
こんにちは。慶應義塾大学大学院 理工学研究科 修士1年の上田栞です。8月から6週間、LINE株式会社の2022年度夏季インターンシップ「技術職 就業型コース」に参加させていただき、リサーチインターンとして、AIカンパニーのComputer Vision Labチームに配属され、「形状を詳細に反映した顔の3次元再構成」という研究に取り組みました。本レポートでは、我々が目標としている課題と、インターンシップにて取り組んだ内容・成果について説明します。
テーマ背景
バーチャルヒューマンの技術は近年急速に発展しており、仮想の人物を創り出すだけでなく、実在の人物をバーチャル化する取り組みも行われています。実在の人物に近いバーチャルヒューマンを作成するためには、リアルな顔を生成することが必要ですが、現在のCG技術では、作成された顔にまだCGらしさが残っており、リアルであるとは言えません。
コンピュータビジョンの分野でも、人物の顔を操作する研究が活発に行われています。有名な例として、ディープフェイクがあります。ディープフェイクでは、敵対的生成ネットワークを使用して2人の人物の顔を入れ替えることで、顔画像の操作が可能となります。
以下は、DeepFaceLab[1]を用いて顔交換を行った例です。
(左: 元動画、右: 顔交換を行った結果、動画の参照元: https://www.whitehouse.gov)
また、他にも以下の画像のような顔交換が可能です。

(参照元: I. Perov et al., 2020)
これらの結果を見ると、ディープフェイクを用いて表情の変化をリアルに生成できていることが分かります。一方で、学習データが不足している向きの顔の合成に失敗したり、照明条件が異なる時に色味に違和感がある場合があります。
我々は、顔画像の生成に顔の幾何情報を用いることで、これらの問題が解決するのではないかと考えました。照明条件を変えても違和感少なく画像を生成するには、詳細で正しい顔の3次元形状が必要となります。そこで、本インターンでは、よりリアルな顔画像を生成するための、顔の詳細な3次元再構成に取り組みました。
顔の詳細な3次元再構成の方法
1枚の顔画像から顔の3次元再構成を行う手法の多くは、人物の顔の3次元モデルを事前知識として持ち、画像に合う3次元モデルを当てはめる(すなわち、顔の3次元モデルのパラメータを求める)ことによって3次元再構成を行っています。しかし、顔の3次元モデルのメッシュは頂点数が少なく、大まかな顔の表現しかできません。
そのため、顔の詳細な3次元再構成の手法には、1. 顔の3次元モデルを元に詳細な形状を再構成する方法と、2. そもそも顔の3次元モデルを使わない方法があります。
1. 顔の3次元モデルを元に詳細な形状を再構成する方法
