
こんにちは。Data Platform室 Data Solutionsチームの片岡と北川です。
Data Platform室では、約400ペタバイトのデータ分析基盤を運用しております。このData Platformは、「Information Universe」(以下、IU) と呼ばれており、LINEの様々なアプリケーションから生成されるデータをLINE社員(以下、ユーザ)が活用できるように、データの収集、処理、分析、可視化を提供しています。我々が所属するData Solutionsチームでは、IUのプロダクトのユーザへのデリバリー、IUの安定運用のためのエンジニアのサポート、ユーザからのテクニカルな質問への回答を担当しています。
今回は、その活動の一環として実施したSpark3.2.1アップグレードプロジェクトにおけるリソース効率の改善事例について紹介します。
Spark3.2.1アップグレードプロジェクト発足の背景
IUでは、IUのテーブルに対してデータ操作をする際には、SQLやScriptを利用してユーザ自身でDDL/DMLを実行してもらう運用としており、IU側で実行エンジンとツールを用意することで、ユーザは自分たちのサービスのワークロードに応じた実装方式を選択できるようになっています。以下はその一例です。
- 実行エンジン:
- Spark
- Trino(Presto)
- Hive
- MapReduce
- ツール:
- 内製Clientツール(以下、IU Client)
- 内製BIツール(以下、OASIS)
- 内製ETLツール
- Tableau / Datalore
IUにおけるSparkはIU ClientやOASIS、内製ETLツールなどから利用することができ、HiveやTrinoよりもリソース効率に優れていることからバッチ処理における利用が主となっています。元々IUのSparkのバージョンはSpark2.4.4だったのですが、大きく以下の3点の理由により、Spark3.2.1にアップグレードをすることになりました。
- Spark2.4が2021年5月にEOLを迎えたため、継続して利用した場合にセキュリティ面や互換性の懸念があり、バグ修正などが見込めなくなること
- Spark3.2には、Apache Icebergとのより優れたIntegrationなどの機能的なメリットがあること
- Spark3.2を導入することで、Adaptive Query Executionなどの機能により、リソース効率が改善されること
1はアップグレードをしない場合デメリットが発生するものであり、2と3はアップグレードをすることで享受できるメリットになります。また、このSpark3.2.1アップグレードのタイミングに合わせて、IU Webと呼ばれるIUのポータルサイト上にのAtlas Connectorを導入することで、Sparkジョブのパイプラインを簡単に確認できるようになり、ユーザの利便性を高めるData Lineageを実現できました。こちらについては、先日のTech Verse 2022や過去のLINE Engineering Blogでも紹介しているため、もし興味があればそちらをご覧ください。
今回のブログのメイントピックは3に関する部分であり、プロジェクト完了時点でバージョンのアップグレードに伴いリソース効率の改善がどの程度見られたかについてお話しいたします。
プロジェクト概要
Sparkのバージョンのアップグレードにあたり、IUプロダクト側・IUユーザ側で発生した作業は以下の通りです。
- IUプロダクト側:Spark Clusterだけでなく、各ツール内部で利用しているSpark Engineのアップグレードが必要
- Hadoop管理者:Spark Clusterのアップグレード、IU Clientの開発
- OASIS: Spark3.2.1のアップグレード
- IU Web: Data Lineageを実現するためのAtlas Connectorの導入
- IUユーザ側:使用中のツールに応じて、以下のアップグレード作業が必要
- IU Clientのアップグレード
- SQL/Scriptのアップグレード
1に関しては、一部2の期間と重複する形で2022年3月に開始し、2023年8月に完了しました。途中技術的な課題が発生しつつも、PoCからReleaseまで当初の予定通り進行しました。発生した課題については次の章で紹介いたします。
