
1. 初めに
こんにちは、東京大学大学院情報理工学系研究科コンピュータ科学専攻の修士1年の増本雄斗です。研究室では自然言語処理を専門に研究をしています。今回、LINEでの就業型エンジニアリングインターンシップに参加し、AI開発室のComputer Vision Lab チーム(以下、CVLチームと表記)での取り組みを紹介したいと思います。本記事では、LINEでのインターンがどのようなものであったかを私の取り組みを紹介しつつ伝えられれば、と思っております。
2. インターン課題と目的
背景
近年のVision&Languageモデリングは、大規模に画像とテキストを両方用いた学習により、画像からのテキスト、テキストから画像といった高品質な生成が可能となりました。具体的には、画像生成においては、テキストから任意の画像を生成するOpenAIのDALL・E[1]や、商用利用可能なStable Diffusionモデル[2]などが公開されており、その生成画像の品質の高さに注目を集めています。一方で、テキスト生成においては、画像を入力としてその説明文を生成する、Imgae Captioning の分野でも活発に研究が進められています。[3,4]このような背景のもと、幅広い分野で高い性能を示しているVIsion & Language モデルですが、LINEにおいてもこの技術のプロダクト化に向けた研究開発を進めているところです。
前述の通り、大規模モデリングによるテキスト生成において、高品質なテキストも生成可能になりました。しかしながら、このような高品質なテキストを生成できるモデルの構築には、大規模な学習データが必要不可欠になります。最近では、数十億を超えるデータを扱うこともありますが[1,2,3,4]、このような大規模データには収集と構築の際にモデルの学習にとって不都合なデータが含まれている傾向にあります。そしてそれらのノイズデータは、モデルの品質低下をもたらします。ノイズデータには様々なものがあり、画像やテキストそれぞれに不都合な性質を有している場合もあれば、画像とテキストの両方を考慮すると不都合な性質だと判定される場合もあります。具体的な例でいくと、アダルトな画像や表現のデータは、企業での技術利用においては不都合なデータと言えます。他にも、犬の画像に"これは、ネコです。"という説明文が付されている場合も、画像やテキストだけで言えば一般的なものですが、その両方を考えるとモデルに悪影響を及ぼしそうなデータと言えます。実際に、高品質な画像生成を実現している既存研究[1,2]では、ノイズデータに対して独自のフィルタリングしたデータセットを利用していることも報告されています。
このように、大規模データを使用したモデル構築においては、用途に応じたフィルタリングを迅速に行うシステムを構築することが、高品質なモデル構築において必要不可欠であると言えます。以上から、本インターンにおいては、「大規模Vision&Languageモデリングに向けたLAION-5Bのデータ分析と大規模データ整備システムのプロトタイプ検討」というテーマの下で、LAION-5Bと呼ばれるデータセットに対して、分析を行うだけでなく、フィルタリングを含むデータ整備システムの検討を行いました。
目的と課題
i) 目的
現在、CVLチームでは、高性能な画像生成モデルの商用化に向けた検討を進めており、先行する高性能な画像生成モデルの研究[1,2]を参考に新しいモデルの研究開発を進めています。CVLチームにおいても、前述の背景のもと、高性能な画像生成モデル開発に必要な大規模なデータセットの構築を進めております。しかしながら、収集されたデータをどのように洗浄すべきなのか、あるいは、学習に適したデータセットをどのように作成すべきかは、一般的には知られていません。そこで、本インターンの最初の目的として、まず、大規模データセットの1つであるLAION-5Bデータセットの分析を行い、どのようなデータが含まれているかを調べることとしました。また、企業で機械学習モデルを運用していく場合に最も重要なこととして、新しい(未知の)データへのモデルの対応もあります。そのため、大規模モデルの開発と運用という観点から、再学習の必要に迫られた際、数千万〜億というデータセットを迅速に整備する必要があります。そこで、インターンの2つ目の目的として、数十億に渡るデータセットを高速に処理し、データ分析で得た知見を用いて適切に洗浄を行えるシステムを構築することとしました。
ii) 課題
前述の目的から、以下の2つの課題を定めました。
-
LAION-5Bデータセットの分析を通したフィルタリング方法の検討.
