
はじめまして。AIプロダクト開発2チームにて就業型インターンシップに参加しておりました、東京大学大学院 情報理工学系研究科 修士1年の冨山英佑です。普段はFederated Learningに関する研究を行っています。
LINEのプライベートクラウドであるVerdaでは、マネージドKubernetesプラットフォームのVerda Kubernetes System (VKS) が提供されています。本インターンでは、VKSのクラスタに、KubernetesアプリケーションのオブザーバビリティツールであるPixieを導入しました。本レポートでは、Pixieを用いた効果的なアプリケーションのパフォーマンス分析手法を提案します。
背景と目的
高い品質のKubernetesアプリケーションを提供するには、アプリケーションのパフォーマンスを高く保つ必要があります。アプリケーションのパフォーマンスを分析するためには一般的に多くのツールを組み合わせて用いなければなりません。
例)
- Podのメトリクスを監視するためにPrometheusを用いる
- HTTPリクエストのレイテンシの調査にnginxのログを用いる
- 負荷の大きい関数を発見するためにプロファイラを用いる
Pixieは、近年注目の集まるeBPF(Extended Berkeley Packet Filter)という技術を利用したオープンソースのオブザーバビリティツールです。PixieはeBPFを用いることで、パフォーマンス分析に必要なデータをPixieひとつで全て収集することができます。また、Pixieがオープンソースになったのは2021/04のことであり、日本語のドキュメントやブログがほとんどないような比較的新しいツールです。そのため、実際にPixieをVKSクラスタ上にデプロイ、運用して得た知見をもとに、Pixieを用いたアプリケーションのパフォーマンス分析手法を提案し、Pixieの活用方法や課題点などを共有したいと思います。
Pixieとは
特徴
Pixieの特徴は主に3点挙げられます。
- Pixieはデータの収集にeBPFを用いています。eBPFとは、システムコールや特定のパケットの受信等のカーネルのイベントをトリガーとしてユーザが定義しておいたコードを実行できるカーネル技術のことです。しかしPixieを利用する際にユーザがeBPFを特に意識する必要はありません。リソースやネットワークのメトリクス、トラフィックの中身、アプリケーションのプロファイル等のデータはPixieによって自動的に収集されます。
- データの収集、保存、クエリの実行はすべてクラスタ内で行われます。そのため、Pixieをデプロイするために、追加でサーバを立てる必要がありません。クラスタ全体でPixieが使用するCPUリソースは5%未満であり、多くの場合は2%未満であるため、Pixieによるオーバーヘッドも大きくはありません。
- 収集したデータへのクエリはPxL(Pixie Language)というPythonベースのドメイン固有言語(DSL)を用いて表現されます。これはUIのみならずCLIやAPIからも統一的に用いられるインターフェースです。一般的なユースケースにおけるPxLは最初から提供されているので、Pixieを利用し始めた際に一からPxLを書く必要はありません。
アーキテクチャ
Pixieのアーキテクチャに含まれる主要なコンポーネントとその関係について紹介します。
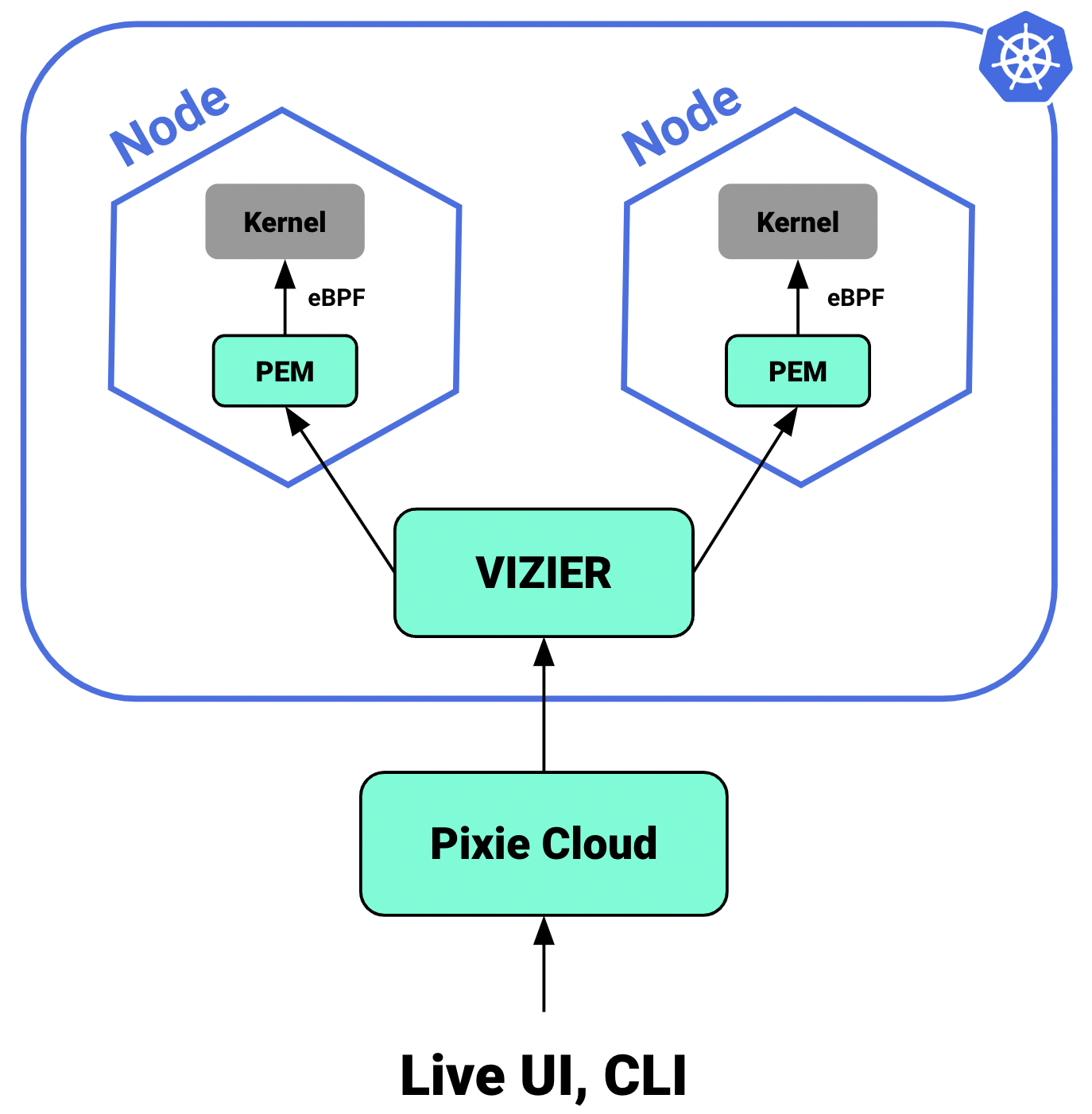
Pixie Edge Module (PEM)