2に関しては、プロジェクト進行中にもユーザが増えたこともあり、当初の予定よりも延びたものの、最終的に全てのユーザにアップグレード対応をしていただくことができました。ユーザ側のアップグレードは2022年5月初に開始し、2022年9月にツール単位での大規模なSQL/Scriptのアップグレードが始まりました。アップグレード完了は当初2023年1月末までの予定でしたが、移行作業の中で発覚した課題などもあり、最終的に2023年5月末まで延長され、約1年間の活動となりました。
プロジェクト終了時の2023年5月時点で完全にSpark2のジョブがなくなり、記事執筆の2023/07/25時点では1日あたり約70000件のSpark3のジョブが実行されていることが確認できます。
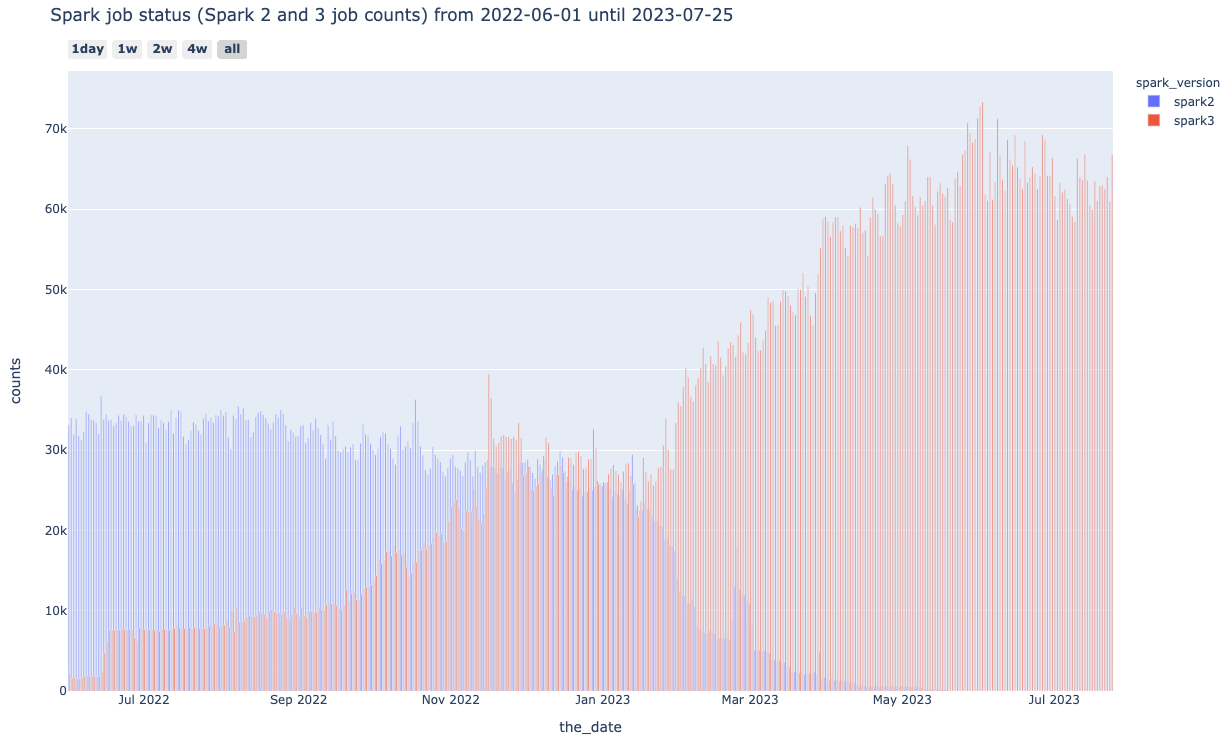
プロジェクト開始時と終了時の数値の比較は以下の通りです。
|
項目 |
開始時 |
終了時 |
上昇率 |
|---|---|---|---|
|
Unique Spark User Counts |
361 |
564 |
56.2% |
|
Spark Daily Job Counts |
30,746 |
61,090 |
98.7% |
|
Spark/Hive/MapReduce Job Counts |
103,689 |
153,206 |
44.7% |
|
YARN Worker Node |
3,643 |
3,643 |
0% |
つまり、同じワーカーノード数で、より多くのユーザのより多くのジョブを処理する必要がある状況になっていました。この利用状況はプロジェクト開始当初には意図していなかったものでした。
なお、YARNのWorker Nodeは、Spark/Hive/MapReduceのジョブにおいてYARNのリソース管理とジョブスケジューリング機能を使う際に利用されているため、Sparkだけでなく3種類のジョブの合計の比較も記載しています。
プロジェクト中に発生した技術的課題
LINE DataPlatformの大規模なワークロードならではの特性として、多くのユーザが各々のビジネス要件に合わせて様々な形態でジョブを実行するため、発生頻度の低い問題やコミュニティに報告されていない問題が発生することがよくあります。
実際、今回のプロジェクト期間中にも、大きな技術的課題が2件発生しました。これらの問題に対処するのは大変な労力を必要としましたが、ユーザ自身の調査により解決いただいたケースも多く、ノウハウをユーザに展開しながら前進することができました。
ここでは、発生した技術的課題とその解決策について紹介いたします。
Spark 3のHistory Server上に完了したアプリケーションのログが表示されない
- 課題の概要
- Spark History Server UIに、完了したSparkアプリケーションが表示されないという問題が発生しました。
-
このバグはコミュニティに報告されていないものであったため、LINE SparkエンジニアリングチームからSpark公式コミュニティに報告しました。
-
この問題は、Apache Jira上でSPARK-39083として追跡されています。
- 課題の背景
- Spark History Serverはevent log directoryを定期的にスキャンしてSparkアプリケーションの情報をKVStoreで管理しているが、たくさんのSparkアプリケーションが走ると、状態の更新時に競合が起こります。
- この競合状態が引き起こす問題として、完了したアプリケーションの情報がKVStoreから誤って削除されしまい、Spark History Server UIに表示されなくなるのが原因でした。
- 解決策
- 競合が起こらないように、アプリケーションの状態を更新する際に、ロックをかけることで解決しました。詳しくは、上記JIRAチケットを参照ください。
- テスト結果と結論
- 更新されたパッチはSparkエンジニアリングチームによりIUのSpark Clusterにデプロイされ、以降は例外が報告されなかったため、バグは修正されたと考えられます。
- 最終的に、このプルリクエストはSparkプロジェクトのmasterブランチ、3.3ブランチ、そして3.2ブランチにマージされました。
