
はじめに
前回の記事、LINE TIMELINEの新たな挑戦vol.1 – おすすめのコンテンツが探索できる「ディスカバー」と新しい購読モデル「フォロー」に続き、今回は「ディスカバー配信システム」についてより詳しく紹介したいと思います。ディスカバー配信システムは、大きくDiscover FeedとDiscover Agent、Discover ML(Machine Learning)サーバーで構成されます。今回の記事では、Discover FeedとDiscover Agentを中心に説明し、次回の記事でDiscover MLサーバーについて説明します。下図は、vol.1で紹介したディスカバー配信システムの全体フローチャートです。Discover Feedは、6番と7番、8番、10番の役割を担当し、Discover Agentは8番と9番の役割を担当しています。
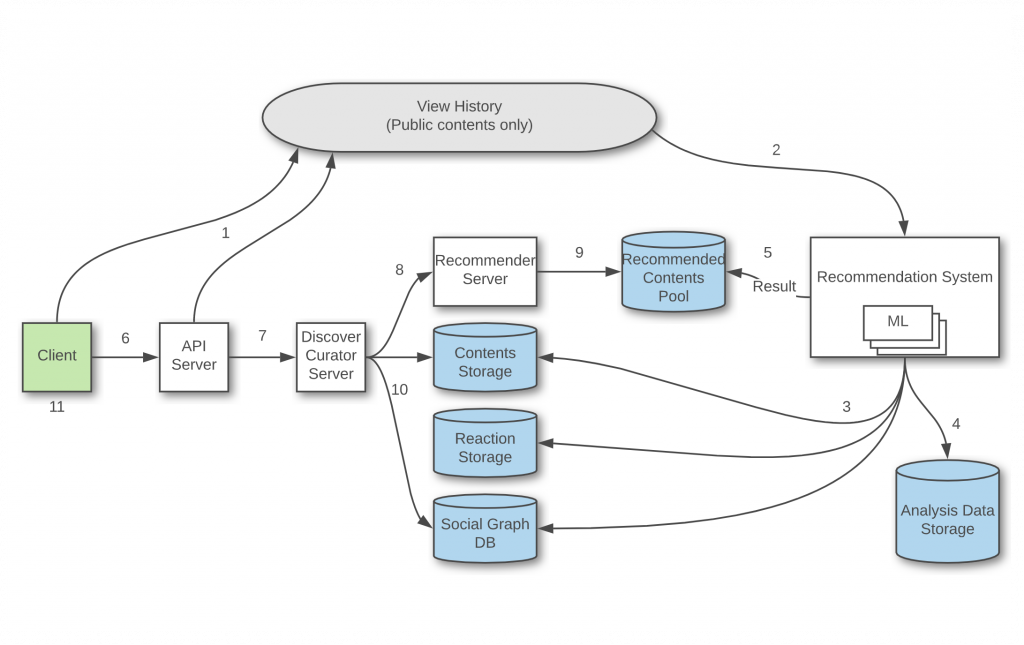
ディスカバー配信システム
下図は、Discover FeedとDiscover Agentの構造と流れを示したものです。
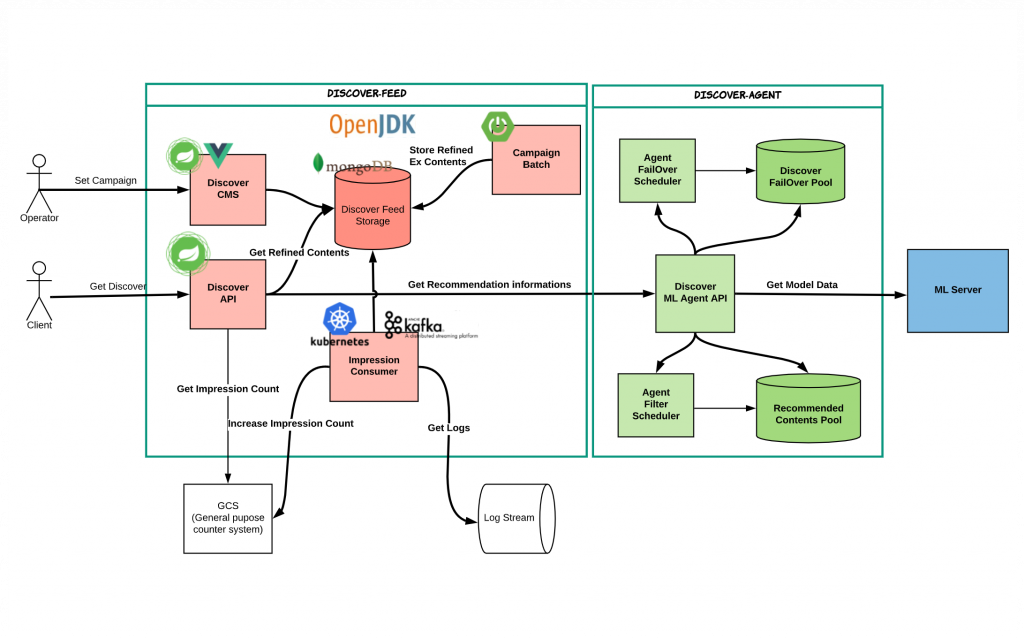
Discover Feed
Discover Feedは、Discover APIとDiscover CMS、Discover Consumer、Discover Batchモジュールで構成されています。
Discover API
Discover APIは、以下のようなコンテンツを統合(aggregation)してクライアントに伝える役割をします。
- Discover MLのエージェントAPIでおすすめされたコンテンツ
- オペレーターがDiscover CMSで設定したコンテンツ
各モジュールで作成されたコンテンツデータを集め、次に紹介するコラージュ(collage)画面やフィード形式のビューに合った形に切り替え、クライアントに送る前にコンテンツの状態をチェックします。
Discover CMS
Discover CMSは、MLでおすすめされたコンテンツだけでなく、前述のオペレーターが設定したコンテンツを表示する機能をサポートします。Discover CMSで設定したコンテンツは、Discoverコラージュ画面に表示されます。
