
はじめに
こんにちは!LINEの6週間の就業型インターンシップで、ML室Solution3チームに所属させて頂いた王朔といいます。
簡単に自己紹介をすると、東京大学大学院情報理工学系研究科の修士1年で、機械学習の理論を専門とする研究室に所属していて、個人的には機械学習の解釈性に関する研究をしています。
インターンでは私の研究分野との融合を考えて「MLモデルの解釈性の探究」を1つの大きなテーマとしました。
また今回お世話になったチームではユーザ属性(users' persona)をメインに扱っており、LINEの開発環境自体に触ることや、属性推定の精度を向上をさせることを目的として「family serviceデータを用いた属性推定の改善」というテーマについても取り組むことになりました。
この記事では、これら2つのテーマについて私が得た体験と学びを書いていこうと思います。
それでは第一部として「MLモデル解釈性の調査・探究」についてどうぞ!!
MLモデル解釈性の調査・探究
背景
AIはblack box
一般的な話として、機械学習・深層学習モデル(以後MLモデルと呼ぶ)は基本的にブラックボックスだと言われています。
どういうことかというと我々人間はMLモデルがした予測に対して、「なぜそのような予測をしたのか」や「なぜその意思決定になったのか」を知らないということです。
ただただユーザのあれこれを見抜いて、色々な問いに対する答えだけを言ってくれるオラクルみたいなものだと思ってください。
答えを教えてくれるならそれでいいじゃないかと思うかもしれませんが、こういうモデルは非常に扱いにくいという問題点があります。
例えば、間違った予測をしてしまった時に、どうして間違えたのかのフィードバックは一切ありませんので、モデルの改善がしにくいですし、入力のなんらかの手掛かりを使って正解しているとしても、それを一切教えてくれないので、これはこれで情報不足です。
このような事情があり、世の中ではMLモデルの解釈性(interpretability)や説明性(explainability)に関する研究が進んでいます。
LINEにおける解釈性のメリット
LINEのMLモデルに解釈性を与えると大きく分けて2つのメリットがあります。
- モデルのロジックと抽出されているユーザ層が分かる
- 必要な入力サイズを抑えることができコスト削減につながる
これを理解するために、MLモデルの運用の全体像を見てみましょう。
まずアンケートなどで集めたデータであったり、複数サービス上のユーザの行動履歴(= z_features)を残したりすることで、それをMLモデルの入力データとして活用できるようにします。
z_featuresはdtypeと呼ばれるユーザ特徴量ごとに使用できるように保持されてます。dtypeはサービスのようなイメージで、例えば、スタンプの購入履歴や公式アカウント、広告などの分類があります。