- このパッチの適用により、SparkのHistory Serverにおける競合状態が解消され、ユーザーはHistory ServerのWeb UIでより正確な情報を確認できるようになりました。
spark.sql.hive.convertMetastoreOrcオプションの挙動に関する課題
- 課題の概要
- Apache Sparkには、「spark.sql.hive.convertMetastoreOrc」という設定オプションがあり、HiveのORC形式のデータを内部最適化のためにSparkの独自フォーマットに変換するかどうかを指定することができます。
- IUではこのオプションのデフォルト値をfalseにしていましたが、アップグレードに伴い、パフォーマンス向上のためにSpark3.2.1のデフォルト値であるtrueに変更しました。
- 下記のような挙動の違い自体は認識しており、ユーザに周知もしていたのですが、上記OptionをTrueにした場合に複数のSparkアプリケーションが同じTableの異なるpartitionに同時に書き込めないという問題がありました。
- サブディレクトリが読めなくなる: https://issues.apache.org/jira/browse/SPARK-28098
- dynamic partitioningを使った場合に必要以上に多くのHive partitionの情報をHMSから取得する:https://issues.apache.org/jira/browse/SPARK-38230
- その結果、一部のユーザのジョブ実行の結果、不完全なデータが生成されてしまったり、ジョブ自体がエラーになってしまう事象が発生しました。
- 原因
- 下記で議論されているため、詳細については下記をご確認ください
- 下記で議論されているため、詳細については下記をご確認ください
- 解決策
- 以下のいずれかを適用することで解決できます
- spark.sql.hive.convertMetastoreOrcをfalseにする
- spark.sql.hive.convertMetastoreOrcをtrueのままにする場合は、以下2点を実施する
- spark.sql.sources.partitionOverwriteModeオプションをdynamicにする
- INSERT時にSELECTしたデータから動的にpartitioningが可能なSQLを記述する。例)INSERT OVERWRITE ... PARTITION (dt, hour)
- 以下のいずれかを適用することで解決できます
- 対応方針
- 今回発生した全ての問題が既知の問題ではありましたが、特定の条件下で起こる問題であり、かつその発生頻度は非常にランダムであったため、再現が難しく調査が難航しました。
- 最終的に、一部のユーザだけが直面する問題であることが分かったため、デフォルト値はtrueのままにして、問題がある場合にfalseにしてもらうよう、案内する方針としました。
評価方法
続いて評価において利用したメトリクス・データ・評価のアプローチについてお伝えします。
メトリクス
アップグレードに伴うリソース効率の改善を評価するために使用したメトリクスと解釈方法については以下の通りです。いずれの指標も、分散処理環境における評価によく使われるものを採用しました。
ジョブ実行には深夜・早朝帯が多かったり、土日は少ないなどの時間帯・曜日のトレンドがあったため、日次の集計ではなく、単位時間あたりの合計をメトリクスとして計算しました。
|
メトリクス |
説明 |
解釈方法 |
解釈理由 |
|---|---|---|---|
|
Aggregated vCore |
単位時間あたりのクラスター内の全てのワーカーノードにおける利用中のvCore(仮想コア)数の合計 |
少ないほどよい |
マシンごとに処理能力が異なるため、集約した合計値を利用。vCoreの合計値が少ない=各ジョブの実行に必要なリソースが少ないと考えられるため |
|
Aggregated Memory |
単位時間あたりのクラスター内の全てのワーカーノードにおける利用中のメモリ容量の合計 |
少ないほどよい |
同上 |
|
Windowed Job Counts |
単位時間あたりのジョブの数 |
少ないほどよい |
単位時間あたりのジョブの数が少ないということはジョブ実行効率が優れており、各ジョブの実行時間の平均が短いと考えられるため |
