
こんにちは、Data Platform室の湯川です。
今回は社内のデータ分析基盤を提供しているData Platform室の紹介をカジュアルにしたいと思います。
どんな人がいるのか、どんな技術を使っているかなどを紹介するのですが、Data Platform室のメンバー(エンジニア)を対象にアンケートを取ったのでその結果について僕の印象をコメントする形で進めたいと思います。
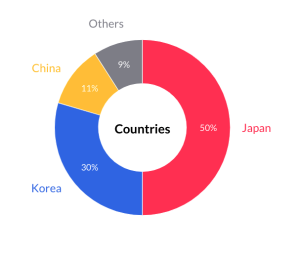
どんな国の人がいるかですね。日本人比率はちょうど半分です。この比率は部署によって結構違っていてほぼ日本人しかいない部署もあれば日本人はほぼいなくて普段の会話は英語という部署もあります。

業務でどんな言語を使うかですね。言語に関してカジュアル面談で聞かれることも多いようなので正確に書きたいと思いますが、ドキュメント(e.g. wiki, pull request description)は英語で書かれることが多く、Slackはchannelによって違いますが英語が多いのと通訳botを使うケースもあります。
会議は日本語が多く必要に応じて通訳の人が入ります。実態としては日本にいる外国人社員はたいてい日本語が喋れるので、日本人が日本語を使うことに甘えているケースは多いかと思います。
まとめると口頭ベースのものは日本語で、writing/readingに関しては英語が多いです。
会社全体でも英語ネイティブの人は少なくて、ドキュメントの共通言語として英語を使う機会があるのかなと思います。
また会社には、日本語、韓国語、英語の3つの語学講座があるので勉強したい場合はこれを活用することもできます。