優れた品質を持つ大規模モデリング作成において、高品質な大規模データセットが必要になります。 まず最初に、一般には大規模データのフィルタリング方法は研究段階で、決まった方法があるわけではありません。 そのためどのようなデータが元データに含まれるかを分析することが必要になります。また、フィルタリングとして取り除かないといけないものが大きく二つあります。一つ目は、製品にした場合に不適切なものを生成する可能性があるもの。二つ目は、学習に適してない、低品質の画像やテキストが含まれるものになります。そのためには、画像やテキストの観点から優れたデータというものを検討する必要があります。 -
高速な大規模なデータセットを洗浄するシステムの構築
大規模なデータを扱う必要があり、一般的な手法のままでは莫大な時間がかかります。そのため、実現可能時間内でデータを整備できるアルゴリズムやシステムの開発がデータセットの構築機構に必要となります。
LAION-5B[5]
LAION-5Bデータセットとは、研究と技術開発の民主化を目的に画像とテキストのペアデータで構成されている大規模でオープンなデータセットになります。このデータセットは、約50億サンプルを超えるインターネット上から取得可能な画像と多言語テキストのペアデータで構成されています。しかしながら、このような超大規模なデータセットは一般的に半機械的に収集と整備が行われるため、一般社会通念上あるいは倫理的に適さない画像や表現のテキストが含まれていたり、画像とテキストのペアが必ずしももっともらしいペアと言えない状態のサンプルが含まれていたりします。そのため、商用利用や企業での技術開発利用には、一定の洗浄処理が求められています。
3. データ分析
データ分析について
本インターンで分析・抽出の対象となる大規模なデータセットには、LAION-5Bデータセットを用います。LAION-5BデータセットのEnglishサンプル群の約20億サンプルからランダムサンプリングした約1,400万件の(txt,img)ペアデータを用いました。データ分析は大きく三つのステップに沿って行います。一つ目は画像データのみによるもの、二つ目はテキストデータのみによるもの、三つ目は画像データとテキストデータ両方を加味したものになります。今回データ分析をさまざまな観点から行いましたが、スペースの都合上全てを掲載できることはできないので、その一部をご紹介します。
