
こんにちは, 今年の4月からLINEのゲームセキュリティチームに新卒として入社しました草間好輝( @yocchii_ )です.
ゲームセキュリティチームは. 主にゲーム内で発生する不正行為の対策を目的としたチームです. 例えばゲームチート解析(バイナリ/パケット解析)やクライアントセキュリティモジュールの提供(例:ORK(https://engineering.linecorp.com/ja/blog/ork-vol-1/)), ゲームサーバでの疑わしい動作の分析, リリース前のゲームのセキュリティ診断などです.
本記事では, 同じゲームセキュリティチームのメンバーであるWah Dekaiと共にLINE GAMEのチート分析の一貫で行っているランダムフォレストを用いたabuser検知について解説したいと思います.
[関連記事:https://engineering.linecorp.com/ja/blog/monitoring-to-prevent]
背景
ゲームセキュリティチームでは(https://engineering.linecorp.com/ja/blog/monitoring-to-prevent-game-cheating/)の通り, ゲームサーバ側でユーザーのログを分析し, 日々不正なログがないかをチェックしています. 以下はチェック項目の例です.
- 1回のプレイでゲーム内の通貨を想定以上に獲得している
- 1回のプレイでスコアを想定以上に記録している
- 極端に短い時間でゲームをクリアしたログがある
- クリア(WIN)ログはあるが, プレイの詳細記録はない
例えば, 1回のプレイで「ゲーム内の通貨を想定以上に獲得しているユーザー」や「スコアを想定以上に記録しているユーザー」は, メモリチート系やパケット改ざん系の不正をした可能性があります. よってこの指標をモニタリングし, 急激に数値が増加したらメモリチート系やパケット改ざん系のabuserだと推測できます.
ゲームサーバーにはコインの獲得数, プレイ時間などを含めた多くのユーザー情報がありますが, 現在は上記のような一定の情報のみ(例えば獲得コイン数のみ)でabuserかどうかを判断しています. 例えば「一定時間内に獲得したコイン数が10000以上ならabuserだと判断する」というruleはシンプルでわかりやすいですが, 10000という閾値が解ればその迂回は容易です。ゲームサーバーには他にも様々な要素の膨大なログが保存されているため, 我々はそのログを活用し, 総合的にabuserを判断できないかと考えました. そしてこれらのログからランダムフォレスト(Random Forest)を用いてabuserかどうかを判断するモデルを作成しテストを行いました. 今回はその取り組みについて解説したいと思います.
アプローチ
一般的なabuser検知は複数のruleによって実装されています。例えば「一度の獲得コイン数が10000以上ならばabuserと判断する」はひとつのruleです。このようなruleをいくつも組み合わせることで不正なユーザーを検知します。ruleによる検知は明確で高速ですが, 大きく2つの問題があります。ひとつは新しいabuserが増えるたびにruleを新規に追加しなければならない、もうひとつはabuserが閾値を推測することで容易に迂回できてしまうことです。事実, サービス提供側のBAN基準がabuser側に漏洩してしまい, BANされないギリギリの閾値を設定したチート行為が行われていた事例がありました. このような問題に対処するため, ランダムフォレストを用いてより高精度に検知を行いたいと考えました.
一般的にSecurityのデータセットには不正なユーザーであることを示すラベルはありません. よって正常データのみを学習させて, 正常から外れたデータをabuserとして検知するという, いわゆる異常検知がよく用いられますが, 我々には今までruleによりBANしたユーザーのログがあるため, それをラベルとして教師あり学習を行いました.

特徴としてレベル, コイン, 経験値, プレイ時間などを渡すと, 結果としてNon-Abuser/Abuserの確率を返す. 例えばレベル1なのにコイン数が多かったり, プレイ時間が少ないのにレベルが高かったりするとabuserの可能性が高いと判断してくれるプログラムを作ることが目的となります.