MLモデルを作る際には、必要なユーザ特徴量を選んできてからそのデータを利用して学習させ、評価分析を行うことで実際にプロダクトとしてリリースしていいのかということを決めます。
このようなMLモデルに対して解釈性を与えるということは、実質的には「どのdtypeに注目して予測を行ったのか」という情報を得ることを意味します。
言い換えると、ユーザ特徴量であるdtypeはユーザの行動/性質という情報であるので、MLモデルがユーザのどの行動/性質をみて出力をしているのかということを明らかにするということです。
例えば、A社の公式アカウントがMLモデルでメッセージの送り先を絞ることになったとき、モデルが特に注目している属性(≒ユーザ像)が分かれば、運用方針の観点で圧倒的に楽になります。
これが1つ目の利点です。
2つ目の利点はコスト削減だと言いましたが、先ほど述べた通りMLモデルの作成には必要なユーザ特徴量を選ぶ作業がありますが、特徴量の種類は多岐に渡っており全て使うことは基本的にしません。
また、多くのdtypeを使えば使うほど入力のサイズが大きくなるため、必然的にMLモデルを大きくせざるを得ません。
モデルが大きくなると計算資源を多く使う必要があり、コストが増えてしまって良いことがありません。
そこで「どのdtypeに注目して予測を行ったのか」という情報をもってすれば、必要最低限の特徴量に抑えることができるので、高精度でお財布にも環境にもユーザにもやさしいMLモデルを作ることができるわけです。
手法
ではこのパートから、我々が探究した解釈性の手法についての説明に移ります。
まずLINEで使用されているMLモデルがどのような流れで予測をしているかを見てみましょう。
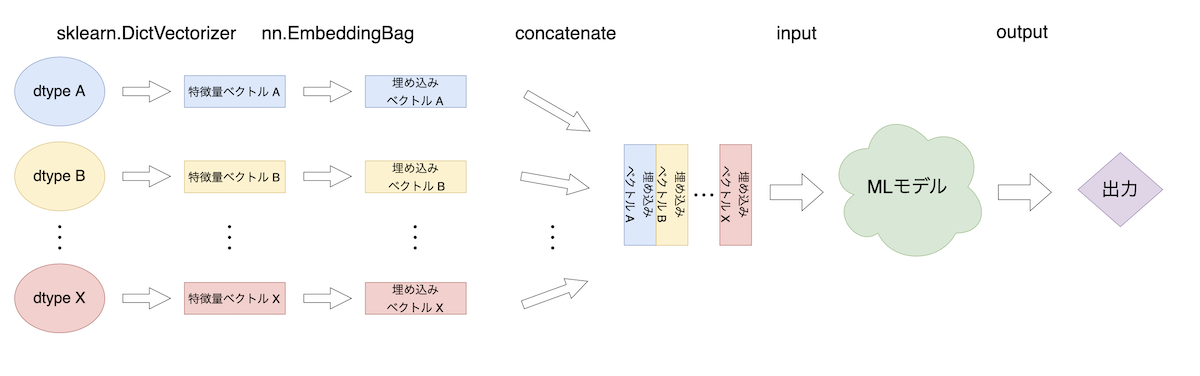
特徴量のdtypeからこれに対応する特徴量ベクトルを生成し、それを埋め込み空間へと写します。埋め込みベクトルはまとめて1つの入力として、MLモデルに与えられ出力を得るといった流れです。
解釈性手法は入力に対する勾配を考慮して重要度を決定する手法がとても多いですが、dtypeによる特徴量は表データのようなもので離散的なため、直接的に微分できるような画像などのデータとは違って勾配を伝播させても意味がありません。
しかし、表データを埋め込んだ後の埋め込みベクトルに対しての勾配を考えれば、勾配を必要とする解釈性手法によってでも各dtypeの重要度を測ることができるため、そのようにして解釈するというのが基本的な方針となっています。
解釈性手法自体は近年の研究によって既にいくつか確立されていて、少し列挙してみると、SHAP、Integrated Gradients、DeepLIFT、Permutation Importance などがあります。