Step 1 : 画像データからの分析
ここでは、画像の観点からの選別結果を示します。フィルタリングすべき画像として、まず社会通念上不適切なものが挙げられます。本ステップではこのような画像のフィルタリングについて紹介します。LAION-5Bには、Not Safe For Work(NSFW)という職場で見るのには適さない画像を意味するラベルが付与されています。これはNSFWを認識する画像分類モデルによって付けられたものになります。画像データにおける洗浄処理の先行研究[4,5,6,7]では、簡易的なものから、ツールを使用したものも見受けられました。具体的には、画像のサイズが400ピクセル以下のものを除くもの、アスペクト比が一定以上になるものを除くもの、ポルノ検出機に引っかかったものを除くものなどが見受けられました。
Step1では、この画像に付与されているNSFWラベルを用いてその種類と分布を計測し、その後画像の選別を行いました。その結果を以下に示します。
画像データからの分析結果
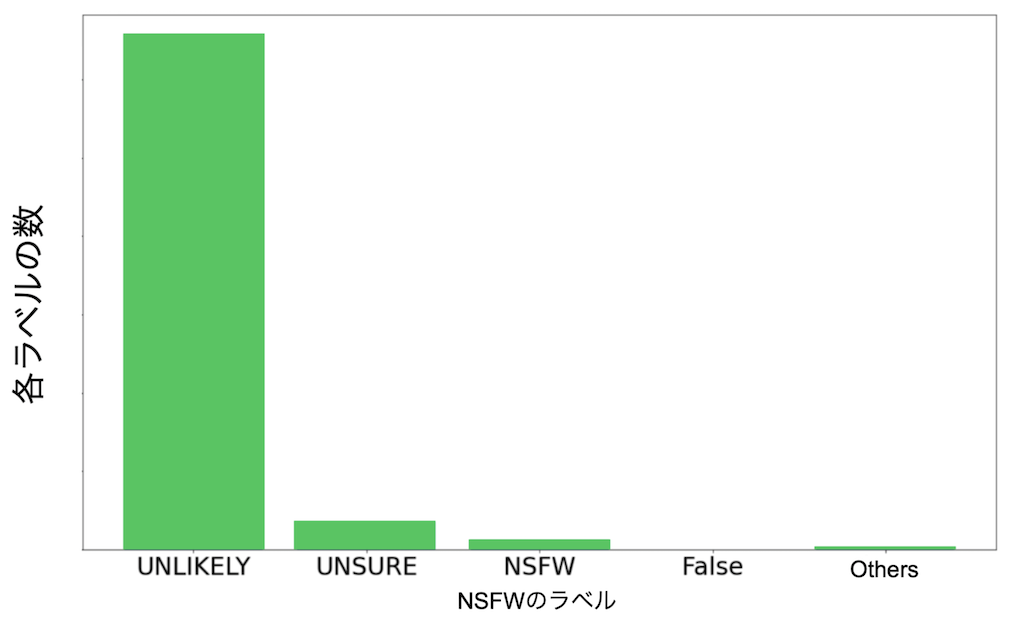
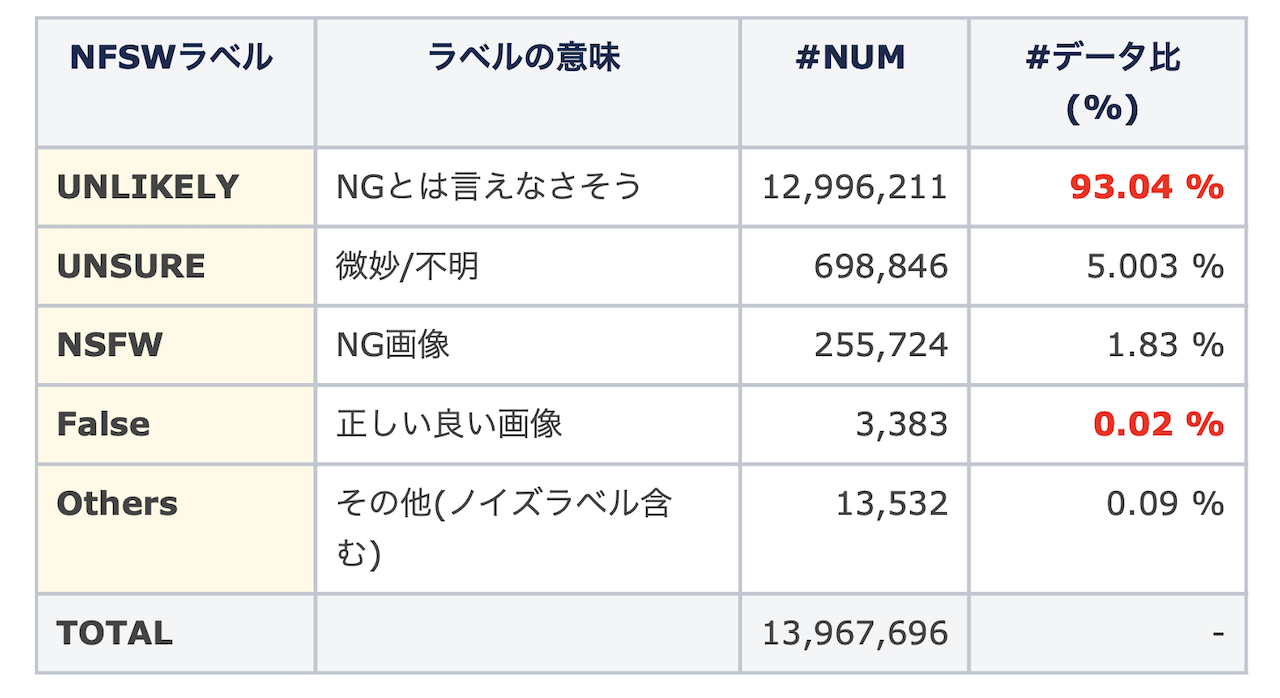
分析結果としては、NSFWラベルについては、1,076種類ものラベルを確認できました。しかしながら、そのほとんどは意味をなさない無意味な文字列や数字のみのラベルが見受けられました。またそれらのタグを確認したが特に規則性などを確認されませんでした。そのため本件では頻度上位の4種ラベル(UNLIKELY, UNSURE, NSFW, False)とそれ以外(others)で分類することにしました。以下の図は、各NSFWのラベル数をヒストグラムとして表したもので、ほとんどの画像がUNLIKELYに属することがわかります。これは、ほとんどの画像がNSFWでは無さそうということを意味しており、本当にそうであるか実際に画像のサンプルを以下で見てみます。
