
2021年の夏のインターンシップに参加した大石( @elect_gombe )です。システム室システムエンジニアリングチームでオートベンチマークツールを6週間で作成しました。この記事では作成したシステムについて紹介します。
物理サーバのベンチマーク取得の問題
LINEは5万6,000超もの物理サーバを抱えている会社で、そのサーバインフラの整備も社内で行われています。新規購入のサーバに対してベンチマークを取ることで一定の基準を設けてサーバを比較することができ、機種の選定などに役立てることができます。
今まではベンチマークの取得を手動で行われてきており、ドキュメントベースのベンチマーク結果や、その都度作成されるスクリプトだけではそのベンチマーク結果を異なる旧世代とを直接比較をすることが難しくなってきました。また、ベンチマーク結果の集計方法が統一されておらず、ベンチマーク対象のノードが多い場合は保存し忘れなどもありました。
今回のインターンシップでは、物理サーバに対して基本的なベンチマークの取得の自動化を目的としてオートベンチマークツールを開発しました。
作成したベンチマークツール
今回作成したシステムは、1つがベンチマーク実行部分(Pythonで記述)ともう1つがそれを可視化するWeb UI部分からなります。前半ではベンチマーク実行部分について説明し、後半でWebUIの実装について説明します。
4種類のターゲットベンチマーク
今回は、ターゲットベンチマークとして4つの取得の自動化をします。
1つ目はCPUのベンチマークです。CPU性能を図る指標としてUNIXベンチがありますが、今回はそちらを使うことになりました。整数演算と浮動小数点数演算の両方をベンチマークします。スレッド並列数を変更して、性能がどのようにスケールするかを調べます。
2つ目はメモリ帯域のベンチマークです。こちらはstreamというプログラムを基本にしてベンチマークを取ります。和積演算を繰り返し実行し、Load2、Store1の割合でアクセスした時のメモリ帯域をスレッド並列別に見ます。メモリ帯域の理論値はメモリ規格やチャネル数によって異なるので、理論値にどこまで近づけれるかを調べます。
3つ目はストレージのベンチマークです。こちらが一番複雑なベンチマークで、測りたい項目としては以下のような項目があります。
- 読み込み帯域
- 読み込みIOPS (I/O per Sec)、一秒間に何回読み込みが実行されたか
- 読み込み遅延
書き込みに関しても同様です。これをブロックサイズと呼ばれるアクセス単位やjobサイズ、それからアクセスパターン(例えばシーケンシャルリード、ランダムリードなど)を変更しながら計測します。
4つ目は電力値のベンチマークです。アイドル中とストレステスト中の電力値を取ります。
上記のベンチマークターゲットのほか、電力プロファイルも別に取得しています。
ベンチマークシステムの概要
このベンチマークツールでは、自動的に必要なベンチマークを実行し、その結果をWebUI上で表示し、任意の機種間とのベンチマーク結果を比較することができます。
今回作成したものの動作の図を示します。
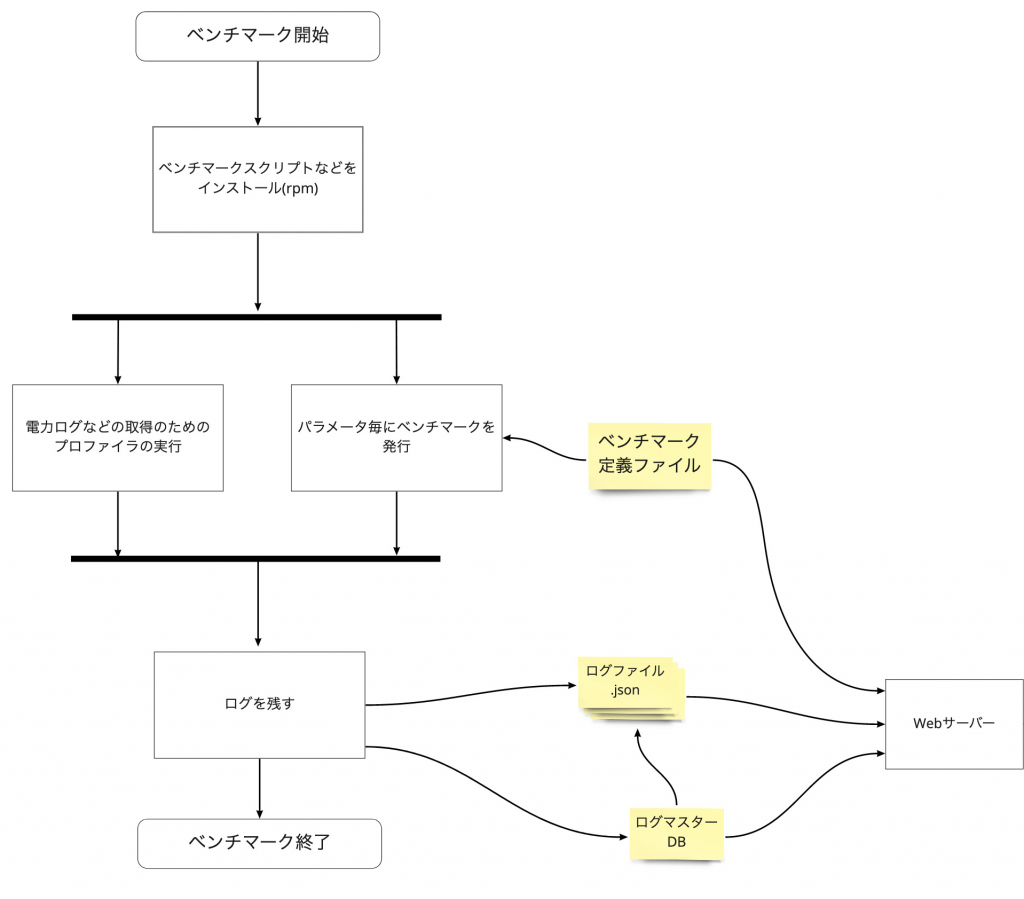
ベンチマークを開始すると、必要なスクリプトなどをインストールします。その後、プロファイラを裏で動かしながらベンチマークを実行します。ベンチマークは定義ファイルに沿って入力パラメータを変えながら実行します。その結果をログとして残してベンチマークを終了します。そのログファイルのパスなどを管理するためにログマスターの中にベンチマーク全体の情報を保存します。
ベンチマークの定義ファイルは、ベンチマークの種類毎に作成し、実行時にはそのリストを渡すことでベンチマークが実行されます。この定義ファイルには、ベンチマークのコマンド部、パラメータの切り替えの設定、出力結果、それからWeb UIで表示に必要なグラフの定義が入っています。
ベンチマークの差異を定義ファイルに入れるべきか、派生クラスにするべきか?