Discover Consumer
Discover Consumerは、ログを取得して非同期で処理する機能を担当しています。Discover CMSで設定した特定のコンテンツの場合、表示する回数を設定でき、インプレッション(impression)値で表示するかどうかを制御しています。このインプレッションデータをDiscover Consumerで収集しています。
Discover Batch
Discover Batchは、Discover CMSで設定したコンテンツの情報を事前に収集して検証する役割を果たします。Discover CMSでは、表示される投稿をアカウントやハッシュタグ単位で設定できます。設定されたアカウントやハッシュタグに関するコンテンツを選択する作業は、毎回コンテンツが存在するかについて確認が必要です。また、関連情報を得るためにコンテンツを閲覧するAPIを呼び出す必要があります。これは性能に大きく負担を与えるため、どのコンテンツを表示するか事前に収集してフィルタリングしますが、この作業をDiscover Batchで行います。もちろん、アカウントおよびハッシュタグ単位で設定したコンテンツ以外にDiscover CMSで設定した他のコンテンツもこのプロセスを経ます。
Discover Agent
Discover Agentは、MLサーバーからのおすすめリストを前処理または後処理するシステムです。ユーザーに良質なコンテンツを安定的にサービスするため、MLサーバーはコンテンツのおすすめだけ担当し、運営しながら追加で必要になるものはエージェントが処理するように構成しました。今回の記事では、Discover Agentのさまざまな構成要素のうち、上記の詳細構造図で紹介されているいくつかの主要モジュールについて簡単に紹介します。
フェイルオーバー(failover)スケジューラー
フェイルオーバースケジューラーは、安定的なサービスのために真っ先に考慮した部分の1つです。エージェントにコンテンツを提供するMLサーバーは、最新のデータを利用して定期的に新しいコンテンツプール(pool)を作り、このコンテンツプールを利用して新たなモデルを作ります。