
はじめに
LINEのタイムラインに必要な機械学習とレコメンドモデルを作っているData Science DevのJo Younginです。vol.1とvol.2に続き、今回のvol.3では「ディスカバー」を閲覧するユーザーに見せるコンテンツをどのように選定し、どの順番で配置するかについて説明します。
ディスカバーのレコメンド
ディスカバーにアクセスするユーザーがディスカバーに長く滞在して多くの投稿を閲覧し、また次回の訪問につながるようにするには「レコメンド」が非常に重要な役割を果たしています。
ポストプール(post pool)
まず、LINEのタイムラインの数多くの全体公開の投稿の中、ディスカバーのユーザーにおすすめできる候補群を作成します。この候補群をポストプールと呼びます。ディスカバーサービスの特性上、視覚化が必要なので画像や動画を含む全体公開の投稿のみを対象とします。ディスカバーのユーザーに違和感がない投稿を見せるために、LINEのタイムラインで一定数以上の「いいね」をもらった投稿をポストプールに追加し、vol.2(vol.2発行後リンクをつける)で紹介したおすすめコンテンツのフィルタリングを経て、コンテンツの品質を再度検証します。サービスを円滑に運営するために、特定のユーザーや投稿をポストプールに追加したり除外したりすることもあります。このように毎日1回ポストプールを作成し、ポストプールに登録されている投稿のみがユーザーに届きます。
埋め込み(embeddings)
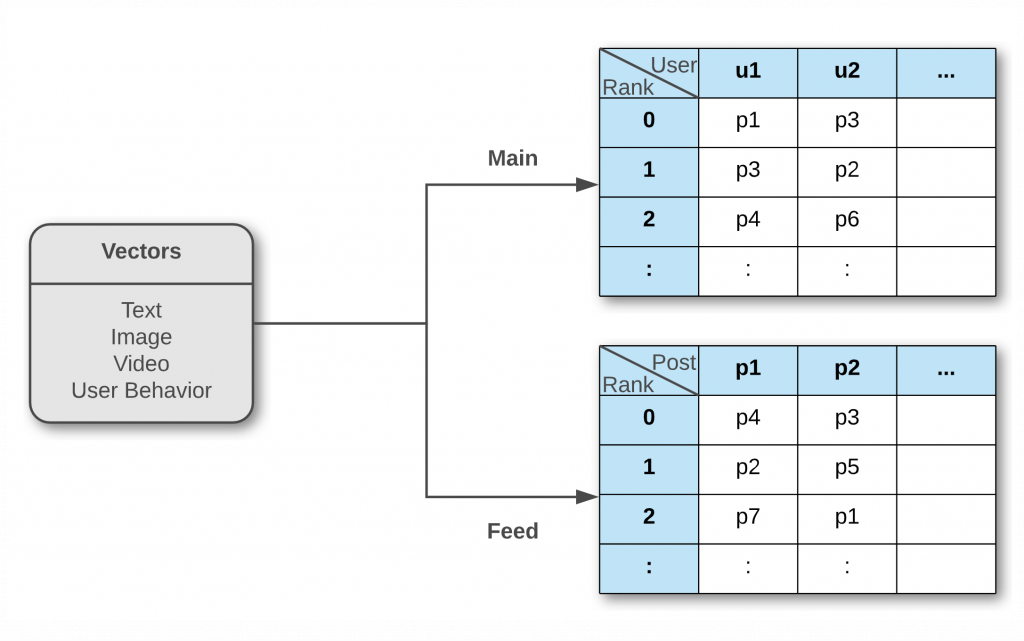
ユーザーに適切なコンテンツをおすすめするには、投稿の特性をベクトルで表現する埋め込み工程が必要です。ポストプールに登録されている投稿の情報を、おすすめ作業のための演算をしやすい形にする工程になります。ディスカバーのレコメンドに使用している埋め込みは、投稿に含まれているコンテンツの情報(画像、動画、テキスト)に関するものと、投稿をクリックするユーザーの行動パターンに基づいた埋め込みです。現在、ユーザー行動ベースの埋め込みとテキスト埋め込みは、ポストプールに登録されている投稿に関してのみ別途作成、使用しています。
テキスト
ユーザーが作成した投稿のテキストをトークン化(tokenize)して小さい単位の単語に分け、各単語の埋め込みベクトルを求めた後、投稿に登場する単語の埋め込みベクトルの平均値を投稿のテキスト埋め込みベクトルとして定義しました。単語の埋め込みベクトルを取得するため、Facebookが公開したfastTextを使用しています。157の言語についてcommon crawlやウィキペディアのデータを利用し、fastTextモデルを学習した結果である単語の埋め込みベクトルを取得できます。言語ごとに200万の単語が300次元のベクトルで表現されます。投稿がどの言語で作成されているかを検知し、その言語に応じて単語ベクトルを見つけられるようにしました。
このような方法で学習済み(pre-trained)モデルを使用することで学習にかかるリソースを節約できましたが、LINEのタイムラインのデータをうまく説明するには物足りない気がしました。LINEのタイムラインの投稿はフォーマルな文書ではなく、個人のメモやノートあるいは友だちとの会話のようなものなので、口語や造語などが頻繁に登場します。既存のテキスト埋め込みは、このような単語の埋め込みを作り出せなかったのです。このような限界を乗り越えるために、前処理方式の高度化とともに学習済みfastTextモデルにタイムラインの投稿のテキストデータを追加で学習する方法を試みました。また、投稿に登場した単語について、埋め込みの平均値を投稿のテキスト埋め込みで使用していた従来の方法を、単語の登場回数や品詞を考慮した加重平均に改善しました。その結果、埋め込みを作成できる単語の数が増え、単語やテキストの埋め込みベクトルがより正確になり、オフラインの評価とオンラインの評価ともに向上したパフォーマンスを見せました。
