
はじめに
こんにちは、中谷颯太と申します。京都大学大学院の修士1年で、都市計画系の研究室に所属しており、転居に伴う弊害についての研究を行っています。今回は6週間の就業型インターンとしてML Infrastructure1チームに参加させていただき、ML Annotation tool におけるAuto Labeling機能の開発に取り組みました。本記事では、その内容について紹介します。
ML Infrastructureチームとは
ML InfrastructureチームではMLエンジニアがモデル開発に集中できるように、また社内の他組織がMLおよびその周辺環境を利用しやすくなるような環境を作ることを目的としており、そのためのプロダクトの開発や運用保守を行っています。
そのようなプロダクトの一つとして、ML Infrastructureチームでは社内のデータから学習データをより便利に円滑に作成するためのAnnotation toolの提供を進めています。今回はこのプロジェクトに参加させていただき、その中の一機能であるAutoLabeling機能の開発を行いました。
背景
アノテーションとは
まずはじめに、アノテーションとは何なのかについて簡単に説明します。
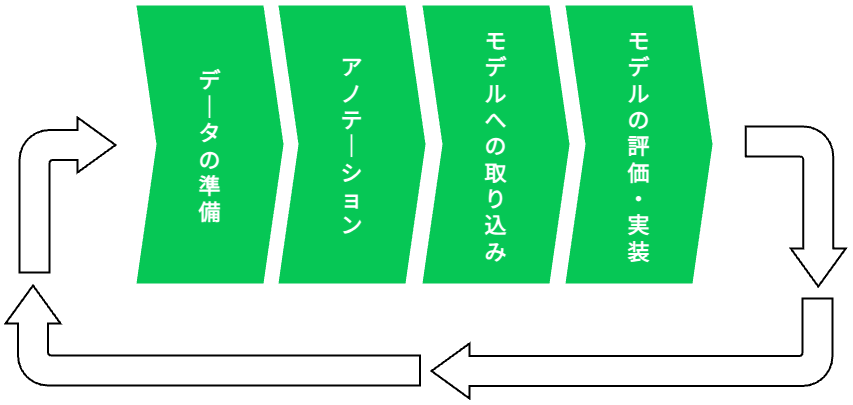
「アノテーション」とは、機械学習の中でも「教師あり学習」に必要な「問題とその正解ラベル」のデータを作成する工程のことです。学習の過程は以下の図のようになっています。このアノテーションというフローは教師あり学習の中で重要な過程の一つであり、モデルの精度を上げていくためには、アノテーションによって得られる「問題とその正解ラベル」のデータの「正しい」セットが「大量」に必要になります。
アノテーションデータ作成には人手が必要なため、大量のデータを作成するには時間と費用がかかります。例えば、とあるニュースにおいてアノテーションのデータを作成する場合を考えます。ここで、野球選手の画像と宮城県で行われた野球の試合の記事があれば、作業を行う人は野球のタグと宮城県のタグをつけて「問題とその正解ラベル」のセットを作成します。アノテーションデータを作成する際には、このような作業を様々なニュース記事に対して行う必要があります。
