
こんにちは。NLP Foundation Devチームの新里顕大とNLP Platform Devチームの馬越雅人、和田有輝也です。
2023年8月末に開催された研究シンポジウム「NLP若手の会(YANS)第18回シンポジウム」にて、新里が奨励賞を受賞しました。
また、同シンポジウム内で開催された「YANS分野交流ハッカソン with 言語処理学会30周年記念事業」のデモアプリ開発ハッカソンにて馬越が優秀賞・審査員特別賞を受賞し、リーダーボードハッカソンにて和田が優秀賞を受賞しました。
各受賞について報告いたします。
「HojiChar: テキスト処理パイプライン」奨励賞受賞の報告
研究シンポジウムにおいて「HojiChar: テキスト処理パイプライン」 というタイトルの発表について奨励賞をいただくことができました。発表ポスターや開発へのフィードバック、各種実験を実施をしていただいたチームの方々、YANS運営の方々に感謝致します。
奨励賞を頂いた発表は、私が開発をしている という オープンソース・ソフトウェア(OSS) についてのものです。以下には HojiChar のアピールポイントや開発経緯について紹介します。
HojiChar は、 構築の際に学習コーパスの構築に使われた、テキスト前処理ソフトウェアです。LLM の性能向上のためにコーパスの量が注目されがちですが質も重要です。その中でも前処理はコーパスの質を向上させる取り組みとして主要な役割を担っています。しかしながら、前処理というタスクを扱う際に、処理を効率よく扱うために痒いところに手が届くフレームワークがない状況でした。
テキストの前処理は、いくつもの処理のチェインからなります。比較的シンプルな処理は、
- 正規化 (Unicodeの正規化、小文字正規化、数字の正規化、改行の正規化...)
- テキスト長によるフィルタ
- 特定のキーワード (アダルトキーワード等) に一定水準でマッチする文書のフィルタ
- 各種タグ除去
などです。より高度なケースでは、
- 言語判定
- 近似重複処理
- 名詞ばかり含む文書(ワードサラダ)の排除
- 軽量言語モデルによるフィルタリング
を行う場合があります。これらの多種多様な処理は、全データに対して一律に適用されるのではなく、各コーパス種別に対して特定の設定で実施する必要があります。つまり、テキスト処理を効率よく扱うには、処理のチェインのプロファイルの構成と管理をスマートに行うことが求められます。また、コーパスは数TBにも及ぶのでこれらを効率よく処理する枠組みもあると望ましいでしょう。
HojiChar では、各処理の定義と処理チェインを分離する設計により、処理を扱いやすくしました。
各処理は次のように Filter クラスを継承して任意に定義できます。なお、主要なフィルタについては、HojiChar に事前定義されているものが利用可能です。
from hojichar import Document, Filter
class YourFilter(Filter):
def apply(self, document: Document) -> Document:
text = document.text
text = ... # 任意のテキスト処理
document.text = text
return document文長の最大値と最小値を受け取り、その範囲外のテキストにフィルタを実施する例です:
class DocumentLengthFilter(Filter): # テキスト長が一定範囲内にない文書をフィルタする
def __init__(self, min_doc_len=0, max_doc_len=10**10):
super().__init__()