また画像分類などのタスクでは、GradCamやRISEなどの手法が提案されています。
他にも、MLモデルのアーキテクチャ自体を解釈できるものに制限することで説明を与える方針がありますが、モデルを一から作る必要があるのでそのような方針は取りませんでした。
今回のインターンではdtypeの重要度だけではなく、dtypeよりも細かい粒度で解釈性を与える手法を探究しました。
例えば、profileと呼ばれるdtypeの分類の中には更に、性別、年齢、職業などの属性が含まれており、これらの属性に対しても直に重要度を計算できるような仕組みを考えます。
モデルへの入力は表データの形式であるので、これらに対して勾配を求めても意味はなく、既存の解釈性手法を適用するだけでは実現することができません。
そこで我々は微分を用いないランダムサンプリングがベースの手法であるRISEを応用することで、このような仕組みを実現します。
このような仕組みができれば、「職業 > 年齢 > 性別 > ... をMLモデルが考慮して、ユーザに合わせた広告を出している」という説明がついたりして、サービスの改善や傾向の把握に貢献することができます。
RISE
それでは、まずはRISEから紹介していこうと思います。
RISEは「画像分類を行うブラックボックスなMLモデルが画像のどの部分をみて分類したのか」という説明を与える手法です。
下の図のように、画像
これを何度も繰り返した後、スコア
この計算では期待値
つまり、ありとあらゆるマスクのうち、画像の
期待値をランダムサンプリングによる近似計算で求めることをモンテカルロ法といいますが、これはその一種となっています。
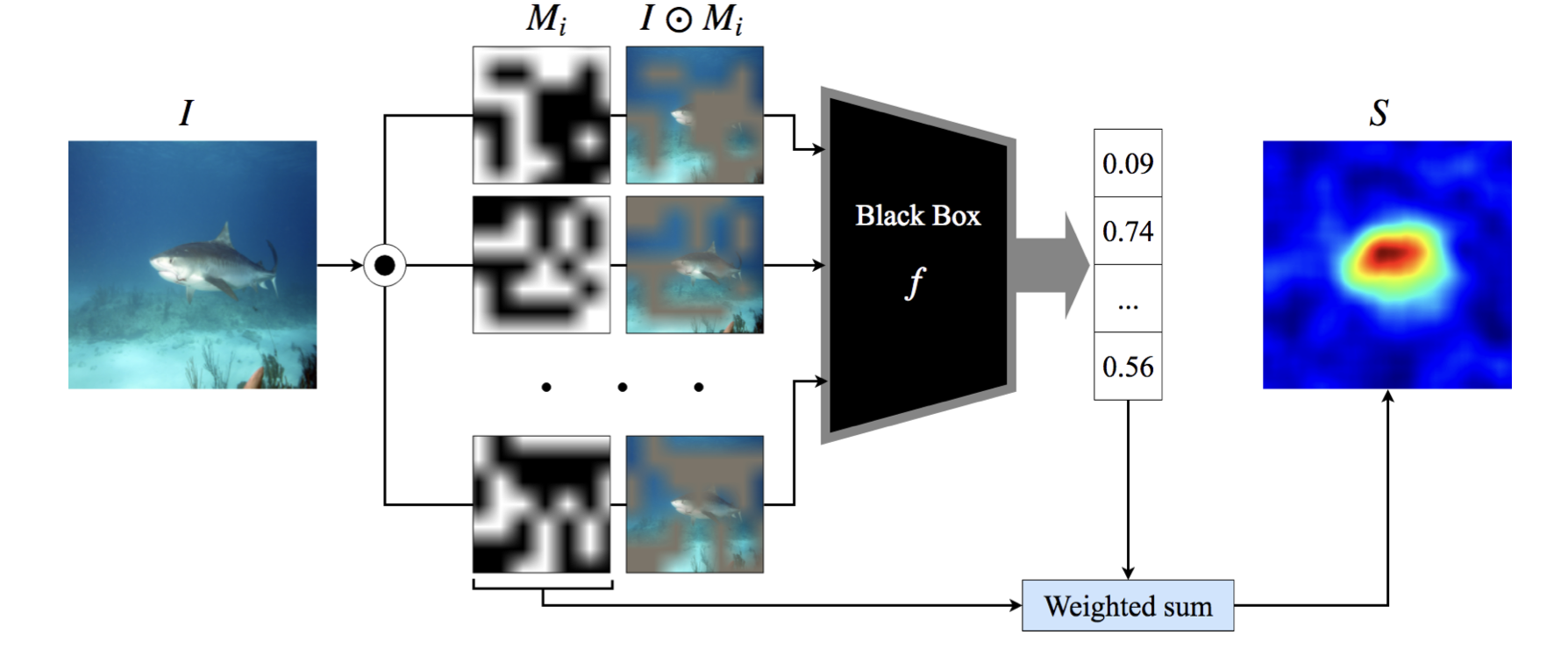
(引用: https://arxiv.org/abs/1806.07421)
dtype への拡張
RISEの仕組みがわかったところで、dtypeより細かな属性についての重要度をどう扱うかについて説明します。
MLモデルの全体像のところでは詳細を省きましたが、dtypeのデータの中身は次のようになっています。
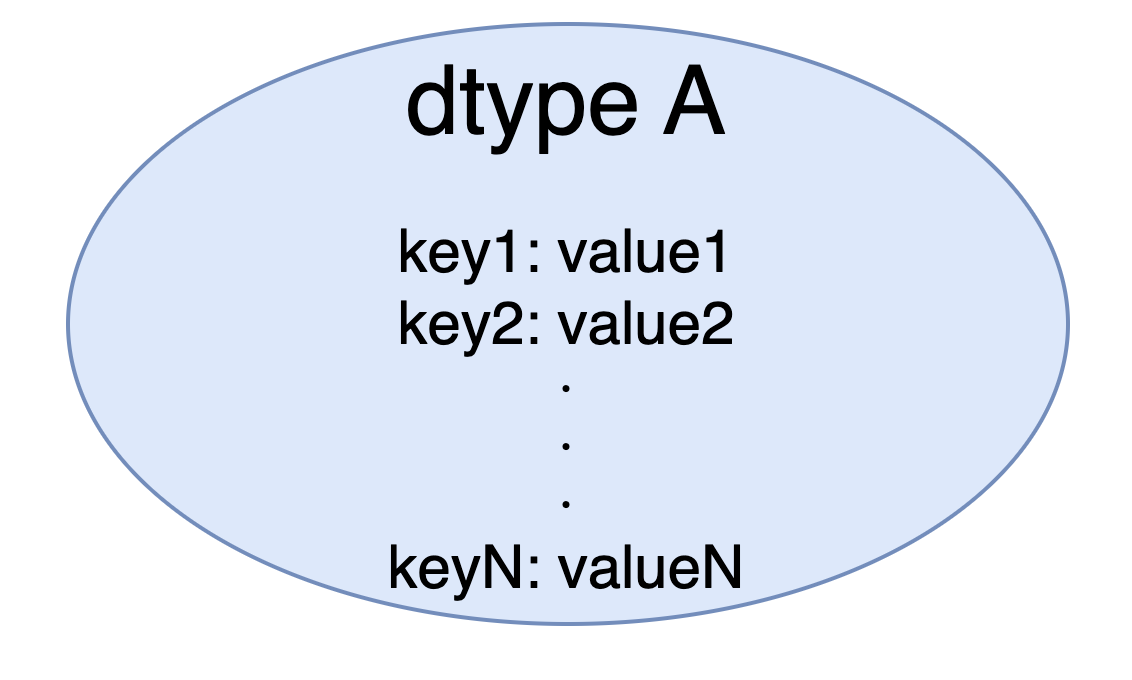
RISEは画像のピクセルに対してマスクを考えていましたが、これを(key, value)に対するマスクを生成するように変更することで、dtypeよりも細かな粒度で解釈性を与えることができるようになります。
最も単純なアルゴリズムとして、全てのdtypeの(key, value)に対してマスクを生成することも考えられますが、モデルへの入力の全てのdtypeが持っている(key, value)の総数は多くなりうるため、単純にこの手法を適用するだけではモンテカルロ法の精度が悪くなり正しい重要度を求めることができない可能性があるという問題点を抱えています。
