
LINEの開発組織のそれぞれの部門やプロジェクトについて、その役割や体制、技術スタック、今後の課題やロードマップなどを具体的に紹介していく「Team & Project」シリーズ。
今回は、LINEグループ全体のデータ関連業務で根幹になる戦略づくりや開発業務を担当しているData Platform室から、データ基盤の開発をしている「Data Infrastructureチーム 」とData ingestion pipelineを開発する「Ingestion Pipelineチーム」をご紹介します。Wang Tianyiと齋藤智之に話を聞きました。

LINEのプラットフォーム上では、多様なサービスの中から、非常に多くの種類の大量のデータが日々生成されています。このデータを次のサービス・ビジネスに繋げ拡大するため、横断的に大量のデータを対応する組織として「Data Science and Engineeringセンター」が立ち上がりました。今回紹介する2つのチームは「Data Science and Engineeringセンター」組織内にあるData Platform室で、LINEグループを含む全社でData Platformを利用する、全ての人に有益なデータ活用の環境を提供するための開発と運用をしています。
―― まず、自己紹介をお願いします。
Wang:Data InfrastructureチームのリードのWang Tianyiです。私は中途で入社して4年目になります。データ基盤の様々なミドルウェアの運用と開発に携わっています。
齋藤:Ingestion Pipelineチームの齋藤智之です。私は新卒で入社しました。今年で6年目になります。主にデータ基盤へのデータの取り込みをサポートするData ingestion pipelineの開発をリードしています。
―― みなさんがLINEに入った理由を教えてください。
Wang:大規模ならではの技術課題に取り組んでいきたいと思ったのが一番大きな理由です。私は学生の頃からデータに関わる開発に取り組み、前職ではデータの基盤を利用するユーザの立場でサービス開発を担当していました。データに関する自分のスキルをもっと生かして、世の中に価値を提供していきたいと思いLINEに入社を決めました。
齋藤:ユーザ数が多く、大規模なシステムの課題に取り組めるのはLINEならではですよね。私も大規模システムの開発に取り組むことができ、高いエンジニアリングの技術を要求されるところに大きな魅力を感じました。常に難しい課題に挑戦でき、一緒に解決するエンジニアに囲まれた環境で働くことができるので毎日がとても刺激的です。
―― LINEで働くやりがいを教えてください。
Wang:私たちが開発しているプラットフォームは、通常パブリッククラウドの会社などが提供しているものを使用するケースが多い領域です。実は内製している会社は大変珍しく、ビッグデータを取り扱う業界の最前線で開発ができることは大きなやりがいに繋がっています。また、大規模開発ならではのscalabilityのボトルネックとなる箇所を迅速に発見し、最適化することもできます。最新の機能を使うので、今まで遭遇したことのないバグを発見することも多く、そのバグを一つ一つ自分で解決していくのはとても面白いですよ。OSSにコントリビューションするチャンスも多いです。
齋藤:Data Scienceや機械学習など、データを扱う業界は今めまぐるしい速度で発展しています。クラウドサービスもどんどん進化する中で、速度の速い業界に身を置き、自ら新しいニーズをキャッチアップしながら開発ができることはとても面白いです。リアルタイム処理などの新しい課題にチャレンジできる環境もやりがいの一つだと思います。
―― チームの構成・役割などについて教えてください。
Wang:Data Infrastructureチームの主な役割は、Storage, Computation Resource, Message Blocker などビッグデータ基盤を構成する基本的コンポーネントの開発と運用です。
Data Science EngineerやMachine Learning Engineerは、生データを直接触って開発することもできますが、それでは開発や分析の効率が悪くなってしまいます。私たちはデータを扱うエンジニアの人たちが、効率よく分析や開発できるためのIU Data PlatformというProductを社内で提供しています。このIUクラスターは約2000台のサーバーがあります。ビッグデータ基盤を構成するコンポーネントに求められるものは、安定性と効率です。この2000台という数だけを見るとすごいな、と思う人も多いと思いますが、それぞれのクラスターのパフォーマンスを100%もしくは120%を出すために、日々課題に取り組んでいます。
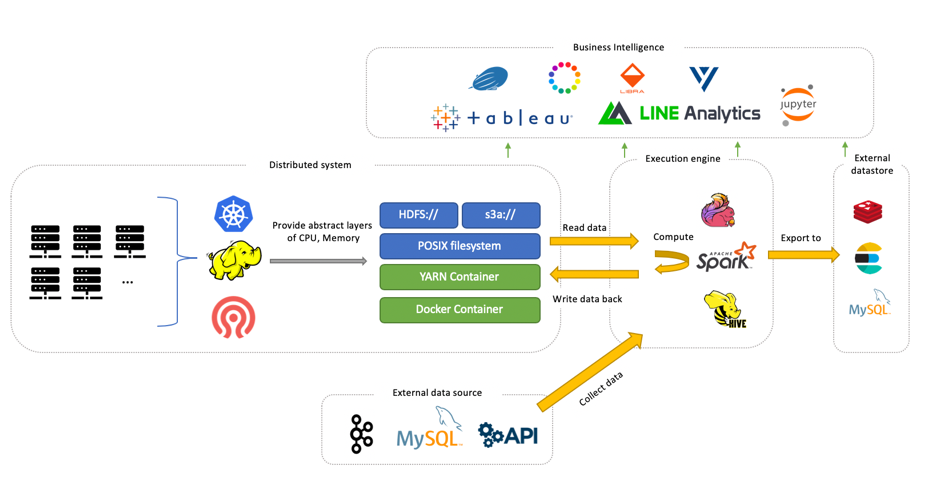