PEMは、クラスタのノードにそれぞれ1つずつインストールされるPixieのコンポーネントです。eBPFを用いてノードのカーネルからメトリクス等のデータを収集しており、収集したデータをノード内に蓄積しています。PEMは実体としてはDaemonsetリソースです。
VIZIER
クラスタに1つインストールされるPixieのコンポーネントです。クエリの実行や、PEMのマネジメントの役割を果たします。実体としてはDeploymentリソースです。
Pixie Cloud
Pixieのユーザ管理、認証や、データのプロキシとして用いられるコンポーネントのことです。Community版とSelf-hosted版の2種類があります。Community版は、Pixie Communityによって提供されているPixie Cloudであり、既にGCP上でデプロイされていて、サインアップするだけで利用できます。Self-hosted版は自分でクラスタにデプロイして利用します。
Live UI, CLI
ユーザがPixieの収集したデータにアクセスする方法として、Pixie Live UIやPixie CLIがあります。Pixie Live UIはPixie CloudにホストされているWebベースのUIです。Live UIにはプリセットのPxLが用意されています。
PixieのVKSクラスタへのデプロイ
Pixieをデプロイする前に、Pixie Cloudについて、Community版とSelf-hosted版のどちらを用いるのか決める必要があります。本インターンでは、VKS内の閉じた環境にて動作確認を行うため、Self-hosted版のPixie Cloudを選択しました。
Pixie Cloudのデプロイ
Pixie CloudをVKSクラスタ上に、実際に本番運用を想定した形でデプロイする際に、2点の工夫が必要になりました。
Kubernetesクラスタ内DNSサーバのドメイン名変更
サポートされている環境はPixieの公式ドキュメントに示されている通りです。EKS, GKE等のマネージドサービス上では動作が保証されていますが、VKS上でのデプロイは当然公式にはサポートされていません。
標準的なKubernetesの実装では、kube-dnsというDNSサーバが組み込まれています。一方で、VKSでは少し仕様が異なり、vks-dns-upstreamがその役割を果たしています。そのため、DNSにkube-dnsが指定されている場合、それをvks-dns-upstreamに置き換える必要があります。Pixie Cloudに関しては、nginxの設定ファイル(nginx.conf)内のresolverの設定が必要となりました。
設定ファイルを書き換えた後で再度サーバのimageをbuildするのは手間なので、設定ファイルをConfigMapに設定しておいて、VolumeMountでファイルをマウントすることで、マニフェストの変更だけにとどめることができます。
resolver kube-dns.kube-system.svc.cluster.local valid=5s;resolver vks-dns-upstream.kube-system.svc.cluster.local valid=5s;Pixie Cloudを独自のドメイン名でホスト
Pixie Cloudは以下複数のドメイン名が使われます。
- work.dev.withpixie.dev
- segment.dev.withpixie.dev
- slackin.dev.withpixie.dev
- docs.dev.withpixie.dev