実際に海外とやりとりする頻度はそんなには多くないですが、韓国、台湾、タイ、ベトナム、中国、とやりとりすることはあります。
ちなみに僕は日本語が喋れて、英語はちょっとわかって、韓国語は読めないけど、韓国ドラマを見たせいか何単語かは聞いたことあるレベルです。
例えば、「あじょし(おじさん)」、「ちんちゃ?(本当?)」、「でー(はい)」、「あにょ(いいえ)」、「けっちゃなよ(大丈夫)」、「みやねー(ごめん)」、「びょんて(変態)」、「いさんいむにだ(以上です)」、「あいげっすむにだ(わかりました)」、「もるげっすむにだ(わかりません)」、「めんぶん(メンタル崩壊)」、「ふぁいてぃん(がんばれ)」などです。結構ありますね。
あと僕はスペインが好きなのでスペイン語の「ビールください!」「Una cerveza, por favor!(ウナ セルベッサ ポルファボール!)」だけは覚えました。
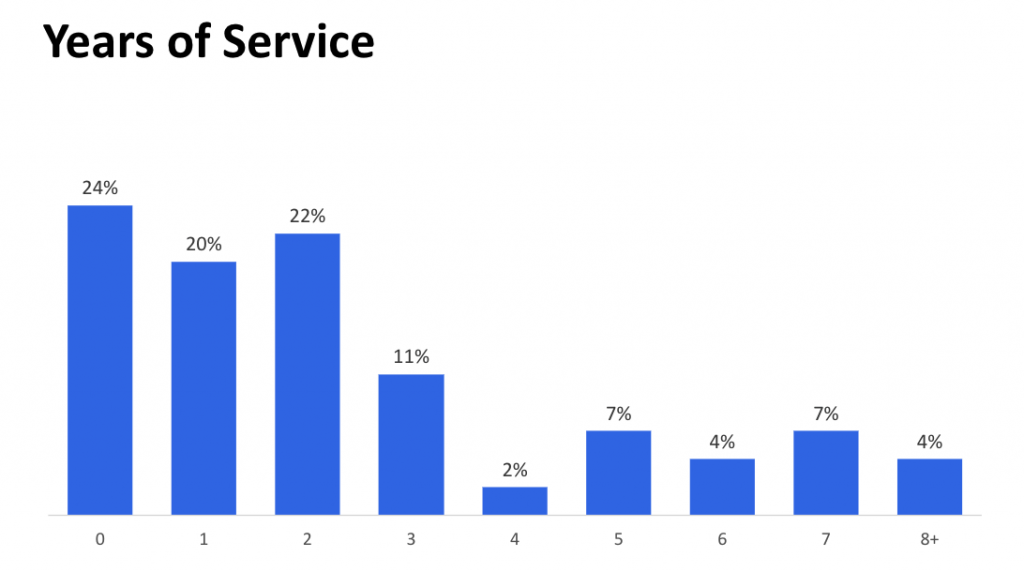
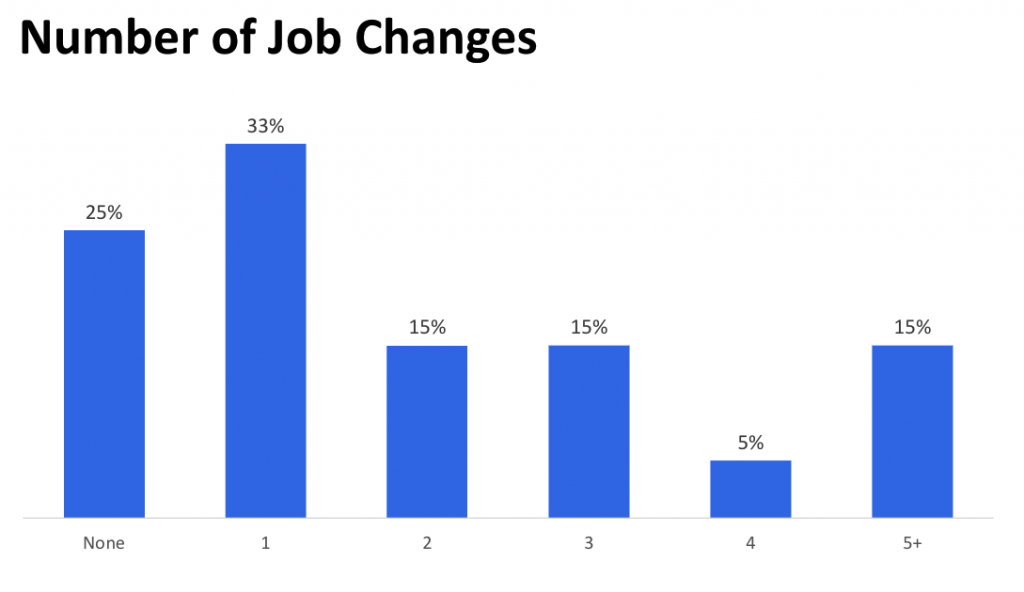
上の画像はメンバーの入社年数、下の画像は転職回数をあらわしています。
LINEは中途入社の人が多いのですが、ここ数年は新卒入社の方も増えてまして、Data Platform室では2018年は1人、2019年は3人、2020年は3人、新卒入社しています。
若いから大事な仕事は任せられないというようなことはないですし、若い人も普通に活躍している印象です。
ちなみに私は入社して8年目でメンバー内では古株ですが、古くからいる人も若手の人も関係なくフラットに開発できる雰囲気作りを心がけています。
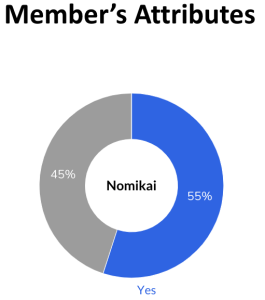