self.min_doc_len = min_doc_len
self.max_doc_len = max_doc_len
def apply(self, document):
doc_len = len(doc.text)
if doc_len < self.min_doc_len:
document.is_rejected = True # 排除フラグ
if self.max_doc_len < doc_len:
document.is_rejected = True
return document処理のパイプラインは、各フィルタを Composeクラスでまとめ上げて利用します。
from hojichar import Compose
from hojichar.document_filters import *
pipeline = Compose([
JSONLoader(key="text"),
DocumentNormalizer(),
DocumentLengthFilter(max_doc_len=100),
])
pipeline('{"text": "①11"}') # '111'Compose クラスで定義したパイプラインを、入出力のインターフェイスに接続してファイル等のデータを処理します。Parallel クラスでラップすることで並列処理を簡単にサポートします。
以下はJSON Lines 形式のファイルを並列に処理して書き出す例です:
import hojichar
input_file = "your_text.jsonl"
input_doc_iter = (hojichar.Document(line) for line in open(input_file))
with hojichar.Parallel(pipeline: hojichar.Compose, num_jobs=10) as parallel: # Compose クラスで定義した pipeline を 10 並列で処理
out_doc_iter = parallel.imap_apply(input_doc_iter)
with open("your_processed_text.jsonl", "w") as fp:
for doc in out_doc_iter:
fp.write(doc.text + "\n")このほかにも、前処理の実装に役立つログを取得したり、プロファイルを所定の書式で書いてCLIで処理を実行する仕組みを用意しています。
このような実装に行き着くまでには社内外で類似の処理を実装する機会があったのですが、処理のルールや設定ファイルが肥大してコードの管理がつらくなることがよくありました。NLPに携わる人にとって「前処理は楽しくない」と認識されることが多いのですが、タスクやコードベースの管理のつらさも原因の一つにあると思っています。HojiChar を使えば個々のフィルタ処理の実装のみに集中できます。前処理のつらさを少しでも軽減して、楽しく前処理に取り組めたらと思い、HojiCharを開発しました。
@software{Shinzato_HojiChar_2023,
author = {Shinzato, Kenta},
license = {Apache-2.0},
month = sep,
title = {{HojiChar}},
url = {https://github.com/HojiChar/HojiChar},
version = {0.9.0},
year = {2023}
}デモアプリ開発ハッカソン 優秀賞・審査員特別賞受賞の報告
NLP Platform Devチームの馬越です。