これらはダミーのドメイン名であり、クライアント側が/etc/hostsを書き換えながら利用することになっています。Self-hosted Pixie Cloudを実際に運用するには、これらを所望のドメイン名に置き換えることが必要ですが、Self-hosted Pixie Cloudの公式のデプロイ手順にはこの工程が含まれていません。
そこで、Self-hosted Pixie Cloudのマニフェスト内にハードコードされているダミーのドメイン名すべてを、変更したいドメイン名に書き換えました。また、Self-hosted Pixie CloudのロードバランサのIPアドレスを、書き換えたドメイン名に対応したDNSのAレコードに設定しました。
Pixieのデプロイ
Pixie自体のデプロイは非常に簡単です。以下のコマンドを実行するだけでデプロイすることができます。Pixieのデプロイが正常に完了すると、特にそれ以上の設定を行う必要はなく、自動的にデータの収集が開始されます。
export PL_CLOUD_ADDR=pixie.line-apps-alpha.com
# install Pixie CLI
brew install pixie
# login Pixie Cloud
px auth login
# Deploy Pixie with a specific memory limit
px deploy --dev_cloud_namespace plc --pem_memory_limit=1GiPixieを用いたアプリケーションのパフォーマンス分析手法
提案手法
Pixieは、観測対象のアプリケーションと同じクラスタ内にデプロイするだけで、特別な設定を行わなくても、パフォーマンス分析に必要なデータを得ることができます。例えば、クラスタ上にOSSをデプロイしている場合、ソースコードに特別な変更を加えることなく、メトリクスやトラフィックの中身を見ることができます。
そこで、Pixieを用い、以下3つの視点によるメトリクスやトラフィックの中身を見ることにより、Kubernetesアプリケーションのパフォーマンス分析を行う手法を提案します。
- APIの視点
- Podの内部的な視点
- DBクエリの視点
VKS上にデプロイしたZulipというオープンソースのチャットアプリケーションを例に、3つの視点での分析方法を説明します。
APIの視点
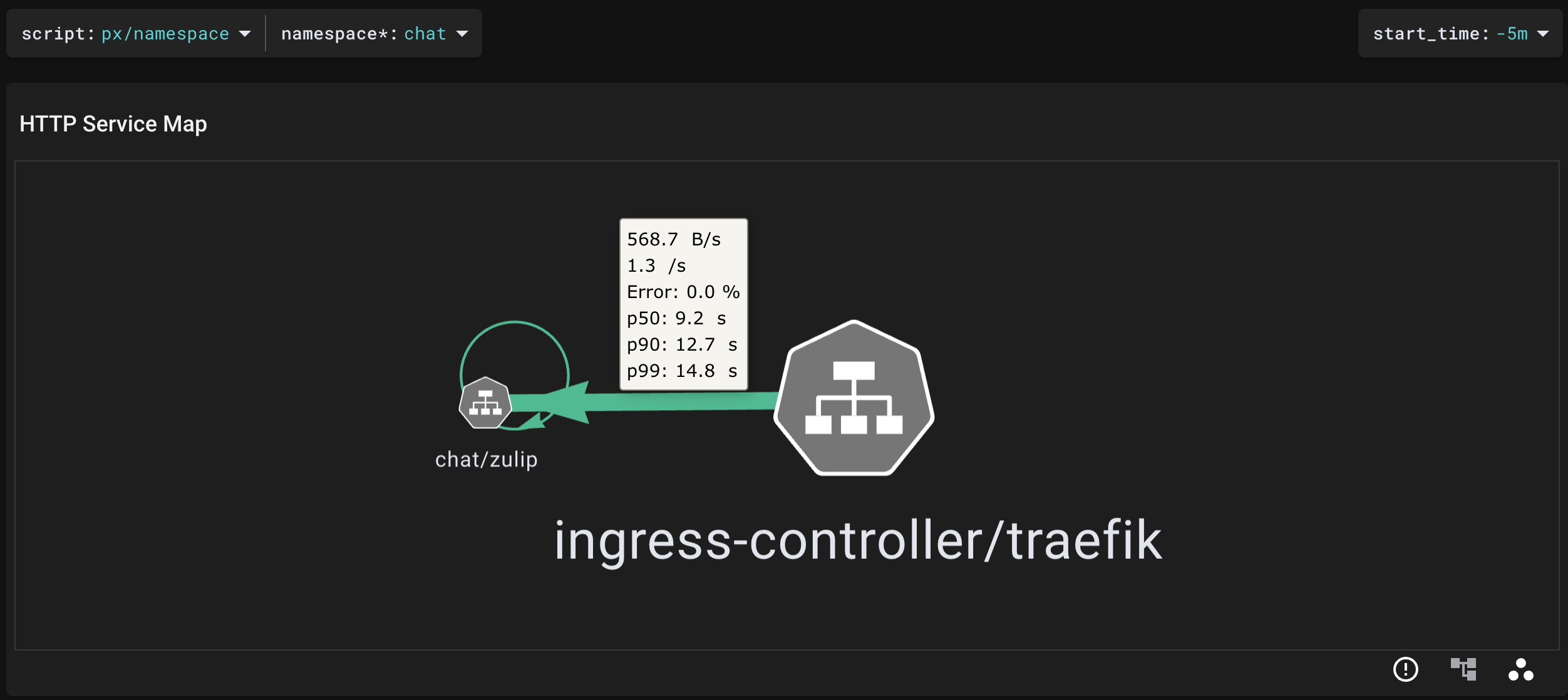
Pixie Live UIで"namespace"というプリセットのscriptを用いて、Zulipの対応するnamespaceを指定すれば、そのnamespace内で生じているHTTPリクエスト・レスポンスをサービスマップの形で表示できます。
以下の図では、ingress controllerからzulipサービスにHTTPリクエストが送信されている様子が確認できます。矢印上をホバーすると、スループット、エラーレートやレイテンシなどのメトリクスも得られます。
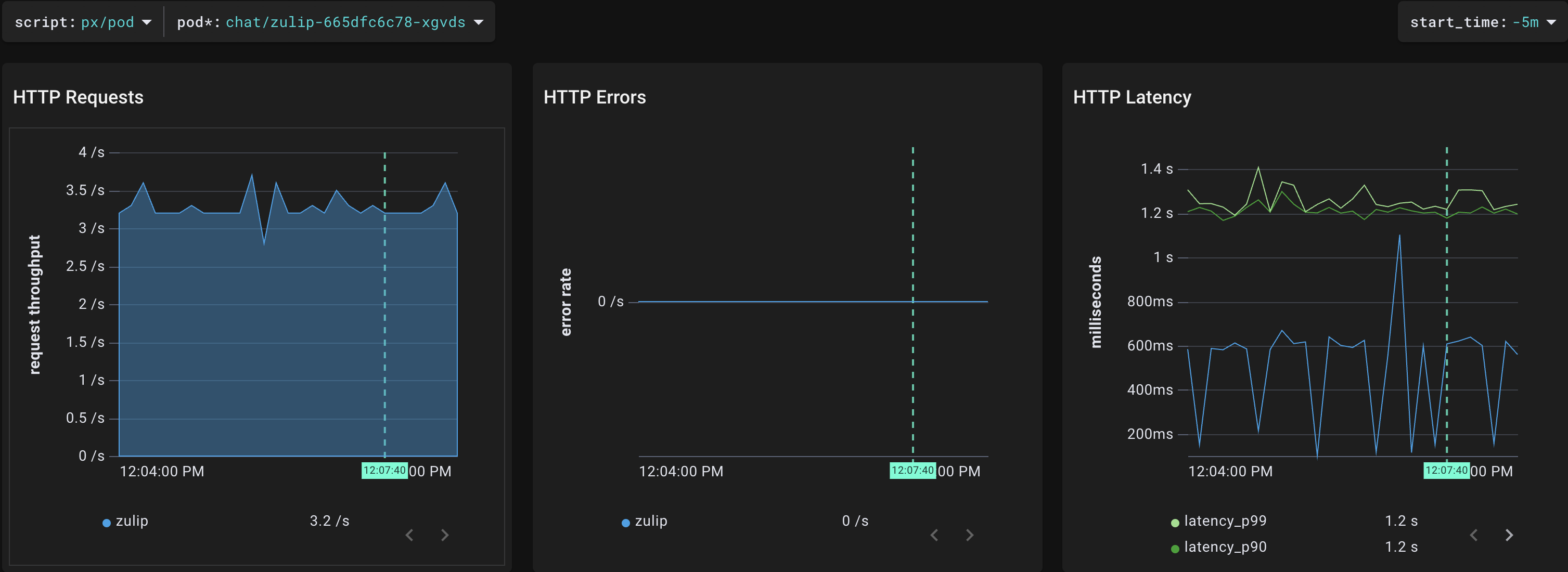
"pod" scriptを用いて、スループット(下図左)、エラーレート(下図中央)、レイテンシ(下図右)を確認することもできます。
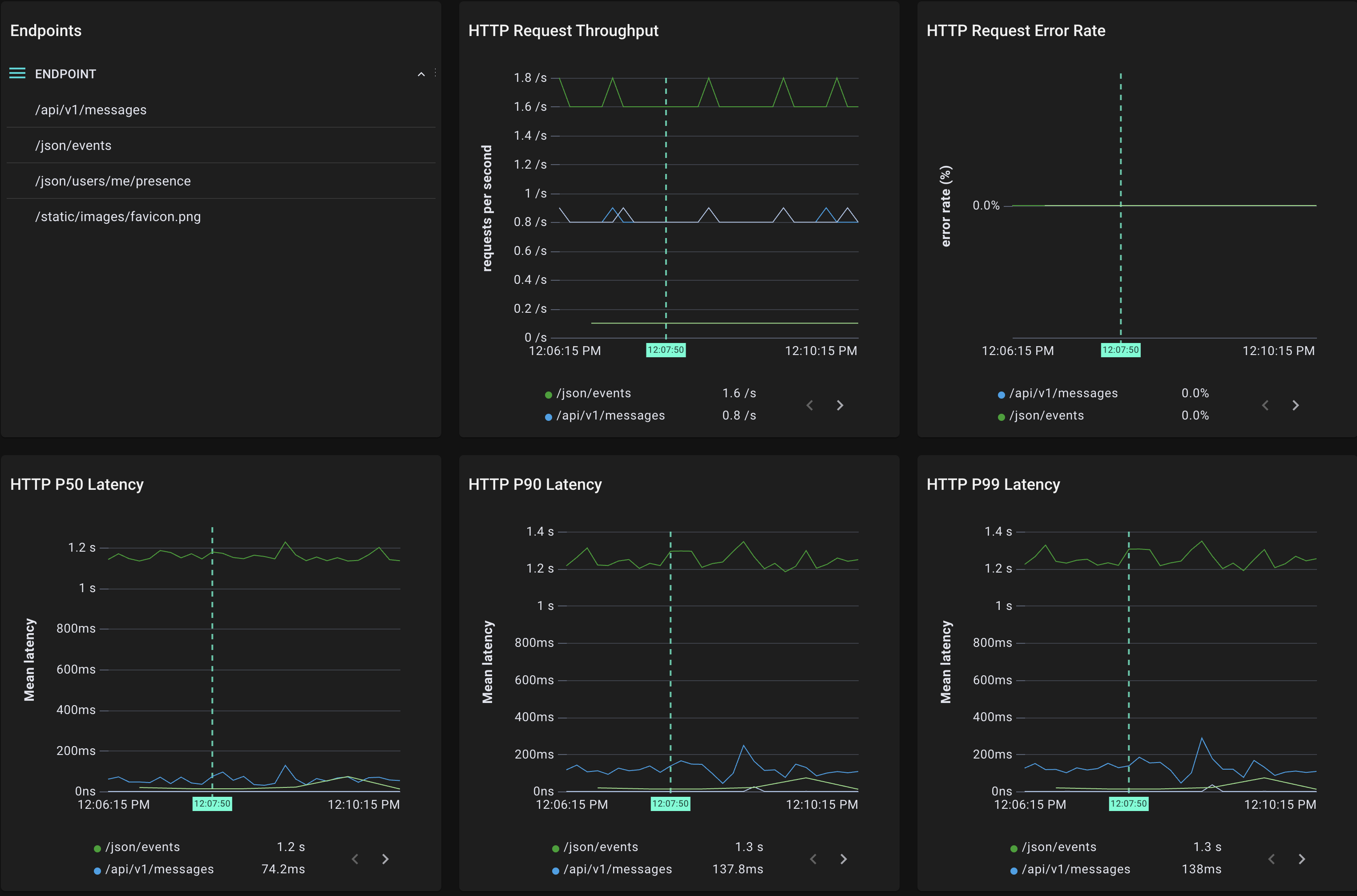
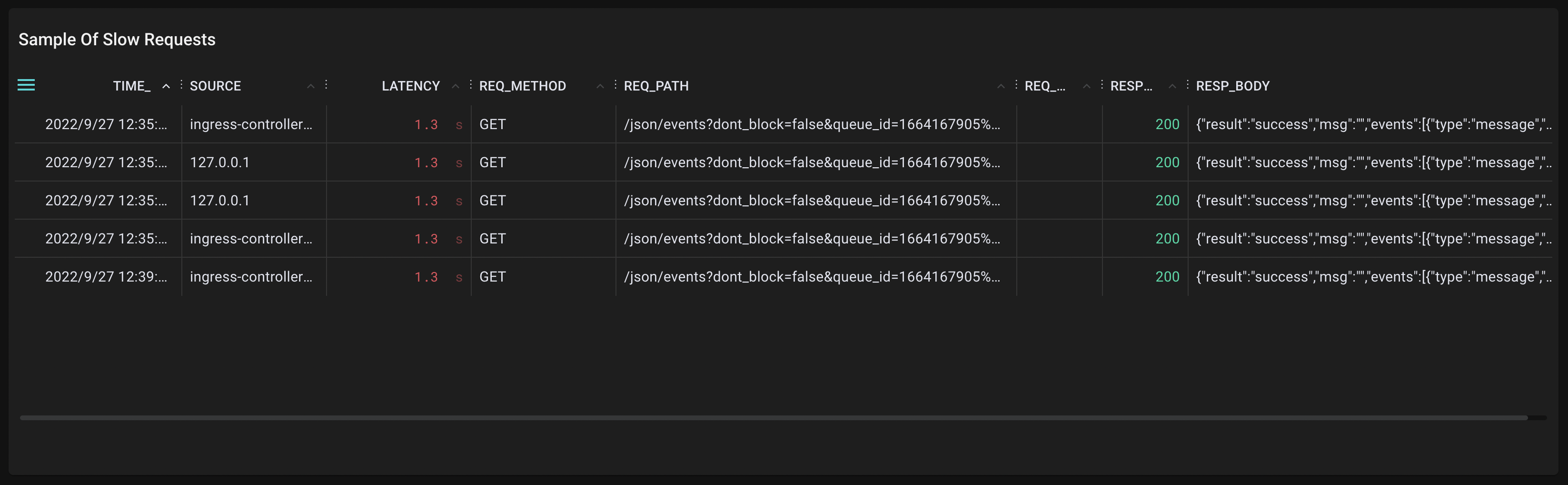
さらに、"endpoints"スクリプトを用いて、L7レベルでエンドポイントごとのメトリクスを得ることもできます。下三つのグラフを見ると、/json/eventsというパスにおいてレイテンシが大きくなってしまっていることが確認できます。
