
1.はじめに
こんにちは, 東京大学工学部計数工学科数理コースの4年生, 西邑勇人です. 執筆時はまだ研究室に所属していませんが, インターンとして音声分野の研究室に所属していました. 今回, LINE での就業型エンジニアリングインターンシップとして行った, AI開発室の Voice チームでの取り組みを紹介したいと思います.
2.インターン課題と目的
背景
近年, 音声合成分野は目まぐるしく発展しており, ここ最近で特に話題になったモデルとしては, VITS[1] と呼ばれるものがあります. このモデルは, 音声合成分野における強力なモデルを組み合わせているだけでなく, VAE[2], GAN[3], Flow[4], といった深層学習分野で有名な手法を組み合わせているという, まさに集大成のモデルになっています. その精度も非常に高く, 実際の人間の音声との比較において有意差がなくなるほどまでになりました※1.
一方で, これが研究の終着点というわけではありません. 更に自然性を上げることは勿論のこと, 音声変換への拡張, 多言語・多話者への適用, 合成音声の表現力の向上... というように, 更なる発展先は多々あるのですが, 特にプロダクトとして需要が見込まれ, Voice チームとしても研究したいと考えられているものとしては, 「少量のデータによって話者適応を行う」というものがあります. これは, 目的話者に少量の音声を収録してもらい, その音声をもとにモデルを学習しそのユーザーと同じ声で話せるような音声合成モデルを作成するというものになります. なぜ需要があるのかと言うと, 例えば有名声優のように大量に音声収録が難しい場合でも適用可能で, 他にもアプリユーザーに大量の収録を要求するのはハードルが高いですが, それを下げられるといったメリットがあげられるからです. このような条件で作成するモデルは "Few-shot model" と呼ばれます. また, Few-shot modelよりさらに難易度の高いタスクとして, 目的話者のデータを学習には利用せず, 目的話者が1発話, 2-3秒喋っただけの音声を推論時にのみ使う"Zero-shot-model"もあります. こちらができれば理想ではありますが, その条件の厳しさから精度がまだあまり良くないというのが現状です.
Few-shot model, Zero-shot model, いずれの場合にせよ, 問題となってくるのは目的話者のデータの少なさになってきます. これは, 音声分野に限らず様々な分野で興味を持たれている話題で, その基本的アプローチとしては「大量のデータで訓練したモデルを用意しておき, そこからの fine-tuning を行う」というものになります. 以上から, 本インターンシップにおいては, この Few-shot model の作成においてどのような工夫を行えば高品質かつ目的話者の特徴を保った音声を生成することが可能になるのかについて検討を行いました。
※1: MOS テストの結果. 人間の音声と合成音声との CMOS テストでは僅かに差が表れる結果となっていることに注意.
目的と課題
目的
大まかな目的は先述した通りで, 少量のデータから高品質な TTS (Text-To-Speech) モデルを作成することになっています. そのために, 100名以上の英語話者による発話が収録されている VCTK コーパス[5] を利用します. これを用いることで, 上述した「大量のデータで訓練したモデルを用意しておき, そこからのファインチューニングを行う」ということが達成できます. その「大量のデータで訓練」 するために train 話者, validation 話者 を用意し, 「そこからのファインチューニング」 のために test 話者を選定します. validation 話者, test 話者としてそれぞれ 6話者ずつ取り出します. そして, 残りの96話者で構成された train 話者で VITS を訓練した後, test 話者の100発話(合計600発話ということ) で fine-tuning を行うことを考えます. これによって作成されたモデルの性能を良くしていくことが本インターンシップの目的になっています.
課題
課題を見つけるところから本インターンシップは始まりました. このブログでは, その部分から記述していきます.
3. 課題の探索
さて, 先述した通り, 本インターンシップでは課題は設定されていませんでした. というのも, まずは実験を回してみて, 現状の精度がどの程度のものなのかを調べるところが開始地点でした. これは一般的な研究やプロダクト開発と同様で, まずは従来法がどれほどうまく動くのかを調べるところから始めるということです.