データ
ゲームサーバにはuserに関する様々なデータが保存されており, 今回はその中の5グループ, 26種を特徴量として使用しました. 主にユーザー, プレイ, ランク, そしてログインに関する情報です.
| 情報 | 説明 |
| ユーザー情報 | 現在のレベル, 経験値などユーザーに関する情報 |
| プレイ情報 | 一度のプレイでのコンボ数などプレイに関する情報 |
| ランク情報 | ゲーム内のランキングに関する情報 |
| ログイン情報 | ログイン回数やログイン日時などログインに関する情報 |
| その他 | その他の情報 |
ラベル付けに関してはAirAirmor(https://air.line.me/)の情報や, 今までのBANユーザーのログを教師データとして活用しました. また今回の学習に用いたデータセットにおいては, 普段abuserとして判断する際に基準となるデータ(特徴)は除きました. これらを含めるとすでに運用しているruleと等価な(極めてシンプルな)決定木が作成されてしまうためです.
今回は研究目的なのでデータセットの一部, ユーザーデータからランダムに抽出した94,833件のnormalと, 15,165件のabuserを使用しました.
| 0(normal) | 1(abuser) |
| 94,833 | 15,165 |
モデル
ランダムフォレスト(Random Forest)のベースとなっているのは決定木です. 決定木は木構造で分類を行うモデルで, これらを組み合わせたものがランダムフォレストです. 複数のモデル(決定木)を組み合わせていることからアンサンブル学習アルゴリズムの一種といえるでしょう.

ランダムフォレストを採用した理由は, 1.いくつかのアルゴリズムを試した結果もっとも良い精度が出た, 2.分析が目的のためFeature Importanceも調査したい, 3.決定木をベースとしているため判断基準がある程度明確である, の3つです. 今回の調査はデータセットの分析も兼ねており, これらの理由によりランダムフォレストを採用しました.
では, 分析していきましょう. まず初期モデルの精度を調べるため, モデルのTrain_test_Splitを実行しました.
Train_test_Split
training = pd.DataFrame(training)
training['abuser'].value_counts()
# 一部の特徴名を伏せています
headers = ['lv', 'exp', 'fe1', 'fe2', 'fe3', 'tutorialflg', 'fe4', 'playcnt', 'logincnt', 'cntlogincnt', 'maxlogincnt', 'rank1cnt', 'rank2cnt', 'rank3cnt', 'fe5', 'fe6', 'fe7', 'fe8', 'gamefeature1', 'gamefeature2', 'fe9', 'avgcoin', 'gamefeature3', 'gamefeature4', 'invcnt']
y = training.abuser
train_Xi, val_Xi, train_y, val_y = train_test_split(training, y,random_state=1,train_size = 0.8)
print(val_y.value_counts())
print(train_y.value_counts())
val_X = val_Xi[headers]
train_X = train_Xi[headers]
データセットをトレーニングデータとテストデータに分割し, 初期モデルのOverfittingもしくはUnderfittingのチェックを行います. データは8割がトレーニングデータ, 2割がテストデータ, それぞれのサイズは以下になります.
| 0(normal) | 1(abuser) | |
| Training Set | 75,925 | 12,073 |
| Validation Set | 18,908 | 3,092 |
まずはパラメーターチューニングなしのモデルをトレーニングし, テストデータで結果を確認していきます.
Result
rf_train_accuracy: 0.999306802427328
rf_train_fscore: 0.9974694046878241
rf_val_accuracy: 0.9851363636363636
rf_val_fscore: 0.9459235984785845
トレーニングデータの精度(rf_train_accuracy)が99.93%に対して, テストデータ(rf_val_accuracy)では98.51%と少し低いことがわかります. ちなみにF値(rf_train_fscore)も99.75%に対して, テストデータ(rf_val_fscore)では94.59%と大幅に低くなりました. それぞれの検知数は以下になります.
| Training Set | Prediction | ||
| abuser | non-abuser | ||
| Labels | abuser | 12,022 (TP) | 51 (FN) |
| non-abuser | 10 (FP) | 75,915 (TN) | |
| Validation Set | Prediction | ||
| abuser | non-abuser | ||
| Labels | abuser | 2,860 (TP) | 232 (FN) |
| non-abuser | 95 (FP) | 18,813 (TN) | |
注目すべきはテストデータでのFalse Negativeの多さです. モデルはトレーニングデータに非常によく適合していますが, テストデータではあまり適合していないように思えます. またトレーニングデータの精度とテストデータの精度を見ると分かる通り, トレーニングデータの精度が少し高い傾向にあります. これはOverfittingの兆候を示しているため, 次の章ではパラメーターチューニングを行いこの2つのデータ間でのバランスをとり, モデルを最適化していきます.