気になるエンドポイントについて、"endpoint"スクリプトで、レスポンスが遅くなってしまったリクエストの一覧から、パラメータやレスポンスボディ等についても詳細に知ることができます。
Podの内部的な視点
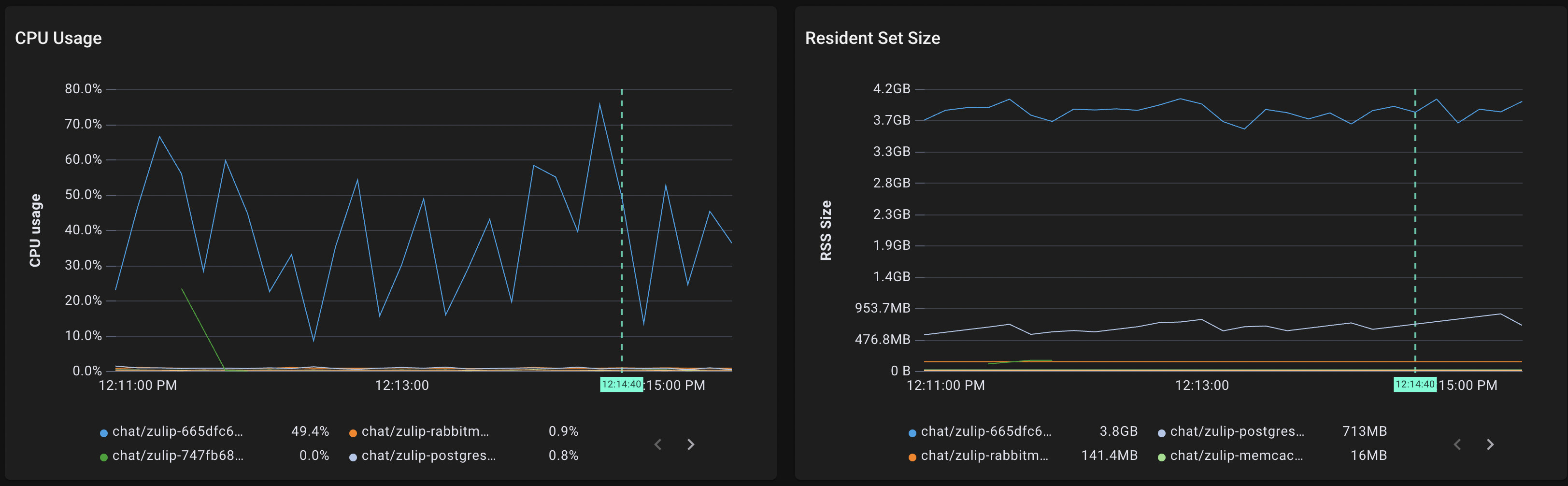
各Podについて、PodのCPU使用率(下図左)や、メモリ使用量(下図右)も収集されています。"pods" scriptを用いて、Zulipのnamespaceを指定すると、そのnamespace内のPodそれぞれのCPU使用率や、メモリ使用量が確認できます。
今回は青線で表されているPodが他のPodに比べてCPUの使用率が高く、メモリの使用量も大きく、比較的高負荷がかかっている様子が確認できます。
DBクエリの視点
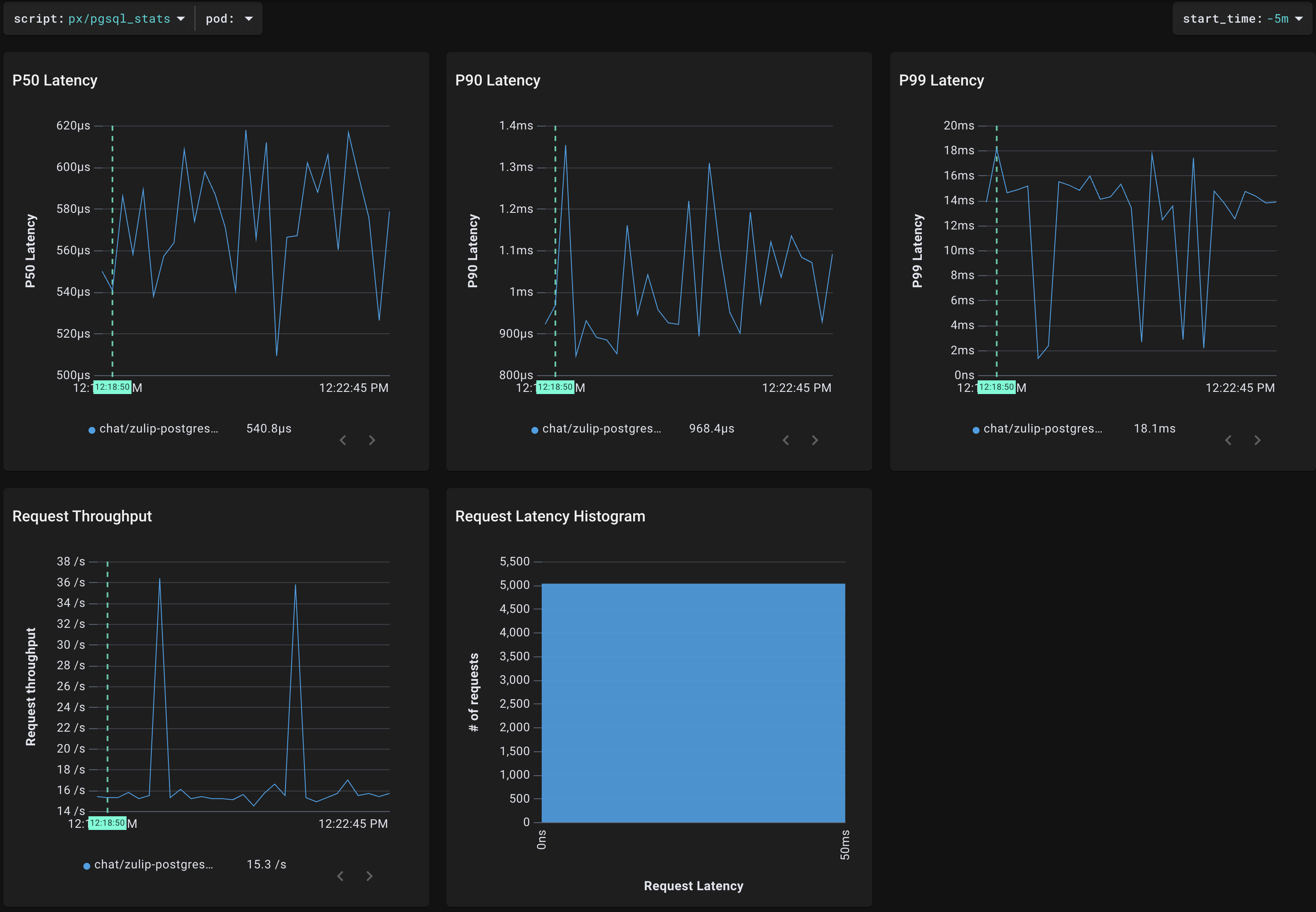
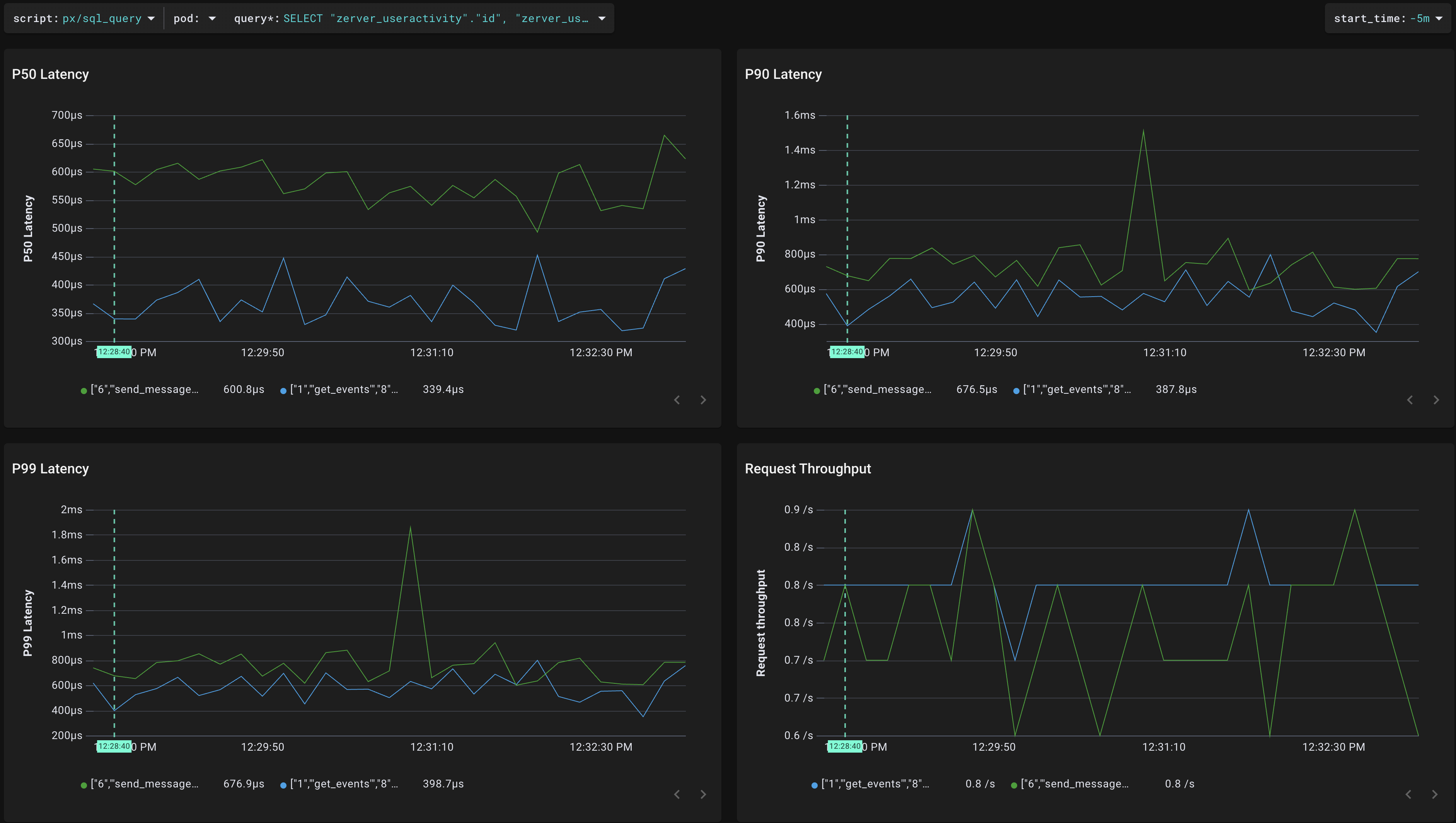
ZulipのバックエンドではPostgresDBが使われているので、"pgsql_stats" scriptを用いて、DBごとのスループット(下図左下)やレイテンシ(下図上)のデータを得られます。
"sql_queries" scriptを用いて、標準化されたクエリごとのスループット(下図右下)やレイテンシ(下図上)を表示することもできます。
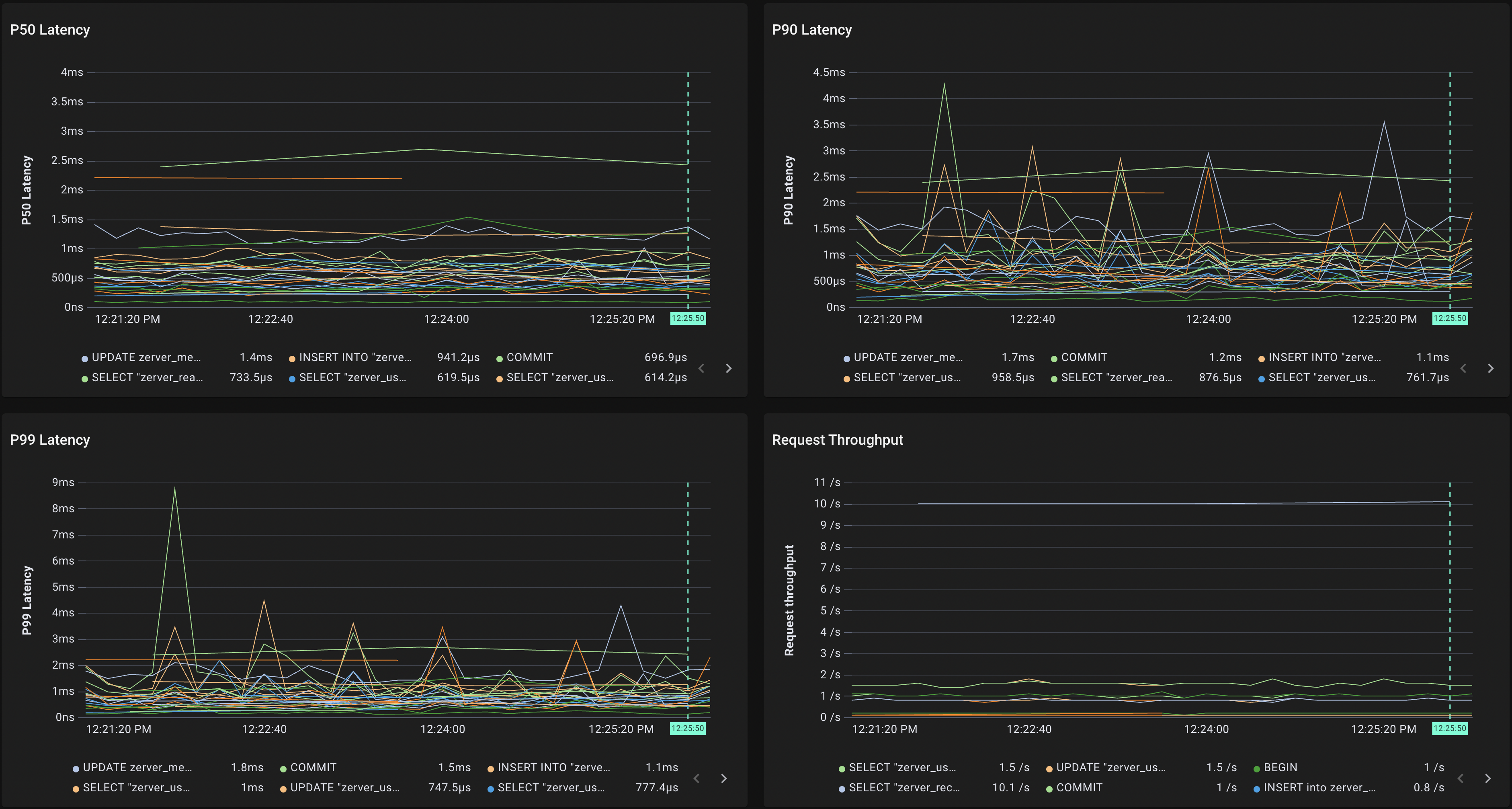
さらに、ある標準化されたクエリに注目して、"sql_query"スクリプトで、そのクエリのパラメータごとのスループット(下図右下)やレイテンシ(下図上)を表示することも可能です。
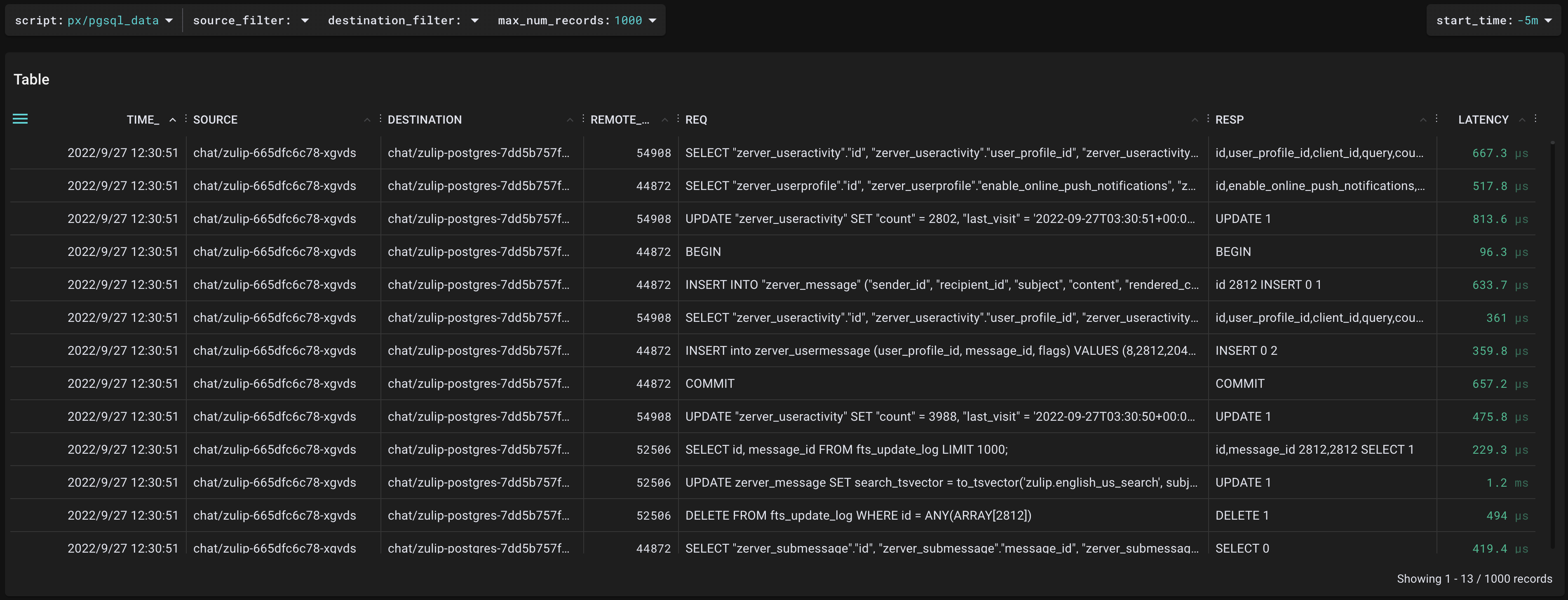
"pgsql_data"scriptで、実際に発行されたクエリひとつひとつの詳細な内容や、それぞれのレイテンシについても詳細に分析することが可能です。
提案手法の検証:API Gatewayのオーバーヘッド分析
AIプロダクト開発2チームでは、現在、OpenAIのGPT-3のような、大規模汎用言語モデルであるHyperCLOVAを用いたアプリケーション開発に取り組んでいます。大規模汎用言語モデルは、大量のGPUリソースを必要とするため、リソース有効活用の目的で、アプリケーション毎に大規模汎用言語モデルの推論APIを呼び出す頻度を制御するAPI Gatewayを試作しています。このAPI Gatewayを推論APIサーバの前段に配置した際、処理のオーバーヘッドがどの程度になるかを提案手法を用いて調査します。
調査する項目は以下の通りです。
- オーバーヘッドの具体的な時間
- APIへの入力の大きさとオーバーヘッドの関係
- オーバーヘッドの原因:DBへのクエリのレイテンシ
- オーバーヘッドの原因:高負荷の関数の存在
以上の項目のうち、Pixieによって、1,2は調査が可能、3は部分的に調査可能、4は調査不可能でした。以下ではその詳細について説明します。
オーバーヘッドの傾向調査
APIの入力テキストに、5文字の短い入力を与えた場合と、1200文字程度の大きな入力を与えた場合のオーバーヘッドの違いについて調査します。
まず、「こんばんは」という短い入力が与えられた場合を調べます。Pixie Live UI上で、"http_data"というプリセットのscriptを用います。API Gateway宛(図中の"sawarabi"はAPI Gatewayサーバのコンポーネント名)の通信で絞り込むと、下記のような出力を得ることができます。
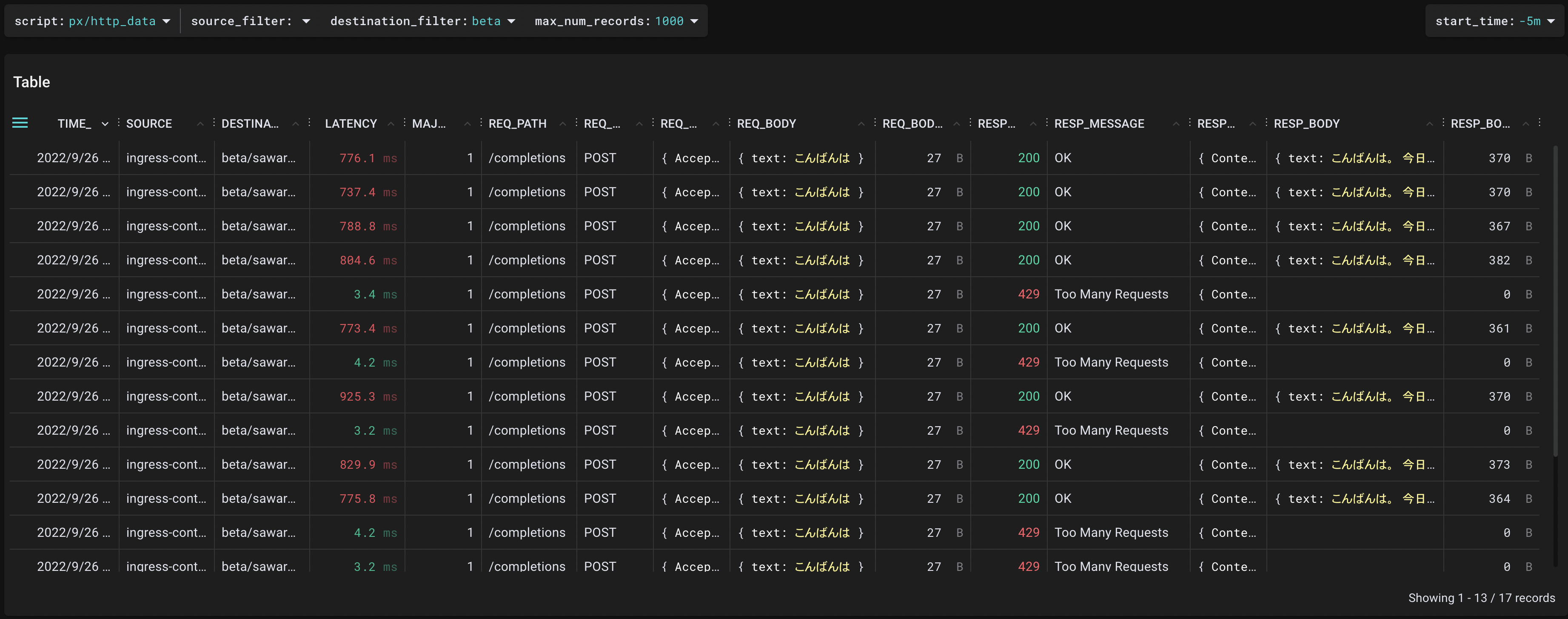