顔の3次元モデルのパラメータを当てはめることによって顔の大まかな形状を得て、その後に顔の詳細な形状を得る処理を行います。
この方法の例として、Fengら[2]の手法があります。この手法では、1枚の顔画像から、FLAMEと呼ばれる顔の3次元モデルに加えて、その3次元モデルからのdisplacement mapも推定します。FLAMEのパラメータで定まる顔の3次元メッシュに、displacement mapに合わせたメッシュの変形を行うことにより、顔の詳細な形状を得ることができます。
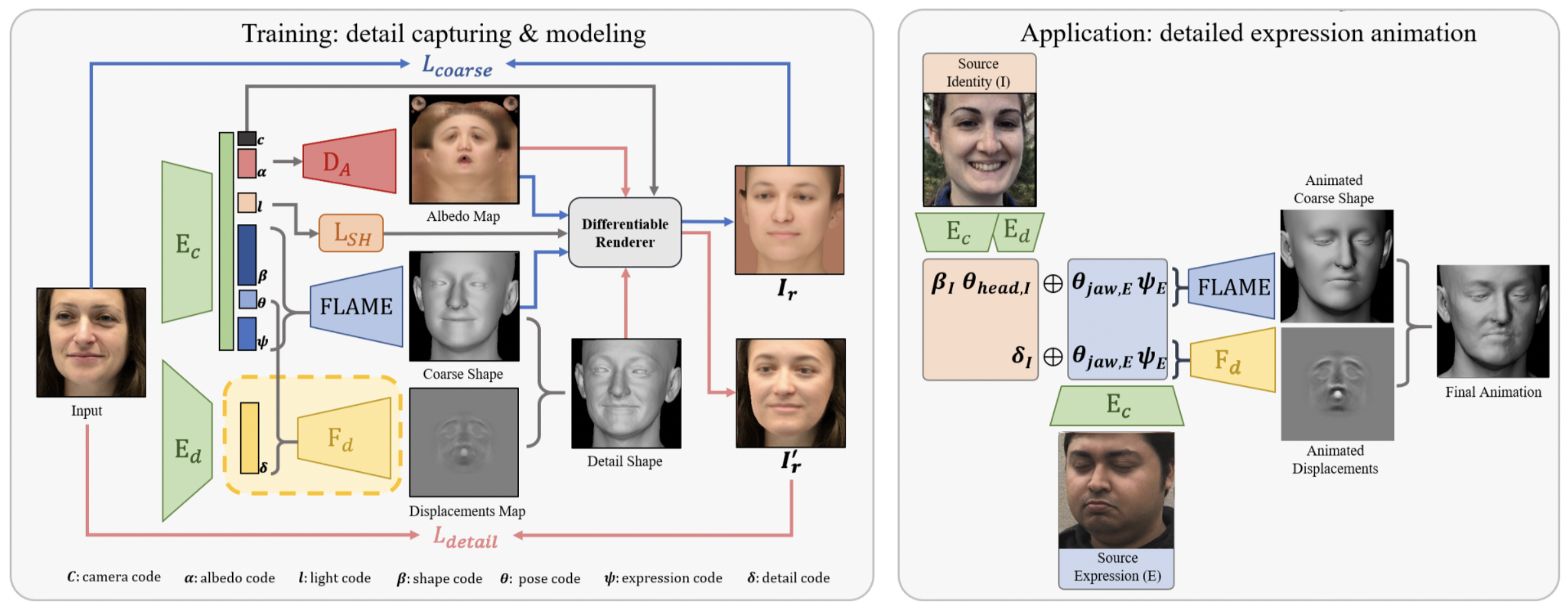
(参照元: Y. Feng et al., 2021)
これらの手法では、パラメータ化された顔の形状を当てはめるので、姿勢の変化や照明変化、遮蔽にも堅牢です。また、パラメータを変化させることによって、顔の表情を変えることも可能です。一方で、FLAMEのような顔の3次元モデルは、表現できる顔のバリエーションには制限があるというデメリットもあります。
2. 顔の3次元モデルを使わない方法
パラメータ化された顔の3次元モデルを使わずに、顔画像から直接顔の3次元構造を推定する方法です。
この方法の例として、Selaら[3]の手法があります。この手法では、顔の画像から深度マップを求め、顔のテンプレートメッシュと非剛体レジストレーションを適用することにより、顔の3次元形状を得ます。さらに、レジストレーションの後には、顔のシワなどの形状も再構成する処理も行なっています。
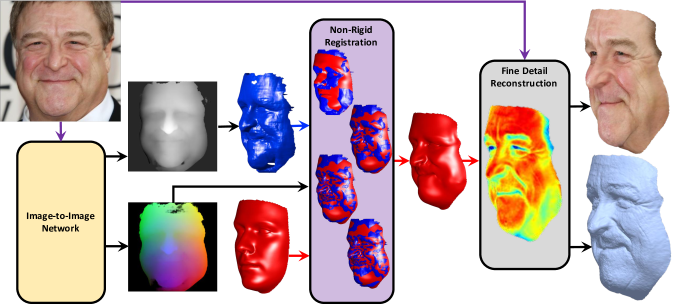
(参照元: S. Sanyal et al., 2017)
これらの手法では、パラメータ化された顔の3次元モデルを使わないので、パラメータで表すことができない顔の形状も柔軟に表現することができます。一方で、堅牢性が弱く、顔の表情を変化させることもできません。
検証
実験概要
3次元再構成ベンチマーク[4]の5人の顔画像を用いて、3つの方法で顔の3次元再構成を行いました。
- Feng+ coarse
Fengら[2]の手法のうち、FLAMEの3次元メッシュをそのまま出力したもの - Feng+ detailed
Fengら[2]の手法を全て適用し、FLAMEの3次元メッシュにdisplacement mapによる操作を行ったもの - Sela+
Selaら[3]の手法の中の深度マップの推定をした後に、1や2のFLAMEモデルに位置合わせを行ったもの(位置合わせは比較のため)
結果・考察