また話は少しずれますが, 各特徴量の重要度(importances)にも触れておきましょう.
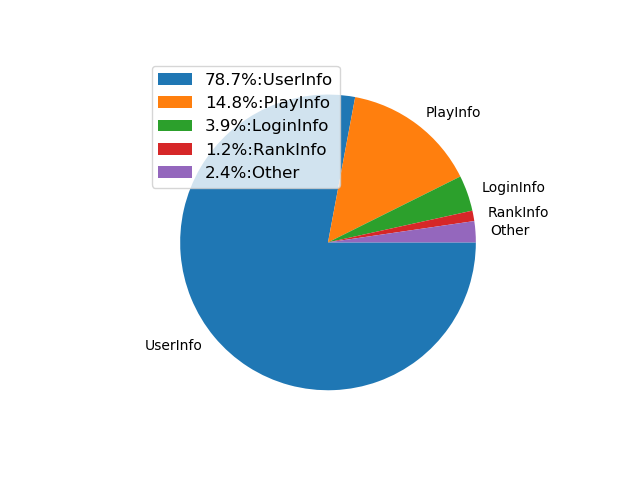
この図を見て分かる通り, ユーザーの情報が重要度の大部分を占めています. このユーザー情報の内訳を見てみるとコインに関する情報が多いことがわかります. その原因として正解ラベルをruleによる検知結果から得ており, 主にコインの情報を使ったruleに関するものが多く含まれているからと推察できます.
パラーメータチューニング
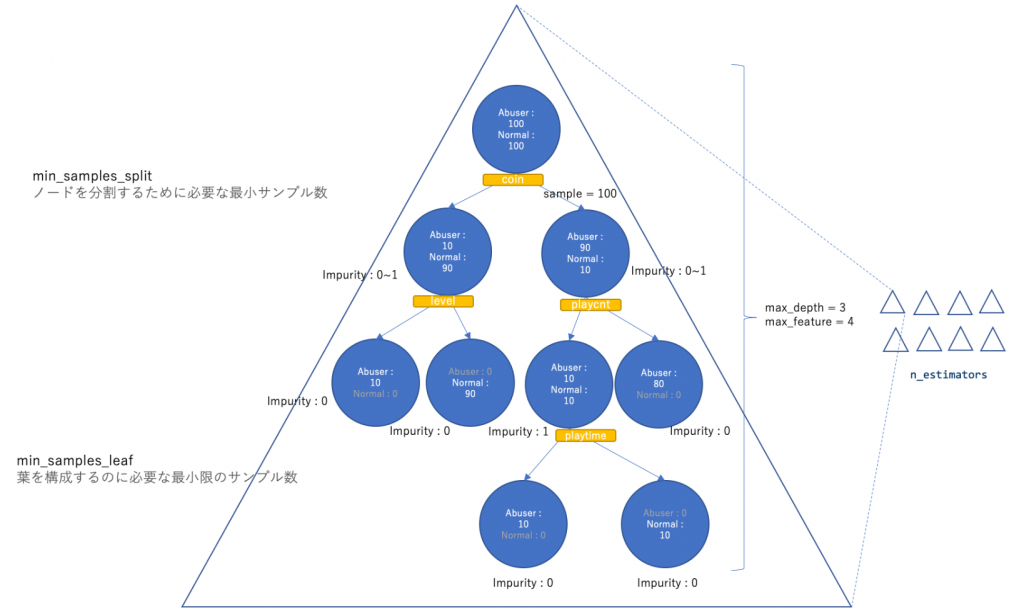
ここからはパラメーターチューニングについて解説していきます.まずは以下のパラメーター(ハイパーパラメーター)を独立に調査し, 最適な値を調べていきましょう.