このシステムの最大の特徴はベンチマークの特有の記述をこのベンチマーク定義ファイルに押し込めて、システム自体にはノーコードでベンチマークを追加できる点にあります。
他の実装方法としては基本的なベンチマークを親のクラスとしてその派生クラスの中にベンチマークの差異を記述する方法が考えられます。この時のシステムの違いと定義ファイルの利点、派生クラスの利点について考えてみます。
派生クラスによる個別のベンチマーク別の実装
派生クラスによるベンチマークの記述の特徴は拡張性の高さにあります。そのため、派生クラスに記述することであらゆるベンチマークの種類を高い拡張性でサポートすることで将来追加されうるベンチマークを幅広くサポートし続けることができると考えられます。一方で弱点としては、派生クラスを書くうえでシステムの構成の理解が必要であり、親クラスの構成を把握しつつ派生クラスの構成もかなり決まった形で記述し、システム全体で見たときに統制が取れている必要があります。また、派生クラスのみではベンチマーク部分とWebUI部分で別々のコンポーネントを結合するための手段としては不十分で、Web UIの描画に必要な記述をどのようにするかも1つの課題になります。
定義による個別のベンチマークの実装
今回は設定ファイルに差異を押し込めることによりベンチマークの差異を吸収しました。この場合の長所はこのベンチマークシステムに対する理解が深くなくても設定ファイルさえ書ければ自動的にベンチマークが取れてそのベンチマークの結果もWebUI上にプロットできる点にあります。また、派生クラスほど拡張性はないですが、それでも追加の設定が必要な時でも設定ファイルへの機能拡張の可能性、システムの機能拡張を残しておけばベンチマークが増えたときにも派生クラスのような構成ではなくても追加の設定や拡張を行うことは十分に可能であり、ベンチマークを取る上では必要十分だと考えました。
メモリーベンチマークの定義の1つを示します。
memoryのベンチマーク定義の例
この定義ファイルの中では、実際にメモリベンチマークの定義をしています。
大きく分けて以下の4つのブロックからなります。
- ベンチマークの基本定義
- パラメータ定義
- 結果の定義
- グラフプロットの定義
パラメータは軸を複数生成することができます。
グラフもパラメータや固定する結果を選択することができます。
それらを直積として定義することで容易に全ての組み合わせのグラフを自動生成することもできます。
{
"name": "stream-memory-BW-test",
"command": "./benchmark-program/stream/linux-amd64.out",
"cmdpostfix":"",
"results_extract_cmd":"python3 result-extractor/streamparser.py",
"parameter_list": [{
"name": "thread count",
"sh_var_flag":"true",
"parameter": {
"val_range": [1,100,1],
"option_prefix": "OMP_NUM_THREADS="
}
}],
"results_format": {
"result_format_data": [{
"name": "Triad benchmark bandwidth",
"multiply":1000000,
"unit": "B/s",
"yaxis":{
"tickformat": "s"
}
}]
},
"graph_list": [{
"name": "(stream) memory bandwidth bench result",
"graph_type": "scatter",
"labelx": "Threads",
"labely": "Bandwidth[B/s]",
"data": {
"x": [{
"dataname": "thread count"
}],
"y": [{
"dataname": "Triad benchmark bandwidth"
}]
}
}]
}一番複雑なストレージベンチマークに関しても200行くらいで定義できるように、様々なオプションを用意しています。直積集合を生成するシステムがあるため、少ないコードで多くの種類のグラフを生成することができます。
ストレージのグラフ定義部の一部
"graph_list": [{
"name": "Read-BW, IOPS. latency results-block size",
"graph_type": "scatter",
"labelx": "Block Size",
"labely": "B/s",
"data": {
"x": [{"dataname": "bs"}],
"y": [{"dataname": "Read-BW"},{"dataname": "Read-IOPS"},{"dataname": "Read-latency"}
],
"for":[{
"dataname": "QD-jobs"
},{
"dataname": "type",
"select": ["read","random-read","random-read50-write50","random-read70-write30"]
}]
}
},{
...