以下に, その結果を記載します. 結果に記載すべき評価指標としては, 本来人間による聴取実験を行うのが一般的ですが, 今回はインターンの期間が短いことから困難だと判断しました. 一般的に, 目的話者のデータが少ない今回のような状況では, 1) 明瞭性の問題:うまく発音ができないことがある(例えば学習データに "ぱ" と発話したデータがなければ "ぱ" の音声合成がうまくできない) 2) 話者類似性の問題:目的話者らしさが十分にでない (合成した音声が目的話者の声に聞こえない) という2つが主要な問題なので, 今回はそれぞれに対応する以下の2つの客観指標を採用しました.
- 音声認識率: 人間の音声と生成した音声の両方を音声認識によって分析し, どれくらい音素が落ちているかを見ます. 明瞭性の問題に対応しています.
- 話者類似度: 話者性を数値列へとエンコードするモデルを利用して, 人間の音声と生成した音声がどれくらい似ているかをコサイン類似度で測ります. 話者類似性の問題に対応しています.
なお今後は次のように単語を定義し, 呼んでいくようにします.
- pre-train model (単に pretrain): VCTK コーパスの train 話者で訓練した model のこと. 600000 step ほど訓練する.
- fine-tuning model (単に ft): VCTK コーパスの test 話者の各100発話で訓練した model のこと. 100000 step ほど訓練する.
- Zero-shot: pre-train を用いて test 話者の20発話 (fine-tuning の訓練データとは被らない) で推論すること.
- Few-shot: fine-tuning を用いて test 話者の20発話 (fine-tuning の訓練データとは被らない) で推論すること
- inf: inference (= 推論. 学習したモデルから音声を生成すること) のこと
- ref: reference (= コーパスに含まれる正解の録音データ) のこと
- ASR: Automatic Speech Recognition の略. 音声認識率のこと.
- spk sim: 話者類似度のこと. 正解の目的話者のデータと合成したデータの話者性がどれだけ近いかを表す指標のこと.
|
pretrain/ft
|
ASR corr of inf/ref
|
spk sim
|
|---|---|---|
| pretrain | 84.2/87.7 | None |
| ft | 62.3/87.7 | None |
ただし, 音声認識率の結果は hugging face で公開されている学習済みのモデルである Wav2vec2.0[7] を利用して算出し, 話者類似度に関しては Resemblyzer[8] を利用して作成されています (この実験時は未実装のため None としています). 表の値は当該モデルの音声に対してあらかじめ用意した音声認識モデルで認識結果を出し、それと正解のテキストの一致率を見たものです. 高いほど入力されたテキストに忠実な音声を生成できているということになります.
この結果から, まずは単純に fine-tuning のモデルによって生成した音声は音声認識率が悪くなっていることがわかります. これは, 一部の音素が欠落したり間延びしたりといった現象が起きていることを示唆します (サンプル音声を下に添付します) . また, 話者類似度に関しては, この段階では客観評価を行えていなかったのですが, fine-tuning であれば十分同一話者が話しているようには聞こえる精度になっていることが実際の音声を聞いてみると確認できました. ここから, 当面の課題としては 「ft は必須で, ft をしながらも音素を落とさない (音声認識率の精度を下げない) ようにするにはどうすればよいのか」 という課題が生まれました.
間延びした音声の例:
| 正解の音声 | |
| 間延びした音声 |
さて, ではこの課題に対して原因を見つけ修正していくにはどうすればよいのか, ですが, それは科学全般の対処法と同じで「仮説を立てていく」というやり方になります. そしてその仮説がどれだけよい仮説かで原因がわかるまでの時間が変わってきますが, これに関しては経験・知識がものをいうので, 今回は惜しげもなく Voice チームの皆さんのお力をいただき, 高速かつ的確な仮説検証を回していけました.
では, 実際に検証した仮説について, 書いていこうと思います.
4. 仮説検証
仮説0. 基本的な仮説
まずは, 基本的な部分, 具体的には「データ量の問題」「訓練量の問題」といった仮説を検証していきました.
以下が結果になります.
|
pretrain/ft
|
data num
|
iteration
|
ASR corr of inf/ref
|
spk sim
|
|---|---|---|---|---|
| ft | 100 | 100000 | 62.3/87.7 | None |
| ft | 150 | 100000 | 67.7/87.7 | None |
| ft | 200 | 100000 | 71.0/87.7 | None |
| ft | 250 | 100000 | 70.6/87.7 | None |
| ft | 100 | 200000 | 56.1/87.7 | None |
まず上から4行のデータを見ると学習データ数を250発話まで増やしても性能が70.6と低いままであるため, データ量の問題ではない他の問題が隠れているということがわかります. また, 1行目と5行目を見比べると訓練不足でもないことが分かります.