メンバーの属性ですが、飲み会好きの人がやや多いです。IT系の会社っぽい感じはします。
ちなみに僕はどちらかというと飲み会好きです。サンクトガーレンの湘南ゴールドとかよなよなのインドの青鬼とかおいしいですよね。
ビアレストランとしてはキリンシティやよなよなビアワークスが好きです。キリンシティ の「漬けラムのじゅうじゅうロースト」やよなよなビアワークスの「月見ブラックラーメン」は美味しいですよね。
有志でZoom飲み会もほぼ毎週やってます。お酒を飲まなくてもいいし、好きなタイミングでjoin/leaveしてもいいですし、他部署の方もいます。
このコロナの状況だと新入社員がon boardingしづらいという問題がどこの会社もあると思いますが、このZoom飲み会でその辺が少しでも解消できたらいいなと思ってます。
ほぼ毎週やってるせいか、オフィスのカフェでたまたま会ったから雑談するようないわゆるhallway conversation的な風味も少し出ているかと思います。
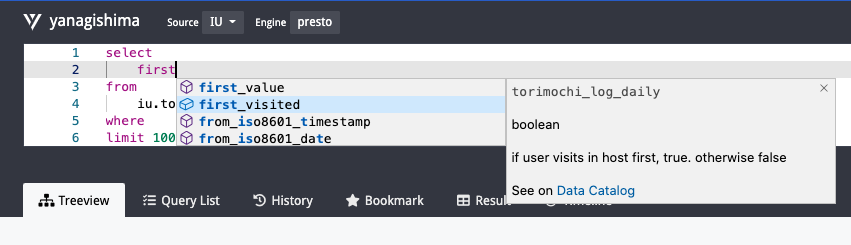
Zoom飲み会からの雑談で社内ツールに機能が追加されたケースもあります。yanagishimaという僕がメインでやってるprestoのweb uiツールがあるのですが、選択行だけ実行する機能もその流れで実装しました。
yanagishimaについては、9月にmeet up https://line.connpass.com/event/188176/ があってその時の資料でも少し触れられています。
ただちょっと補足するとyanagishimaは社内版とOSS版があって、社内版の方が上記の選択行実行以外にもクエリ補完など実装されており、OSS版と全然違います。