齋藤: Ingestion Pipelineチームは主に、IUのストレージにデータを取り込むためのセルフサービス・データ処理システムの開発・運用をしています。データの取り込みには、様々な種類のストレージへの対応、データスキーマの変更のサポート、データの流出や遅延の防止などの課題があり、これらを解決しながら大容量データ・多様なデータセットに対してスケールするシステムの開発が求められています。
イベントログをストリーム処理して取り込むシステムでは、みなさんが使っているLINEのメッセンジャーのサーバサイドログも収集しています。システムで取り込まれるデータの総量はピーク時秒間1200万レコード、1日あたり6000億レコードを超えます。
データを取り込むシステムは、データを取り込む先のストレージの性能に影響を受けるため、効率よく安定した処理が行えるよう、Data Infrastructureチームと連携して開発・運用しています。
―― チームメンバーを紹介してください。
Wang:チームは社員が9名、プラットフォームを提供してくれているパートナーのClouderaのメンバー含めて全部で12名で構成されており、入社年数が2〜3年くらいの人が多く、平均年齢が30代前後でとても若いのが特徴的です。
齋藤:私たちのチームは、インド、台湾、韓国、中国、日本の国籍のメンバーで構成されており、10人で開発をしています。Data Infrastructureチームよりは平均年齢は少し高く、多様な人たちが働いています。
―― 利用技術・開発環境について教えてください。
Wang:Data InfrastructureチームとIngestion Pipelineチームでは開発環境はだいたい同じですが、利用技術については少し違いがあります。
| 利用技術、ツール | Data Infrastructureチーム | Ingestion Pipelineチーム |
| Hadoop Ecosystem | HDFS, YARN, Hive, HBase (Hadoop 3.Xを利用) | ー |
| Data Governance: | Ranger, Atlas | ー |
| Deployment | Kubernetes, Docker, Ansible | Kubernetes, Docker, Ansible |
| Streaming | ー | Flink, NiFi, Kafka Streams, Flume |
| Processing | ー | Sqoop, Spark |
| Storage | Kafka, HDFS, Elasticsearch | |
| Framework: | ー | Spring Boot |
| Language | Java, Kotlin, Python, Go | Java, Kotlin, Python, Go |
| Other | Kafka, Presto, Spark, Airflow, | Scheduler: Airflow |
―― 今のチーム課題と課題解決に向けた取り組みを教えてください。
Wang:私たちのチームでは、主に3つの課題について取り組みを進めています。
まずは1つ目の課題は「マルチテナントのクラスターの運用」についてです。 Hadoopは一般的に、有数のユーザと予測可能なワークロードで運用されていますが、LINEのData OpenによってDAUが700人弱であり、且つワークロードも10万+/日となっています。Isolationがまだ完備されていないので、ユーザ間にリソースの競合が発生している状況です。
2つ目は「Data catalog」についてです。ユーザが自由にデータを生成したり利用したりする環境においては、データのカタログがとても重要です。そのため、Data Lineageを自動的に生成する仕組みが必要となってきます。
そして「大規模のインフラを効率よく運用すること」も私たちの課題です。私たちは去年まで、チームメンバーの6人で約2000台以上のクラスターを管理していました。少数精鋭のチームはとても効率が良いのですが、今年からKafka, Elasticsearchに関わる対応 も私たちのチームの管轄に入ってきたこともあり、より新しい技術の検証や導入と他の開発に力を入れていく必要があります。そのため、今より更に効率よく運用をしなければならないと思っています。
これらの課題を解決するために私たちは以下の取り組みを進めています。
マルチテナントのクラスターの運用
- クラスター全体のObservabilityを向上しNoisy Workloadを抑える
- SLAに基づいたYARN、Prestoの最適化
- Kubernetesを活用してIsolationを高める
Data Catalog
- Hive Hooks、 Apache Atlas APIを実装してData Lineageを自動的に生成する(Work in Progress)
大規模のインフラを効率よく運用すること
- 自動化してヒューマンオペレーションを最小限にする
