
先日、日本のテクニカルライター専門チームによる紹介記事が掲載されましたが、韓国にもテクニカルライターは在籍しています。
テクニカルライターとしてもっとも楽しい瞬間は、新しいプロジェクトをスタートする時です。プロジェクト開始時点においてはすべてがオープンで自由なため、新奇な領域への探究心が刺激されます。難解な技術を学べる技術文書のコンサルティングは、短期間にせよ、とても刺激的な仕事です。この記事では、数ヶ月前にAPIドキュメントのコンサルティングをするうえで学んだことを紹介します。記事のテーマは、新しいプログラム言語のための、コメントベースのAPIドキュメント生成ツール開発についてです。厳密には、「ツール開発」と言うより「最適なツールを探して利用する」ことなので、難解なコードを期待したり、心配する必要はありません。
ソースコード上にコメントで記述したAPIの説明文を、自動で文書化することはありふれた手法です。JavadocやJSDocと言うツールが有名ですが、主要なプログラミング言語であれば、これらのドキュメント生成ツールを利用してドキュメントを作ることができます。どの言語にどのツールを利用できるかあらかじめ把握しておいて、A言語のAPIリファレンスを作りたいという問い合わせがあれば、「その言語ならBツールやCツールが使えますが、プロジェクトの環境を考慮するとCが最適でしょう」などと答えることから、APIドキュメントのコンサルティングは始まります。もちろん依頼元のチームから利用するツールを指定されることもありますが、大抵はこのように始まります。
年初にも、このようなAPIドキュメントコンサルティングの依頼を一件引き受けました。面白いことに、このプロジェクトでは一般的なプログラミング言語ではなく、特定のソリューションでのみ利用される独自のスクリプトを使用していました。このスクリプトは、APIドキュメント生成機能を持っておらず、構文が特殊なため既存のツールを利用することもできませんでした。これでは自動文書生成は難しいかとも思いましたが、まだドキュメントの作成に取り掛かる前だったので、自由にコメントの記述ルールを決められることに希望が湧きました。コメントの記述ルールを単純化すると、いくら新しい言語でもコメント内容を解析することはそれほど難しくありません。こうして、『APIドキュメントツールを持たないプログラミング言語の、ソースコードベースのAPIドキュメントツール作り』が始まりました。本記事では、このプロジェクトにおける取り組みを以下の順で説明します。
- コメント記述ルールの定義
- パーサのカスタマイズ
- コメントデータの文書化
コメント記述ルールの定義
コメント記述ルールの定義段階では、ドキュメントに表示するAPI情報を決め、ソースコード上のコメントをどのように記述するか定義します。通常は、最初にドキュメントに含めるAPI情報について依頼元のチームからヒアリングしてから、ポピュラーなAPIコメントのフォーマットを参考にし、コメントの記法と情報分類タグを決めます。APIの基本説明、パラメータ、対応OS、サンプル画面のスクリーンショットを出力する例を考えてみましょう。該当のAPIコードの上部にコメントブロックを作り、プレーンテキストで基本説明、@paramタグでパラメータ、@osタグで対応OS、@screenshotタグでサンプル画面のスクリーショットファイルのパスを記述するルールを決めます。ソースコードでは、以下のようになります。
参考:以下のソースコードはサンプルです。実際のプロジェクトで使用されたプログラミング言語ではありません。
(**
説明文だけでなく、サンプルコードを表示するメソッドです。
冗長な説明文の代わりにこのメソッドを呼び出します。
@param code 表示するコード。Nullの場合、エラーが発生します。
@os Android,iOS
@screen assets/screenshot1.png
**)
function showMeTheCode code
...