以下の画像群がFalse、UNLIKELY、UNSURE、とラベル付された画像のサンプルになります。
FalseとUNLIKELYでは明らかに安全な画像が多く見られました。UNSUREになると、人間が写っている画像の割合が増え、中には肌の露出が多いものが見て取れます。NSFWの画像に関しては、約30%ほどが不適切な画像で、それ以外は比較的安全なものが見受けられました。不適切な画像を含めないために、厳しくラベルが付けられていることがわかります。
画像データの分析からわかること
結果より、FalseとUNLIKELYがNSFWと見受けられる画像が含まれる割合が少ないと考えられました。これは全データの 93.06% に該当します。以上で、画像スクリーニングによりNSFWの可能性のある画像データやノイズ画像の除去は終わりました。
Step 2 : テキストデータの分析
次に、テキストからの除去を行います。高品質なテキストは、文法構造が破綻しておらず、画像の内容を適切に表現しているものになります。そのため様々な観点から適切なテキスト以外を除く処理を行います。他の研究論文では、出現単語の瀕死によるもの、特定の単語のトークンを繰り返す場合に除くもの、肯定的すぎる場合や否定的すぎる場合に除外するもの、辞書登録されていないものを除くものなどがみられました。[6,7,8,9]今回実装したスクリーニング処理は複数あるのですがその中の代表的な二つを今回は紹介します。
テキストデータからの分析結果
名詞が含まれるか否か
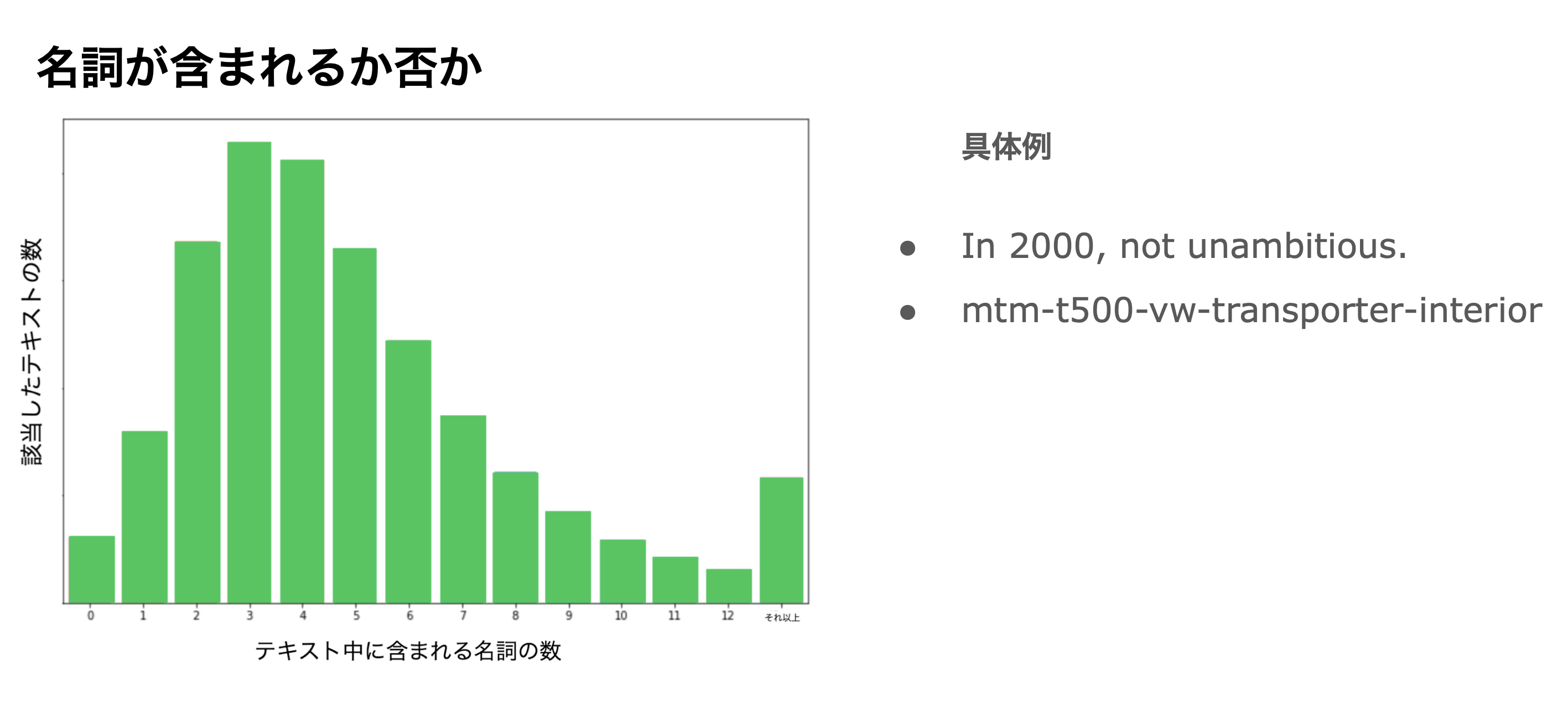
一つ目の分析としては、名詞がテキスト中に含まれるか否かというところに着目しました。以下のグラフがテキスト中の名詞の分布になります。ほとんどの場合、名詞がテキストに含まれていることがわかると思います。名詞が含まれてないテキストの例が右図になります。これらより、名詞が含まれてないテキストは少ないが、名詞が含まれていない場合、抽象度が高いテキストにであることがわかります。また、名詞として成り立っていないもののみのテキストであることも見受けられました。