Annotation tool の概要
上記で述べたように、機械学習のモデルの精度を上げていくために精度の高いアノテーションのデータが大量に必要になってきます。しかし、社内のアノテーションプロジェクトには「アノテーションを新たに作成して学習を行うハードルが高く、必要なタイミングで学習のためのデータを増やすことができない」という問題がありました。具体的には、アノテーションのツールが社内で統一されておらず、プロジェクトの開始に際しては技術選定が必要であったり、アノテーションのためのExcelシートの準備を行っていました。また、学習のデータを増やす際には、社内のデータベースから取り出したデータをアノテーションをする人に提供し、アノテーション後に結果をまた、社内のデータベースに格納しモデルを学習する必要があり、アノテーションをする環境が効率的ではない、という状況でした。
この様な問題を解決するために、ML InfrastructureチームではAnnotation toolの開発および導入を進めています。内製の統一的なAnnotation toolを開発・導入することで、社内のデータベースから学習データをより便利に、統一的に扱うことができたり、技術選定やExcelの作成に工数をかけずにスムーズにアノテーションプロジェクトを開始することができます。つまり、アノテーション自体のハードルを下げたり、必要なタイミングでスムーズに学習のデータを増やすことが可能になるというわけです。これにより、ニュースのカテゴリ分類やスタンプレコメンドなどの自動化を進めることができ、機械学習を利用したサービスの提供を促進することができます。
AutoLabeling 機能
今回、私はAnnotation toolにおけるAutoLabeling機能の開発を行いました。