そこで重要度の計算を3ステップに分けることで、この問題点を解決します。
ステップ1では、dtypeごとの重要度を計測します。この計算では埋め込みベクトル自体を入力だと考え、 Integrated Gradients や DeepLIFT など任意の解釈性手法を適用します。
ステップ2では、特に興味のあるdtype (ここではAとします) を1つ選んできて、その中に含まれる(key, value)だけをマスクするようにRISEの手法を適用します。これによって、A内の(key, value)の分類スコアの期待値を計算しておきます。
最後に、ステップ1で計算されたdtype Aの重要度を、ステップ2で計算された分類スコアにsoftmaxを通したものに従って分配することで最終的な結果を得ます。
ステップ2を1回行うときに考えられるマスクは、
実験
手法のセクションで書いたアルゴリズムの実装を行い、実際に試した結果について書きます。
今回は職業予測タスクを行う簡易的なMLモデルに対しての分析を行いました。
使用されているdtypeは5種類ほどありますが、特に性別, 年齢, 居住エリアなどをkeyとし、valueがその推定値であるようなdtype "demographic"に注目して解釈性を与えてみることにしました。
なお、アルゴリズムのステップ1で用いた解釈性手法はIntegrated Gradientsになります。
- ユーザAにおける結果
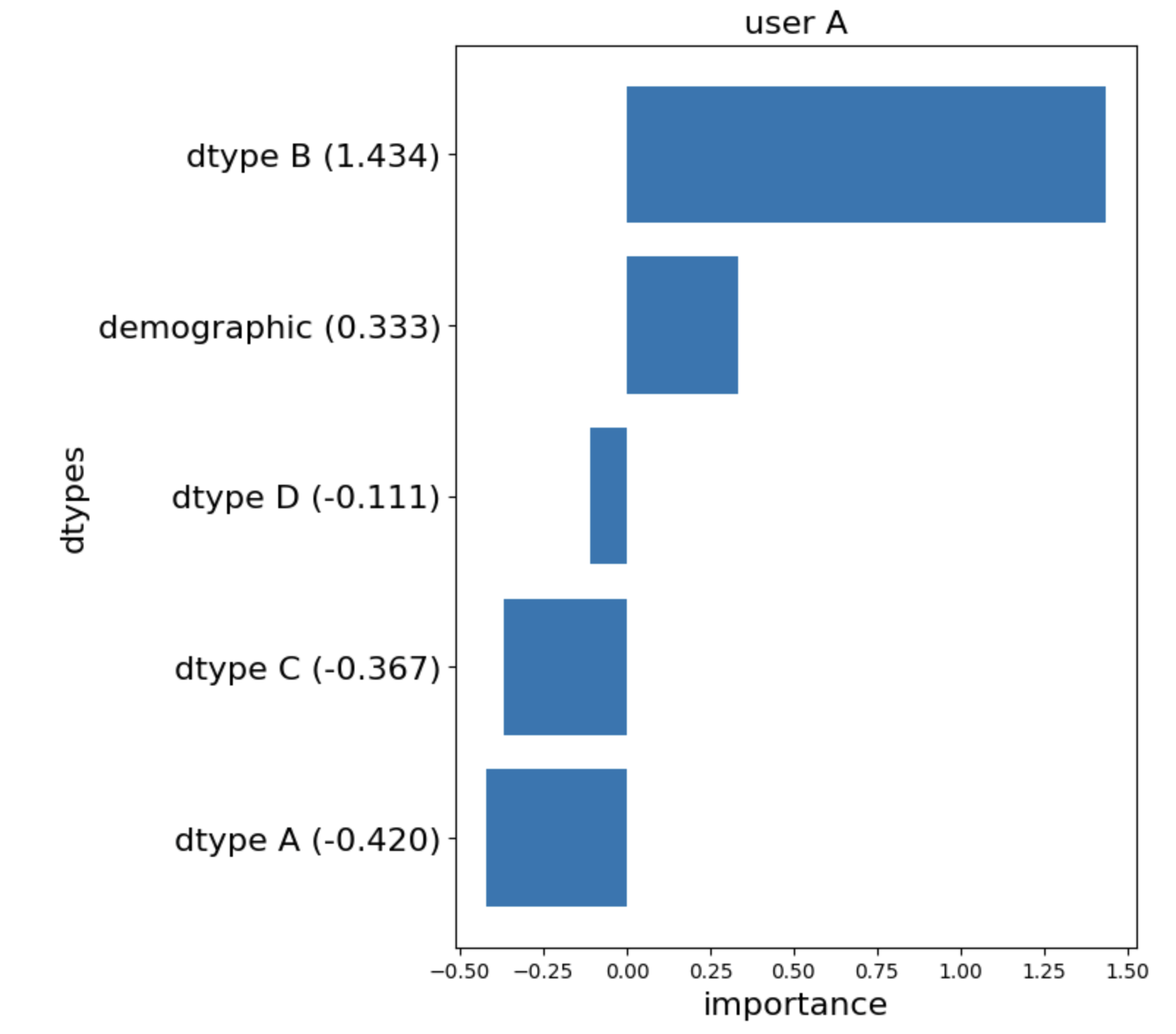
Integrated Gradientsを適用した結果、ユーザAの職業を予測するのに最も重要だったdtypeはBでしたが、2番目に重要だったのはdemographicということが分かりました。他のdtypeに関しては予測を行うにあたって負の寄与をしていることを示していますね。
これはモデルがdtype A, C, Dから想像している職業像とは違う職業にユーザAが就いていたというように解釈することができます。
そしてステップ2として、demographicに含まれている(key, value)についてマスクをしながら分類時のスコアへの寄与度の期待値を求めます。
結果は次の表のようになりました。
softmaxを通しているので、scoreの総和はちょうど1になります。また最終的なimportanceは、scoreとステップ1で得たimportanceの掛け算で算出できます。
この表からはどのkeyも同じくらいの貢献をしているということが見て取れますね。
|
key
|
value
|
score
|
importance
|
|---|---|---|---|
| 性別 | 女性 | 0.37744758 | 0.12569004 |
| 年齢 | 25-29 | 0.33001235 | 0.10989411 |