新たなモデルがサービスされると、新モデルで使用するコンテンツプールと以前のモデルで使用していたコンテンツプールが違うため、以前のモデルにのみ存在するコンテンツへのリクエストが発生した場合、正常に応答できない場合が発生します。この場合でも正常にサービスを提供し、サービスの品質を維持するためにフェイルオーバーモジュールを作り、スケジューラーがフェイルオーバーを管理するように構成しました。
フィルタースケジューラー
フィルタースケジューラーは、コンテンツの品質を管理します。MLサーバーは、ユーザーのリクエストに応じてユーザーが関心を持つようなコンテンツをおすすめしたり、リクエストしたものと類似したコンテンツをおすすめしたりすることもあります。この際、おすすめのコンテンツがサービスに適しているかどうかを判断するため、フィルタリングサーバーがおすすめプールのコンテンツを検査します。フィルタースケジューラーは、定期的にフィルタリング情報を更新し、最短時間でフィルタリング情報が適用されるように作動します。
それ以外にもMLサーバーの負荷を減らし、ページング(paging)をサポートするためのキャッシング機能と、A/Bテストをサポートするモジュールなどがあり、それを管理するための管理者画面も提供します。今後のカテゴリーサービスに向けてモジュールも開発中で、このモジュールは現在類似コンテンツのおすすめにも使用しています。
コンテンツ配信
次は、ディスカバーでどのようなコンテンツを扱い、どのような過程を経てユーザーに届けているかを説明します。
ディスカバーで扱っているコンテンツ
ディスカバーで扱っている基本のコンテンツは投稿です。ユーザーが全体公開の投稿を作成すると、タイムラインのタブだけでなく、ディスカバーにもおすすめされて表示されることがあります(ディスカバーサービスの特性上、視覚化が必要なので、おすすめされる投稿にはビデオまたは画像が含まれる必要があります)。では、ディスカバーにおすすめされるには必ず投稿として作成すべきでしょうか。そうではありません。ディスカバーは、さまざまなコンテンツをカバーできるように柔軟な構造で開発されました。セルビューのモデルをシンプルにして、ディスカバーに連携される各コンテンツがこのルールを守るようにガイドしています。複雑なロジックはサーバーの中に隠して、クライアントに送るデータは簡素化する戦略を取っています。以下はビューモデルクラスの一部を抜粋した内容です。
