
こんにちは。8月26日から5週間、Verda室のネットワーク開発チームというところでインターンをしていた齋藤遼河といいます。私は今回、データセンター内にあるネットワークノードのパケット処理の高速化についての開発を行っていました。今回は、その成果についてお話していきます。
背景
LINEでは多くのサービスをローンチしており、それらの多くはVerdaと呼ばれるプライベートクラウドに収容されています。Verdaはオーバーレイ技術によるネットワーク分離を行わないシングルテナント構成のL3ネットワーク上に構築されており、ノード間でお互いに直接通信できる仕組みになっています。この構成を採用したことによりネットワークのシンプル化が実現されましたが、一方でサービスによってはネットワーク分離をはじめとするマルチテナント構成が必要となるケースもあり、プライベードクラウドを提供する上で課題となっていました。
- https://www.janog.gr.jp/meeting/janog44/application/files/6815/6464/4550/jano44_srv6_tsuchiya-02.pdf
そのため、新しく作られたネットワークでは、SRv6を用いてマルチテナントな構成を実現しています。SRv6のパケットを処理できる機器はまだあまり無いため、Linuxカーネルを用いた実装を利用してSRv6のパケットを処理しているのですが、Linuxのネットワークプロトコルスタックは汎用的な作りになっているため、十分に高いスループットを出すことが出来ません。
より高速にSRv6のパケットを処理するために、今回私はXDPを用いてSRv6のパケットを高速に処理するプログラムを作成しました。
Segment Routingとは