| 居住エリア | 東京都 | 0.29254007 | 0.09741584 |
他のユーザの場合も見てみましょう。
- ユーザBにおける結果
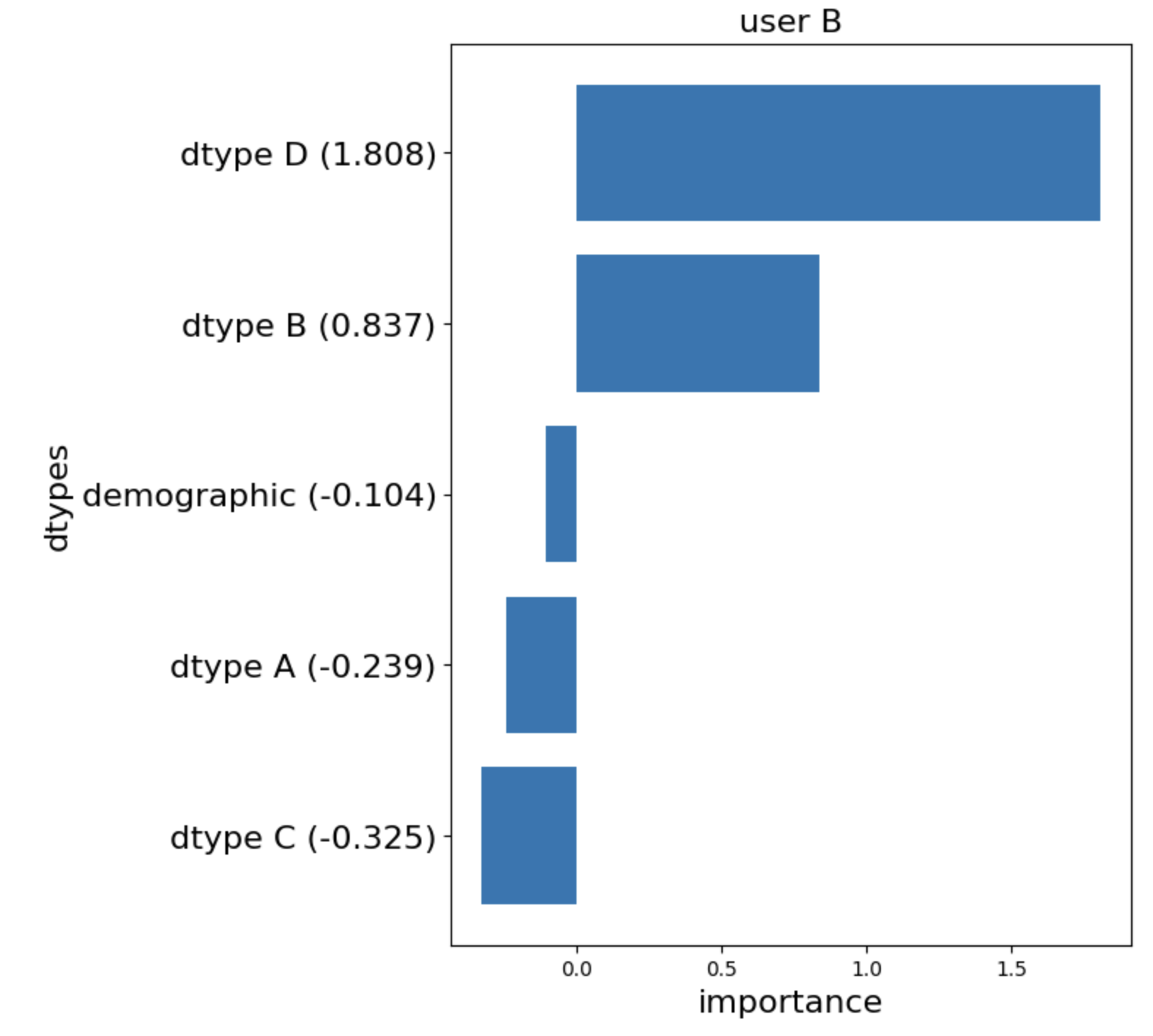
今回の場合は、先ほどと違ってdemographicが予測に悪影響を及ぼしているという例になります。
こちらも分類時のスコアを見ていきます。今回はdemographicが悪影響(=負の値の重要度)を持っているので、重要度の算出には少し注意が必要です。
分類スコアは高ければ高いほど、そのkeyが残っている時に正解に近い予測結果になったという意味なので、単純に掛け合わせると間違った結果になります。
ここでは逆比の形で分配することでこの問題を回避します。
つまり、
|
key
|
value
|
score
|
importance
|
|---|---|---|---|
| 性別 | 女性 | 0.18228641 | -0.04871194 |
| 年齢 | 35-39 | 0.21955502 | -0.04044328 |
| 居住エリア | 愛知県 | 0.59815854 | -0.01484478 |
ユーザBの予測の際は、ユーザAと違って居住エリアに重点を置いて出力がなされているということになります。
逆にいうと、愛知県では何かしらの職業のバイアスが存在しているかもしれないという可能性も考えられます。
このようにMLモデルが何を見て予測しているかの情報がわかると、改善なり運用なりをしていく上で物事を進めやすくなりそうだということが分かると思います。
まとめ
第一部では解釈性手法の探究ということで、LINEのMLモデルの入力に沿った解釈性手法の研究開発を行いました。
dtypeごとという大雑把な重要性に限らず、さらに深掘りした細かな属性についての重要度も算出できるようにすることで、よりサービスを利用しているユーザのイメージを捉えられるような手法を探究してみました。
このプロジェクトでは既存のコードをある程度理解して、そこに組み込んでいくようにコーディングする能力が必要となりました。
コードを1つ1つ紐解いていく作業は、技術的な意味でとても勉強になるものでした。とても楽しかったです。
それでは、次に第二部の「family serviceデータを用いた属性推定の改善」に移りましょう!
family serviceデータを用いた属性推定の改善
第二部では、既存のプロダクトの精度改善を行うために必要なワークフローであったり、LINEで動いている様々なシステムに触ってみるという目的で取り組んだ仕事について書いていこうと思います。
背景
LINEでは、ユーザの属性推定を行うMLモデルは多く存在しています。例えば、皆さんの年齢や性別、職業などが該当します。
