
初めまして。奈良先端科学技術大学院大学修士1年の西川勇太です。2022年夏にLINE株式会社の就業型インターンシップに6週間参加しました。インターンシップではAI開発室のSpeechチームに所属し、「BERTの知識蒸留によるEnd-to-End音声認識の性能向上」のテーマで研究を行いました。本インターンシップの内容は学会に投稿予定のため、本記事ではその一部の内容のみを紹介させていただきます。
問題背景・目的
近年、End-to-Endモデルによる音声認識手法が目覚ましい成果を上げており、注目を浴びています。この手法は、従来の音響モデル、言語モデル、発音辞書を組み合わせて構成されるモデルと比較して、シンプルなアーキテクチャでかつ、高い精度での推論を可能とします。このEnd-to-End音声認識モデルは大きく分けて自己回帰型のモデルと非自己回帰型のモデルの2通りのモデルがあります。まず、自己回帰型のモデルはAED(Attention Encoder-Decoder)モデル[1][2]やRNN Transducer[3][4]などがありまず。これらの自己回帰型のモデルは、各トークン間の依存関係をうまく学習することにより、文脈情報や意味情報を考慮した推論を可能とするため高い性能を発揮しますが、同時に推論速度が遅いという欠点を持ちます。次に、非自己回帰型のモデルはCTC(Connectionist Temporal Classification)モデル[5]があり、入力音声の特徴量と出力トークンのアライメントを非自己回帰的に出力するように学習されます。このCTCモデルは、自己回帰型のモデルと比べて音響情報に強く影響を受けた推論を行い、かつ高速な推論が可能です。しかし、トークン間の依存関係をうまく学習に取り入れることが出来ないという欠点も持ちます。実際のプロダクトに音声認識システムを組み込むためには高速な推論を必要とする場合が多く、そのためには非自己回帰型のCTCベースモデルにおいて、各トークン間の依存関係をいかに扱うかが重要となります。
今回のインターンシップでは、CTCベースモデルに対して各トークン間の依存関係を学習することで、音響情報と文脈・意味情報の両方を強く考慮した非自己回帰型モデルを構築し、End-to-End音声認識モデルの性能向上を目指しました。
手法
今回、Conformer[6]+CTCの非自己回帰型のEnd-to-End音声認識モデルに対して、大規模言語モデルであるBERT[7]から知識蒸留を行うことにより性能の向上を目指しました。今回のモデルの構築について、2段階に分けて説明します。
1. CTC/AEDハイブリッドモデル(ベースモデル)
まず、ベースモデルとしてCTC/AEDハイブリッドモデルを構築しました。(Fig.1)
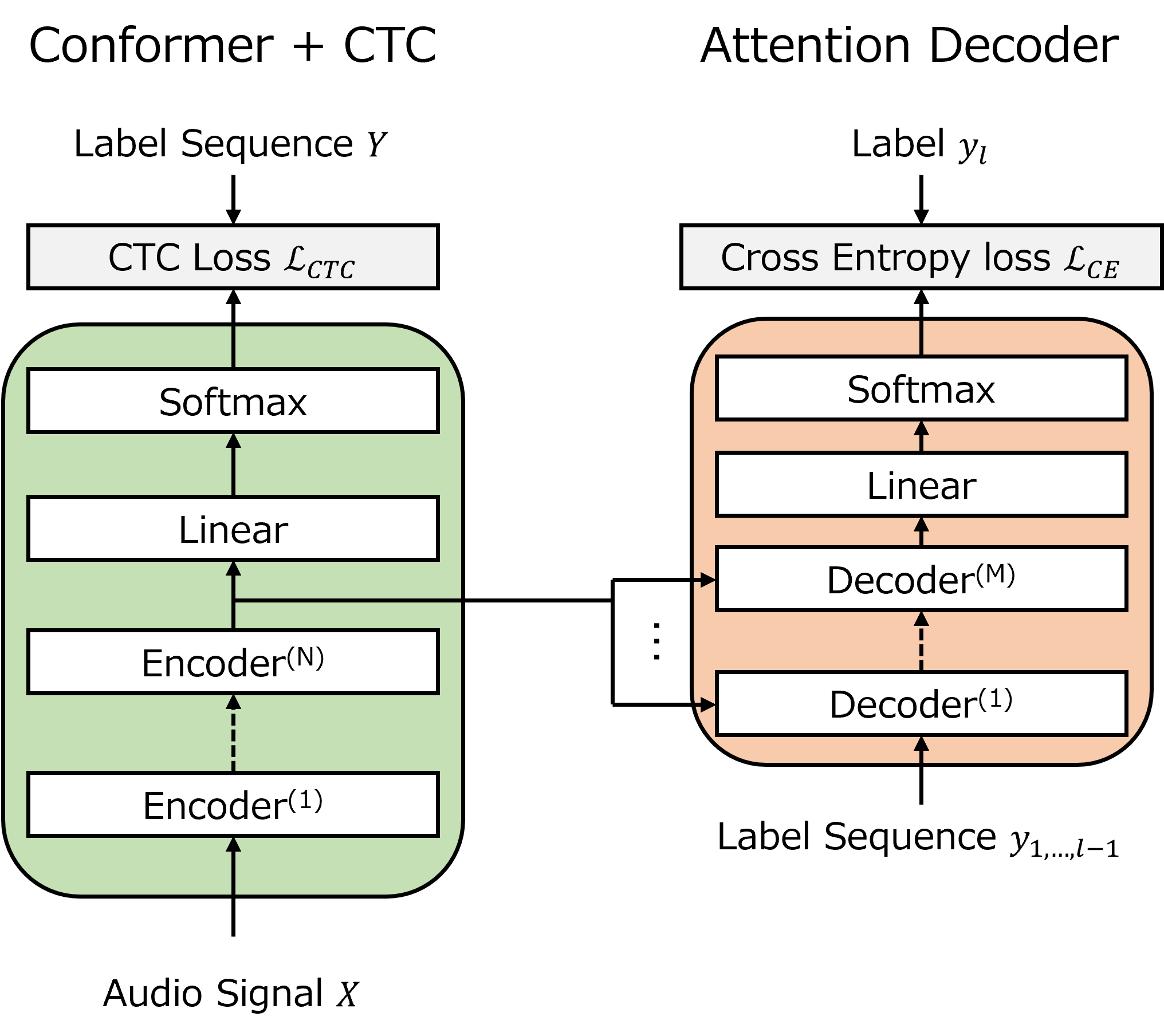