- 十分な数のサンプルがあり、外れ値の存在が確認できたため、Aggregated vCore/Aggregated Memoryの評価には、98パーセンタイルの値を使用しました。
- 1つのジョブにつき数件のログが出力されることから、期間全体で合計2.23×10^12件のログが存在していました。
メトリクスの取得・可視化方法
IUではYarn ResourceManagerのApplication Summary Logをテーブルとして保存しており、このLogには各ジョブの実行時間やアプリケーション名、使用リソース量などが含まれていましたが、あるジョブがどのバージョンのSparkで動作したかを示すログは含まれていませんでした。一方で、アップグレード状況を追跡するためには、Spark2とSpark3それぞれバージョンを区別できるログの情報を取得する必要がありました。加えて、プロジェクト期間中の全作業ログを確認及び比較する必要があったため、十分なリテンション期間を持つログが必要でした。バージョン情報はSpark History ServerのREST APIやSparkのイベントログからも取得できるのですが、IUでは、HDFSのsmall file問題を避けるためにリテンションを短く7日に設定していています。そこで、以下の点に着目しHDFSのfsimageを保存したテーブルの情報を使うことにしました。YARNのApplication Summary Logに加えて、Application IDで突合することでバージョン別のジョブのメトリクスを作成しました。
- ユーザーのSparkジョブのイベントログが、バージョンとアプリケーション単位でHDFS上に保存されている*1
- HDFSのfsimageはHiveテーブルに保存している
*1: ログのHDFSパスはHistory Serverで使われ、SparkのバージョンごとにHistory Serverが別に存在するため、このような設計としました。設定されたログの構造によっては、私たちが採用したこの方式が適用できない可能性もありますので、その点をご了承ください。当初、我々の設計はバージョン別のログ取得を目指したものではありませんでしたが、作業状況の確認には非常に有用でした。
メトリクスはTrinoを使って集計を行いました。その結果、前述のグラフのような形式でSparkアップグレード状況の追跡と、移行情報の管理が可能になりました。
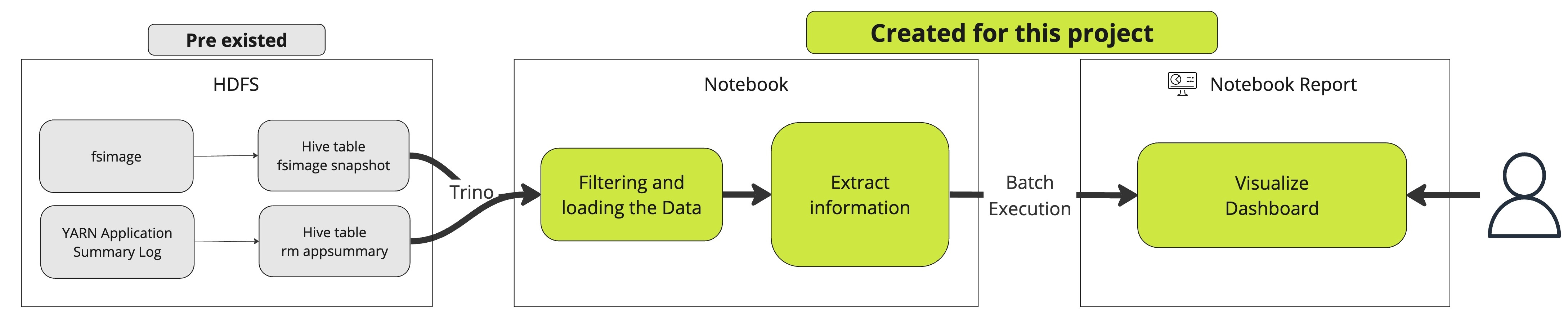
また、解決すべき別の課題として、各ログデータに若干の不一致があったことが挙げられます。fsimage_logテーブルのパーティションは日次で作成されていましたが、パーティションごとのSparkログの保存期間は7日とされていました。しかし、データを詳細に確認すると、多くのパーティションの初日と7日目のデータが欠損していることに気づきました。この問題を解決しデータの完全性を保証するため、5日ごとのパーティションを取得し、5日間分のデータを連続して取得する新たな方針を採用しました。この不一致の主な原因は、ログデータの集計タイミングおよび日を跨いで実行されるような長期実行タスクによるものと考えられます。
結果については、レポート作成・共有可能なNotebook Solutionを用い、グラフはPlotlyを利用して可視化しました。使用したものの中から、いくつかの例を以下に示します。
Spark 2
| Total usage trend |
|
|---|---|
| Usage trend by username |
|
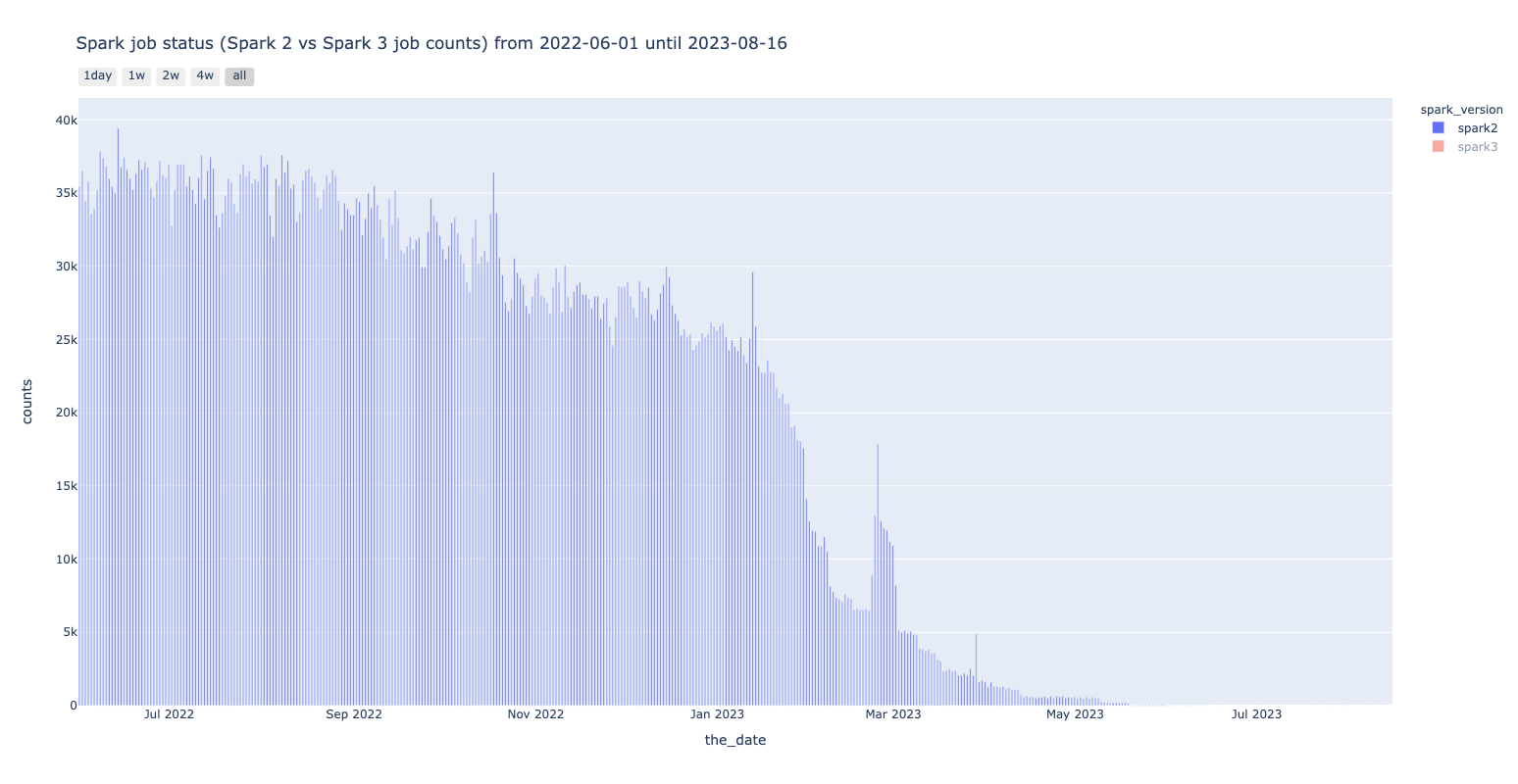
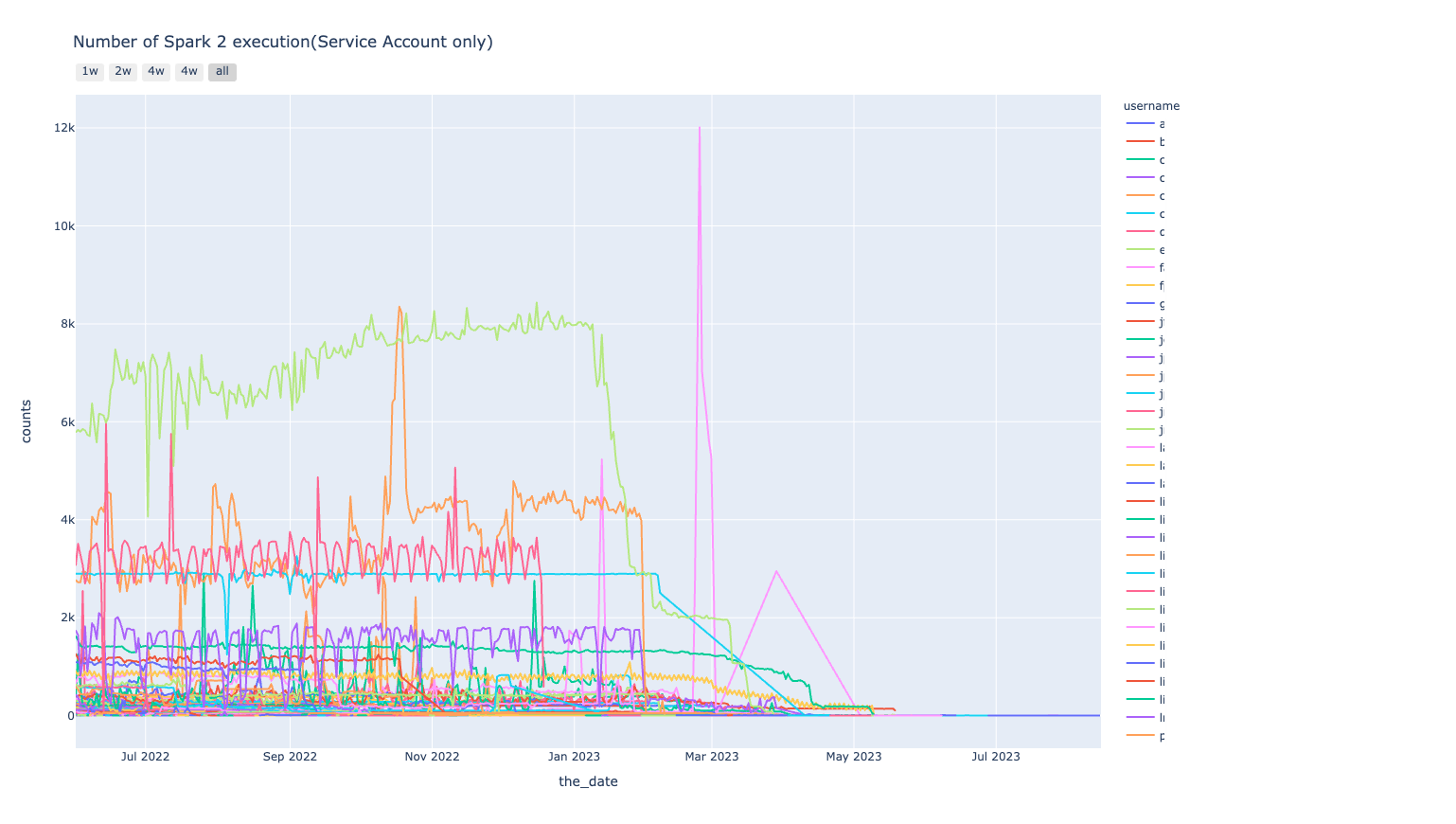
Spark 3
| Usage Percentage |
|
|---|---|
| Total usage trend |
|
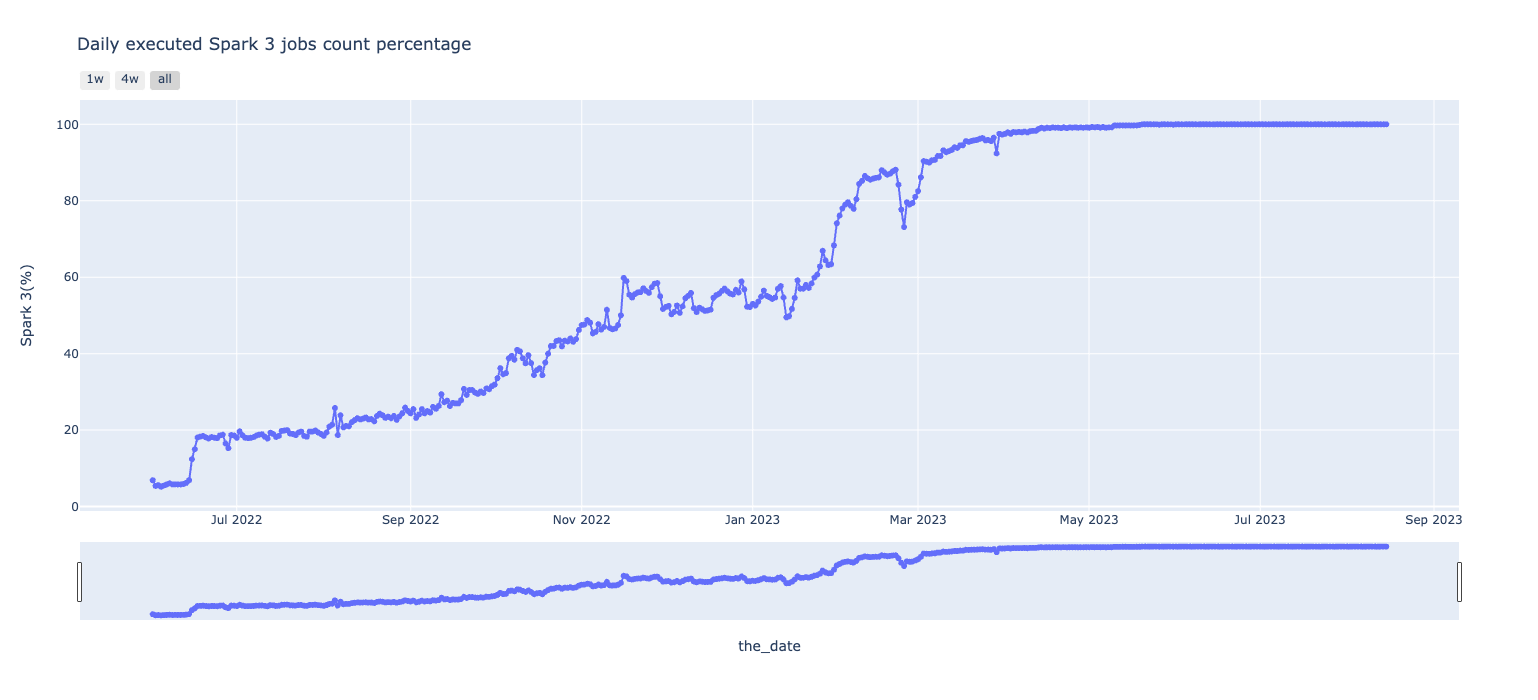
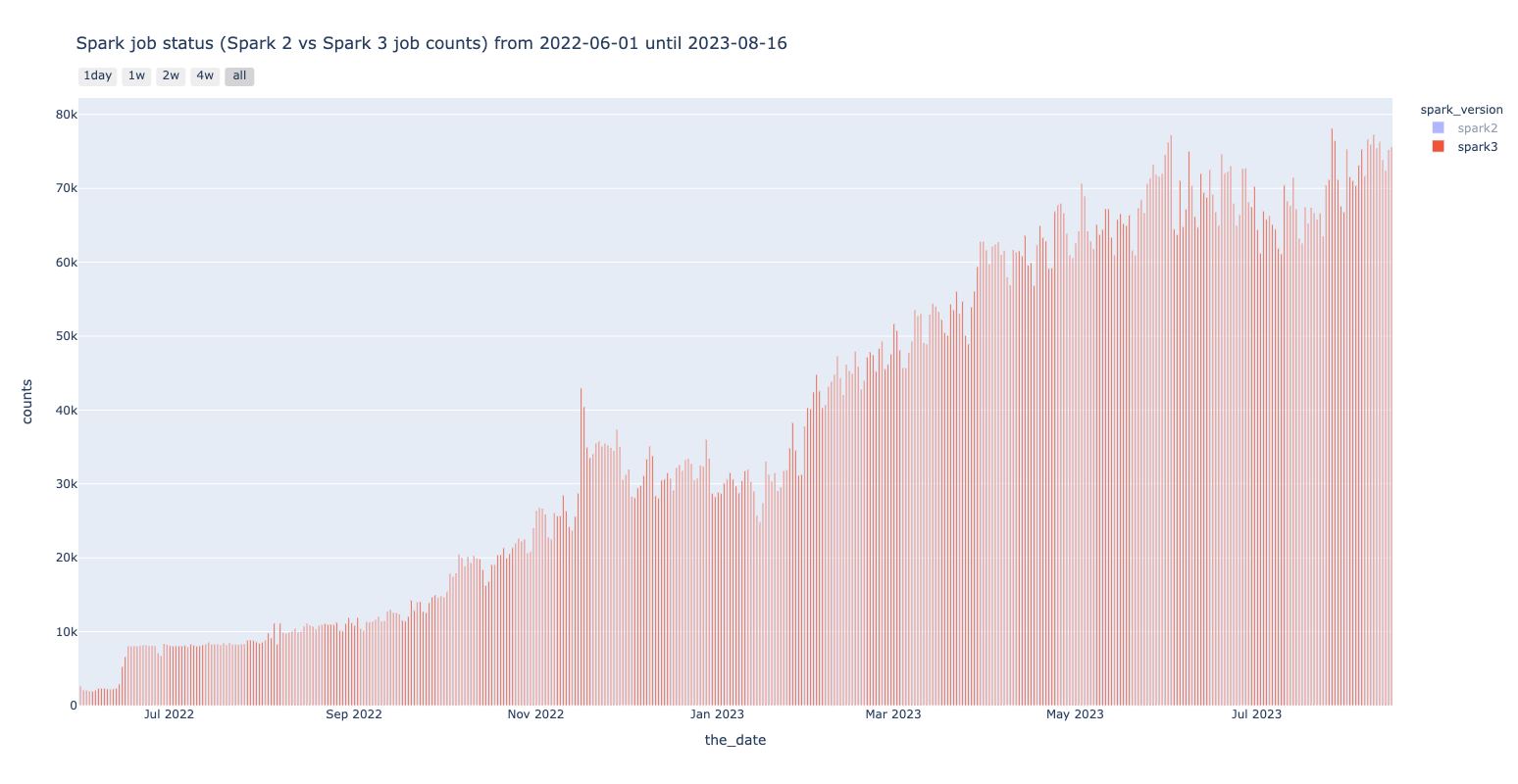
以下には使用したコードのサンプルを示します。
# Spark 3 upgrade trend
# Importing libraries
import pandas as pd
import plotly.express as px