デモアプリ開発ハッカソンにて優秀賞&審査員特別賞を受賞しましたことを報告します。
ハッカソンでは、OpenAI API を用いてマルチモーダルな入出力を行う Web アプリをチームで開発しました。私はGradio を使ったフロントエンド実装と全般的なサポートを担当しました。
また、優秀賞、審査員特別賞はそれぞれYANS参加者のアンケート、3名の審査員の方々の判断によって決定されました。
ハッカソンを担当された委員の方々には、企画・運営に加えてハッカソン中に技術的なサポートもしていただき、スムーズに開発を行うことができました。心より御礼申し上げます。また、チームメンバーの皆さんとはアイデア出しから実装まで (大変なところもありましたが) ワイワイ楽しく完走できました。 ありがとうございました!
以下に今回開発したアプリ「大喜利バスターズ」の内容を紹介します。
大喜利バスターズ
チームメンバー: 馬越雅人 (LINE),加藤大地 (東大),亀井遼平 (TohokuNLP),片山歩希 (NAIST)
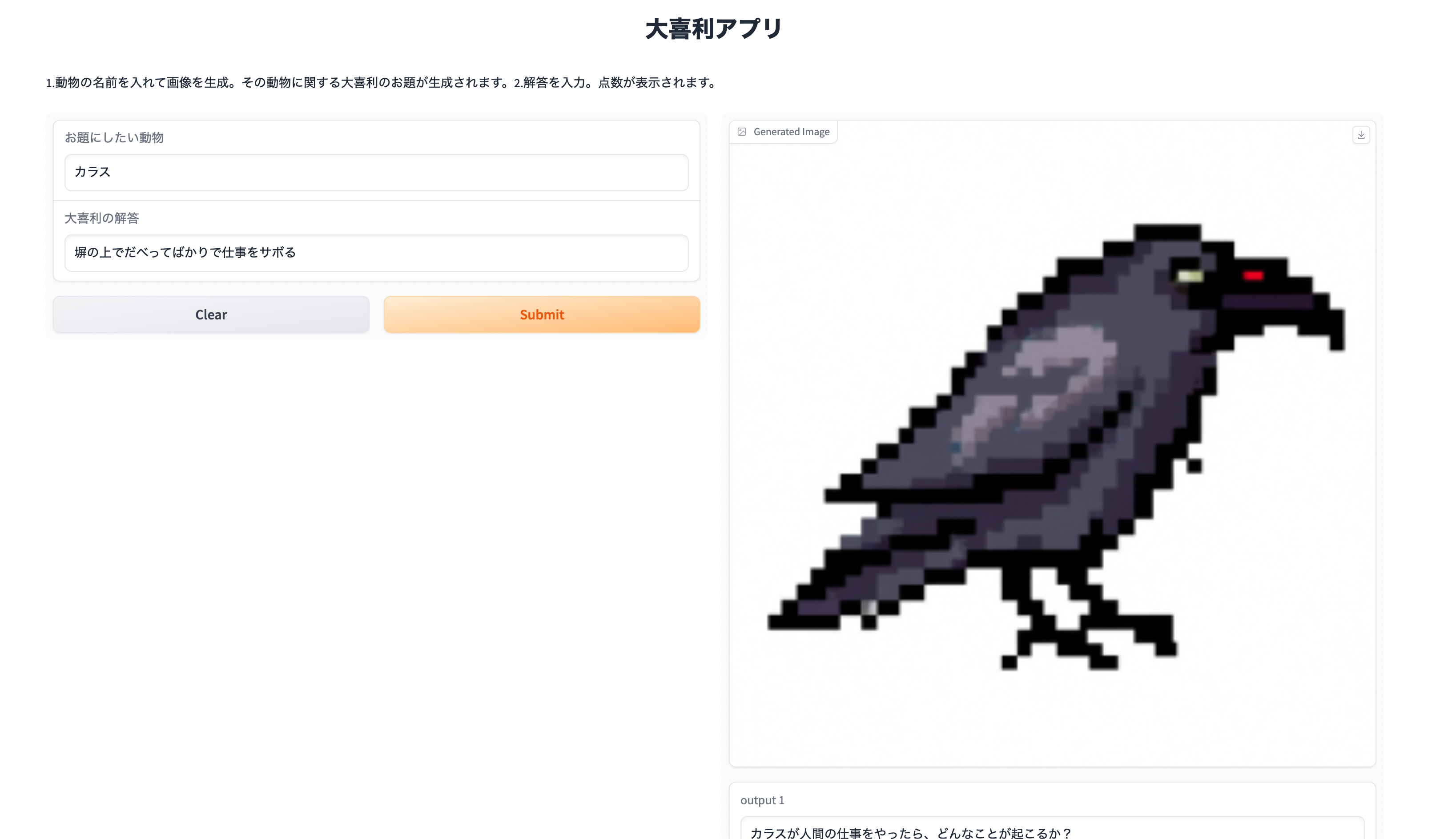
このアプリは、一言で言うと面白い大喜利を考えて敵を倒すゲームです。
まず、ユーザーは敵となる生き物の名前を入力します。するとその敵を表すドット調の画像が生成され、その生き物にまつわる大喜利のお題が生成されます。例えば、"カラス"を入力すると、"カラスが人間の仕事をやったら、どんなことが起こるか?"というお題が生成されます。
次にそのお題に対する大喜利の答えを入力すると、10点満点で採点され、その採点に至った理由が表示されます。例えば、"塀の上でだべってばかりで仕事をサボる"と入力すると、"7点\n理由:カラスの特性をうまく取り入れていて面白い。しかし、もう少し予想外の展開やオチがあるとより面白くなる可能性がある"といった回答が得られます。カラスが電線の上にいがちという特性を言語モデルが捉えられているようにも見え、面白いですね。
加えて、点数が高い場合にはその生き物が傷ついた状態になるように画像を更新するような処理も実装しました。しかしこちらは傷ついているようには見えない画像しか生成されず、あまりうまくいっていない印象でした。
技術的には、大喜利のお題生成や採点などで ChatGPT を、ドット調の画像を生成する部分で DALL・E を使用しています。
工夫した点としては、DALL・E への入力を英語に翻訳してから与えるようにしました。日本語のプロンプトではドット調の部分がうまく反映されなかったのに対し、英語でプロンプトを与えることでドット調の画像が生成されるようになりました。
また、他のチームもそれぞれユニークなアイデアを実装に落とし込んでおり、大変刺激的なハッカソンでした。
リーダーボードハッカソン 優秀賞受賞の報告
NLP Platform Devチームの和田です。
この度、YANS2023ハッカソンのリーダーボードハッカソンにチームDの一員として参加し、優秀賞を受賞しましたことを報告します。(チームD: 和田有輝也(LINE)、山本悠士さん(東京理科大)、郷原聖士さん(NAIST)、木山朔さん(都立大))
リーダーボードハッカソンの課題は生成AIを活用した広告文の生成であり、優秀賞はハッカソンの参加者全員で各チームの生成した広告文の中から良いと思ったものに投票し、最も得票数の多かったチームに贈られる賞です。賞を頂いたことを励みに、今後もより一層精進してまいります。
非常に楽しいハッカソンの場を設けてくださったYANS2023運営委員の皆様・スポンサーの皆様に心より感謝申し上げます。また、チームメンバーの皆さんとは手法の議論から実装まで楽しく取り組み、ハッカソンを完走することができました。ありがとうございました!