画像と動画
各投稿の代表画像あるいは代表動画に関する埋め込みベクトルを、投稿の埋め込みベクトルにしています。画像の埋め込みベクトルは、Googleの画像分類モデルである「Inception V3」の最終層(分類(classification)層の線形層)にPCA(Principal Component Analysis、主成分分析)を適用した1024次元のベクトルを使用しています。動画では2秒ごとに1つずつ最大150のフレームを抽出し、各フレームの画像の埋め込みベクトルを求めた後、このベクトルの平均値を動画の埋め込みベクトルとして使用します。新しい投稿が作成されるたびに、投稿の画像や動画に関する情報をベクトルにして保存し、ポイントプールに登録されている投稿に関する埋め込みのみ別途保存する方式を使っています。
ユーザー行動ベース
ユーザー行動ベースの埋め込みベクトルを求めるため、「Word2vec(以下w2v)」モデルを活用しています。w2vモデルは、NLP(Natural language processing)分野において文書内の単語のシーケンス構成関係から単語の埋め込みベクトルを学習するモデルですが、最近はレコメンド分野でも多く使われています。NLP用のw2vの入力データである単語のシーケンスの代わりに、ユーザーが1日にクリックした投稿の作成者に関するシーケンスをw2vアルゴリズムで学習することで、投稿の作成者の埋め込みベクトルを取得できます。ユーザー別に、過去30日間のクリックログから1日単位で文章を作成しました。つまり、ユーザー1人当たり最大30の文章を作ることになります。
上記の埋め込みをベースにレコメンドロジックを実装するため、埋め込みを作成できるコンテンツであればすべてディスカバーでレコメンドできます。今後、LINEのタイムラインの投稿だけでなく、LINE内のさまざまなコンテンツをディスカバーで扱うことを期待しています。
類似投稿の探索
ディスカバーでは、ユーザーの過去ヒストリーに似た投稿を見つけてメインページに表示することと、ユーザーがメインページでクリックした投稿に似た投稿を見つけておすすめフィードを構成する、AとB、2種類のレコメンドを提供しています。両方とも共通して必要なのは類似の投稿を見つけることです。そのために、おすすめ候補になる投稿それぞれに関して、類似の投稿を事前に見つけておく作業を行います。その際、おすすめ候補になるすべての投稿に関して類似の投稿を見つけますが、この過程を1つの投稿に関する過程で簡単に説明します。
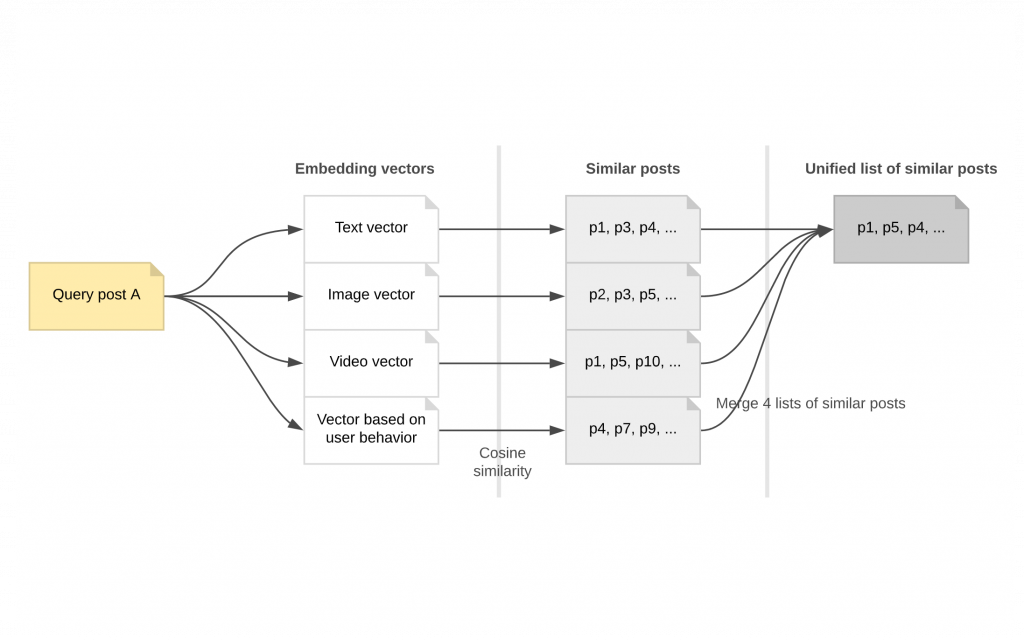
