
こんにちは、ネットワーク室サービスネットワークチームでアルバイトをしている中川 稜です。
LINEでは現在インターネットエッジルータのFlow情報を収集・分析・可視化するためのツールとしてElastiFlowを利用しています。今回はElastiFlowをどのように構築し、どのようにデータを可視化しているかを紹介します。
ElastiFlowの導入に至った背景
データセンタのインターネットエッジでFlow情報を取得する目的として以下のものがあります。
- ピアリング/トランジット事業者別の通信を分析し、LINEの通信品質を向上・維持させるための最適なトラフィックコントロールを柔軟かつリアルタイムで行うための根拠データとする
- リアルタイムでデータ分析・可視化を行うことで、迅速な障害対応やデータドリブンなオペレーションを可能にする
- 過去の通信がどのような状態であったかを追跡調査する
LINEでは過去数年間利用した自社開発の別ツールがありましたが、これにはいくつかの課題がありました。
- インターネットに接続するEdge Routerは流れるトラフィックが多いため、Flowも多くなるがCollector側のスケールがしづらい
- Netflow v9やIPFIXなど後発のプロトコルに対応していない
- データの可視化手法が単純であり、複数のパラメータを組み合わせた多角的な分析が困難である
これらの課題を解決する上で、比較的容易に構築できコストを抑えてFlowの可視化をすることができるツールとして、ElastiFlowを選択しました。
ElastiFlowについて
Flow情報を取得して可視化を行うツールには、SaaSで提供されているものやオンプレで構築するものなど様々な形態がありますが、基本的に商用のサービスは高額になりがちです。
今回紹介しているElastiFlowはELK Stackで費用をかけずに利用することができます。ElastiFlowはNetflow v5/v9, sFlow, IPFIXに対応しています。
ElastiFlowを構成するコンポーネントは以下です。
- Elasticsearch
FlowのデータがJSON形式で保存されます。 - Logstash
Flow Collectorとして動作します。
Netflow v5/v9, sFlow, IPFIXのデータをデコードして共通のモデルに正規化しElasticsearchにデータを保存します。 - Kibana
グラフの表示を行う部分です。
ElastiFlowではデフォルトでいくつかのダッシュボードが作成されていて、データが保存されていれば簡単に可視化されたデータを見ることができます。
ElastiFlowはELK Stackのバージョンに応じて更新され続けていて、最新のバージョン(今回試したElastiFlowのバージョンはv3.5.2)ではELK Stack 7.x が必要になります。昨年12月下旬にリリースされた新しいメジャーバージョンのベータ (v4.0.0-beta1)ではELK Stack 7.5.Xが必要になります。
またElastiFlowは要求性能がとても高く、INSTALL.mdには2,500 flows/secで下記の性能が必要とされています。
| flows/src | vCPU | Memory | Disk (30-days) | ES JVM HEAP | LS JVM HEAP |
|---|---|---|---|---|---|
| 2500 | 12 | 64GB | 3TB | 24GB | 6GB |
この表記は推奨なので実際の環境に応じて調整する必要があり、2,500 flows/secを超える場合はElasticseachのクラスタやLogstashのみのノードを用意ことを推奨すると記載されています。
For anything beyond 2500 flows/sec a multi-node cluster should be considered, and that Logstash be run on its own instance/server.
The above recommendations are a starting point. Once you are up and running you can make adjustments based on the actual load of your environment.