- max_depth
- n_estimators
- max_feature
- min_samples_split
- min_samples_leaf
これらをイメージとして説明した図が以下です.
最適なハイパーパラメーターを探す方法はいくつかあり, 代表的なものはグリッドサーチとランダムサーチです. グリッドサーチは各パラメーターのパターン全てを試す方法で良い値が見つけられますが, 探索に時間がかかります. 対してランダムサーチは各パラメーターをランダムに組み合わせて試す手法で, 時間をかけずに"それなりの"値を見つけられますが, もっとも良い値とは限りません. 今回はランダムサーチでパラメーターを探索します. ちなみにハイパーパラメーターの探索には他にも様々な手法があります. [https://en.wikipedia.org/wiki/Hyperparameter_optimization]
ではハイパーパラメーターの調査を始めましょう.
まずはTree_depth(max_depth)です. これはツリーの深さに関するパラメータです.
ツリーの深さが1から30までの時のAUCをチェックしました. AUCとは縦軸にTPR(True Positive Rate)、横軸にFPR(False Positive Rate) の割合をプロットした時の範囲のことで, 一般的にAUCの面積が大きいほど精度が良い事を意味します.
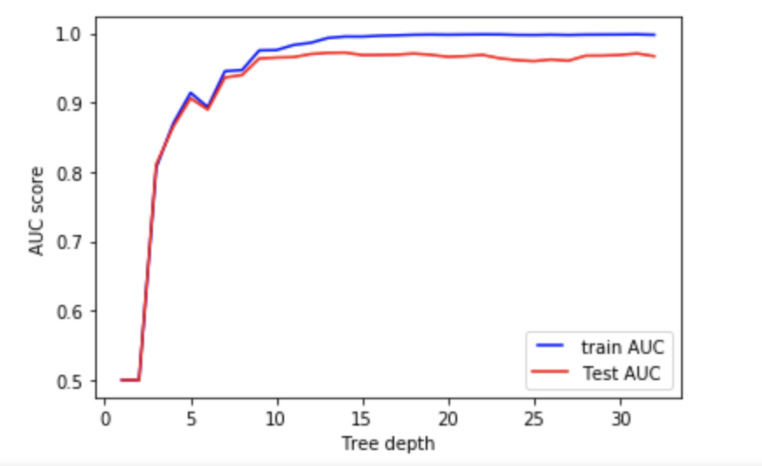
ツリーの深さを分析すると, 範囲が10〜15を超えたところでTest AUCのパフォーマンスがわずかに低下することがわかります. つまりOverfittingの可能性があります. 逆に10〜15未満の範囲ではAUCは低くなり, つまりは検知率が芳しくありません. そのため10〜15あたりが適切であると判断できます. このようにAUCと各パラメーターのグラフから適切な値を探索できます.
次にn_estimatorsです.
ランダムフォレストは複数の決定木から成っていますが, この決定木の数に関するパラメーターがn_estimatorsです. 使用するTreeが多いほど一般により堅牢で正確なモデルになるといわれていますが, Overfittingと計算速度の問題が発生するため他のパラメータとのトレードオフで決めることが多いです.
