
はじめに
こんにちは、東京大学情報理工学系研究科修士1年の兵藤弘明です。
私は、今回のインターンでNeural Audio Codecを用いたテキスト音声合成モデルの性能検証に取り組みました。
この記事では、その内容について紹介します。
背景・課題
はじめに、今回取り組んだテーマに関連する技術であるテキスト音声合成とNeural Audio Codecについて説明します。
まずテキスト音声合成(Text-to-speech; TTS)とは、自然言語で記述されたテキストを対応する音声に変換する技術です。例えば、入力として「今日はいい天気ですね。」というテキストを受け取ると、TTSモデルは「今日はいい天気ですね。」と人間が発話したような音声データを出力します。TTSはその汎用性の広さからコールセンター、駅の案内放送、動画コンテンツ作成に至るまで日常生活の様々な場面で使われています。
次にAudio codecとは、音データを圧縮するためのアルゴリズムや方式のことです。有名なものとしては、MP3やAACなどがあります。Audio codecを用いて音データを圧縮することで、ストレージ容量を節約したり、ネットワーク上でのデータ転送速度を向上させることができます。これらの利点から、音の品質を保ちつつデータサイズを小さくするため、様々なAudio codecが研究されてきました。その中で近年、Audio Codecの性能をさらに引き上げるためにニューラルネットワークを使用するNeural Audio Codecと呼ばれる手法が注目されています。
Neural Audio Codecでは従来の信号処理ベースの手法と異なり、ニューラルネットワークを使用してデータドリブンで音データの特徴を学習します。この方法により、従来法と比較して高い音声品質を維持しながらデータサイズを大幅に削減することができます。例えば、今回のインターンで使用したDescript Audio Codec[1] という手法は、音声品質の低下を最小限に保ちつつデータサイズを90分の1程度にすることが可能とされています。また、Neural Audio Codecの利点として、あらゆる音信号を同一の枠組みで学習可能であるという点が挙げられます。これは、音声や音楽、環境音などの多様な音信号を同じモデルで圧縮・復元できることを意味しています。
これらの利点を持つNeural Audio Codecは様々な音声系タスクに応用されています。例えば、音声や音楽のサンプルから続きとなる音を生成する AudioLM[2] や、拡散モデルと組み合わせることでTTSを行う NaturalSpeech 2[3] などの応用例があります。これらのモデルにおいてNeural Audio Codec は音信号の情報を持つ中間表現として使用されています。その他の利点として、少ないパラメータ数で音声の特徴を詳細に捉えることができる点や、離散表現であるため自己回帰モデルであるTransformerを用いたいわゆる言語モデル的アプローチとの相性が良い点が挙げられます。これら2つは特にTTSなど他の生成モデルと組み合わせる際には大きなメリットとなります。
Neural Audio Codecを用いたTTSにはいくつかの先行研究があります。例えば、Transformerをベースとした時間方向の自己回帰モデルを採用したVALL-E[4]やSpear-TTS[5]、拡散モデルを用いたNaturalSpeech 2などが挙げられます。これらのモデルは、Neural Audio Codecの表現力と大量の学習データ量を活かして高い品質の音声合成を行うことが可能です。しかしながら、学習コストが高いことや、自己回帰モデルや拡散モデルを採用しているが故に推論に時間がかかるといった欠点が存在します。
目的
そこで本インターンでは、Neural Audio Codecの高い表現力を活かしながら高速に動作するTTSモデルについて検討を行いました。
具体的には、時間方向に対して自己回帰をしない(非自己回帰型の)FastSpeech 2[6]などのモデルは、一般的に自己回帰モデルや拡散モデルと比べるとやや品質面で性能が劣ると言われますが、これらのモデルと比べてより高速な推論が可能であるため、今回は非自己回帰型の高速なTTSモデルとNeural audio codecを組み合わせたモデルについての検討を行いました。
実験
前述の通り、今回のインターンの大きな目的の1つは高速に動作する非自己回帰型のTTSモデルと表現力(入力音声に対する再構成の品質)が高いNeural Audio Codecを組み合わせた際の性能の検証です。
そこで実験では、非自己回帰型のTTSモデルとして代表的なFastSpeech 2と今年6月に発表されたNeural Audio Codecモデルの1つであるDescript Audio Codec (DAC)を組み合わせたモデルを実装し、その性能を検証しました。
