
こんにちは、黒澤友哉と申します。 2022 年 8 月 15 日から 6 週間、LINE株式会社の NLP 開発チーム(現在は NLP チーム)で就業型インターンシップを行ないましたので、その内容を報告していきたいと思います。私は東京大学情報理工学系研究科コンピュータ科学専攻の修士で、自然言語処理を専門としています。所属は谷中研究室です。
0. 概要
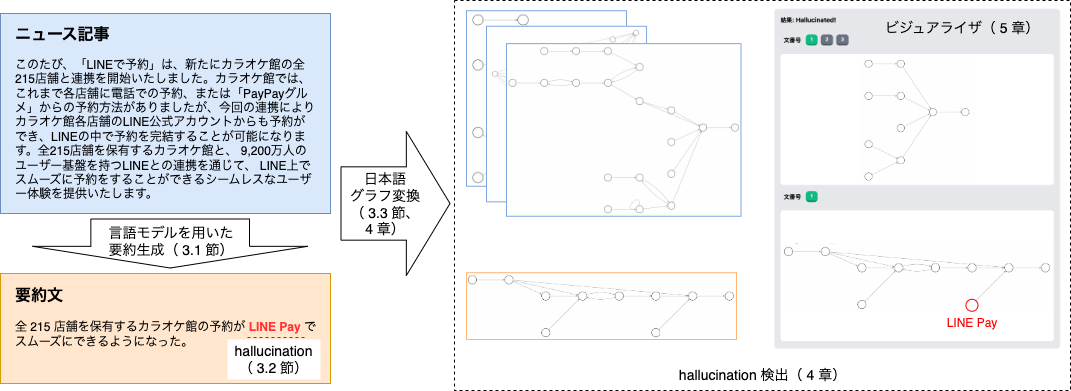
本文に入る前に、このレポートの概要を書きます。以下の図はこのインターンレポートの背景と手法をまとめた図です。このレポートでは第 3 章で「言語モデルを用いた要約生成」、「hallucination」、「日本語のグラフ」について説明した後、第 4 章でグラフ生成手順と hallucination 検出の手法、第 5 章でビジュアライザを紹介し、第 6 章以降でデモと課題を説明するという構成となっています。
1. はじめに
自然言語処理という分野(もはやどの分野でもそうかもしれないですが) では機械学習を用いた手法が多くを占めています。DeepL は機械学習を用いた有名な機械翻訳ツールであり、論文を読んだり書いたりするのに重宝されている方がいるかもしれません。分野に限らず執筆時点(2022 年 9 月中旬)でのホットな話題は、Midjourney や stable diffusion (Rombach et al., 2021) のようなテキストから自動的に画像を生成してくれる AI でした。倫理的な問題は生じつつも、夢の広がるようなツールがどんどん公開され続けています。
しかしながら、このような機械学習のアプローチは、いかにして結果を出力したかに関して問い合わせる手段がありません。私の卒業論文では自然言語推論という、与えられた背景情報(前提)に対して主張(仮説)が含意するか否かを判定するタスクに取り組んでいましたが、そのタスクにおけるデータセットのひとつである JSNLI (Bowman et al., 2015; 吉越ら, 2020) では次のテストケースが例示されています。
前提: 自転車で 2 人の男性がレースで競います。
仮説: 人々は自転車に乗っています。
私たち人間がこの 2 文を見たとき、「2 人の男性」は「人々」と解釈でき、「自転車で」と「レースで競います」からその人々が「自転車に乗って」いることが読み取れるので、前提のもとで仮説が正しい、すなわち前提が仮説を含意するということが結論づけられます。一方で自然言語処理の文脈で用いられる機械学習のモデルは、これらを単語の並びとして食べ、(理解しているかどうかはさておき)前提が仮説を含意するという結果を吐き出します。機械学習モデルがどのように考え、答えを出したかは誰にもわからないのです。
このような機械学習の blackbox な一面は、時にその出力だけでは満足されない場合に顕著に現れます。全知全能の言語モデルが「tan 1° は有理数か」1 という入力に対し「いいえ」とだけ出力しても、ユーザは満足してくれないでしょう。確かに答えは正しいですが、過程の方が重視される問題においては答えが最早何の情報量をもたないということも往々にしてあります。
極論を言えば言語モデルはすべての自然言語処理タスクにおいてそのような解釈性を保持していてほしいのですが、とりわけ重要なタスクで言えばファクトチェックかと思います。ファクトチェックとは、主に有名人や著名人の発言が、正しい統計や研究結果の客観的な事実に基づいているか否かを判定するタスクです。発言が正しい場合はそれを裏付ける情報を、嘘の場合はそれを暴くような情報を付与してあげることができて初めて、そのモデルはファクトチェックができると言え、ユーザに重宝されることでしょう。
個人的なことを言うなら、私は機械学習が先頭に来るようなプロジェクトにあまり興味が湧きません。私は毎朝コーヒーを淹れるのが習慣なのでそれに例えてみますと、古典的なアプローチ、たとえば形式的意味論に基づいた解析は、コーヒー豆の品種や焙煎度合いを選ぶことから始まり、グラインダーやフィルターの選定、豆の質量や粒度、お湯の温度や注ぎ方を変えていくようなものです。一方で機械学習に頼り切りのアプローチは、まさにコンビニにあるような全自動コーヒーメーカーです。確かに豆は選べるし、粒度などもパラメータの設定で調節できるでしょう。しかし、内部構造に手を付けるのはそう簡単ではありませんし、それをいじくることに対して魅力を感じません。
今や機械学習を使わないことは時代遅れと見なされるかもしれませんが、こういう時代だからこそ基礎的で透明性の保証されるアプローチを開発していくのも価値があると信じています。
話は逸れましたが、このインターンレポートではニュース記事の要約文における hallucination (3.2 節参照)を、機械学習を使わずにグラフで検出するという取り組みを紹介します。
2. インターンの振り返り
この記事は一応インターンレポートということになっているので、成果紹介に入る前にインターンの流れを簡単に書きます。
NLP 開発チームのインターンでは他の多くの領域と異なり、テーマは与えられません。6 週間は、テーマの模索から始まっていきます。振り返ってみると、私のテーマが確定したのは第 2 週の火曜日なので、テーマ決めに 6 日間程度かかったことになります。その間は主にメンターさんと、自分のやりたいこと・やりたくないことについて相談したり、先行研究を漁ったりする日々でした。