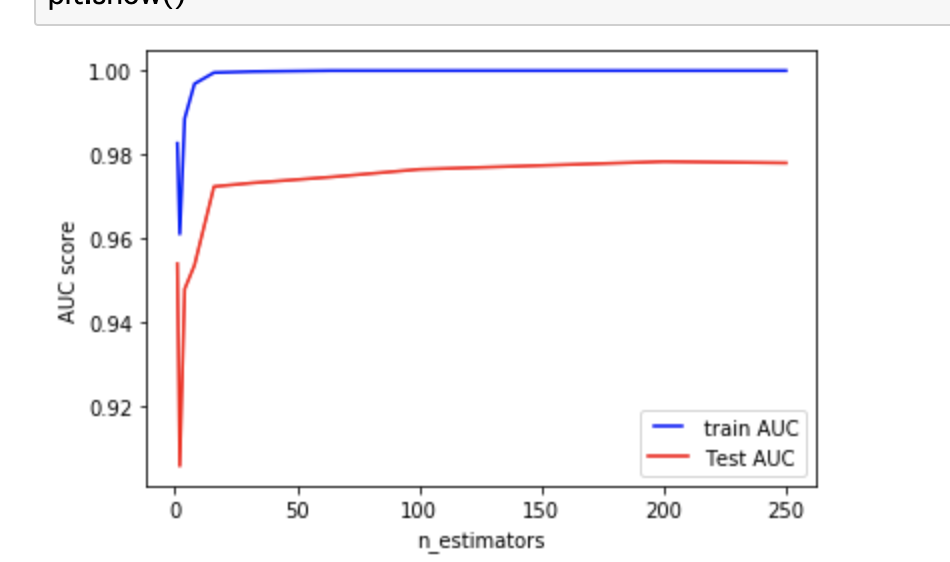
n_estimators=25以降で安定し, それ以降もTest AUCの精度はわずかずつ向上していきます. 25以降ならあまり違いはないようです.
次にmax_featureです.
今回使用している特徴は26であるため, この特徴数が適切かどうかを調べましょう.
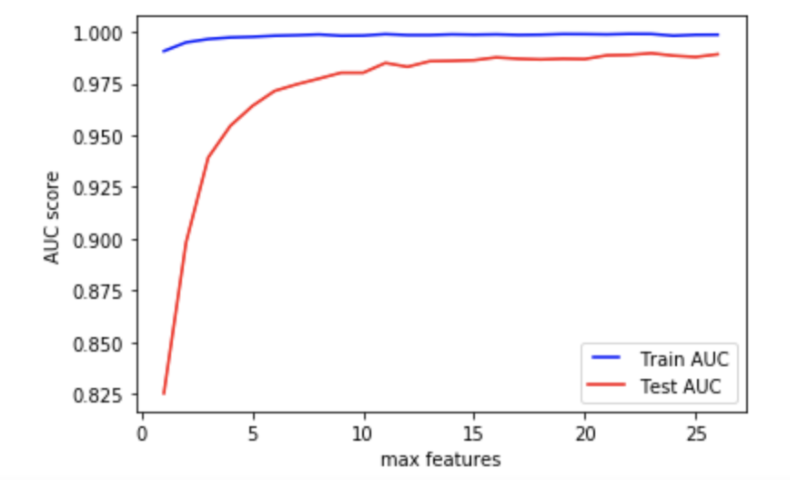
max_features=15以上は問題なさそうです. なだらかですが, max_featuresが26へ向かうにつれてTest AUCも少しずつ増加します.
最後にmin_sample_splitとmin_sample_leafです.
この2つは似ていますが, min_sample_splitはノードを分割する時の最小データ数, min_sample_leafはノードを構成する最小データ数です. 例えばmin_sample_leafが小さい値(仮に1とする)だった場合, "2つだけの"データを持つノードをさらに分割し, "1つだけの"データを持つノードを2つ作る可能性があります. より細分化できるわけですが, それはつまりOverfittingのリスクを増加させます.