通常, データ量を増やせば基本的に性能上限が得られますが, その精度がかなり低いというのが現状です. そのため, 何か根本的な問題が内在していることが示唆されます. そこで, チームの方が仰ったのは, 「データがおかしいのではないか. VCTK は多話者英語データセットであるが, アクセントも多様に含まれる. テストデータだけアクセントが少数派になっている可能性がある」ということでした. そこで, それについてデータセットを分析してみました.
仮説1. データセットの不均衡
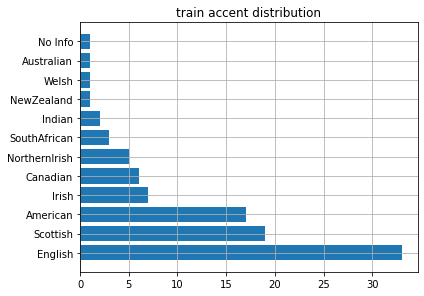
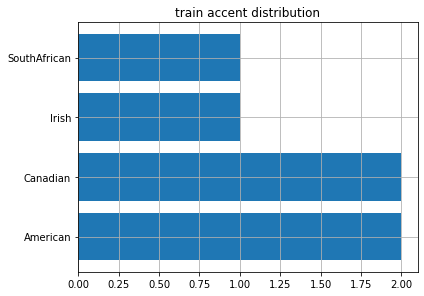
VCTK は話者のアクセント情報 ※2 をまとめているので, それをもとにアクセントの分布を図示しました.
※2: 英語には, イギリス英語やアメリカ英語といったアクセントの違うものが存在しています.
train
val
test
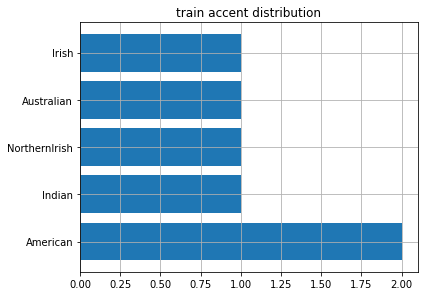
ここから, test データには train データにほとんど含まれないような少数アクセント話者で構成されていたということが分かりました. つまり, 相当不均衡なデータで検証を行っていたということになります.
本来, テストデータを変更することは良くないことではありますが, 精度の高い多話者モデルを作成したいという目的から train と test のアクセントの分布が一致するようにデータの分割を変更することにしました.
その結果, 以下のように変化しました.
|
pretrain/ft
|
dataset old/new
|
ASR corr of inf/ref
|
spk sim
|
|---|---|---|---|
| pretrain | old | 86.9/87.7 | None |
| ft | old | 75.6/87.7 | None |
| pretrain | new | 90.6/90.9 | 0.739 |
| ft | new | 82.3/90.9 | 0.867 |
この結果から, データセットに不均衡があったことが確かめられました. 実際, 自然音声ですらかなりの精度上昇があったことが分かります.
また, 話者性の入れ方を少し変更したのでpre-train, fine-tuningともに結果が良くなっていることに注意してください.
仮説2. text encoder の fix
次に考えられる仮説としては, 話者非依存のモジュールは変えないで置くべき, というものです. というのも, 今までの実験から, fine-tuning は大きく音声認識率の精度を落とすので, これは言い換えると重みを悪い方向に最適化させているとも言えます. 特に, 入力されたテキストの情報を高次元の潜在変数に学習している text encoder は、悪い方向に最適化されると音声認識率の精度に影響を大きく与えることが考えられるため、こちらを固定した条件を試してみました.
以下がその結果です.
|
pretrain/ft
|
text encoder fix
|
ASR corr of inf/ref
|
spk sim
|
|---|---|---|---|
| pretrain | false | 90.6/90.9 | 0.739 |
| ft | false | 82.3/90.9 | 0.867 |
| ft | true | 69.3/90.9 | 0.859 |
音声認識率の精度にかなりの悪化があることが分かります. 一方で, 話者類似度に関してはほとんど変化がないこともわかります. このことから, text encoder は確かに話者類似度に関しては影響をあまり与えないことは分かります. それ以上のことに関しては, 単に学習率などのパラメータが悪くうまくチューニングできなかった可能性もあるため, あまり明解な解釈をすることができませんでした.
