
DataLabsのSpeech teamに所属している小松です。環境音認識に関する基礎研究を行っています。環境音認識とは我々の身の回りで起こる多種多様な音、たとえば咳や話し声、物音などを機械に自動的に検出・認識させる技術です。この技術は音に関する分野の中で最もホットで急成長しているトピックの一つであり、環境音を専門に扱う国際コンペティション/ワークショップ、DCASEも毎年開催されています。
そのコンペティション部門であるDCASE2020 Challengeのtask 4に、LINEは昨年度のインターン成果 [1] を主軸にした名古屋大学、ジョンズ・ホプキンス大学との合同チームで参加し、世界1位を獲得することができました。本記事ではまず環境音認識の概要について簡単に説明し、我々が参加したコンペティションのタスク、そして我々が1位を獲得した用いた方式について紹介いたします。
環境音認識について
環境音認識とは、どんな状況でどんな音が発生しているかを認識・理解する技術です。具体的には、音響信号を入力としてどのタイミングで何の音が発生したかを出力する分類問題となります(図1)。

今回のコンペティションDCASE2020 Challenge task4では、YouTube上の動画の音で構成されたデータセットを対象として、家庭内で発生する犬の鳴き声や子供の泣き声・話し声など10クラスの分類性能を競いました。
それらの音はもちろんユーザが投稿した動画の音ですので、複数の環境音が同時に発生していたり、認識対象ではない不必要な雑音を含んでいたり、さまざまな実環境の特性を持ち問題を複雑化させています。
音データは時間波形のままだと扱うのが難しいため、多くの場合は周波数解析(短時間フーリエ変換など)によりスペクトログラムという時間×周波数の二次元表現へ変換してから扱います。

スペクトログラムの例を図2に示します。図2からもわかるとおり、各環境音ごとに異なる周波数の特徴(主に縦方向の模様)を持つことが見て取れます。つまり音データは周波数解析を行うことでより画像のように扱えるようになります。
一方で、音データが画像データと比べて異なる性質の一つとして、音データにとって時間情報が重要なことが挙げられます。つまりスペクトログラムの局所的な特徴、模様を捉えるだけではなく、大域的な時間変化の情報もうまく扱う必要があります。
そのため、環境音認識で現在最も採用されている方式として Convolutional Neural Network(CNN)とRecurrent Neural Network(RNN)を組み合わせた Convolutional Recurrent Neural Network(CRNN)があります (図3)。
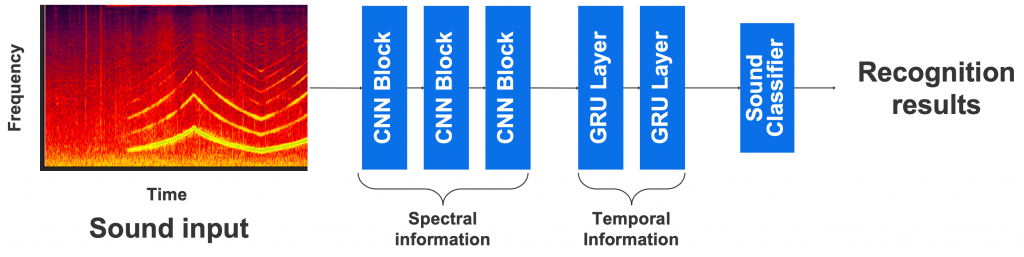
この方式は、まずスペクトログラムの局所的な情報をCNNで捉え、大域的な時間変化には後段のRNNによって対応します。CRNNに基づく方式が高い認識性能を示すことは多くの論文で報告されており、実際、今回のDCASE2020 Challenge task4においても、ほとんどすべてのチームがこの方式を採用していました。
参加したタスクについて
今回我々が参加したのは、DCASE2020 Challengeのtask4、"Sound Event Detection and Separation in Domestic Environments" というタスクです。