https://github.com/robcowart/ElastiFlow/blob/master/INSTALL.md#requirements
LINEはコンテンツ事業者でアウトバウンドトラフィックの量がとても多くなるため、精度を上げれば上げるほど、Flow情報も相当多くなり必要な要求性能が上記の表よりも一気に跳ね上がります。
Flow Exporterについて
LINEではデータセンタが国内外の複数の拠点にあり、それぞれの拠点にEdge RouterとしてJuniper MX Routerを複数台導入しています。今回はこれらのルータからデータを取得します。
Ingress/Egress 両方のデータを取得するため、対象となる各インタフェースには下記の設定を入れています。
| set interfaces interface unit 0 family inet sampling input set interfaces interface unit 0 family inet sampling output |
全ての通信を収集することは困難なのでサンプリングを行っています。簡単に説明すると、サンプリングレートを1/1000に設定すると、1,000個に1個のパケットの情報を収集します。
1/2000, 1/4000とサンプリングレートを減らすとルータからのFlow数が減り、1/500, 1/250と増やすとFlow数が増えます。
サンプリングレートは使用している機器や実際の環境の通信量に応じて変更する必要があります。
要求されるリソースの算出
まずはじめに、実際に使うリソースがどのくらいかを調べるために、ルータ1台からFlowを収集するところからはじめました。
この際に使用したElastiFlowの基盤は、社内のプライベートクラウドサービスVerdaのVM上にデプロイしたものです。
VMに標準で提供されているディスク量だけでは足りないため、オブジェクトストレージをマウントしています。
このVMにはElastiFlowが提供しているDocker Compose Fileを一部編集して利用しました。
- Verda VM
- vCPU: 12
- Memory: 64GB
- Disk: SSD 100GB
- Object Storage: HDD 5000GB
- ElastiFlow Settings
- ES_JAVA_OPTS: -Xms32g -Xmx32g
- LS_JAVA_OPTS: -Xms4g -Xmx4g
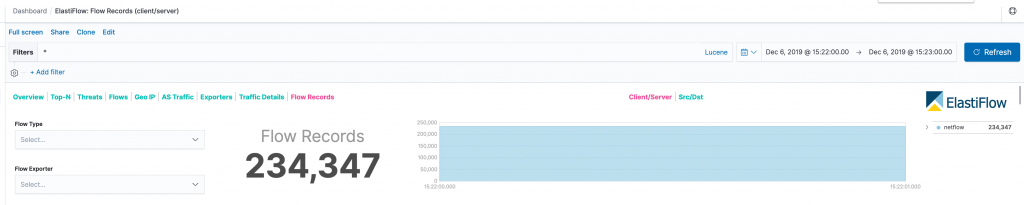
デプロイが完了したら後はルータにFlowを送る設定をすれば完成です。この環境で取得したFlow数は3,905 Flows/Secでした。
下記の画像は1分で取得したFlow数です。
ただこのElastiFlowの基盤はお試しで立てただけなので、運用面において複数の問題点があります。
- Elasticsearchのクラスタを組まず、またチューニングを一切せずに1つのVMにELK Stackを構築しているためダッシュボードが表示されない・表示が遅い。まともに見れるレベルではない