おすすめ候補になる投稿Aと類似した投稿1000個を見つける状況を想定してみましょう。Aをクエリ投稿と呼びます。前述のとおり、投稿ごとに最大4種類(テキスト、画像、動画、w2v)の埋め込みが含まれています。「最大」と表現した理由は、画像のみで動画はない投稿であれば、動画の埋め込みは存在せず、ユーザーがテキストを作成せずにアップした投稿であれば、テキストの埋め込みが存在しないはずだからです。まず、Aの埋め込みベクトルとコサイン類似度(cosine similarity)が高い1000の投稿を見つけます。限られたレコメンドプールから類似した投稿を見つける場合、クエリ投稿との類似度、つまり各投稿間の「類似度のランキング」が重要な役割を果たすと判断したためです。Aは、4種類の埋め込みを持っているので、埋め込みごとに1000の類似投稿を見つけます。次に、このようにして見つけた最大4000の類似投稿を1つの基準で並び替える工程が必要です。ところで、「画像は非常に似ているもののテキストは違う2つの投稿」は、どれくらい似ていると言えるのでしょうか。性質が違う4種類の類似度ランキングの一覧を組み合わせて1つにするために、RRF(Reciprocal Rank Fusion)を導入しました。RRFは、とても簡単で性能は優れている教師なし学習(unsupervised)のランク学習(learning-to-rank)で、情報検索(information retrieval)分野で検索語を入力すると、属性別に違う基準で検索される複数の文書を最終的にどの順番で組み合わせてユーザーに見せるかを決める方法です。今回の場合、文書=投稿、投稿のランキングを決める属性=埋め込みベクトルの種類になります。テキストと画像、動画、作成者の特性まで、属性別に類似した投稿を見つけ、ユーザーに見せる最終ランキングをRRF点数で決めるのです。
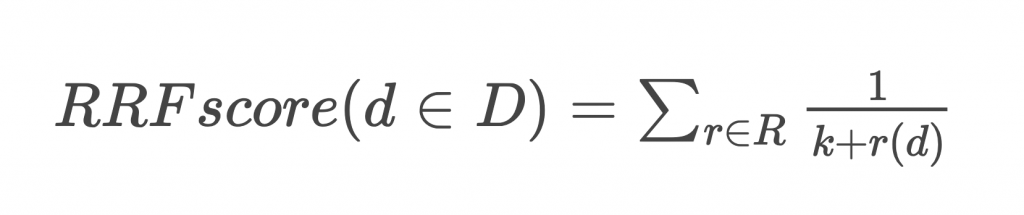
上記のように簡単な計算式を利用し、さまざまな基準で選定されたランキングをより良い1つのランキングにマージできます。埋め込みの種類別の類似度ランキングを各情報システムから取得した文書のランキングだとすると、このRRFでクエリ投稿Aに類似した投稿のランキングを合わせてマージする工程をすぐ理解できます。RRFで4000の投稿のランキングが決まります。クエリ投稿Aと類似した投稿を見つけた結果が以下のとおりだと想定します。括弧の内容は{投稿a:レコメンドプール内のすべての投稿のうち、Aとのコサイン類似度のランキング}を意味します。
- テキスト埋め込み:{a:1, b:2, c:3, … , N: 1000}
- 画像埋め込み:{a:1, b:2, x:3, … , M: 1000}
- 動画埋め込み:{b:1, a:2, y:3, … , I : 1000}
- w2v埋め込み:{c:1, a:2, z:3, … , b:100, … , J:1000}
クエリ投稿Aに対し、投稿aとbのRRF点数は以下のとおりです。
- a = 1 / (k+1) + 1 / (k+1) + 1 / (k+2) + 1 / (k+2)
- b = 1 / (k+2) + 1 / (k+2) + 1 / (k+1) + 1 / (k+100)
本来kは、いろんなシステムのランキングをマージするとき、高いランキングの文書にアドバンテージをどれくらい与えるか、または低いランキングの文書にペナルティーをどれくらい与えるかを決める定数値です。しかし、私たちは埋め込みの種類別にkの値を定数ではなく変数として扱っています。kの値によってどの種類の埋め込みに、より重みを高く与えるかを決められるためです。
ポストプールに登録されているすべての投稿に対して、すべての組み合わせの投稿ペアを対象にコサイン類似度を計算し、各クエリ投稿に関してコサイン類似度順にソートされた類似投稿の一覧を作る作業は、レコメンドモデル内で行うには時間やリソースがあまりにも多く必要です。なお、続いて紹介する3種類のレコメンドモデルともに、この結果を共通で使用するため、ポストプールが作成される時点で事前に類似投稿を作る作業を進めています。