public class DiscoverFeedView {
//Tile View
private GridBoxSpan span;
private MediaView thumbnailMedia;
private Url actionUrl;
private DiscoverTitle DiscoverTitle;
private DiscoverInfo DiscoverInfo;
// Original Contents
private DiscoverOriginContents contents;
...
}
public class Post implements DiscoverOriginContents
public class DiscoverAD implements DiscoverOriginContents
public class Campaign implements DiscoverOriginContents
...ディスカバーで表現されるコンテンツは、サムネイルやタッチすると遷移するURL、画像の上にオーバーラップされるタイトルなど、基本的な動作やビューのために必須の共通要素を備えるように定義しています。なお、必要に応じて原本のコンテンツを送信するように実装しました。それにより、いかなるコンテンツでもクライアントの修正なしにディスカバーに表示できます。また、投稿以外にもイベントや広告のコンテンツまで、さまざまなタイプのコンテンツを配信しており、今後さらに幅広いタイプのコンテンツが追加される予定です。
ディスカバーでは、多くのコンテンツを一目で見られるタイル状のビューで、さまざまなタイプのコンテンツを提供しています。通常タイルと言えば、正方形を思い浮かべると思いますが、ディスカバーでは縦長の長方形を採用しました。基本のコンテンツである投稿に含まれた画像の比率を調べた結果、正方形よりは長方形の比率の画像が多かったためです。また、より洗練された感じを強調するために縦長のセルを採用しました。以下は、正方形のセルを使用したものと、長方形のセルを使用したものを比較したサンプルです。
| 正方形 | ディスカバー |
|---|---|