ステータスコード200で正常に完了したリクエストに関しては、レイテンシが平均800ms前後であることが確認できます。それと同時に、ステータスコード429でエラーとなっているレスポンスの中身が、Too Many Requestsであることも確認できます。
次に、同じく"http_data"というプリセットのscriptを用いて、API Gatewayから外への通信で絞り込むと、下記のような出力を得ることができます。
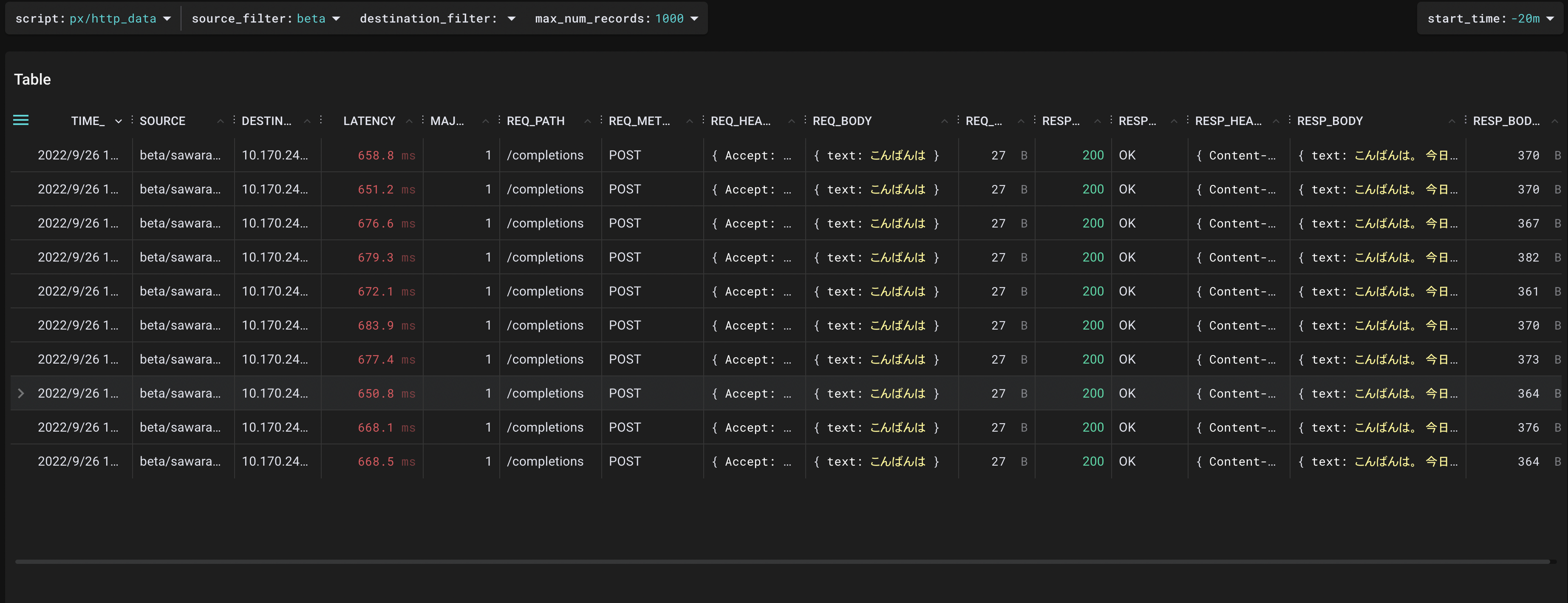
この結果から、API Gatewayから推論APIサーバへの通信のレイテンシは平均670ms程度であるため、入力が小さい時、API Gatewayのオーバーヘッドは130ms前後であることが判明しました。
次は、約1200文字の大きな入力を与えた場合について調べます。先ほどはリクエストボディが27Bであったのに対し、今回はリクエストボディが3.1KBです。この場合に、API Gateway宛の通信で絞り込むと、下記のような出力を得ることができます。
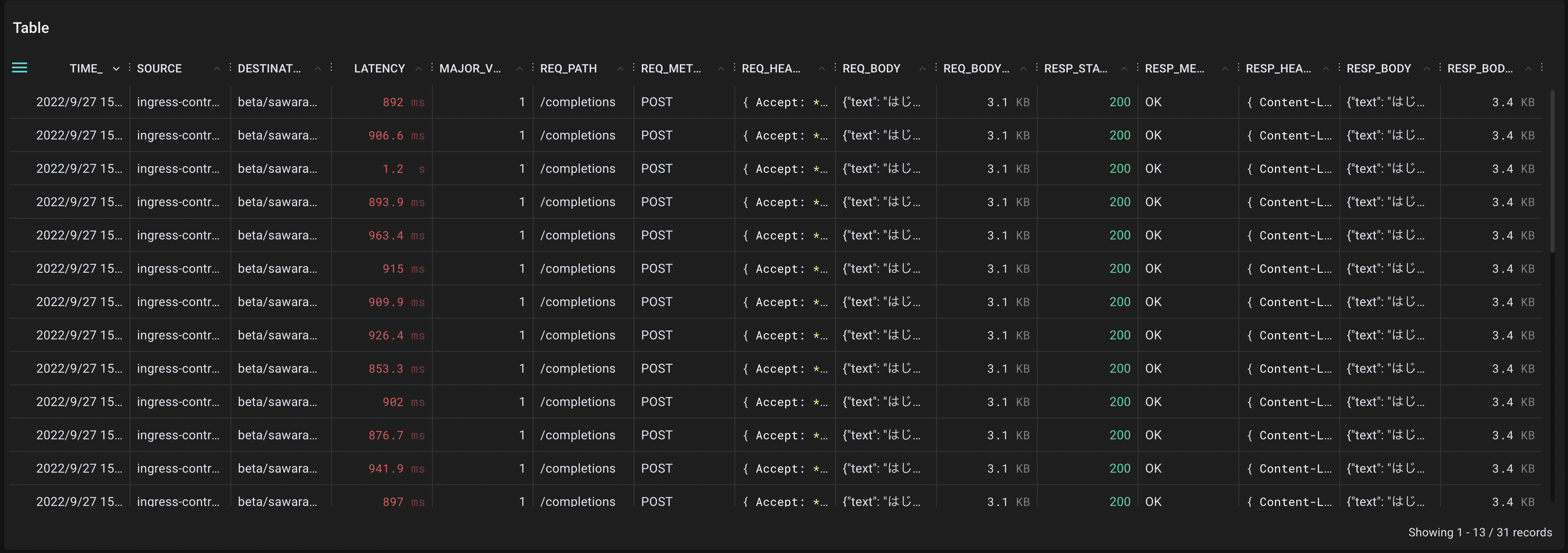
リクエストボディが大きい時、レイテンシは平均900ms前後に増加していることが確認できます。
また、API Gatewayから推論APIサーバへの通信で絞り込むと、下記のような出力を得ることができます。
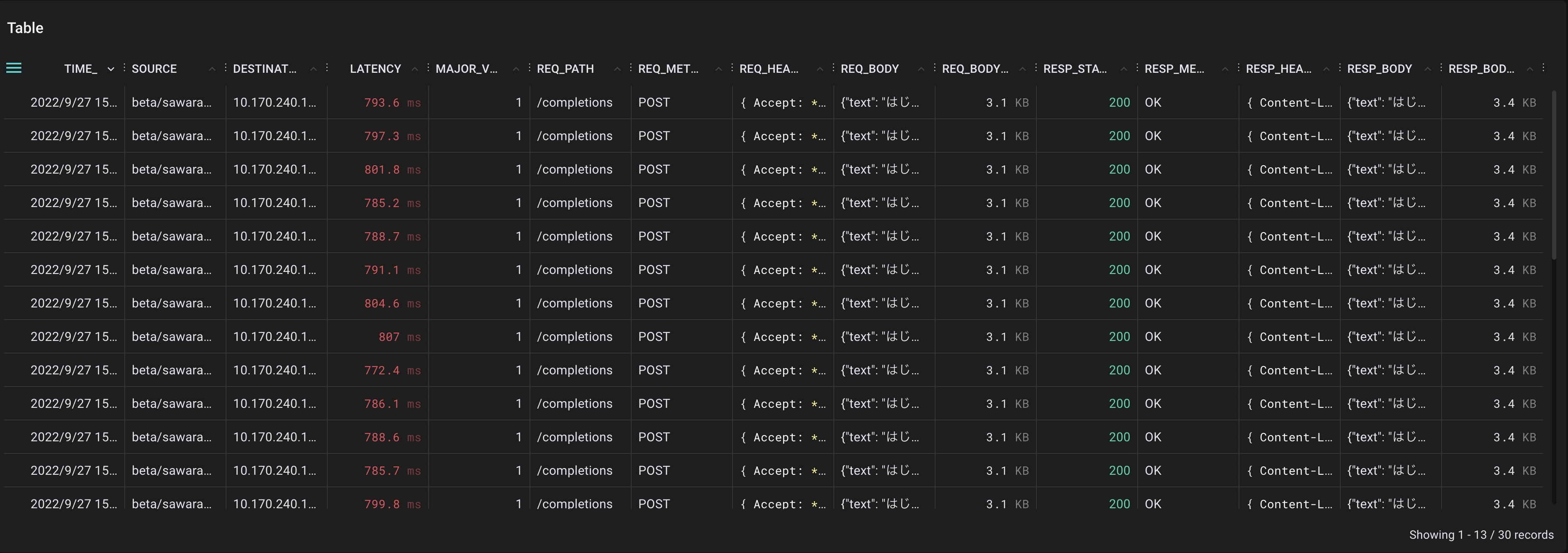
推論APIサーバへの通信も同様に、レイテンシが平均790ms程度まで増加している様子が確認できます。入力が大きい時、API Gatewayのオーバーヘッドは110ms前後であることが判明しました。
|
短い入力
|
長い入力
|
|
|---|---|---|
| リクエストボディサイズ | 27B | 3.1KB |
| API Gatewayのレイテンシ | 800ms | 900ms |
| 推論APIサーバのレイテンシ | 670ms | 790ms |
| オーバーヘッド | 130ms | 110ms |
以上から、API Gatewayの全体のレスポンスのレイテンシはリクエストボディの大きさに依存するものの、オーバーヘッド自体はリクエストボディの大きさとそこまで関係がない可能性が高いと判断できます。
オーバーヘッドの原因調査
オーバーヘッドの生じる原因として、以下のようなものが挙げられます。
- DBのクエリにかかるレイテンシが大きい
- API Gatewayの内部で実行されている関数に高負荷のものがある。
DBのクエリのレイテンシ
HyperCLOVA API GatewayはバックエンドにRedisとMySQLを使用しています。Redisサーバとの通信のレイテンシについては、"redis_data"というプリセットのscriptを用いて、リクエスト・レスポンスの詳細やそのレイテンシについても分析が可能でした。
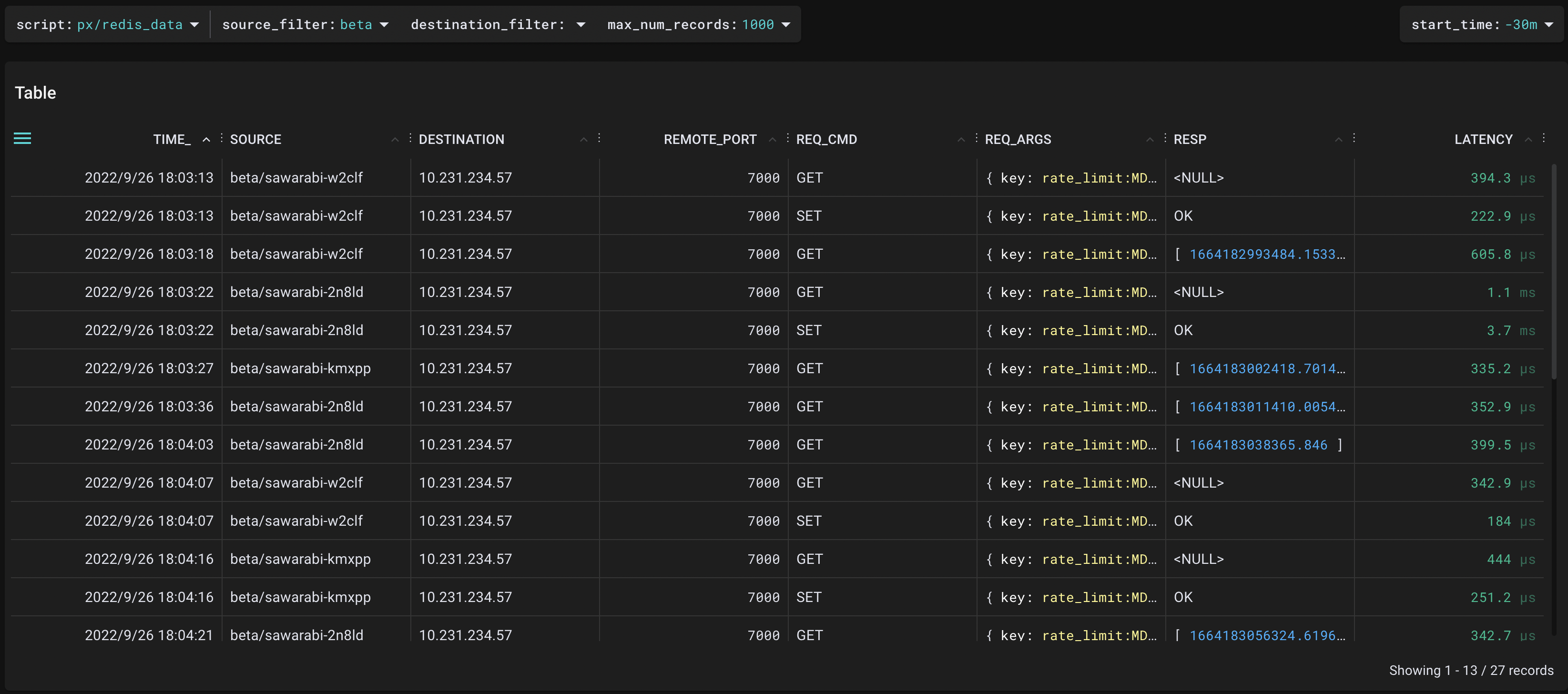
レイテンシはほとんど1msにも満たない大きさなので、Redisとの通信がオーバーヘッドの原因ではない可能性が高いです。
次に、MySQLとの通信ですが、現状のままではMySQLサーバとの通信内容やレイテンシについてデータを収集することができませんでした。HyperCLOVA API GatewayはMySQLとの通信をTLSで暗号化していますが、実装に用いられたMySQLのクライアントライブラリが、Pixieのサポートする暗号化ライブラリに含まれていないためです。
API Gatewayの内部で実行されている高負荷の関数