テーマが確定した後(第 2, 3 週)はやりたいことを実現すべく実装に取り掛かっていましたが、第 4 週でそのやりたいことへの実現には課題がありすぎることに気づいてしまいました。この時点でインターン期間は残り 3 週間程度しかなかった上に、このレポートの執筆期間も鑑みると開発には実質 1 週間しか費やせないということになったため、インターンとしては進路変更を行ない、要約文の hallucination 検出に舵を切ったという次第です。
3. 背景
3.1. 要約生成
機械学習を用いた手法が活性化している分野の一つに「要約生成」があります。このタスクは、与えられた長文に対しそれを短くまとめた文を出力するというものです。手法の一つには、言語モデルを用いたものがあります。 BERT (Devlin et al., 2019) や GPT (Brown et al., 2020) などの大規模汎用言語モデルを用いることで、要約を生成させるのです。方法としては、たった数組の要約前の文章とその要約文例を入力することで few-shot な要約生成モデルが完成します。
ここでは、 LINE と NAVER が共同開発した HyperCLOVA (Kim et al., 2021) を用いた要約生成を試していきます。日本語版 HyperCLOVA は、世界初の日本語に特化した大規模汎用言語モデルです。現在は 820 億のパラメータをもつモデルの開発が進められています。
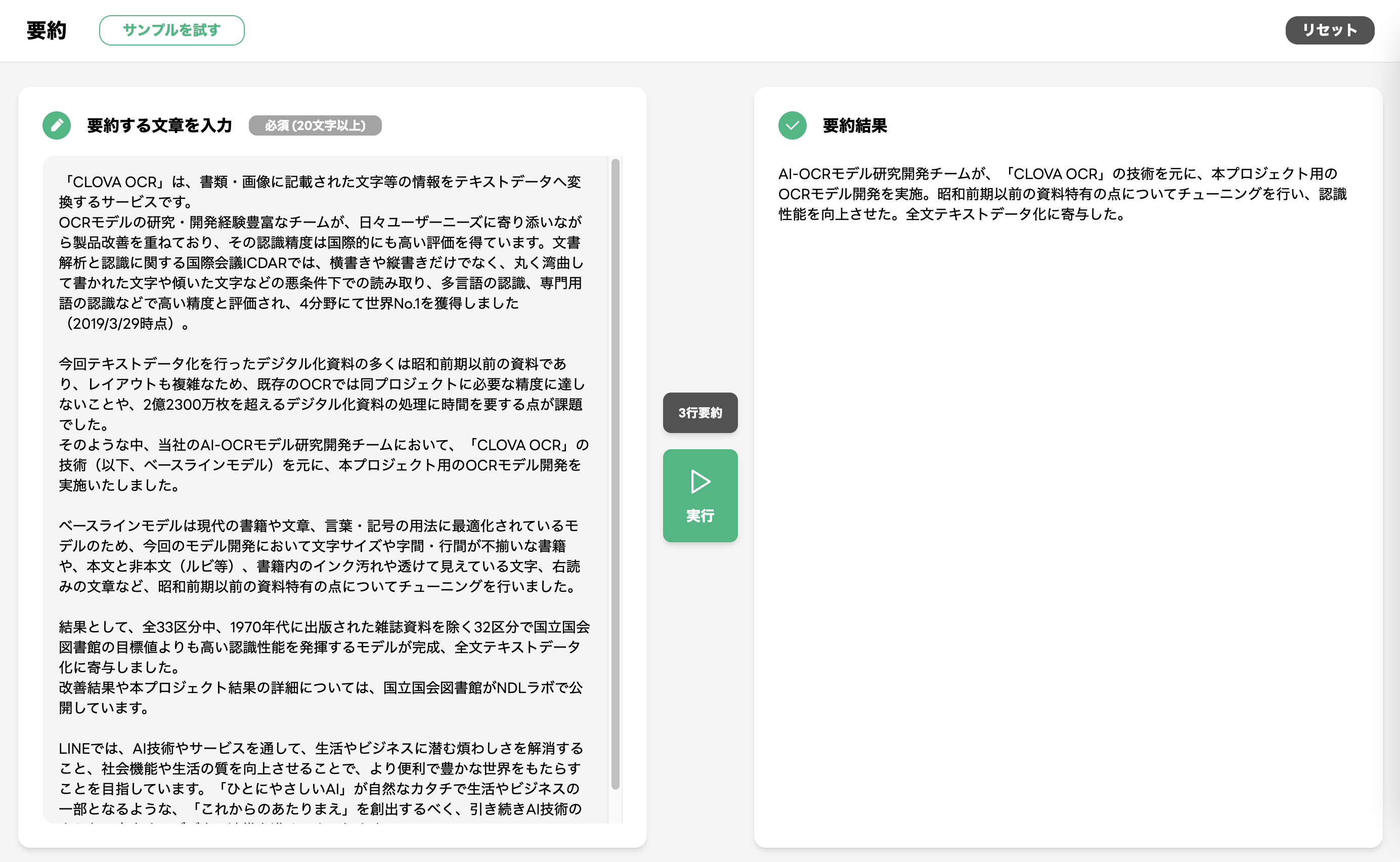
それでは、この HyperCLOVA を使って要約生成に取り組んでみましょう。要約する文章は LINE、昭和前期以前の資料にも対応する OCR モデルを開発。国立国会図書館のデジタル化資料 247 万点のテキストデータ化を完了 という記事から抜き出しています。ちなみに、要約文の行数(文の数)は 1 〜 5 行から選択することができますが、今回は 3 行に設定します。要約結果は次のようになりました。
要約結果: AI-OCR モデル研究開発チームが、「CLOVA OCR」の技術を元に、本プロジェクト用の OCR モデル開発を実施。昭和前期以前の資料特有の点についてチューニングを行い、認識性能を向上させた。全文テキストデータ化に寄与した。
「本プロジェクト」とは何のことか、また「資料特有の点」についての説明不足など気になる点はいくつか見られますが、要約元の記事を概ね良い感じにまとめた文章が生成できました。この要約の自動生成は多くの応用先が考えられます。その一つは、このようなニュース記事を要約しそれを記事の上部に配置することで、本文を読まずとも内容を理解できるような形に持ち込むことができます。本来であれば人間が記事本文を読んで要約文を作成するわけですが、これが自動化できればで大きなコストカットが見込めます。
3.2. hallucination とは
様々なタスクで突出したパフォーマンスを発揮している汎用言語モデルですが、すべてにおいて万能であるわけではありません。
たとえば、言語モデルを用いた文章生成には hallucination と呼ばれる問題を抱えています。hallucination は日本語で「幻覚」という意味ですが、言語生成タスクにおいては、入力の内容に対し不誠実な内容を言語モデルが生成してしまう現象のことを言います (Maynez et al., 2020)。HyperCLOVA も例外に漏れず、hallucination をしてしまうこともあります。以下のような文章に対し HyperCLOVA を用いた 1 行要約を試みると、 hallucination が生じます。
要約する文章: フェイクニュースとは虚偽の情報で作られたニュース、すなわちデマ情報を意味する言葉である。フェイクニュースという言葉の拡大は、政治家の発言や現地メディアの報道の真実性に関する議論を勃発させていた。2
要約結果: トランプ大統領が自身のツイッターで「フェイクニュース」という言葉を使い、波紋を呼んでいる。
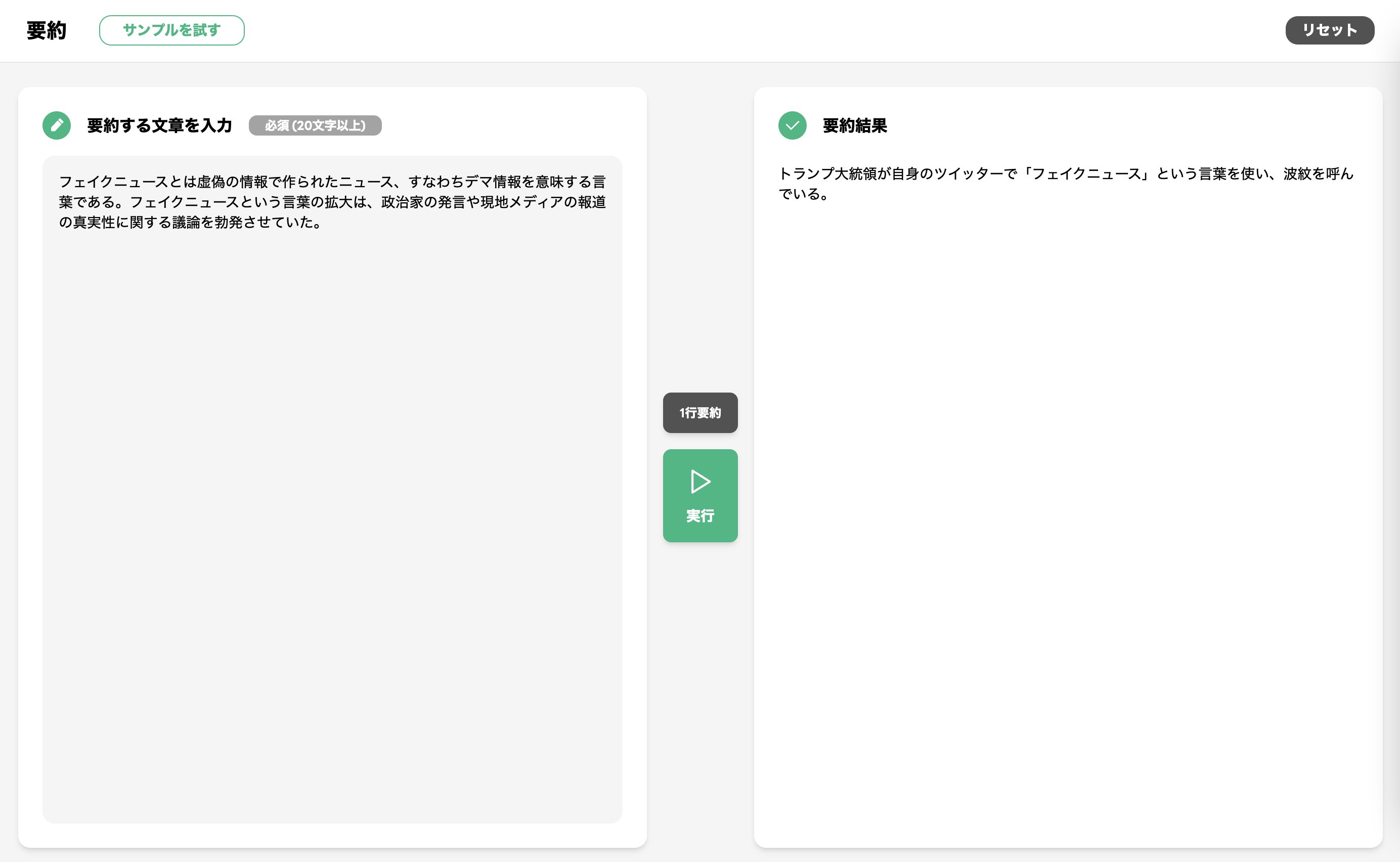
要約する文章には言及がなされていない内容、たとえば「トランプ大統領」や「ツイッター」などが生成されてしまいました。これは要約生成の失敗例です。また、 hallucination として時にヘイトスピーチなど有害な文章を生成してしまうこともあり、言語モデルを用いた生成において hallucination の抑制は避けては通れない課題です。
それに従って hallucination の検知もタスクの一つになっていきます。検知ができないとその抑制に繋げられないためです。要約生成における hallucination の検知に関しては、まだその問題に関しての歴史が浅いながらも、他分野のタスクで洗練された手法を活かし提案されたデータセットやニューラルネットワークベースのモデルが存在します (Durmus et al., 2020; Wang et al., 2020)。しかしながら、これらは hallucination が存在するかどうかということしか焦点を当てていません。hallucination の「検知」と「検出」には大きな隔たりがあります。