 |
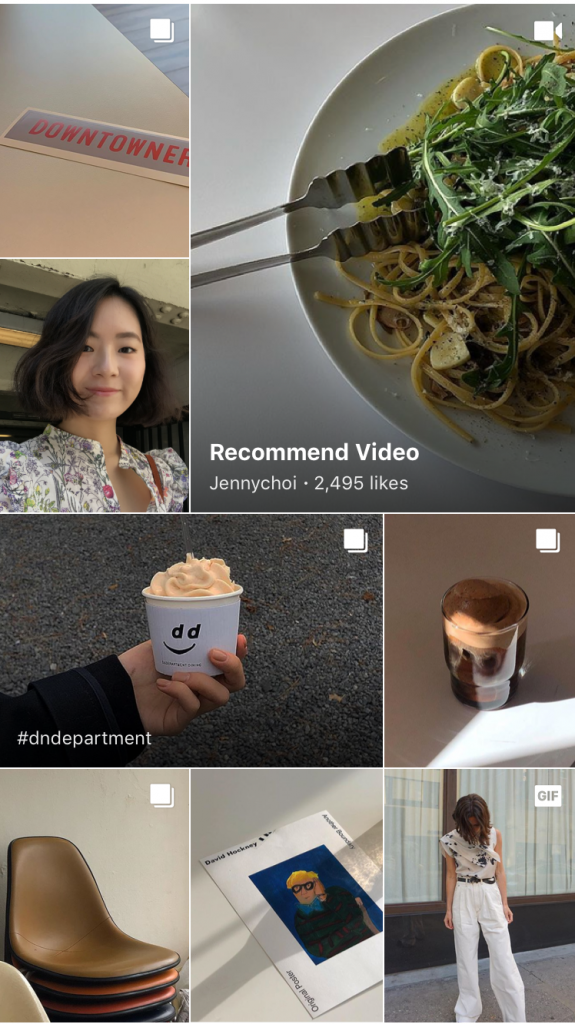 |
ディスカバーでは1ページに表示される画像が比較的に多いため、画像のサイズを考慮する必要があります。そこで、サイズを減らすために一定の比率で表示されるよう、代表画像をクロップ(crop)処理しています。しかし人物画像の場合、クロップ作業で顔の部分が切れてしまうことがあります。それを防ぐために、人物写真は画像分析技術を有するLINEのVision AIプラットフォームのPicCellと連携し、顔が切れないようにクロップ処理を行っています。このように、LINEには有効なツールと技術が多いため、より速いスピードで開発を進めることができたと思います。
| 原本 | 結果 |
|---|---|
 |
 |
 |
 |
 |
 |
 |
 |
コンテンツの検証
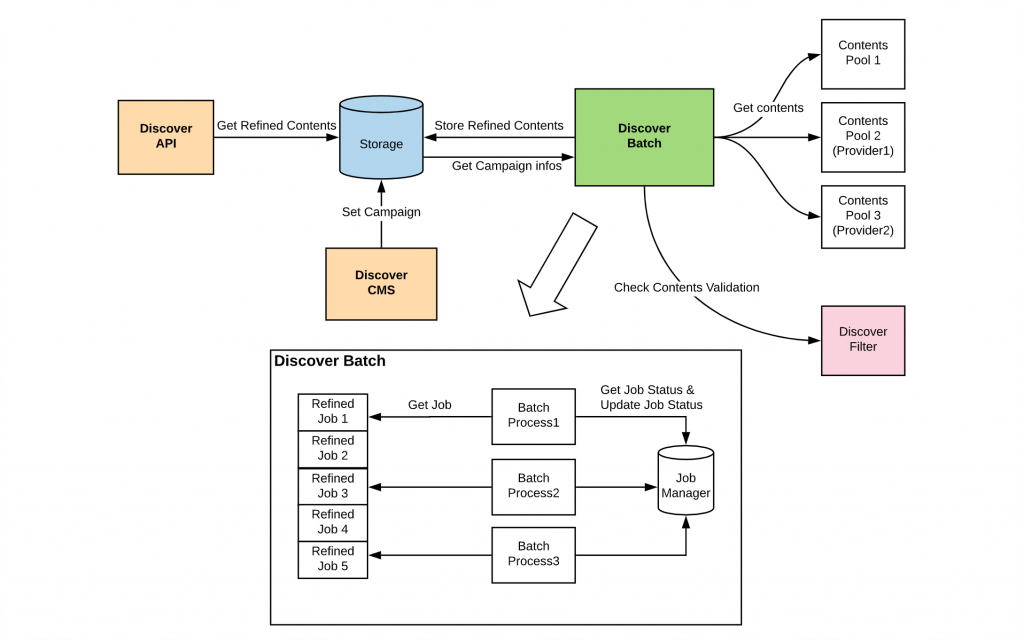
先に説明したように、Discover CMSで設定したコンテンツを、Discover Batchで収集しています。このとき、コンテンツを効率よく収集するには、いろんなコンテンツを調達するジョブ(job)をそれぞれ登録し、ジョブマネージャーよりプロセッサーがバッチジョブを重複処理しないように管理します。また、表示するコンテンツを収集する際、コンテンツは正常なのか、表示してもいいのかを確認する段階があります。投稿はタイムライン投稿APIで検証し、正常な投稿は「Refined Post」と呼ばれる候補プールに入れます。前述のアカウントやハッシュタグ単位で設定することをキャンペーンと言いますが、このようにキャンペーンで設定したコンテンツも検証します。例えば、設定がアカウント(account)になっている場合、当該アカウントの最近の投稿を検索して候補プールに含めます。
このような作業は毎回閲覧する場合、トラフィックに負担を与えるため、特定のサイクルを設定して実行します。プールに入っている投稿は、レコメンドフィルターによって最終的に表示するかどうかを決めます(今回の記事では、詳細は紙面の関係で割愛します)。投稿以外のコンテンツは、コンテンツ提供者が提供したAPIでコンテンツを検証して表示します。