このような推定属性は、ユーザひとりひとりに合ったコンテンツを届けられるように活用されています。
しかしながら、MLモデルを訓練するための正解データというのはそう簡単には手に入らないというのが実情であり、アンケート調査の結果などを利用してモデルを訓練するということがなされている状況です。
MLモデルの精度改善は難しい問題の1つであり、多種多様なやり方が存在しますが、今回は最も単純な学習データ数を増やすことで解決しようとしました。
LINEは多くのサービスを持っているため、訓練用の正解データと似た形式のデータを入手することができることがあります。
今回は、LINEのあるfamily serviceから使えそうなデータをアンケート調査結果に加えて学習させようという試みを行いました。
ワークフロー
私が経験した仕事の流れは、データ分析、実験、batch jobを書くことになります。
フローチャートとしてはこんな感じになります。結構単純です。
データ分析はよくある話だと思いますが、ここでは取り入れるデータを様々な観点から見て、それが訓練用のデータとして耐えうるものなのかを検証するという作業です。
この作業によって、外れ値的なデータや明らかに不自然なデータを取り除く目処を立てるわけですね。
そして実験としてMLモデルを訓練して、元々のデータで訓練されていたベースラインモデルとの比較や出力分布全体を確認して、どっちの方が良いかを検討します。
その検討をパスしたら、batch jobというのものを走らせるためのコードを書いていきます。これは定期的に走らせる一連のプログラムみたいなものです。
family serviceデータは日々更新されていくものなので、batch jobで毎日更新できるようなプログラムを組む必要があります。この中ではデータの結合、train/testへの分割、そして訓練の一連の流れを書くことができ、自動的にMLモデルが更新されるようなjobを作ることもできます。今回は実際のプロダクトを更新させるようなことはしないので、データの結合に関するjobを書いてみるというところまでを体験しました。
データ分析
ここでは、年齢や性別などから対象のデータの分布が不自然でないかをチェックし、また登録日と更新日がかけ離れていないかなどをみてデータのフレッシュさに関して確認しました。
他にも、アンケート調査とのデータに重複があった場合に、登録内容に齟齬がないかなども調べたりしました。
情報を登録をする際のデフォルトの生年月日のせいで、その年に生まれたとされるユーザの数が異常に多かったりして、改めてデータ分析の重要性を感じました。
LINEではOASISと呼ばれるデータ分析の"オアシス"となるプラットフォームがあり、データの可視化などを快適にこなすことが出来ました。
実験
上のデータ分析から、基本的にfamily serviceのデータが使用できるということが分かりました。