Segmentはパケットに対する指示(Function)を表しています。例えば、「最短経路でとあるノードに転送する」や「とあるルックアップテーブルを見て次の送り先を決定する」などがSegmentになります。送信者がこのようなSegmentをパケットに対して付けることで、パケットの流れる経路を自由に制御するという仕組みがSegment Routingというものになります。
ネットワーク内でSegmentを一意に識別するために、SIDと呼ばれるIDが割り当てられています。データセンター内で使われているSRv6の場合、SIDはIPv6アドレスの形にエンコードされています。通るべきSegmentのSIDは、Segment Routing Headerと呼ばれるIPv6拡張ヘッダーの中に格納されます。
よく使われる基本的なFunctionの例として、次のようなものがあります。
- End: 特に何もしない(経由するだけ)
- End.DX4: Segment Routing Headerを外してから特定のnexthop(IPv4アドレス)に転送する。
- End.DT4: Segment Routing Headerを外してから特定のルーティングテーブルを用いてパケットを転送する。
他にも、様々な基本的なFunctionが定義されています。
また、Functionは自分で作成することもでき、「ファイアウォールに通す」や「パケットをダンプしてpcapに残す」などといった独自のFunctionを加えることで複雑な要件のサービスも単一のネットワークに収容することができるようになります。
XDPとは
