
This is Keiji Yoshida, a data engineer from LINE Data Labs. From 2017, our team has been working on building and providing a system where any Liner could access data of services they are involved in.
Have you heard of LINE Data Labs?
LINE Data Labs is a team supporting LINE services, with data; we expertise in collecting, processing, aggregating and analyzing data for each LINE service and provide our result to service members. About 50 members consisting of machine learning engineers, data scientist, data designers and data engineers work together to collect and aggregate data and provide BI (Business Intelligence) and reporting service for visualization. We help service stakeholders to make decision with analyzed data and continually seek ways to help them such as applying machine learning to services and so on.
Room for improvement
LINE Data Labs aggregate service data on a Hadoop cluster and generate visualized reports using IBM Cognos and Tableau. Service product manager, sales, planners and engineers monitor service's KPIs such as user numbers and sales using our reports.
Our BI/reporting service is provided in the following process:
- Data designers of LINE Data Labs and service members define the KPIs to monitor and report specification.
- Data engineers of LINE Data Labs collect data on a Hadoop cluster, and develop an ETL (Extract, Transform and Load) module to process and aggregate the data collected.
- Data designers of LINE Data Labs generate reports using IBM Cognos and Tableau, and share it with the service team.

Service teams have no access to the Hadoop cluster managed by LINE Data Labs, prohibiting them to analyze data and generate reports as desired. All they could do was to view reports made by LINE Data Labs.
Opening up Hadoop cluster data to every Liner
To increase the efficiency of data analysis and reporting task, we decided to open up the data on the Hadoop cluster to all Liners and began working on it from late 2017.
Requirements
The requirements we lined up for the task are as follows.
Security
A user, that is a Liner, shall be able to access permitted data only, such as the services they are involved in. (Accesses to user data imported to or exported from the Hadoop cluster have been restricted before the opening, and still are restricted.)
Stability
- Running a large query application with massive load shall not affect other queries or applications in execution itself and performance.
- Data services shall be stable regardless of increase in number of users.
Functionality
- Users shall be able to create a query application and export data from the Hadoop cluster.
- Users shall be able to visualize extracted data as in tables or graphs.
- Users shall be able to aggregate data extracted for a report.
- Users shall be able to share the reports they made with other service members.
- Users shall be able to set a schedule to update reports automatically for reports to provide the latest information.
- Users shall be able to recompose a report by changing parameters such as aggregation period.
Implementing the requirements
For the security requirement, we've employed Kerberos authentication on the Hadoop cluster, for Apache Ranger to control which HDFS paths a user can access. For query application engine, we chose Apache Spark which can be run as a YARN application on Hadoop YARN cluster. For end-user's web interface, we chose Apache Zeppelin for the following reasons and decided to run an internal trial test:
- We can run a Spark application with a user account using user impersonation (We can apply the Apache Ranger ACL at the point of accessing the HDFS file)
- Based on Apache Zeppelin's document, and it seemed feasible to satisfy our functionality requirements.
Our trial version was structured as illustrated below.

Reality
While running the trial version, we've realized that there were a few differences between our requirements and Apache Zeppelin's features and philosophy. Here is a list of requirements that could not be satisfied.
The version we used in our trial was the latest at that point of time, v0.7.3, and the latest version at the point of writing this article is v0.8.0. Thus some of our issues may have been solved or improved in the recent release.
Security
- You can assign an account, even if it is not yours, when you set a schedule for an automatic run on Zeppelin notebooks. Running a Spark application with someone else's account can grant you an access to data that is forbidden to you as controlled by the Apache Ranger ACL (Access Control List).
- If you use a Zeppelin notebook set with someone else's account at the time of automatic run, you can edit the code for the Spark application that is to run. Which means that you can run a Spark application with someone else's account to access data that is forbidden to you as controlled by the Apache Ranger ACL.
Stability
- Apache Zeppelin can be run on a single server and Spark applications can be run only in the yarn-client mode. Which means, if a driver program of a Spark application has a big load, it will affect the whole server, making Apache Zeppelin unstable.
- With Apache Livy and Livy Interpreter, you can run a Spark application in the yarn-cluster mode, but the trade off is inefficiency in running the application due to the following reasons:
- Spark SQL, PySpark, and SparkR on the same Zeppelin notebook are ran as separate Spark applications.
- No simultaneous tasks are allowed in the same Livy session.
- Parallel execution (fair scheduler, fair pool) within the Spark application is not supported.
- If Zeppelin notebook and interpreter stop working at the same time, there will be a deadlock on Apache Zeppelin JVM and the system becomes unresponsive until Apache Zeppelin is restarted.
Functionality
- Access (reading and writing) to Zeppelin notebooks are controlled per notebook. Every time a notebook is created, we need to set permissions, increasing the load on users.
- Zeppelin notebook pages are always open in editing mode and cannot be open in read-only mode. Changing parameters without intention or changing graph layouts get saved right away.
Every time we hit a wall, we created JIRA issues and pull requests on Zeppelin's repository as listed below, in order to use Apache Zeppelin in our system.
- ZEPPELIN-2950: JIRA, GitHub
- ZEPPELIN-2995: JIRA, GitHub
- ZEPPELIN-2997: JIRA
- ZEPPELIN-3022: JIRA, GitHub
- ZEPPELIN-3045: JIRA, GitHub
- ZEPPELIN-3048: JIRA, GitHub
- ZEPPELIN-3049: JIRA, GitHub
- ZEPPELIN-3054: JIRA, GitHub
- ZEPPELIN-3066: JIRA, GitHub
- ZEPPELIN-3077: JIRA, GitHub
However, not all requests were accepted, such as amending access control, for not agreeing with Zeppelin's design philosophy. Apache Zeppelin is updated usually twice a year; after forking the official repository, we would need to backport costing us in operation and management. We came to decide that continuing with Apache Zeppelin wasn't an option for us.
So, what did we do? We decided to make our own web interface to open the data on a Hadoop cluster to Liners.
OASIS
Hence was born OASIS. We've reference the features and usages of Apache Zeppelin. Due to openness, we've casted strict access control and stability to accommodate user expansion.
Core pages of OASIS
Here are three core pages of OASIS:
Main page
The main displays the components of a root directory, also called as a space, which consists of notebooks and directories. A space is created per LINE service or a team, and permissions are granted per space. For example, we can set that a user A can only access notebooks in the Data Labs space.