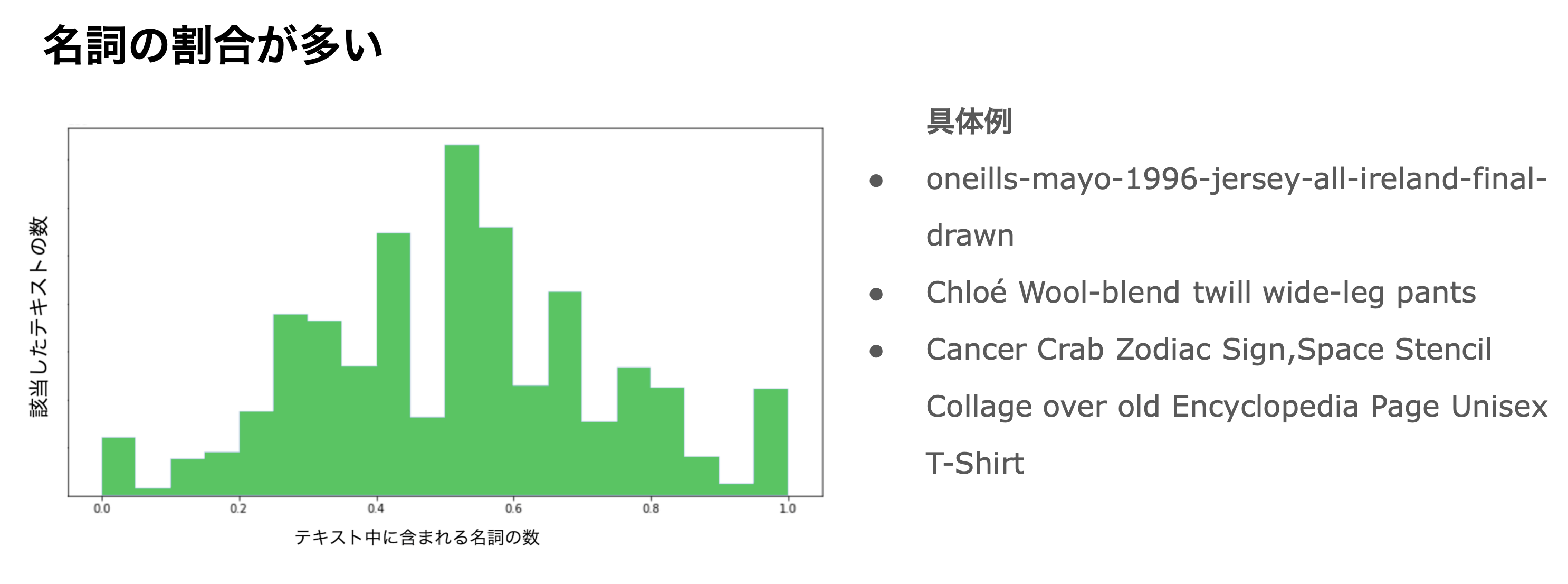
名詞の割合が多い
二つ目の分析としては、名詞がテキストに含まれる割合に注目しました。以下のグラフがテキスト中の名詞の割合を示した分布になります。名詞が含まれてないテキストの例が右図になります。名詞比率が高いテキストは、テキストを構成する単語数も2~3語で終わる場合が比較的多かったため画像の情報としては少なく適切でないように考えられます。
テキストデータの分析からわかること
結果より、FalseとUNLIKELYがNSFWと見受けられる画像が含まれる割合が少ないと考えられました。この二つのタグのみの使用をStep2以降ではしていきます。これは全データの 93.06% に該当します。以上で、画像スクリーニングによりNSFWの可能性のある画像データやノイズ画像の除去は終わりになります。
4. システム開発
ここまでは、データ分析によるLAION-5Bデータセットの性質やデータの洗浄方法について詳しく見てきました。次に、これまでのデータ分析結果を踏まえ、このような超大規模なデータセットに対して現実的な時間でのデータ洗浄及び抽出するシステムを検討します。ここでの目的は、それぞれのデータ洗浄及び抽出処理が現実的な時間内に終えられるだけでなく、データ処理の目的に応じた柔軟性の高い処理フロー実現するシステムの構築を検討することです。
本インターンではLAION-5Bから抽出した1,400万件の規模のデータを取り扱うのですが、検討初期では主に1,000件程度のサンプルを用いて実際のデータ洗浄の手続きなどを作成していました。1,000件程度の場合では、データ洗浄の処理速度について特に気にすることはなかったのですが、1,400万件になると処理が一向に終わらなくなり途方に暮れました。チームメンバーとの議論の中で、処理が終わらなくなった具体的な要因は、次の2点だと仮説を立てました。データサンプル数が少数の場合は、データを全てRAM(random-access-memory)に展開して比較的高速に処理が実行出来ていましたが、1,400万件の場合ではRAMにデータを全て展開出来ないため、ファイルバッファなどでデータのやり取り発生し、データ処理に遅延が生じやすくなります。データ特徴量の保存に対して最適なデータ構造を用いていなかったため、単純な処理であっても計算時間がかかっていました。このような仮説に対して、以下の2つのアクションをとることで、計算時間を大幅に改善しました。