Linuxのネットワークプロトコルスタックは様々なプロトコルをサポートしていたり、様々な地点でフックをかけられるようになっています。セキュリティや利便性という点から見ると無くてはならない機能なのですが、とにかく高速にパケットを処理したいというときにはそれらのオーバーヘッドが無視できなくなってきます。
XDPはLinuxで高速パケット処理を実現するための技術の1つです。ネットワークプロトコルスタックの最下位(デバイスドライバの内部)でパケットを処理するためのプログラムを動かすことが出来ます。他の高速パケット処理基盤と比べて、Linuxとの親和性がとても高いというのが特徴です。例えば、パケットを転送先を格納するFIBテーブルはLinuxカーネル内にあるものを利用できたり、ARPや自分で処理できないパケット(ICMPやBGPのパケットなど)はネットワークプロトコルスタックに処理を投げたりすることができます。
実装について
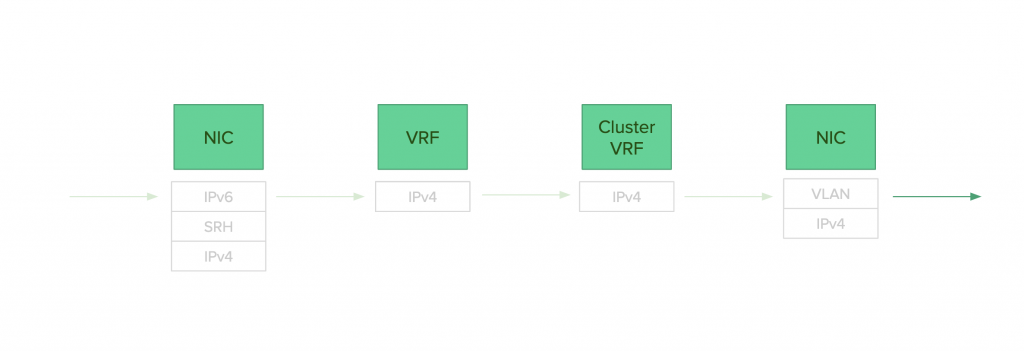
現在デプロイされているLinuxカーネルを用いた実装では、次のような流れでパケットのdecapsとencapsを行います。
decaps
- SRドメインからパケットを受信する。
- End.DX4を行い、Nexthopに指定されているVRF(l3mdev)にパケットが転送される。
- VRF内のdefault routeであるCluster VRF(l3mdev)にパケットが転送される。
- Cluster VRFからパケットが転送される。この時に、NexthopとしてVLANインターフェースが指定されている。
- もう一方のインターフェースからパケットが送信される。
encaps
- パケットを受信する。
- VLANタグが外されCluster VRFからパケットがVRFに転送される。
- VRF内に書かれているencapsルールによってパケットがencapsされる(T.encaps)。