- 15分程のデータは辛うじて見れますが、24時間のデータを表示させるとタイムアウトして見れない
- Logstashの使用リソースがとても多い
- UDPのFlowパケットをデコードしているため使用リソースがとても高い
- Flow数が増えると使用リソースが増える
- 1台のみでこれだけのリソースを消費するので、全拠点のルータから送信されるFlow数は処理はできない
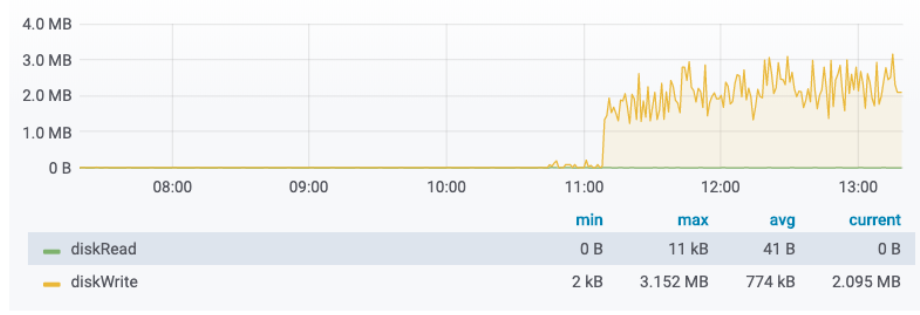
- ディスクの使用量
- 約4日間運用して450GB ※この時点では1ノードのためreplicaはない
- 長期間のデータを見れるようにするには、より多くのストレージが必要
| CPU Usage | Disk IO |
|---|---|
 |
 |
ElastiFlowの基盤について
リソースの算出後、全拠点のルータからFlowを取得しモニタリングをするための基盤を構築しました。
Logstash
まずFlowのCollectorになるLogstashについて説明します。
全拠点のFlow数は既存のツールで確認したところ、お試し環境で利用したルータの約3倍のFlow数の約11,000 ~ 12,000Flows/Sec程度ということがわかりました。このFlow数を処理するにはLogstashをマルチノードで動かすことが必要になります。
社内ではオンプレミス環境でプライベート Kubernetesクラスタを管理する仕組みVerda Kubernetes Service(以下VKS)があるので、スケールのしやすさの面からVKSの上にLogstashを展開しました。
VKSにLogstashをインストールする際はHelmを利用しました。下記がvalues.yamlの中身になります。
image: "robcowart/ElastiFlow-logstash-oss"
imageTag: "3.5.1"
logstashJavaOpts: "-Xmx8G -Xms8G"
replicas: 6
persistence:
enabled: false
resources:
requests:
cpu: 7000m
memory: 16G
limits:
cpu: 7000m
memory: 16G
cessThreshold: 1
extraEnvs:
- name: ElastiFlow_ES_HOST
value: "Elasticsearch-ingest:9200"
service:
type: NodePort
externalTrafficPolicy: Local
ports:
- name: netflow-udp
port: 2055
targetPort: 2055
nodePort: 30055
protocol: UDP
readinessProbe:
httpGet: null
tcpSocket:
port: 4739
initialDelaySeconds: 200
periodSeconds: 30
failureThreshold: 20
successThreshold: 1
livenessProbe:
httpGet: null
tcpSocket:
port: 4739
initialDelaySeconds: 200
periodSeconds: 20
failureThreshold: 5
successThreshold: 1
lifecycle:
postStart:
exec:
command: ["/bin/sh", "-c", "sed -i -e 's/number_of_shards": 3/number_of_shards": 14/g' /etc/logstash/ElastiFlow/templates/ElastiFlow.template.json && sed -i -e '/refresh_interval/a "lifecycle.name": "ElastiFlow-ilm-delete-policy",' /etc/logstash/ElastiFlow/templates/ElastiFlow.template.json"]
起動時にindex templateに書かれているshard数の変更とIndex Lifecycle Managementの適用をしています。
また検証時にはVKSにまだLoad Balancerが提供されていなかったので、NodePortで公開しているノードに対してLoad Balancingしてくれるものを用意する必要がありました。これにはNginxのTCP and UDP Load Balancingを利用しています。
TCP and UDP Traffic Load Balancingを利用するには --with-streamフラグが必要になります。ElastiFlowはFlowを送信しているルータをNetflowのパケットのsrc IPを見て判断しているため、NginxでSrc IPを変更しないようにproxy bindにtransparentの設定と戻りパケットがないためproxy_responses 0を設定しています。
TCP and UDP Load Balancing
https://docs.nginx.com/nginx/admin-guide/load-balancer/tcp-udp-load-balancer/
stream {
upstream logstash_udp_upstream {
server vks-woker-01:30055;
server vks-woker-02:30055;
server vks-woker-03:30055;
server vks-woker-04:30055;
server vks-woker-05:30055;
server vks-woker-06:30055;
}
server {
listen 2055 udp;
proxy_pass logstash_udp_upstream;
proxy_responses 0;
proxy_bind $remote_addr:$remote_port transparent;
}
}
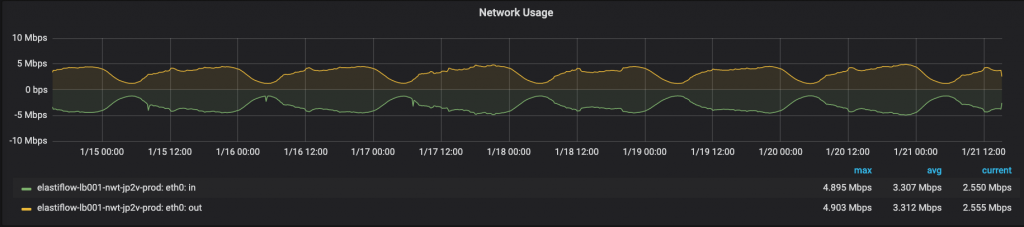
