
みなさんこんにちは、LINEのサーバーサイドエンジニアの長谷部です。普段は、最近でいうとLINE Login や LINE Customer Connect などの開発を担当しています。
2018年の年始に LINEのお年玉 というイベントを実施し、その開発を担当しました。今回の記事では、LINEのお年玉のアーキテクチャの紹介や、当日実際に発生した問題(サービス過負荷起因のkafka consumer遅延)などの振り返りについて書こうと思います。
LINEのお年玉とは
お年玉イベント期間中に、お年玉とLINEスタンプをセットで「お年玉つきスタンプ」として販売しました。対象スタンプを購入したユーザーさんは、スタンプ購入数 x 10個 のお年玉が付与されます。

ユーザーは自分がもっているお年玉を友だちに直接送ったりグループに送信することができ、お年玉を受け取って開封したユーザーは抽選で以下の報酬を得ることができます。
- 1等
- 100本
- 現金にて 1,000,000円
- 2等
- 1,000本
- LINE Pay残高10,000円分
- 3等
- 10,000本
- LINE Pay残高1,000円分
- 4等
- 10,000,000本
- LINE ポイントにて 1ポイント
- スタンプ賞
- 700,000本
- LINE ポイントにて 120 ポイント
また、LINEにはシェイク機能というのがあり、指定した期間/ロケーションでLINEを起動しているときに端末を振ると指定したページを表示することができます。このシェイク機能を使って、期間中に一度だけシェイクしてくれたユーザーに対してお年玉を1つ付与するということも実施しました。
アーキテクチャ概要
ざっくり図で書くと、こういったアーキテクチャになっています。
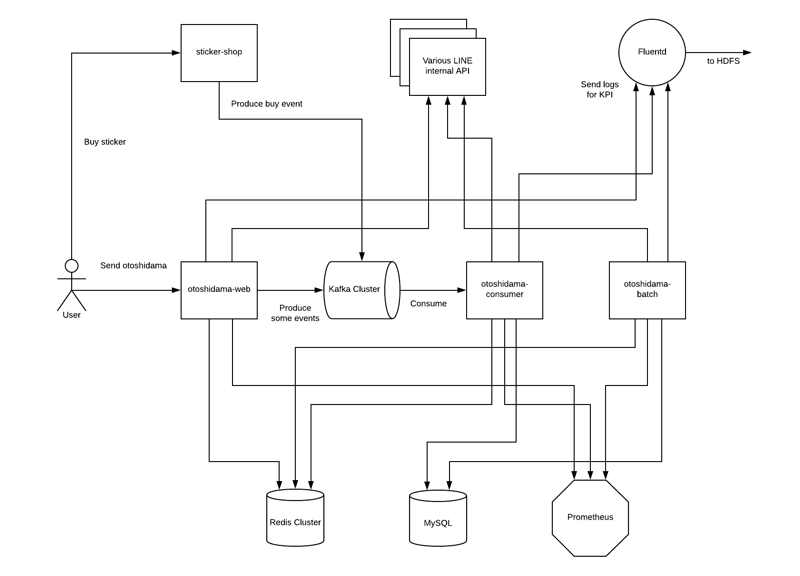
今回新規に実装したものが、otoshidama-web, otoshidama-consumer, otoshidama-batch の3つになります。(厳密には管理画面などもありますが、割愛)
ただの期間限定イベントの割には、少々ゴツイ印象を受けるかもしれませんが、実は下記のような理由でなかなか突発的なトラフィックが見込まれるイベントなのです。
- 新年早々のあけおめメッセージと一緒にお年玉が送信されるので、トラフィックが見込まれる
- 大体的にTVマーケティング行われる
- TV CMもガッツリと実施される
- 元旦のゴールデンタイムに放送される高視聴率なTV番組中で紹介がされる(この時、気軽に無料で行えるシェイク機能も紹介されます)
- 友だち数が数千万を超える複数の公式アカウントから一斉送信告知がされる
また、サービスをリリース(イベント開始)する1月1日の00:00付近にいきなりデカいスパイクがあるので、エンジニアとしてはちょっとドキドキするサービスになります。
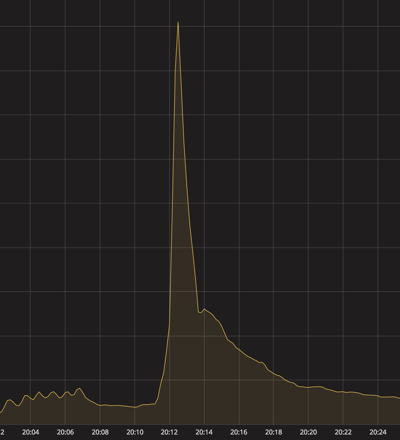
結果としてotoshidama-webサーバーには、TV番組紹介時のピークタイムで25K request/sec ほどのアクセスがありました。
以下の図は、その時のGrafanaのグラフです。スパイクがすごいですね。
各componentは以下のような役割を担っています。(DB, ストレージなどは割愛)