日本語における hallucination の検知に関する研究は、たとえば森脇ら (2022) があります。彼らは、既存の対話コーパスを用い、意図的に hallucination を含む対話を生成させたデータセットを作成しました。そのデータセットを用いて Transformer (Vaswani et al., 2017) を学習させることで、対話に含まれる hallucination を検出、修正を高精度に実現しました。しかしながら、この研究では対話における hallucination 検出であること、またその対象を数詞や固有名詞に限定していることなどがあります。そこで私は、日本語要約文の hallucination 検出をインターンのテーマに設定しました。
3.3. 日本語のグラフ
先述した日本語要約文の hallucination の検出という課題に対して、私はグラフを用いた手法を提案します。
最近の NLP における研究では機械学習、ここではニューラルネットワークを用いた手法が主流ですし、特にhallucination の検知・検出では機械学習が産んだ分野なため、ほとんどのアプローチがそれを用いています。しかしながら、今回はそのような機械学習を解析過程では一切用いません。
その理由はいくつか存在しますが、一つは解析過程を透明化したいという点です。機械学習を用いたアプローチには、 SOTA の大きな上昇に寄与している一方で、それがいかにしてその出力をしたかに関して一切の根拠がありません。この状態を blackbox (Jacobi et al., 2018; inter alia) と呼び、そのようなアプローチの透明度を上げていく解釈可能性という分野も存在します。今回は機械学習を用いない手法を試みることで、 hallucination の検出過程を透明度 100% にしようというのが狙いです。
他の理由としては、自然言語の構造の可視化ができるという点です。私たちが普段何気なく話したり書いたりするような言葉一つ一つにはすべて、構造が裏に存在しています。日本語においては、動詞には「何が」「何を」などの構成要素が、名詞にはその状態や性質などを表す構成要素が存在します。たとえば、「ひかりが眠っているネコを見ている」という文 ![]() は、ひかりが眠っているわけではないことをその構造から判断します。3 このような自然言語の構造に焦点を当てるという手法は、機械学習から離れた解析法が得意な点です。
は、ひかりが眠っているわけではないことをその構造から判断します。3 このような自然言語の構造に焦点を当てるという手法は、機械学習から離れた解析法が得意な点です。
自然言語の構造は(グラフ理論における)グラフに起こすことができます。ここでのグラフの頂点は文節を、辺は係り受けの関係を表します。「係り受け」とは、文章中で、係る語句と受ける語句のことを意味します。たとえば主語と述語、修飾語を被修飾語はいずれも係り受けの関係にあります。先ほどの例文 ![]() を形態素解析器 JUMAN++ と構文解析器 KNP を用いてグラフに起こしてみます。
を形態素解析器 JUMAN++ と構文解析器 KNP を用いてグラフに起こしてみます。
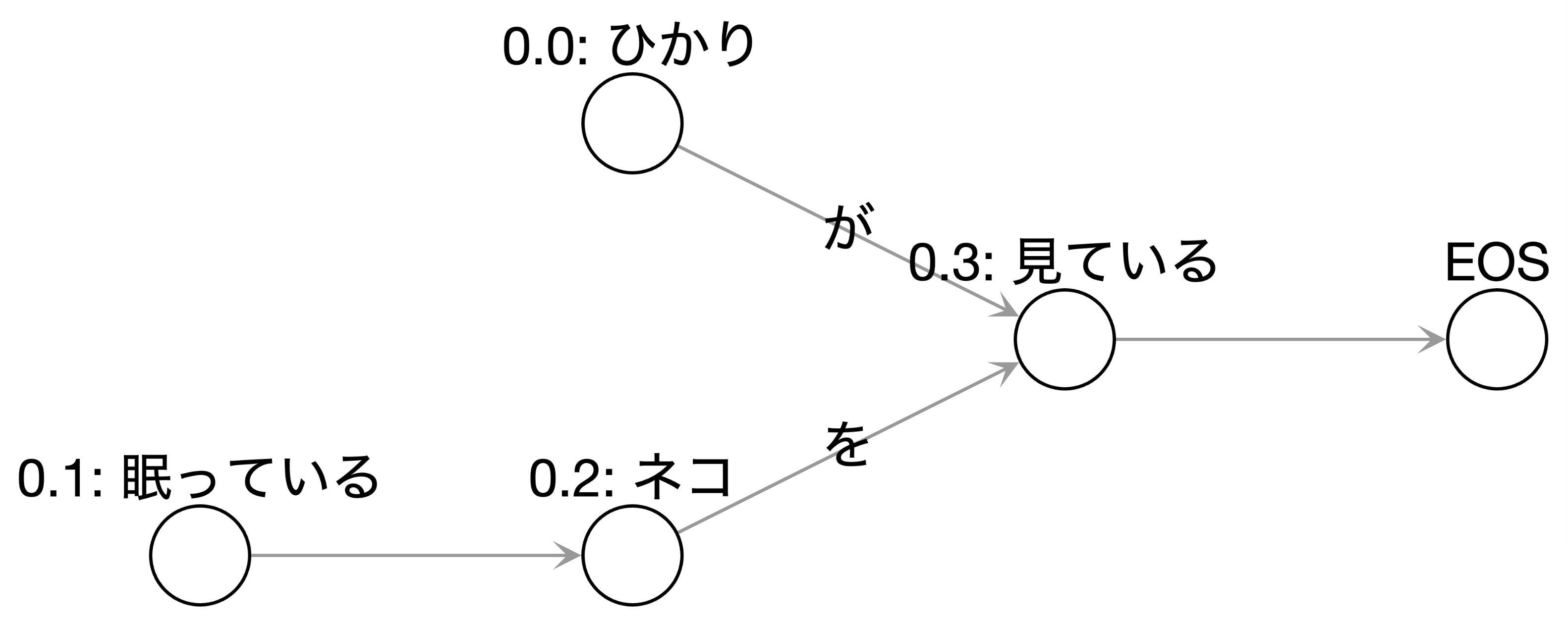
文の表面的な情報に惑わされず、正しい係り受け関係がグラフ化されました。
ただ、このままでは問題が生じてしまいます。(*) という文からは「ネコが眠っている」も読み取ることができます。しかし、「ネコが眠っている。」という文をグラフに起こすと以下のようになり、例文 ![]() から作られたグラフには含まれていません。
から作られたグラフには含まれていません。

これを解決するのが照応です。「照応」とは、二つのものが互いに関連し対応することであり、特に、文章の前と後の文句が互いに対応していることを意味します。構文解析器 KNP には照応解析も行なうことができるので、それを ![]() から作られたグラフ(図3)に追加してみます。
から作られたグラフ(図3)に追加してみます。
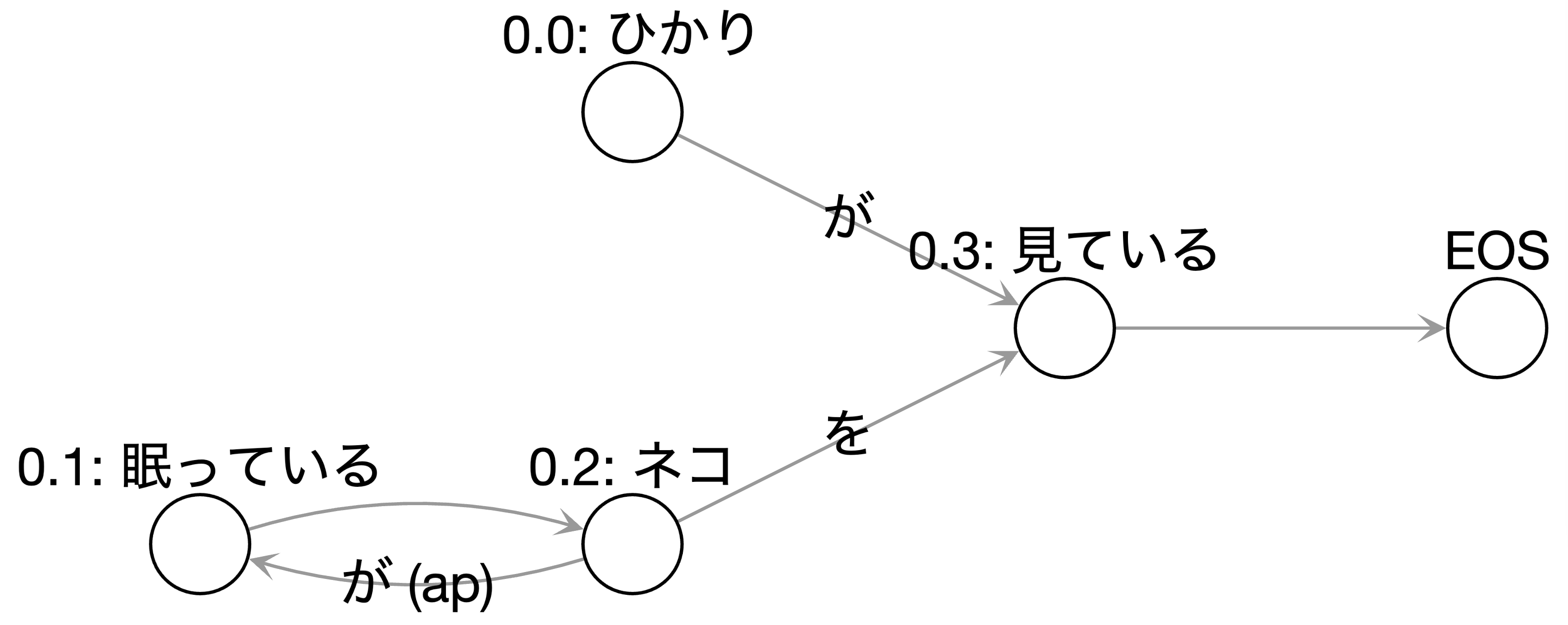
無事に「ネコが眠っている」という照応関係が辺としてグラフに追加され、文章 ![]() からこの情報が言えるようになりました。
からこの情報が言えるようになりました。
さて、要約文の hallucination 検出では、要約する前の文章と要約文それぞれを上述のようにグラフに起こします。それから、グラフの整合性を判定するための解析をします。
グラフに起こすということは、ここまで見てきたように可視化ができるということになります。そのため hallucination の検出をするに当たり、その位置もビジュアルに明らかにすることができます。それに従い、今回はアプローチの提案だけでなく、 hallucination の場所を表示できるビジュアライザも作成しました。ビジュアライザについては第5章で紹介します。
最後に、日本語は英語などの欧州言語と異なり、基本的に述語が文章の中心を司ります。たとえば「ひかりは月曜日の朝に料理をする」という文章は、述語である「する」抜きでは成立しません。その他の文節「ひかりは」「月曜日の朝に」「料理を」はすべて補足語と呼ばれ、これらの有無は文章の成立に何ら影響を及ぼしません。今回のアプローチは、述語を核とした解析をしていきます。
4. 手法
提案するアプローチは以下の手順で解析されます。
制約
はじめに、今回は 6 週間のインターンであり、特に開発期間は実質 4 週間だったため、開発しきれないことで生じたいくつかの制約が存在します。
- 要約文は 1 文のみ。