- パケットがSRドメインに送信される。
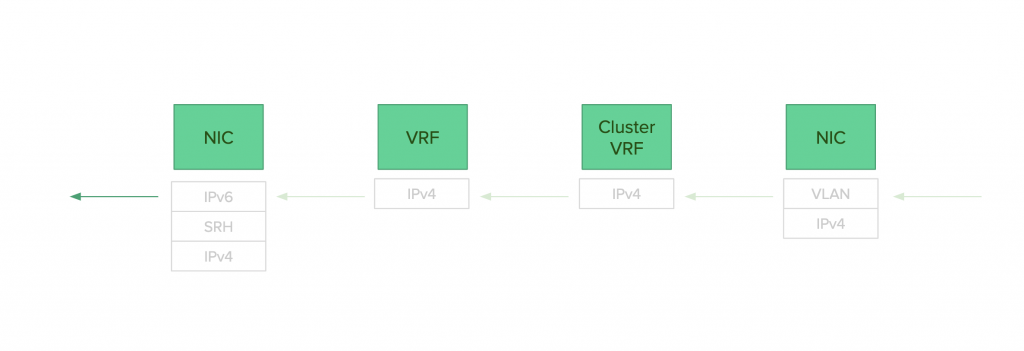
LinuxでEnd.DT4相当の機能がないためこのような構成にしているのですが、何度もパケットが内部で転送されるためにあまりスループットを出すことが出来ませんでした。
そのため、今回実装したプログラムではLinuxカーネルで行われていることと同様な処理をXDPで行うことで高速にパケット処理を行いました。具体的には、次のような流れでパケットのdecapsとencapsと行います。
decaps
- そのパケットがXDPで処理されるべきパケットかを判断し、そうでないならXDP_PASS(Linuxカーネルに処理を投げる)を返す。
- パケットが正しいフォーマットであるかを検証し、そうでないならXDP_DROP(パケットを破棄する)を返す。
- パケットにかかれているSIDから通るべきCluster VRFのifindexと割り当てるべきVLAN IDを取得する。
- fib_lookupというhelper functionを用いて、Cluster VRFに紐付いているルーティングテーブルからnexthopのMACアドレスを取得する。この際に、neighborが解決できていなければXDP_PASSを返す。
- パケットの書き換えを行い、もう一方のインターフェースにXDP_REDIRECT(インターフェースからパケットを送出する)を返す。
encaps
- そのパケットがXDPで処理されるべきパケットかを判断し、そうでないならXDP_PASS(Linuxカーネルに処理を投げる)を返す。