sticker-shop
LINEアプリ内のスタンプショップと LINE STORE の両方を便宜上、この記事ではsticker-shopと表記しています。
Userがスタンプを購入すると、sticker-shopがそのevent dataをkafkaに送信します。後述するotoshidama-consumerがそのevent dataをconsumeし、お年玉の付与処理を行います。
※普段からこういったevent dataをkafkaに送っているため、今回のLINEのお年玉のようなイベントが実施されるときでもsticker-shop側では特別な対応をせずに済むようになっています
otoshidama-web
UserがLINEアプリからアクセスするサーバーです。
お年玉の送信ページ/開封ページや今までもらったお年玉の一覧ページなど、根幹となる機能を提供しています。処理が迅速に行われるべきものは、このサーバー上で行われます。
例えば、お年玉の送信を例にすると、自分の送信BOXなどの追加はこのサーバー上で行います。
相手側の受信ボックスの反映や、LINEメッセージの送信などといった非同期処理でも問題ないような処理は、kafkaに対してeventを発行してconsumer側で行うようにしています。先述しましたが、突発的なアクセスが見込まれていましたので、requestが詰まることがないようこのような設計にしていました。
otoshidama-consumer
Kafkaからevent dataをconsumeする、consumerです。Kafka Streamsを用いて実装しています。
sticker-shopサーバーからproduceされる購入event dataが受け取ったら、そのUserに対してお年玉の付与処理をしてLINEメッセージの送信などを行います。
また、otoshidama-webの説明でも書いた通り、他にも様々なeventを受け取ってそれに応じた処理を行います。
otoshidama-batch
Userのステータスによって、LINEメッセージを送信するbatchサーバーです。
例えば、もしもユーザーがまだ未開封のお年玉を持っていた場合は「未開封のお年玉があります。開封しましょう!」といった旨のLINEメッセージを送信します。
Prometheus
しばしばこのブログでも言及されていますが、LINEではモニタリングとしてPrometheusを使用することがあり、今回の案件でもPrometheusを使用しました。(もちろんチームやプロジェクトによって違いますが、最近はPrometheusを使うケースが多いです)
otoshidama-* の実装はJavaを使用していたので、公式のjava clientを利用して以下のようなmetricsを取得していました。
- System系 (CPU, memory, ...etc)
- JVM (Heap, GC, thread count)
- nginx -
- サーバーへのリクエスト数とレイテンシ
- 各APIのリクエスト数とレイテンシ
- Kafka producer / consumer
- batch処理数
- ...etc
問題が起きた時に頼りになるのはこういったメトリクスの情報ですので、しっかりと取っておくのが大事です。こういったgrafana dashboardを何個か作成して、一覧で閲覧できるようにしていました。
