
LINEは最新技術の業務への応用を歓迎しており,その一助として情報収集を目的とした社員の国際会議への参加を支援する制度があります.
2022年11月28日から12月3日にかけて開催された機械学習分野のトップカンファレンスであるNeurIPS 2022には,弊社Machine Learning Solution室からSatoとLiewが聴講参加してきました.
この記事では会議の様子や得られた知見を報告します.
NeurIPS 2022とは
NeurIPS(Neural Information Processing Systems)は年一回開催される機械学習に関する国際会議で,当該分野におけるトップカンファレンスの一つとして知られています.2022年は9634本の投稿があり,このうち2672本が採択されました(採択率27.7%).採択された論文のうち,約200本が口頭発表(オンライン)を実施します.
今年のNeurIPSはアメリカ合衆国ルイジアナ州に位置するNewOrleansで開催されました.

南北におよそ1.1kmという広大な面積をもつ.
この会議のスコープやトレンドを概観してもらうことを目的として,採択された論文のタイトルに含まれる単語から生成したワードクラウドを以下に示します.

頻度の高い名詞の上位3件は「Learning」「Neural」「Network」であり,近年盛んに研究されている深層学習に関する話題が多く見られます.
「Reinforcement Learning」は154回登場しており,実に約5.7%の採択論文が強化学習に関する論文でした.
また,「Graph」「Adversarial」といった単語もそれぞれ80回以上登場していることから,重要な要素としてグラフ構造や敵対的学習を取り入れる研究が多いことが伺えます.
会議は非常の多くの参加者で賑わっており,ポスター発表で発表者と一対一の対話をするためには少なからぬ待ち時間を要しました.


Geoffrey Hinton氏の招待講演ではこの広大な会場の7割以上が
聴衆で埋められているように見受けられました.
Satoが注目した発表
<Expo Talk Panel> Adapt and Optimize ML Models for Hardware-Aware AI
Presenter: Di Wu
URL:https://nips.cc/Conferences/2022/Schedule?showEvent=56498
概要: OmniML社がhardware-awareなニューラルネットワーク構造のoptimizerである「Omnimizer」を紹介しています.
背景: ニューラルネットワークの高速化の文脈では,ハードウェア特性に合わせた(=hardware-awareな)モデルの圧縮(=ニューラルネットワークの構造改変)手法が注目されています.これは,あるハードウェアで有効なモデルの圧縮手法が,異なるハードウェアでは期待したレベルの高速化を達成できないケースがあることに起因しています.換言すれば,ニューラルネットワークの高速化というソフトウェア側のアプローチは,土台となるハードウェア・プラットフォームのアーキテクチャを無視できないことを意味しています.
提案: OmniMLは,クラウドプラットフォーム上でハードウェア特性に合わせたニューラルネットワークの高速化を実現するサービスであるOmnimizerを提供します.
Omnimizerは重みの量子化など一般的なモデルの圧縮手法に加えて,モデルの部分的なfine-tuningといった機能を有しています.またターゲットとなるハードウェアを指定すると,最適化中のニューラルネットワークの当該ハードウェア・プラットフォーム上でのレイテンシをクラウド経由で計測する機能があります.モデルの圧縮と特定ハードウェアでのレイテンシの計測の2つの機能を繰り返し用いることによって,ユーザーが利用したいハードウェアに適した高速かつ高精度なニューラルネットワークの獲得を実現します.
Qualcommデバイス上で自動運転車向けのsemantic segmentationモデルを8.6倍高速化したり,DistillBERTを0.1%精度向上しながら2.63倍高速化するなどの活用事例があります.
Pythonライブラリとしてのインターフェースも紹介されており,MLエンジニアにとって親しみのあるインターフェースとクラウドサービスとしての機能提供により,使い勝手は良さそうな印象でした.
LINEでもFederated Learningの枠組みでモバイルアプリ上でスタンプの推薦を行う取り組みを行なっています(https://tech-verse.me/ja/sessions/46).ここでも計算コストとモデル精度のトレードオフは重要な課題であることから,この発表から我々の実務課題にも役立つ知見が得られたと感じています.
<Expo Talk Panel> Human-in-the-Loop Is Here to Stay
Presenter: Fedor Zhdanov
URL: https://nips.cc/Conferences/2022/Schedule?showEvent=59799
この講演はYoutube(https://www.youtube.com/watch?v=G6S1mUXP2wI)でも閲覧することができます.
概要: MLモデルの学習と,データのアノテーションの2部で構成されるサービス「Toloka」を紹介しています.
提案: Tolokaの特徴は,公演タイトルにも含まれるようにHuman-in-the-loop(=システムを構成する一部として人間を用いる)の考えに基づくアノテーションと学習のシステムを構築している点にあります.アノテーション機能には,human-verification = 人間に入力データに対するMLモデルの出力が正しいか否かを問う形式でアノテーションさせる特徴があります.人間に「これは何ですか(→ xxです)」と問うopen-endedな質問ではなく,「これはxxですか(→ yes or no)」と問うclosed-endedな質問は,アノテーションの負担を軽減することを可能にします.