そこで family serviceのデータとアンケート調査データを合わせて、trainとtestに分割してからモデルを訓練するという実験を行ってみました。
結果は次の表にまとまっています。色付きの文字は、アンケート調査データのみから学習したモデルをベースラインとした時の精度からの増減を表しています。
|
test set
|
accuracy
|
f1_macro
|
f1_weighted
|
precision_macro
|
precision_weighted
|
recall_macro
|
|---|---|---|---|---|---|---|
| アンケート調査 only |
0.5743 (▼2.26 %) |
0.4923 (▼1.78%) |
0.5576 (▼1.69%) |
0.5418 (▼2.49%) |
0.5585 (▼2.06%) |
0.4820 (▼2.07%) |
| family service only |
0.5575 (▲25.95%) |
0.4672 (▲19.38 %) |
0.5420 (▲22.23%) |
0.4992 (▲10.82 %) |
0.5461 (▲8.91 %) |
0.4627 (▲18.32 %) |
| アンケート調査 + family service |
0.5713 (▲19.88%) |
0.4886 (▲18.02%) |
0.5560 (▲18.71%) |
0.5318 (▲16.29%) |
0.5586 (▲9.66%) |
0.4794 (▲10.29%) |
表から分かることは、アンケート調査だけから構成されているテストセットに対しては精度が少し落ちてしまっていますが、family serviceデータに対しては大きく精度が上がっているということです。
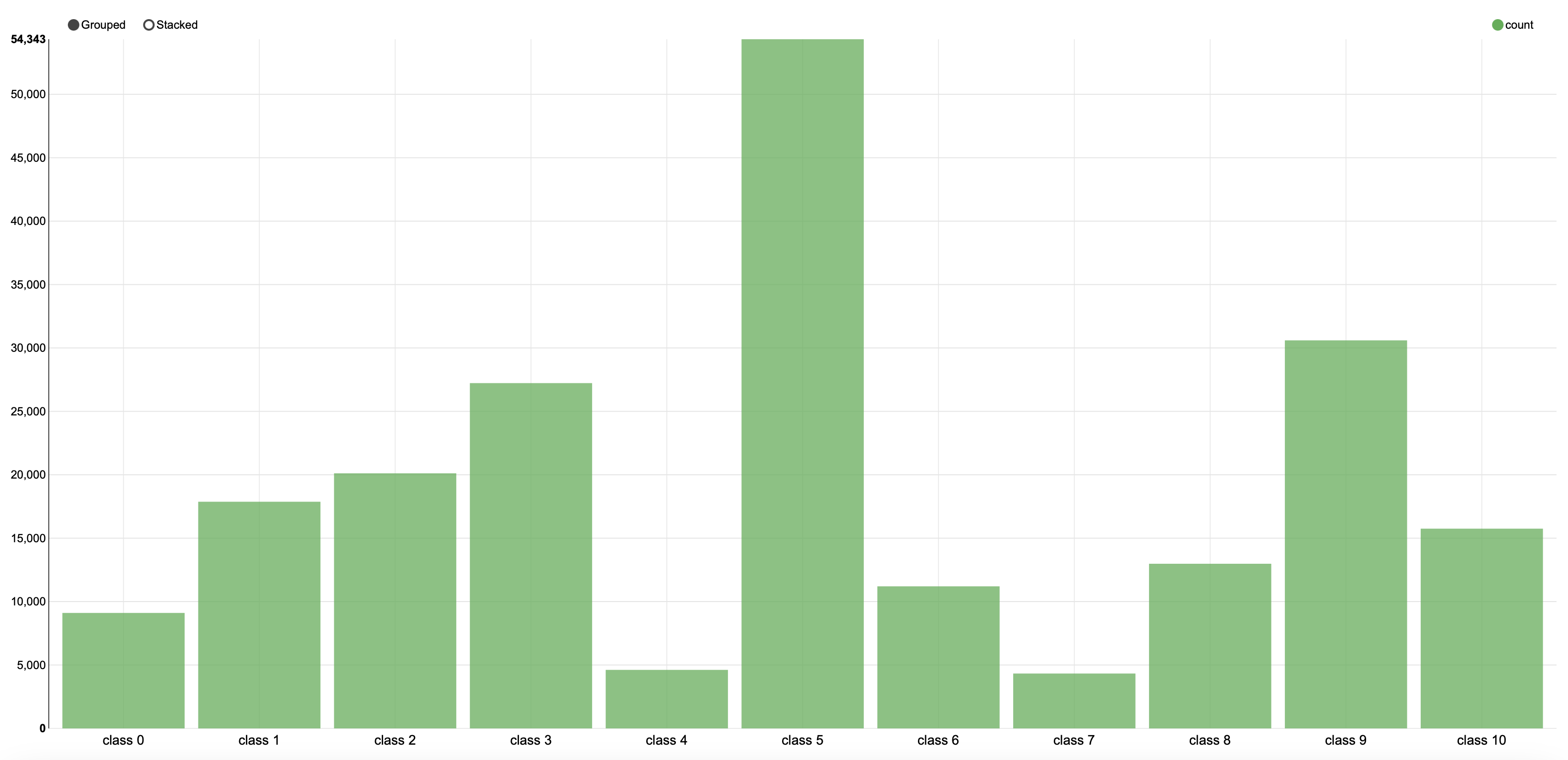
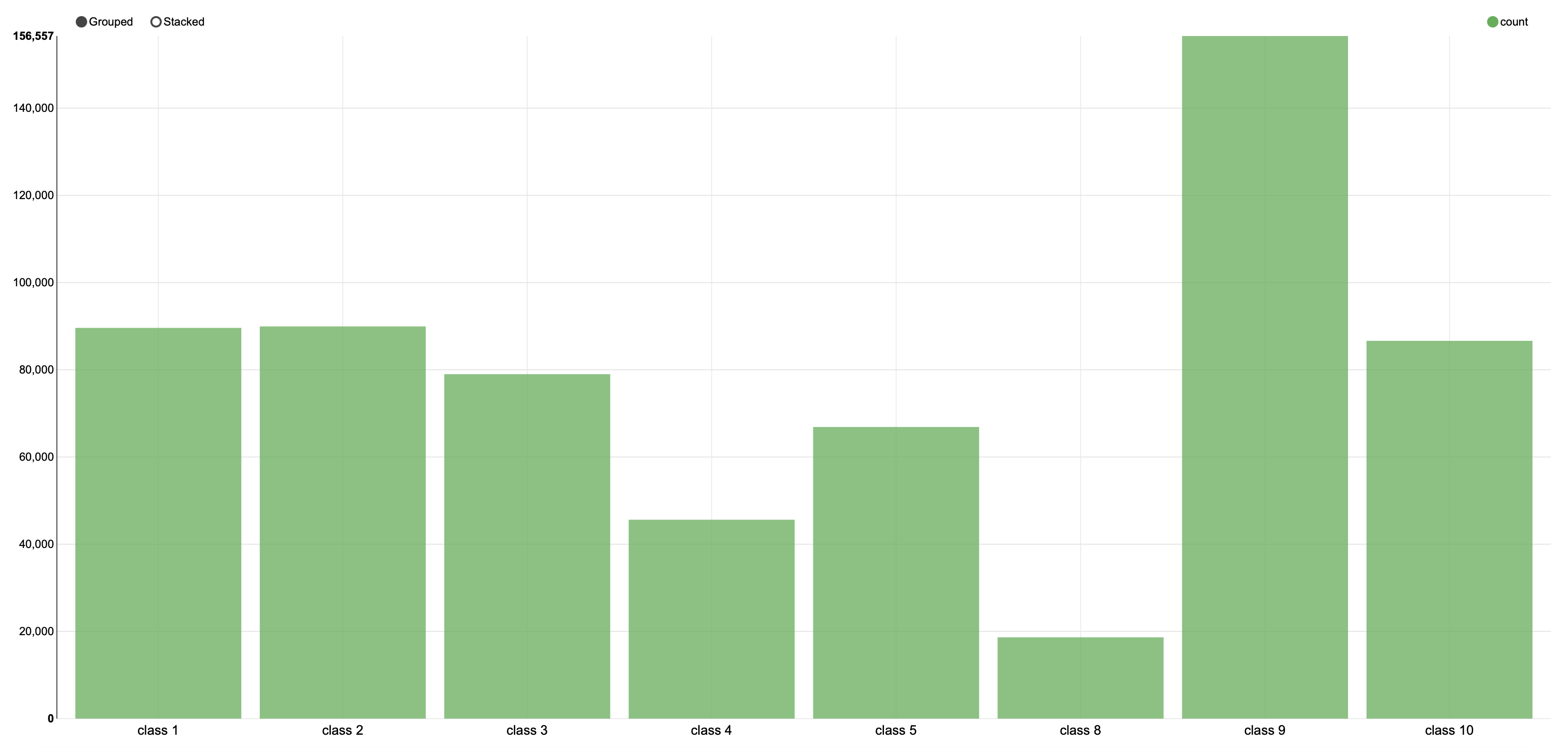
この結果となった理由は、ソースが違う2つのデータ間の分布の違いにあると考えられます。それぞれのtest setを可視化したものは次のようになります。
明らかに分布の仕方が異なることが見て取れます。
|
|
|
|
(アンケート調査) |
(family service) |
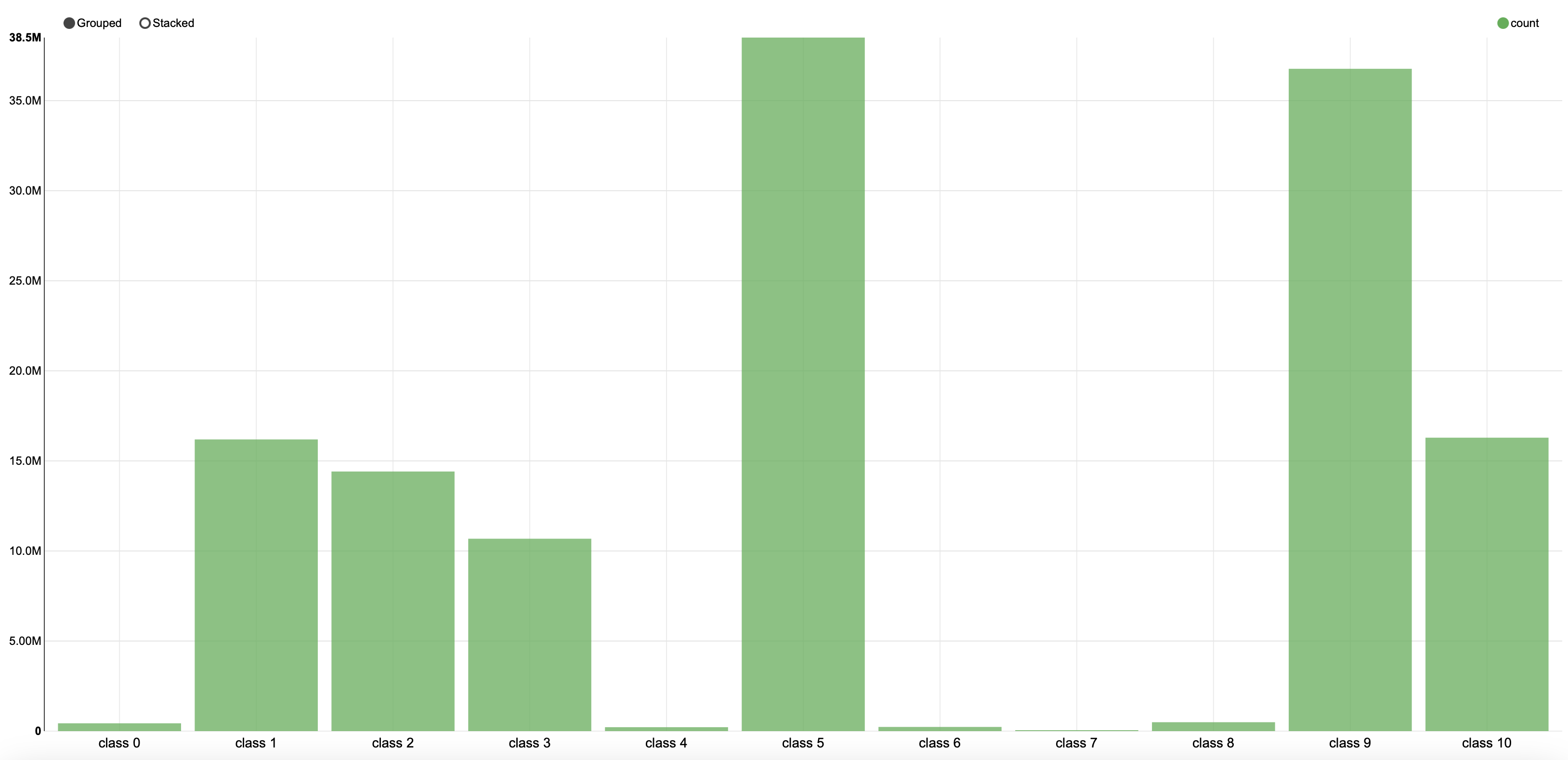
また分布が違うデータを混ぜると、追加したデータのバイアスがかかることになります。
実際に出力分布についても可視化してみると、大きく変わってしまっていることが確認できました。
|
|
|
|
(新しいモデル) |
(ベースラインモデル) |
では、どちらのモデルの方が"良いモデル"なのでしょうか?