社内依存なロジックが多々あるので簡単には切り分けられないという状況です。
たとえばLINEのhadoopクラスタには大量のhiveテーブルがあるため単純にprestoからshow catalogsやshow tablesをすると遅いため、hive metastoreのmysqlを直接参照するAPIサーバー経由でmeta情報をとってくるようなことをしていたり、ユーザがtableに対して書いた注釈、例えばカラムの意味など、をカラム補完時に表示するなどしています。
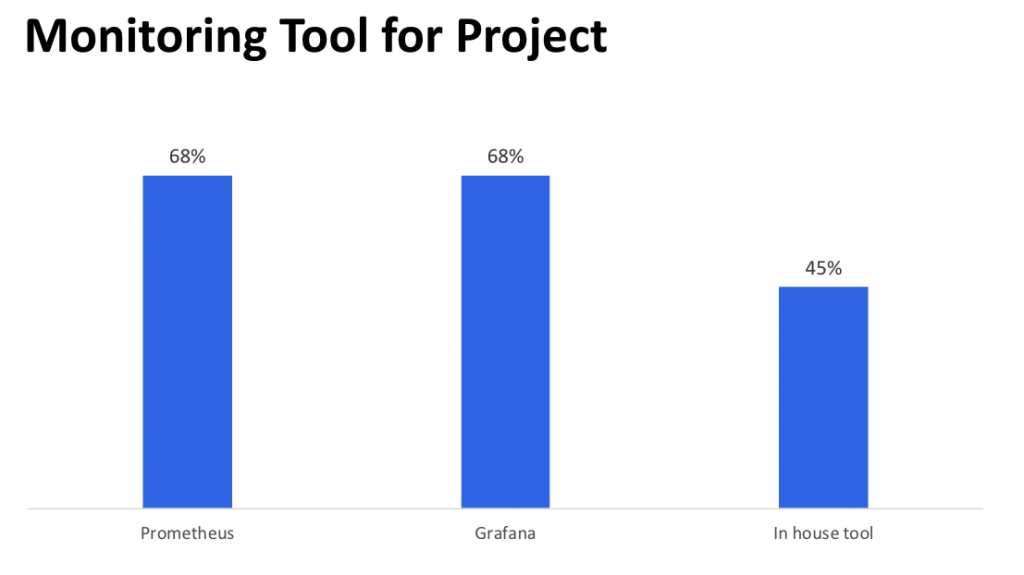
こちらはメンバーが使っているモニタリングツールの割合(100人いたら68人がPrometheusを使っていると回答した)ですが、内製のものとPrometheus/Grafanaというおそらく近年の鉄板モニタリングツールの両方を使っています。
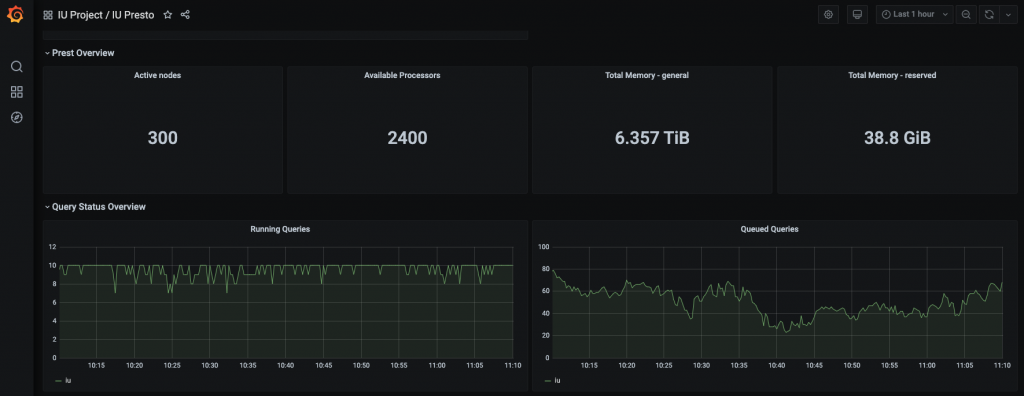
promgenというLINEで開発されたOSSツールを用いてprometheus環境を管理しています。とはいえpromgen/prometheus/grafana自体は別部署で管理しておりそれを使わせてもらっています。https://github.com/line/promgen
LINEはオンプレミス環境なのでdatadogのようなサービスは現在使っていませんが、将来的には変わるかもしれません。
またオンプレミスと言ってもVerdaと呼ばれるプライベートクラウド環境を使っているのでサーバーやMySQLの追加などは比較的簡単にできます。