# Define date variables
current_date = pd.Timestamp.today().date().strftime("%Y-%m-%d")
initial_date = "2022-06-01"
### To create DataFrame for display charts ###
def extend_query_params(query_params, final_date=current_date):
"""
Expands the date range. If the provided date(s) is not present, an additional interval(tuple elements) is added to the list.
Args:
query_params (list): A list of date intervals, where each item is a triplet of dates in a .
final_date (str): The determined end date.
Returns:
list: A revised list of date intervals.(Elements will be tuple)
"""
last_interval_date = query_params[-1][2]
if last_interval_date != final_date:
query_params.append((final_date, last_interval_date, final_date))
return query_params
def create_query_param(input_date):
"""
Extracts and formats a range of dates based on the provided date.
Args:
input_date (datetime): A specific date.
Returns:
tuple: A tuple containing three strings, each representing the partition date, the starting date of the interval, and the ending date of the interval.
"""
start_interval_date = (input_date - pd.Timedelta(6, "d")).date()
end_interval_date = (input_date - pd.Timedelta(1, "d")).date()
return tuple(
x.strftime("%Y-%m-%d")
for x in [input_date, start_interval_date, end_interval_date]
)
def generate_dataframe(start_date, end_date=current_date):
"""
Create pandas DataFrames of spark log data
get_presto_auth <- A function to get internal presto auth
Args:
start_date (str): The start date of the data range.
end_date(str, optional): The end date of the data range.
Returns:
tuple: A tuple of three pandas DataFrames:
* `df_total_logs`: A DataFrame of the total number of spark logs per day, by spark versions.
* `df_logs_by_user`: A DataFrame of the number of spark logs per day, spark version for the past 28 days by execution users.
* `df_spark3_percentage`: A DataFrame of the number of spark logs per day, spark version, and the percentage of Spark 3 logs.