end function Javadocのようなドキュメントツールを試したことがある人であれば、こうした記法に馴染みがあるでしょう。1つ異なるのは、コメントブロックの記法です。多くのプログラミング言語では、コメントブロックを /* ... */ のように 記述しますが、このスクリプト言語では (* ... *) を使用します。また、通常のコメントではなくAPI情報を含むコメントであることを示す場合、コメントブロックの構文にもう1つアスタリスクを加えて (** ... **) と記述します。そのため、今回作成したツールでは、アスタリスクが1つのコメントブロックは無視するようにしました。これらの基本構文を元に、以下のとおり各情報の記述ルールを決めました。
| 識別子 | 意味 | 記述内容 | 記述内容の解析 |
|---|---|---|---|
| (** | APIコメントの開始位置 | 複数行で記述されるテキスト | @がない場合は説明文として解釈し、@がある場合は以下の指示子に従います。 |
| *), **) | APIコメントの終了位置 | なし | なし |
| @param | パラメータの説明 | {name} 説明 (javadoc style) | スペースで区切った左側の文字列をパラメータ名、右側の文字列をパラメータの説明文として解釈します。(複数タグ使用可能) |
| @os | 対応OSのリスト | {os_name}[, {os_name}] | カンマ(,)を区切り文字として使用し、対応OSを並べて記述します。(複数タグ使用可能) |
| @screen | サンプル画面のスクリーンショットのファイルパス | {file_path} | 画像ファイルのパスです。1つのみ記述できます。ソースファイルのルートを基準にした相対パスを指定します。 |
@param はJavadocのようなツールでサポートしているタグなので、パラメータ名と説明をスペースで区切る従来の記法に従いました。一方、 @os と @screen はこのプロジェクトで定義したタグなので、記法も独自に定義します。APIドキュメントをきちんと作るにはもっとタグの種類が必要ですが、サンプルでの定義はここまでとします。このように記述ルールを定義してソースコードに適用すれば、ルールに従ったAPIコメントを抽出・解析することができます。
パーサ(parser)のカスタマイズ
まず、ソースコードでAPIの説明文が記述されているコメントブロックを探して、上記の表で定義したルールを確認することから始めました。何ができるか確認するため、Pythonコードを書いてソースコードを読み込んでみました。思ったよりシンプルな構造だったので、誰かがすでにパーサを開発しているかもしれないと思いました。GitHubで検索したところ、案の定、試してみる価値のありそうなオープンソースプロジェクトが見つかりました。それが、Parse commentsです。JavaScript系言語のソースコードからコメントブロックを抽出し、JavadocやJSDocで定義されたタグを分析して、JSONオブジェクトを生成するツールです。残念ながら、コメントブロックの記法を /** ... */ あるいは /** ... **/ に限定していたため、その点には多少手を加える必要がありました。せっかくなので決まったコメント記法を解析するのではなく、任意のコメント識別子を指定できるように改修しました。必要な作業項目は以下の2点です。
第一に、コメントブロックの記法をオプションで指定できるようにParse commentsを更新しました。3〜4行程度の修正でしたので、ここでは修正内容の説明は省きます。ご興味がございましたら、リポジトリ(https://github.com/lyingdragon/parse-comments)を参照してください。
第二に、新規のスクリプト言語でも、コメントを識別する抽出ツールを実装することです。ソースコードのどこにAPIコメントがあるか識別し、Parse commentsに通知するのが抽出ツールの役割です。/** で始まるコメントを抽出する場合は、Parse commentsの提供しているデフォルトの抽出機能を使用できますが、このプロジェクトでは (** で始まるコメントを抽出する必要があるので、独自の抽出ツールが必要になります。
参考:
(**で始まるコメントを識別する抽出ツールを作れば良いのではと思いがちですが、Parse commentsは抽出ツールから通知された内容が本当にコメントなのか再確認する機能を持っているので、その点にも修正が必要になります。
ユーザー定義の抽出ツールの役割
独自実装したカスタム抽出ツールは、入力ソースコード内の (** で始まり *) で終わるコメントブロックを識別して、以下のプロパティを含むオブジェクトを生成します。
| 名前 | 値 |
|---|---|
| type | コメントブロックの場合は「CommentBlock」、インラインコメントの場合は「CommentLine」 |
| value | 文字列 (** と **) を除くコメント |
| range[] | 文字列内のコメントが占める部分。文字列内のコメントブロックの始点と終点のインデックスを配列で代入 |
| loc{} | 文字列内のコメント位置を行番号/列番号で表したオブジェクト |
| loc.start{} | 文字列内のコメントの始点の位置。 (** を含む |
| loc.start.line | 文字列内のコメントの開始位置の行番号 |
| loc.start.column | 文字列内のコメントの開始位置の列番号 |
| loc.end.line{} | 文字列内のコメントの終了位置。 **) を含む |