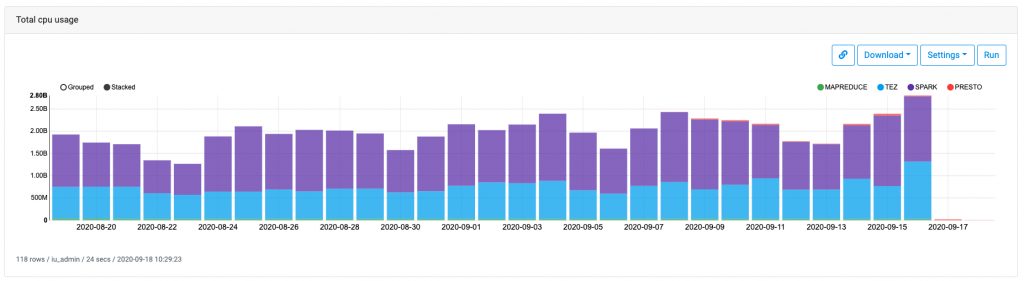
上記モニタリングツール以外だとOASISという内製のBIツールがあってこちらも上記meet up資料で少し触れられていますが、これによってhadoopクラスタのリソース状況をモニタリングしています。
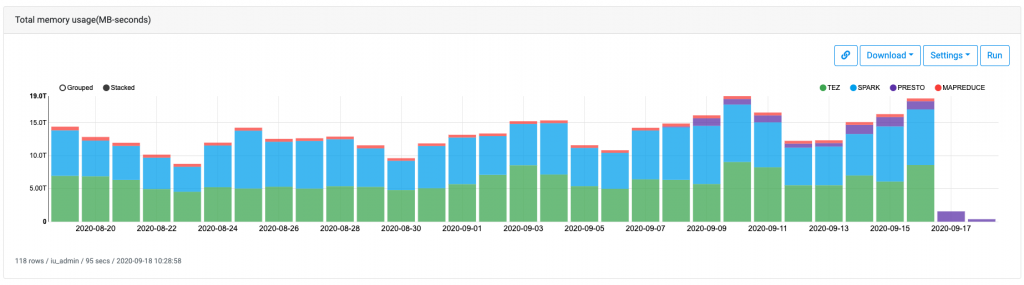
こちらはリアルタイムではありませんが、下記のようにmemory/cpuの使用状況を見ることができます。sparkとtezをメインのエンジンとして使っていることがわかると思います。
mapreduceもsqoopやdistcpでは必要なのでゼロになることはない気がします。
もっと詳しいユーザ利用状況に関してはLINE DEV DAY 2020でのこちらの発表が参考になると思います。https://linedevday.linecorp.com/2020/ja/sessions/0974
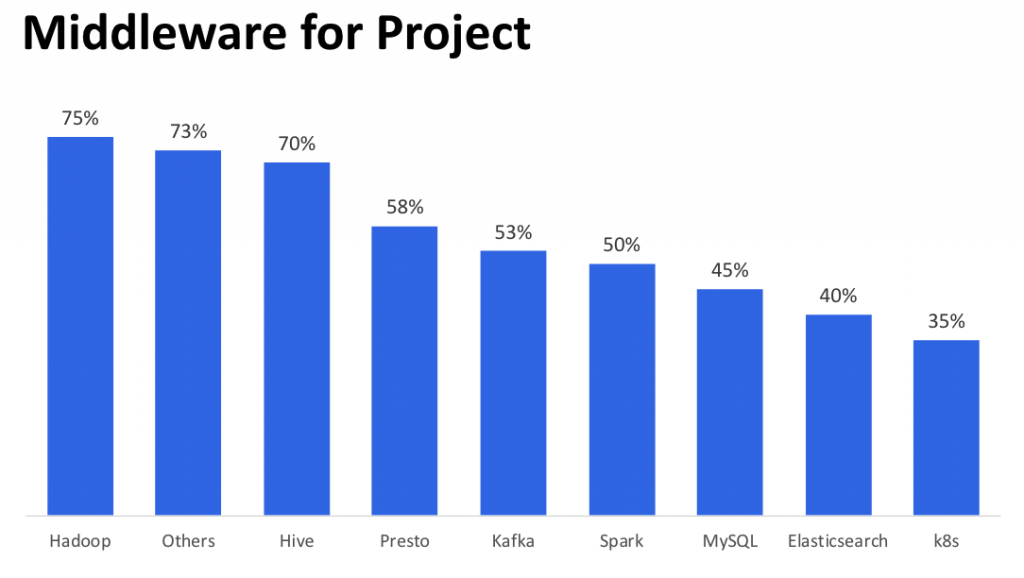
こちらは使っているミドルウェアです。社内ではhadoopをベースとした分析環境を提供しているので、その意味ではHive/Presto/Kafka/Sparkといったおなじみのミドルウェア群が並んでいると言っていいかもしれません。
Prestoに関しては社内にコミッタもおり、LINEでのPresto使用状況に関しては、Presto Conference Tokyo 2020 (Online) で発表がありました。https://techplay.jp/event/795265
k8sについては社内でもマネージドなKubernetes環境があるので今後増えていくと思われます。