"""
def adjust_start_date(start_date):
"""Adjusts the start date"""
return (
(pd.to_datetime(start_date) + pd.Timedelta("6D"))
.date()
.strftime("%Y-%m-%d")
)
query_params = extend_query_params(
[
create_query_param(i)
for i in pd.date_range(adjust_start_date(start_date), end_date, freq="5d")
],
end_date,
)
df = pd.concat(
[
pd.read_sql(
"""
SELECT path, modificationtime, username
FROM fsimage_log
WHERE path like '/log/spark%' and dt = '{}' and modificationtime between '{}' and '{}'
""".format(
*d
),
get_presto_auth(),
)
for d in query_params
]
)
df["spark_version"] = (
df["path"]
.str.split("/")
.apply(lambda x: x[2] if x[2] == "spark3" else "spark2")
)
df["log_date"] = pd.to_datetime(df["modificationtime"]).dt.date
df_grouped = (
df.groupby(["log_date", "spark_version", "username"])["modificationtime"]
.count()
.rename("counts")
.reset_index()
)
df_total_logs = (
df_grouped.groupby(["log_date", "spark_version"])["counts"]
.sum()
.rename("counts")
.reset_index()
)
df_logs_by_user = df_grouped[
df_grouped["log_date"]
> (pd.to_datetime(end_date) - pd.Timedelta(28, "d")).date()
]
df_spark3_percentage = (
df_grouped.groupby(["log_date", "spark_version"])["counts"]
.sum()
.reset_index()
.pivot_table(
index="log_date",
columns="spark_version",
values="counts",
aggfunc="sum",
margins=True,
margins_name="Total",
)
.reset_index()
.iloc[:-1]
)
df_spark3_percentage["Spark 3(%)"] = round(
df_spark3_percentage["spark3"] / df_spark3_percentage["Total"] * 100, 1
)
return df_total_logs, df_logs_by_user, df_spark3_percentage
# Get data for Charts
df_total_logs, df_logs_by_user, df_spark3_percentage = generate_dataframe(
start_date=initial_date
)
### Chart starts ###
# Spark job status (Spark 2 and 3 job counts)
fig = px.bar(
df_total_logs,
x="log_date",
y="counts",
color="spark_version",
hover_data=["spark_version", "log_date", "counts"],
barmode="group",
title="Spark job status (Spark 2 and 3 job counts) from {} until {}".format(
initial_date, current_date
),
height=800,
)
fig.update_xaxes(
rangeslider_visible=False,
rangeselector=dict(
buttons=list(
[
dict(count=1, label="1day", step="day", stepmode="backward"),
dict(count=7, label="1w", step="day", stepmode="backward"),
dict(count=7 * 2, label="2w", step="day", stepmode="backward"),
dict(count=7 * 4, label="4w", step="day", stepmode="backward"),
dict(step="all"),
]
)
),
)
# Spark job status (Spark 2 and 3 job counts) in 28 days for user support
fig = px.bar(
df_logs_by_user,
x="log_date",
y="counts",
color="spark_version",
hover_data=["spark_version", "log_date", "username", "counts"],
