
はじめまして、宮崎晃一です。2019年夏の2ヶ月間、LINEのResearch Labsにて研究インターンシップに参加しました。「環境音認識のための弱ラベル学習」をトピックとして、2ヶ月間で新たな手法の開発から実験、論文執筆・学会投稿までを行うことができました。インターン期間中の成果をまとめた論文は音声・音響信号処理のフラッグシップカンファレンスであるICASSP2020 ((International Conference on Acoustics, Speech, and Signal Processing)) にて採択されており、発表論文とスライドはこちらからご覧いただけます。
K. Miyazaki et al., Weakly-Supervised Sound Event Detection with Self-Attention, ICASSP2020
https://ieeexplore.ieee.org/document/9053609
https://www.slideshare.net/NU_I_TODALAB/weaklysupervised-sound-event-detection-with-selfattention/NU_I_TODALAB/weaklysupervised-sound-event-detection-with-selfattention
今回のレポートではその際に行った研究内容について報告いたします。
※なお、ICASSP2020 は 5月4日〜8日にかけてスペイン・バルセロナで開催予定でしたが、COVID-19の世界的な感染拡大の影響から、バーチャルカンファレンスに変更となり、私もビデオで講演します。レジストレーションをすればどなたでも参加できますのでぜひレジストレーションして聞きに来てください!
背景
インターンのテーマは「環境音認識のための弱ラベル学習」でした。これは、環境音の認識モデルを学習するためのコストをできるかぎり少なくするための研究です。
環境音認識は音から周囲の状況を認識する技術です。対象となる環境音は想定するアプリケーションによってさまざまですが、例えば赤ちゃんの泣き声を認識する見守りシステム、悲鳴や叫び声などの危険な音を対象とした監視システムなどへの応用が検討されています。
環境音認識モデルを構築するには、音声認識や画像認識と同様に教師あり学習に基づく手法が一般的です。教師あり学習とは、学習させるデータとそれに対応する正解ラベルのペアを教師データとして用いる機械学習手法です。近年の機械学習ブームの火付け役としてビッグデータと呼ばれる大量の教師データを用いた汎化性能の向上が挙げられます。
録音・記録デバイスの普及によってデータを収集することは以前に比べてとても簡単になりました。しかし、対応する正解ラベルの付与は依然として人力によるところが大きく、大量の教師データを用意するには多くのコストがかかります。何十時間とある音声データに対して、何秒から何秒までミリ秒単位でどんな環境音が発生しているか記録することを考えると、それがとても大変な作業であることがわかると思います。
そのような状況に対処するために、少量の教師データを用いて学習を行う手法や、部分的にラベル付けされた教師データ(弱ラベルデータ)を用いて学習を行う手法が検討されています。
環境音認識における弱ラベルデータとは、環境音の発生タイミングや発生回数などの情報を考慮せず、データに特定の環境音が含まれているかどうかのみラベル付けされたものを指します(図1)。弱ラベルデータには時間情報を含める必要はないため、ラベル付けのコストはぐっと下がります。
弱ラベルデータは収集コストの問題をある程度解決しますが、環境音発生の時間情報が含まれていないため、そのままでは教師データとして利用できません。このようなデータを活用して認識精度を向上させるための学習方法は弱ラベル学習といいます。

時間情報を必要とする強ラベルに対して、
弱ラベルは各ファイルに含まれる環境音ラベルしか必要としません
問題設定
今回は屋内環境で発生する話し声や犬の鳴き声といった10種類の環境音を対象として環境音認識システムを構築します。弱ラベル学習に用いるデータはYouTube上から収集されたものを用いました。
このデータは環境音認識に関する国際的なコンペティション・ワークショップであるDCASE (http://dcase.community/) が提供しているもので、様々な研究機関が提案した方式との性能比較を同一のデータを用いて行うことができます。