AutoLabeling機能とは、その名の通り機械学習モデルを使用して自動的にデータセットに付与すべきラベルを提案する機能のことを言います。この機能を活用することにより、アノテーション作業をする際は自動ラベルを付与されたデータセットを確認し、必要に応じて間違っているラベルを削除したり、足りないラベルを付け足すだけで良くなります。つまり、「問題とその正解ラベル」を作成するアノテーション作業にかかる時間とコストを削減することができます。
本機能を開発することにより、いかにアノテーションのハードルが低く楽に、また学習コストを抑えてアノテーションプロジェクトの開始ができるかを主眼に置いています。
現状の問題点と解決策
ML Annoation tool は Doccano(https://github.com/doccano/doccano/)というOSSを元に必要に応じた改修を加えることで開発を行っています。
本OSSには備え付けのAutoLabeling機能が存在していますが、社内の運用フローと合わない仕様になっているため、LINEにおける運用フローと合うようにまた、アノテーションプロジェクトのハードルが低く、学習コストを抑えた独自の仕様に改修していきます。
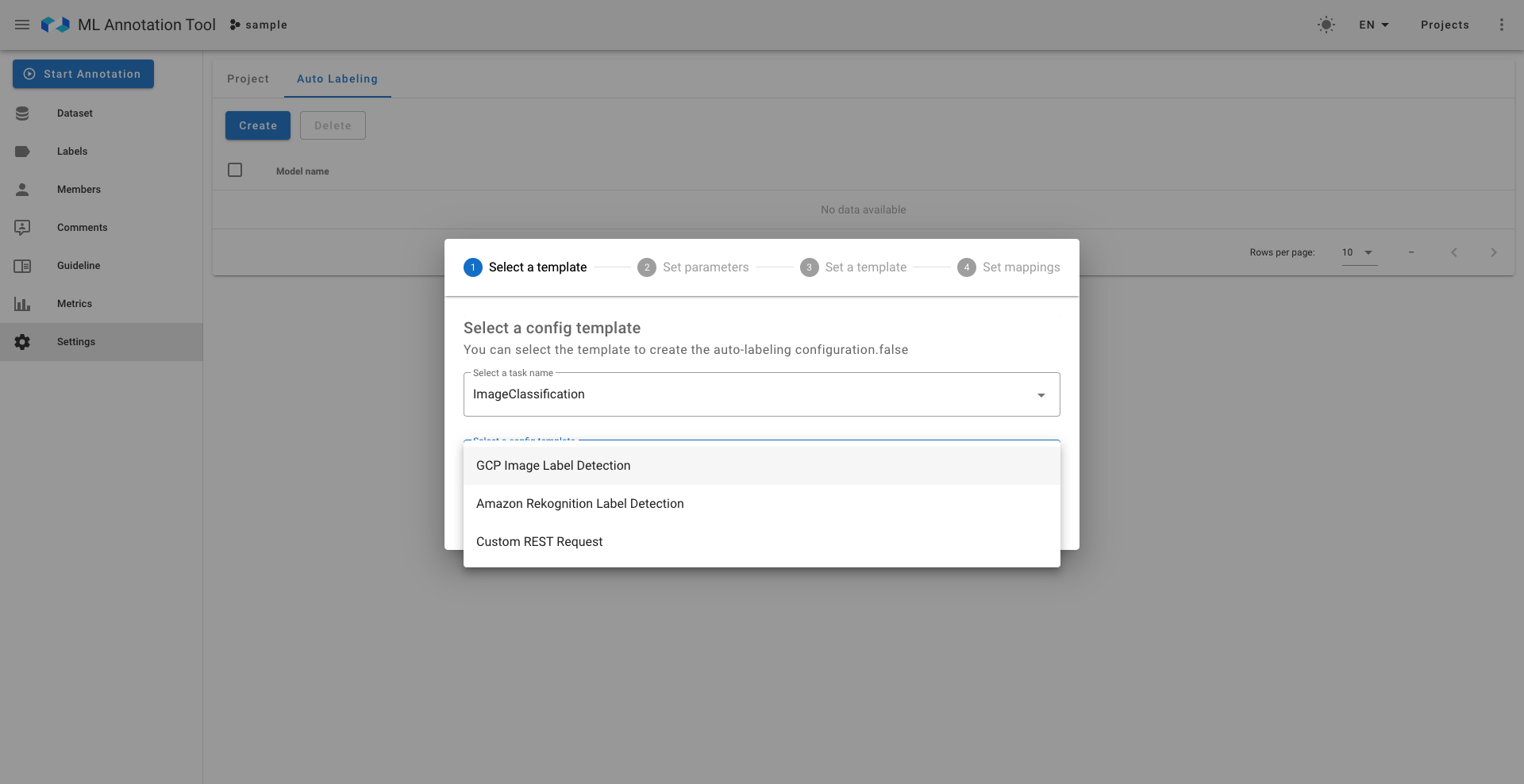
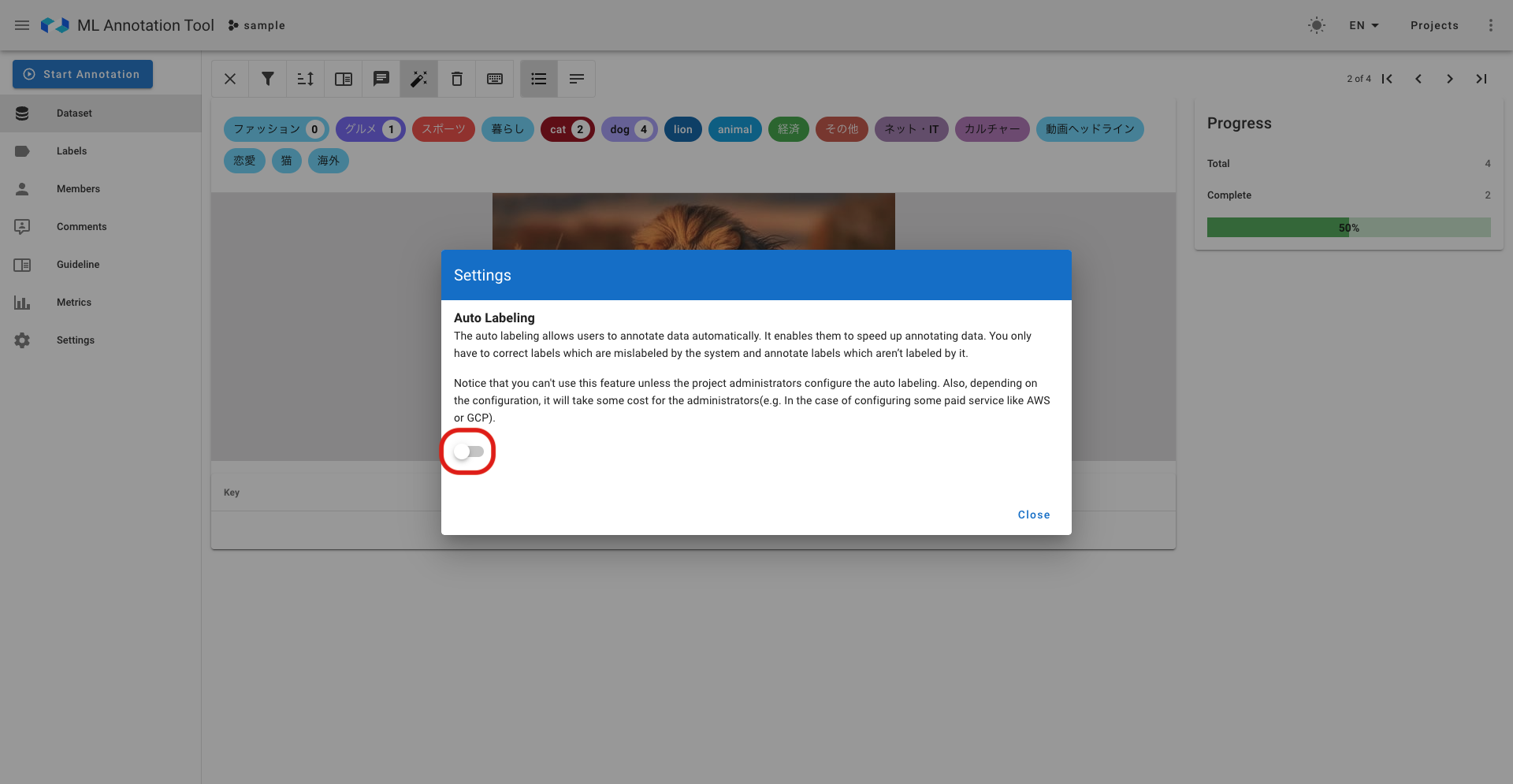
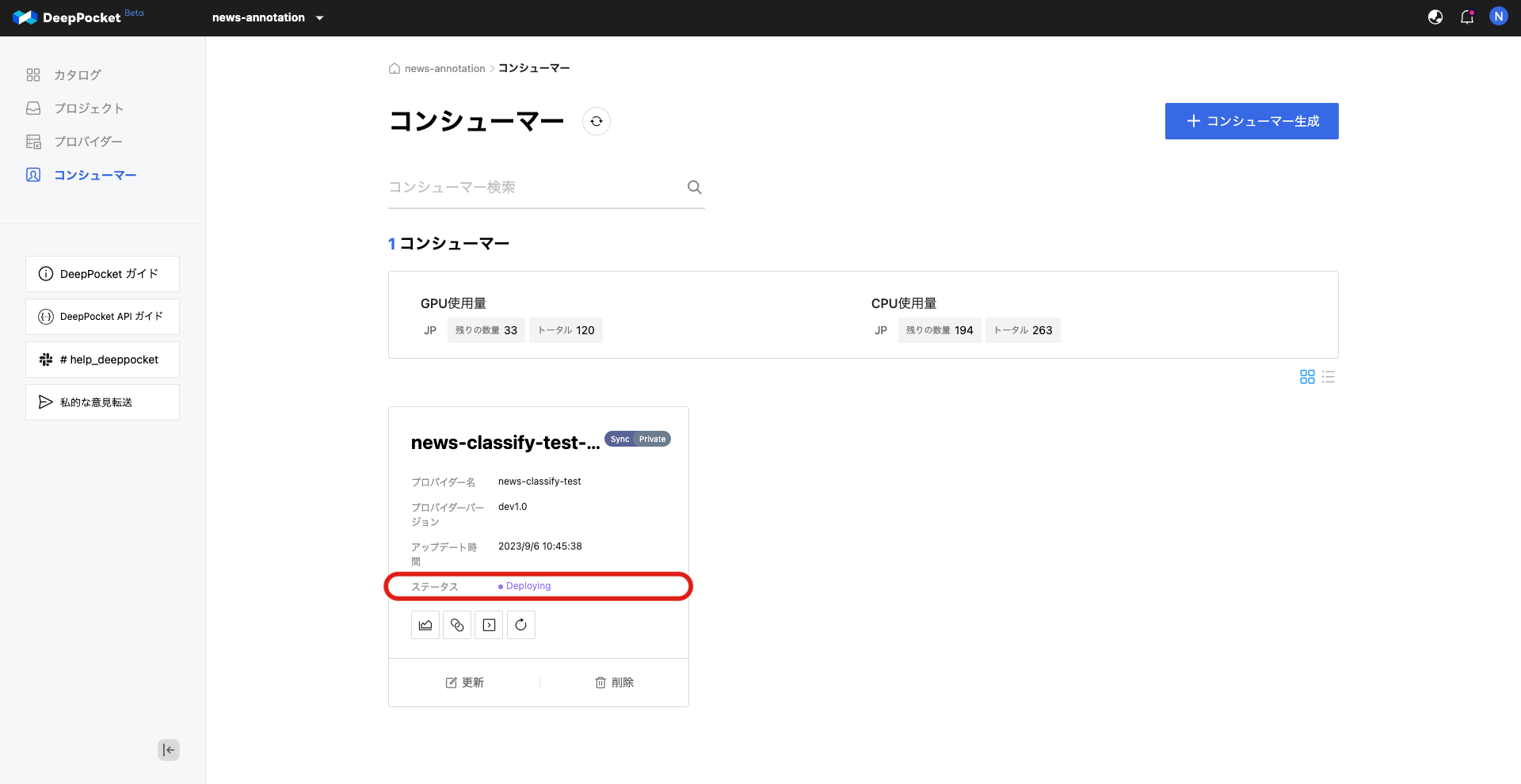
具体的には、まずAutoLabelingの設定部分についてです。本ツールでは以下のように外部の推論サーバーとの連携設定を行うことで機能を実現しています。詳しくみていくと、まず以下の写真一枚目にみられるようにAWSやGCPの設定に対応しています。また自分で作成したエンドポイントを使用するCustom Endpoint設定も可能となっており、豊富で高度な設定が可能です。社内向けの推論APIを開発しているLINEにおいては、Custom Endpoint設定を用いればAutoLabeling機能の設定を行うことができますが、社内のアノテーションプロジェクトでは非エンジニアも使用する予定のため、AutoLabeling設定のための学習コストや心理的ハードルを下げたいです。
