
はじめに
初めまして。大阪大学工学部4年の白井僚と申します。2022年の夏期インターンシップに6週間参加し、その後アルバイトとして勤務しています。期間中、ML PrivacyチームとFamily Service Data Scienceチームに所属し、「Positive-Unlabeled Learningを用いた位置情報とチェックインログに基づく滞在店舗推定」というテーマで研究に取り組みました。本記事では、私が行った研究についてご紹介します。また、本研究に関する論文は、第15回データ工学と情報マネジメントに関するフォーラム(DEIM2023)にて発表しました。
背景
本研究では、リアルタイムに取得したGPSやWi-Fiなどの位置情報データから、ユーザが滞在している店舗を推定する「滞在店舗推定問題」に焦点を当てます。この推定によって、現在位置に基づくクーポン提供などの施策が可能になります。ただし、位置情報データには誤差があるため、この誤差範囲を考慮して、誤差範囲内に存在する店舗から実際にユーザが訪れた店舗を推定するための予測モデルが必要です。下図に、この誤差範囲とその中に存在する店舗の例を示します。
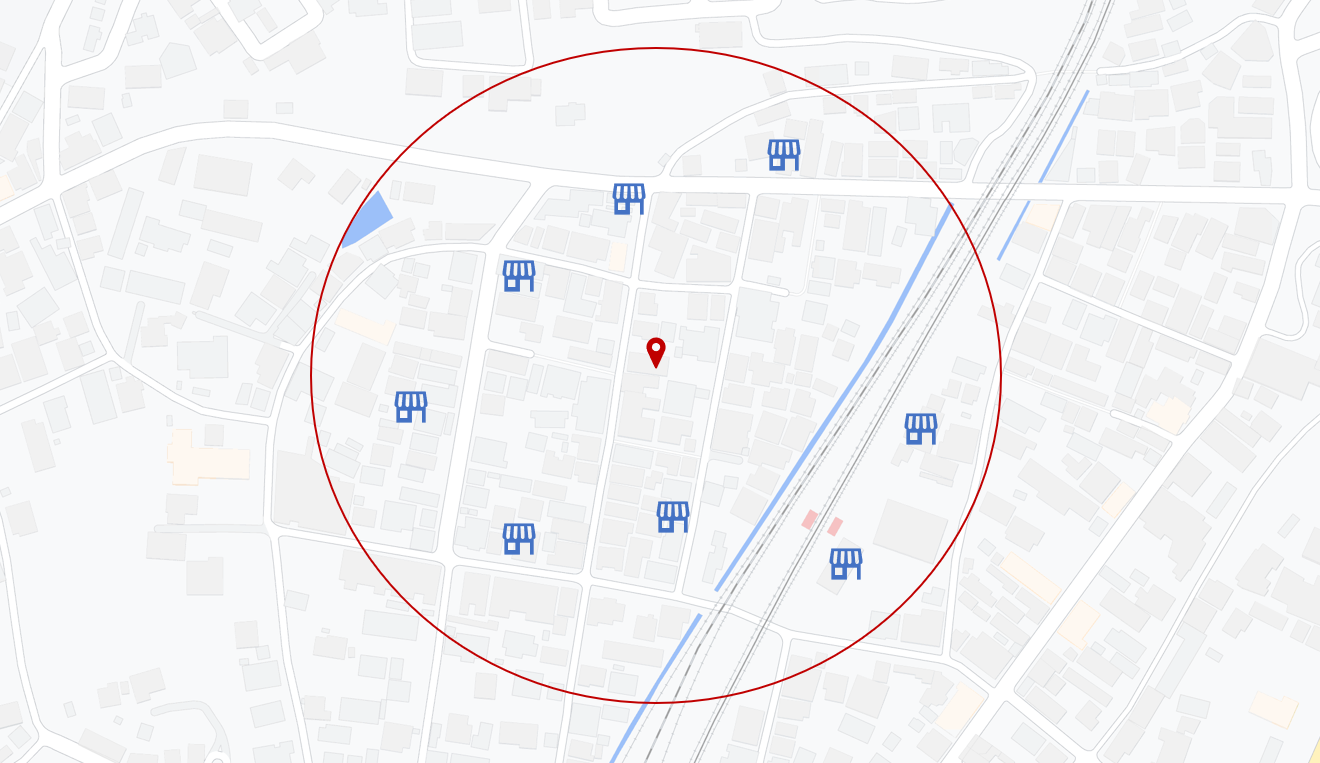
位置情報データ自体には、ユーザがどの店舗に滞在したかという明示的な情報は含まれていません。そのため、滞在情報をこのデータに付与する必要があります。そこでまず、チェックインログに記録された「ユーザがある店舗に滞在した」という情報を、位置情報データに付与します。これにより、GPSだけでは得られない滞在時の情報を補完し、このデータを正解データとした滞在店舗推定モデルを構築することができます。
多くの店舗推定手法はこのように、チェックインログが持つ「来店した」情報(Positiveデータ)に基づいて行われ、店舗に「来店しなかった」情報(Negativeデータ)は利用されません。実際、NegativeデータはPositiveデータと比較して取得が困難であるという課題があります。そのため、このような状況下では、Negativeデータを利用する精度の指標(Precision、Accuracyなど)での評価を行えません。しかし、例えばクーポンの提供を行う際、誤った提供(False Positive)を図るPrecisionは重要な指標です。そのため、本研究では、Negativeデータが得られない状況下で、Precisionを考慮した予測モデルの構築および評価を行うという問題に取り組みました。
問題設定
GPSを取得したとき、ユーザの滞在店舗の候補集合はGPSの誤差範囲内に存在する店舗であるといえます。この候補集合から、実際にユーザが滞在した店舗を推定します。また上述の通り、本研究ではPrecisionを考慮した予測モデルの構築を行うため、Negativeが得られない状況下でPrecisionを推定する指標を作成し、Recallおよび作成した指標に対して高精度なモデルを構築することを考えます。
提案