| loc.end.line | 文字列内の解析対象の終了位置の行番号 |
| loc.end.column | 文字列内の解析対象の終了位置の列番号 |
記事冒頭のAPIコメントのサンプルに適用すると、以下のような位置情報が表示されます。複数のAPIコメントがあるため、配列として表示されます。
[{
type: 'CommentBlock',
range: [ 0, 138 ],
loc: {
start: { line: 1, column: 1 },
end: { line: 6, column: 3 }
},
value: '\n' +
'説明文だけでなく、サンプルコードを表示するメソッドです。\n' +
'冗長な説明文の代わりにこのメソッドを呼び出します。 \n' +
'@param code 表示するコード。Nullの場合、エラーが発生します。\n' +
'@os Android,iOS\n' +
'@screen assets/screenshot1.png',
}]
rangeやlocからコメント位置を見つけ出すのは少し面倒ではありますが、正規表現を使えばそれほど難しくありません。
ユーザー定義の抽出ツールを適用する
それでは、先に作った抽出ツールをParse commentsと組み合わせてAPIコメントを解析してみましょう。まず、コメントブロックの識別子をオプションで指定できるように拡張した、Parse commentsの修正版をインストールします。
> npm install https://github.com/lyingdragon/parse-comments Parse commentsでソースコードを読み込んで、APIのコメント情報を出力する機能を実装します。簡単に以下のように作成してみました。
apidoc-generator.js
const Comments = require('parse-comments');
const fs = require("fs");
// コメント識別子
const commentPrefix = '(**';
const commentSuffix = '*)';
// ユーザー定義の抽出ツール。APIコメント情報を含むオブジェクトの配列を返します。内部的に commentPrefix と commentSuffix を使用します。
const myExtractor = function (str, options) {
var comments = [];
... 省略 ([ユーザー定義の抽出ツールの役割]で説明した処理を実行
return comments;
}
// Parse-commentsオブジェクトを生成。オプションでユーザー定義の抽出ツールとコメント識別子を入力する。
var comments = new Comments({
extractor: myExtractor, // ユーザー定義の抽出ツールを指定
commentStart: commentPrefix, // コメントブロックの開始文字列
commentEnd: commentSuffix} // コメントブロックの終了文字列
);
// 解析結果の出力。test.sourceは、[コメント記述ルールの定義]でサンプルとして使用したコメントとコードです。
console.log(comments.parse(fs.readFileSync('test.source').toString('utf-8'))); 実行すると、「test.source」のコメントの解析結果が出力されます。
{
"apis": [
{
"type": "Block",
"loc": {
"start": { "line": 1, "column": 1 },
"end": { "line": 6, "column": 2 }
},
"range": [ 0, 138 ],
"raw": "\n説明文だけでなく、サンプルコードを表示するメソッドです。\n冗長な説明文の代わりにこのメソッドを呼び出します。\n@param code 表示するコード。Nullの場合、エラーが発生します。\n@os Android,iOS\n@screen assets/screenshot1.png",
"code": {
"context": {},
"value": "function showMeTheCode code",
"range": [ 139, 166 ],
"loc": {
"start": { "line": 7, "column": 0 },
"end": { "line": 7, "column": 27 }
}
},
"description": "説明文だけでなく、サンプルコードを表示するメソッドです。\n冗長な説明文の代わりにこのメソッドを呼び出します。",
"footer": "",
"examples": [],
"tags": [
{
"title": "param",
"name": "code",
"description": "表示するコード。Nullの場合、エラーが発生します。",
"type": null,
"inlineTags": []
},
{
"title": "os",
"name": "",
"description": "Android,iOS",
"inlineTags": []
},
{
"title": "screen",
"name": "",
"description": "assets/screenshot1.png",
"inlineTags": []
}
],
"inlineTags": []
}
]