下記のグラフは現在動いているNginx Load Balancer VMのトラフィック量です。
Edge Router 6台分のFlowを送っていますがピーク時間帯(12,000 Flow/Sec)でも5Mbps程しかありません。CPU使用率についてはほぼ0%です。
LogstashをKubernetesに展開するにあたって遭遇したトラブルを2つ紹介したいと思います。
- LogstashのPodがずっとRestartしている
このトラブルの原因は、起動に時間のかかるコンテナイメージであるのにもかかわらず、ヘルスチェックのinitialDelaySecondsを起動時間より短く設定していたため、ヘルスチェックが起動中に失敗し永久に再起動しつづけることでした。
ElastiFlow LogstashのイメージはIPFIX-TCPに対応しているため、LivenessProbe/ReadinessProbeはIPFIX-TCPで利用するポートに対してtcpSocketでヘルスチェックを実施しています。
ElastiFlow Logstashのコンテナイメージの起動には時間がかかりますが、実際の起動時間よりもinitialDelaySecondsを短く設定していました。
そのため起動中にヘルスチェックが失敗になりRestartするというのを繰り返していました。
この問題はinitialDelaySecondsの時間を延ばすことで解決しました。 - ExporterのSource IPが変更される
ElastiFlowではFlowがどのルータから送られているかを、送られてくるNetflow UDPパケットのsrc IPを見て判定しています。
しかしこの本番環境用の基盤にFlow情報を送ったところルータのIPアドレスが全く関係のないIPアドレスになっていました。
これでは複数台のルータからFlowを送った際にどのルータから送られているのかを判別することはできませんでした。
Flowを送っているルータの設定ではsource-adddressをLoopback interfaceのIPにして送信していることと、
お試し環境ではこのトラブルが起きていなかったことから、どこかでSource IP Addressが書き換わっていると考えました。このトラブルはNodePortの動作が原因でした。
NodePortのサービスに来たパケットはデフォルトでSource NATされます。これはノードにパケットが到達した後に、別ノードのPodに対して分散させる機能があるためです。
Source NATさせないためにはexternalTrafficPolicyをLocalにする必要がありました。ただしLocalにするとSource IPは変わらなくなりますが、パケットが他ノードに転送されることが無いためトラフィックが不均衡になる場合があります。詳しくは以下のドキュメントを参照してください。
Using Source IP
https://kubernetes.io/docs/tutorials/services/source-ip/
Preserving the client source IP