- 要約文に含まれる用言は 1 個のみ。
- グラフには辺のラベルに関わらず多重辺(ある頂点から別の頂点に複数の辺があること)が存在しない。照応解析により追加される辺が、係り受け関係や別の照応関係ですでに存在している場合、その辺を上書きする。
定義
具体的な手順を示す前に、この章とそれ以降で用いる言葉の定義をします。ここでの日本語の構成に関する単語の定義は、広く一般に用いられるものとは異なる場合があります。
- 文: 文字列であって、最後の文字が「。」「!」「?」のいずれかであるもの。「一文」と呼ぶこともある。
- 文章: 文のかたまり。より厳密には、文からなる配列。
- 前提: 要約する前の文章。
- 要約文: 前提を要約した文章。
- 文節: 文において、1 個の自立語と後続する 0 個以上の付属語からなる文字列。名詞と接辞に関しては、連続するものをひとまとめにしたときにその数が最小になるようにし、そのまとまりを 1 個の自立語として捉える。たとえば「ひかりが朝ごはんを食べた。」という文を文節に分割すると「ひかりは / 朝ごはんを / 食べた。」となる。
- 基本句: 文節中の自立語を形態素に分割した際に、1 個の形態素と後続する 0 個以上の付属語からなる文字列。たとえば「ひかりが朝ごはんを食べた。」という文を基本句に分割すると「ひかりは / 朝 / ごはんを / 食べた。」となる。
- 形態素: 意味を保ったままで最大限分割した際の 1 個の文字列。単独で自立語、付属語、接辞のいずれかに当てはまる。たとえば「ひかりが朝ごはんを食べた。」という文を形態素に分割すると「ひかり / は / 朝 / ごはん / を / 食べた / 。」4 となる。「単語」と呼ばれることもあるが、この記事では形態素の意味でそれを用いない。
- 自立語: 名詞や動詞など、単独でも文節を構成できるような形態素のこと。
- 付属語: 助動詞と助詞のこと。
- 接辞: 接頭辞と接尾辞のこと。
- 用言: 動詞、形容詞、判定詞のこと。
- 形容詞: 物事の状態を表す形態素で、基本形が「〜い」または「〜だ」のもの。いわゆる「形容動詞」もこれに含まれる。
- 判定詞: 名詞と結合して述語を作る形態素で、基本形が「〜だ」「〜である」「〜です」のもの。
- サ変名詞: 名詞のうち、直後に「する」が付けられるもの。
グラフの頂点と辺に関しても定義をします。
- 頂点は以下の属性をもつ:
- name: 文節全体の文字列。
- core: 文節の核。name から付属語を取り除いたもの。
- hinshi: 文節の核の品詞。
- sahen: core がサ変名詞かどうか。
- neg: hinshi が用言であり、name 中に「ない」が含まれるかどうか。
- 辺は以下の属性をもつ:
- from: 始点。そのグラフに存在する頂点のいずれか。
- to: 終点。そのグラフに存在する頂点のいずれか。
- label: from に当たる頂点の name 中の付属語列。照応解析により追加された辺であれば、その関係。
入力
入力は前提と要約文の2つの文章です。前提は ![]() からなり、要約文は 𝑛𝑄 = 1 文 𝑄0 からなります。
からなり、要約文は 𝑛𝑄 = 1 文 𝑄0 からなります。
グラフ生成
この節では、文章からグラフを生成する手順を説明します。イメージとしては、前章でいくつか例示したように文節を頂点とし、構文解析や照応解析などで判明した頂点間の関係を辺に表していきます。基本的には一文ずつのグラフが作られますが、照応先が別の文にある場合はその頂点を複製します。
(手順) ![]() の有向グラフの配列
の有向グラフの配列![]() の生成手順は次の通りです。なお、各
の生成手順は次の通りです。なお、各
- 各
0≤𝑖<𝑚 に対し、𝑆𝑖 に形態素解析を施して得られた文節の配列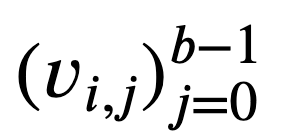 に対し、
に対し、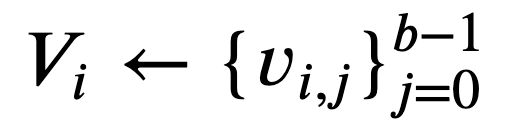 とする。
とする。 - 各
0≤𝑖<𝑚 に対し、𝑆𝑖 に構文解析を施して得られた係り受け関係の集合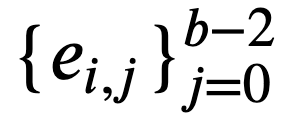 に対し、
に対し、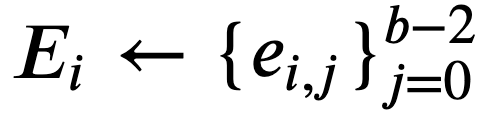 とする。
とする。 - 文章 𝑆 全体に照応解析を施し、得られた文節間の照応関係の集合
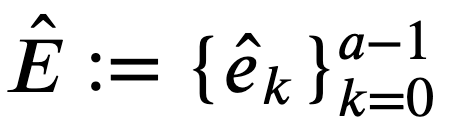 を得る。
を得る。 - 各
0 ≤ 𝑖 <𝑚 に対し、次の操作を施す。
- 各
0≤ 𝑘 <𝑎 に対し、𝑒̂𝑘.from と 𝑒̂𝑘.to について、- 𝑒̂𝑘.from∈𝑉𝑖 かつ 𝑒̂𝑘.to∈𝑉𝑖 のとき、 𝑒̂𝑘.from=𝑒𝑖,𝑗.from かつ 𝑒̂𝑘.to=𝑒𝑖,𝑗.to を満たす 𝑗 が存在すれば、 𝐸𝑖 中の 𝑒𝑖,𝑗 を 𝑒̂𝑘 に置き換える。存在しなければ、 𝐸𝑖 に 𝑒̂𝑘 を追加する。
- 𝑒̂𝑘.from∉𝑉𝑖 かつ 𝑒̂𝑘.to∈𝑉𝑖 のとき、𝑉𝑖に𝑒̂𝑘.from を追加し、𝐸𝑖 に 𝑒̂𝑘 を追加する。
- それ以外のときは何もしない。
- 各
なお、ここで現れる解析器は次の通りです。
hallucination 検出