GPSと紐づく店舗以外の誤差範囲内の店舗はユーザが滞在していないNegativeデータであるとして、学習データに追加することを考えます。しかし、GPSとチェックインログは取得タイミングが同期されていないため、ある店舗の滞在情報を表すGPSが存在する場合でも、その他の店舗には滞在していないとは言い切れません。具体的には、次のようなケースが考えられます。
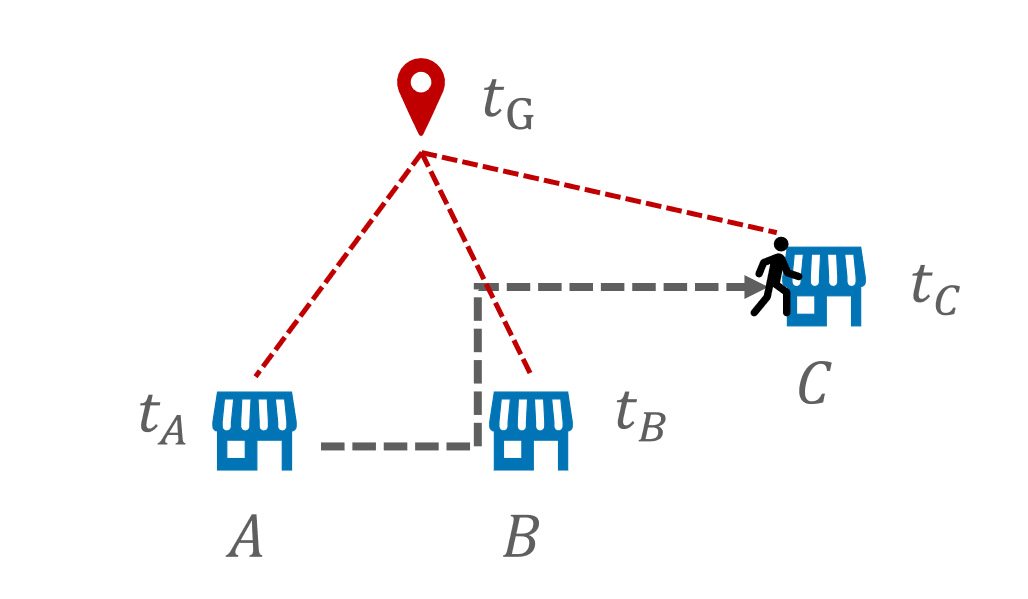
これを踏まえ、GPSと紐づく店舗以外の誤差範囲内の店舗をPositiveもしくはNegativeどちらの可能性もあるラベルの無い(Unlabeled)データとして訓練データに追加し、学習を行います。また、このように周辺店舗を追加することで、GPSが複数店舗の滞在情報と結びつく場合も考慮することができます。
実験概要
2022年8月1日から8月31日の、店舗情報、GPS、およびチェックインログを用いて、提案手法の精度を評価しました。評価指標には、Recallと作成した指標(Category-aware PUF Score)を使用しました。Category-aware PUF Scoreは、PU Learningの分野で用いられるPUF Score[1]を拡張したものであり、本問題においてF値を推定可能な指標です。
比較手法
実験では、次に示す4つの手法を作成し、提案手法と比較しました。
- ランダム選択
- GPS誤差範囲内の店舗からランダムに滞在店舗を選択します。
- 近傍選択
- GPSの位置座標から距離が最も近い店舗を滞在店舗とします。
- ベースライン
- 「背景」のセクションで示したPositiveデータのみでの学習モデル
- PN Learning
- 本来Unlabeledデータとして扱う必要のある周辺店舗のデータをNegativeデータとして扱い、このPositiveデータとNegaitveデータを用いて提案手法と同様に2値分類を行います。
実験結果
それぞれの指標を用いて評価した結果は以下のようになりました。
| Recall | |||||
|---|---|---|---|---|---|
| k | 1 | 2 | 3 | 4 | 5 |
| ランダム選択 | 0.166 | 0.265 | 0.333 | 0.392 | 0.434 |
| 近傍選択 | 0.326 | 0.438 | 0.504 | 0.560 | 0.597 |
| ベースライン | 0.276 | 0.356 | 0.418 | 0.461 | 0.492 |
| PN Learning | 0.435 | 0.578 | 0.641 | 0.678 | 0.709 |
| 提案手法 | 0.437 | 0.578 | 0.642 | 0.681 | 0.711 |
|
Category-aware PUF Score |
|||||
|---|---|---|---|---|---|
| k | 1 | 2 | 3 | 4 | 5 |