DACはResidual vector quantization(RVQ)という手法をベースとした最先端のNeural Audio Codecモデルの1つです。RVQでは、音声の圧縮表現としてフレーム(10ms程度の短い時間単位)ごとにn個の離散的なcodebook(離散codebook)を保持します。codebookは各nに対してそれぞれK種類のクラスを持っており、例えば今回のDACではn=9, K=1024, 1秒間のフレーム数が86程度なので1秒の情報量はおよそ9 * 10bit (2^10=1024) * 86 / 1000~= 8kbpsとなります。入力として想定される44.1kHz/16bitでサンプリングされた音声は705.6kbpsもの大きな情報量を持つため、高い圧縮率が実現できていることがわかると思います。
RVQを採用したNeural audio codecには他にもSoundStream[7]やEncodec[8]がありますが、それらの後続のモデルであるDACは従来法の問題点のいくつか(例えばcodebook学習の安定性)に対する改善策を提案しており、より高品質な圧縮再構成を可能としています。
今回のインターンでは、著者による事前学習済みモデルが公開されているためこちらを使わせていただきました。
FastSpeech 2は、2020年に発表された音声合成分野では代表的な非自己回帰型TTSモデルの1つです。非自己回帰型モデルであるがゆえに学習・推論が高速であることのほか、音声の高さや大きさを制御できることなどの利点があります。
モデルの学習・評価用のデータセットにはLibriTTS corpusを使用しました。
提案法
前述のようにDACは、圧縮した音声表現として離散codebookを保持します。そのため、TTSとして一番シンプルな方法はこの離散codebookをテキスト情報から推定する方法になります。
一方、実際にDACを通して音声信号を復元する際には離散codebookを一度連続値に変換し、得られた表現(連続codebook)をDACのdecoderに入力することで再構成された音声信号を出力します。そのため、上記の離散codebookを推定する方法以外にも連続codebookを推定する方法も考えられます。
そこで、それぞれの手法に対する検討として以下の二つの提案法を実装し、学習を行いました。
提案法1: 連続codebookの推定
まず1つ目は、テキストからフレームごとの連続codebookをL1 lossによる回帰で推定する方法です。
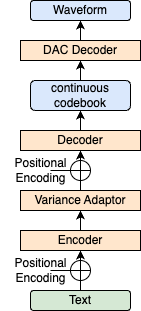
この手法では、まずテキストから抽出した音素の情報を入力し、従来のFastSpeech 2と同様にEncoderとVariance Adaptorを用いて特徴量にピッチや強弱の情報を付加します。その後段のDecoderでは、従来のFastSpeech 2ではMel Spectrogramに対して回帰を行うのですが、今回の手法では代わりに学習済みのDACから生成した正解連続codebookに回帰します。
推論時には、モデルから推定された連続codebookをDACのDecoder (図の DAC Decoder) で展開することで音声を合成します。
2: 離散codebookの推定
次に、テキストから離散codebookを多クラス分類で推定する方法です。
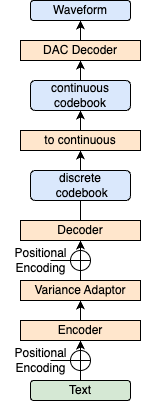
離散codebookはフレームごとに9チャンネル分の値を持ち(n=9)、それらは0から1023までの整数値を取ります (K=1024)。従って、離散codebookの推定は1024クラスの分類問題となります。
学習時には、従来のFastSpeech 2の損失関数に加え、モデルのdecoderが推定した離散codebookのクラスの確率分布と正解クラスの間のCross Entropyを取ることによって離散codebookを推定するモデルを学習します。
推論時には、モデルが推定した離散codebookを連続codebookに変換し、DACのdecoderに通すことで音声を合成します。
結果
DACの事前学習済みモデルによって再構成した音声(再構成音声)と、提案法によるTTSモデルで合成した音声(合成音声)の例は以下の通りです。
提案法1: 連続codebookの推定
- 再構成音声(≒正解の音声)
- 合成音声(音量注意)
合成音声の言語情報に関しては何かを喋っているということはわかるものの、発音が曖昧になっている箇所があります。
合成音声の声質に関しては、正解話者のそれを再現できておらず、正解の声質にかかわらずロボットのような音声になっています。
提案法2: 離散codebookの推定
- 再構成音声(≒正解の音声)
- 合成音声
合成音声の言語情報に関しては、発話内容をある程度聞き取ることができます。