使っているサーバーの台数は合計約2500台あります。
Elasticsearch環境を社内ユーザに提供している場合は自分たちでElasticsearchを運用していますが、hiveのログを集めてチェックするようなケースではVESという社内のmanaged Elasticsearchを使っています。
仕事で使っているフレームワークとプログラミング言語です。サーバーサイドではJava+Springを使い、ちょっとしたスクリプティングにはPythonを使うケースが多いです。
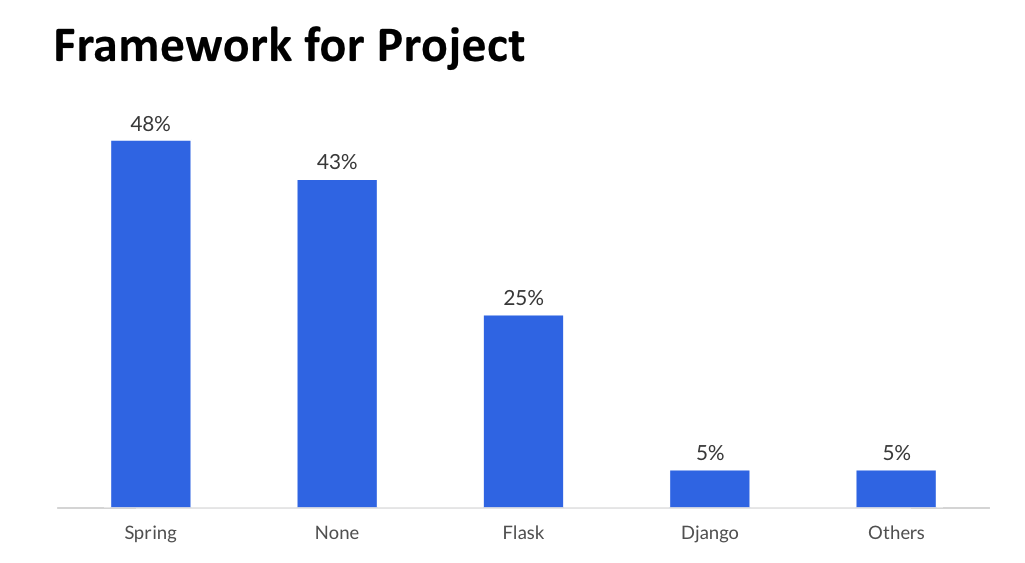
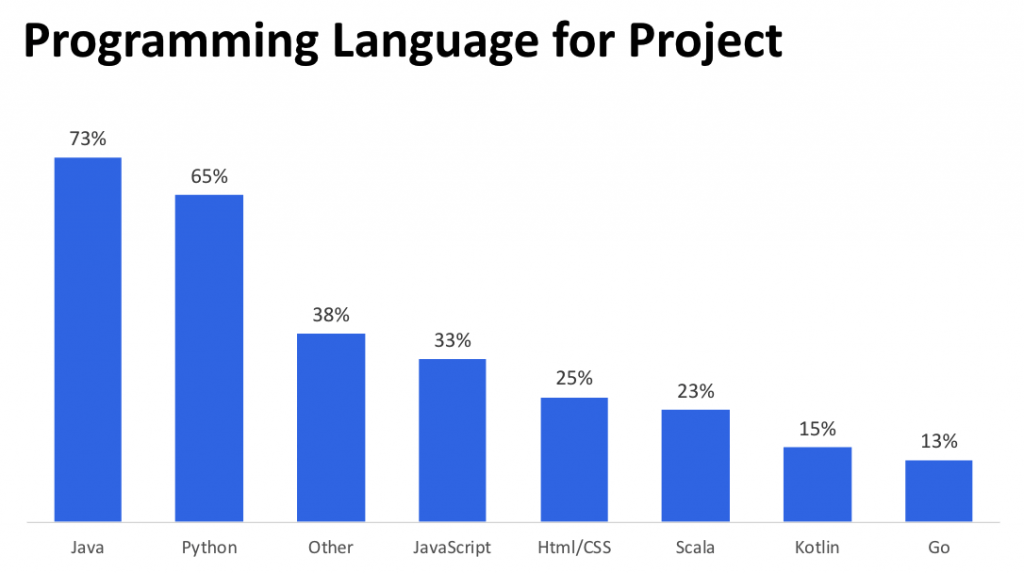
新しくツールを作る場合はJava 11で開発することが多いと思います。
あとJavaでコードはあまり書かないけど、読むのは多いというケースもあります。
例えばHiveやPrestoなどでユーザから何か動かないという問い合わせがきてソースコードを読んで設定変更などのworkaroundがないか調べるといったパターンです。
例えばhive on tezクエリが重くてApplication Masterがうまくリソースを確保できないという問題があって、
set hive.exec.orc.split.strategy=BI を指定することで回避したというものです。
このオプションはApplication MasterがORCファイルを読んでmapper数をどう決めるかというものなのですが、BIを指定することでファイル自体は読まずファイルサイズだけで判断するのでメモリを大量消費することはありません。
