
はじめまして。LINE の夏季就業型インターンに参加させていただいた小林亮太です。所属は東京大学大学院情報理工学系研究科で、普段はシステムソフトウェアやプログラミング言語に関する研究を行っています。今回のインターンでは、LINE公式アカウントのメッセージ配信を司る BOT Platform チームにお世話になり、LINE Messaging API のバックエンド開発に携わりました。この記事ではその背景と、インターン期間中の取り組みについてお話します。
背景
Messaging API は LINE公式アカウントでの配信に利用される API で、一度に多数のユーザにメッセージを送り届けることができるのが特徴です。LINE公式アカウントでは、各月一定の件数までは無料でメッセージを配信できますが、それを超えると件数に応じて課金されるというモデルになっています。そのため LINE公式アカウント管理者の視点では、「できるだけ少ない配信数で効果的にメッセージを送り届けたい」という要望が生まれることになります。
これを実現するのが「ナローキャスト」という仕組みです。ナローキャストでは配信対象を性別や年齢、地域といった情報で絞り込むことができ、本当にメッセージを届けたい対象属性だけに配信することができます。API ではこれらの属性や過去の配信情報を AND や OR、NOT といった集合演算で組み合わせ、「東京都在住の 20 代男性のうち、過去にナローキャストで配信していないユーザ」のような複雑な条件を指定できるようになっています。
しかしながら現状の API では、「絞り込まれた結果最終的に何人に届けられるのか」を事前に知るすべがありません1。そこで今回のインターンでは、指定された条件から配信対象人数を推定する機能の実装を行いました。
何が難しいのか
既に条件を指定して配信する仕組みが存在することを踏まえると、その対象人数を求めるのは難しくないことのように思えます。ただここで問題となるのは、その配信対象の特定には時間がかかり得るということです。フォロワー数は LINE公式アカウントによって様々ですが、場合によっては億単位のフォロワーを抱えている場合もあります。ある数日のデータを調べたところ、10,000 人以上のフォロワーがいる LINE公式アカウントからのナローキャストのうち 10% は計算に 25 秒以上かかっており、最大では 1,153 秒にまで到達していました。ナローキャストはこのように重い処理であるため、リクエストを受け取った後バックグラウンドで計算・配信される非同期な API として実装されています。一方今回実装する API は配信前に試行錯誤して、一定の予算内で最適な条件を導くために使われることが想定され、毎回のリクエストにこれだけの時間がかかることは許容できません。
ここでポイントとなるのは、「人数さえ分かればよく、しかもその値は必ずしも正確でなくてもよい」という点です。配信にかかる費用を予測するために、配信対象が 10,000 人なのか 100,000 人なのかは重要な情報ですが、10,000 人と 10,010 人を区別できる必要は多くの場合ありません。そこで、実際の値から多少のぶれがあることを許容する代わりに計算を高速に行えないか、というアイデアが生まれます。
手法