この節では、前節の手順で生成されたグラフ列の組をもとに、要約文に hallucination が含まれるか否か、含まれる場合はその場所を特定します。先述したとおり日本語は用言が文を担うので、まずは用言の一致を判定して、その後にそれに伸びている辺の先が、各助詞で一致しているかどうかを判定していきます。
(手順)前提 ![]() から生成された要約文 𝑄0 が hallucination を含むか否かを判定し、含む場合はその文節集合 𝐻 を特定します。簡単のため、 𝑛=𝑛𝑃 , 𝑄=𝑄0 とします。
から生成された要約文 𝑄0 が hallucination を含むか否かを判定し、含む場合はその文節集合 𝐻 を特定します。簡単のため、 𝑛=𝑛𝑃 , 𝑄=𝑄0 とします。
- はじめ 𝐻=∅ とする。前提
 から得られるグラフの配列を
から得られるグラフの配列を  、要約文 𝑄 から得られるグラフを とする。
、要約文 𝑄 から得られるグラフを とする。 - 𝐺𝑄=(𝑉𝑄,𝐸𝑄) 中の頂点 𝑣𝑄∈𝑉𝑄 であって、その品詞が用言であるような頂点集合を 𝑌𝑄⊆𝑉𝑄 とおく。
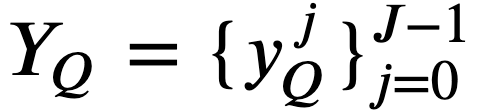 とおく。制約より必ず 𝐽=1 となるため、 𝑌𝑄={𝑦𝑄} とする。
とおく。制約より必ず 𝐽=1 となるため、 𝑌𝑄={𝑦𝑄} とする。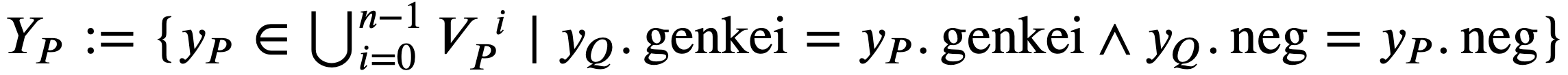 を定義する。 𝑌𝑃=∅ の場合は、 𝐻 に 𝑦𝑄 を追加し、操作 6 に進む。
を定義する。 𝑌𝑃=∅ の場合は、 𝐻 に 𝑦𝑄 を追加し、操作 6 に進む。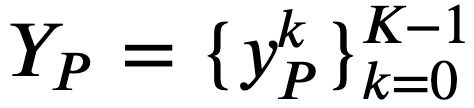 とおき、 𝑘=0 とする。
とおき、 𝑘=0 とする。
- 𝑘=𝐾 であれば操作 6 に進む。そうでなければ、頂点
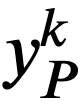 と 𝑦𝑄 に対し、その頂点に向かう辺の label とその一端の頂点の core の組からなる集合
と 𝑦𝑄 に対し、その頂点に向かう辺の label とその一端の頂点の core の組からなる集合 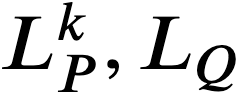 をそれぞれ定義する。より厳密には、
をそれぞれ定義する。より厳密には、 である。
である。 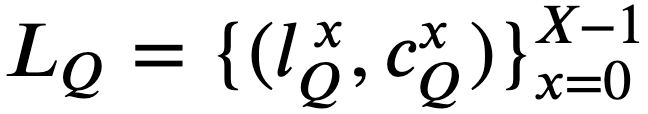 とおき、 𝑥=0 とする。
とおき、 𝑥=0 とする。
- 𝑥=𝑋 であれば操作 5-c に進む。そうでなければ、付属語
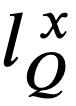 を第1要素としてもつ組を
を第1要素としてもつ組を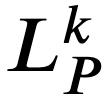 中から取り出し、その組の第2要素からなる集合を
中から取り出し、その組の第2要素からなる集合を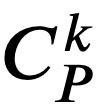 と定義する。より厳密には
と定義する。より厳密には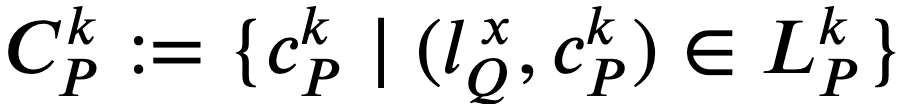 である。
である。 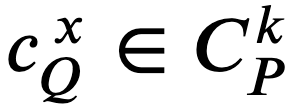 であれば 𝑘 に 1 を追加し、操作 5.a に戻る。𝑡𝑄∉𝑇𝑃 であれば 𝑥 に 1 を追加し、操作 5.b.i に戻る。
であれば 𝑘 に 1 を追加し、操作 5.a に戻る。𝑡𝑄∉𝑇𝑃 であれば 𝑥 に 1 を追加し、操作 5.b.i に戻る。
- 𝑥=𝑋 であれば操作 5-c に進む。そうでなければ、付属語
- 𝐻 に 𝑦𝑄 を追加したあと、𝑘 に 1 を追加し、操作 5.a に戻る。
- 𝑘=𝐾 であれば操作 6 に進む。そうでなければ、頂点
- 最終的に 𝐻 が空であれば hallucination を含まないと出力する。 𝐻 が空でなければ hallucination を含んでいることと 𝐻 を出力する。
5. ビジュアライザ
今回はグラフを用いて hallucination を特定するというアプローチを取ったため、hallucination の可視化ができるようになります。そのため、今回は手法の提案に加え、hallucination の可視化をするビジュアライザ Hallucination Detector を作成しました。
ニュース記事ではないですが、先ほど紹介した例文 ![]() に関する以下の例を考えます。
に関する以下の例を考えます。
前提: ひかりは眠っているネコを見ている。
要約文: ひかりは眠っている。
この要約文が、前提に対する正しい理解ではないことは 3.3 節で説明してあります。
これらの入力を左部の上段、下段にそれぞれ入力し Check を押下すると、右部に前提と要約文それぞれのグラフが出力されます。hallucination が含まれる場合は、結果に「Hallucinated!」と表示されるとともに、その位置が赤色で出力されます。この例では、要約文中の用言「眠っている」に対して「ひかり」が hallucination 、すなわち前提では言及されていない内容が書かれているので、その部分が赤色で出力されています。
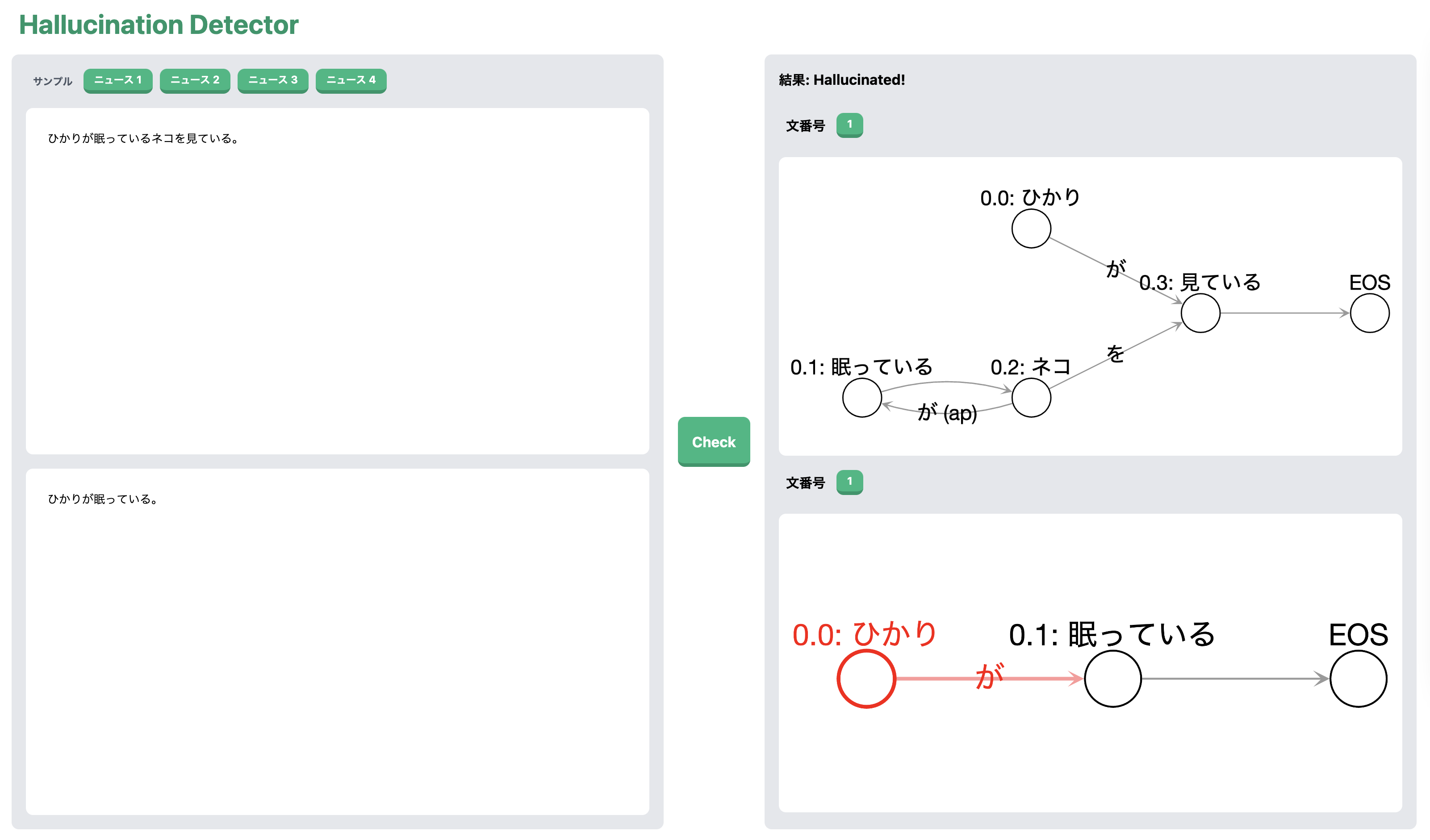
このビジュアライザはフロントエンドを Vue.js と TailwindCSS で、バックエンドを FastAPI で作成しました。これを使って、ニュース記事要約文の hallucination 検出をしていきたいと思います。