結果の図を下に示します。この図は、1行が1人の顔画像に対しての結果となっています。各行で左から順に、入力画像、次の3枚が各手法で再構成した顔を入力画像と同じ向きで表示したもの、その次の3枚が各手法で再構成した顔を別の向きで表示したもの、最後が実際に撮影された画像のうち、直前の3枚と最も近い向きの画像となっています。
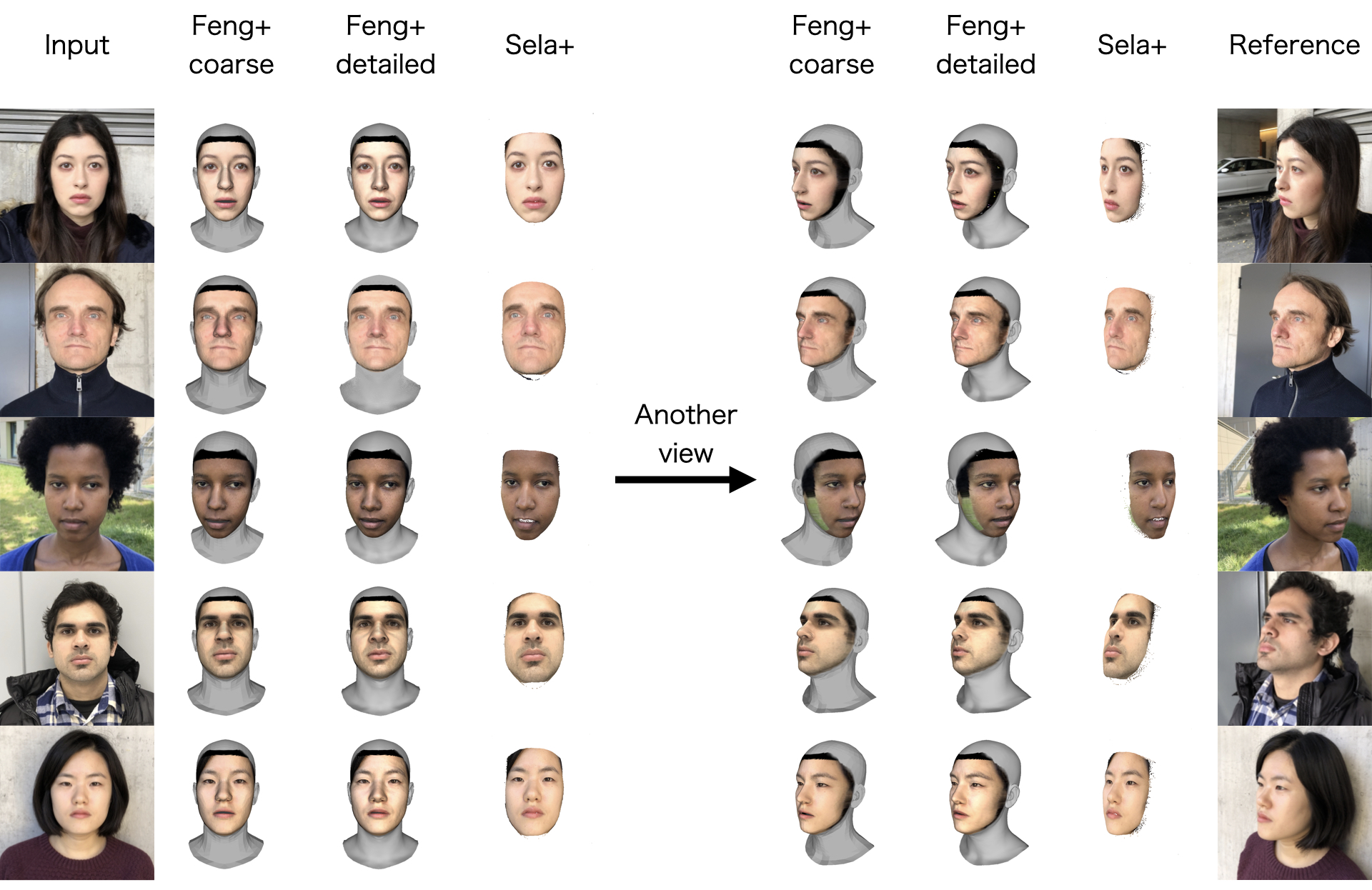
また、これらの3次元メッシュの頂点数は、Feng+ coarseは5023個、Feng+ detailedは59315個で、Sela+は平均85509個でした。
これらの図を見ると、2行目の例では、Feng+ coarseの時点でもある程度正解に近い顔の形状の推定ができていることが分かります。また、Feng+ coarseがFeng+ detailedになると、頂点数が増え、displacementによるメッシュの変形の処理が加わることにより、顔の詳細な表現ができるだけでなく、多くの例でメッシュ全体の形状がある程度正解に近づいているように見えます。一方で、5行目の例ではFeng+ coarseはもちろん、Feng+ detailedでも、かなり正しい形から外れています。これは、FLAMEを用いた予測が、正解から大きく外れてしまっているからだと考えられます。一方で、5行目の例では、FLAMEを用いて表現できていない顔の形を、妥当に推定できているように見えます。
これらの結果から、FLAMEの3次元モデルでも表現できる顔もあり、FLAMEでは表現しきれていない多少の形状は、頂点数の増加とdisplacement mapの操作で改善可能なことが分かります。しかし、FLAMEでの表現が正解から大きく外れてしまっている場合、displacement mapの操作のみでは、正しいメッシュを推定するのは困難です。一方で、パラメータ化されているモデルを使わない手法では、堅牢性の弱さといったデメリットはあるものの。より柔軟な顔の形状を推定することが可能です。
まとめ・今後の課題
今回のインターンシップでは、照明条件を変えてもリアルに顔画像を生成するための、顔の詳細な3次元再構成の検証に取り組みました。
今後の課題としては、まず、FLAMEに対して、顔の3次元モデルを用いない手法で推定した顔を適切に対応づけする方法の検討が挙げられます。FLAMEモデルは動かせる顔のモデルとして有用ですが、やはり頂点数が少ないことから、表現できる顔の形状に限界があります。そこで、より柔軟性のある3次元メッシュをFLAMEに対応づけすることができれば、お互いのメリットを活かした、動かせるリアルな顔を生成できるのではないかと考えています。
また、現状では、当初取り組む予定であったシワなどのより細やかな表現についての検証ができていませんが、上記のことが達成できれば、細やかな表現についても達成可能であると考えています。