barmode="group",
title="Spark status by user in recent 28 days",
height=870,
)
fig.update_xaxes(
rangeslider_visible=False,
rangeselector=dict(
buttons=list(
[
dict(count=1, label="1day", step="day", stepmode="backward"),
dict(count=7, label="1w", step="day", stepmode="backward"),
dict(count=7 * 2, label="2w", step="day", stepmode="backward"),
dict(step="all"),
]
)
),
)
# Spark job status (Spark 2 job by users)
fig = px.line(
df_logs_by_user[df_logs_by_user["spark_version"] == "spark2"],
x="log_date",
y="counts",
color="username",
hover_data=["spark_version", "log_date", "username", "counts"],
title="Number of Spark 2 execution(Service Account only)",
height=870,
)
fig.update_xaxes(
rangeslider_visible=False,
rangeselector=dict(
buttons=list(
[
dict(count=7, label="1w", step="day", stepmode="backward"),
dict(count=7 * 2, label="2w", step="day", stepmode="backward"),
dict(count=7 * 4, label="4w", step="day", stepmode="backward"),
dict(count=90, label="4w", step="day", stepmode="backward"),
dict(step="all"),
]
)
),
)
# Spark job status (Spark 3 overall percentage)
fig = px.line(
df_spark3_percentage,
x="log_date",
y="Spark 3(%)",
markers=True,
title="Daily executed Spark 3 jobs count percentage",
height=800,
)
fig.update_xaxes(
rangeslider_visible=True,
rangeselector=dict(
buttons=list(
[
dict(count=7 * 2, label="1w", step="day"),
dict(count=7 * 5, label="4w", step="day", stepmode="backward"),
dict(step="all"),
]
)
),
)評価アプローチ
評価にあたり、期間中にSparkのジョブ数が増えたことからプロジェクト前後の単純比較ができないことが懸念事項でした。実際に単位時間ごとの各メトリクスをグラフ上にプロットすると、緩やかに上昇していました。これでは、Spark Versionのアップグレードによりリソース効率が改善されていたとしても、グラフ上から改善効果を確認することは難しいです。
また、増えたジョブだけを除いて評価することも検討しましたが、工数がかかるため断念しました。扱ったデータが時系列データであったため、季節変動要因や時間ベースの要因の分解や、統計モデルなどを含む様々な分析を試みましたが、最終的には統計の事前知識がない人にも伝わるように、線形モデルの評価に利用されるシンプルな統計分解モデルを利用しました。具体的には、下記のアプローチで評価しています。その結果について説明いたします。
- 2022年9月を境に、①アップグレード前(2022/05-2022/08)・②アップグレード後(2022/09-2023/05)の期間に分ける
- ①②の各期間で回帰直線を引くことで、トレンドを観測する
- さらに、Sparkバージョン2.4をそのまま継続利用することを仮定した場合の予測モデルを作成し、②の回帰直線とプロジェクト完了時点での数値を比較する
評価結果
それでは、前述の評価方法を用いた評価結果について説明します。
初めに、メトリクスごとにアップグレード前後を比較したグラフは以下となります。横軸が期間、縦軸が各メトリクスの値を表したもので日次でのプロットとなっています。赤い線が各グラフごとの全データを使って作成した線形回帰直線です。
| vCore usage comparison |
|
|
|---|---|---|
| Memory usage comparison |
|
|
| Windows job count comparison |
|
|
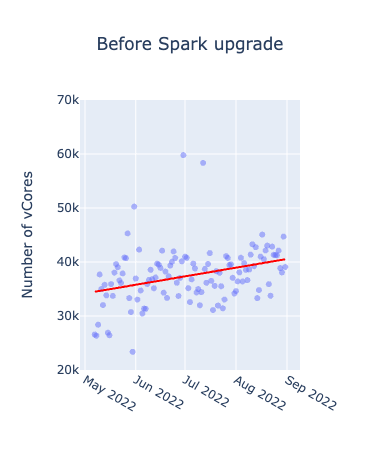
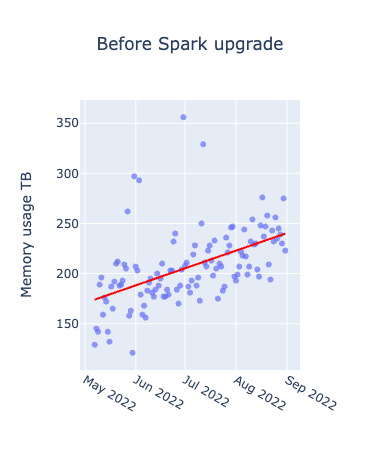
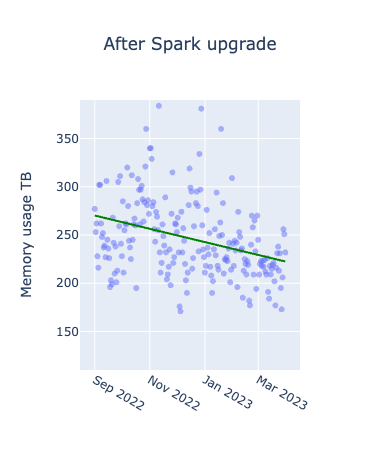
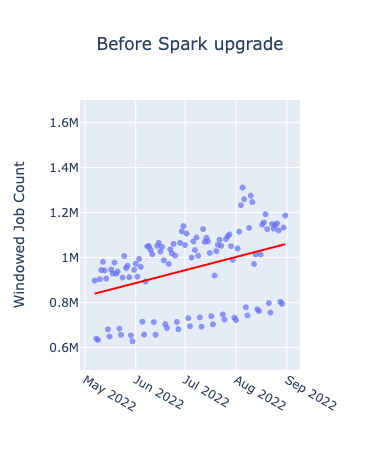
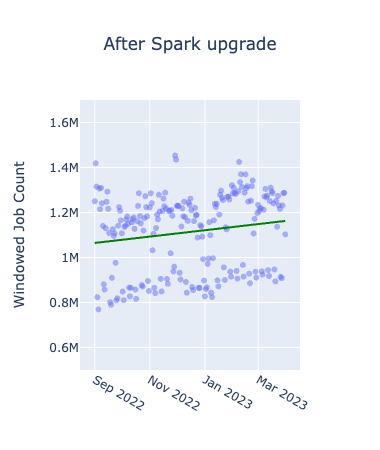