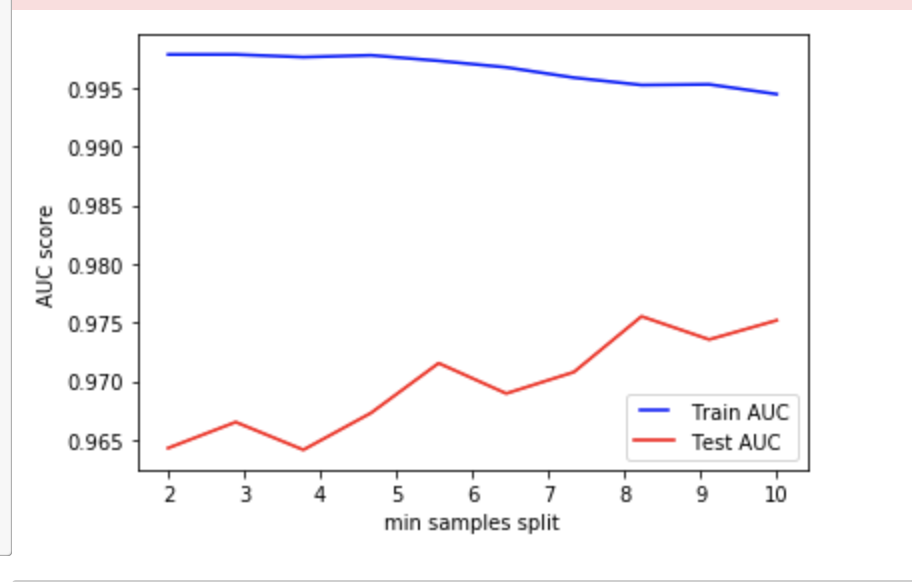
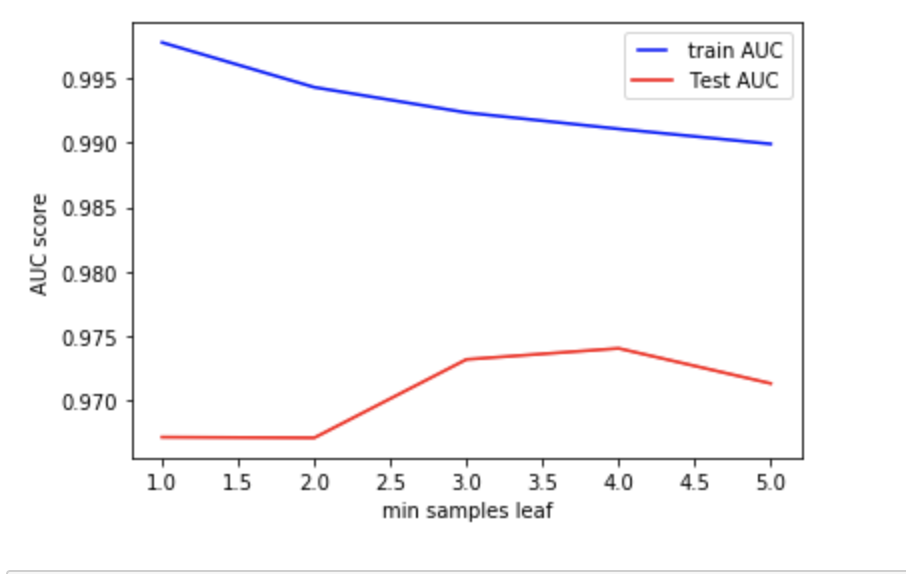
min_samples_leafのデフォルト値は1で, min_samples_splitは2です. 2つのパラメーター変数に基づいてAUCスコアをみてみるとモデルのパフォーマンスがとても低くなっていることがわかります. これは初期状態ではOverfittingが発生していると考えられます. Train AUCがなるべく下がらず, しかしTest AUCが上がるような値を候補として考えます.
- 探索範囲の設定
各パラメーターを独立に変化させた場合を例にパラメータチューニングについて解説しました. 各パラメーターに対してめぼしをつけた範囲でランダムサーチを行えば, それなりに良い結果が得られます. しかし, 計算時間をある程度許容できるならば, より広い範囲に対してランダムサーチを行うことでさらに良い組み合わせを探索できます. 例えば以下のような範囲で探索します.
- n_estimators: 1 to 250
- max_features: 1 to 26
- max_depth: 1 to 200
- min_samples_split: 2 to 20
- min_samples_leaf: 1 to 20
この範囲で探索するととても時間がかかりますが, かなり精度の良い組み合わせが見つかります.
以下は少々天下り的ですが, 上記で得た組み合わせを含めた範囲のコードとなります. 本来のコードはn_estimatorsを1 to 250としていますが, すぐに結果がわかるように150 to 250とし, 同じようにmax_depthを1 to 200から110 to 130に, また他の値も範囲を小さくしています. 最初はある程度広い範囲を探索し, 分析を進めていくことで探索範囲を狭めていくのも良いでしょう.