以下にハッカソンの課題とチームDで取り組んだことの概要を紹介します。
ハッカソンの概要
リーダーボードハッカソンの課題は生成AIを活用した広告文の生成でした。より具体的には検索連動型広告がテーマとなっており、ある商材に関する説明文(ランディングページの説明文)と検索キーワードを入力として、その商材の広告文を生成するタスクです。
チームDではChatGPT(gpt-3.5-turbo)にFew-shotプロンプトを与え、広告文を生成する手法を採りました。工夫した点は次の2つです。
1つ目はFew-shotの作り方についての工夫です。説明文・検索キーワードと広告文の例としてCAMERAデータセットの一部が提供されたのですが、チームDではこの中から3つのデータをランダムに選択し、Few-shotとして使う方法を採りました。ランダムに選択する方法を選んだのは実装の容易さもさることながら、Few-shotの多様性を保てるのではないかと考えたためです。データセットの中にはよく似た広告が多く存在していたため、データを選ぶ指標によっては似たようなデータばかりが得られてしまい、Few-shotの多様性が乏しくなることが懸念されました。また、ランダムに選択する前に説明文と検索キーワードの関連性が乏しいデータ(具体的には、説明文と検索キーワードに共通する名詞/動詞/形容詞がないようなデータ)を除外するデータクリーニングも実施しました。このデータクリーニングによって12,395件中3,705件のデータが除外され、Few-shotの品質の安定性が向上したと考えられます。
2つ目はプロンプトの工夫です。チームDでは広告文を生成する前に、説明文からその商材のセールスポイントを抽出させるようなプロンプトを設計しました。これによりセールスポイントを踏まえた訴求性の高い広告文の生成が期待できます。
以上の工夫の結果として、訴求性がありながらも忠実性・事実性を損なわない、良い広告文を生成することができました。発表資料がYANS公式ブログで公開されていますので、興味のある方はぜひこちらもご覧ください。他のチームも様々な工夫を検討・実装されており(中には先日リリースされたばかりの gpt-3.5-turbo の fine-tuning を実施しているチームもおられました!)、非常に刺激を受けました。
なお、今回のハッカソンですが、開発のために与えられた時間はなんとたったの4時間でした。スケジュールはとてもタイトでしたが、運営の方が予めベースライン手法を実装し、開発環境を整備してくださっていたおかげでスムーズに開発することができました。ChatGPTのような大規模言語モデルが利用可能な時代だからこそ実現できる、スピーディーで楽しいハッカソンでした。
おわりに
本記事では、NLP 若手の会(YANS)第18回シンポジウムにおけるLINE NLPチームの取り組みを紹介しました。このような素晴らしい交流・議論の場を準備してくださったYANS運営委員の皆様に改めてお礼申し上げます。
LINE NLPチームでは、今後も自然言語処理に関する幅広い分野における研究開発を続けてまいります。