最近話題のChatGPT(https://openai.com/blog/chatgpt/)にも,上記の発想と同様のclosed-endedな質問によるアノテーションが用いられています.
また,LINEでもユーザーのサービス利用ログからユーザーの年齢や興味関心といった属性を推定するモデル(https://linedevday.linecorp.com/2021/ja/sessions/91/)を構築しており,この推定モデルの学習には人間が生成した少量のラベル付きデータが用いられています.このように,MLモデルの学習と人間によるアノテーションは密接に関連しているため,今後もアノテーションの負荷を軽減するという方向性の検討が深まっていくことが期待されます.
<Poster> An Asymptotically Optimal Batched Algorithm for the Dueling Bandit Problem
Author: Arpit Agarwal 他
URL: https://openreview.net/forum?id=u6GIDyHitzF
概要: K-armed dueling banditのbatch化アルゴリズムを提案し,このアルゴリズムのregretが既存のアルゴリズムのregretに対して漸近的であることを示します.
背景: K-armed dueling bandit (比較バンディット)は,確率的なアームの比較を介した最適腕の探索問題です.
より具体的には,腕iとjについて,確率p(i,j) = 1/2 + Δ(i,j)で「jよりもiが優れている」といった観測が得られる環境を想定しています.
ここで,Δ(i,j) ∈ (-1/2,1/2) はiとjのdistinguishabilityのようなもので,gapと呼ばれます.
エージェントの目的は,T回の腕の比較において,より小さなregret(最適腕を選択し続けた場合との期待報酬の差)を達成することにあります.
提案: これまでdueling banditのアルゴリズムは,1度の観測で1回エージェントを更新するfully-adaptiveなアルゴリズムが主流でした.
一方,この研究では,複数のエージェントが並列してアームを引き,観測をbatchとしてまとめた結果に基づいてエージェントを更新するbatch化されたdueling banditアルゴリズムであるC2Bを提案しています.これは,多数のユーザーに並列してレコメンドを行うようなwebサービスなどに親和性のある問題設定といえます.
この研究における最大の問いは,batch数,すなわちC2Bにおけるエージェントの更新回数BがB=O(log(T))を満足することを仮定した時,regretの上界は既存のfully-adaptiveなアルゴリズムのregret上界に対して漸近的だろうか,というものです.そして彼らはこの問いに肯定的に答えています.換言すれば,C2Bは既存手法と同様にT回の腕の比較を行う一方で,エージェントの更新回数は既存手法のT回に対してO(log(T))回に削減されており,にも関わらずregret上界は既存のregretに漸近的であることが強みといえます.
実験的にも提案するC2Bが既存手法とほとんど同程度のregretを達成することを確認しています.
実際のサービスにおけるレコメンデーションと親和性のある問題設定であることから面白い研究だと感じました.
<Poster> DreamShard: Generalizable Embedding Table Placement for Recommender Systems
Author: Daochen Zha 他
URL: https://openreview.net/forum?id=_atSgd9Np52
概要: 強化学習を用いた分散学習の最適化手法であるDreamShardを提案しています.
背景: レコメンデーションなどを目的として,サービスから得られるデータをニューラルネットワークに入力する際,カテゴリカルな,すなわちスパースな特徴量をembeddingを用いてdenseな特徴量に変換したいことはよくあります.しかし,実際のデータは非常に高次元で,1千万を超えるカテゴリを持つsparseなテーブルを扱うケースもあります.このような場合に,embeddingの学習には非常に多くのメモリが必要で,分散学習は必要不可欠です.
分散学習の枠組みで,高次元のsparseな特徴を変換するembeddingテーブルをM個に分割してN個のGPU上で学習することを検討します.この時,どの(1<=n<=N番目の)GPUがどの(1<=m<=M番目の)embeddingテーブルのpartitionを担当して学習を行うかという「embedding-partitionの適切な配置」が課題となります.