https://kubernetes.io/docs/tasks/access-application-cluster/create-external-load-balancer/#preserving-the-client-source-ip
Elasticsearch
次にElasticsearchです。ElastiFlowは日単位でindexが作成されます。
お試し環境のデータから使用するディスク量を計算したところ、Replica 1にした場合に1indexに全拠点のルータを合わせて約700GBが必要になります。Verdaには性能が必要なもの向けに物理のマシン(以下PM)が提供されているのでデータノードにはこれらを利用しています。
データノードのスペックは以下のとおりで、14台使用しています。
- CPU: 20
- Memory: 64GB
- Disk: SAS 1.2TB

設計方針として1ノードに1shard配置してreplicaを1にしています。
現状用意したPMのディスク量だけではreplica 1でも21日程度しかデータを保存できないので、今後データノードを増やせたらreplicaを2以上にする予定です。shard数は14に設定して1shardがおおよそ25GBぐらいになる計算です。
下記の画像はElasticsearch-headでみたものですが、実際に保存されているデータも600 ~ 700GB/day 程度と計算通りになっています。
最終的に現在動いているElastiFlowの構成図と使用リソースは下記のとおりです。
(CPU/Memory/Disk)
- Logstash Pod * 6
- 7Core/16GB
- Elasticsearch
- Master node * 3
- VM
- 4vCPU/4GB/SSD 100GB
- Ingest node * 3
- VM
- 8vCPU/16GB/SSD 100GB
- Data node * 14
- PM
- 40CPU/64GB/SAS 1.2TB
- Master node * 3
- Kibana
- VM
- 8vCPU/16GB/SSD 100GB
実際に可視化されたデータ
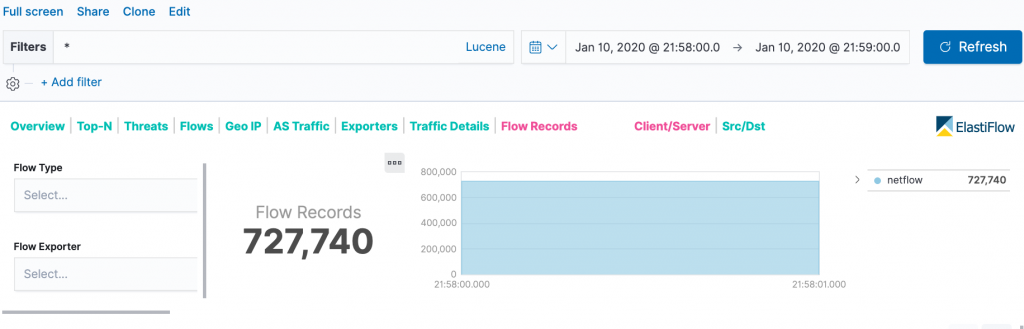
- ピーク時のFlow数
この数値はピーク時間帯の1分間に取れた全ルータの合計Flow数になります。約12,000Flow/Secを記録しています。
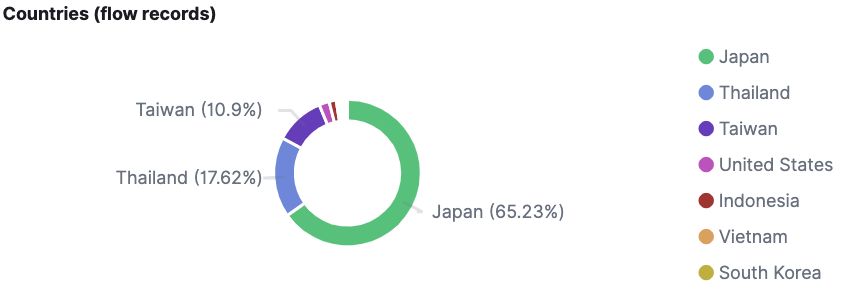
- 国別のFlow数
下記の図は国別のFlow数になります。
LINEは日本に次いで台湾、タイなどで多く使われていますが、それがFlow数からも確認することができます。
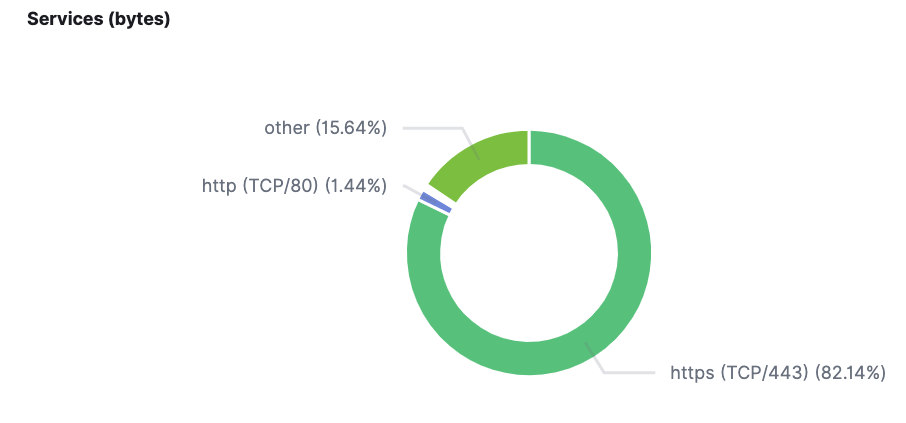
- サービスの割合
主要なサービスはHTTPSを使用しているため、HTTPSが8割以上を占めています。
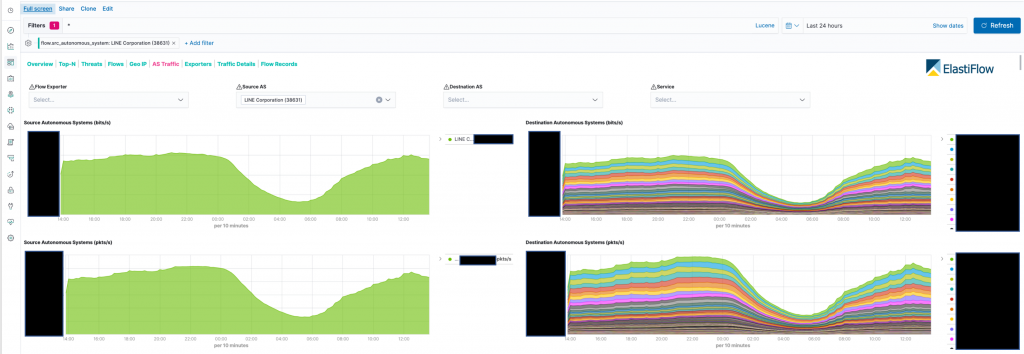
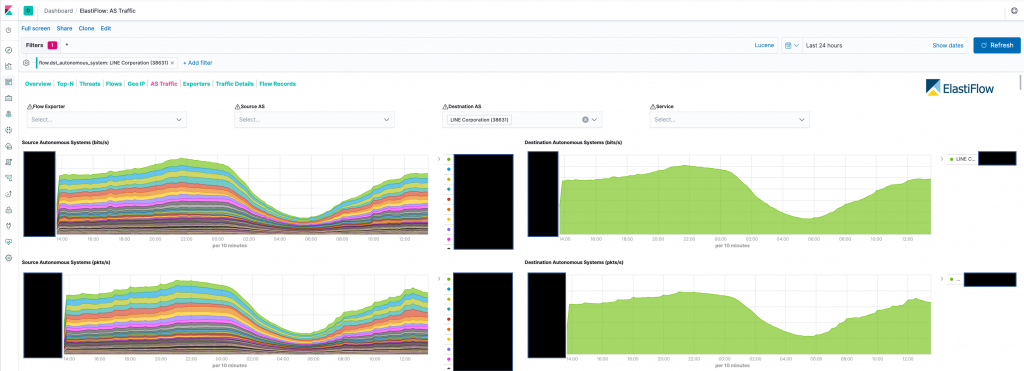
- Src/Dst AS Top N