CTC/AEDハイブリッドモデルは、Conformer+CTCモデルをベースとし、学習時にConformer Encoderの最終層にAttention Decoder(Transformer Decoder)を接続したものです。Attention DecoderはTeacher Forcingにより正解トークンの系列を入力して受け取り、自己回帰的に次単語予測のタスクを解きます。これにより、Attention Decoderが学習する意味的・文脈的情報をConformer Encoderに伝播し、Conformer+CTCモデル単体でより意味的・文脈的情報を考慮した推論が可能になります。
また、本モデルで計算するLoss関数として、それぞれのモジュールでのLoss関数の重み付き和を定義します。
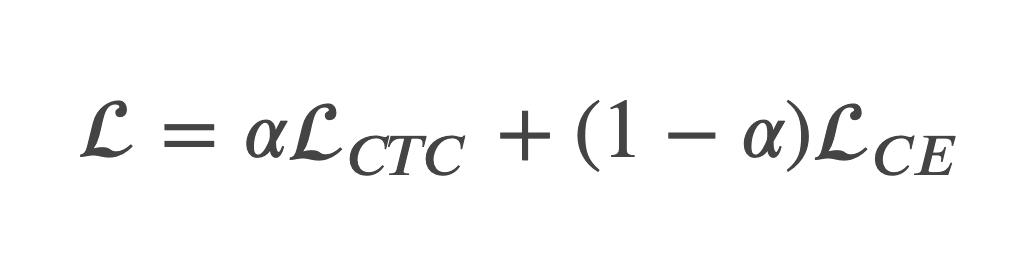
LCTCはCTC Loss、 LCEはAttention Decoderで計算されるSmoothed Cross Entropy Lossを表します。また、係数である𝛼は手動で設定し、今回は𝛼=0.3と設定しています。本モデルでの推論時は、Attention Decoderを用いず、Conformer+CTCモデルのみを用いることにより、非自己回帰的な高速な推論を行います。
2. 知識蒸留モデル
次に、1.で説明したモデルをベースに、知識蒸留を行うモデルを構築しました。(Fig.2)
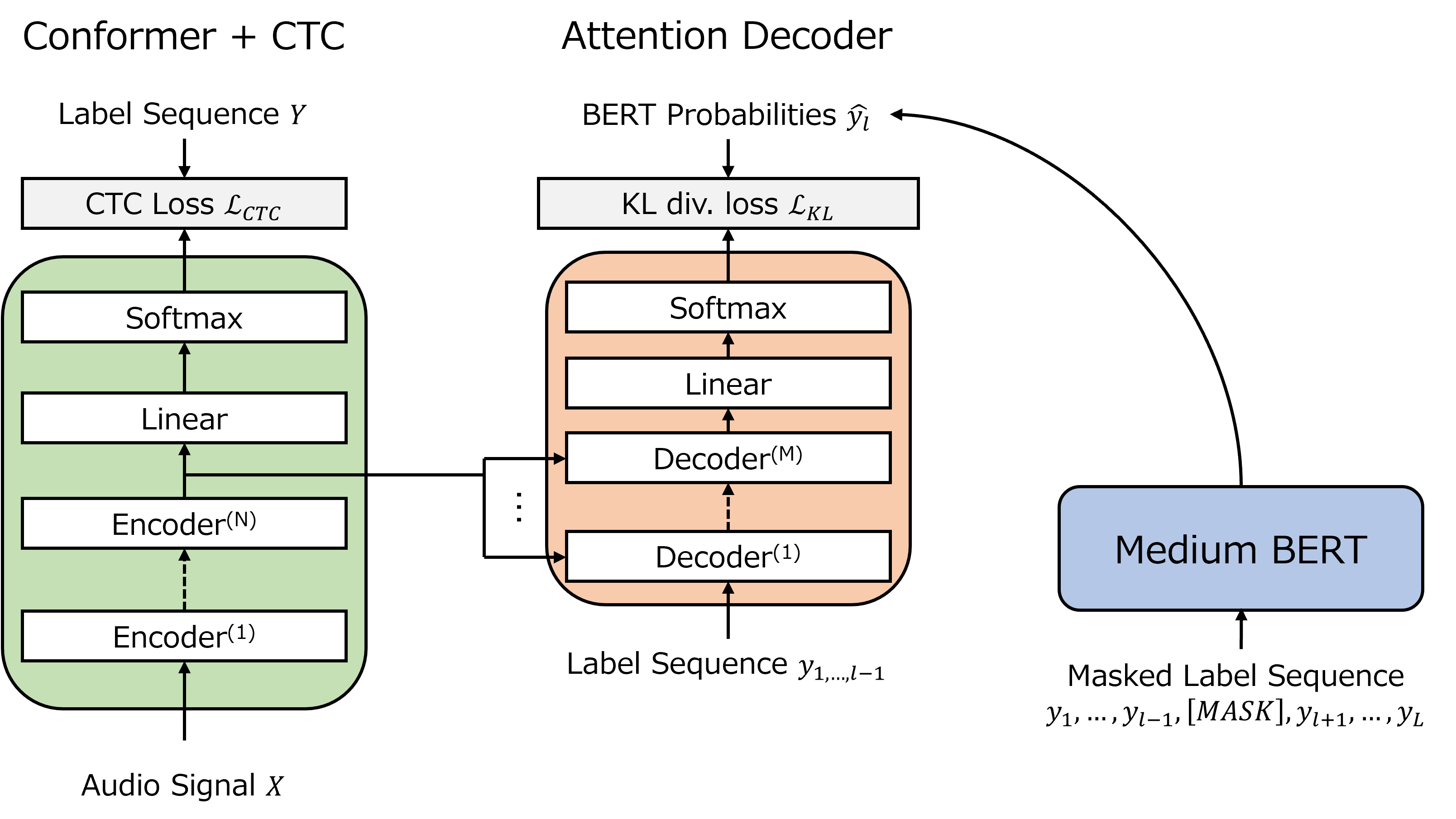
知識蒸留モデルでは、CTC/AEDハイブリッドモデルのAttention Decoderに対して知識蒸留を行います。Attention DecoderはTeacher Forcingにより正解トークンの系列を入力として受け取り、次単語のBERTの確率分布を予測するようにLoss関数を計算します。ここで、BERTから知識蒸留を行う理由は、BERTはMasked Language Modelと呼ばれるタスクでBidirectionalな文脈情報を学習しているからです。そのため、BERTから出力される確率分布にはBidirectionalな情報が入っており、その分布を正解ラベルとすることにより、生徒モデルであるAttention DecoderがBidirectionalな文脈理解をすることが出来ます。
本モデルのLoss関数として、CTC/AEDハイブリッドモデルと同様にそれぞれのモジュールでのLoss関数の重み付き和を定義し、その値を最小化するように学習を行いました。
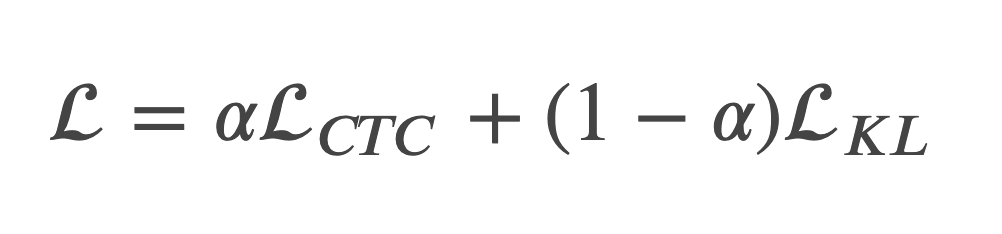
LKLはAttention Decoderで計算されるKL Divergence Lossを表しており、ベースモデルと同様に 𝛼=0.3と設定しています。