Pixieには、フレームグラフという形で、どの関数がどれだけCPUを消費しているのか可視化する機能があります。しかしながら、現在PixieがサポートしているのはGo, C++, Rust, Javaのみであり、API Gatewayを実装するのに用いられたRubyは含まれていません。
例えばGoアプリケーションならば下図のような出力を得られますが、
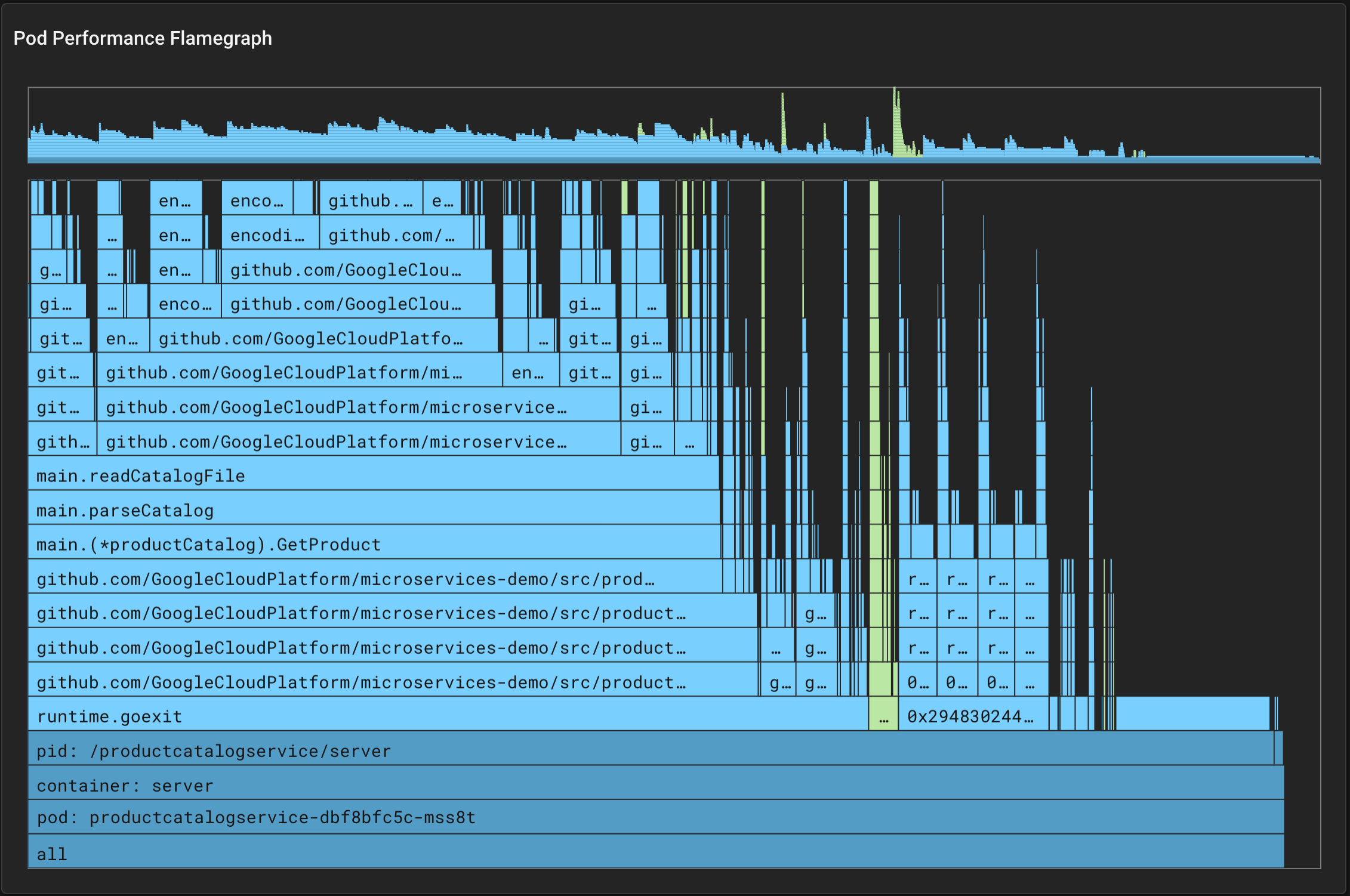
引用:https://docs.px.dev/tutorials/pixie-101/profiler#reading-the-flamegraph
Rubyで実装されたAPI Gatewayでは以下のような出力しか得られません。
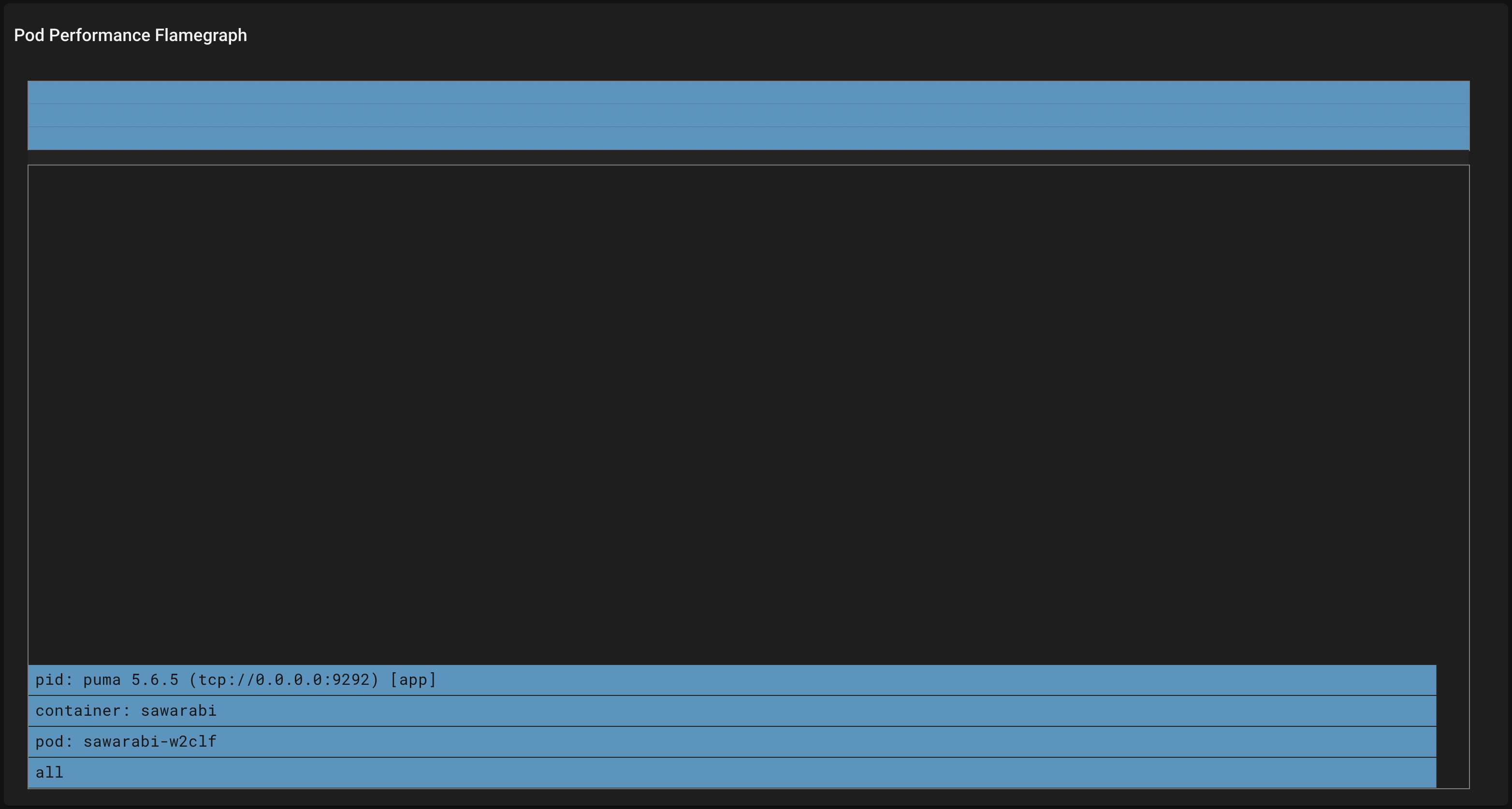
検証結果
Pixieを用いれば、パフォーマンス分析に必要な、API、Podの内部、DBクエリに関するメトリクスや、通信内容の詳細等のデータを自動的に収集でき、可視化することができることを示しました。そこで、実際にPixieを用いた分析の例として、API Gatewayのオーバーヘッド分析を行いました。
Pixieを用いれば、リクエスト・レスポンスの詳細情報が閲覧でき、レイテンシの発生する状況や、具体的なオーバーヘッドの時間を把握することが可能でした。HTTP通信の内容やメトリクスを手軽に調査するという点でPixieは優れていると言えます。それに加えて、Redis, MySQL等のアプリケーションの通信もサポートしており、言語によってはCPUプロファイリングが可能など、バックエンドの実装次第では、手軽にアプリケーション全体にわたってパフォーマンス分析を行う能力を持っていることが分かりました。しかしながら、今回のユースケースのように、サポートしているライブラリや言語の制約によってはその機能を存分に利用できないケースもあるので、導入前に検討が必要な点も明らかになりました。
Pixieを使う上での課題
Pixieを使う上で、デプロイに関する課題と、機能面での課題があります。
デプロイに関する課題
Self-hosted Pixie CloudをVKSで独自のドメイン名で利用するためにかかる手間
上記で触れたように、Pixie CloudをVKS上で独自のドメイン名でデプロイするには、マニフェストの書き換えが必要になるため、pullしたものをそのままデプロイするわけにはいきません。また、Pixie Cloudにアップグレードが生じた際には毎回、自分で書き換えたマニフェストの変更を保持しながら、最新の差分をマージしていく必要があり、手間になります。
Pixieシステム全体の消費リソース
Pixieのクラスタ全体の消費CPUリソース多くの場合は2%未満であると言及されていますが、本実験内では定量的には未調査です。ノードのメモリはPixie用に各ノードで最低1GiB以上を確保する必要があります。
また、Self-hosted Pixie Cloudは、Pixieと独立しているようで、実はPixieと同じクラスタにデプロイすることしかできません。 Pixie Cloudの消費リソースについては言及されておらず、実運用上でPixie Cloudが監視対象のアプリケーションのパフォーマンスを阻害するようでは本末転倒です。アプリケーション内で大量のトラフィックが生じる状況においてPixieとPixie Cloud自体のリソース消費には注意が必要です。
機能面の課題
通信データを収集できない場合がある