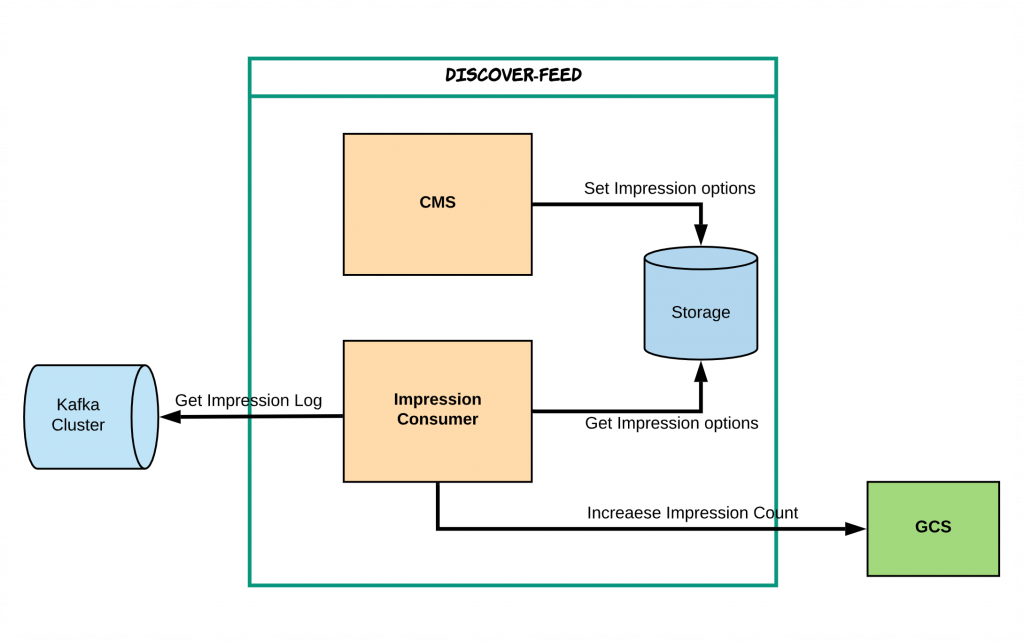
キャンペーンのインプレッション(impression)
ディスカバーでは、キャンペーンとして登録されているコンテンツが過度に表示されないように調整できます。この機能を実装するには集計システムが必要でした。独自で簡単に実装することも考慮しましたが、ユーザー別インプレッションなど実装の難度が少し高く、非効率的だと判断しました。その代わり、すでにできている社内ソリューションを検討しましたが、その中でGCS(General purpose Counter System)というシステムが目に留まりました。GCSでは、サービスに必要な数値を定義し、測定できるようにサポートしていたので、GCSを利用することにして連携しました。LINEで最小限に収集できるユーザーの行動情報は、LINEのデータウェアハウスに保存され、このデータが保存されるパイプラインは、Kafkaを使用しています。そのため、このKafkaにつなげると必要な情報を得ることができ、この情報を加工してGCSシステムに集計されるように設計しました。このような方法で、ちょうど必要なビジネスロジックだけを実装したため、無駄なリソースを減らしながら必要な結果も得ることができます。
レコメンドコンテンツプールの設計
MLサーバーで作成するモデルはユーザーに適切なコンテンツを提供するため、定期的に学習と配布を繰り返します。このとき使用されるコンテンツは、最新のコンテンツに更新を続けます。新たなモデルは、以前使用されたコンテンツと重複する部分もありますが、消えていくコンテンツと新しく追加されるコンテンツもあります。そのため、以前のモデルでサービスしたコンテンツを持っているユーザーと現在のモデルで提供するコンテンツの間に違いが発生することがあります。このような問題を解決するため、コンテンツプールを設計するにあたっては、以前のコンテンツプールと新しいコンテンツを重ねる方法を使用しました。エージェントは、常に最新のモデルと通信し、過去のコンテンツプールも閲覧できます。そのおかげで、過去のコンテンツについてのリクエストにも適切に応答できます。下図と合わせて例を挙げてみます。
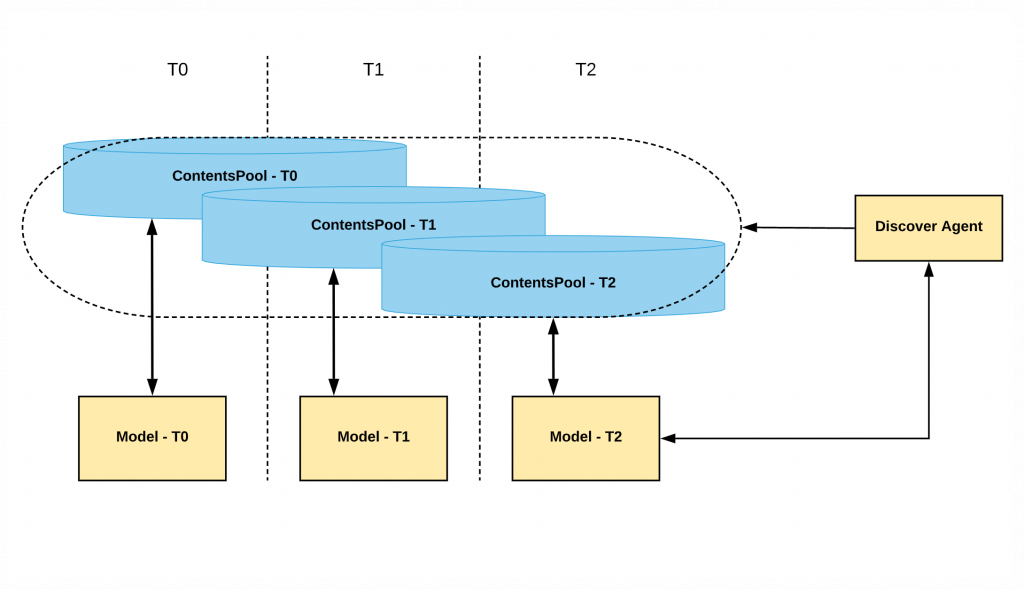