実装
実装は、音声認識、自然言語処理、音声合成のための深層学習ツールキットであるNVIDIA NeMo[8]を用いて行いました。今回のモデル構築にあたり、既に実装されていたCTC/AEDハイブリッドモデルに、以下のモジュールを追加実装しました。
- Attention Decoder用のGreedy Decoding関数(正しく学習されているかを確認するために実装しました。)
- Attention Decoder用のWER計算モジュール
- BERT確率のDataloader
- 知識蒸留モデル
- NeMo用のKL Divergence Lossモジュール
初めはNeMoに全く触れたことが無く、どこになにがあるか、どのように動いているかなど全く分からない状態からのスタートでした。そのため、コードを書く時間よりも読む時間の方が長く、大変でした。しかし、メンターさんに度々助けて頂くことで、最終的には自分だけでコードを読んで実装出来るようになるまで成長することができました。
実験結果
実験として、英語音声話し言葉コーパスであるLibriSpeech[9]の960時間データセットを用いてモデルの学習を行いました。入力音声はあらかじめ前処理としてメルスペクトログラムに変換し、SpecAugment[10]によるデータ拡張を行いました。今回比較したモデルは、Conformer Encoderに加えてCTCのみを用いたモデル、Conformer Encoderの最終層にAttention Decoderを接続したCTC/AEDモデル、CTC/AEDモデルに知識蒸留を行ったモデルの3つです。それぞれの学習済みモデルを、LibriSpeechのdev_clean、test_clean、dev_other、test_otherのベンチマークでWER%を評価しました。(Table.1)
Table.1 LibriSpeechによる比較実験結果
| Model | WER% | |||
|---|---|---|---|---|
| dev_clean | test_clean | dev_other | test_other | |
| Conformer + CTC | 3.86 | 4.11 | 9.76 | 9.83 |
|
Conformer + CTC/AED |
3.43 | 3.69 | 9.02 | 8.79 |
|
Conformer + CTC/AED w/ Distillation |
3.06 | 3.23 | 7.28 | 7.42 |
結果から、以下の事が明らかとなりました。
- CTCとAEDでハイブリッドLossをとることにより、CTCのみのモデルと比べて性能が向上した。