6. デモ
この章では HyperCLOVA を使って生成した要約文の hallucination 検出を、ビジュアライザとともに紹介します。
6.1. 解析に成功した例
LINEリサーチ、若年層の流行に関する定点調査( 2022 年上期)という記事の本文中から、以下を前提とした要約文を HyperCLOVA で生成しました。
前提: LINE では、同社が保有する約 604 万人の国内最大級のアクティブな調査パネルを基盤とした、 スマートフォン専用のリサーチプラットフォーム「LINEリサーチ」を運営しております。LINEリサーチでは、全国の 15 〜 24 歳の若年層の男女を対象に、四半期ごとに最近の流行についてアンケート調査(自由記述形式)を実施しております。 2022 年上半期は 3 月、 6 月の 2 回の調査と、 2022 年下半期の流行予測に関する調査を実施いたしましたので、その調査結果をお知らせいたします。
要約文: 2021 年の流行語大賞は「にじさんじ」だった。
こんな大胆な hallucination をするのかという気持ちにもなりますが、これを Hallucination Detector にかけてみます。

要約文中の用言である『「にじさんじ」だった』は前提中に存在しないために hallucination であることが表示されました。ちなみに、この要約文の内容も虚偽なわけですが、この虚偽の検出は要約生成における hallucination とは別物であることに注意してください。
6.2. 解析に失敗した例
続いては LINEギフト、お母さんがもらって嬉しい「母の日ギフト」最新ランキング発表 母の日限定メッセージカードで想いを届ける!母の日特集を本日より公開 という記事の本文中から、以下を前提とした要約文を HyperCLOVA で生成しました。
前提: 「LINEギフト」は、「LINE」のトークを通じて友だちとギフトを贈り合うことができるコミュニケーションサービスです。住所を知らなくても直接会えなくても、 LINE 上で簡単にギフトを贈ることができるため、ちょっとしたお礼を言いたい時や季節イベント、大切なライフイベントなど様々なシーンでご利用いただいています。特にコロナ禍においては、離れていても、会えなくても、大切なひとにオンライン上でギフトを贈りたいというユーザー傾向が高まり、 2022 年 3 月に累計ユーザー数は 2,300 万人を突破いたしました。
要約文: LINEギフトの累計ユーザー数が 2,300 万人を突破した。
これまた要約文としては疑問符が浮かびますが、これを Hallucination Detector にかけてみます。

一見、解析に成功しているように見えますが、要約文の最初の文節の核である「LINEギフト」と辺で接続している「累計ユーザー数」が前提のグラフでは接続されていません。これは、照応解析が複文にまたいだ照応関係の特定に弱いがために生じた問題です。また、よく見ると「2,300 万人」が「2,」と「300 万人」に分割して解析されてしまっています。確かに 200 か 300 かという意味合いで「2,300」という言葉を使うこともありますが、このコンマは桁区切りのためです。このように数詞や固有名詞の取り扱いには改善の余地が残されています。
7. 課題
さて、ここまで私の提案するアプローチとそのデモを紹介してきましたが、実はひとつ致命的な欠陥があります。
それは、用言からたどる頂点を 1 手先に限定しているという点です。どういうことかを例とともに説明します。(以下、前提としての入力を「入力 A」、要約文としての入力を「入力 B」と書きます。)
入力 A: ひかりは月曜日の朝に料理をする。
入力 B: ひかりは木曜日の朝に料理をする。
この例もまたニュース記事の要約ではないですが、これらを Hallucination Detector にかけてみます。
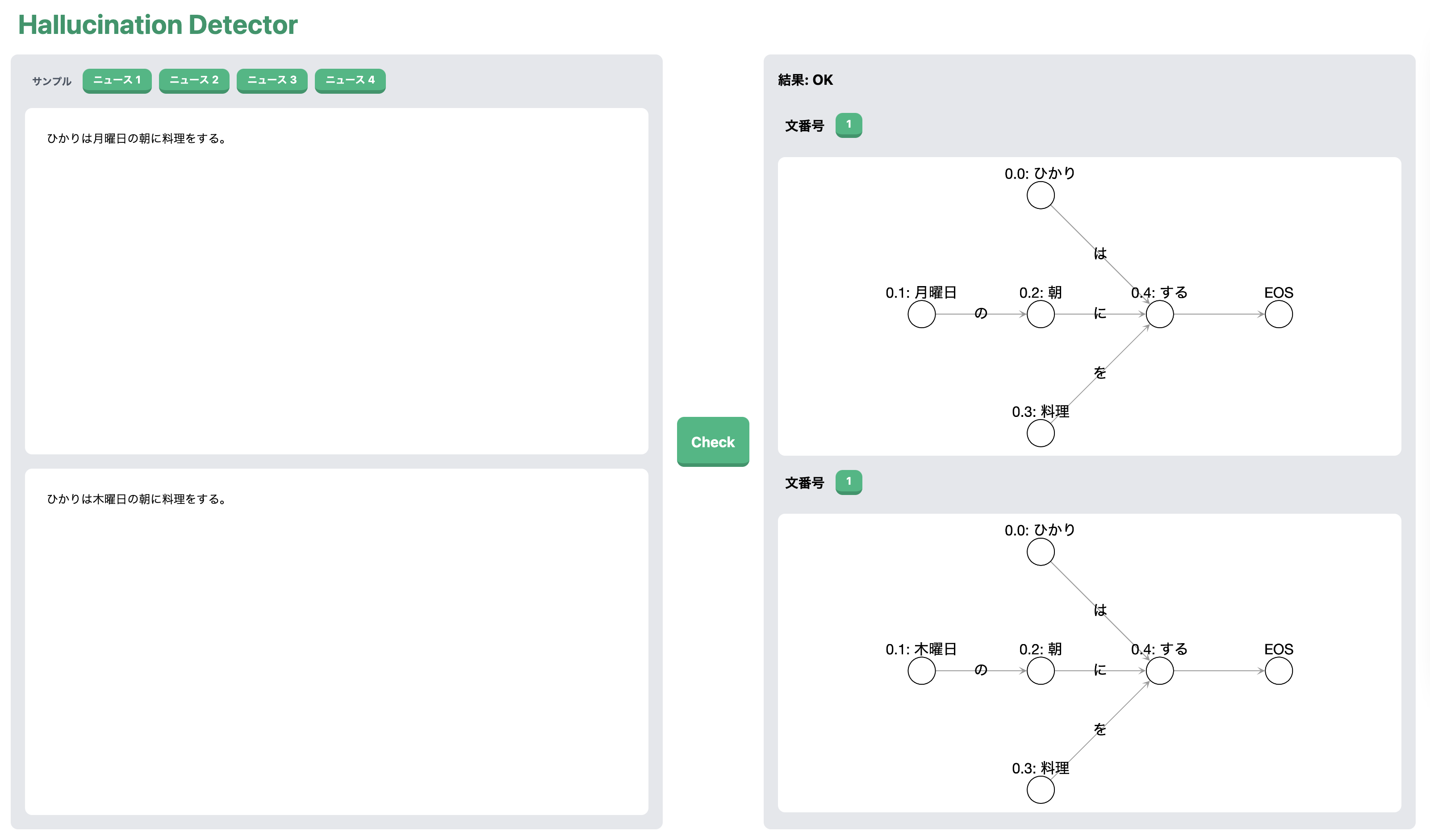
解析手法で説明したとおり、まずは用言の一致を見て、そしてその頂点が辺の先になっている頂点の一致を見るわけですが、「する」、「朝」と一致を見た後に解析はストップします。さらにその先に hallucination の原因となる頂点があるのにもかかわらずです。
これが実装できなかった理由はいくつかあり、十分な時間がなかったというのもその一つですが、それ以上に助詞の結びつきに対する解析の難しさがありました。上の例は、素直に 2 手先を見て一致しているか判定すれば hallucination がわかるのですが、この例はどうでしょうか。
入力 A: ひかりは渋谷のカフェに行った。
入力 B: ひかりは東京のカフェに行った。
2 手先の「渋谷」と「東京」の一致を見てしまうと、場合によっては誤った hallucination 結果を示してしまうことになりかねません。さらに別の例を挙げます。
入力 A: ひかりは渋谷の 109 に行った。
入力 B: ひかりは東京の 109 に行った。
今度は 109 が 2 手先の記述に関わらず同じものを表すため、一致を見てしまうと誤った hallucination 結果を示してしまいます。このように、助詞の結びつき、特に接続助詞「の」の扱いはインターン期間中、何度も私を悩ませました。もちろん、この問題は 1 手先でも起こりえますが、時間のないことで捻り出した苦肉の策だったということを理解していただければと思います。