元々のタスク、つまりアンケート調査に対する正解だけをみた場合には、ベースラインモデルの方が優れているという結論になりますが、このようにして訓練されたモデルは他のサービスから得たデータに対しては正しい予測がほとんどできていないということが言えます。
とはいえ、新たに訓練したモデルには family serviceデータの強いバイアスが乗った状態であるということもまた事実です。
何らかの公的な調査結果に沿った分布が良いのか、はたまたLINEユーザに合わせた分布が良いのか、という問題は答えのないものです。
時間的制約もあり、今回はこのことを突き詰めることはしませんでしたが、ここからは訓練データに工夫を入れていく作業が必要になっていくことになります。
batch job
ここまでで実験の作業が終了したので、batch jobの方に進んでいきます。
LINEで定期的に様々なjobを実行しているのは、airflowと呼ばれるワークフローエンジンです。
そのため、batch jobの開発は
- job処理のためのスクリプトを書く
- airflowから呼び出すためのコードを書く
- 動作確認
の3段階に分かれています。
さらに、dev環境やbeta環境などで順次試していき、テストを行います。
job処理のためのスクリプト
書くことになったjobのスクリプトは、2種類のデータをマージするものでした。これらのデータはIUと呼ばれるデータプラットフォーム上に蓄積されています。
データをマージする際は片方のデータにフォーマットであったり正解ラベルを合わせないといけないため、慎重に作業を行う必要があります。
また、データ間での同一ユーザに対する処理や、訓練データへの工夫もここに記す必要があります。
実際のスクリプトはPythonで書くことになりました。
特にPysparkと呼ばれるビッグデータに対する高速分散処理を行うライブラリを使ってデータを読み書きをします。このライブラリではSQLを用いることができるので、不慣れながらも、頑張ってマージするコードを書きました。またcuminというライブラリによってdevやbeta環境ごとのデータアクセスの範囲を設けることで、範囲外アクセスを防ぎ、安全な開発ができるようになっていました。
airflowから呼び出すコード
airflowと呼ばれるワークフローエンジンでは、ここに登録されたjob処理のスクリプトを自分で定義した順序で実行することができます。
例えば、マージされたデータでMLモデルを訓練することになった時は、データをマージするスクリプト、データを前処理するスクリプト、MLモデルを訓練するスクリプトを1つずつ順番に実行させれば良いわけですが、
そのようなフローをここで定義するコードを書くことになります。これはDAG(Directed Acyclic Graph)の形で定義されており、実行する順番を明確に決めることができます。
今回の場合は、例に出したような一連の流れこそないものの、データのマージを単発で行うワークフローがあっても良いので、そのようなコードを書きました。
動作確認
そして、最後に動作確認を行います。
airflowでjob実行状態が見れるので、successとなったらデータがしっかりとマージされているのかを確認します。
やることといえば、お祈りしておくくらいでしょうか。
まとめ
こちらのタスクでは、MLモデル運用のより現場的な側面を垣間見ることができました。
問題設定に始まり、データ分析からbatch jobを書くところまでと、LINEでのMLプロダクトに対する理解度がぐんと上がった気がします。
大きなサービスを扱うからこそ生まれるメリットや、そこから現れる課題もあり、大変さを直接肌で感じられました。
第一部・第二部とインターンのお仕事について紹介してきましたが、最後に番外編として感想を書きます。
LINEの雰囲気が少しでも伝わればと思います。
是非、ご覧ください!
【番外編: 感想】
思い出・感想
インターン開始の1週間ほど前でしょうか、貸与PCが来た時のワクワク感はすごかったですね。しかも最新の高スペックM2 Macbook Pro。
そして一度も触らなかった貸与ヘッドセットはなんだったのでしょうか...笑
四ツ谷オフィスに訪れる機会がありました。ここはとても働きやすい環境で、ビルの高いところにあって、ほぼフルリモートだったのが勿体なく感じました。(来年以降は、四ツ谷オフィスではないのでご注意を。)
LINEカフェという場所があって、100円でコーヒーを買えます。いらっしゃいませではなく、お疲れ様ですと声をかけてくれるのは社内カフェって感じがしてええなぁとなりました。
チームで歓迎会と称してホテルビュッフェに行きました。チームメンバーの方と対面でお話しできてとても楽しかったです。料理は最高に美味しかったですが、それがランチだったせいでそのあと働く気力が...
業務に関しては、開発環境に慣れるのが一番大変でした。システムが多すぎて未だに全く全貌を掴めていないです。
また、普段使わないライブラリなども使うのが大変でしたが色々と学ぶことが出来ました。私はSQLを書いたことがありませんでしたが、インターンを経て完全に理解しました。もう怖いものはありません。
よく分からないバグに引っかかった時に、slackで颯爽と現れて似たようなバグの解決法を貼ってくれたチームのR.S.さん。一生ついていきます。ありがとうございました。
基本的にどんな時も、質問を投げるとものすごい速度で返答があります。
自分で調べたほうが早いのか、聞いた方が早いのかでいうと、いつでも聞いた方が早いまでありますが、勉強のためということで自分で調べようとドキュメントを見たりコード読んだりはしてました。(トレードオフとして時間はなくなります。)
社員の皆さんは、本当に楽しそうに働いていました。こういう環境があるのはすごい良い所だなあと素直に感心しました。しかもフレンドリーで溶け込みやすい雰囲気を作ってくださってありがたい限りでした。
また普段では絶対に扱えないような大きなデータに触れたのはとても実りある経験でしたし、大きいサービスに携わることがどういうことなのかも身近に感じることができました。
6週間という長いようにも短いようにも感じられるインターンではありましたが、
日本最大級のサービスを作っているからこそ持っている技術を直接目にすることができたのは、この先の自分のキャリアにとって大きな糧になると思いました。
間違いなくイチオシの夏インターンです。
謝辞
上長の齋藤さん、メンターの馬さん、たくさんサポートをしてくださった伯楠さん、色々と不慣れな私が働きやすいように、すばやく質問対応等をしてくださったり、ミーティングを頻繁に開いてくださり本当にありがとうございました。これから何をしていくのかを明確化しながら仕事を進めることが出来たことは、新しい環境の中でもストレスなく働けた一因であったと感じています。
ML solution3チームの皆さんや、ミーティングで関わる機会の多かった皆さんと一緒に働けて、とてもよかったなと感じています。
改めましてありがとうございました!