Fluentd
社内にFluentdを用いたlog収集基盤がありますので、そちらに利用統計データ算出に必要なlog dataを送信していました。
KPIのdataも、Grafanaにdashboard作成してreal timeに見れるような状況を整えていました。
当日あった問題 - kafka consumer 処理遅延
一番最初のスパイクの時点(1/1 00:00 - 01:00付近)で、個別のお年玉の送信が最大で30分ほど遅延してしまうという問題がいきなり起きてしまいました。
もともと、スパイク時に数分くらいの遅延は起きることは想定していたのですが、ここまで遅延してしまうとは...見積もりが甘かったようです。
ユーザーさんにはご不便をおかけしてしまい、申し訳ありません。
原因
なぜ起きてしまったのかについて書いていきます。
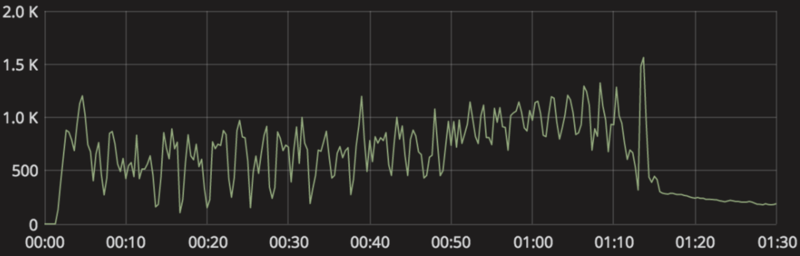
grafanaにて問題発生当時のconsumeスループットとproduceスループットを比較すると、produceのほうが上回っているので徐々に処理すべきmessageが溜まっていきconsumerの処理遅延が起きてしまっていることが確かに確認できます。
通常であればこのようにスループットがギザギザと上下することもないので、なにがかおかしいです。
(上がconsumer,下がproducer)
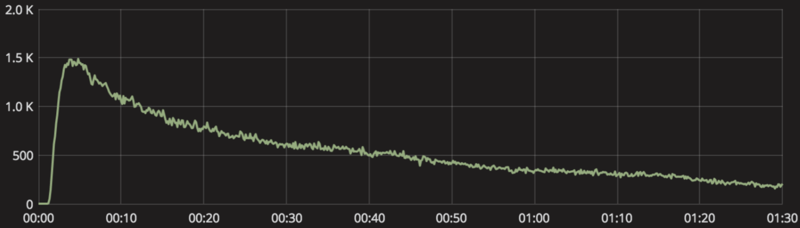
当初の見積もりでは、該当するkafka topicに関してはこの3倍くらいはconsumerのスループットが出るようにpartition数を設定していました。
kafka Streamsでは、素直に実装するとconsumerの並列度は最大でparttionの数になります。Kafkaのpartitionやconsumerの関係は、公式のドキュメントをご参照ください。
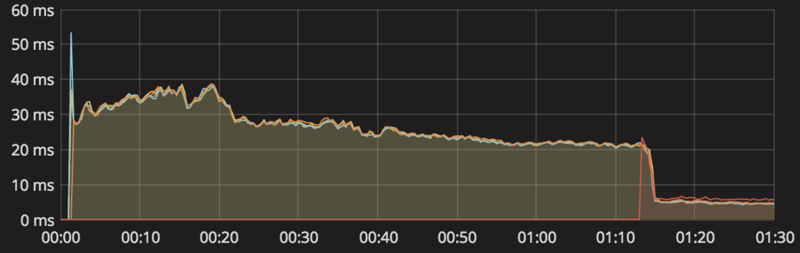
実際にconsumerのaverage latencyを見てみましょう。グラフの右側が問題がないときのaverage latencyなのですが、なんと3倍以上も差があります。
なにかしらの処理で詰まっていることが予想されます。
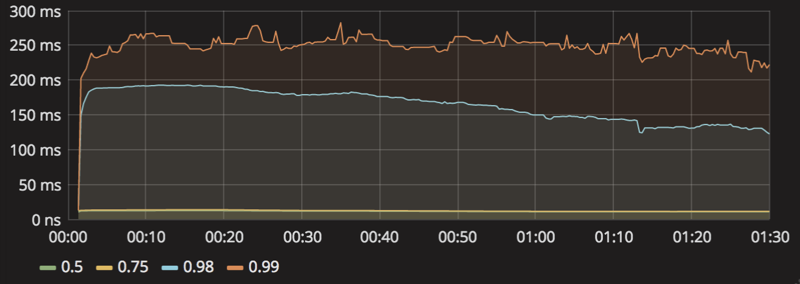
consumeスループットによって発生した多くのリクエストが内部サービス用のAPIサーバに負荷をかけているかもしれないと思い、grafanaにてlatencyを調べてみました。
すると、以下のように50-75 percentileでは10msほどですが98 percentileで200msほどもかかってしまっていることが確認できました。
通常時であればここまで遅くはありません。2%ほどの確率で200msかかっているとなると、consumerのスループットのグラフがギザギザと上下していることにも納得ができます。
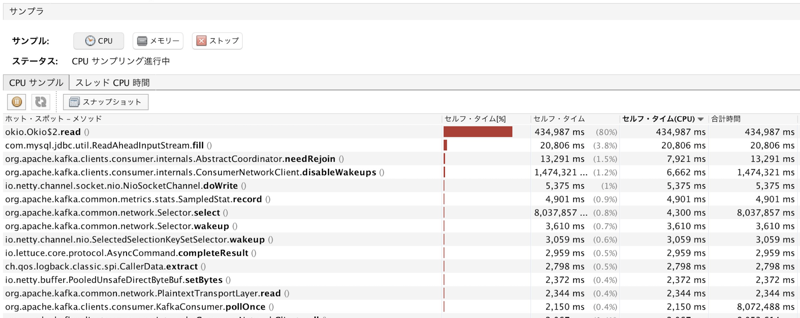
CPUプロファイラも見てみると、以下のようにHTTP client(OKHttp3)のread部分に時間を取られていることも確認できました。
解決策