アップグレード前はいずれも上昇傾向にあるのに対し、アップグレード後に関しては、上昇が緩やか、あるいは減少していることが確認できます。Spark3.2.1のアップグレードにより、Adaptive Query Executionというクエリの実行プランを最適化する機能が追加されたため、メモリの使用効率に特に大きな影響があったと考えられます。Windowed Job Countsの分布に規則性があるように見えるのは、曜日ごとのトレンドによるものであり、ジョブ数が特に少なくなっているのは休日のジョブを表しています。
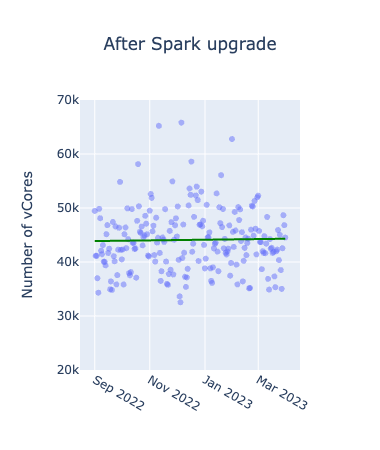
次に、メトリクスごとに予測モデルを使って実際のアップグレード後の結果とアップグレードしなかった場合の結果の比較をしたグラフが以下となります。横軸が期間、縦軸が各メトリクスの値を表したもので日次でのプロットとなっています。赤い線がアップグレード前のデータを用いて引いた線形回帰直線で、緑のグラフがアップグレード後データを使って作成した線形回帰直線です。また、青のグラフはプロジェクトの全期間のデータを使って作成した二次多項式の回帰直線です。縦の緑の点線はプロジェクト完了時点を表しています。
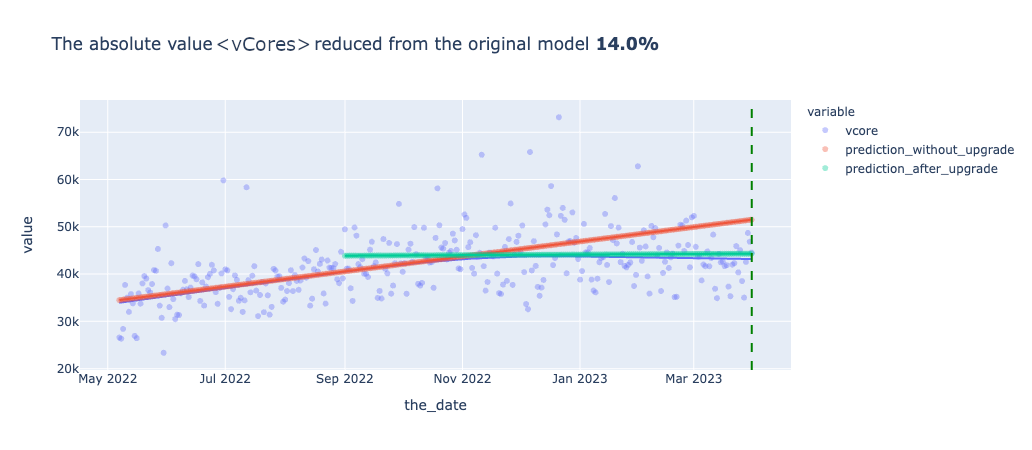
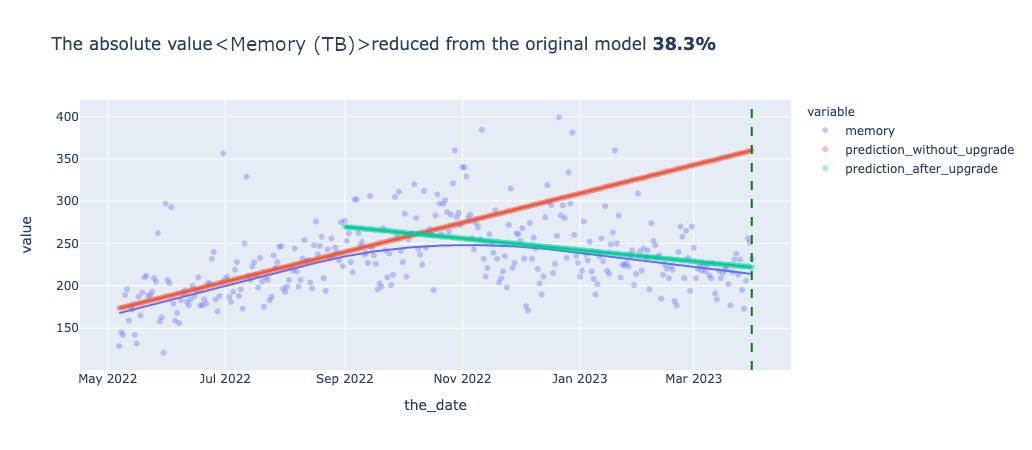
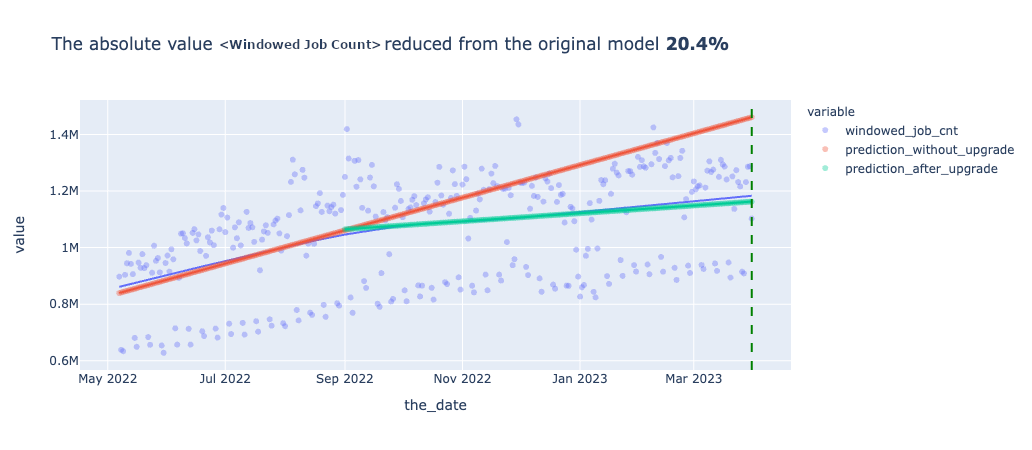
プロジェクト完了時点での、アップグレードしなかった場合の予測(赤の直線)とアップグレード後(緑の直線)を比較すると、実際アップグレードをしなかった場合の未来は確認できないのですが、おそらく全てのメトリクスについて改善されたいるであろうことが確認できます。UpgradeをしないままSpark2.4を継続利用していた場合、間違いなくYARNのWorker Nodeの増強が必要になっていたことが予測されます。また、vCoreよりもMemoryの改善の方が顕著であることも確認できました。
また、全体での結果の他にユーザごとにジョブの傾向を出してみると、興味深い結果が得られました。下記がメトリクスごとに、使用率やジョブの数が多いTop10のユーザを出したグラフです。プロジェクトのフェーズごとにどのようにメトリクスが変化したかも合わせて示しています。
|
用語 |
説明 |
データ取得期間 |
|---|---|---|
|
Start |
Spark 3アップグレードが開始した時点における1週間のメトリクス |
2022-05-08 ~ 2022-05-14 |
|
Middle |
Spark 3アップグレード後半(全体で90%程度のSpark2ジョブの移行が終わったタイミング) |
2023-04-09 ~ 2023-04-15 |
|
End |
Spark 3アップグレード完了後 |
2023-06-11 ~ 2023-06-17 |
ユーザ名はUUIDに置き換えていて、同一のUUIDは同一のユーザを表しています。なお、ジョブのグラフの中でs7sがMiddle以降の値がないのは、サービス自体が廃止されたからであり、s3tやa8tのStart時点での値がないのはプロジェクトの期間中に作成されたジョブであることが理由です。
| Top 10 usage users' total vCore trend (vCore seconds) |
|
|---|---|
| Top 10 usage users' total memory usage trend (Memory seconds) |
|
|
Top 10 users' total job count trend (Total Spark job counts Job counts) |
|
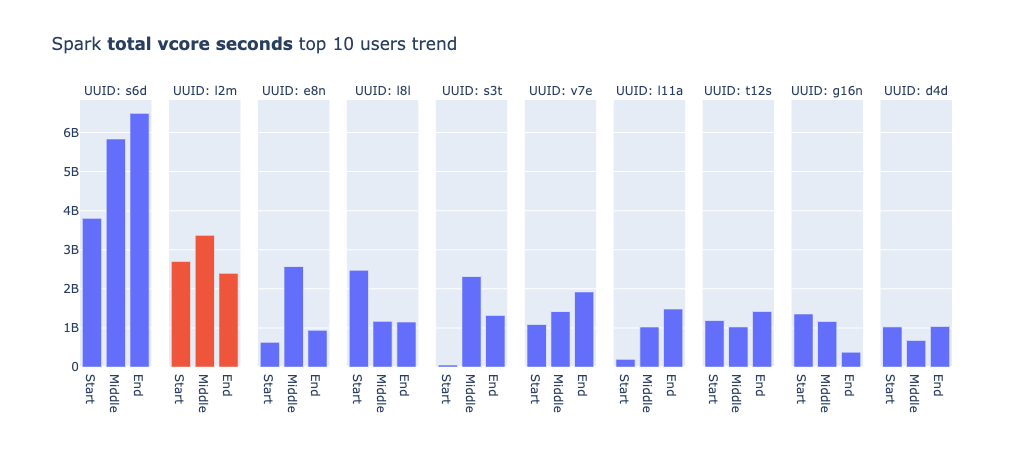
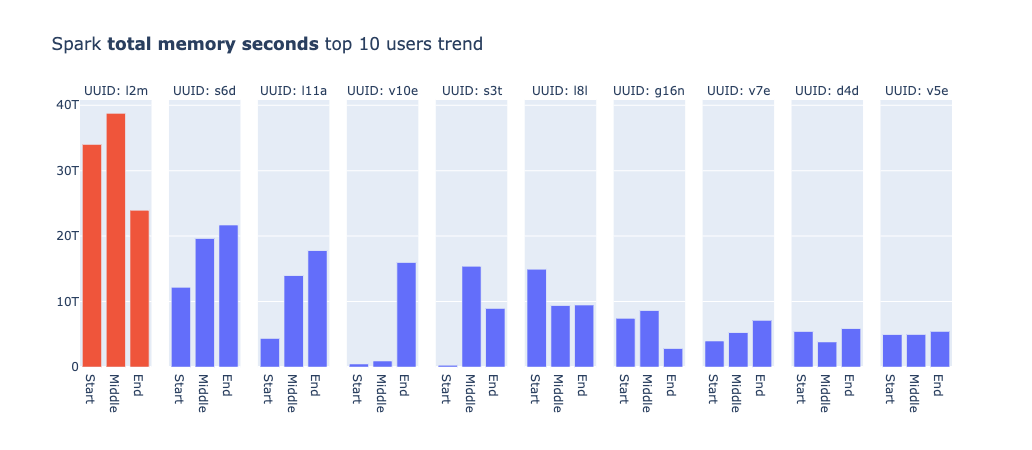
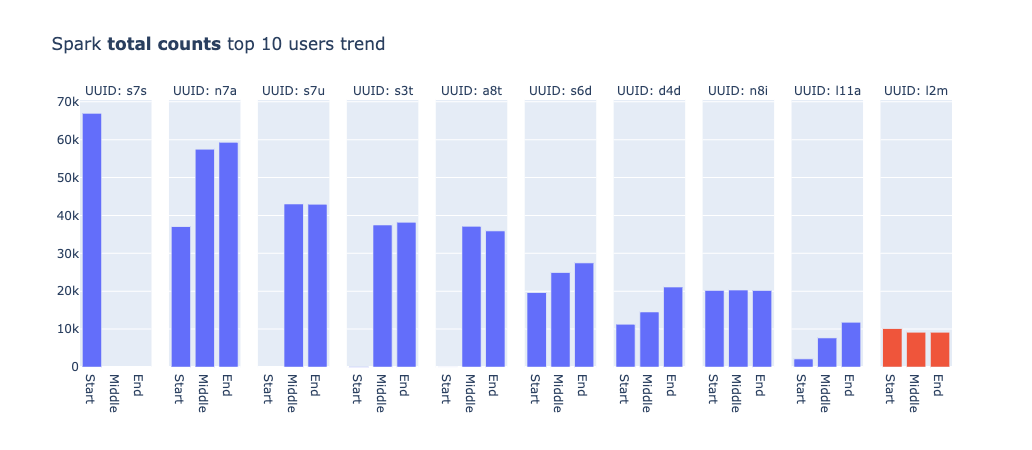
まず、各メトリクスごとにTop10のラインナップが異なることは、それぞれのジョブにおけるリソース使用の特性が異なることを示していると考えられます。UUID:l2mのユーザーは、アップグレード後にメモリ使用量が大幅に減少しています。このユーザーは機械学習系のタスクを担当していたため、メモリを頻繁に使用するSparkジョブを運用していたと推測できます。そのため、改善の効果が見られたのではないかと思われます。他にも多くの考察が可能ですが、説明が長くなりそうなので、今回はこれで終わらせていただきます。
まとめ
本記事では、Spark3.2.1のアップグレードプロジェクトにおいて、Hadoopクラスタのリソース効率が向上した事例を紹介させていただきました。ユーザ数・ジョブ数が増えたにも関わらずアップグレード前と同様のサーバ台数でワークロードを維持したことを実数値をもとに確認し、アップグレードしなかった場合に生じたであろうリソース不足について予測モデルを使って確認しました。この活動を通じて単にアップグレードを実行するだけでなく、アップグレード後の成果を目に見える形で表現することで、より多くのユーザに納得性のある効果を説明できることを身をもって実感しました。
IUでは、現在IU NextというInitiativeのもとで下記などの複数のプロジェクトを計画しています。今後も本プロジェクトのように成果の可視化を進めていこうと思います。
- 各ユーザが自分たちの使ったリソース状況を可視化できるようにするプロジェクト
- IUのデータにデータの正確性や信頼性、安全性といったデータの質を評価する仕組みを導入するプロジェクト
- より柔軟にデータを管理できるようにすることを目的とし、ACID対応のApache Iceberg FormatのテーブルをIU全体に向けて導入するプロジェクト
- HiveServer2を利用するユーザに対して、よりリソース効率の高いSparkへの移行を促すために、Hive互換性を持つSparkのJDBC Interfaceを導入するプロジェクト