そこで、今回はAutoLabeling設定部分についてユーザが使いたいモデルを指定すると、推論モデルのAPIがオンデマンドで起動される独自の連携設定を開発しました。これにより、非エンジニアでも簡単に利用できるようになり、アノテーションプロジェクトを始める際のハードルを下げることができます。
 |
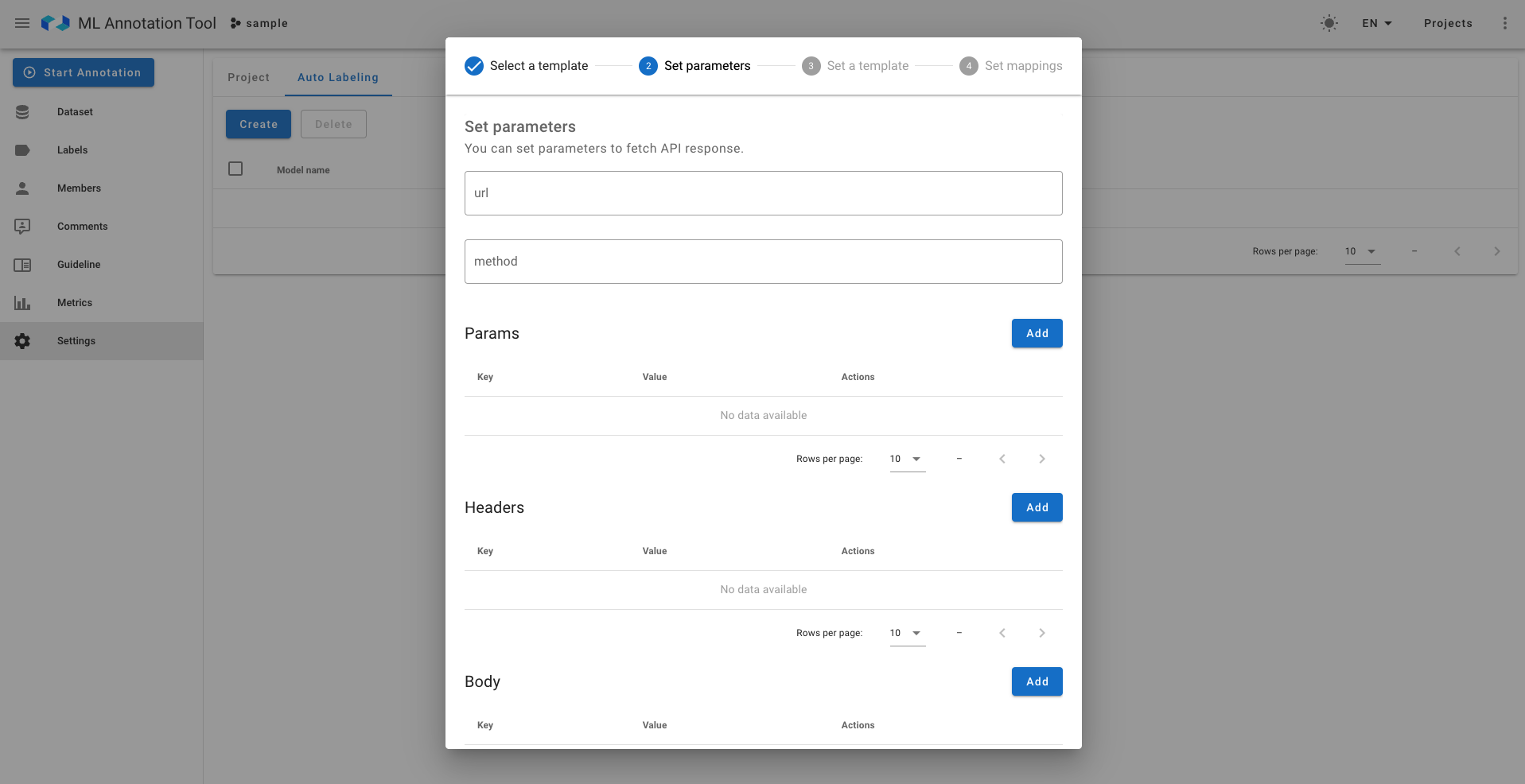 |
- 左:設定の選択肢
- 右:Custom Endpointのみの高度な設定①(推論モデルに対するリクエストの設定)
 |
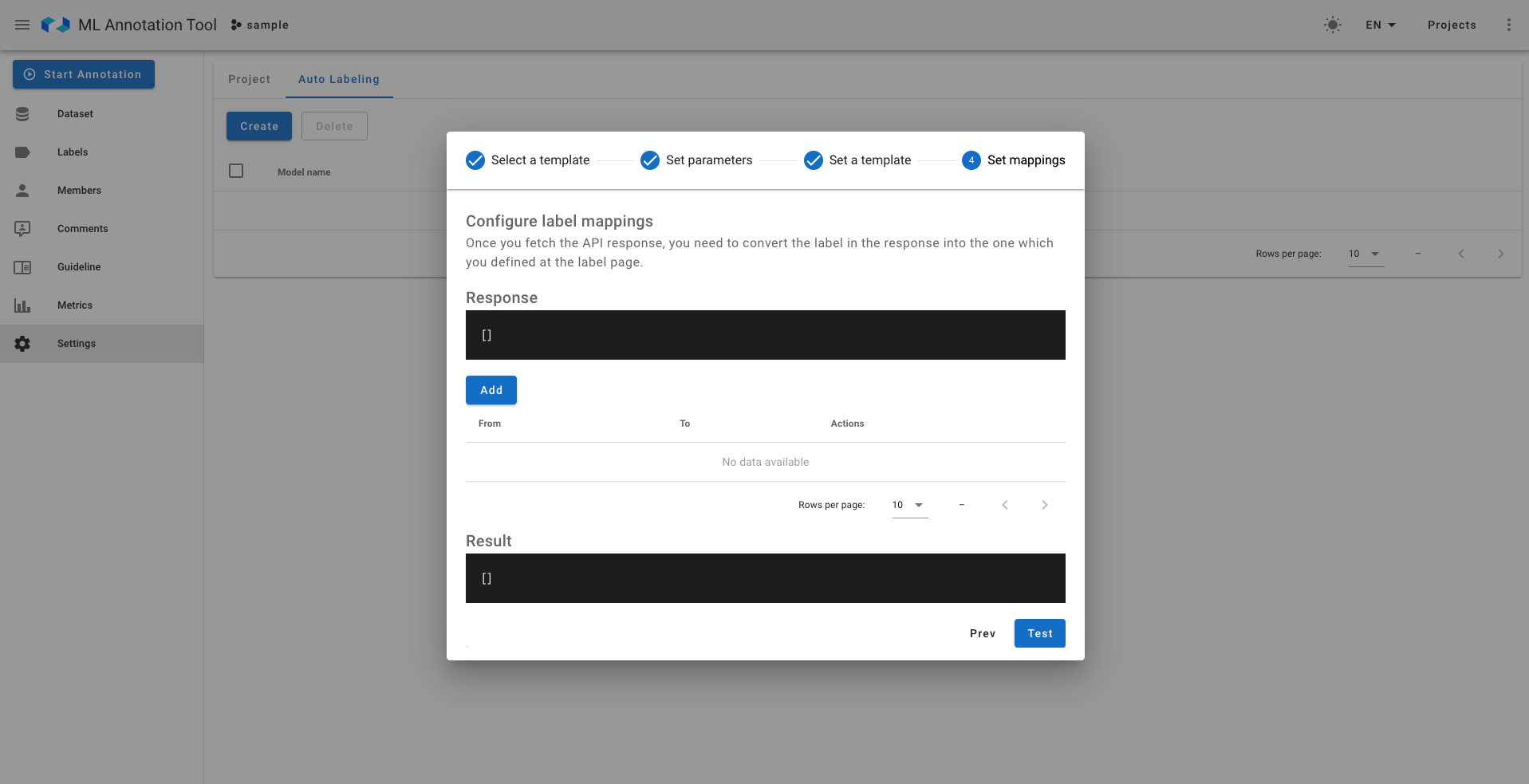 |
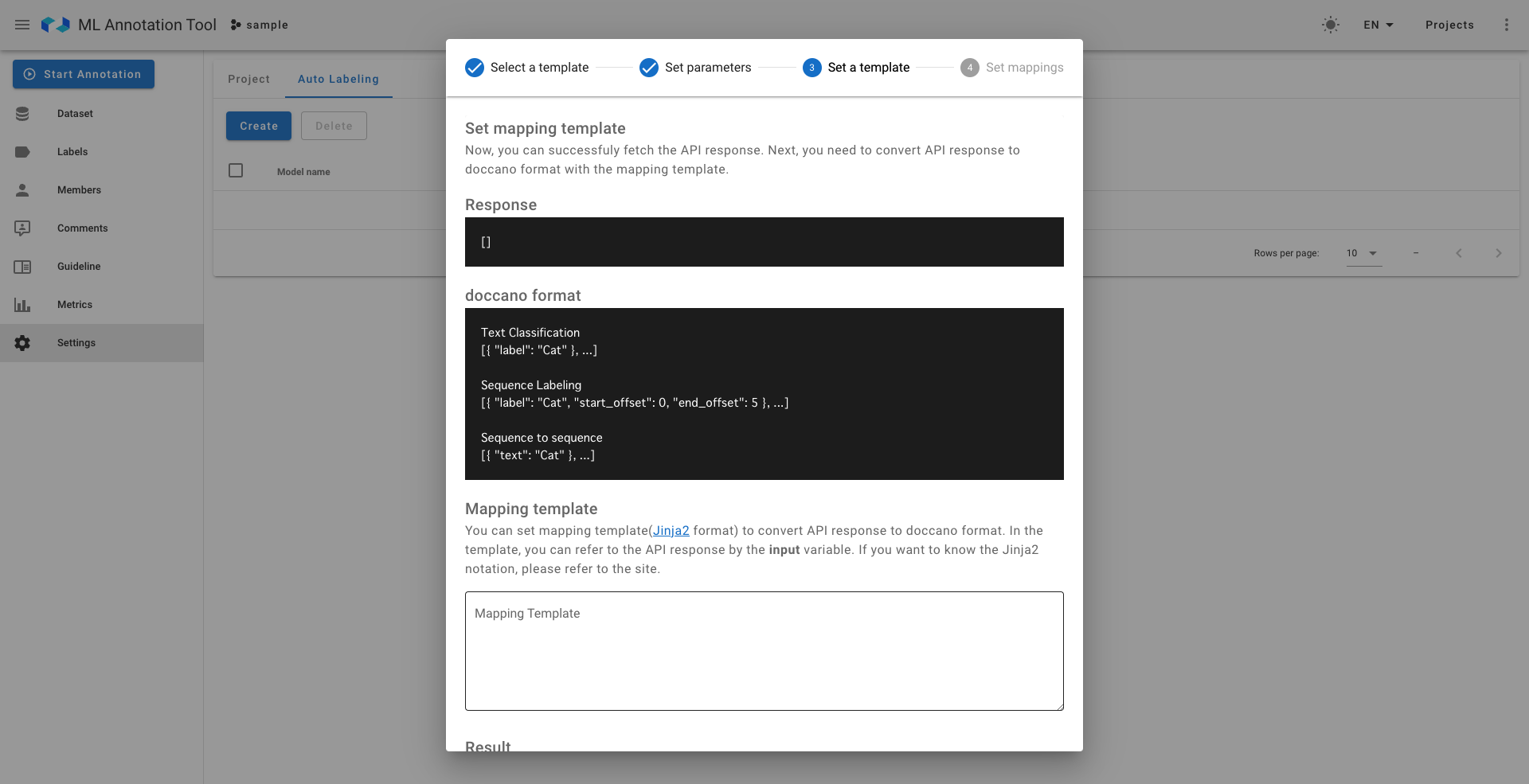
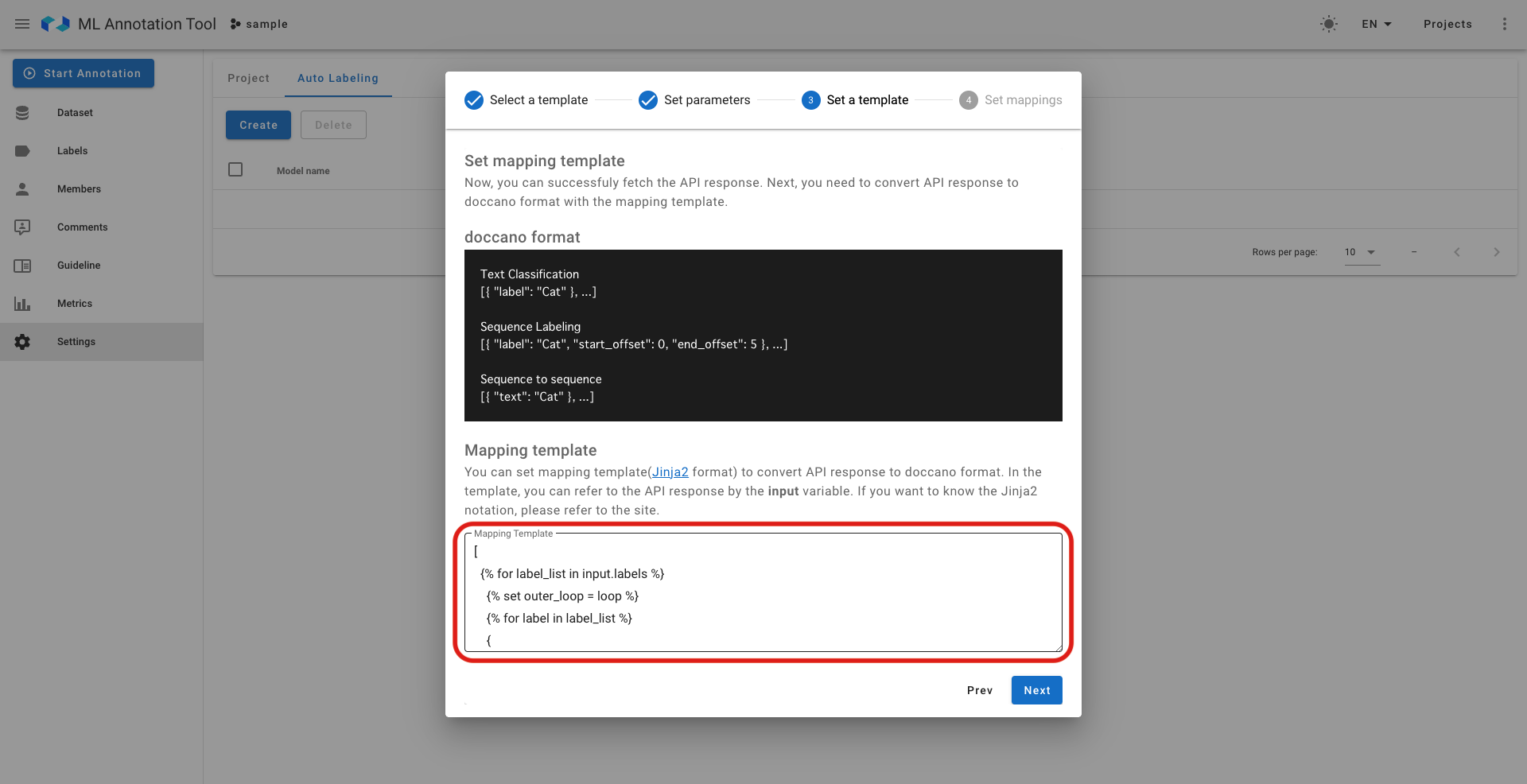
- 左:Custom Endpointのみの高度な設定②(推論モデルのレスポンスをAnnotation tool内で使用できる形へ変換するための設定、OSSのテンプレート設定を用いているため記述には知識が必要)
- 右:Custom Endpointのみの高度な設定③(推論モデルのレスポンスをAnnotation tool内のどのラベルにマッピングさせるかの設定)
AutoLabelingの実行機能についても、社内運用フローと合わない部分があります。社内では、アノテーションプロジェクトの管理者がデータセットやラベルの整備、AutoLabeling設定や実行を行い、アノテーターがアノテーションを実施するという運用フローを採用する予定です。しかし、現在のUIでは、管理者がAutoLabelingを行う際に一つ一つのデータセットの詳細画面を訪れ、AutoLabelingを実行する必要があります。元のOSSにおいてはAWSやGCPをAutoLabelingに使用できるような仕様ですので、推論にかかるコスト面を考慮してこのような仕様になっていますが、LINEにおいては社内向けの推論APIを開発し使用する予定のため、AutoLabelingの際の画面遷移は問題点の一つとなっています。