- パケットについているVLAN IDとdestination IPv4 addressからつけるべきSIDを取得する。
- fib_lookupを用いて、nexthopのMACアドレスを取得する。
- パケットの書き換えを行い、XDP_REDIRECTを返す。
このような処理にすることで、Linuxカーネルで行うよりもfib_lookupの回数を減らすことができ、結果としてスループットが向上します。
性能測定
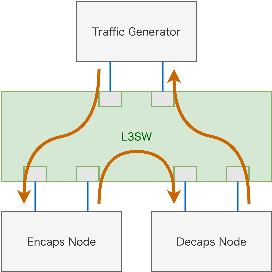
以下のような環境でLinuxカーネルを用いた実装と今回実装したプログラムの性能測定を行いました。Traffic Generatorから送出されたパケットは矢印の経路を通ってTraffic Generatorに戻ってきます。
- Traffic Generator
- CPU: Intel(R) Xeon(R) CPU E5-2630 v4 x2
- MEM: 256GB
- NIC: Intel XL710 40GbE 2port x1
- Kernel: 3.10.0-693.21.1.el7.x86_64
- Generator: TRex v2.50
- Encaps Node / Deacps Node
- CPU: Intel(R) Xeon(R) Silver 4114 CPU x2
- MEM: 128GB
- NIC: Mellanox MCX516A-CCAT 100GbE 2port x1
- Kernel: 5.3.0-rc5.1.20190902.el7.x86_64
- L3SW
- Mellanox SN2700
- OS: Cumulus Linux 3.5.3
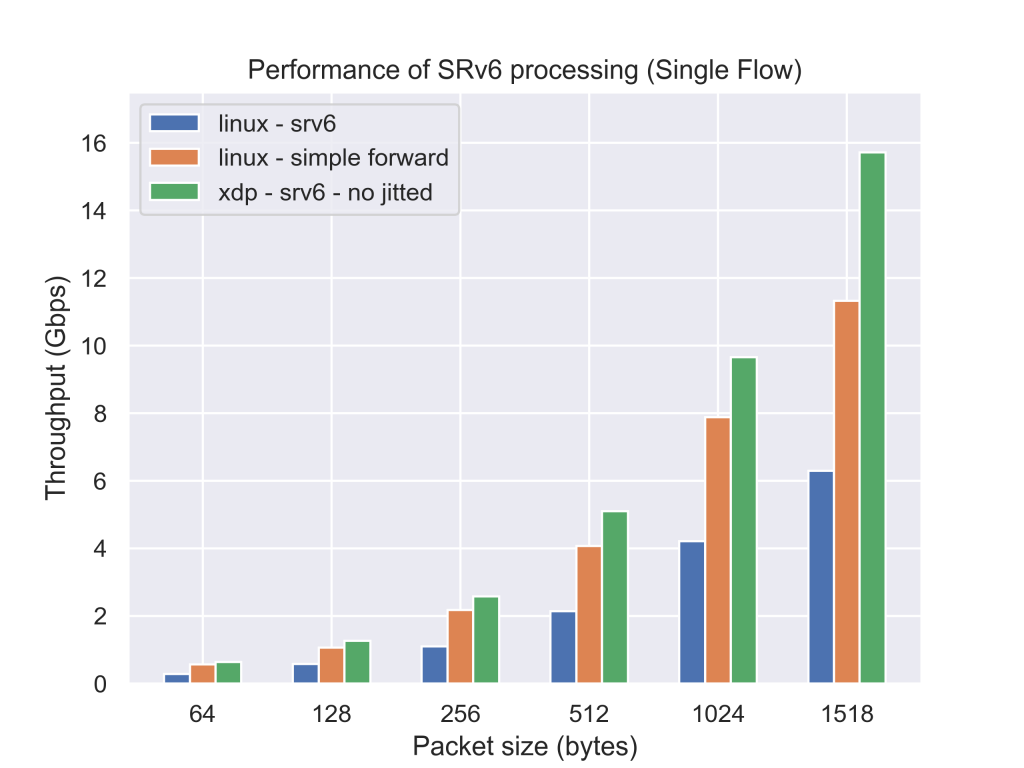