現在の時間がT2だと想定すると、サービスモデルとコンテンツプール、エージェント参照プールは以下のとおりです。
- サービスモデル:Model-T2(=Mt2)
- コンテンツプール:ContentPool-T2(=CPt2)
- エージェント参照プール:ARP(=CPt0+CPt1+CPt2)
エージェントが参照するコンテンツプールは、モデルMt0~Mt2が作成したCPt0~CPt2全体を参照できるように設計しました。
最近モデルが変更されましたが、ユーザーが過去に作成されたコンテンツプールのデータをリクエストしたと想定してみましょう。仮に当該コンテンツが今回のモデルに含まれている場合は、モデルは正常に応答できます。しかし、当該コンテンツが今回のモデルに含まれていない場合は、正常に応答できません。この場合は、フェイルオーバーでサービスを提供します。
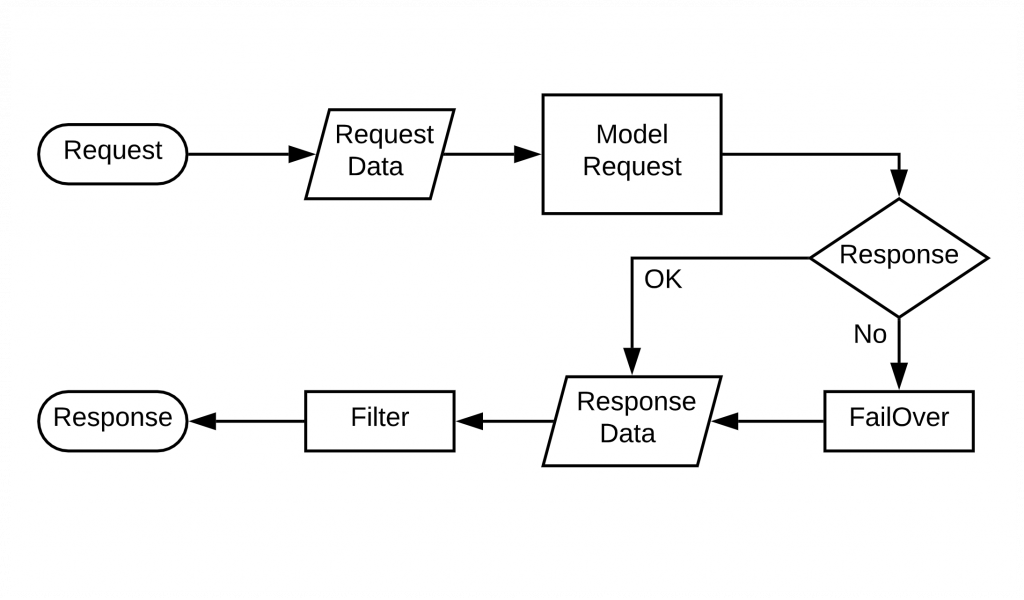
フェイルオーバーでサービスを提供する場合は、ARP(Agent Reference Pool)全体にカテゴリーサービスロジックを適用し、類似コンテンツを抽出して品質が保証されるように考慮しました。
おすすめのコンテンツのフィルタリング
モデルが新たに学習して新しいコンテンツをレコメンドプールに追加し、新たなモデルがサービスを開始すると、MLサーバーは新しく追加されたコンテンツを応答に含めます。このとき、プールに追加されたコンテンツは、ユーザーにすぐには提供されません。さまざまな方法で検証を行い、その検証を通ったコンテンツのみ実際のユーザーに提供されます。いろんな種類のコンテンツフィルタリングがあり、下図のように各状況に応じてフィルターと機能が実行されます。
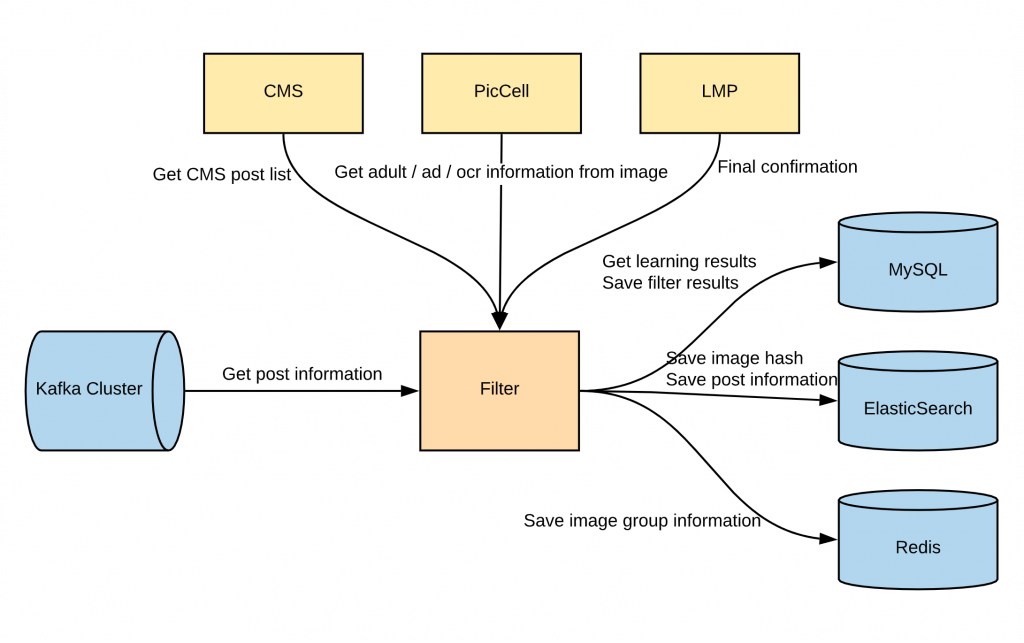
現在適用しているフィルターと機能は以下のとおりです。
- フィルター
- テキストフィルター:コンテンツに特定の単語が含まれている場合、フィルタリングを行います。
- アダルト(adult)フィルター:コンテンツに含まれている画像にアダルト向けのものが含まれている場合、フィルタリングを行います。
- 広告(AD)フィルター:コンテンツに含まれている画像が広告だと判断されると、フィルタリングを行います。