} このように、わずか数行コードを追加しただけで、簡単にコメントに記述されたAPIの説明文やタグを解析することができました。一つだけ残念なのは、12行目のcode.contextが空欄になっていることです。code.contextには、コメントが説明しているメソッドのコンテキストが入るはずですが、コンテキストの解析に失敗すると空欄になってしまいます。code.valueプロパティに「function showMeTheCode code」と言うメソッド名が代入されるので、どのメソッドを説明しているかわかりますが、なんだかスッキリしませんね。少し大変ですが、文書化の際にデータを扱いやすくするため、code.valueに「function」を、code.contextに「showMeTheCode(関数名)」と「code(パラメータ名)」を分割して代入するようにします。
参考:解析するプログラムがJavaScript構文の場合、Parse commentsが自動でcode.contextに値を代入します。上記でこの値が空欄なのは、このプロジェクトで使用しているスクリプトがJavaScript構文でないためです。
code.valueをスペースで分割して、code.contextに代入するためのメソッドを作ります。単純な文字列のパーシングなので、コードは省略します。作ったメソッドをpreprocessに指定することで、Parse commentsオブジェクト生成時にコメントを解析する前にこのメソッドが実行されるように設定できます。
api-generator.js
...上略
// Parse-commentsオブジェクトを生成。オプションでユーザー定義の抽出ツールとコメント識別子を入力する。
var comments = new Comments({
extractor: myExtractor,
preprocess: myFunctionParser, // code.valueパーサを追加。function/name/parameterを分離するように実装する。
commentStart: commentPrefix,
commentEnd: commentSuffix}
);
...下略 上記の設定をして実行すると、解析されたメソッドのコンテキストがcode.contextに含まれるようになりました。
...上略
"code": {
"context": {
"type": "function",
"name": "showMeTheCode",
"args": "code"
},
"value": "function showMeTheCode code",
"range": [
139,
166
],
...下略 オープンソースを利用することで、あまり時間をかけずに独自のドキュメント生成ツールがないプログラミング言語のコメントを抽出して、解析することができました。あとは、この抽出したコメント情報を利用してドキュメントを生成するだけです。
コメント情報の文書化
参考:実際のプロジェクトでは、私がよく使うPandocを利用して文書化を実現しましたが、この記事ではより多くの方に馴染みのあるHandlebarsを使用します。
出力するドキュメントのレイアウトを、Handlebarsテンプレートを使って作ってみましょう。HTMLを使用することもできますが、最近の技術ドキュメントのトレンドに則り、Markdownを使ってサンプルテンプレートを作成しました。実際のプロジェクトではもっと複雑になりますが、ここでは単純にAPI名、説明文、スクリーンショット、パラメータのみ出力します。
apidoc.md.hbs
# API reference
## Summary
| API | Description |
|---|---|{{#each apis}}
|[`{{this.code.context.name}}`](#{{id this.code.context.name}}) | {{brief this.description}} | {{/each}}
{{#each apis}}
## {{this.code.context.name}} {{#if (getTagValue this.tags "title" "deprecated")}} <sup>Deprecated</sup>
> **Deprecated**
>
> {{lookup (getTagValue this.tags "title" "deprecated")}}
{{/if}}
> **Summary**
>
> **Script file:** test.script | **Supported:** {{#each (getTagValue this.tags "title" "os")}}{{this.description}}{{/each}}
## Overview
{{this.description}}
{{#each (getTagValue this.tags "title" "screen")}}

{{/each}}
## Parameters
| Name | Description | Type | Default |
|---|---|---|---|
{{#each (getTagValue this.tags "title" "param")}}
| `{{this.name}}` | {{this.description}}| {{this.type}} | |
{{/each}}
{{/each}} Parse commentsが生成したJSONオブジェクトをHandlebars テンプレートに渡し、Markdownファイルを生成します。
apidoc-generator.js
...上略
const handlebars = require("handlebars");