},{
"name": "Write-BW, IOPS. latency results - QD",
"graph_type": "bar",
"labelx": "QD",
"labely": "",
"data": {
"x": [{"name":"QD","dataname": "QD-jobs","select":["qd1-j1","qd4-j1","qd16-j1","qd32-j1","qd64-j1","qd128-j1","qd256-j1","qd512-j1"]},
{"name":"jobs","dataname": "QD-jobs","select":["qd1-j1","qd1-j8","qd1-j16","qd1-j32"]}
],
"y": [{"dataname": "Write-BW"},{"dataname": "Write-IOPS"},{"dataname": "Write-latency"}
],
"for":[{
"dataname": "bs"
},{
"dataname": "type",
"select": ["write","random-write","random-read50-write50","random-read70-write30"]
}]
}
}]Web UIの作成
Web UIはVueを使って作成しました。グラフにはplotly.js を使い、UIの要素としてモーダル表示にvue-modal-js、通知にvue-notify-js、 UIのcssにSemantic-UI(cssのみ)、 結果を並べて表示するためにvue-grid-layout、アニメーションにvelocityなどを使いました。
なるべくユーザが自然に操作できるようなSPA(シングルページアプリケーション)を目指して作成しました。
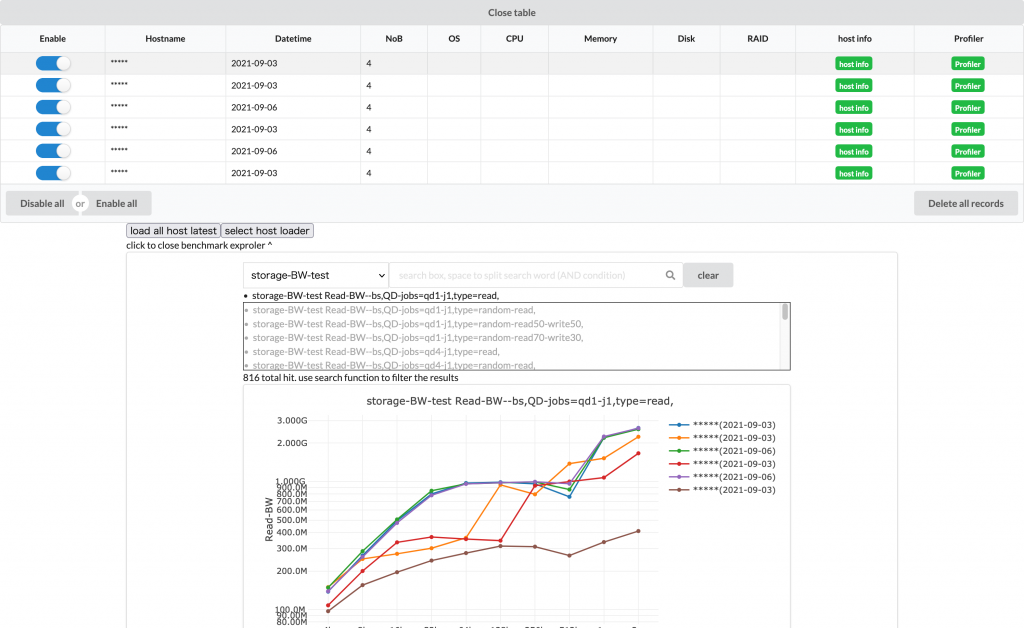
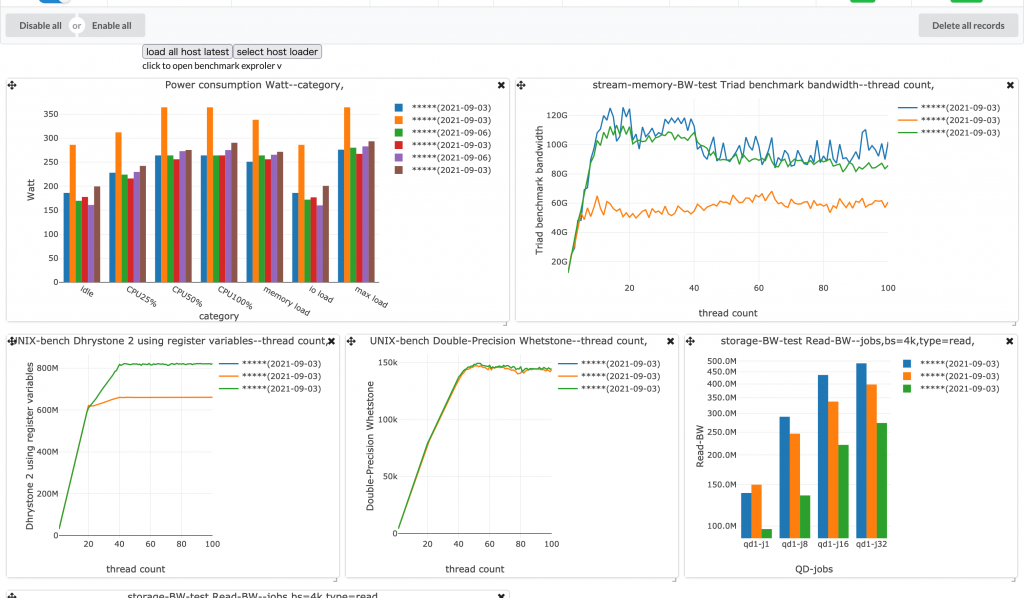
上のスクリーンショットはメイン画面を示していて、画像上部の表はロード済みのレコードを示しています。hostnameやOS~RAID情報は機密情報のため載せていません。
次のセクションでは、Web UIの作成について説明します。
モーダルの利用
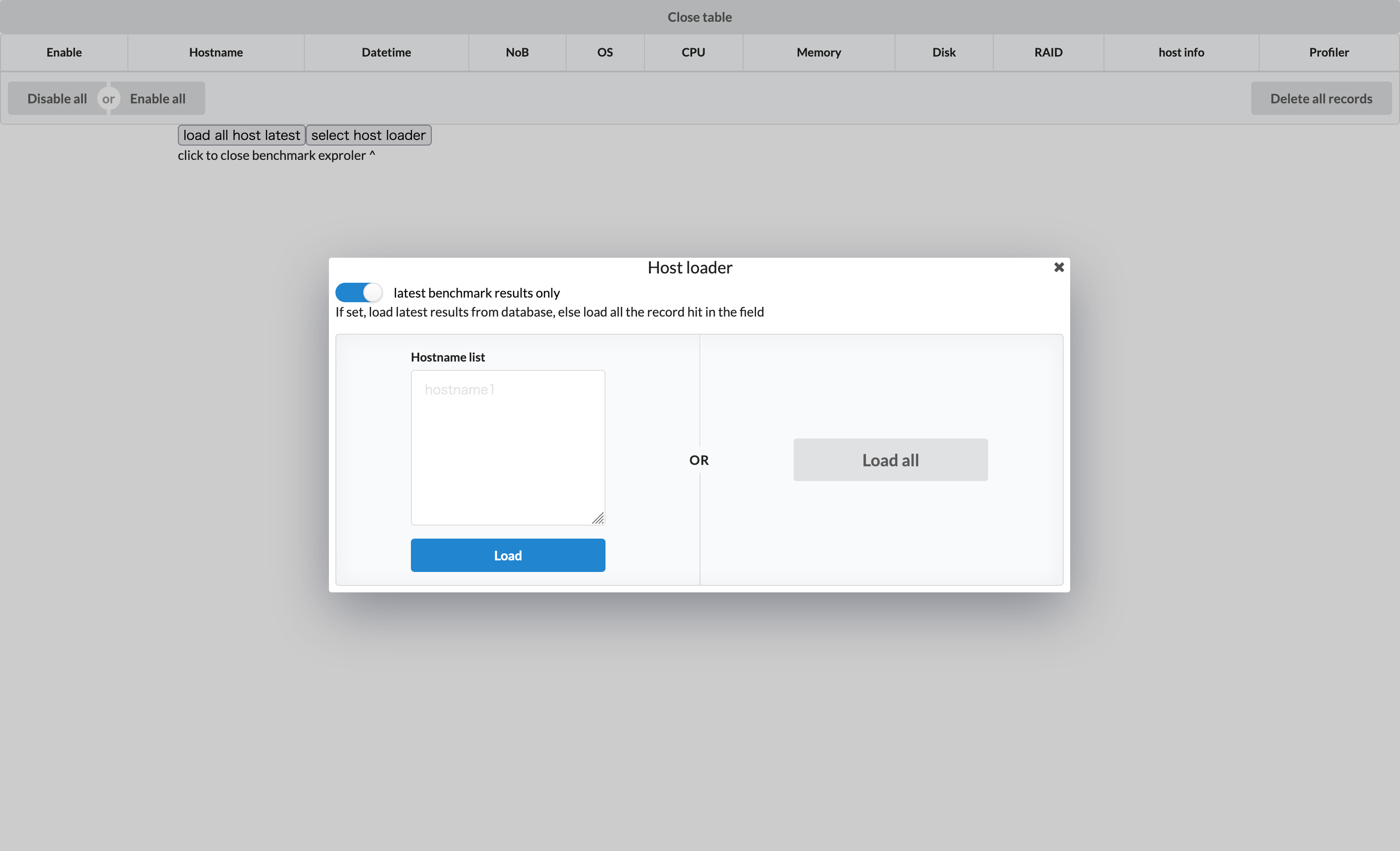
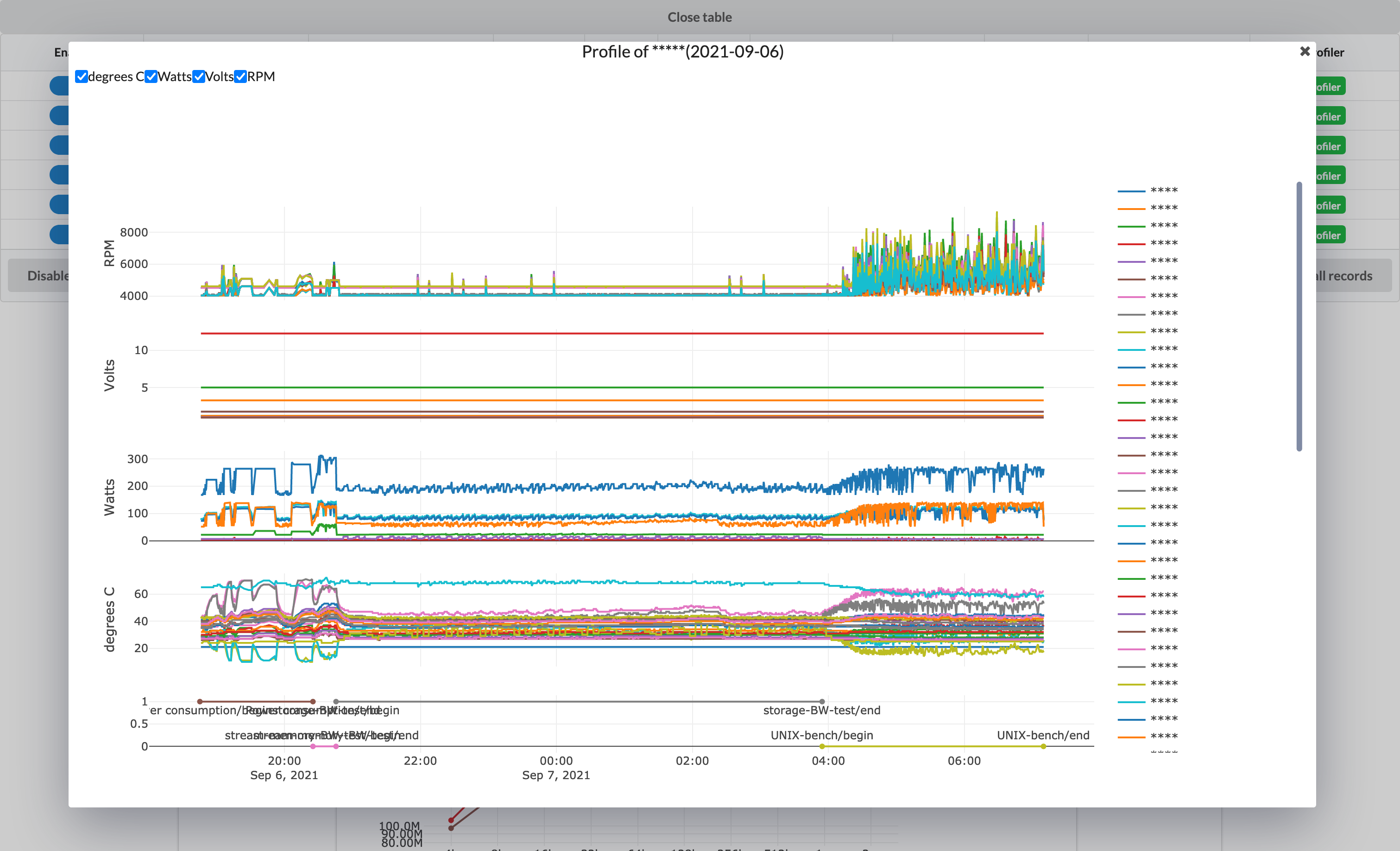
各ノードのベンチマークのサマーリーの表のハードウェア構成を表示するボタンからハードウェア構成のモーダルを表示したり、プロファイルのモーダルを表示できるようにしています。ホストの選択画面もモーダルで作成しています。
モーダルはとても便利で、背景や閉じるをクリックすることですぐに復帰可能(キャンセルが可能)でユーザもモーダルの内容に集中することができます。タブの切り替え機能では実現できない、元のメイン画面への「復帰」を必要とするアプリケーションで有効です。