ユースケースで挙げた例のように、クラスタ内の通信が、Pixieによってサポートされていないライブラリによって暗号化されていると、通信内容を閲覧することができません。そのため、Pixieを導入する前に、用いられている暗号化ライブラリがサポートされているのか調べる必要があります。
限られた技術スタック
PixieのCPUプロファイラがサポートしているのはGo, C++, Rust, Javaのみであり、その他の言語ではフレームグラフを閲覧できません。また、クラスタ間の通信についても、HTTP, DNS, MySQL, PostgresSQL等の、Pixieのサポートするプロトコルに含まれている必要があります。
Pixieの将来性
Dynamic LoggingというPixieのalpha版の機能を紹介します。Dynamic Loggingとは、ソースコードにロギングの処理を追加することなくロギングを行うことができる機能です。現在はGo言語のみサポートされています。Goのソースコードを通常通りデバッグシンボル込みでコンパイルしていれば、特に事前準備する必要もありません。Dynamic Loggingを用いれば、任意のデバッグしたい関数に注目して、PxLを記述するだけで、Pixieが自動的にその関数をトリガーとするeBPFコードを生成し、その関数の実行された時刻、引数(戻り値)、レイテンシを知ることができます。
Dynamic Logging のユースケース
下記の関数は、ネイピア数eを求める関数です。iterationsに指定された回数だけ級数を足し合わせることで、近似値を求めます。
func computeE(iterations int64) float64 {
res := 2.0
fact := 1.0
for i := int64(2); i < iterations; i++ {
fact *= float64(i)
res += 1 / fact
}
return res
}上記の関数がいつ、どのような引数によって実行されて、レイテンシがどれほどだったか知りたい場合、PxLをこのように記述します。
import pxtrace
import px
# ロギングしたい対象のプロセスのID(Pixie CLIで取得)
upid = "0000000d-0001-2c03-0000-000000143280"
# トレース用の関数
def probe_func():
return [{
'iterations': pxtrace.ArgExpr("iterations"),
'latency': pxtrace.FunctionLatency(),
}]
# トレースポイントをupsert
pxtrace.UpsertTracepoint("test_tracepoint",
"test_table",
probe_func,
px.uint128(upid),
"5m")
# 結果の表示
px.display(px.DataFrame(table="test_table"))Table ID: output
UPID TIME GOID ITERATIONS LATENCY
0000000d-0001-2c03-0000-000000143280 2022-09-21 18:17:14.551660386 +0900 JST 12 1 9.7 µs
0000000d-0001-2c03-0000-000000143280 2022-09-21 18:17:26.787813033 +0900 JST 21 100 6.5 µs
0000000d-0001-2c03-0000-000000143280 2022-09-21 18:17:35.738948099 +0900 JST 14 10000 23.8 µs