| ランダム選択 | 1.33 | 1.78 | 2.01 | 2.09 | 2.14 |
| 近傍選択 | 7.38 | 6.28 | 5.45 | 4.94 | 4.56 |
| ベースライン | 19.83 | 8.89 | 6.24 | 5.33 | 4.67 |
| PN Learning | 422.13 | 26.95 | 15.79 | 11.74 | 9.54 |
| 提案手法 | 401.80 | 26.97 | 15.81 | 11.86 | 9.60 |
提案手法はベースラインと比較していずれのkにおいても高精度となり、周辺店舗を追加する有効性を確認しました。また、提案手法はPN Learning と同程度の精度となりました。今回はGPSとチェックインログの時間的な誤差を±3分として考えています。そのため、誤差範囲内に1店舗のPositiveデータのみが存在するケースが多く、これはPN Learningで想定する状況となります。この状況下で提案手法がこの精度に近づき、さらにわずかに向上しているのは、GPSが複数の店舗滞在と結びつくケースを捉えたためであると考えられます。
以上の結果から、周辺データの追加によってPrecisionが推定可能となり、RecallおよびPrecisionにおいて高精度なモデルを実現可能であることを示しました。
おわりに
今回のインターンシップでは、「Positive-Unlabeled Learningを用いた位置情報とチェックインログに基づく滞在店舗推定」のテーマで研究を行いました。チェックインログのみでの予測に対して、周辺の店舗をUnlabeledデータとして共に学習を行うことでRecallとPrecisionにおいて高精度なモデルを実現することが出来ました。
GPSなどの位置情報データは日々数億件単位で大量に取得されるデータです。しかし、これらの位置情報データは単に場所を表す情報なので、取得した後にどのように解析するかが重要になります。LINEでは、これを解析するための分散処理環境やツールが整備されており、これを実際に扱うことが出来たのは自分にとってとても良い経験となりました。また、これらデータを統計値として集約するだけではなく、リアルタイムに解析し続けるモデルなどを見て、その規模感に圧倒される場面が多々ありました。
インターンシップではこれらのシステム開発に携わった方々に直接アドバイスを頂けて、とても有意義な期間を過ごすことができました。また、インターンシップ期間中は毎日ミーティングの時間を設けてくださり、研究内容から細かい相談まで手厚くサポートしていただいたおかげで、大きく成長できました。今後もアルバイトとしてお世話になります。これからもよろしくお願い致します。
参考文献
[1] J. Bekker and J. Davis, “Learning from positive and unlabeled data: A survey,” Machine Learning, vol.109, no.4, pp.719–760, 2020.