- Monitoring、 Alertingを継続的に改善して不要不急なオペレーションを減らす
齋藤:私たちのチームでも大規模インフラを効率よく運用することは課題の一つです。プラットフォームを利用するサービスが増え、データの種類が増えていく中で、今までは起きていなかった問題・懸念点が出てきています。システムがスケールし、オペレーションの面でもマシンリソースの面でも効率的に運用できるよう、新しいアーキテクチャの設計・開発を進めています。
チームではデータ取り込みのセルフサービス化を目指していますが、まだまだ課題は多いです。バッチ処理でデータを取り込むシステムでは、Web UIが実装されていないデータソースについては、問い合わせを受けてプラットフォームのエンジニアがジョブを設定しています。このやり方ではコミュニケーションコストが高く、データを利用するまでに時間がかかり、また、プラットフォームを運営するエンジニアも対応に追われて開発の時間が取れなくなってしまいます。データ利用者自身がジョブを設定できる利用用途を広げられるように、Web UIの開発やジョブの実行エンジンの開発、ジョブ実行の自動化のための開発をしています。
ストリーム処理のデータ取り込みシステムでは、データ変換の要求や、データが取り込まれてから利用できるようになるまでの時間を短縮して、よりリアルタイムで分析をしたいという要求など、まだ実現できていない要求があります。プラットフォームとして提供するには、現実的なサービスレベルや運用コスト、提供されることで解決される問題の価値などを検討して解決方法を選択する必要があります。これらの課題に対して、データの業界で同様の課題に取り組んでいる例についてのインプットを得ながら、新しいアーキテクチャの模索・検討も進めています。
大規模・多様なデータに対するスケーラビリティ
- 新しいアーキテクチャの導入検討
セルフサービス化
- 新しいデータソースのサポート
- システムの自動化、安定化
リアルタイム性などの新しい要求
- データ業界の最新の取り組みのインプット
- 新しいアーキテクチャの模索
―― 今後のロードマップを教えてください。
Wang:私たちは、ビジネスニーズに応えるために提供するミドルウェアの種類を増やしてそれぞれのミドルウェアの強みを生かした開発を進める必要があります。例えば、KV storageのHBaseの運用はまだ課題がありますが、Block storageのHadoopは安定的に運用できているので、Object storage、Steaming処理に得意なstorageを提供していかなくてはいけません。その他以下の内容を目標として取り組んでいます。
YARNとKubernetesのバランス取る
- ビッグデータ界隈はまだHiveとYARNに依存性が高いものの、Spark on Kubernetes、Flink on KubernetesのようなKubernetesにシフトしていく動きも見せている
- ワークロードをどうKubernetesに移行できるかに取り込む
Workload Optimization
- Hive、Spark、Presto etcのJobを効率的に動かす施策
- システムの無駄減らす
- 例えばYARNのContainerのOrchestrationの時間を減らしたり、Query Optimizationを工夫したりして同じマシンリソースでより多いworkloadを駆動するなど
齋藤:私たちのチームでは、先ほどお話ししたように、データ利用者が必要なデータを早く分析に利用できるよう、データ取り込みのセルフサービス化を進め、コミュニケーションコスト、運用コストを減らすことを目標にしています。また、LINEがデータ業界をリードする会社になれるよう、新しい分析の要求に応えられるシステムの設計・開発も、優先度の高い目標と考えています。
データプラットフォームの提供はまだまだ始まったばかりです。それぞれのチームが持つ役割と課題を解決しながら、連携してよりデータが活用できるサービスを私たちは開発していかなくてはいけません。

―― 最後に、Data InfrastructureチームとIngestion Pipelineチームに興味を持ってくれた人にメッセージをお願いします。
Wang:分散型システムに興味あればDIチームは非常にマッチングすると思います。OSSとEnterpriseのclusterの接点を体験できて改善をしていける環境を提供できます。
齋藤:Ingestion Pipelineチームには、新卒入社時にチームに加わった方もいれば、経験のないところから新たにストリームデータ処理にチャレンジしようとチームに加わった方もいます。そういった方でも活躍されている環境なので、興味をもっていただけたなら経験がなくても、応募してもらえれば嬉しいです。
Data Infrastructureチーム とIngestion Pipelineチームではメンバーを募集しています。