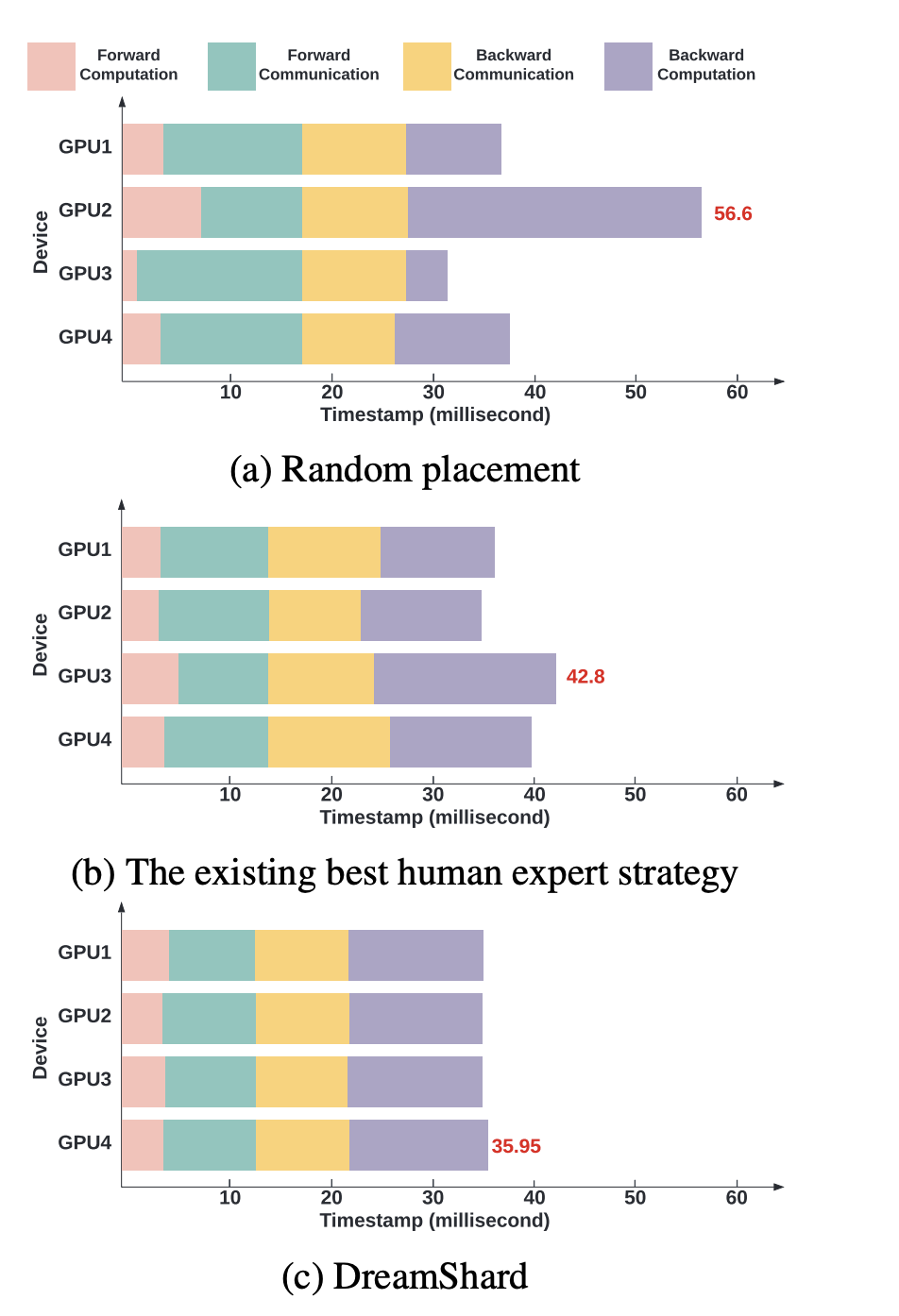
上図に一例を示します.ランダムに配置した場合,n=2番目のGPUに割り当てられたembedding-partitionの学習がボトルネックとなり,全体の完了までに56.6ミリ秒の時間を要したことが示されています.一方で,人間のエキスパートが配置した場合,42.8ミリ秒まで短縮されています.しかし,人間のエキスパートに配置を決定させるには労力がかかるため,自動化やアルゴリズムによるより優れた配置の決定手段が求められます.
提案: この研究では,適切に負荷分散されたembedding-partitionの配置を,強化学習を用いて学習したエージェントに出力させるアプローチである「DreamShard」を提案しています.
エージェントは前時刻までに決定された配置やテーブルの情報を元に,1タイムステップ毎に1つのembedding-partitionに対して配置先のGPUを決定します.全てのembedding-partitionの配置が決定した後,負の実行時間を報酬として与え,これを最大化するように学習されます.
また,ある配置で学習した際の実行時間を計算する関数は,実際に伝播計算を行う必要があるため,実行に時間がかかります.これを解消するために,予めいくつかの配置に対して対応する実行時間を計測し,このペアデータから実行時間を予測するモデルを学習することで,エージェントの学習を高速化しています.
LINEではユーザーの各種LINE関連サービスでの行動ログを用いた大規模な特徴量開発を行なっており(https://linedevday.linecorp.com/jp/2019/sessions/C1-5),これらのテーブルも高次元かつスパースな性質を持っています.この側面では,本研究はLINEのML課題に通じる問題設定となっています.