そこで、アノテーションプロジェクトの管理者権限を持つ人が一括でAutoLabelingを実行できる機能を実装します。また、間違った設定によりAutoLabelingを実行してしまった場合の対策として、間違ったラベリングの一括削除機能についても実装します。
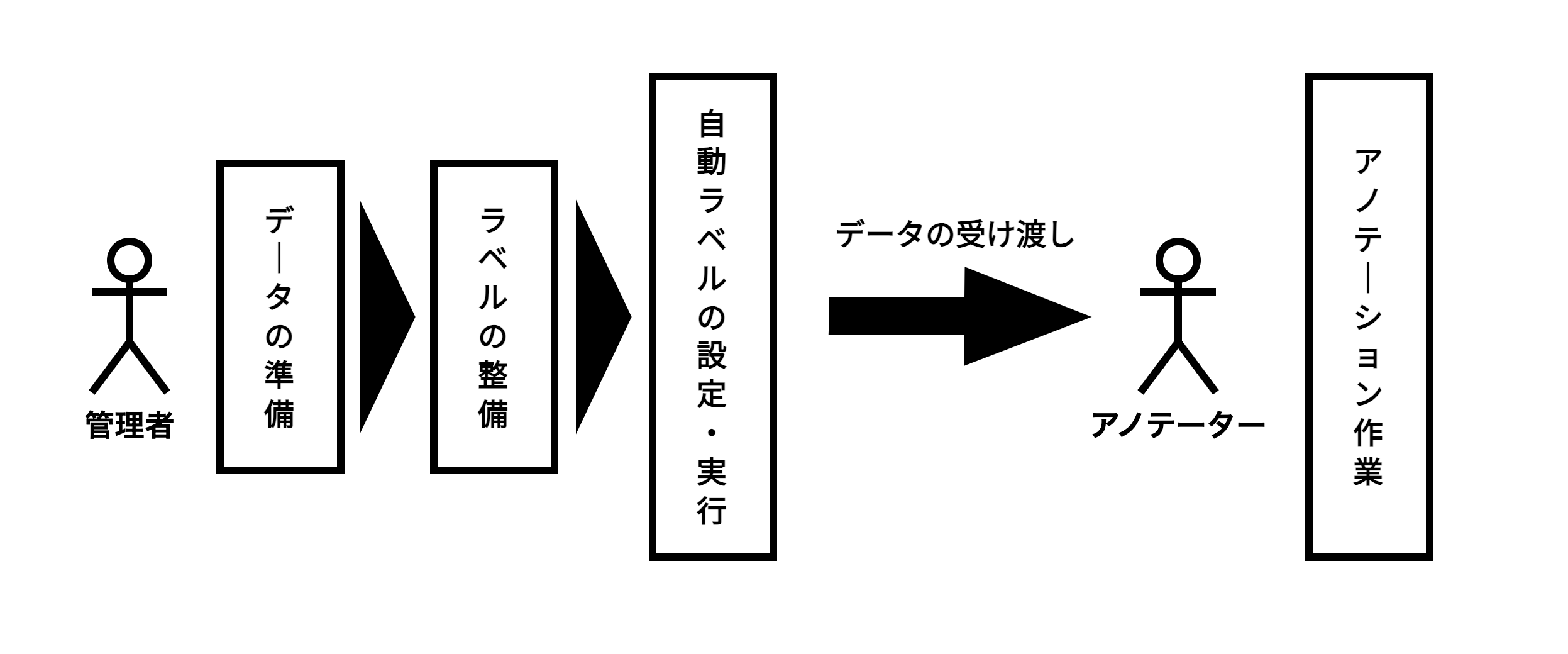
- 社内のアノテーションフロー想定
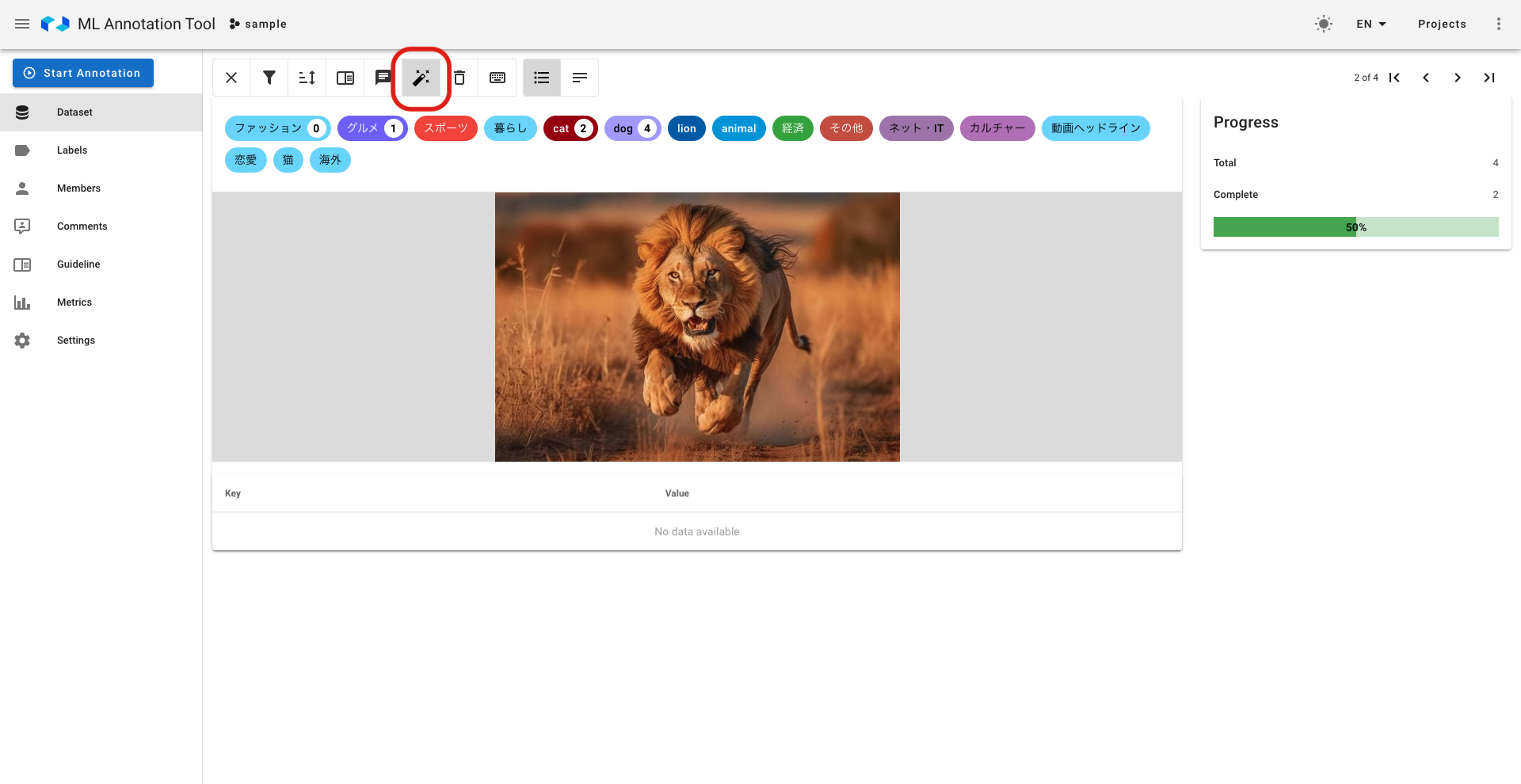
- AutoLabeling機能を使うまでの操作
実装
では、解決策を元に具体的な実装を行いたいと思います。使用技術については、フロントエンドについてはNuxt.js、バックエンドについてはDjango REST Frameworkでの実装を行い、フロントエンド改修、APIエンドポイントの作成、正しく動くかどうかのテストの作成を行ないました。本ツールでは既存のOSSを拡張する形で開発しているため、いかに現在の抽象度を壊さずに拡張するかを考慮して実装します。
社内ツール「DeepPocket」を用いたAutoLabelingのための連携設定の開発
今回、推論モデルのAPIがオンデマンドで起動される独自の連携設定を開発するに当たって使用したのが、社内サービス「DeepPocket」です。DeepPocketは、機械学習モデルの推論APIを簡単に運用できるようにする社内システムで、必要なモデルに応じて推論APIサーバーをUI上から建てることができます。本サービスは、APIサーバーに関する操作や元となるモデルの操作に関する外部APIを提供しています。今回の開発においては、提供されている外部APIを利用して独自の連携設定を作成しました。