hive.auto.convert.joinとかもそうですが、大半のケースでは有効なメモリに依存した高速化オプションもエッジケースではマイナスになることはよくあります。
batchは安定可動することが大事なので、例えば30分かかっていたdaily batchが高速化オプションによって20分に短縮されてもメリットは大きくないと思います。それでリスクが増えるならむしろ30分のままの方がいいと思います。
ただこれが3時間が1時間になるようなケースだとまた話は変わってくるので、ケースバイケースではあります。
設定変更だけではなく、本家にpatchを送ることもあります。例えば https://github.com/prestosql/presto/pull/4211
これ自体はニッチなケースだと思いますし、直接はPrestoの問題じゃない気もしますが、我々の環境ではPrestoをアップグレードする際のblockerになっていたのでpatchを送って取り込まれ、無事アップグレードも完了しています。
このhiveとprestoのトラブルシューティングは2019年新卒入社の若手がやっており、僕がすごいなと最近思った例です。
https://engineering.linecorp.com/ja/blog/data-infrastructure-ingestion-pipeline/ で紹介されたData Infrastructureチームだとそういった仕事が割とあります。
Pythonに関しては、スクリプティング以外だと社内ツールのwebアプリケーションに使われるケースもあります。
JavaScriptフレームワークとしてはVue.jsを使うことが多いです。上で紹介したOASISやyanagishimaもVue.jsでフロントエンドは実装されています。