A )最適なデータ構造の利用と共通処理をまとめる
比較的小さなデータ量では誤差と言えるほどの計算速度の差が、データ量が大規模になると無視できなくなります。このため、各データ洗浄の関数で共通して用いるデータの特徴量は予め事前に計算しておき、データ洗浄過程で何度も同じ手続きが発生することを抑制することで計算回数を減らし、計算時間を小さくしました。また、計算量についても、データ構造として単純にリストで管理していた特徴量を、辞書型(HashMap)で管理できる形に変えることで計算量の削減をしました。データ洗浄手続きの計算速度の向上による計算時間の削減の次は、データ洗浄プロセスの並列処理化による効率化を進めました。本件のデータ洗浄はデータセットの各サンプルに対して実施されるため、サンプル間の依存関係や特徴量はデータ洗浄には無関係であるため、データセットを分割し並列処理を行いました。今回は、1,400万件のデータを100万件ずつに分割することで10個の並列ジョブで進められ、とても高速に処理ができるようになりました。
B ) 消費されるRAMの抑制
比較的小さなデータ量の場合では、処理を行うデータを全てメモリに展開して処理を行っていました。しかしながら、今回のデータサイズは非常に大きいため、メモリに全てのデータを展開することは困難です。(ジョブ並列でも同様。)ここでは、以下の2つのアクションによりメモリ消費の問題を改善しました。ひとつは、Pandasと呼ばれるデータ分析向けデータフレームの利用から、シンプルなJsonデータを用いる方法に変更したことです。Pandasは特徴量の作成機能により大量のデータに対して端的な実装で一括での特徴量生成が可能である反面、データ全体をメモリに展開するためメモリに入り切らないデータはファイルバッファに一時格納されるなどで処理が著しく遅延する傾向にあります。