具体的には、DeepPocketでのAPIサーバービルド、建てたサーバーの状態確認や、推論APIにリクエストを送るためのクラス作成、設定を行うためのエンドポイント作成やUI改修を行いました。
本機能を開発するにあたり、既存のOSSの抽象クラスの定義を上手く残しつつ、拡張する点についてはかなり気をつけて実装しました。具体的にはMixinの抽象クラスを作成し抽象度を保つことで堅牢性に考慮したり、既存の抽象クラスをオーバーライドする形でうまく実装しています。
また、推論サーバーとの連携機能をシームレスに提供するにあたり、推論サーバーへのRate Limitへの考慮や非同期でのサーバービルドの処理も行っています。
以下は具体的な動作の様子です。
他のAWS, GCPの設定については今回の運用フローにおいて使用しないため削除しています。
Custom Endpoint設定についてはエンジニアも使用するので機能を拡張しつつ残しており、DeepPocketの設定を追加しています。

簡単な設定を行い、テストボタンを押すと、DeepPocket側でのサーバービルドの処理が走ります。
ここで、見慣れない言葉がありますが
- provider_project:推論モデルを所有しているプロジェクト
- provider_name:推論モデルの名前
- revision:推論モデルのバージョン
くらいに考えていただければ大丈夫です。
また、設定自体が本当に正しく推論APIにリクエストを送れるのかを確かめるためのテストの画像やメタデータをここで入れます。
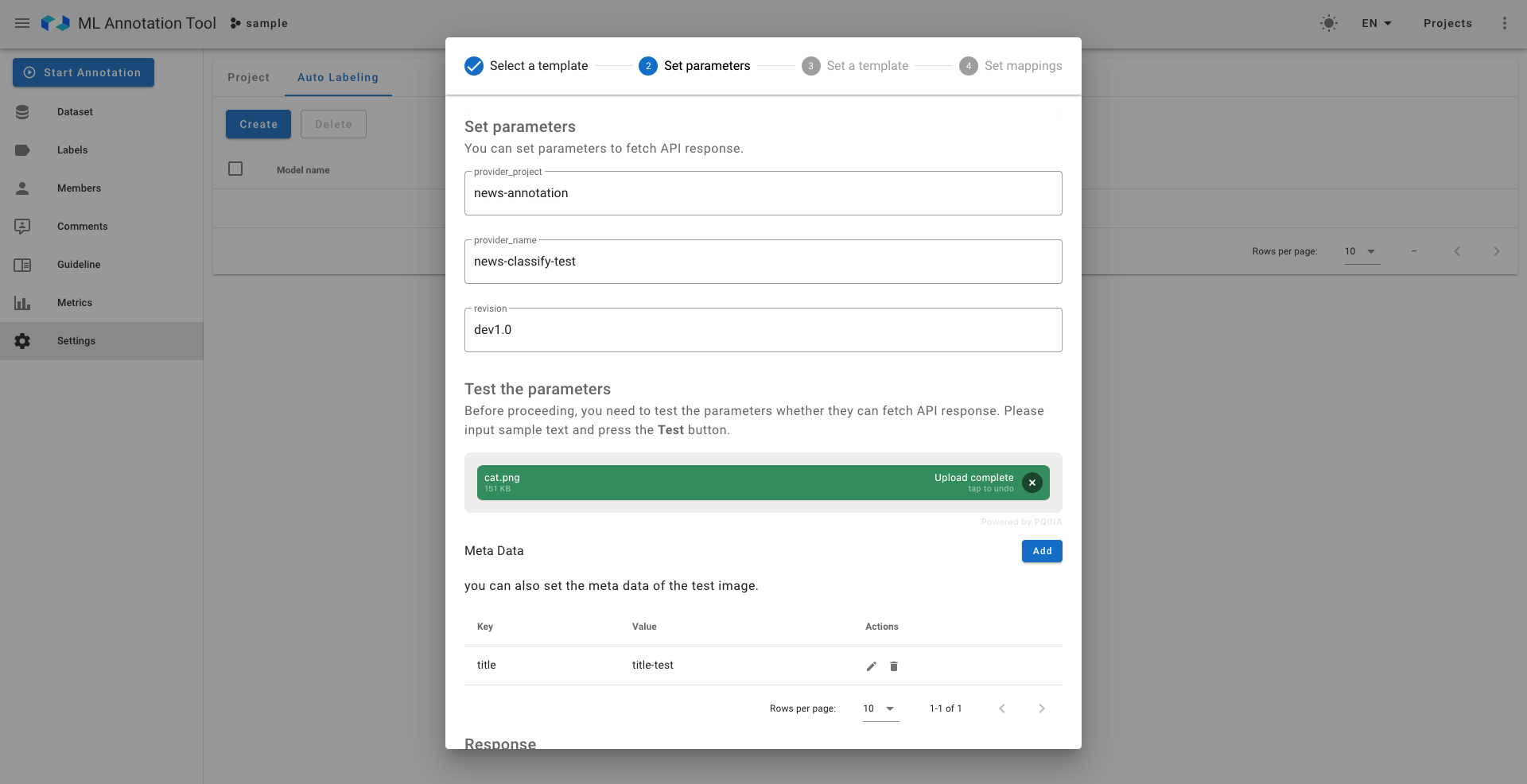
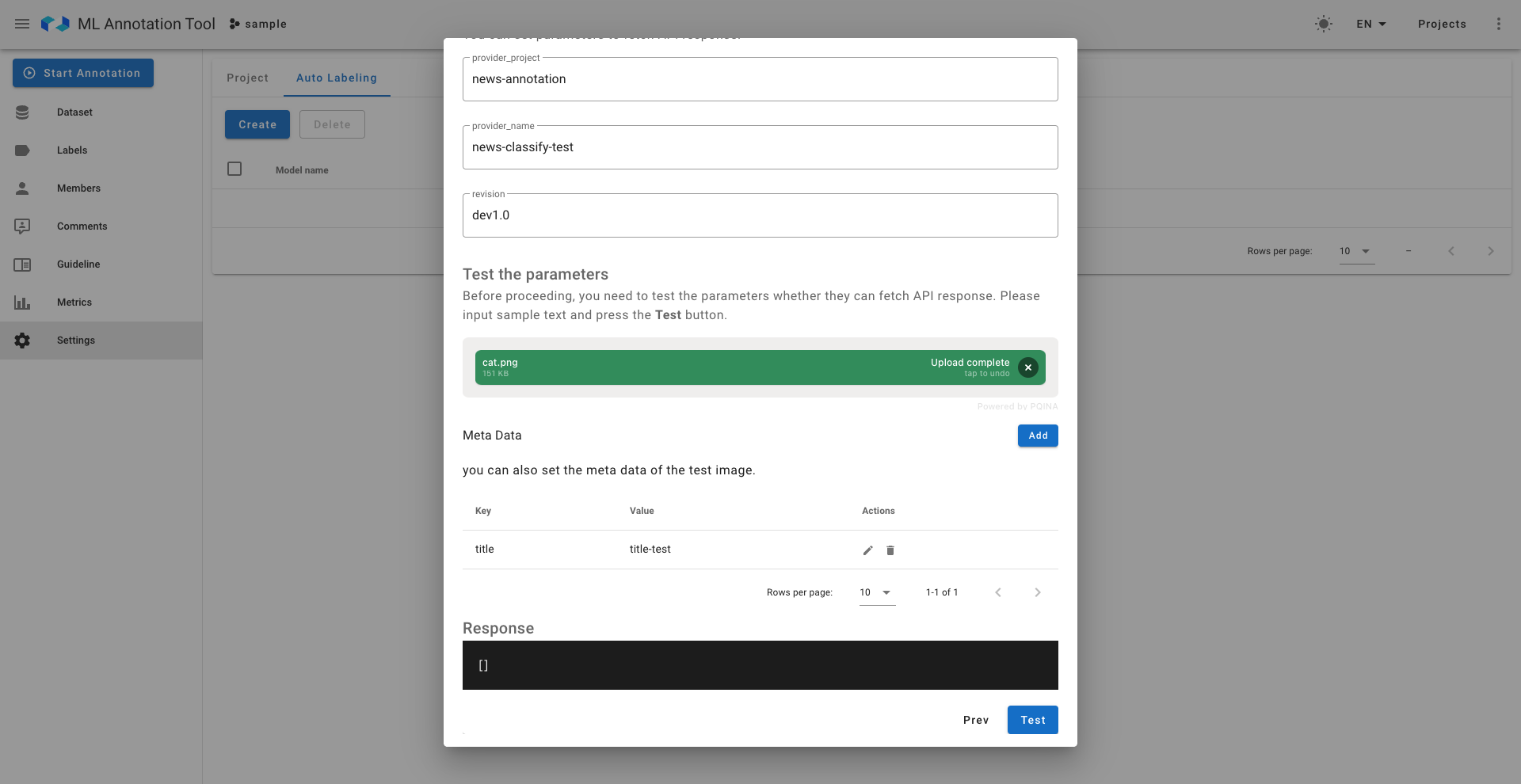
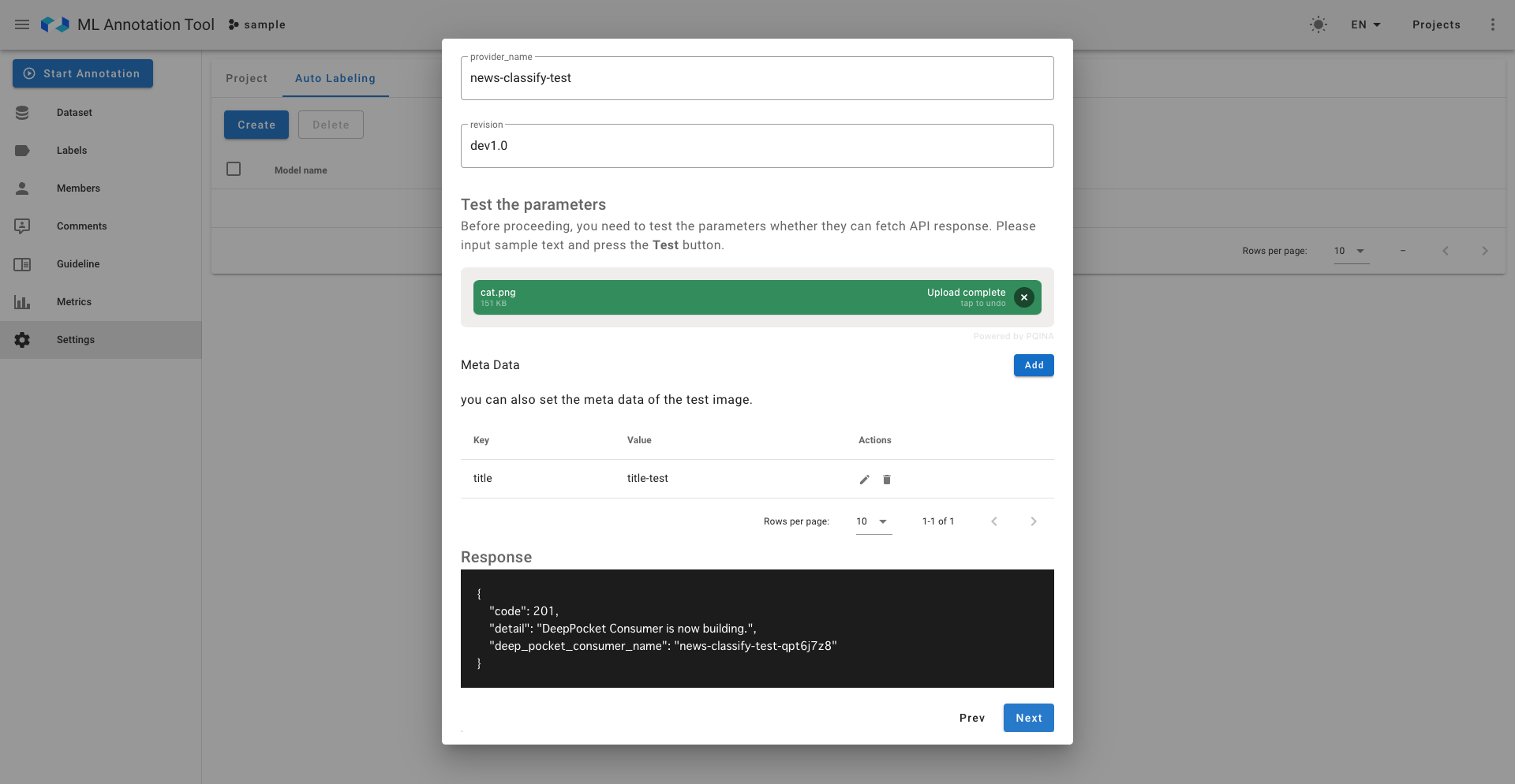
DeepPocket側では推論APIのサーバーがデプロイ中であることが確認できます。
テンプレート設定についても、学習コスト低下を促すため対応モデルについては自動で入力された状態になっています。
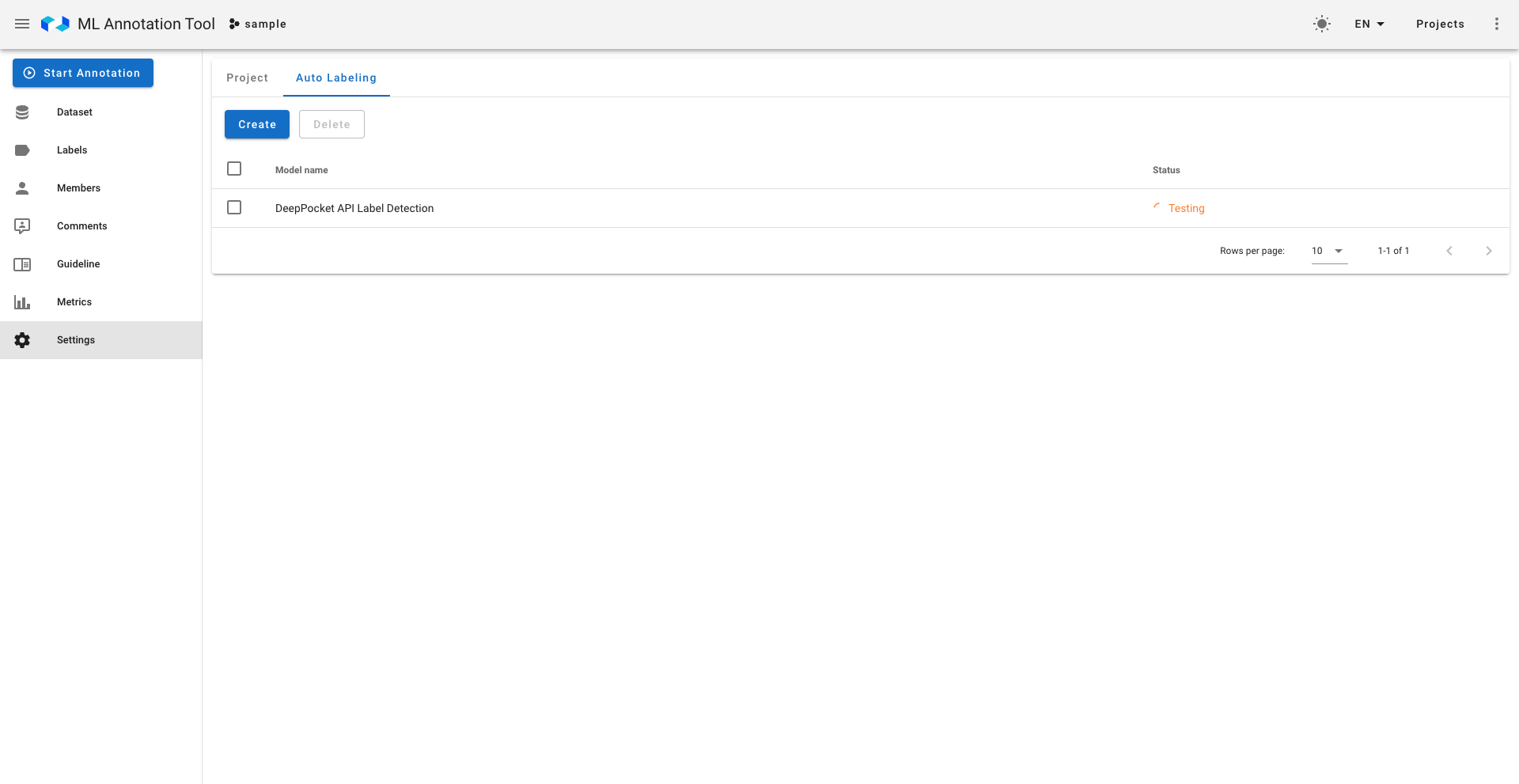