このタスクは家庭内で発生する犬の鳴き声や子供の泣き声、話し声など10クラスの分類性能を競うタスクです。
オープンなデータとしてYouTubue上の動画の音で構成されたデータセットが与えられ、各チームはそのデータセットを用いていかに性能の高い分類モデルを学習できるか競います。また、学習済みモデルや外部データの利用は禁止されています。
これらは実際にデータセットに含まれる音の例です。「ピアノの音」と「犬の鳴き声」や「音楽」「赤ちゃんの泣き声」「人の話し声」などが同時に発生しており、それらの音をうまく分類する必要があります。
このタスクのメインのテーマとして、弱ラベル学習があります(図4)。

通常、環境音認識のための学習データには、音データの中でどの音がどのタイミングで発生しているかというタイムスタンプ情報がラベルとして必要となります。
しかしながら、そうしたラベルの付与は実際にすべての音を聞く必要があり非常にコストがかかります(自分でやってみたところ、1分の音のラベル付けに10分かかりました)。
そこで注目されているのが、音データの中に何の音が含まれるかはわかるがどのタイミングでなっているかはわからない、というゆるいラベルを用いた学習、弱ラベル学習です。
もちろんこの弱ラベルには目的の環境音が発生している時間区間以外の情報、雑音や他の検出対象の音も含まれているため、どのタイミングで環境音が発生しているのかわからない中で本当に必要な情報のみをうまくとりだす必要がある、非常に難しい問題になります。
またこのタスクにおける弱ラベル学習以外の重要な課題として、弱ラベルどころか何もラベルがついていない膨大なデータ(タスク用データセットとして提供されています)をうまく学習に用いるための方法や、さまざまな特徴やノイズを含んだ多様な音にロバストなモデルを学習する必要があります。
我々の方式について
今回のタスクにむけて我々のチームは、2019年インターンにおいて開発した self-attentionに基づく環境音認識モデルをベース [1] にして複数の技術を取り入れた新たな方式を用いました。
本記事ではその中でも大きなポイントとなる
(1)認識モデルの構造、(2)ラベルが無いデータの活用、(3)多様な音にロバストなモデル
という3つの視点から方式を紹介します。
(1) 認識モデルの構造
我々の方式は、NLPや音声認識など様々な分野で高い性能を示しているTransformer(self-attention)に弱ラベル学習に対応できるよう新たな構造を組み込んだ環境音認識モデルです。
Transformerはグローバルな特徴をより効果的に捉えることができます。弱ラベル学習のための特別なトークンを新たな入力として用いてTransformerの中でうまく弱ラベルを扱うための方式を開発しました。
この方式はTransformerを環境音認識に初めて適用した方式となっており、実際参加者のうちほぼすべてのチームがCRNNを用いていた中、新しい構造のネットワークを用いたのは我々のみでした。
この方式は2019年のインターンシップにおいて開発を行ったもので、音声・音響・信号処理系トップカンファレンスICASSP2020へ採択されるなど有効性についてはすでに示されています。
詳細については下記のブログ記事をご覧ください。
【インターンレポート】環境音認識のための弱ラベル学習に関する研究