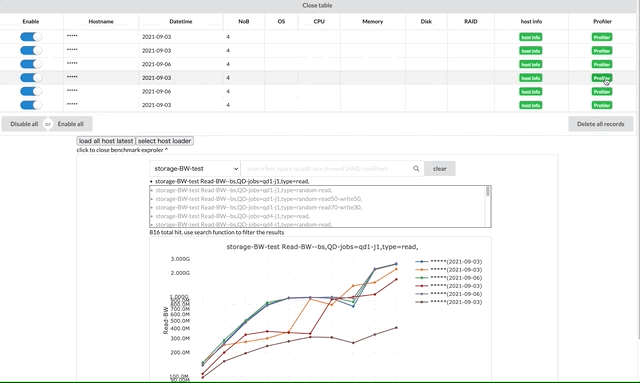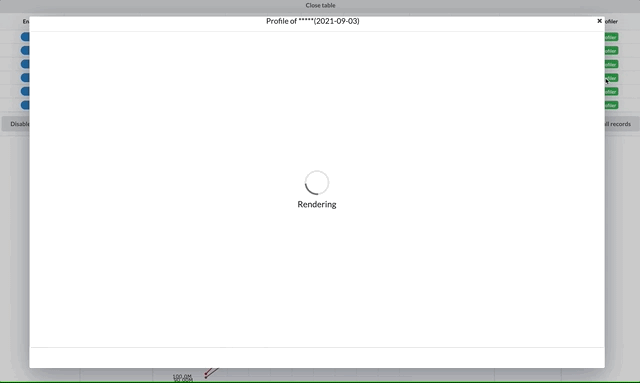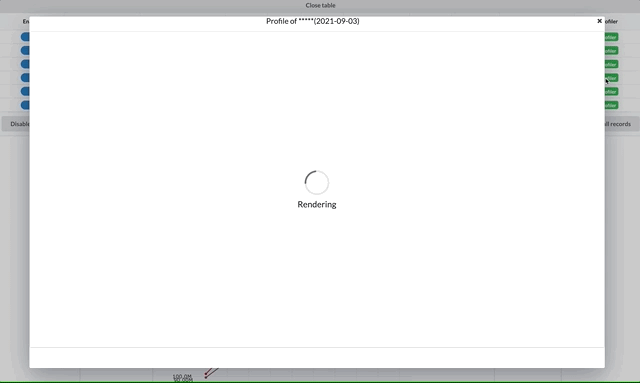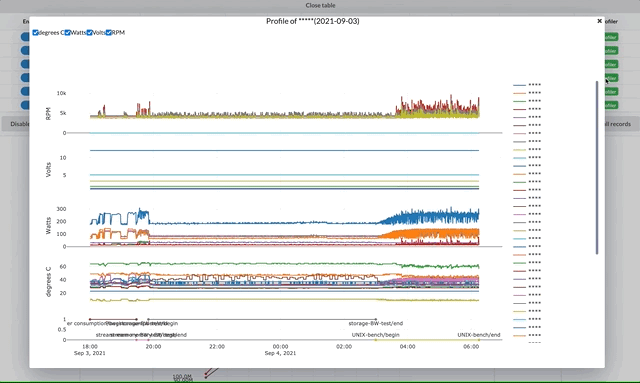
プロファイルのモーダルでは、消費電力、温度などの情報や、どのベンチマークが実行中であるかの情報などをグラフとして表示することができます。ベンチマークのスコアのヒントとして利用することができます。
ローディング表示
ユーザが自然に操作できるためには状態の表示が必要です。特にUIのフリーズは避けなければなりません。ロード中の表示やレンダリング中の表示などでユーザが今どういう状態なのかを把握できることは大切です。
プロファイルの表示ではプロットに最大で2秒くらい時間がかかるので、レンダリングのアニメーションをレンダリング中につけ、完了するとともに切り替えることでレンダリング中のUIのフリーズを避けることができました。それでも重たかったのでロードしたプロファイルのいくつかの密集データはロード時にあらかじめ切り捨てています。
グラフの選択
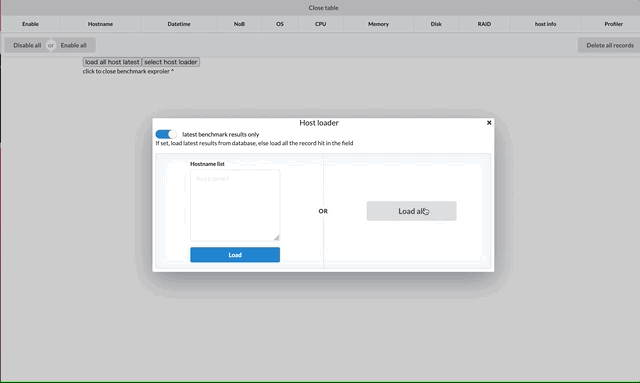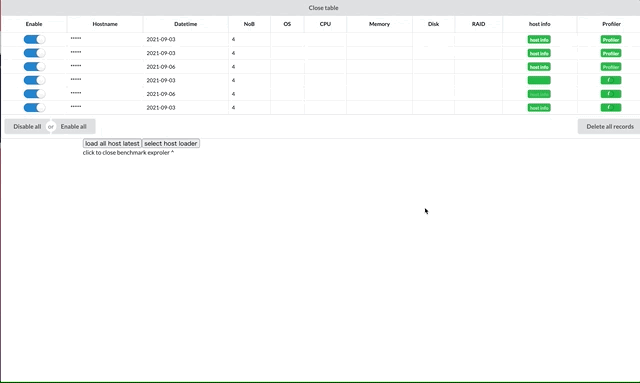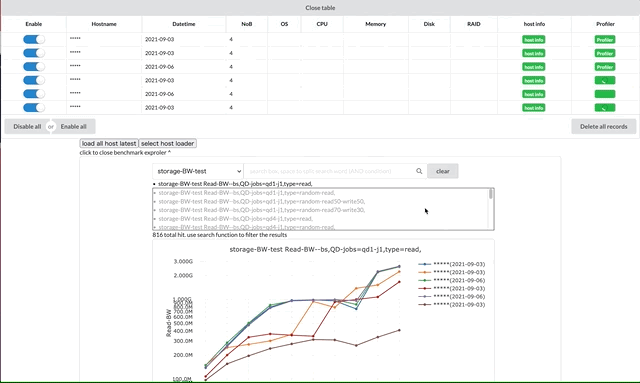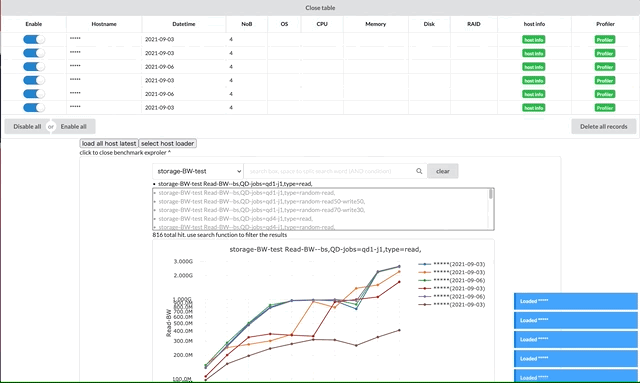
グラフの選択機能です。ベンチマークの種類を選択後、そのベンチマークの結果のグラフを選択します。