仮説3. モジュールのどこかに問題
ここまでの実験で, データセットの不均衡については解決したものの, 満足いく精度向上には至っていません. あと考えられることとしては, VITS のモジュールのどこかに問題があるか, 学習が最適化できていないかという点になっています.
前者に関してまずは調査を行いました. これは, 学習時に計算される grad_norm ※3 を各モジュールごとに監視することで, どこかで不自然な変化が起こっていないか, 起こっていればそこで問題が発生しているかもしれないことが示唆されます.
以下に, 結果を示します. 実験は fine-tuning で行われています. text encoder は固定していません.
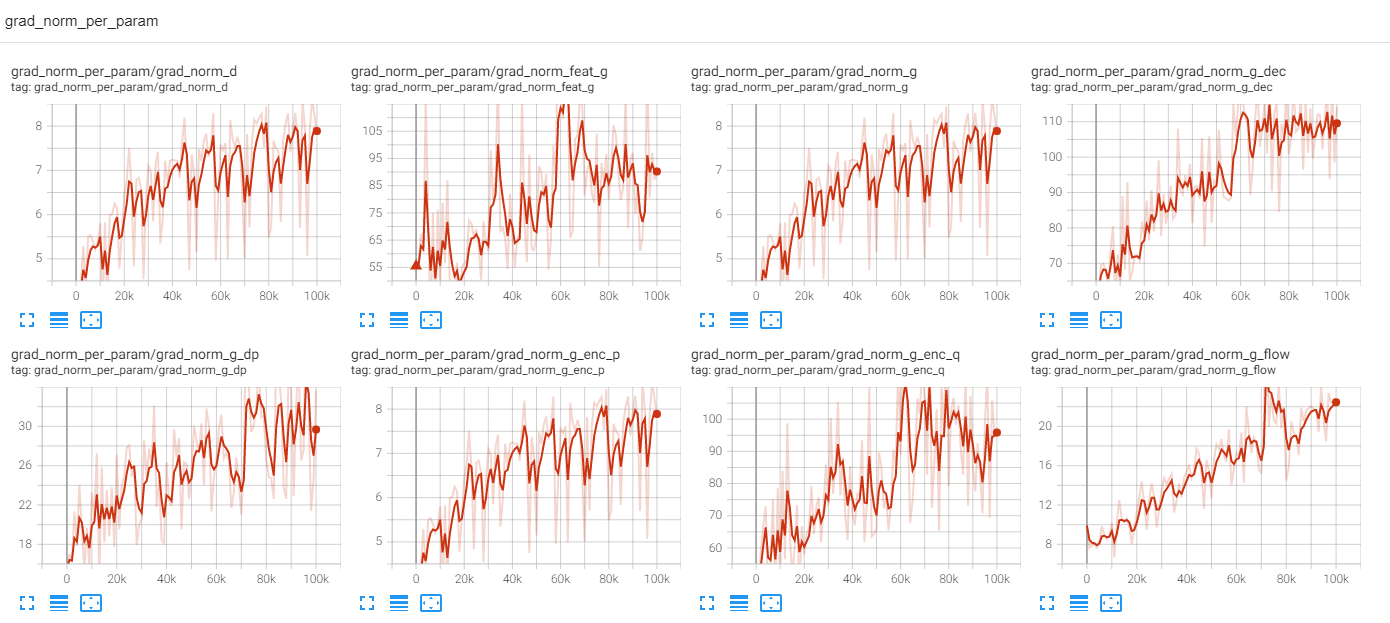
これは各モジュールごとの grad_norm をパラメータの数で平均をとったものになります. これによって, 絶対値で各モジュールがどれくらい更新されているかがわかります.
ここから, 詳細は省きますが, モジュールとして dec = enc_q > feat_g >> flow = dp >> enc_p という順に大きく更新されていて, より話者性に依存する部分から大きく変更を受けているという自然な結果が出ています.
また, 特に大きな発散があるなどの明らかな問題があるモジュール等も確認できませんでした. 一方で, grad_norm が step に応じて増加していることが気になりました. これは 学習率 が大きすぎるのか, step 数が大きすぎるのか, といったハイパーパラメータの調整が必要かもしれないということを示唆しています.
※3: grad_norm: 誤差逆伝播法によって計算される勾配の大きさを L1 ノルムで計算したもの.