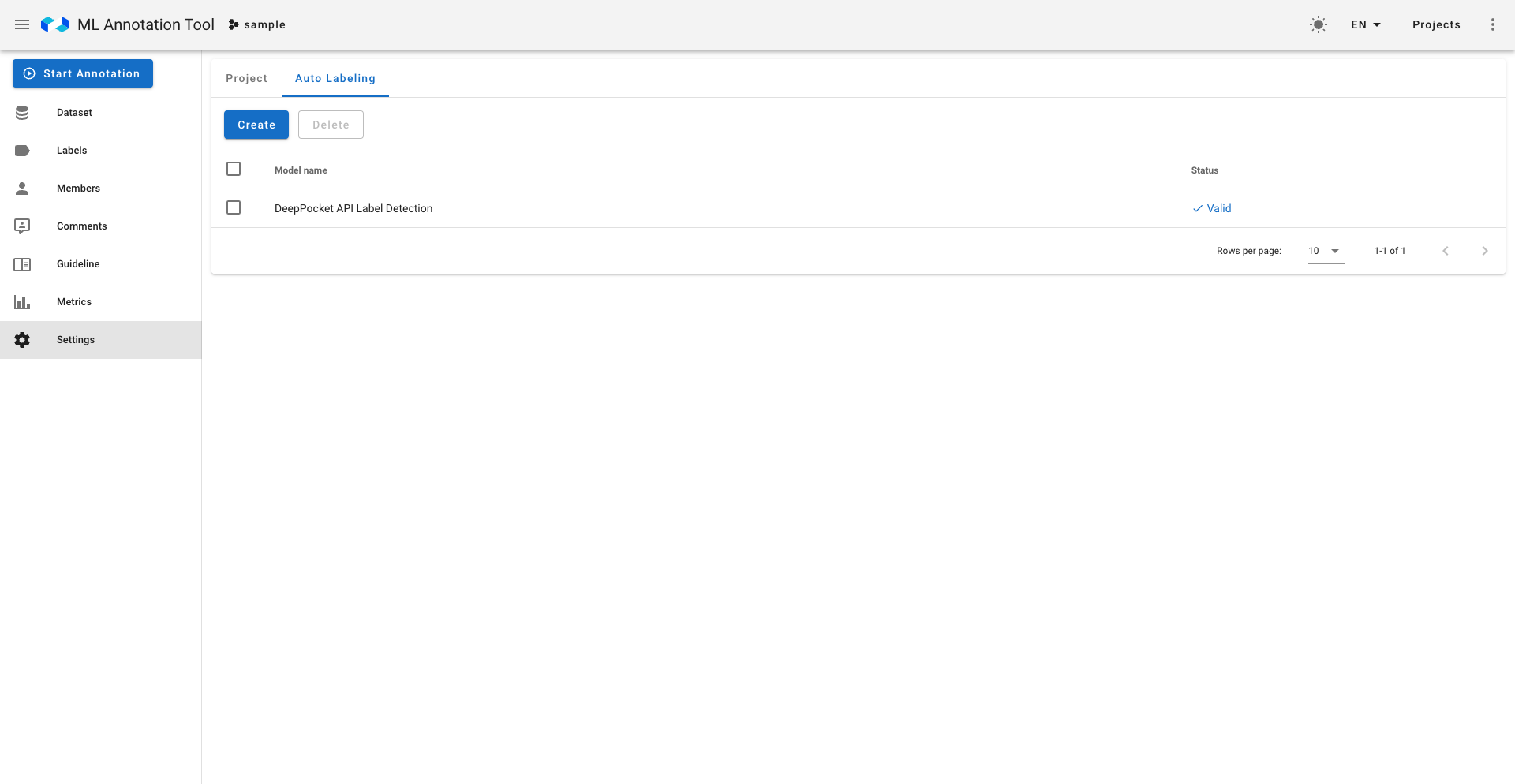
設定後は設定自体が有効に動くかどうかのテストが非同期で走り、正しい場合は右のように有効だという表示がなされます。もちろん無効な設定はAutoLabelingには使用されません。
一括AutoLabeling実行部分の開発
AutoLabeling実行部分、削除部分については、主にUI改修及び実行部分に関するエンドポイントの作成を行いました。
実行部分に関して、推論サーバーへの一括リクエストは負荷のかかる処理のためceleryを用いた非同期タスクとして実装し、Rate Limit制限もかけています。削除部分に関して、アノテーション作業が終わったものについては削除を行わないように、また負荷の少ないクエリを記述するように心がけました。
以下のように一括でAutoLabelingが実行されていることが確認できます。
これらのラベル付けが間違ったモデルによるものだった場合には以下のように一括で削除が可能です。
finished、つまりアノテーションが終わっているものに関して削除がなされない仕様で実装しています。
今後の課題
ここまで、アノテーション作業をより良いものにするという目的解決にあたり、AutoLabeling機能周りの開発に取り組みましたが、本インターンで解決できなかった課題もいくつかあります。特にアノテーション作業を行うときに、現在の仕様だとAutoLabeling機能によってラベル付けされたものなのか、アノテーターが新たにつけたラベルなのかの区別がわかりにくいという点が大きな課題だと考えられます。
例えば、以下の画像の赤枠で括ったラベルはモデルには存在しないラベルであり、それ以外はAutoLabeling機能によって使用するモデルに存在するラベルになっていますが、現在見分けはつきません。
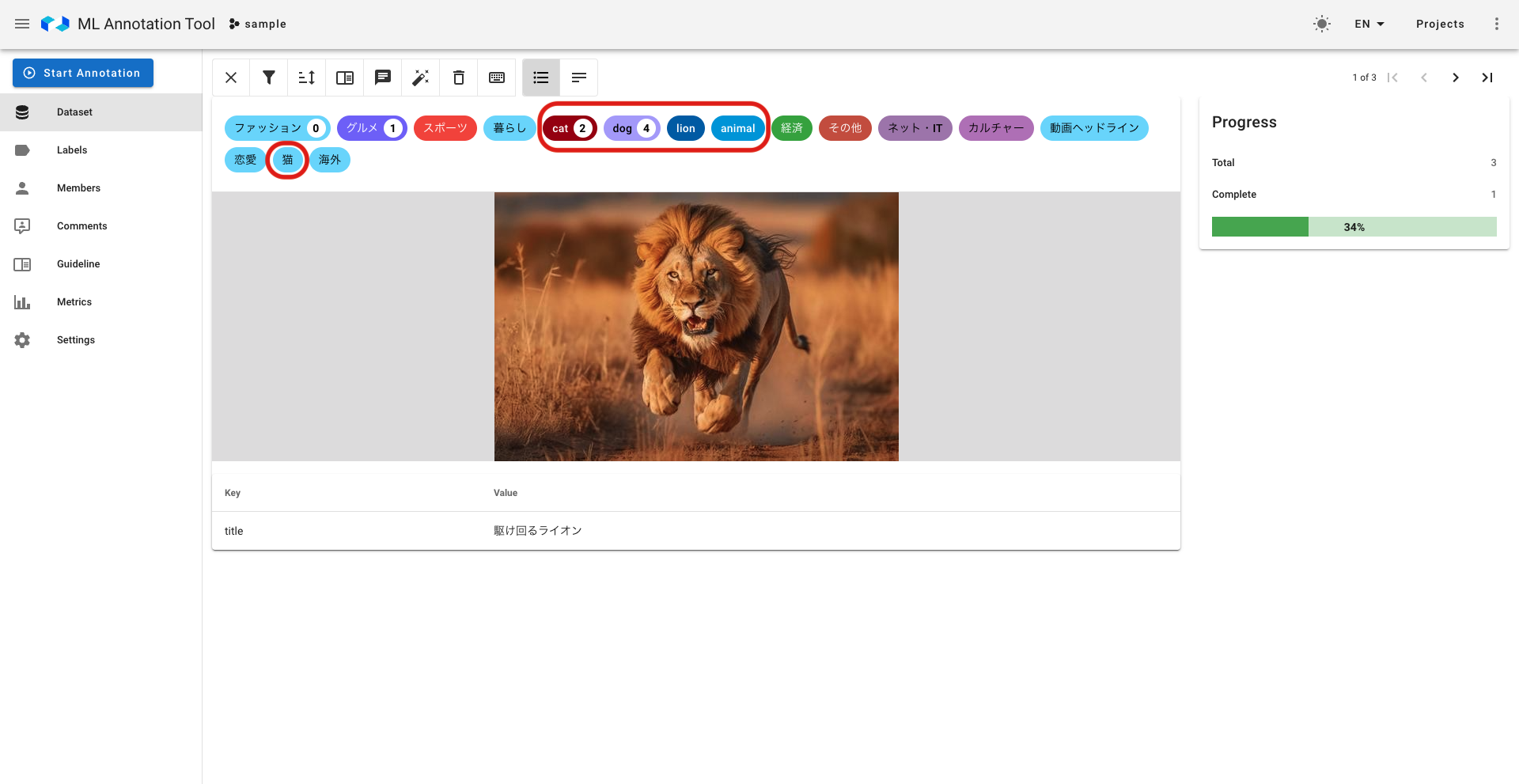