const template = handlebars.compile(fs.readFileSync('apidoc.md.hbs', "utf8"));
fs.writeFileSync('out.md', template({apis: ast})); わかりやすくするために基本的なコードしか書いていませんが、上記で定義したテンプレートを使用するには、 brief 、 id 、 getTagValue など、ユーザー定義のヘルパーをいくつか作る必要があります。そうしたヘルパーがあると仮定すると、出力したMarkdownをGitHubでレンダリングするだけで、オンラインドキュメントが出来上がります。以下は、 showMeTheCode 以外に mycode というAPIをもう1つ追加した結果です。

出力結果を見ると、標準的なAPIリファレンスと大差ない出来です。ただ、Javadocなどのツールとは違って、美的センスに優れたテクニカルライターに重視される「ブランディングを兼ねたルック・アンド・フィール」を取り入れることができます。もちろんフロントエンドやデザインには、もう少し手を加える必要があるでしょう。
次のステップ
すべての作業が終わったら、「今後このツールはどこで活用できるだろう」と想像を膨らませます。今回のコンサルティングではAPIドキュメントのために使いましたが、このツールの最大の特徴は「プログラミング言語によらず、ソースコードからコメント情報を抽出する」ことです。コメントに記述されていれば、必ずしもAPI情報でなくとも良いのです。例えば、バージョンごとのバグフィックスの情報をコメントに記述しておけば、別途ドキュメントを作成しなくとも、コメントを抽出するだけでバグフィックスレポートを生成することだってできます。ソースコード一つでメソッドとドキュメントを同時に管理でき、それぞれの内容を同期しやすいのはもちろん、Jenkinsなどで自動化することも簡単なので、一石二鳥と言えるでしょう。この記事で紹介したアプローチでわかるように、既存のAPIドキュメント生成ツールを使って入出力を修正するよりも、ユーザー定義の抽出ツールやテンプレートを作成する方がずっと簡単に思えます。本当にそうでしょうか。試しにバグフィックスレポートを作ってみましょう。下記は、このアイデアが思いついた際に書いたコメントです。
/**
@version 1.0.0
@bugfix モバイル画面でボタンが重なる問題を解決
@issue MYISSUE-1000
**/
class DisplaySystem
/**
@version 1.0.1
@bugfix iOS xxxバージョンによる音声再生エラーを解決
@issue MYISSUE-1242
*/
public class SoundSystem
/**
@version 1.0.1
@bugfix Fetchモジュールの動作エラーを解決
@issue MYISSUE-1243
*/
public class CoreSystem 次にテンプレートを設計します。テンプレートのコードは、ずっと簡単なのですぐ作成できます。バージョンごとにコメントを集めるヘルパーを実装するのに多少時間がかかるだけです。
# Bug fixes
{{#each (uniqueVersion apis)}}
## {{ @key }}
{{log this}}
{{#each this}}
`{{this.code.value}}`
- {{#each (getTagValue this.tags "title" "bugfix")}}{{{this.description}}}{{/each}}
- Related issue: {{#each (getTagValue this.tags "title" "issue")}}{{{this.description}}}{{/each}}
{{/each}}{{/each}} 一瞬で以下のようなバグフィックスレポートを作ることができました。ソースコードだけでなんでも解決したい開発者には、なかなか役立つツールだと思います。

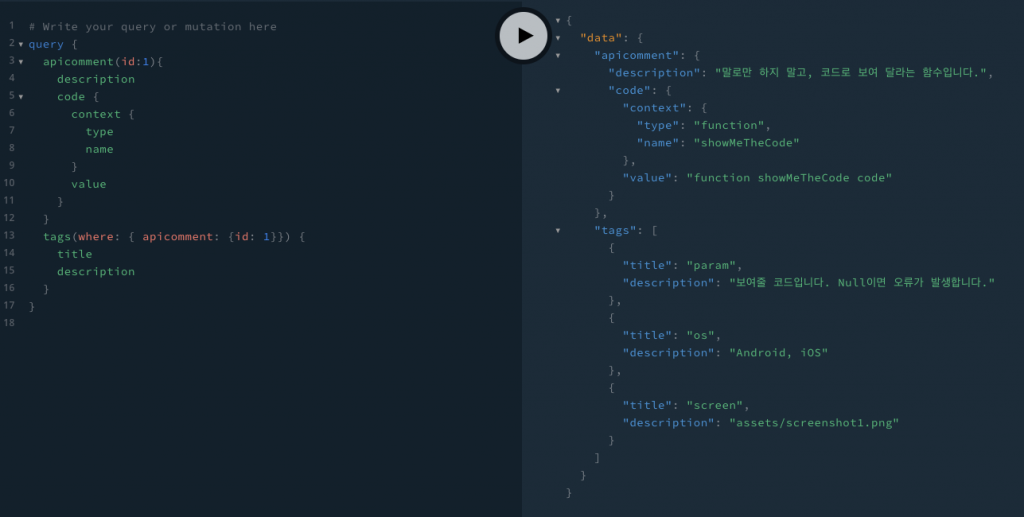
では、テクニカルライターとしてはこのツールをどう活用できるでしょうか。昨年の投稿記事「ドキュメントエンジニアリングとAPIドキュメンテーション」で提案したソリューションを、もう一度思い返してみましょう。記事で提案した内容を要約すると、「ソースコードがない場合は、自分でAPIの仕様を定義してマークアップに変換すること。ソースコードがある場合は、Doxygenを使ってコメントに記述されたAPI情報をマークアップ言語に変換すること」でした。これは、コンテンツをグループ化して最終的なドキュメントを同じフォーマットにすることで、ビュー(出力形式)の変化に素早く対応するためです。前回の記事では詳しく説明していませんでしたが、ソースコードに書かれたコメントをマークアップに変換する作業はかなり煩雑です。ところが、今回のプロジェクトを進めるうえで、そのような煩雑な工程をスキップして、ソースコードに書かれたコメントを直接API仕様書に組み込めるようになりました。つまり、Parse commentsの出力結果を、APIリファレンスのフレームワークとして活用できるのです。テクニカルライターでありドキュメントエンジニアとしての私の次の計画は、以下の画像のようにAPIコメント情報をstrapiのようなヘッドレスCMS(content management system)で管理し、API仕様書を共有し、フロントエンドの自律性をさらに高めることです。
また興味深い成果を得られたら、こちらのブログで紹介したいと考えています。お楽しみに!