仮説4. fine-tuning の step 数最適化
先の分析も踏まえ, また問題を明確にするためにも, fine-tuning の学習パラメータの最適化を行うことにしました. 一方で, step と学習率を同時に最適化するのは困難なため, 学習率は固定し step 数を最適化してみることにしました. その結果が以下になります.
音声認識率結果
ref corr: 90.9
|
5000
|
10000
|
15000
|
20000
|
25000
|
30000
|
35000
|
40000
|
45000
|
50000
|
|---|---|---|---|---|---|---|---|---|---|
| 89.0 | 89.4 | 88.5 | 89.2 | 87.8 | 87.7 | 87.7 | 86.5 | 87.0 | 86.9 |
| 55000 | 60000 | 65000 | 70000 | 75000 | 80000 | 85000 | 90000 | 95000 | 100000 |
| 86.4 | 86.2 | 86.5 | 86.2 | 85.9 | 86.4 | 86.5 | 84.9 | 84.8 | 85.3 |
ただし, 上にある数字は step 数を示しています.
話者類似性結果
|
5000
|
10000
|
15000
|
20000
|
25000
|
30000
|
35000
|
40000
|
45000
|
50000
|
|---|---|---|---|---|---|---|---|---|---|
| 86.6 | 86.8 | 85.7 | 87.0 | 85.4 | 86.0 | 85.4 | 85.4 | 85.0 | 85.5 |
| 55000 | 60000 | 65000 | 70000 | 75000 | 80000 | 85000 | 90000 | 95000 | 100000 |
| 85.4 | 85.3 | 85.8 | 85.0 | 85.6 | 85.2 | 86.2 | 85.8 | 86.0 | 86.2 |
ここからわかることとして, 20000 step というかなり速い段階で音声認識率の結果としては最適に近いということ, 話者類似度に関してはそこまで大きな変化はないことなどがあります.
一方で, 最適である step でもその音声認識率の結果は 89.2 であり, pre-train の 90.6 からはいまだに劣化が大きい印象があります.
仮説5. 音素継続長/未知音素 の問題
ある程度の最適化を行いましたが, まだ少し精度が足りないという状況でした. ということで, 一旦音素継続長の分析を行うことにしました. というのも, ここまでの実験においてすべて音声を聞いているのですが, 例えば uncond などの精度が低いものに関しては音素継続長がひどく短かったり長かったりというような音声が確認されています. そこで初期の段階から音素継続長の精度不足が懸念されていたので, ここで一度見てみることにしました.
また, それと同様に, 音素継続長の推定を失敗するとすれば未知の音素を推論する場合などが想定されるので, train/test データを比較して未知の音素が存在していないかも同時に調べました.
未知音素分析
まず, 音素の分析についてです. 音素は, IPA 音素が利用されていますが, VITS の実装では IPA 音素は文字単位に分解されて利用されているため, 分析も同様に文字ごとに行いました.
- monophone (1音素を一つの塊としてみたもの)
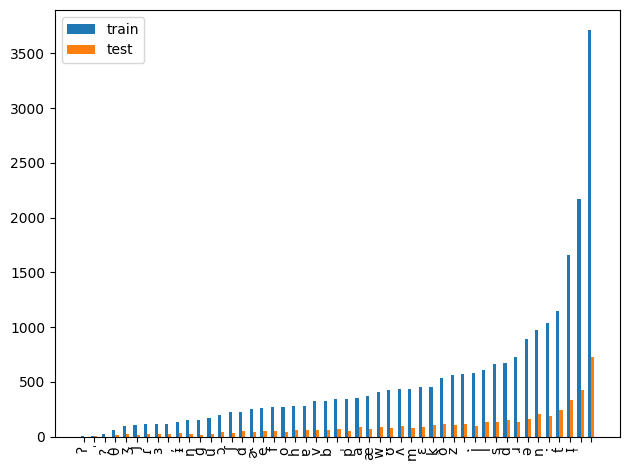
- biphone (2つの連続した音素を一つの塊としてみたもの). train = 0 のところから下位50データ (全体は 750前後)
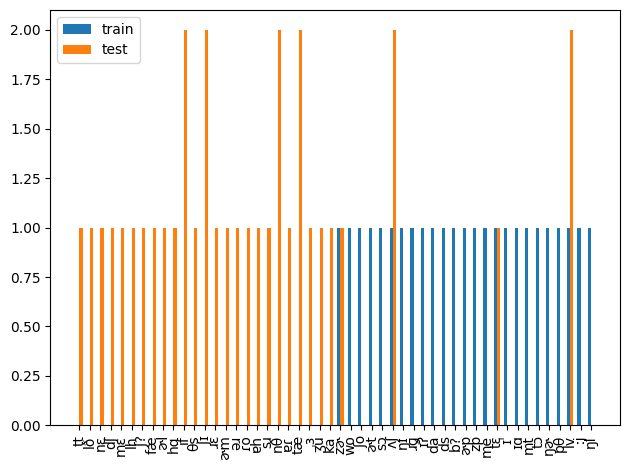
ここから, monophone には未知の音素はないが, biphone になるとある程度存在していることが分かります. 率でいえば, 約 30/750 = 0.04 なので, 無視できるほど小さいわけでもないことが分かります. 手詰まりになってしまった場合, この biphone を持つ音声を聞いてみて実際崩れているかどうかを確認しようかと考えました. 一旦音素継続長の分析に移ります.