レコメンドモデル
ディスカバーが提供しているレコメンドは、タイムラインのユーザーが今までは発見できなかった好みの投稿を見つけるようにしたり、ユーザーが好きな投稿に似た投稿をさらに多く見られる機会を提供したりすることを目指しています。
ディスカバーのメインページ
ディスカバーを開くと最初に表示されるメインページは、ユーザーごとにパーソナライズレコメンドが提供されるページです。ユーザーがディスカバーとタイムラインでクリックした投稿に似た投稿をポストプールから見つけ出して表示します。ディスカバーやタイムラインでクリックした投稿が全くない場合はパーソナライズレコメンドは不可能です。この場合は、ユーザーの性別を予測して各性別で人気を集めている投稿を見せています。もし性別も予測できないユーザーの場合は、全体の人気投稿を見せます。
ユーザー別パーソナライズ・レコメンド・ロジックについて、さらに詳しく説明します。ユーザー別パーソナライズ・レコメンド・ロジックでは、直近28日間のユーザーのディスカバーやタイムラインのクリックヒストリーを参考にします。この際、いいね(like)は一般のクリックより確実に興味を表したものなので、他のクリックとは区別して使用しています。今回の記事では、「クリックヒストリー」と呼びます。現在、ユーザーごとに28日間のクリックヒストリーをRedisクラスターに保存しており、その結果をモデルで読み取って使用しています。このクリックヒストリー情報をもとに最大20までのシードポスト(パーソナライズレコメンドのために参考にする投稿)を指定します。ディスカバーでクリックされた投稿を優先してシードポストとして指定し、もしディスカバーのクリックヒストリーで20のシードポストを取得できなかった場合は、タイムラインのクリックヒストリーを参考にしています。このような方法で20のシードポストを全部取得した後でも、メインページに表示する際にはユーザーが少しでも新たな好きを発見できるように、画面の5%はグローバル人気投稿を表示します。もしディスカバーとタイムラインのヒストリーをすべて参照しても、シードポストが10個未満になる場合は、このヒストリーがユーザーの趣味を説明するには十分ではないと判断し、シードポストの数に反比例して人気投稿の割合を増やす方法でパーソナライズレコメンドと人気おすすめのバランスを取っています。シードポストを見つけた後は、各シードポストに類似した投稿を50個ずつ取得します。ここでの類似投稿とは、前述した方法で類似度順に並び替えた投稿一覧の上位50個をいいます。そして、シードポスト別の類似投稿を1つのおすすめ一覧にまとめるため、改めてRRF点数を利用します。ユーザーに少しでもより多様なコンテンツを見せるために、類似投稿のRRF点数を正規化(normalization)し、その値に比例してサンプリングする方法でメインページのおすすめ一覧を作ります。
また、パーソナライズが不可能なユーザーに、全体の人気投稿や性別ごとの人気投稿より良いレコメンド結果を提供するために、AiRSユーザー埋め込みを使用しています。LINE NEWSの閲覧パターンをベースに作成されたAiRSユーザー埋め込みをクラスタリングし、当該クラスターに属しているユーザーにはクラスター別の人気投稿を見せる方法です。LINE NEWSの閲覧パターンは性別より多くの情報を含んでいるため、ディスカバーやタイムラインで活動が多くないユーザーにも、個人の好みに合わせた投稿を提供できます。
タイムラインのホームタブとモジュール