前述のアイデアを実現するのが「スケッチ」という手法です。スケッチはある種の非可逆圧縮で、元のデータの一部のみを保存してその上で計算を行います。そもそも集合演算に時間がかかっていたのはデータのサイズに由来するものだったので、サイズが小さくなればその分計算は速く行えるというわけです。スケッチを利用した配信人数推定はLINE公式アカウントの管理画面で部分的にサポートされていましたが、今回はそれを一般のナローキャストリクエストに拡張したものになります。
より具体的には、入力されたデータ(LINEのユーザID)をハッシュ関数にかけ、値が小さい k 件(k Minimum Value, KMV)を保存します(正確には KMV スケッチと呼ばれる手法です)。以下の例を見てください。

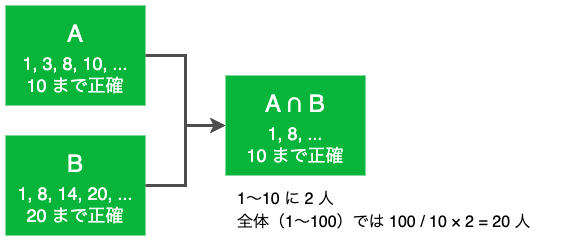
ここでは対象の LINE ユーザの ID のハッシュ値が 1〜100 に一様に分布しているとします。1つ目のユーザの集合 A は、値が小さい 4 件を取り出すと「1, 3, 8, 10」で、2 つ目のユーザの集合 B は「1, 8, 14, 20」です。それぞれの集合において分布が一様であることを仮定すると、A には 100 / 10 * 4 = 40 人、B には 100 / 20 * 4 = 20 人いると推定できます。
ここでこれらの積集合を考えてみましょう。上記の情報だけでは積集合の全体は分かりませんが、少なくとも A はハッシュ値 10 まで、B はハッシュ値 20 までの正確なデータが存在しますから、ハッシュ値 10 までの範囲は正確な積集合が計算できます。したがって、ここでも分布の一様性を仮定すれば集合のサイズを推定できるというわけです。
和集合や差集合も同様です。今回のナローキャストでは、各属性情報ごとに事前にスケッチを作成しておき、上記の方法で集合演算を行うことで推定値が高速に計算できるようになります。
データサイズ
スケッチ構築途中の正確なサイズ(容量)は実装依存ですが、完成後は基本的に k 個のエントリとプリアンブル 24 バイトをあわせた 8 * k + 24 バイトに収めることができます(詳細は DataSketches の解説参照)。
誤差
上述の方法は飽くまでも推定で、誤差が生じる可能性があります。証明は省略しますが、今回利用した ThetaSketch の場合、相対標準誤差(Relative Standard Error, 標準誤差を推定値で割ったもの)が元データのサイズによらず 1/sqrt(k-1) になります。この値から推定値の信頼区間を算出することができます。以下に例を示します。
| 実際の人数 | k | 相対標準誤差 | 95%信頼区間 |
|---|---|---|---|
| 10,000 | 1,000 | 0.0316 | 10,000 ± 632 |
| 100,000 | 1,000 | 0.0316 | 100,000 ± 6320 |
| 10,000 | 3,000 | 0.0183 |
10,000 ± 366 |
| 100,000 | 3,000 | 0.0183 | 100,000 ± 3660 |