合成音声の声質に関しては、少し正解話者のそれが反映されていますが、全体的にピッチ情報(声の高さ)が抜け落ちたような音声になっています。
これらの結果から、シンプルにFastSpeech 2のモデル構造を用いてDACの中間表現を推定するモデルの性能には限りがあることがわかりました。
分析・考察
合成音声の品質改善のため、比較的性能が良かった離散codebookを推定する手法について分析を行いました。
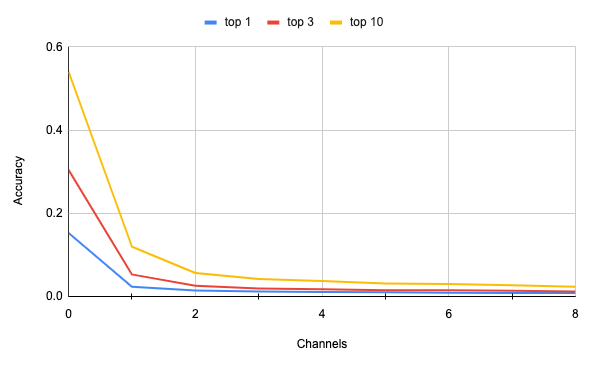
はじめに、連続codebookの推定モデルにおいて推定された離散codebookの各チャンネルの正答率を算出しました。
結果を以下のグラフと表に示します。
なお、グラフ・表の中のtop kの正答率とは、モデルの推定確率の上からkクラスに正解のクラスが含まれている確率を指します。
|
0
|
1
|
2
|
3
|
4
|
5
|
6
|
7
|
8
|
|
|---|---|---|---|---|---|---|---|---|---|
| top 1 | 0.152 | 0.023 | 0.014 | 0.011 | 0.010 | 0.010 | 0.009 | 0.008 | 0.008 |
| top 3 | 0.304 | 0.052 | 0.025 | 0.019 | 0.017 | 0.01487 | 0.014 | 0.013 | 0.011 |
| top 10 | 0.539 | 0.119 | 0.056 | 0.041 | 0.037 | 0.03102 | 0.029 | 0.027 | 0.023 |
以上の結果から以下のような傾向が読み取れます。
- 正答率はチャンネル番号に対して単調減少する傾向がある。
- 0番目のチャンネルの正答率は他のチャンネルより顕著に大きい。特にtop10で見ると54%程度で正答しており、1024クラスあることを考えるとそれなりに高い正答率と言える。
このような傾向には、DACにおける離散codebookの算出方法(つまり、RVQの性質)が関係している可能性があると考えました。
大まかに説明すると、DACをはじめとするRVQに基づく離散codebookは、正解音声と復元音声の差分を次のチャンネルにエンコードする、という処理を繰り返すことで得られます。従って、チャンネル番号が小さいほど正解音声を本質的に表す情報を持っている可能性があります。
この仮説を検証するため、正解の離散codebookのうち、特定の1チャンネルだけを用いて音声を復元する実験を行いました。以下に生成音声の例を示します。
|
再構成音声(チャンネル0-8)
|
チャンネル0 |
チャンネル1
|
チャンネル2
|
チャンネル3
|
チャンネル8
|
|---|---|---|---|---|---|
|
|
|
|
|
|
|
これらのサンプルから、0番目のチャンネルの情報のみを用いた場合でもある程度音声を復元できること、0番目以外のチャンネル単独での音声復元はほとんど上手くいかないことがわかりました。
上記のRVQの性質を考えると、離散codebookの0番目のチャンネルに一番本質的な情報が載っていることは理論的にも納得のいく結果だと考えられます。逆に、1番目以降は0番目の情報が正しくない場合単体ではほとんど意味をなさないことが示唆されました。
また、前半のチャンネルほど保持する情報量が多いため、前半の一部のチャンネルだけを用いて音声を復元する実験を行いました。
|
再構成音声(チャンネル0-8)
|
チャンネル0 |
チャンネル0-1
|
チャンネル0-2
|
チャンネル0-4
|
チャンネル0-6
|
|---|---|---|---|---|---|
|
|
|
|
|
|
|
この結果から、多くのチャンネルを使うほど再構成の性能は上がるものの、TTSモデルで推定する上では前半の半分くらいのチャンネルを正解できればかなりの性能が出そうだということがわかりました。
改善案
以上の実験・分析の結果から、Codebookの特性を踏まえた以下のような改善案を考えています。
チャンネル方向に自己回帰を行うモデル
DACの離散codebookは、正解音声と復元音声の差分を次のチャンネルにエンコードする、という処理を繰り返すことで得られます。また離散codebookに関する分析結果から、0番目以外のチャンネル単独での音声復元が上手くいかないこと、より前にあるチャンネルも用いて音声を復元する方が良い結果が得られるということがわかりました。
これらの発見を踏まえ、チャンネル方向に自己回帰を行うことで、前のチャンネルの情報に基づいて次のチャンネルを推定するモデル構造は有効であると考えられます。
拡散モデル
実験を行った二つのモデルでは、ロスがある程度収束しているにもかかわらず十分な品質の音声を得ることはできませんでした。この結果に対する一つの仮説としては、モデル自体の表現力が足りていなかったということが考えられます。これに対して、シンプルなL1回帰と比較して表現力が高く複雑な分布を学習できるDiffusion modelを採用することによって品質が改善できる可能性があると考えられます。