おわりに
今回はオンラインでのインターンシップでしたが、メンターの方と密にSlack上でコミュニケーションをとっていただいたおかげでスムーズに業務を進めることができました。
今回のインターンで取り組んだテーマは、大学で研究していない分野だったため、ゼロからのスタートでしたが、メンターの方をはじめとする社員の方々のサポートのおかげで、無事成果をまとめることができました。
テーマの進め方も自由だったため、全くの新しい分野でサーベイを行い、既存研究の問題点をチームの方々と議論して解決策を探すといった、自立して研究を進める上で必要な力を鍛えることができ、非常に有意義な時間を過ごすことができました。この期間で得た大きな学びを、大学での研究や今後のキャリアに活かしていきたいです。6週間、本当にありがとうございました。
参考文献
- I. Perov, D. Gao, N. Chervoniy, K. Liu, S. Marangonda, C. Umé, M. Dpfks, C. S. Facenheim, L. RP, J. Jiang, S. Zhang, P. Wu, B. Zhou and W. Zhang, DeepFaceLab: Integrated, flexible and extensible face-swapping framework, arXiv preprint arXiv:2005.05535, 2020.
-
Y. Feng, H. Feng, M. J. Black and T. Bolkart, Learning an Animatable Detailed 3D Face Model from In-The-Wild Images, ACM Transactions on Graphics, vol. 40, pp. 1–13, 2021.
-
M. Sela, E. Richardson and R. Kimmel, Unrestricted Facial Geometry Reconstruction Using Image-to-Image Translation, in IEEE International Conference on Computer Vision (ICCV), 2017.
- S. Sanyal, T. Bolkart, H. Feng and M. J. Black, Learning to Regress 3D Face Shape and Expression from an Image without 3D Supervision, in IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2019.