0000000d-0001-2c03-0000-000000143280 2022-09-21 18:17:44.975345188 +0900 JST 23 1000000 1.8 ms
0000000d-0001-2c03-0000-000000143280 2022-09-21 18:17:54.17734504 +0900 JST 25 100000000 157 ms
0000000d-0001-2c03-0000-000000143280 2022-09-21 18:18:18.342846193 +0900 JST 49 10000000000 15.6 sDynamic Loggingの改善点
依然alpha版の機能なので、実際に使ってみることで、まだまだ本番環境で実用化するには完璧ではない点が見つかりました。
- ドキュメント上では関数の戻り値もロギングすることが可能とあるが、実際に使ってみるとeBPFコードを生成できない旨のエラーが出る。
- CLI上ではDynamic Loggingテーブルのデプロイに失敗してもエラーの詳細がわからない。
- トレースポイントをupsertする処理と結果を表示する処理をひとつのPxL内に記述する必要がある。
現在は、上記のような課題点も依然存在しますが、よりこの機能が洗練されると、Pixieは本番環境でのデバッグに利用できるツールとしても有力になるのではないかと考えています。
まとめ・感想
今回は、Pixieを用いたアプリケーションのパフォーマンス分析手法を提案し、実際にPixieをVKS上にデプロイして、アプリケーションのパフォーマンス分析をPixieで行う例を示しました。またPixieの将来性として新機能のDynamic Loggingを紹介しました。
新規アプリケーションのみならず、既にPrometheus等のツールやnginxのログ出力等によりメトリクスや通信のログを取得できる状態のアプリケーションでも、それらを一つのツールで完結させたいという目的の場合にPixieを導入する価値があります。Pixieは手軽にインストールできる上にCPU消費も少ないため、本番環境に導入しても問題ないと考えています。
一方、アプリケーションの構成や実装が、Pixieのサポート範囲に含まれていない場合には、Pixieを導入する価値は十分に得られません。そのため、Pixie導入前に、調査したいアプリケーションが、Pixieでサポートされているプログラム言語で実装され、サポートされているデータベースを利用しているかを確認する必要があります。また、デプロイの際にSelf-hosted Pixie Cloudを選択する場合は、Self-hosted Pixie Cloudの消費リソースについて追加で調査を行う必要があるでしょう。
現在alpha版のDynamic Logging機能がより洗練されたり、Pixieのサポート範囲が拡充されたり、Pixie Cloudの導入の自由度が増せば、より導入する価値が高まるので、今後の発展に期待したいです。
本インターンでは、Kubernetesに対する理解を深めるとともに、Pixieの調査・運用を通して、複雑なKubernetesマイクロサービスの運用におけるオブザーバビリティの重要性を実感しました。また、調査結果をプレゼンで人に伝える際のロジックや、発表資料の作り方など、技術面以外での学びもあり、6週間で大きな知識と経験を得ることができました。メンターの中村さんと、第2のメンターとして加わっていただいた須田さんには、毎日一時間のミーティングの時間を設けていただいて、進捗確認や技術的な相談、発表の指導をしていただきました。大変お世話になりました。