我々は今回、その方式はさらに発展させ、convolution-augmented transformer (Conformer) [2] という方法を組み込みました(図5)。
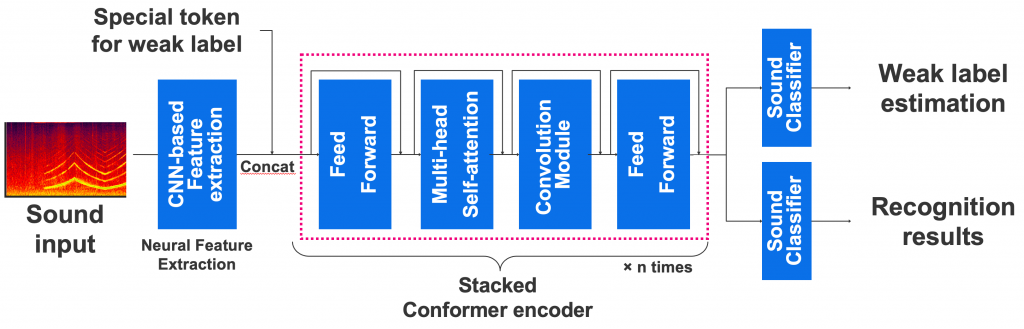
ConformerブロックはTransformerのself-attentionモジュールにConvolutionモジュールを組み込み、さらに2つのfeed forwardレイヤーで挟んでいます。
Conformerは、Transformerよりもローカルの特徴をより捉えることのできるとされており、実際音声認識ではTransformerよりも優れた性能を示しています。
(2) ラベルが無いデータの活用
ラベルが無いデータを用いた学習については、mean teacher [3] という学習方式を適用しました(図6)。
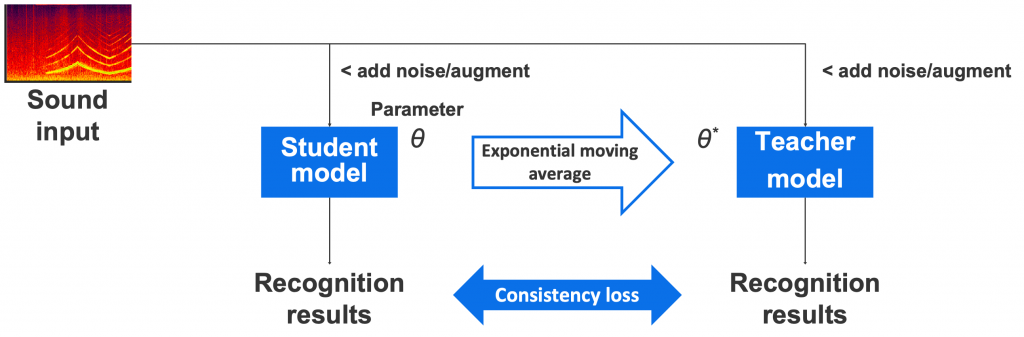
この方式は同じ構造を持つstudentモデルとteacherモデルを用意し、1つのデータに対しそれぞれ別々のノイズやdata augmentationを加えて入力します。
そうして得られたそれぞれの出力の一致度を計算し、その値が高くなるようにstudentモデルのパラメータを更新します。teacherモデルのパラメータはstudentモデルの各更新ごとの指数移動平均によって計算されます。指数移動平均を使うことで、studentとteacherで共通のパラメータを持つ従来法などよりも正確で性能の高いモデルが学習できると言われています。このmean teacherを用いることで、ノイズに対するロバスト性を高めるとともに、ラベルを持たないデータも学習データとして活用することができます。
(3) 多様な音にロバストなモデル
ロバスト性を高めるために、我々は4種類のデータオーグメンテーション方法を用いました(図7)。
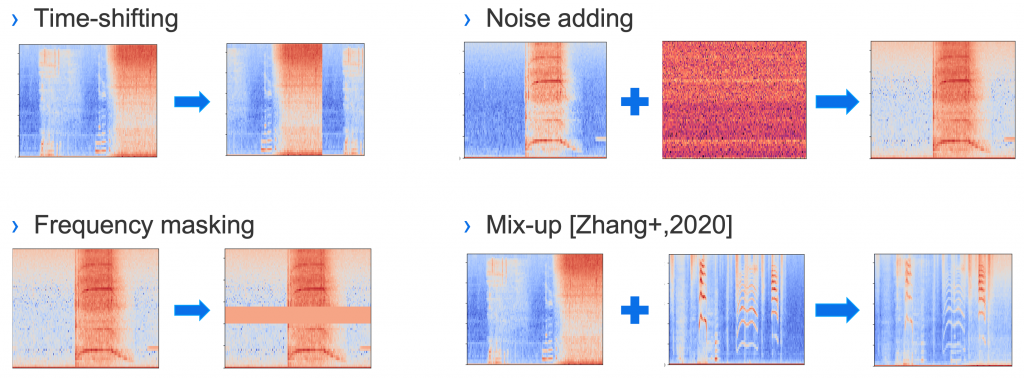
- Time shifting: スペクトログラムを時間軸方向にシフトすることで、音の発生タイミングを人工的に変化させる。元々のデータにおける音の発生タイミングをバイアスとして学習することを防ぐ効果を見込んでいます。
- Noise adding: ノイズを学習データに重畳する方法です。今回はガウス雑音のみを用いました。
- Frequency masking: スペクトログラムの周波数情報をマスキングすることで、あえて周波数情報が欠損したデータを作る方法です。現実のデータは他の音のかさなりの影響などで周波数情報が欠損する可能性があるため、その状況を人工的に模擬しています。
- Mix-up: 画像分野で広く用いられているmix-upという方式で、ふたつのスペクトログラムを足し合わせてあらたな学習データを作ります。複数の音のかさなりへのロバスト性向上などを期待しています。
今回紹介した3つのポイント以外にも、ネットワークパラメータによる性能の変化や、モデルアンサンブルなど性能向上のためにさまざまな実験を行いました。
技術詳細や実験結果、各項目がどれほど性能に寄与したかについては、今回の方式の論文 [4] をご覧ください。
結果
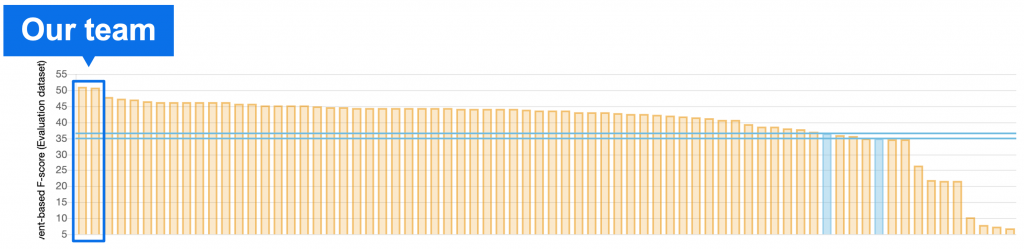