このデータセットに実際に含まれるデータとしてはたとえば、
音楽と犬の鳴き声が含まれるもの(ラベル:dog, musicなどの弱ラベル)
赤ちゃんの泣き声と人の話し声、音楽が含まれるもの(baby cry, speech, musicなどの弱ラベル)
などがあります。
このような動画に含まれる複数音が入り混じった音データから、各環境音の特徴を学習し認識器を構築するのがこの研究の目的になります。
弱ラベルは音の発生タイミングの情報を持たないため、「この音がある」という情報だけを頼りに、どの環境音がいつ発生したかを判断する認識器を学習することは容易ではありません。
提案手法
今回のインターンシップでは環境音認識のためにself-attentionを用いた弱ラベル学習の新しい方式を提案しました。
self-attentionは入力系列に対してどの位置の情報が重要であるか、入力データからネットワークを介して決定するものです。Transfomerによる機械翻訳が高い性能が報告され注目を集めるようになりました。自然言語処理分野に限らず音声認識など音響信号処理におけるさまざまなタスクで有効であることが報告されています。弱ラベル学習における「どの時間の情報が重要であるかわからない」という問題に対して、我々はself-attentionの特徴である「どの位置の情報が重要であるか捉えることができる」ことが活用できると着目し、手法の開発を行いました。
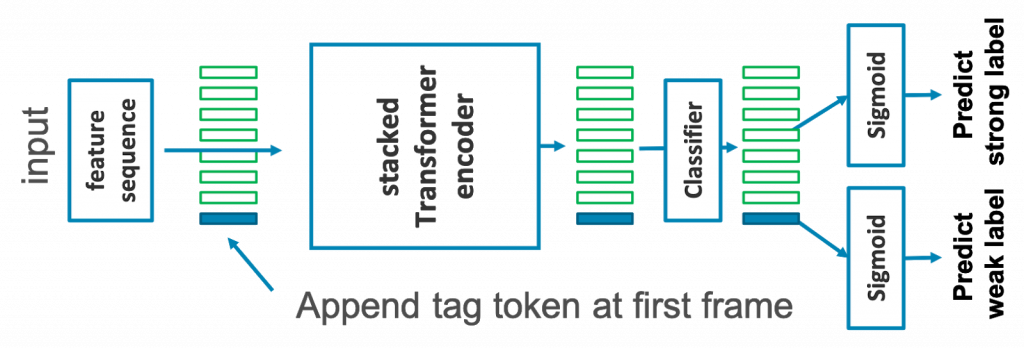
加えて、弱ラベル学習をself-attentionを用いて効果的に行うために、新たに独自のタグトークンの導入しました(図2)。タグトークンは、入力する特徴系列の先頭に追加し、ネットワークを通して系列全体の情報を集約するように振る舞います。従来は弱ラベル情報を出力に近い層でしか活用できていませんでしたが、このタグトークンと複数積み重ねたself-attentionブロックによって、弱ラベルの情報と時間フレームの予測をブロックごとに活用することができるようになります。
提案法の性能を表1に示します。環境音認識で一般的な評価指標、F1-scoreにおいて、従来強力なベースラインとされてきたCRNNを上回る性能を確認できました。
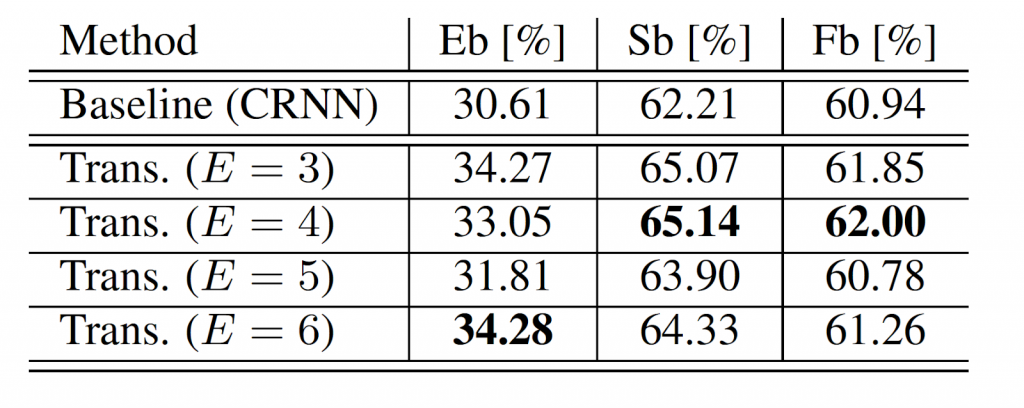
Eb,Sb, Fbはそれぞれイベントベース、セグメントベース、フレームベースでのF1-scoreを表す
インターンの生活について
インターン期間中は、会社から20分程度のところにあるマンスリーマンションを手配していただき、就業時間も10時から18時半であったため、満員電車とは無縁の生活をおくることができました。
就業時間後には、メンターの方が他のインターンの仲間と一緒によく晩ご飯へ連れて行ってくださいました。インターン期間中は真夏でとても暑かったこともあり、とても楽しくおいしいビールをいただけました。東京はあまり馴染みがなかったのため、東京のオフィス街のお店は新鮮で、日中にしっかり仕事をして退勤したあとに道端で飲むビール(図3)は格別でした。

(メンターの方々やインターン仲間と
新橋の立ち飲み屋さんにて)
まとめ
本記事では、インターンシップで取り組んだ研究内容について紹介させていただきました。社員の方々はみんなとても親切で、忙しいにも関わらずとても頻繁に議論の場を設けていただきました。2ヶ月という短い期間で研究成果をまとめられたのはメンターのおかげだととても感謝しています。
研究インターンシップはテーマ設定からアイデアまで自由に研究することができ、研究のための環境もとても充実しています。また就業時間後にはよく飲みに連れて行っていただきました。とても楽しいあっという間の2ヶ月間でした。興味のある方はぜひ次回のLINEのインターンシップに応募してみてください。
[1] K. Miyazaki, T. Komatsu, T. Hayashi, S. Watanabe, T. Toda, K. Takeda, “Weakly-supervised sound event detection with self-attention,” in IEEE Int. Conf. Acoust., Speech, Signal Process. (ICASSP), 2020.