また、以下の条件で測定を行いました。
- Single Flow(source IPv4 addressとdestination IPv4 addressの組が1つだけ)のパケットを送出した。
- 10秒間パケットを送出し、1パケットもロスしない最大スループットを二分探査で測定した。
- パケットのペイロードのサイズを64, 128, 256, 512, 1024, 1518bytesに設定した。
- 5回測定し、最良値と最悪値を除いた3回の平均を計算した。
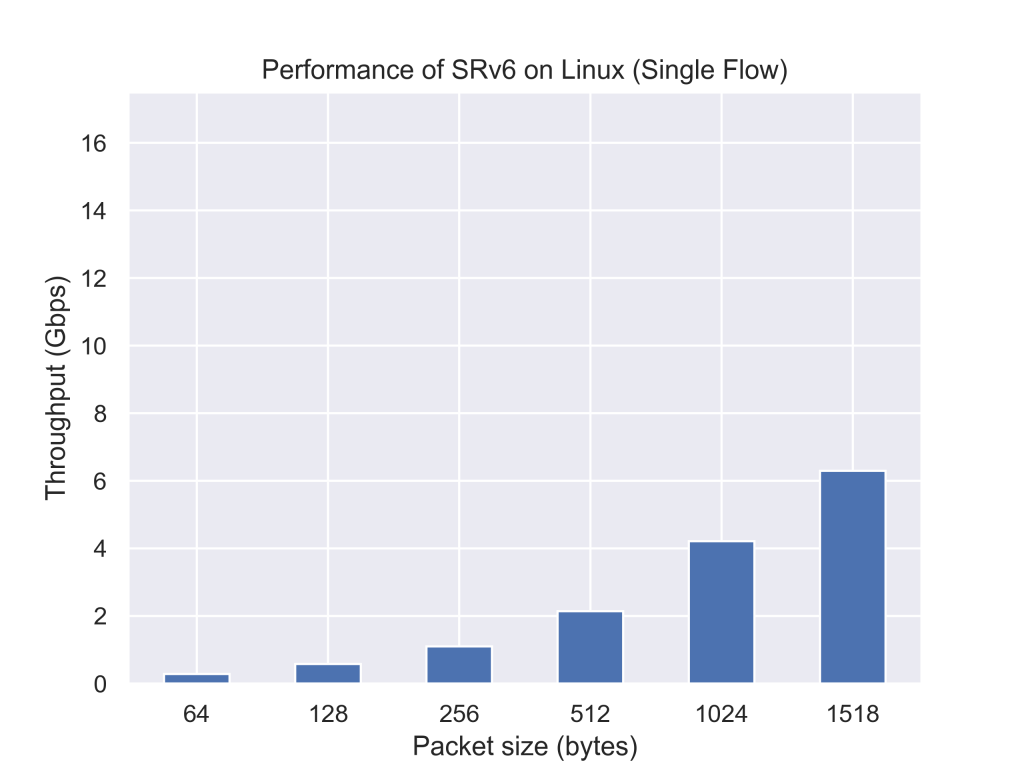
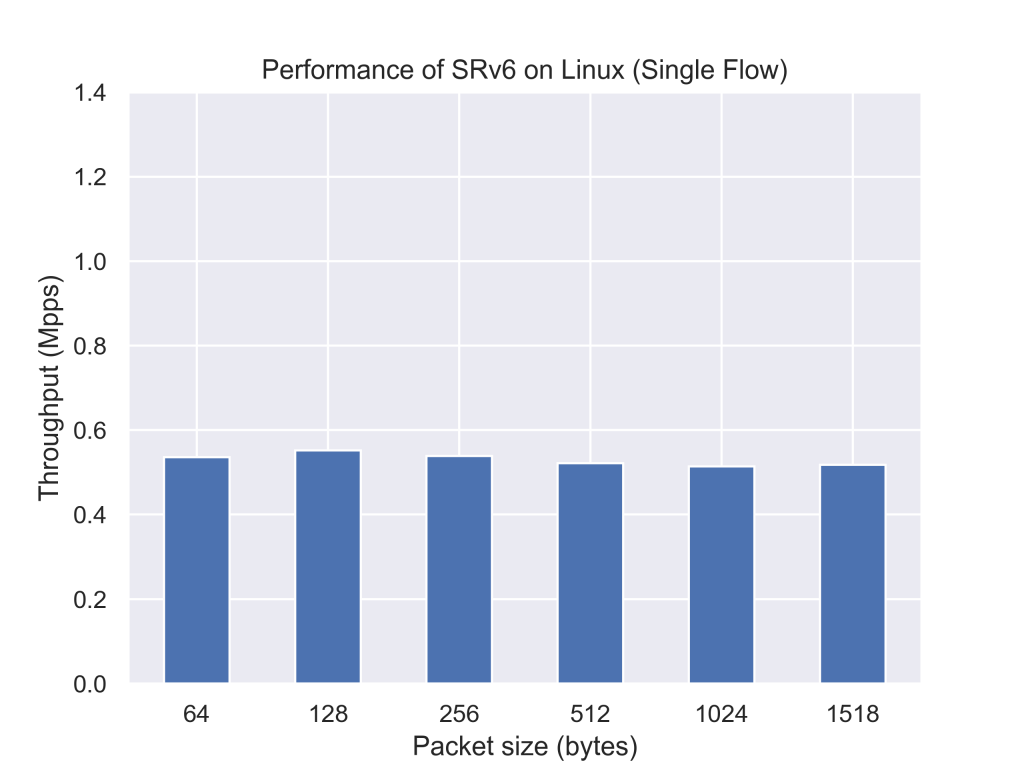
参考としてただのL3転送のスループットの測定結果もsimple forwardとして示します。
 |
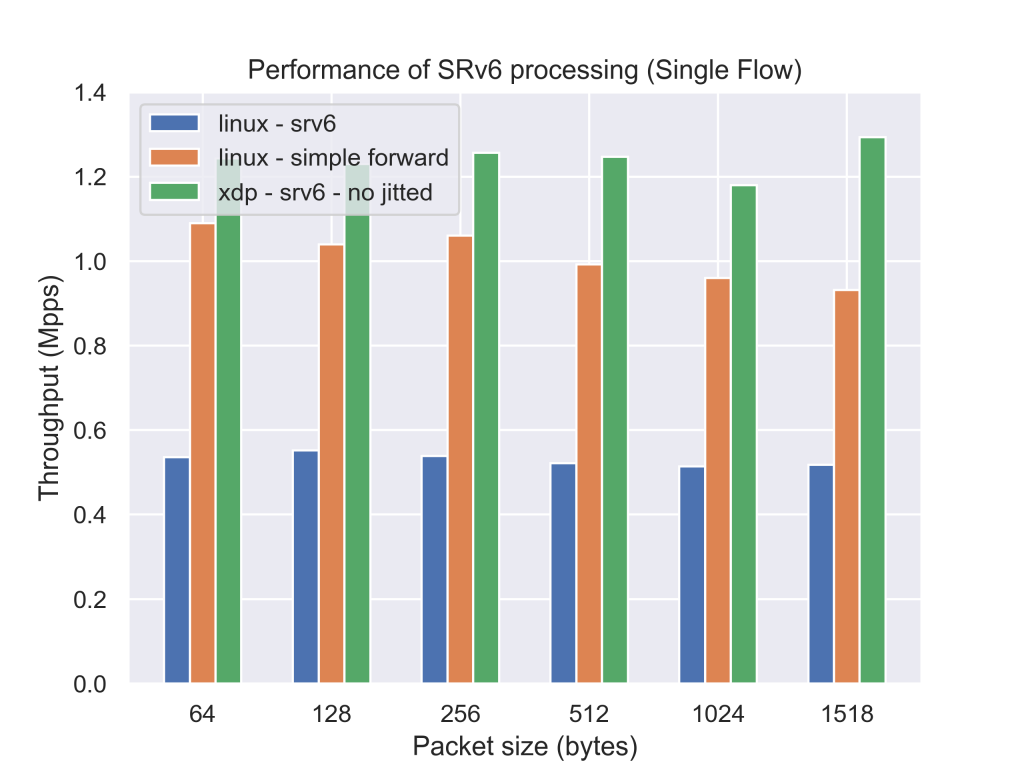 |
現在のLinuxカーネルを用いた実装に比べて、今回実装したプログラムは約2.5倍パケットを転送できていることが分かります。今回のXDPのプログラムはJIT(Just in time)コンパイルをかけていないため、JITを有効にすると更に性能が向上することが期待できます。
改善点
今回作成したXDPのプログラムはSingle Flowの通信においてはLinuxカーネルを用いた実装に比べて十分に高い性能を出せたと考えていますが、まだいくつか改善点が残っています。
まず初めに測定条件をMulti Flowに変更したときの性能についてです。Multi Flow(destination IPv4 addressを/24の中からランダムに選択する)のなパケットを送出してやると、RSS(Receive Side Scaling)が働き、パケットの処理が複数のコアに分散されます。