ボトルネックとなっているAPIのlatencyを改善することが根本的な解決にはなりますが、そこまでの時間はありませんでした。
1月1日の夜には、一番のピークタイムになると想定しているTV番組での紹介が控えています。あまり時間は残されていません。
今回の場合はボトルネックはIOですので、consumerの並列度を高めることができれば解決できます。
consumerの並列度をあげるためには、
- partitionの数を増やす
- アプリケーションの実装を変更する
の2つの方法があります。
今回のケースでは、partitionの数を増やすことで、consumerの並列度をあげてスループットの向上を図ることにしました。既にproducingされているtopicのパーティションをダイナミックに増やす際は以下のような問題点もありますが、今回のケースでは全て許容できたため、もっとも短時間で実行でき、かつ確実な手段を選択しました。
- partitionを増やす操作の前後にproduceされたメッセージに付いては、本来は保証されているpartition毎のメッセージ順序保証が崩れる可能性がある
- producer, consumerともにconfigの変更などの必要がある
また、そもそもとして partitionの数を必要以上に増やすのもいくつかの欠点もあります。
ref: https://www.confluent.io/blog/how-to-choose-the-number-of-topicspartitions-in-a-kafka-cluster/
アプリケーションの実装を変更することも考えたのですが、掛かる実装時間とリスクの兼ね合いから止めました。今回はKafka Streamsを用いていましたが、Low-level APIを使ってこの部分を短時間に変更するのは予期しないbugを生み出す恐れがありました。
きちんと各種メトリクスを計測していたお陰で、こういった問題の原因究明や対応も素早く行うことが出来ました。その後、元旦の夜に一番のピークタイムであるTV番組の紹介を迎えましたが、何も問題は起こらず無事に終えることができました。
反省点と得られた学び
事前に負荷テスト等を用いて高負荷時の該当APIのlatencyを調べたり、負荷テストが難しい状況であれば実際に高負荷になっているときのlatencyなどを調べておくべきではありました。そうすれば、最初からpartition数を多めに設定することができました。
また、API clientのlatencyに関しては計測しているだけでalertの設定まではしていませんでした。このあたりがしっかり設定がされていれば、より素早く対応が行うこともできたはずです。
今回のアーキテクチャにKafkaを採用した際には、「遅れることはあってもロストすることは無いように」と言う意図があったので、実際にスパイクが起きたにも関わらずメッセージ送信をロストすることなく行えたことは期待通りになりました。
kafkaを使用せずにotoshidama-webだけで処理していたら、もしかするとrequest threadが枯渇し目に見える規模の障害となっていたかもしれません。
終わりに
というわけで、LINEのお年玉の開発について振り返ってみました。
来年もLINEのお年玉を実施するときは、今回得られた知見などを活かすことができればと思います。