ランダムサーチはリストされたパラメーターの全ての組み合わせを実行し, 最も精度の高いパラメーターの組み合わせを出力します. また今回はabuserのほうがデータ数が少なく, 不均衡データなのでclass_weightを"balanced"にすることでクラスの重みを考慮した評価結果を算出するようにしました.
RandomSearchGrid
from sklearn.model_selection import RandomizedSearchCV
n_estimators = [int(x) for x in np.linspace(start = 150, stop = 250, num = 3)]
max_features = ['auto', 'sqrt']
max_depth = [int(x) for x in np.linspace(110, 130, num = 3)]
max_depth.append(None)
min_samples_split = [5, 6, 7]
min_samples_leaf = [1, 2, 3]
bootstrap = [True, False]
random_grid = {'n_estimators': n_estimators,
'max_features': max_features,
'max_depth': max_depth,
'min_samples_split': min_samples_split,
'min_samples_leaf': min_samples_leaf,
'bootstrap': bootstrap}
2.ベースモデルを作成
Create_BaseModel
rf = RandomForestClassifier(class_weight= 'balanced')
3.ランダムサーチモデルをインスタンス化
ModelVariableization
rf_random = RandomizedSearchCV(estimator = rf, param_distributions = random_grid, n_iter = 100, cv = 3, verbose=2, random_state=42, n_jobs = -1)
rf_random.fit(train_X, train_y)
grid_search.fit(train_X, train_y)
random_grid = rf_random.best_estimator_
以上を実行すると, 以下のようにパイパーパラメーター最適化の結果が出力されます.
HyperParameterResult
Results:
{'n_estimators': 200, 'min_samples_split': 7, 'min_samples_leaf': 1, 'max_features': 'sqrt', 'max_depth': 110, 'bootstrap': False}
このパイパーパラメーターを使用してモデルを再学習すると, 改善された新しい結果が得られます. 最初の結果と比較しましょう.
Result(パラメーター調整なし)
rf_train_accuracy: 0.999306802427328
rf_train_fscore: 0.9974694046878241
rf_val_accuracy: 0.9851363636363636
rf_val_fscore: 0.9459235984785845
Result(パラメーター調整あり)
rf_train_accuracy: 0.9998181776858565
rf_train_fscore: 0.9993378031619898
rf_val_accuracy: 0.9917272727272727
rf_val_fscore: 0.9706451612903225
全ての結果が改善していることがわかります.
| Training Set | Prediction | ||
| abuser | non-abuser | ||
| Labels | abuser | 3,009 (TP) | 0 (FN) |
| non-abuser | 16 (FP) | 18,809 (TN) | |
| Validation Set | Prediction | ||
| abuser | non-abuser | ||
| Labels | abuser | 12,073 (TP) | 83 (FN) |
| non-abuser | 99 (FP) | 75,909 (TN) | |
結論
私たちはランダムフォレストを用いてゲームログからabuserを検出する学習モデルの構築を行いました. そして, ハイパーパラメーターのチューニングにより精度(Accuracy)・F値(f-score)を向上させました. まだ改良の余地はありますが, ランダムフォレストが不正検知に使える可能性は十分にあるのではないかと感じています.
最近のゲームチートの傾向を見ていると, コインの倍率を数百倍や数千倍という大きい倍率ではなく, 運営側に怪しいと思われないレベルの増加率まで意図して落としています. このような場合, abuserはコインなどをそこまで多く持っていないため, ゲームログを確認しても明らかなabuseだと判断できない場合があります. しかしながら, これらのユーザーは同レベルのプレイヤーと比較するとやはり高い数値を持つため, 調査をするとabuserだとわかります. このような問題を自動化により解決するため, 今後は外れ値検出なども併用し, より精度の良いabuser検知を行なっていきたいと思います.
個人的にこのプロジェクトは機械学習を実践的にabuse検知に用いた非常に興味深い経験ではありましたが, まだまだシステムに正式導入するには課題があります. 私たちゲームセキュリティチームの目標はabuser検出プロセスの自動化と正確さを担保し, ゲームをプレイしてくださるユーザに対して最高のゲーム環境を提供することです. これからもこのような不正検知の調査を進めていきたいと思います.