スケッチ同士で集合演算をした場合、和集合は k だけで誤差が決定されますが、積集合・差集合の場合は保存されている要素数が減り、誤差が大きくなる可能性があります。特に対象となる集合の大きさが大きく異なる場合に注意が必要です(詳細は DataSketches の解説参照)。
他の手法との比較
特定の条件にあてはまるユニークな件数(ここではユーザ数)を求める問題は count-distinct problem と呼ばれ、その推定には上述の KMV スケッチ以外にもいくつかの手法が存在します。その中でもよく知られているのが HyperLogLog で、入力をハッシュ関数にかけた値の「珍しさ」を記録し、そこから件数を推定します。この手法は和集合の計算に関しては KMV スケッチ同様高速に計算できる点で優れていますが、積集合の計算は包除原理による式変形や中間データ構造が必要になり、KMV スケッチに比べると性能的に不利になってしまいます。今回は API のユーザが様々な集合演算を自由に指定できることから、和・差・積の計算が最初から考慮されている KMV スケッチを選択しました。
開発
LINE のバックエンド開発では様々な言語が利用されていますが、ナローキャスト周辺はScalaで記述されています。過去に Scala の経験はおろか JVM 言語の使用経験自体ほとんどない状態からのスタートでしたが、メンターの方にサポートしていただき、楽しんで開発に取り組むことができました。
今回作成したものはおおよそ以下のように表すことができます。
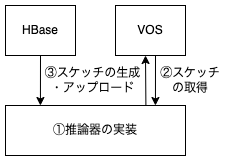
スケッチ処理には KMV スケッチをサポートする Apache DataSketches の ThetaSketch を利用しました(解説はこちら)。以下順にそれぞれの実装概要を紹介します。
推論器の実装
最初に着手したのは機能のコアとなる推論器です。ダミーのスケッチを用意し、gRPC 経由でリクエストを送ってそれらの集合演算ができるようにしました。実際の集合演算は ThetaSketch で既に実装されているため難しくなく、また Scala のもつ代数的データ型とパターンマッチによって直感的に処理を記述することができました。なお、結果には単一の推定値だけでなく 95% 信頼区間も含めるようにしています。
スケッチの取得
過去にナローキャストで配信したユーザ集合等のスケッチは既に存在したため、そのスケッチを指定してダウンロードする機構を作成しました。それらのスケッチは VOS と呼ばれる S3 互換の社内プライベートクラウドに格納されており、パスを指定することでファイルをアップロード・ダウンロードすることができます。Scala のトレイトなどを活用し、拡張性・柔軟性を意識して設計しました。初期設計ではスケッチは逐次的にダウンロードしていましたが、その後並列にダウンロードするよう変更しています。
スケッチの生成・アップロード
ユーザ属性に対応するスケッチは存在しなかったため、ユーザ情報が格納されたストレージ(HBase)をスキャンしてスケッチを作成し、VOS にアップロードする機構を作成しました。HBase はキーバリュー形式のストアで、LINE公式アカウントの ID とそのフォロワー(LINEユーザ)の ID、バージョン(≒作成日時)を組み合わせたものをキーとしてユーザ属性が整列されています。