タイムラインフィード内のExploreモジュールとホームタブにも、パーソナライズレコメンドを提供しています。モジュールやホームタブは、ディスカバーのメインページよりはるかに少ない投稿が表示されるため、メインページのおすすめ結果のうち、上位のいくつかだけを見せる方法ではいいパフォーマンスを出ませんでした。そこで、ユーザーの好みに合わせて、おすすめ投稿のうち全体的にCTR(Click Through Ratio、クリック率)が高い投稿を先に見せるために、CTRベースの確率分布モデルを導入しました。その結果、従来より向上したパフォーマンスを得ることができました。
おすすめフィード
ユーザーがディスカバーのメインページからお気に入りのコンテンツを発見してクリックすると、おすすめフィードにアクセスできます。おすすめフィードは、おすすめ候補群からユーザーがクリックしたコンテンツに似たコンテンツを表示するページです。ユーザーがクリックした投稿に似た投稿をさらに表示し、ユーザーが興味を持ちそうなもので、まだ閲覧していなかったコンテンツを発見できるようにします。おすすめフィードは、クエリ投稿の類似投稿一覧で構成されます。この類似投稿一覧は、前述した方式で作ったものです。おすすめフィードが同じ作成者の投稿ばかりにならないように、すでに表示されている作成者の投稿は点数を少し低くして、より多様な作成者の投稿に接するようにしました。また、可能な限り最新の投稿を多く見せるために、おすすめ一覧を5個ずつ1つの単位にして、各単位内では最新の投稿順に改めて並び替える方法を使います。それにより、類似度のランキングを大きく阻害しない範囲で、最新の投稿をもっと見せるようにしました。
おわりに
今まで説明したディスカバーのおすすめ方法は、多くの方々の工夫と努力で作られました。しかし、まだ改善が必要なところが多くあります。ユーザーに少しでもより良いレコメンドを提供するために、性能改善に向けて引き続き次のようなテーマに取り組んでいます。
- フォロー関係のグラフを利用したおすすめ - ユーザー間のフォロー関係グラフを利用したレコメンドを準備しています。フォロー関係のグラフをベースにユーザーの埋め込みベクトルを取得すると、それを活用してさまざまな形のレコメンドが可能になります。ユーザーがフォローしたアカウント間の関係を基に、フォローする可能性がありそうな他のアカウントをおすすめしたり、ユーザーが好みそうなアカウントの投稿をおすすめしたりできます。
- 差分(incremental)更新 - 現在は、一定の期間をおいて学習を行っていますが、新しいユーザーが流入したり、新しい投稿が作成されると直ちにモデルに反映する差分更新を目指しています。そのために、オンラインw2vやオンライン学習が可能なランキングモデルなどを準備しています。
- カテゴリー化 - 投稿の画像や動画、テキストを分析し、カテゴリー化する作業を行っています。画像や動画の分類モデルはPicCell、テキストの分類作業は日本とタイ、台湾の各ローカルNLPまたはMLチームと協業して完成する予定です。
- Milvus - 「Milvus」は、入力されたベクトル間の類似度を計算し、お互い近いベクトルを見つけてくれる検索エンジンで、類似の埋め込みベクトルをスピーディーに見つけたい私たちの目的に合っているオープンソースです。Milvusを導入し、類似度の計算や類似度順にソート、近いベクトルを見つけることなど、ディスカバーのレコメンドに必要なベクトル演算のかなりの部分をスピーディーに処理できるようになります。