特にストレージベンチマークのグラフは候補が最初は816件あり、その中から必要なグラフを選択する必要があります。このシステムでは、インタラクティブに検索できる機能を実装し、必要なグラフを絞り込んで選択できるようにしています。
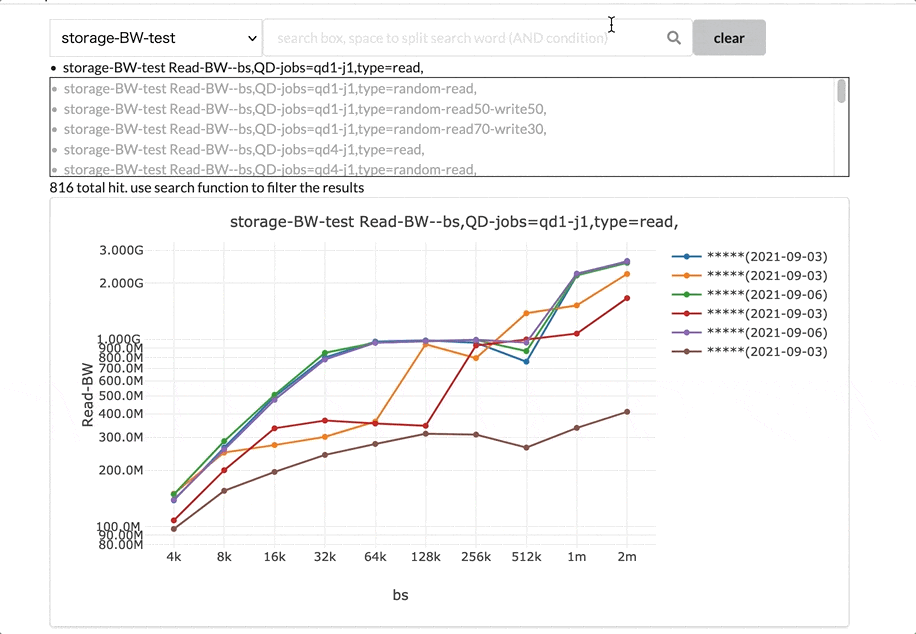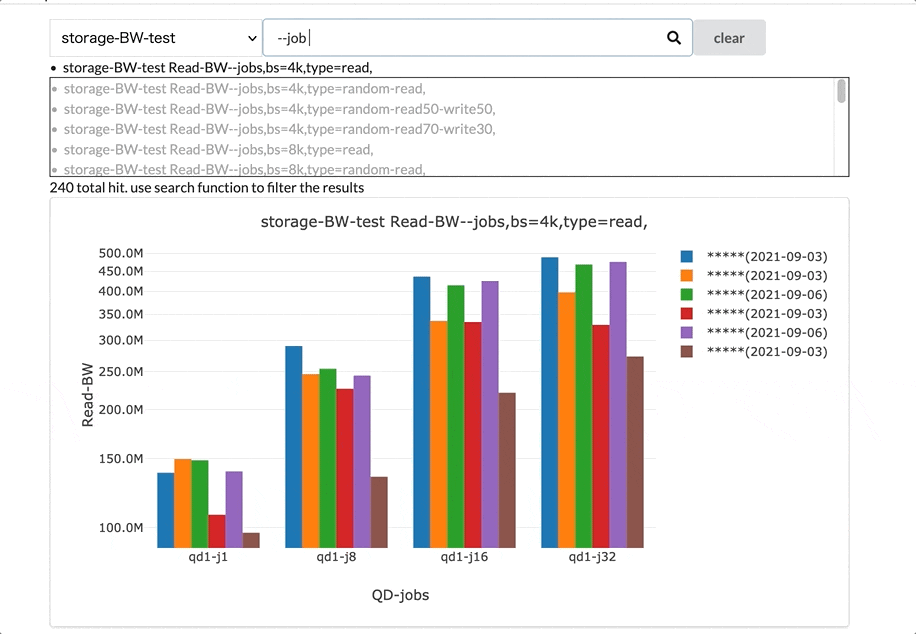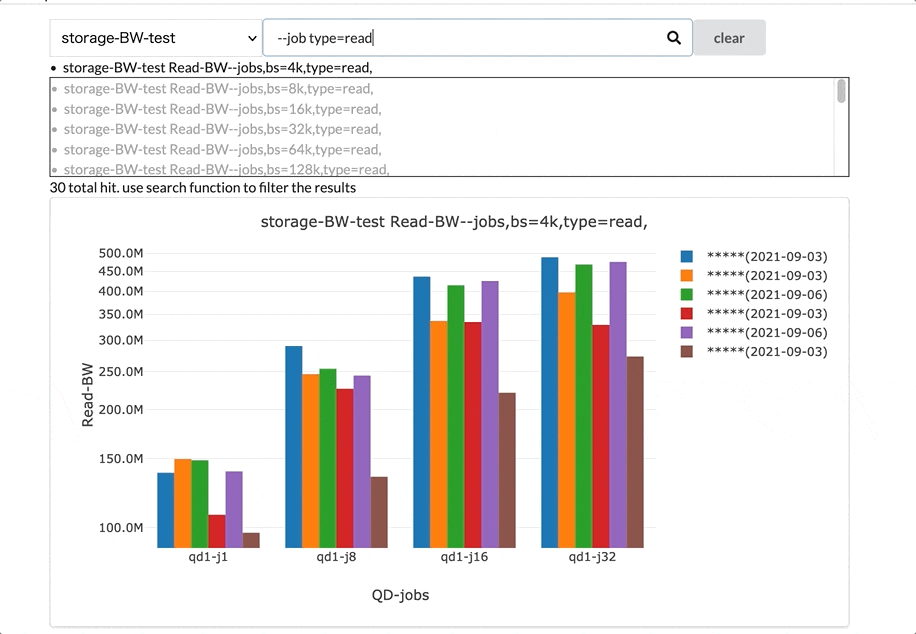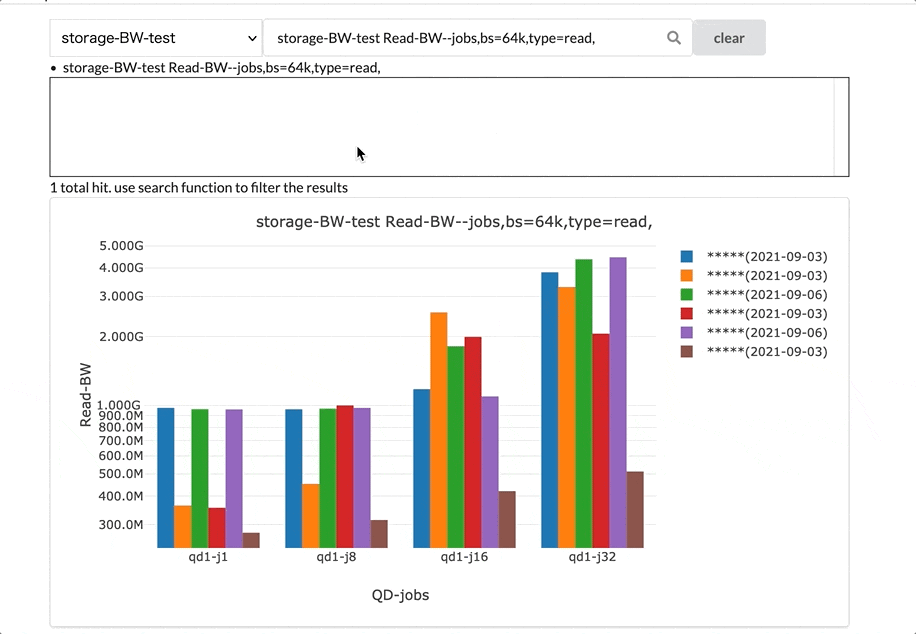
グラフカードのグリッド表示
ベンチマーク結果は並べて比較したいとの要望があったのでグリッド上のカードでグラフを表示するようにしました。
グリッドにするメリットとしては、以下の点があります。
- 小さなウインドウとは異なり、グラフ同士が重ならないことが保証できる点
- 自由にレイアウトを調節できる点
- 大きさを自由に変えられる点
今回はカードを下に押し出すようにして比較したいカードを出して、カードの整理ができるようにしました。
左上のアイコンからドラッグ、右上のアイコンは「閉じる」の機能で、左下のアイコンからはカードのリサイズが可能です。
まとめと感想
全体を通して
このインターンシップでは、ベンチマークのシステムを1から作成させていただきました。コードなどの総量としてはPythonのベンチマーク実行側は300行くらい、定義ファイルが400行くらい、WebUIは1200行くらいで、その他もろもろ合わせて合計で2000行くらい書きました。それ以外にもドキュメントの作成、ベンチマークを取る段階でもデバックなども結構色々とありました。最初に全体設計を簡単にしましたが、その後は全体を1度に作らずにできるところから少しずつ実装していく方式を取りました。