音素継続長分析
pretrain/ft 20000 step/ft 100000 step について, 推論された音素継続長を音素ごとに box plot した結果が以下になります.
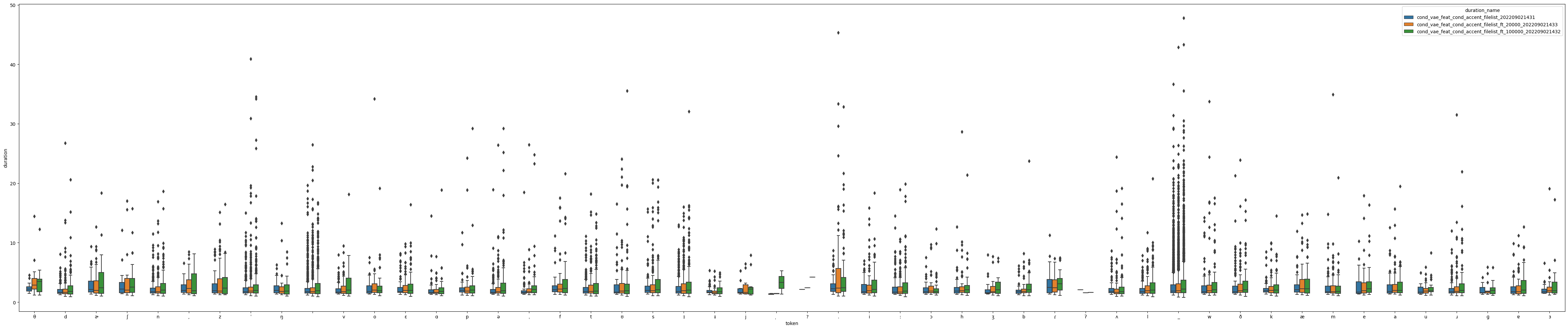
ここから, 100000 step のものはかなり pre-train よりも音素継続長の分布が離れてしまっていること, 20000 step でも偶に音素継続長が pre-train よりも離れることがあるということが分かります.
つまり, 音素継続長推定は実際うまくいっていないのが事実として分かりました. では, duration predictor, 及び Monotonic Alignment Search (MAS) ※2 の構造を見直せばこれが改善するのでしょうか? 確かにその可能性はありますが, モデル構造の変更はつまり他のパラメータの調整からまた始まることになり, 多大な労力がかかります. なので, 可能な限り最終手段にしたいです. そして, まだ試していないこととして, 学習率の変更があげられます. 確かに step 数は最適化しましたが, その時に早々に最適になっていたことから, かなり局所解は近いことが想像されます. その近い局所解に対して, 大きい学習率で最適化を行うのはかなり難しいと想定されます.
以上の考察から, 次に学習率の調整を行うことにしました.
※2: MAS: VITS のモジュールの1つで, 音声から得られた特徴量とテキストから得られた特徴量との間で尤度を計算し, それが最大になるようなパスを獲得してそれを音素継続長として得るための機構.