このグラフは全ルータのAS別トラフィックのグラフです。
左側のスクリーンショットがSource ASがLINEになっているもので、右側がDestination ASがLINEになっているものです。
- とあるASまでのSankey diagram
とあるASまでの通信がどのトランジット事業者やピアリングしている事業者をどのくらいの割合で利用しているかを視覚的に確認したいときがあります。
このSankey diagramはとあるASに対してどのくらいのトラフィックが流れているかを表示しています。
またこのSankeyはElastiFlowで用意されていないため、作成にはKibanaにプラグインを追加して作成しています。
ElastiFlowはカスタマイズすれば、商用サービスで提供されているものとほぼ同等の可視化をすることができます。
ElastiFlowで作成したグラフ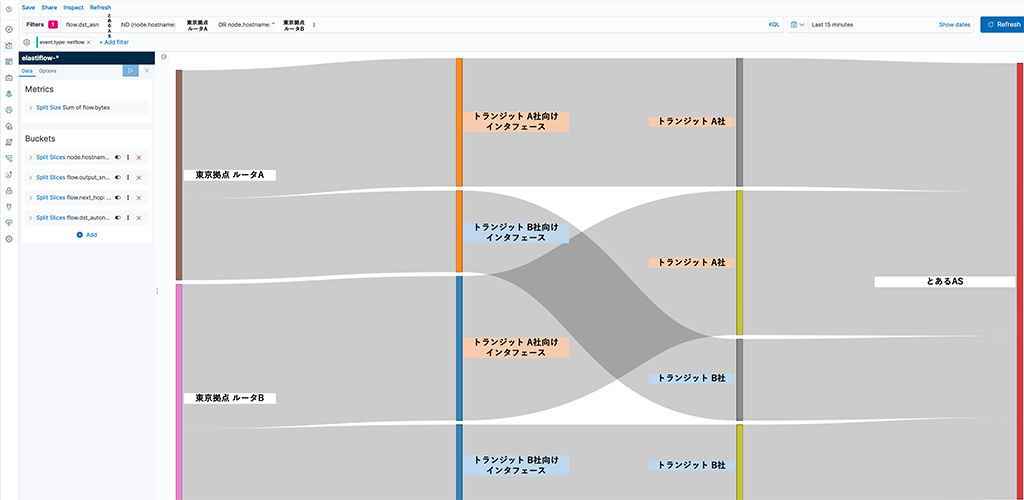
とある商用サービス Aで作成したグラフ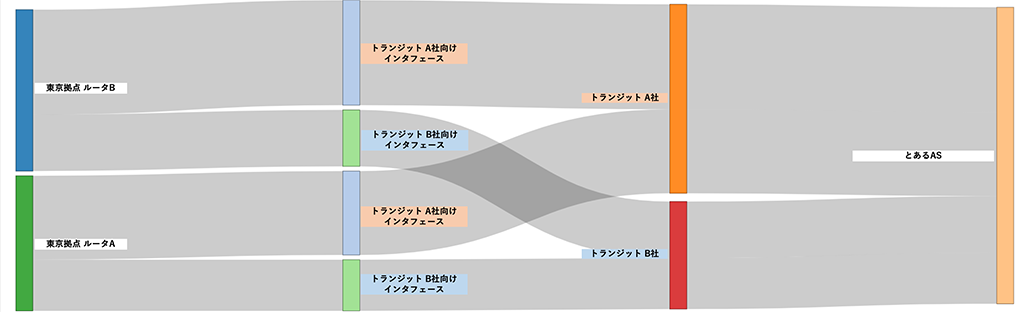
※商用サービスには、事業者ごとにインタフェースをグルーピングする機能が標準で備わっている - Outbound TrafficのSankey diagram
このSankey diagramではLINEが宛先ASに送信しているトラフィックの送信元インタフェースとネクストホップを表示しています。
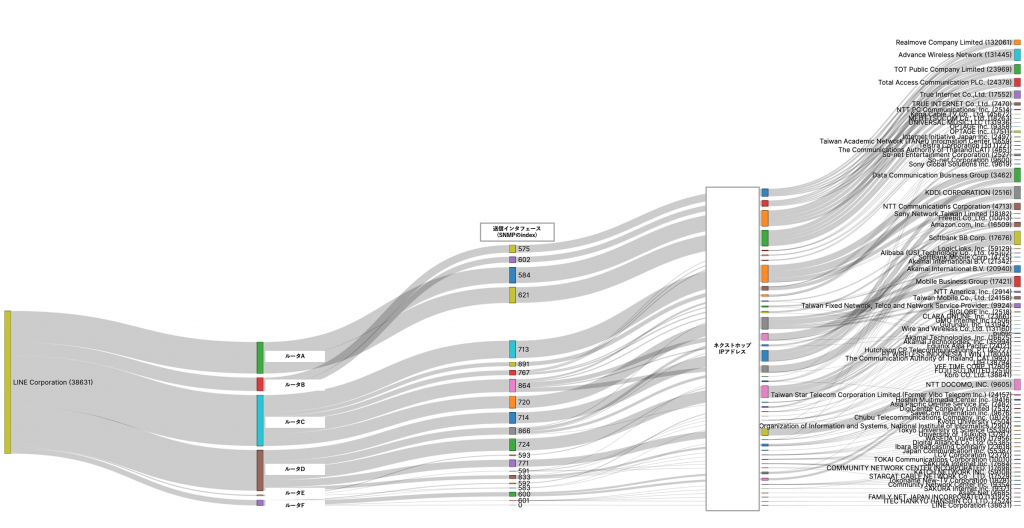
まとめ
以上がLINEで運用しているインターネットトラフィックの可視化ツールの紹介です。
ElastiFlowはしっかりとした基盤を作るのにそこそこのリソースが必要なのとElasticsearchの運用が大変というものがありますが、カスタマイズが独自にできて商用のサービスと変わらないものが表示できるのでとても優れているOSSだと考えています。しかし商用のサービスと比べてElastiFlow単体ではできないことがいくつかあります。それはBGPやSNMPといったFlow以外の情報を簡単に紐付けられないことです。
例えばある商用のサービスではFlow情報以外に、自社ルータとIBGPピアを確立し、BGPのルーティングテーブルを利用してAS_PATHの情報を組み合わせたSankey diagramが作成できます。これによってある宛先ASまでにどのインタフェースからパケットが出て、どのトランジットインタフェースを経由して、どのAS-PATHを通って到達するかを簡単に可視化することが可能です。ElastiFlowではどのASを通るかはAS_PATHの情報がないためできません。
またインタフェース名とDescriptionをSNMPで自動で取得し、グラフ上で自動で置き換えることができるものもあります。これらをElastiFlowで実現するにはある程度の作り込みが必要になります。今後はダッシュボードを見やすくするために、まずはインタフェース名の置き換えといったカスタマイズをしていきたいです。
みなさんもよければFlow情報の可視化に、ElastiFlowを使ってみてはいかがでしょうか。