
2021年夏のインターンシップに参加した海野良介です。普段はゲーム環境での強化学習の利用についての研究を行なっています。今回のインターンシップでは、Data Platform室・Data Engineering3チームに所属しました。この記事では、インターン期間中に私が取り組んだ内容について紹介します。
背景・課題
現在Data Platform室では300PB以上のディスク容量、2000以上のデータノードからなる、大規模なHadoopクラスタを運用しています。これらのクラスタ上では、監査目的のためにHadoopクラスタ内での全てのアクティビティログ(Audit log)を記録しています。記録されたAudit Logに対しては1日単位でバッチ処理によるテーブル形式への変換が行われています。このテーブルはHadoopクラスタで問題が発生した際に原因分析などの手段として利用されます。しかし現状の1日ごとにバッチ処理を行う場合ですと、問題発生からAudit logを使った分析までの間に遅延が発生してしまいます。そこで、Audit logを低遅延なシステムで分析し、問題が発生した際の原因調査や問題の発生が予期される際のアラーティングに活用できるようにしたいと考えました。
このとき、実際に収集され、クラスタ内のファイルシステムに保存されるAudit logは、以下のような形式のテキストファイルとなっています。
2021-08-01 12:34:56,789 allowed=true ugi=hoge (auth:TOKEN) ip=/10.230.123.456 cmd=open src=/user/dir/somewhere dst=null perm=null proto=rpc |
Audit logはファイルサイズが大きく、大規模な処理を行う必要がありますが、テキスト形式のような構造化されていないデータ形式は分析に利用することは処理の実行時間などの面から難しいと考えられました。そのため、分析のためのクエリ実行に適したParquetといった構造化されたデータ形式への変換が必要でした。
今回のインターンでは、テキスト形式で与えられるAudit logをより分析に適した形式に変換し、構造化したデータに対して可視化や異常検知を行うなどして、それらのデータの利用を行うパイプラインの構築に取り組みました。
システム構成
今回Audit logを低遅延に分析し、問題の原因調査やアラーティングに活用するために構築したシステム全体の構成は以下の図のようになっています。
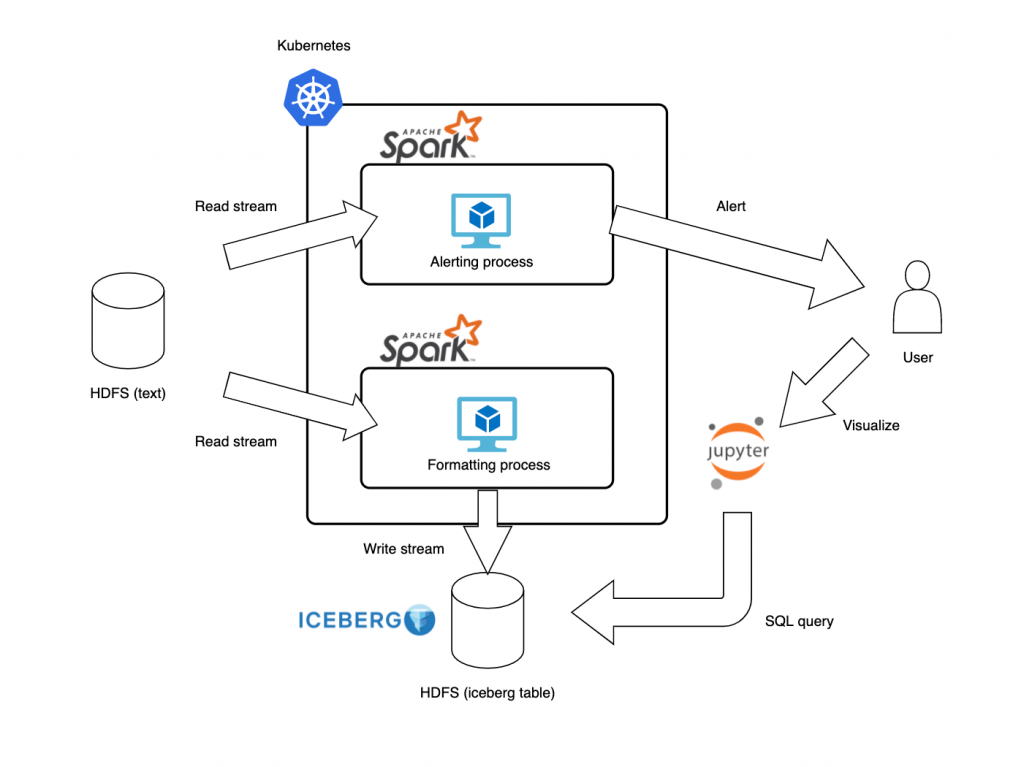
構成したシステムは2つのパイプラインからなります。
一つは図の上部にあたるパイプラインで、クラスタから生成されるAudit logをHDFSから読み出し、その中から異常と判断されるような挙動が観測された場合に、ユーザへのアラーティングを行うパイプラインです。もう一つは、図の下部のパイプラインです。アラーティングのパイプラインと同様にHDFSに保存されたAudit logを読み出し、テーブル形式に変換・保存します。このシステムの利用例としては、上部のパイプラインで発生した通知をもとにユーザが下部のパイプラインで保存されたデータを参照して、具体的にどのようなことが原因で異常が発生したかの分析を行うといったことが挙げられます。