Liewが注目した発表
The Forward-Forward Algorithm for Training Deep Neural Networks
Presenter: Geoffrey Hinton
Hinton氏の10年前のトロント大学の学生たちとの共著論文「ImageNet Classification with Deep Convolutional Neural Networks」がNeurIPS 2022 Test of Time Awardを受賞しました。
今回のInvited Talkでは、Hinton氏は「Forward-Forward」(FF)アルゴリズムについて紹介しました。
確率的勾配降下(SGD)を行いバックプロパゲーション(backpropagation)という手法でニューラルネットワークの勾配を計算し、モデルを更新することは、過去10年間に深層学習の分野において驚くほどの勝利を収めてきました。
Hinton氏は、生物の脳がバックプロパゲーションで学習することはないであろうと問いかけ、脳の学習に必要な勾配を得る他の方法があるのかに興味を持っています。
そこで、バックプロパゲーションに代わるものとして、Forward-Forward (FF)アルゴリズムを提案しています。
バックプロパゲーションのフォワードパスとバックワードパスを2つの(ポジティブとネガティブ)フォワードパスで置き換えることとしています。目的関数は、正のデータに対しては高い良さを持ち(ポジティブパス)、負のデータに対しては低い良さを持つ(ネガティブパス)ように重みを調整します。
論文は本人のホームページに公開されています:https://www.cs.toronto.edu/~hinton/FFA13.pdf
<Poster> Differentially Private Learning Needs Hidden State (Or Much Faster Convergence)
URL: https://openreview.net/forum?id=ipAz7H8pPnI
Presenter: Jiayuan Ye
深層学習を差分プライバシー(differential privacy)で保護させるには、計算されたモデル勾配をランダム化し、ニューラルネットワークの重みを更新するというDP-SGDの手法を取るのが一般的です。
しかし、重みが更新されたたびにランダム化された勾配を公開され、その回数が増えるとプライバシーの強度が損してしまう問題があります。
提案手法では、損失関数が滑らかかつ凸の場合に、勾配を公開せずにプライバシー保護下の学習が可能で、プライバシーの強度が損しないことを示しました。
ノイズを加える機構を拡散過程としてモデル化し、そのRényiダイバージェンスを追跡するし、さらにシャッフルとサンプリング効果を考慮して、プライバシーの強度が先行研究より優れていることを証明しました。
なお、同じ学会で似たような発想の発表もありました:https://openreview.net/forum?id=pDUYkwrx__w
損失関数に強い制限があるためまだ深層学習などへの実応用が難しいですが、今後の進展を期待されています。
<Poster> Private Set Generation with Discriminative Information
URL: https://openreview.net/forum?id=mxnxRw8jiru
Presenter: Dingfan Chen
LINEでも取り組んだ差分プライバシーを保証しながら生成モデルを学習し、プライバシー保護された人工データを作成する研究は今まで盛んでした。
この研究では、人工データを生成モデルを学習せずに作成します。人工データの下流タスク(downstream task)の性能に対して最適化することで人工データ作成するような手法を取っています。
実験結果として、人工データの下流タスクの性能(分類精度)が生成モデルを学習するアプローチより上回ります。
提案手法の欠点として、作成するデータ数に制限があります。そのため、大量のデータ数が必要な評価指標(例:kernel inception distance, KID)ではこの手法を使って評価できません。
プライバシー保護の人工データは個人情報を漏らさない上に、プライバシーの非専門家に扱いやすいので、この分野の進展は今後も注目されるでしょう。
<Poster> Off-Policy Evaluation with Deficient Support Using Side Information
URL: https://openreview.net/forum?id=uFSrUpapQ5K
Presenter: Nicolò Felicioni
新しい意思決定の方策(policy)をオフラインデータ(古い方策)で評価するタスクはoff-policy evaluationと言います。
Inverse propensity scoring (IPS)という、新しい方策と古い方策の行動選択確率の比を使って評価する手法がよく使われています。
しかし、IPSでは、古い方策の全ての行動を選択する確率がゼロでないと評価に偏りが生じるというdeficient support問題が生じます(そうでない時にfull support仮定が満たされると言います)。
この論文において、サイド情報を利用した手法を提案し、deficient support問題を解決します。
サイド情報を使って行動選択確率を適切な変換下でfull supportになるというより緩い仮定の下で、理論解析および実験評価で提案手法が優れていることを示しました。
Deficient supportは実際のサービスにおけるレコメンデーションに存在しうる問題ですので、実用性があって面白いと感じました。
おわりに
本会議に参加したことによって、機械学習の研究分野における最先端の動向と研究者の熱意を肌で感じることができました。
基礎研究の知見を得られただけでなく、応用研究や様々な活用事例を通じて、LINEのサービスを向上するための参考にもなりました。
LINEのData Scienceセンターでは機械学習を活用したプログラムマネージャーを募集しています.興味のある方はぜひ応募をご検討ください.