また、データフレームの性質から処理ができないという不具合に当たることが多々ありました。これに対して、JSONファイルは標準的な辞書型データ構造で特別な関数などを内包していないものの、iteretorを用いてJSONデータを逐次処理できます。このため、必要な分だけデータをメモリに展開し、データ洗浄の処理が終わった後ファイルへを書き込む、といった逐次処理により、大規模なデータを全てメモリ展開する必要がなくなり消費メモリ量が削減できました。
最終的なシステム概要図
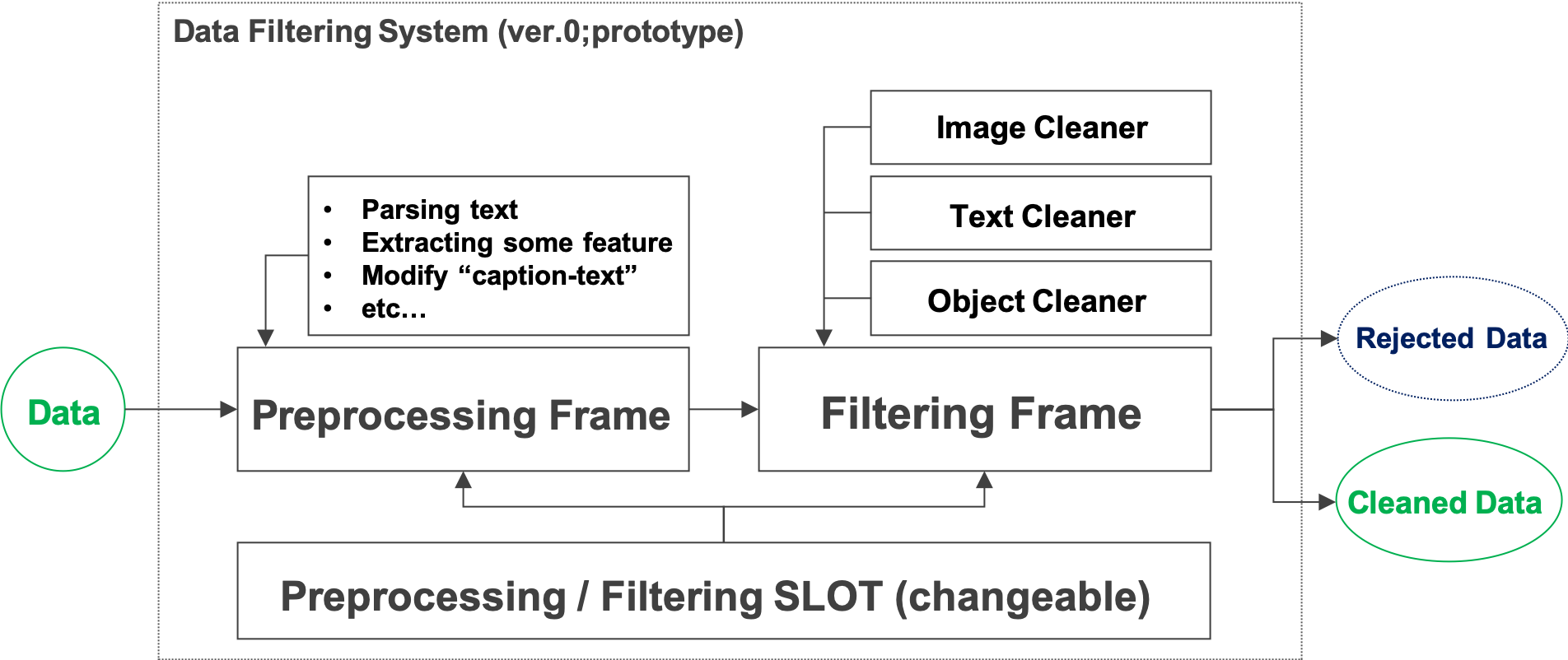
高速化の結果
最適化する前では1,400万件の処理をするのに、422,190秒かかっていたものが、上記の改善を行うことで26,600秒で処理を終えることが可能になりました。約16倍の高速化を可能にしました。
まとめと今後の方針
システム開発では、新規データに対してデータのクリーニングを行うシステムのプロトタイプを検討しました。今後はより大きなサイズのデータセットへの対応やより多くのプロセスでの並列化を適応していくことを予定しております。
5. 感想
6週間ものオンラインインターンということでどのようなものか、最初はとても不安でしたが、質問にはすぐ対応してくれるなど頻繁にミーティングの機会を設けてもらえて安心して働くことができました。また、コロナ渦が緩和傾向にある中で、インターン期間中に本社オフィスに伺う機会もありました。インターンが気になっている方は、参加してみることを強くおすすめします。最後になりますが、オンラインでもスムーズに働ける環境を作ってくださった人事の方々、議論を頻繁にしていただきとても実りのある時間を過ごさせていただいたComputer Vision Labチームの皆様、インターン生の私がなじみやすいようにとても親切にしてくださったAd Unitの皆様、そして特にどんな質問でもすぐにZOOMミーティング開いてくれてすぐに相談に乗ってくれたメンターの方、本当にありがとうございました!
6. 参考文献
- Rombach et al., High-Resolution Image Synthesis with Latent Diffusion Models. In CVPR, 2022.
- Ramesh et al., Hierarchical Text-Conditional Image Generation with CLIP Latents. arXiv preprint arXiv:2204.06125, 2022.
- Hu et al., Scaling Up Vision-Language Pre-training for Image Captioning. In CVPR, 2022.
- Li et al., BLIP: Bootstrapping Language-Image Pre-training for Unified Vision-Language Understanding and Generation. In ICML, 2022.
- Schuhmann et al., LAION-5B: An open large-scale dataset for training next generation image-text models. https://openreview.net/pdf?id=M3Y74vmsMcY, https://laion.ai/blog/laion-5b/,2022.
- Schuhmann et al., LAION-400M: Open Dataset of CLIP-Filtered 400 Million Image-Text Pairs. In NeurIPS Data-Centric AI workshop, 2021.
- Sharma et al., Conceptual Captions: A Cleaned, Hypernymed, Image Alt-text Dataset For Automatic Image Captioning. In ACL, 2018.
- Jia et al., Scaling Up Visual and Vision-Language Representation Learning With Noisy Text Supervision. In ICML, 2021.