仮説6. 学習率の最適化
これは単純に学習率を小さくし比較します. 以下に結果をまとめます. ただし, step 数はすべて 100000 (default) です.
|
pretrain/ft
|
学習率
|
ASR corr of inf/ref
|
spk sim
|
|---|---|---|---|
| ft | 1e-4 (default) | 82.3/90.9 | 0.867 |
| ft | 5e-5 | 87.9/90.9 | 0.860 |
| ft | 1e-5 | 88.8/90.9 | 0.865 |
| ft | 5e-6 | 90.1/90.9 | 0.865 |
| ft | 1e-6 | 90.4/90.9 | 0.855 |
この結果から, 学習率が一番小さいものが音声認識率の精度が最高であることが分かります. pre-train の精度が 90.6 だったので, 僅か 0.02 の減少に留まっています. 一方で, 話者類似度に関しては一番小さくなってしまっていますが, これは実際の音声を聞くと, 0.85 程度あれば十分本人と聞き分けがつかないレベルになることが分かっているのであまり問題ではないと思っています.
さて, ここにきて最高精度を達成することができました. まだ 0.02 の精度上昇は可能と言えば可能ですが, ここからの精度上昇は困難を極めることが予想され, 残りの期間での改善は見込めないと判断したため, ここまでをブログの内容として書かせていただきました.
以下, 最終結果を報告します.
5. 最終結果
以下に, 主要な結果を示します.
|
ID
|
pretrain/ft
|
dataset old/new
|
学習率
|
ASR corr of inf/ref
|
spk sim
|
|---|---|---|---|---|---|
| 1 | pretrain | old | 2e-4 (default) | 86.9/87.7 | None |
| 2 | ft | old | 1e-4 (default) | 75.6/87.7 | None |
| 3 | pretrain | new | 2e-4 | 90.6/90.9 | 0.739 |
| 4 | ft | new | 1e-4 | 82.3/90.9 | 0.867 |
| 5 | ft | new | 1e-6 | 90.4/90.9 | 0.855 |
結果から言えば、「データセットの変更を行ったこと」「学習率の最適化をしたこと」が直接的に精度改善に結びついたのでその条件を変えた場合の結果を記載しました.
以下に, 実際の音声を添付します. また, 以下のような略語を用いています.
- ref: 人間の音声. この音声をもとに話者 embedding を作成し, モデルに条件付けをしている
- pred: 推論された音声. ref とはテキスト内容はリークを防ぐため変更されていることに注意
- ans: 推論された音声と同一テキスト内容を持つ人間の音声.
|
サンプル1
|
サンプル2
|
サンプル3
|
|
|---|---|---|---|
|
ref |
|
|
|
| ans |
|
|
|
| pred_1 |
|
|
|
| pred_2 |
|
pred_1: Zero-shot, baseline. 音韻的破綻は少ないが, 話者類似度が低い.
pred_2: Few-shot, baseline. 音素継続長も含めた音韻的破綻がみられる. 一方で話者類似度は高い.
|
サンプル1
|
サンプル2
|
サンプル3
|
|
|---|---|---|---|
|
ref |
|
|
|
| ans |
|
|
|
| pred_3 | |||
| pred_4 |
|
||
| pred_5 |
|
|
|
pred_3: Zero-shot, dataset fix したもの. 音韻的破綻は少ないが, 話者類似度が低い.
pred_4: Few-shot, dataset fix したもの. 音韻的破綻がみられるが, 話者類似度は高い.
pred_5: Few-shot, dataset fix, 学習率の最適化. 音韻的・話者類似度的に見てほとんど問題がない.
6. 研究のまとめと今後
本研究では, 少量の話者データで如何に精度の高い Few-shot TTS を実現するか, という内容でしたが, 最終的には満足のいく精度のモデルを得ることができました. 具体的には, 以下の知見を得ることができました.
- 音声の分野においても, データセットの不均衡は同様に難題であり, そこを修正すればモデルの学習はうまくいくことが多い.
- 学習率・ step 数といった学習に関するパラメータはデータ依存であるため, タスク開始時にまずは最適化しておくとよい.
また, それ以外にも「客観評価指標は最初から用意し, 常にそれを基準に議論していくべき」「音声研究においては生成音声を兎に角聞くことが重要」といった研究上の重要なことも身をもって実感しました.
今後としましては, 以下のような課題があげられます.