その他、用言の活用に関してや、代名詞に対する共参照の解決、固有名詞の扱いなど、挙げるとキリがないくらいの課題が潜んでいます。これは機械学習を用いない手法に取り組んでいく上で宿命のようなものです。今回のレポートで定量的な評価をしなかった理由は、それをするにはまだまだ改善の余地が残されていたためです。
8. まとめ
このインターンレポートでは、機械学習を用いた要約生成における hallucination という問題に着目し、解析手法において機械学習から離れたアプローチを提案しました。それに伴い、解析結果の過程を透明化したことにより、前提と要約文の構造の可視化、それからその結果である hallucination の存在が可視化されるようなビジュアライザを作成しました。ニュース記事要約文を用いたデモでは簡単な例の hallucination 検出しかできませんでしたが、もしこのアプローチを実用化することになったときに、解決すべき様々な課題が見えました。
最後になりますが、このインターンの間に多大なサポートをしてくださった NLP 開発チームの方々、特にメンターの山崎天さんとマネージャーの佐藤敏紀さんには大きな感謝をしたいと思います。ありがとうございました。
脚注
- 京都大学入試問題(2006 年度後期・文理共通)より。
- 栗原と河原. 2021. ファクトチェック支援のための含意関係認識システムより引用。2 文にするために一部改変。
- このような、名詞修飾節があたかも直前の名詞の述語になっているように見える構造は garden-path と呼ばれる。JaNLI データセット (Yanaka and Mineshima, 2021) 中には garden-path に焦点を当てたサブセットがあり、実験では BERT ベースの2種のモデルが非含意のケースに対して 10% 〜 15% の精度にとどまっているという結果が報告されている。
- 「食べた」を「食べ / た」と分割する文献もあるが、 JUMAN 辞書において「食べた」が原形「食べる」の活用形「タ形」に分類されるため、ここでは一つの形態素として扱う。
参考文献
- Samuel R. Bowman, Gabor Angeli, Christopher Potts, and Christopher D. Manning. 2015. A large annotated corpus for learning natural language inference. In Proceedings of the 2015 Conference on Empirical Methods in Natural Language Processing, pages 632–642, Lisbon, Portugal. Association for Computational Linguistics.
- Tom B. Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, Sandhini Agarwal, Ariel Herbert-Voss, Gretchen Krueger, Tom Henighan, Rewon Child, Aditya Ramesh, Daniel M. Ziegler, Jeffrey Wu, Clemens Winter, et al.. 2020. Language Models are Few-Shot Learners. arXiv preprint. arXiv:2005.14165.
- Jacob Devlin, Ming-Tom B. Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, Sandhini Agarwal, Ariel Herbert-Voss, Gretchen Krueger, Tom Henighan, Rewon Child, Aditya Ramesh, Daniel M. Ziegler, Jeffrey Wu, Clemens Winter, Chang, Kenton Lee, and Kristina Toutanova. 2019. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pages 4171–4186, Minneapolis, Minnesota. Association for Computational Linguistics.d
- Esin Durmus, He He, and Mona Diab. 2020. FEQA: A Question Answering Evaluation Framework for Faithfulness Assessment in Abstractive Summarization. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, pages 5055–5070, Online. Association for Computational Linguistics.