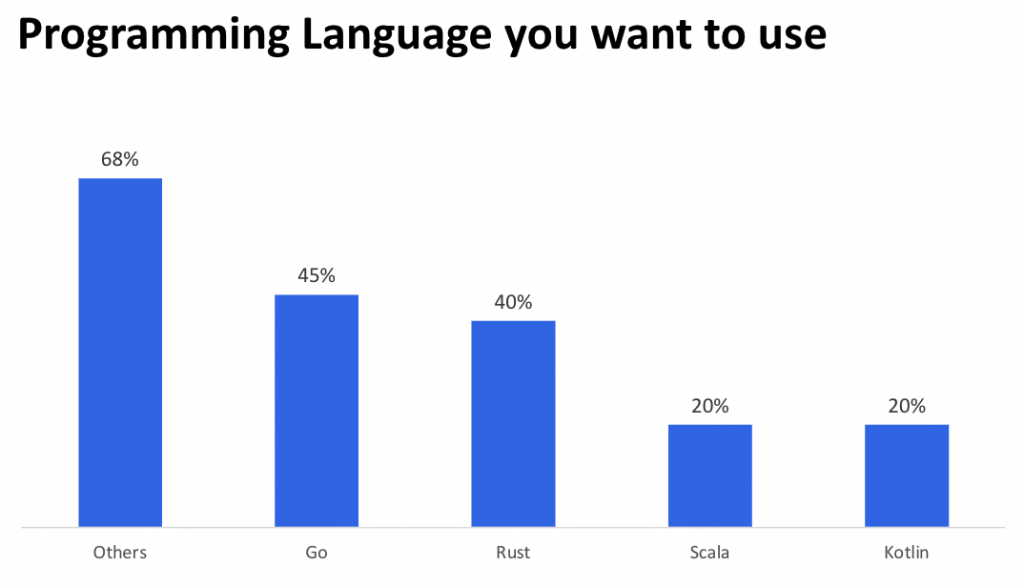
こちらは機会があれば今後使っていきたい言語です。Kotlinはわかるような気がしますし、実際KotlinでAPIサーバーを実装するケースは増えています。
AndroidアプリではなくサーバーサイドでもKotlinを使っているということです。
また最近 https://github.com/JetBrains/kotlin-spark-api のようにKotlinでSparkアプリケーションを実装するという試みも始まっているようで気になりますね。
ScalaもFlinkアプリを実装するときなどに使われています。Goはprometheusのexporterやコマンドラインツールを実装するときに使われています。
Rustに関しては現時点では仕事上使う機会はほぼ無いような気はしますが、https://github.com/apache/arrow/tree/master/rust/datafusion のようにRustで実装されたin memory query engineも出てきているので、今後はData Engineering分野でも活用されるかもしれません。
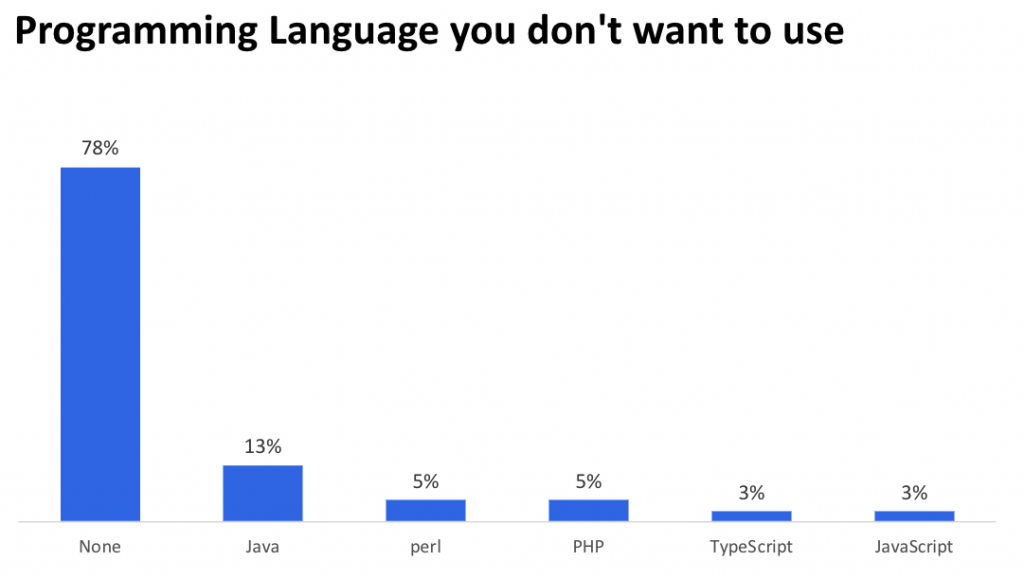
こちらは逆にもう使いたくないと思ってる言語です。皆さん特に無いようです。Javaがちょっと高いですが、これは単に今Javaで仕事してるから飽きたとかな気がします。
以上です。Data Platform室でどんな人が働いていて、どんな技術を使っているかのイメージが伝われば幸いです。