このシステムを構築する上では、以下のような要件がありました。
- 時間経過とともに随時追加されるAudit logに対して、数分程度の遅延で処理・実行結果の保存を行う
- 頻繁に書き込みが行われる処理結果に対するアクセス内容が一貫性を持つ
- 断片化された小さなファイルをマージするといったテーブル管理が容易である
Sparkによるストリーミング処理
データパイプラインを構築する際の要件の1つ目については、ストリーミング処理を用いてデータの変換を行うことで対応しました。このとき、実装に使用するフレームワークはSparkとしました。
ここで、Sparkにおけるストリーミング処理の流れを以下の図に示します。Sparkではデータストリームが与えられた際に、まずそのデータを適当なサイズのパーティションに分割します。分割されたデータのバッチは各ノードにタスクとして割り当てられ、それぞれ並列に処理が実行されて、処理結果が出力されます。ストリームデータをマイクロバッチとして処理しているため、バッチ処理とのモデルの共通化が図れる可能性があります。

また、Sparkでは各種ストレージへのコネクタが充実しているため、今回データソースとして利用するHDFSや、データストリーミングで分散メッセージングシステムと利用されるKafkaとの親和性が高く他のデータソースとの組み替えが行いやすくなっています。さらにSQL処理や機械学習といったSpark向けのライブラリも充実しているため、ストリーミングパイプラインのその他のタスクへの応用が効きやすく、拡張性が高いといった利点もあります。
Iceberg形式のテーブル保存
Sparkを用いてデータの加工を行なった次の段階では、それらのデータを分析のためのテーブルへ保存します。システム要件の2つ目と3つ目を満たすデータの保存先テーブルのフォーマットとして、今回の実装ではIcebergを採用しました。データの形式としてはParquetを利用しました。
Icebergでは、スナップショットによる更新情報の管理を行なっています。書き込みの際には新たなスナップショットを生成し、処理が終わった段階でコミットすることで変更が反映されます。読み込みの際には既にコミットされているスナップショットを参照することで、読み込みと書き込みの分離がなされます。これによりIcebergはテーブルの変更に対するアトミック性を持ち、一貫性に関する要件を満たしていました。
またテーブル管理の面においても、ストリーミング処理では一回当たりの更新量が少なく、頻繁に書き込みが行われるため、サイズの小さいファイルが多く作成されてしまう場合があります。データを多数の小さいファイルに分けたまま保存してしまうと、HDFSのメタ情報を管理するNameNodeのリソースを圧迫したり、読み込みの際のオーバーヘッドが増加して全体のスループットが低下したりしてしまうという問題があります。これに対して、Icebergでは比較的容易にHDFS上での保存に適したファイルサイズにデータファイルのマージ・調節をすることができます。
そして、IcebergはSpark向けのサポートも充実しているため、今回のストリーミング処理に組み込みやすいという利点もあります。
Kubernetesによるリソース管理