インターンシップを通じて考えさせられた、働き方
今回のインターンシップはリモートワークで行われました。リモートワークでもメンターとほぼ毎日MTGを開いて、悩んでいることとか質問に関して答えてくれてとても助かりました。実際に、いくつかの社内ツールの実演なども画面共有越しにリモートで行われましたが、現地と遜色なく問題なかったと思います。
6週間という期間
長すぎず短すぎず、ちょうど良かったと思います。終わってみるとあっという間だったなと思いましたが、ハッカソンなどより実践的でかつ実際のシステムとしての完成度がかなり高くなったと実感しています。ハッカソンではほぼアイデア勝負(+短期実装スキル)、6週間のインターンシップでは実務経験よりですね。
インターンシップで得られたこと
このインターンシップを通じて一番感じたのが、インフラ関連のことをするためにはその周辺幅広く知識を取り入れる必要があるということです。私は元々ハードウェア寄りに興味があったのですが、実際はハードウェアに関する知識はもちろん、Web UIを構成するためのフロントエンドの知識なども必要になりました。5年前くらいにWeb系のインターンシップに参加したことがあったのですが、その時と比べてもフロントエンドに関しても、ここ数年で急激に環境も変わり、より自然で画面の切り替えパフォーマンスが高いシングルページアプリケーション(SPA)が多く使われるようになってきています。これらSPAのフレームワークの仕組みをはじめとし、幅広い分野に興味が持てたこともインターンシップの1つの収穫だと思います。