DCASE2020 Challengeのtask4には、世界各地の研究機関から21のチーム、72のシステムが参加し、その中で我々のチームが世界一位を獲得することができました。
主催者が提供しているベースラインシステムに対して14.6%、2位のチームに3.3%上回る性能を示しており、とくに2位以下は僅差であったのに対して我々は頭ひとつ抜けた性能を示すことができました。
なお、今回のコンペティションに用いたモデルを再現するための実装に関しては、音声認識に関するツールキットESPnetを用いてオープンソース化する予定です。よろしければみなさまチェックしてみてください。
ESPnet: end-to-end speech processing toolkit
おわりに
本記事では、環境音認識に関する国際コンペティションDCASE2020 Challenge task4の概要と、そこに参加し世界一位を獲得した方式について紹介させていただきました。
説明を簡略化した部分もありますので、詳細については今回の方式についての論文 [1,4] も合わせてご覧ください。
DCASEでは、オープンなデータセットやベースライン方式を公開し、誰もが環境音認識に関する研究・開発に挑戦しやすい枠組みを作っています。
本記事で環境音認識に対して興味を持たれた方いらっしゃいましたらぜひ挑戦してみてください。
なお11月25-27日に開催されるLINE DEVELOPER DAY 2020では、LINEの持つ音声・音響技術について複数のセッションを予定しています。
環境音認識セッションでは、本記事では紹介できなかった発展的な技術なども紹介いたしますので、ご興味を持たれた方は参加登録の上ぜひご覧ください。
- 11月25日 14:20-14:50 Parallel WaveGAN: GPUを利用した高速かつ高品質な音声合成
- 11月25日 14:50-15:20 CLOVA Speech: 次世代音声認識のある生活
- 11月25日 15:30-16:00 機械学習を用いた環境音の認識
- 11月25日 16:00-16:30 スムーズなコミュニケーションのための教師なし音声分離
- 11月25日 16:40-17:20 ここまで来た音声技術・今後の展望
参考文献
- [1] Miyazaki, et.al., "WEAKLY-SUPERVISED SOUND EVENT DETECTION WITH SELF-ATTENTION," in ICASSP, 2020
- [2] Gulati, et.al., "Conformer: Convolution-augmented Transformer for Speech Recognition," in INTERSPEECH, 2020
- [3] Tarvainen et al., "Mean teachers are better role models: Weight-averaged consistency targets improve semi-supervised deep learning results." in NIPS 2017
- [4] Miyazaki, et.al., "Conformer-based sound event detection with semi-supervised learning and data augmentation," in DCASE, 2020 [pdf]