上記のSparkによるシステム全体はKubernetes上で開発しました。
Kubernetes上でのSparkプログラムの実行の様子は下の図のような流れになります。まずクライアントがKubernetesのMaster Nodeに対してプログラムスクリプトをspark-submitすることで、Spark DriverのPodが作成されます。その後、DriverのPodが実際の計算処理を実行するSpark ExecutorのPodをクライアントが指定した数だけ作成します。そして作成したExecutorにそれぞれタスクが割り振られ、並列にタスク実行がなされます。
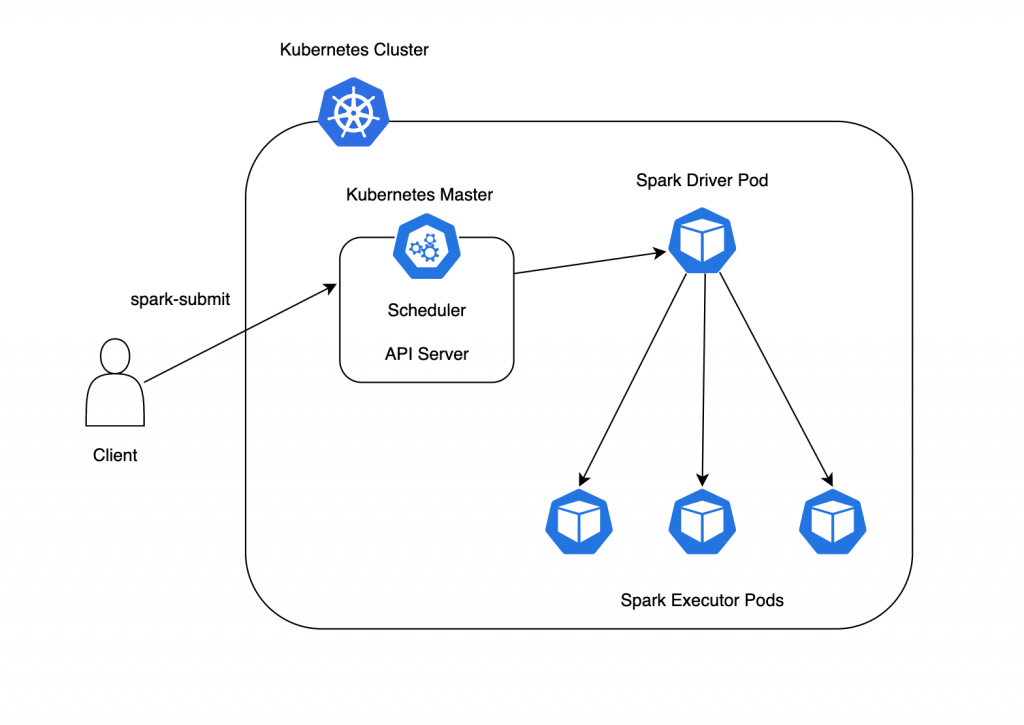
SparkをKubernetes上で利用することにより、予期せぬ理由でタスクに失敗してPodが終了してしまっても、指定されたPod数が維持されるように自動で新たなPodが立ち上がることでシステムの冗長化がなされます。また、クライアントによるspark-submit後はSchedulerが自動でそれぞれのPodに対して、適当なコンピュータリソースの割り当てを行うためリソース管理が容易になります。さらに、コンテナとしてアプリケーションをパッケージ化するため、Pod間の依存関係を管理するコストを下げることができます。
その他のSchedulerであるYARNと比較した場合にも、一般的なアプリケーションとSparkのバッチアプリケーションを共存させることで、全体的なリソース効率を向上させられるといった利点があります。
実装
以下、それぞれのパイプラインの実装について説明します。
アラーティングに関するパイプライン
アラーティングのパイプラインでは、初めにAudit logから得られる情報に異常があると予想される兆候がないかの検査を行います。この判断は事前に定義したルールに従って行われます。もし、データ内の値でルールに該当するものがあった場合にアラーティングをする形式としました。異常を検知するにあたって、クラスタ内で発生し得る可能性のある異常のうち、2つの場合に着目しました。
- アクセス数の急激な増加に伴う負荷的な面での異常
- 不正な操作を行うセキュリティ的な面での異常
このような異常を検知するためのルールの設定において、ドメイン知識を使用したりする場合や日々システムを運用する中で新たなルールを設定したくなる場合があると予想されました。そのため、ルールの記述方法にある程度の柔軟性を持たせたいと考えました。そこで、今回の実装ではSQLクエリ形式でルールの設定を行えるようにしました。
実際に負荷的な面での異常を検知するためのルールとして、以下のようなものを設定しました。ここではクラスタへの操作のうちマシンに与える負荷が高くなる可能性のある、一定時間内に行われるファイルの読み書きに関する操作に注目してルール設定を行なっています。
rule_config = {
"rule": [
{
"alert": "alert1",
"expr": "cmd = 'create' and count > 100000",
"message": "alert1 occur",
},
{
"alert": "alert2",
"expr": "cmd = 'open' and count > 1000000",
