短い間ではありましたが、大変勉強になりました。メンターの高橋さんとLiewさん、チームの皆様、インターン生に感謝を申し上げます。
今後、今回のインターンで学んだことを活かしていきたいと思います。
参考
- https://speakerdeck.com/line_developers/differential-privacy-data-science-with-privacy-at-scale
- Yu, Da, et al. "Differentially Private Fine-tuning of Language Models." International Conference on Learning Representations. 2022.
- Hu, Edward J., et al. "LoRA: Low-Rank Adaptation of Large Language Models." International Conference on Learning Representations. 2021.
- Abadi, Martin, et al. "Deep learning with differential privacy." Proceedings of the 2016 ACM SIGSAC conference on computer and communications security. 2016.
- https://huggingface.co/docs/peft/index
- Nguyen, John, et al. "Where to begin? on the impact of pre-training and initialization in federated learning." arXiv preprint arXiv:2210.08090 (2022).
- https://github.com/FedML-AI/FedML/tree/master/python/fedml/data/stackoverflow
- https://huggingface.co/distilgpt2
- Radford, Alec, et al. "Language models are unsupervised multitask learners." OpenAI blog 1.8 (2019): 9.
- https://event.dbsj.org/deim2022/post/tutorial/deim2022_tutorial_T5.pdf