- Alon Jacovi, Oren Sar Shalom, and Yoav Goldberg. 2018. Understanding Convolutional Neural Networks for Text Classification. In Proceedings of the 2018 EMNLP Workshop BlackboxNLP: Analyzing and Interpreting Neural Networks for NLP, pages 56–65, Brussels, Belgium. Association for Computational Linguistics.
- Boseop Kim, HyoungSeok Kim, Sang-Woo Lee, Gichang Lee, Donghyun Kwak, Jeon Dong Hyeon, Sunghyun Park, Sungju Kim, Seonhoon Kim, Dongpil Seo, Heungsub Lee, Minyoung Jeong, Sungjae Lee, Minsub Kim, Suk Hyun Ko, Seokhun Kim, Taeyong Park, Jinuk Kim, Soyoung Kang, et al.. 2021. What Changes Can Large-scale Language Models Bring? Intensive Study on HyperCLOVA: Billions-scale Korean Generative Pretrained Transformers. In Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing, pages 3405–3424, Online and Punta Cana, Dominican Republic. Association for Computational Linguistics.
- Chin-Yew Lin. 2004. ROUGE: A Package for Automatic Evaluation of Summaries. In Text Summarization Branches Out, pages 74–81, Barcelona, Spain. Association for Computational Linguistics.
- Joshua Maynez, Shashi Narayan, Bernd Bohnet, and Ryan McDonald. 2020. On Faithfulness and Factuality in Abstractive Summarization. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, pages 1906–1919, Online. Association for Computational Linguistics.
- Robin Rombach, Andreas Blattmann, Dominik Lorenz, Patrick Esser, and Björn Ommer. 2021. High-Resolution Image Synthesis with Latent Diffusion Models. arXiv preprint. arXiv:2112.10752.
- Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N. Gomez, Lukasz Kaiser, and Illia Polosukhin. 2017. Attention Is All You Need. arXiv preprint. arXiv: 1706.03762.
- Alex Wang, Kyunghyun Cho, and Mike Lewis. 2020. Asking and Answering Questions to Evaluate the Factual Consistency of Summaries. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, pages 5008–5020, Online. Association for Computational Linguistics.
- Hitomi Yanaka and Koji Mineshima. 2021. Assessing the Generalization Capacity of Pre-trained Language Models through Japanese Adversarial Natural Language Inference. In Proceedings of the Fourth BlackboxNLP Workshop on Analyzing and Interpreting Neural Networks for NLP, pages 337–349, Punta Cana, Dominican Republic. Association for Computational Linguistics.
- 森脇恵太, 大野瞬, 杉山弘晃, 酒造正樹, 前田英作. 2022. Transformer による hallucination error の事後修正. 言語処理学会第 28 回年次大会.
- 吉越卓見, 河原大輔, 黒橋禎夫. 2020. 機械翻訳を用いた自然言語推論データセットの多言語化. 第 244 回自然言語処理研究会.