"message": "alert2 occur",
},
]
}パイプラインでは、一定の時間間隔ごとにAudit logに対する集計をとり、定めた規則に抵触するものがあれば、違反内容も含めて以下の図のようにSlackにアラーティングします。セキュリティ面での異常検知のルールについては、今回の実装では扱っていませんが、同様の方法で設定することができます。

分析に関するパイプライン
分析のためのパイプラインではアラーティングのパイプラインと同様にストリームデータとして与えられるAudit logを、Icebergのテーブル形式にしてHDFSに保存します。それらのテーブルデータに対して、ユーザはJupyter Notebook経由で以下のようなSQLクエリを発行し、表やグラフなどの可視化を行えるようになっています。図は上述のアラートに該当する範囲のデータになります。
sql_command = "SELECT * FROM hadoop_catalog.db.audit"
spark.sql(sql_command)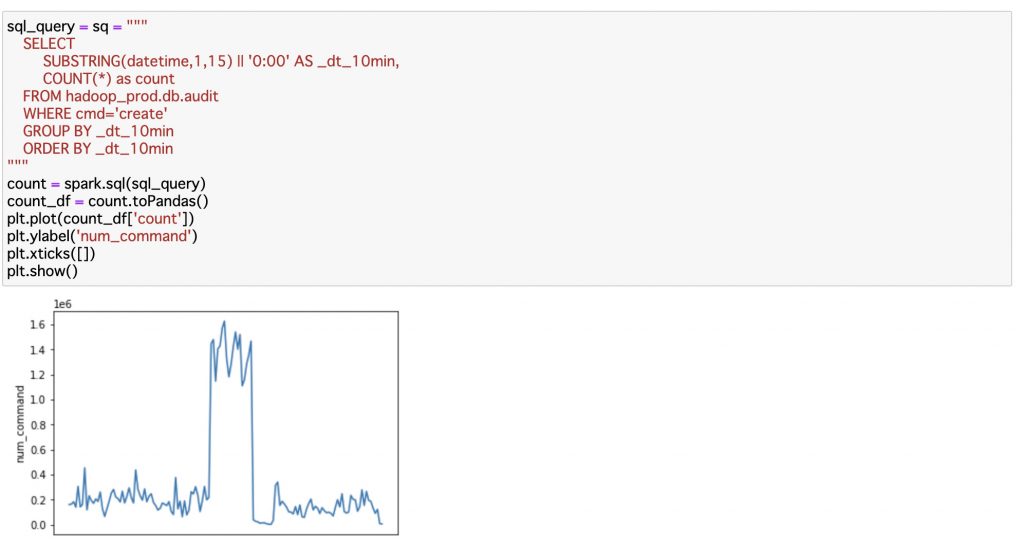
Icebergではテーブルへの書き込み内容の反映を行うコミット周期を設定することができます。今回の実装では周期を1分間に設定しているため、遅延時間も1分程度となり今までよりも低遅延にデータテーブルの参照が可能になります。
サイズの小さいファイルのマージといったテーブル管理は以下のようなコードにより実装しました。下の例ではファイルサイズが100MB程度になるようにしています。
Actions.forTable(table)
.rewriteDataFiles()
.targetSizeInBytes(100 * 1024 * 1024) // 100MB
.execute();まとめ
Hadoop Audit logを数分程度の短い遅延で分析するためのパイプラインを作成しました。これにより障害の可能性がある箇所を早い段階で検知・分析できるようになります。障害発生の検知や分析のタイミングが早くなることで、障害による影響を抑えることができます。
今後の展望としては、Spark内の機械学習フレームワークを利用して障害発生のパターンを学習することで、障害発生をより早い段階で検知できるようになる可能性もあります。また、今回は時間的に扱うことができませんでしたが、Audit logの履歴から不正な操作を検知し、ユーザに対して何らかの通知を行うといったセキュリティ面での異常検知も考えられます。
感想
今回のインターンで扱ったフレームワークなどに関する事前知識がほとんどなかったので当初は不安がありましたが、メンターさんに疑問に思った点に対して質問した際にとても丁寧に教えていただくなどサポートをしていただき、問題なく業務に取り組むことができました。またメンターさんには技術的な面以外でも、多くのサポートをいただきました。作業の方向性を決めるディスカッションなどを通して、多くのことを学ぶことができたと思います。そのほかにも、オンラインでのチーム内や他のインターン生とのランチ会もあり、リモート環境でも多くの人と交流することができました。普段とは全く違う規模感の環境で作業することは自分にとって刺激的で、とても充実した6週間になりました、本当にありがとうございました。