- 更なる精度向上に向けたモジュール等の改良
- 話者類似度の更なる向上
- 声質変換 (VC) への転用と精度向上
1点目に関しては, 本来 TTS の性質上, 人間の音声よりも音声認識率の評価が高くなることもあるため, Zero-shot ですらそれを超えられていないのはデータセットの問題かもしくはモジュールに改良の余地がまだあるということが分かります. 更なる完ぺきを目指し, 製品化まで辿り着くためには避けられない方向性だと思います.
2点目ですが, 今回話者類似度に関して厳密に定義していたわけではないですが, 「同一話者だと判断可能なこと」を意味として使っていました. 一方で, それだとまだ荒い評価であるという指摘もあります. つまり, 話者の話し方や細かい違いまで再現できてこそ, 類似しているというべきだというご指摘をいただきました. こちらも同様に製品レベルを目指すのであれば進めるべき内容だと思います.
3点目は突然 VC の話なのですが, VITS は実はそのモデルの性質上そのまま VC に転用することが可能になっています. そのため, 最終結果にもある最高精度を達成したモデルで VC の評価なども行っています. その結果は正直あまりよくありませんでした. 具体的には特に音声認識率の結果が TTS と比べ大分悪かったです. VC はテキスト内容は入力に用いず, 音声の情報のみ入力として用いるため, 確かに原理上そのテキスト内容を保持するのは困難であったりします. 一方で, それを差し置いても話者性を除去するのが不十分であったりと, 構造上まだ改善の余地がみられると思いました. 個人的には VC に興味があるので, こちらを進めるのも面白いかと思っています.
7. 感想
今回のインターンシップにおいて, 「少量の目標話者データを用いた End-to-End TTS における明瞭性・話者性の改善」というテーマに基づいて研究を行ってきました. 課題の探索から始まり, 複数の仮説検証を経て無事に原因を特定し満足のいく精度を得るに至りました. 結論だけ見てしまうと, 単にデータセットを修正し学習率を最適化しただけではあるので, 基本的なことと言われてしまえばそうかもしれません. 一方で, 私はこの過程にこそ意味があり, 途中過程から得られた知見というのも多くあると思っています. そのため, ブログとしては少々長くなってしまいましたがこのプロセス全体を思考の流れとともに記述させていただきました. 今後インターンシップをする方の参考になればと思います.
最後になってしまいましたが, 本インターンシップを主催してくださった方々, Voice チームの皆様方, 人事の皆様, そして特にメンターの方には非常にお世話になりました. 音声の分野でトップを走る企業で研究をさせていただけて, やはりそのレベルの高さと計算環境などの充実した設備, その他福利厚生の充実さに始終圧倒されていました. まだ先にはなりますが, 今後の就職先選びなどに非常に参考になるとても有意義な時間でした. また, 音声の研究を続けていけば, 必ずこれからも交流があると思いますので, その時はまたご一緒させていただけたらなと思います. 短い間ですが, ありがとうございました.
参考文献
- Jaehyeon Kim, Jungil Kong, and Juhee Son, “Conditional variational autoencoder with adversarial learning for end-to-end
text-to-speech,” in Proceedings of the 38th International Conference on Machine Learning, 2021. - Kingma, D. P. and Welling, M. Auto-Encoding Variational Bayes. In International Conference on Learning Representations, 2014.
- Goodfellow, I., Pouget-Abadie, J., Mirza, M., Xu, B., Warde-Farley, D., Ozair, S., Courville, A., and Bengio, Y. Generative Adversarial Nets. Advances in Neural Information Processing Systems, 27:2672–2680, 2014.
- Chen, J., Lu, C., Chenli, B., Zhu, J., and Tian, T. Vflow: More expressive generative flows with variational data augmentation. In International Conference on Machine Learning, pp. 1660–1669. PMLR, 2020.
- Christophe Veaux, Junichi Yamagishi, and Kirsten MacDonald, “Cstr vctk corpus: English multi-speaker corpus for cstr
voice cloning toolkit,” 2017. - AdaSpeech: adaptive text to speech for custom voice. In International Conference on Learning Representations, 2021
- A. Baevski et al., “wav2vec 2.0: A framework for self-supervised learning of speech representations,” in Advances in NIPS, vol. 33. Curran Associates, Inc., 2020, pp. 12 449–12 460.
- L. Wan, Q. Wang, A. Papir, and I. Lopez-Moreno, “Generalized end-to-end loss for speaker verification,” 2018 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pp. 4879–4883, 2018.