AutoLabeling機能によってラベル付けされたものなのか、アノテーターが新たにつけたラベルなのかの区別が可能になると、アノテーション作業によりどの程度AutoLabelingと人のラベリングが違うかについて評価することができ、モデルの精度向上や評価にも繋げることが可能です。また、新たに今回学習させるラベルは何なのかという点についてもわかりやすくなり、より運用しやすくなるというメリットもあります。
しかし、この課題については他部署も含めた運用体制や連携について協議する必要があり、今回いただいた期間では要件の定義や実装含め解決することが難しく、今後は十分な協議の上ラベル区別について実装を進めるとより良いユーザー体験を提供することができると考えられます。
おわりに
本記事では、ML Annotation toolにおけるAutoLabeling機能を開発するにあたり、その背景や課題、課題を解決するような実装について記述しました。本開発は既存のOSSを、多くの部署が関わる社内の運用フローに合わせた形でより良い形で拡張していく点が難しくも楽しい開発でした。この難しさや楽しさが本記事で伝われば幸いです。
本インターンでは、実装能力に加えて人への伝え方や問題の発見・解決能力の重要さを実感し、向上するような充実した6週間でした。実装だけでなく様々なミーティングや交流会や面談、勉強会に参加させていただき、LINEならではのインフラに触れたり、企業の雰囲気やエンジニアとして働くとはどういうことなのかについて深く知ることができ、とても貴重な体験をさせていただくことができました。この6週間で学んだ経験を今後の開発及び人生に活かしていきたいと思います。
毎日朝MTGの時間をいただき、具体的な実装やその方向性について様々な意見をいただいたりコードレビューをいただいたメンターの方、また様々な面でサポートいただいたマネージャーの方々、開発チームのメンバーの方々をはじめとする全ての方々に心よりお礼申し上げます、大変お世話になりました。
ぜひ皆さんも様々な学びや実りのある本インターンに参加してみてください。ここまで読んでくださりありがとうございました。