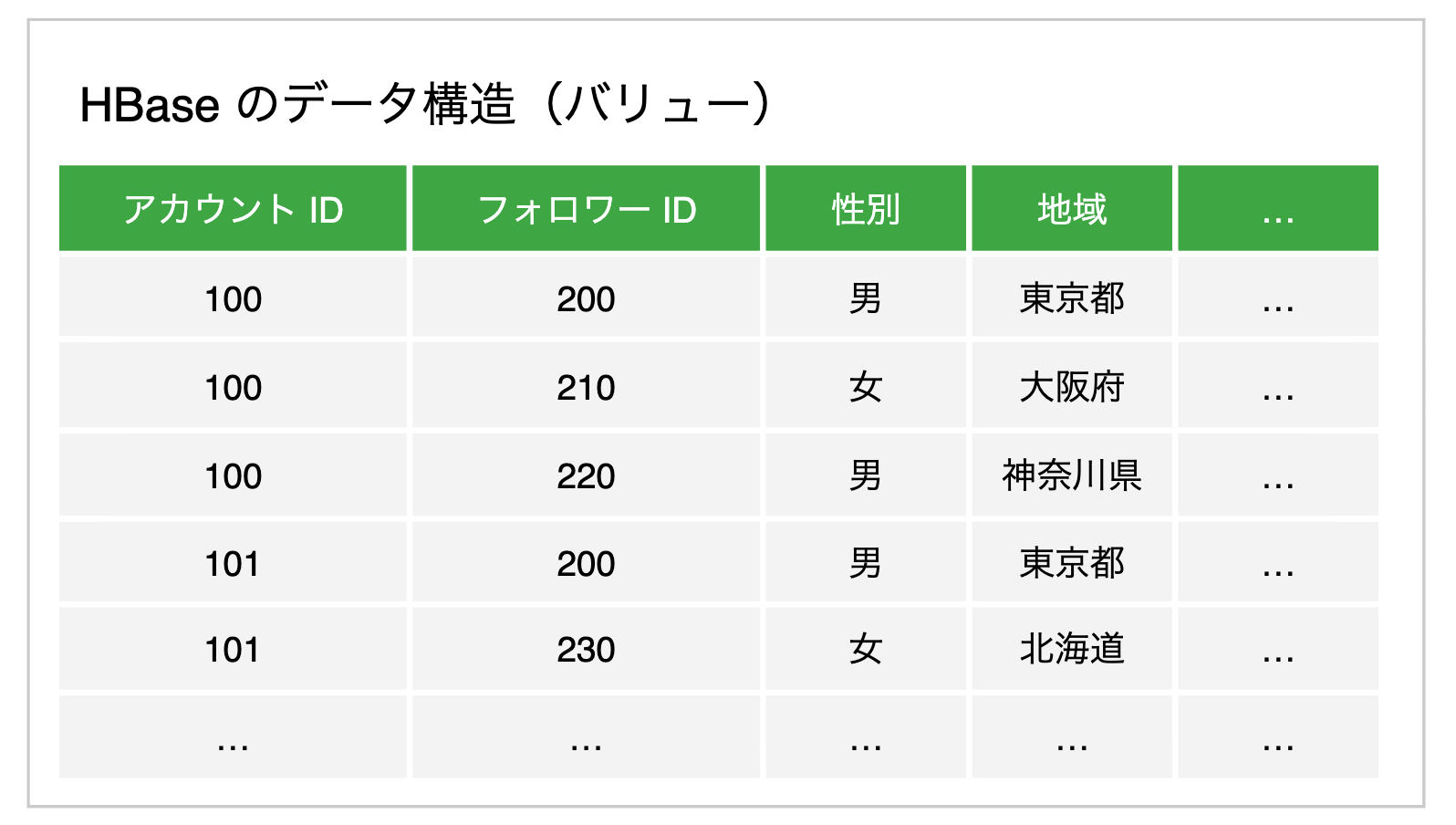
ここでは、HBase 全体をスキャンして最新バージョンのみ取り出し、アカウントごとに属性別のスケッチを用意してフォロワーの ID を投入していくことでスケッチ群を作成しました。スキャン結果は LINE公式アカウントの ID に関して整列しているため、処理の過程で随時スケッチをアップロードすることができ、LINE公式アカウントの数が増加してもメモリ使用量を一定の範囲に収めることができます。なお、HBase 全体のスキャンは当然重い処理であり、将来的にはその分散・並列化ができることが期待されます。
Scala について
今回始めて利用した Scala ですが、代数的データ型やモナドなど、手続き型言語の中に関数型言語の良さが多く取り入れられていることに魅力を感じました。糖衣構文や記号が多いこともあり慣れるまで少し時間がかかりましたが、今では数あるプログラミング言語のなかでもかなり好きな言語の一つになりました。
今後の展望
上述のバッチ処理や推定値算出はベータ環境のデータを利用して検証しています。これを実環境でも使えるようにするためには、より効率の良い HBase スキャンや、外部向け API の設計が必要になります。また、KMV スケッチにおける k の値は現状固定値ですが、元となる集合のサイズに合わせ可変とするなどして、精度が落ちない工夫をすることが今後の課題となると考えられます。
感想
今回のインターンはほぼオンラインで、自宅から VPN で接続して勤務していました。こうした環境では一人で問題を抱えがちになりますが、メンターの方が毎日 1 on 1 で疑問を解消してくださり、また Slack 上でも多数の質問や相談に乗っていただいたおかげで手を進めることができました。コードレビューを受けるのも初めての経験で、抽象的な設計・テストのしやすさの重要性を改めて認識しました。Scala でのプログラミングは楽しく、インターン後も学んでいきたいと感じています。
こうしたメインのタスク以外にも、オンラインランチ会などチームの方とお話できる機会があり、社員としての生活により具体的なイメージを持つことができました。また期間中数日はオフラインで勤務させていただき、四谷オフィスの環境を堪能しました。オフィスには人がまばらで、また同じチーム内でも四谷に出社したことがなかったという方も少なくなく、テレワークが浸透していることを実感しました。テレワークは楽ですが、あらゆる机が昇降机だったり、100 円で山盛りのサラダが食べられたりとオフィスの環境もなかなかに魅力的なので、機会があればぜひ行ってみてください!
6週間と長期のインターンでしたが、充実していてあっという間に過ぎてしまいました。初めてのインターンをこのような恵まれた環境でできたことを嬉しく思います。今回得た実践的な開発経験を、今後の個人の活動や研究に活かしていきたいと思います。
1 API 経由で知る方法はありませんが、LINE公式アカウントの管理画面(LINE Official Account Manager)では一部のクエリに対して推定値を表示する機能があります。ただ入れ子になった条件に対応していないなど、API 本来の自由度と比べると限定的な機能となっており、今回は別個に開発することになりました。