- Attention Decoderに対して知識蒸留を行うことにより、大きく性能が向上した。
これらより、AEDモデルによるマルチタスクや、BERTからの知識蒸留が音声認識の性能向上に良い影響を及ぼしている事が分かりました。この結果は、言語的な文脈理解は音声認識において非常に重要な役割を担っている事を示唆しています。
さいごに
今回のインターンシップでは、「BERTの知識蒸留によるEnd-to-End音声認識の性能向上」のテーマで研究に取り組みました。結果として、Attention DecoderをConformer+CTCに接続したモデル上に知識蒸留を行うことで、非自己回帰モデルの音声認識性能が大きく向上することが分かりました。学会には、知識蒸留の手法をさらに工夫した手法を投稿する予定です。
インターンシップ期間は、非常に学びが多かったです。インターンシップは普段の大学院の研究室での研究生活と異なり、時間が限られた環境の中での研究生活でした。そのため、「どのようにすれば効率的にモデルを実装・学習できるか」、「何に優先して取り組むべきか」を常に考えながら過ごし、研究を効率よく進めるために必要なノウハウを学びつつ研究に取り組むことが出来ました。また、Speechチーム共用のリポジトリにPRを送り、コードレビューをして頂くといった機会があったため、実務レベルのコードを書く力も少し身についたかと思います。そして、実装力や知識面でも大きく成長できたと思います。ここで身に着けた力を、これからの自分の研究やキャリアで着実に活かしていこうと思います。
最後になりましたが、Speechチームの皆様、人事の皆様、そして特にメンターの方には大変お世話になりました。沢山多面的にサポートして頂けたおかげで、非常に濃密で、有意義で、何より楽しい時間を過ごすことが出来ました。
短い間でしたが、ありがとうございました。
参考文献
- William Chan et al., "Listen, attend and spell: A neural network for large vocabulary conversational speech recognition", in 2016 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 2016, pp.4960-4964
- Shinji Watanabe et al., "Hybrid CTC/Attention Architecture for End-to-End Speech Recognition", IEEE Journal of Selected Topics in Signal Processing, vol.11, no.8, pp.1240-1253, 2017
- Alex Graves, "Sequence Transduction with Recurrent Neural Networks", in International Conference of Machine Learning (ICML) Workshop on Representation Learning, 2012
- Alex Graves et al., "Speech recognition with deep recurrent neural networks", in 2013 IEEE International Conference on Acoustics, Speech and Signal Processing, 2013, pp.6645-6649
- Alex Graves et al., "Connectionist Temporal Classification: Labelling Unsegmented Sequence Data with Recurrent Neural Network", in Proceedings of the 23rd International Conference on Machine Learning, 2006, pp.369-376
- Anmol Gulati et al., "Conformer: Convolution-augmented Transformer for Speech Recognition", in INTERSPEECH, 2020, pp.5036-5040
- Jacob Devlin et al., "BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding", in NAACL HLT, 2019, pp.4171-4186
- Oleksii Kuchaiev et al, "Nemo: a toolkit for building ai applications using neural modules", arXiv preprint arXiv: 1909.09577, 2019
- V. Panayotov et al., "Librispeech: An ASR corpus based on public domain audio books," 2015 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 2015, pp. 5206-5210
- Park, D.S. et al., "SpecAugment: A Simple Data Augmentation Method for Automatic Speech Recognitio," Proc. Interspeech 2019, 2613-2617