システム室でインターンシップさせてもらって、社内の様々なシステムを触りながら開発させてもらって、社内インフラもかなり充実していると感じました。数万台のサーバを円滑に管理して、きちんと使い切るようにするためにはどのようなインフラが必要かを考え、スケールして行ったのだなと思いました。
序盤は社内のコードもgitにあったものを参考にさせていくことが多かったですが、インターンシップ中に社内のツールのソースコードを見れたことも良かったと思います。
ツールを作る上で大切なこと
ユーザにとって使いやすいツールを作りたいと思いながら制作することは大事です。社内ツールの作成はあくまでも社内のユーザ向けのものですが、社内の使用ユーザにとってどのように使われるのかをすり合わせて機能を実装していくこともでき、「あれもほしいよね」とか「こうもできるようになったらいいかも」などといった要望を仕様に落として実際に実装することは貴重な経験となりました。この経験を生かして、これからも誰かの人の役に立つ、使いやすいツールの開発などをしていきたいと思いました。
謝辞
インターンシップをさせていただくにあたってメンターの芳賀さんにはお世話になりました。忙しい中でも頻繁にミーティング時間を作ってもらえて、お互いに情報共有を密にして仕事ができたと思います。また、木村さんも実際のシステムの実装などの相談をさせていただきありがとうございました。