- OCR(Optical character recognition)フィルター:コンテンツに含まれている画像で文字が一定の面積以上を占める場合、フィルタリングを行います。
- 顔認識フィルター:コンテンツに含まれている画像に有名人ではない人が認識される場合、フィルタリングを行います。
- 機能
- LMP(LINE Monitoring Platform):フィルターをすべて通った場合、直接検査を行います。
- 画像ハッシュ:同じ画像が重複して表示されないように画像ハッシュを利用して、フィルタリングが完了されたコンテンツをグルーピングします。
- CDN(Content Delivery Network)キャッシュ:クライアントでサムネイル画像を迅速に確認できるよう、キャッシュ機能を提供します。
新たなモデルのためのA/Bテスト
新たなモデルを開発すると、従来のモデルに比べて性能が向上されたかどうかを評価する過程が必要です。そこで、リクエストの一部分を新たなモデルに送ってユーザーに提供し、その後発生するユーザーのログをベースにした新たなモデルの性能を評価します。また、この評価をベースに従来のモデルを新たなモデルに変更するかどうかを判断します。このような評価は、実際にユーザーのリクエストに基づいていないと、より正確な結果を得られないため、サービス中に任意にテストできるように実装しました。

現在実装されているA/Bテストモジュールの特徴は以下のとおりです。
- ユーザーベースのテストグループ設定をサポート
- 国別またはモデル別テスト設定をサポート
- 同時に複数のモデルテストをサポート
- サービス無停止でのテストをサポート
おわりに
今回の記事ではディスカバーサービスのうち、配信システムについて紹介しました。通常のWebベースサービスで多く使われている技術を使用したため、技術について詳しく説明するよりは、LINEが提供するディスカバーサービスに特化した内容を説明しました。さて、ディスカバーサービスのカギは、「どのようにしてユーザーが好きなコンテンツをおすすめするか」あるいは「どのようにして類似コンテンツを提供するか」という問題になると思います。次回のvol.3では、このような問題をどのようにして解決したかを説明します。お楽しみに!