そのためより、高いスループットを実現することが可能なのですが、30Gbpsを超えるかどうかくらいのあたりになるとスループットが頭打ちになってしまうという点です。単位時間あたりに転送できるパケット数の部分で頭打ちにあっていることを考えると、XDPのプログラム以外の部分でボトルネックがあるのだろうと考えられるのですが、その部分をインターン期間中に見つけ出して改善することが出来ませんでした。自分の作ったプログラムの性能限界を見てみたかったのですが少し残念です。
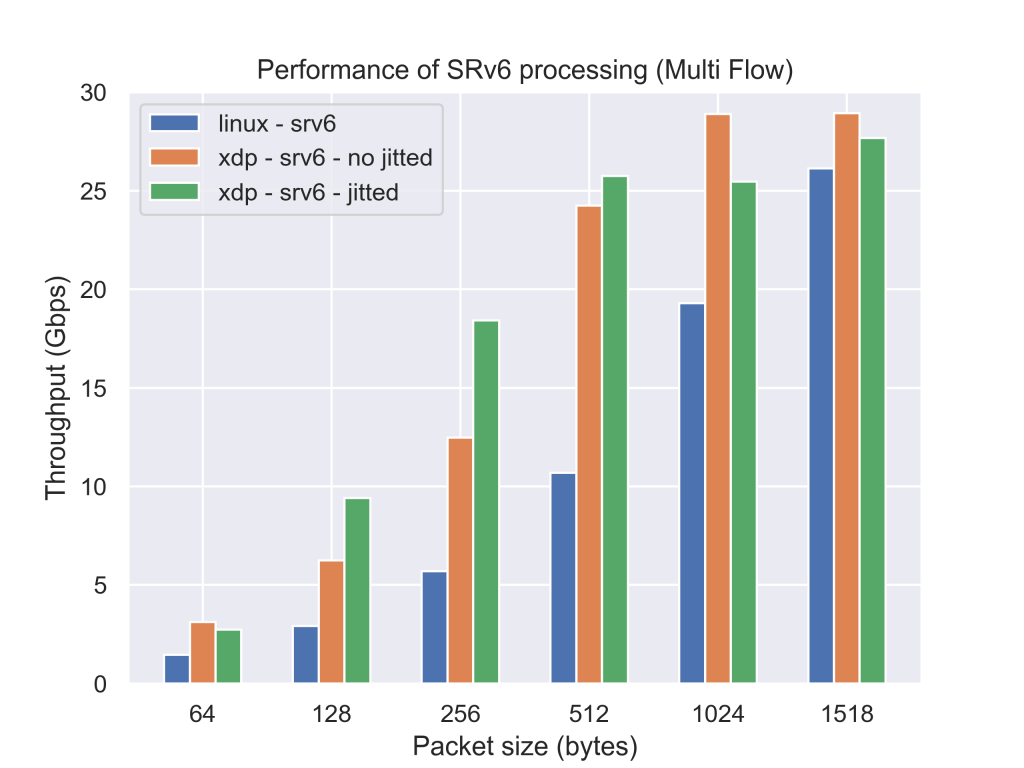 |
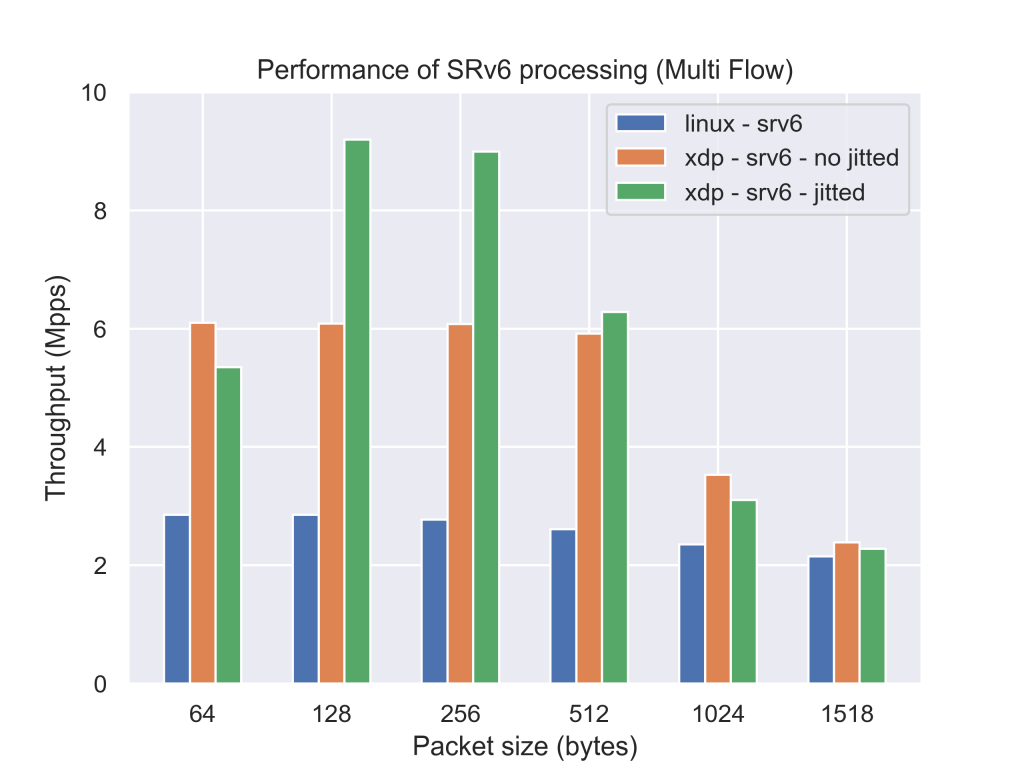 |
その次に、時間が無く手がつけられなかった実装をどうにかしたかったことです。まだ利用していない高速化のためのオプションを利用してみたり、ルールを格納しているデータ構造を変更してやることでより高速に処理できるのではないかと考えている部分があるのでそれに着手したかったです。また、複数のSIDをつけるのに対応していないのでそのあたりもいづれ対応していきたいと考えています。
まとめ
新しい技術の学習から始まり、プログラムの設計・性能評価・結果の考察・改善案を考えるまでの一連の流れをひと夏で体験できたのはとても充実していて楽しかったです。また、普段自分が使っているサービスの裏側でどのように通信が処理されているのかを知ることが出来たのはとても嬉しかったです。業務以外の部分でも、無料の朝食が提供されていたり、同じチームのメンバーと様々な技術の話ができたり、通勤や宿泊施設が良かったりとすごくQoLの高い夏になりました。本当にありがとうございました。