先行研究としては、拡散モデルとNeural Audio Codecを組み合わせた手法として、NaturalSpeech 2[3]などが存在します。拡散モデルの推論速度は一般的に高速ではないため、当初の目的であった高速な推論のできるNeural Audio Codec TTSモデルという目的からはやや外れてしまいますが、品質を改善するという意味では重要なアプローチだと考えられます。また、Consistency model[9] など拡散モデルの高速化手法については研究が進んでいるため、合わせて検討できると思います。
まとめ
今回のインターンでは、従来のNeural Audio Codecを用いた高品質なTTSモデルの高速化を目指して、非自己回帰型TTSモデルであるFastSpeech 2と最先端のNeural Audio CodecであるDescript Audio Codecを組み合わせたモデルについて実験を行いました。
実験結果から、今回検討した手法では高速化はできるもののシンプルな方法であるが故に品質面に課題があることが明らかになりました。また、モデルの分析の結果、Descript Audio Codecの離散codebookはRVQの学習構造から想起されるように0番目を代表とした前半のチャンネルに再構成に必要な本質的な情報が詰まっていること、逆に後半のチャンネルは半分程度存在していなくてもかなりの精度で再構成が可能であることが示されました。
今後の展望としては、上記改善案に基づいた実験・評価ができると良いと考えています。
最後に
今回のインターンでは、ASPチームをはじめとするLINEの皆様から様々なことをサポートいただき、研究を楽しみながら大きく成長することができたと感じています。
特にメンターの白旗さんからは、研究の進め方や実験など、様々な面で非常に多くのアドバイスをいただきました。
この場を借りて、皆様に改めて感謝申し上げます。本当にありがとうございました。
参考文献
[1] Kumar, Rithesh, et al. "High-Fidelity Audio Compression with Improved RVQGAN." arXiv preprint arXiv:2306.06546 (2023).
[2] Borsos, Zalán, et al. "Audiolm: a language modeling approach to audio generation." IEEE/ACM Transactions on Audio, Speech, and Language Processing (2023).
[3] Shen, Kai, et al. "Naturalspeech 2: Latent diffusion models are natural and zero-shot speech and singing synthesizers." arXiv preprint arXiv:2304.09116 (2023).
[4] Wang, Chengyi, et al. "Neural codec language models are zero-shot text to speech synthesizers." arXiv preprint arXiv:2301.02111 (2023).
[5] Kharitonov, Eugene, et al. "Speak, read and prompt: High-fidelity text-to-speech with minimal supervision." arXiv preprint arXiv:2302.03540 (2023).
[6] Ren, Yi, et al. "Fastspeech 2: Fast and high-quality end-to-end text to speech." arXiv preprint arXiv:2006.04558 (2020).
[7] Zeghidour, Neil, et al. "Soundstream: An end-to-end neural audio codec." IEEE/ACM Transactions on Audio, Speech, and Language Processing 30 (2021): 495-507.
[8] Défossez, Alexandre, et al. "High fidelity neural audio compression." arXiv preprint arXiv:2210.13438 (2022).
[9] Yang, Song, et al. "Consistency Models." arXiv preprint arXiv:2303.01469 (2023).