Notebook reference page
This page lets you view a complete notebook. You can modify parameters such as aggregation period and rerun the notebook or recompose and change graph format.

Notebook editing page
This page lets you create or edit a notebook.
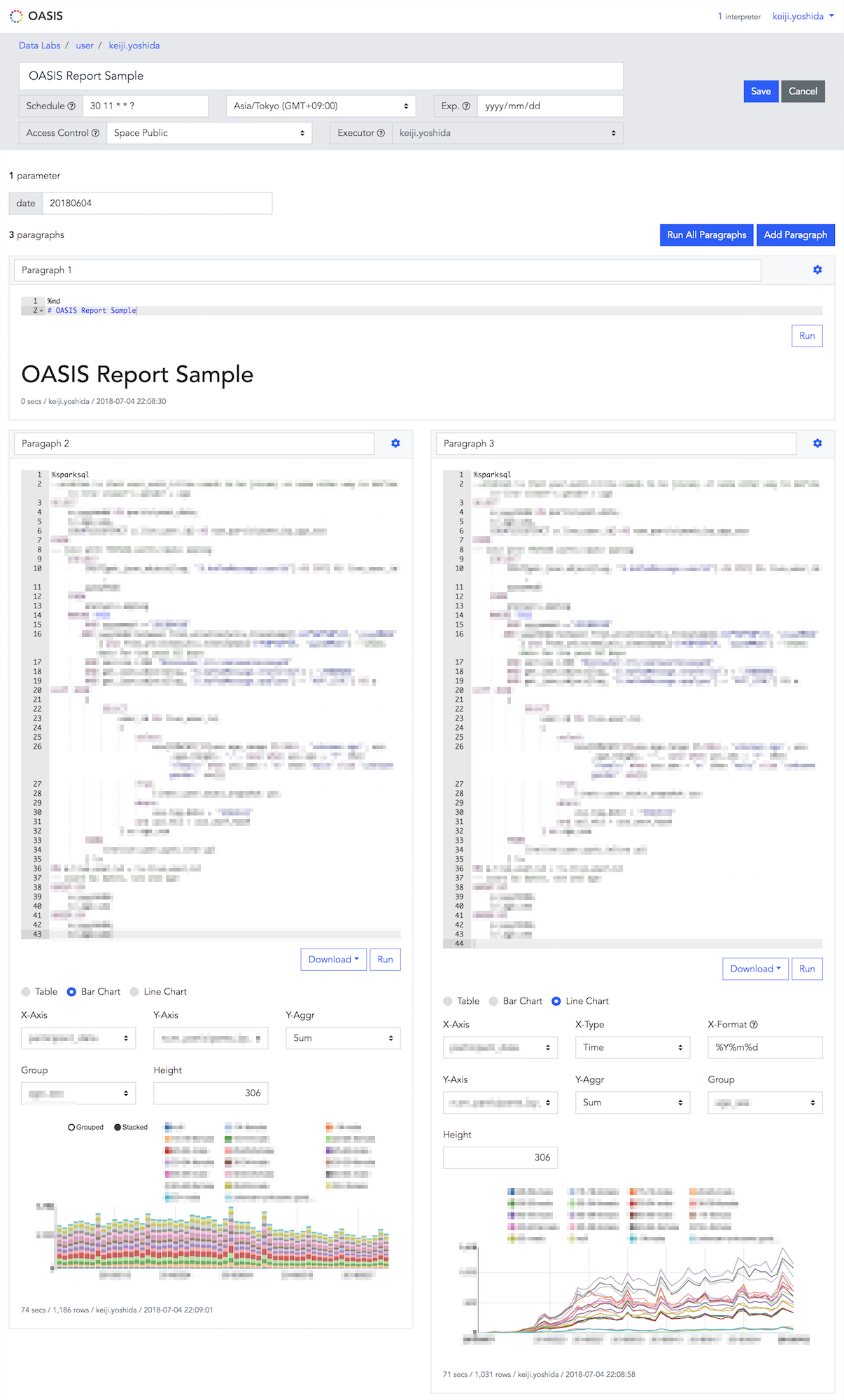
OASIS features
Here are main features and merits of OASIS:
- You can run Apache Spark applications — Spark, Spark SQL, PySpark and SparkR — and Presto queries.
- The same Spark application is shared among Spark, Spark SQL, PySpark and SparkR on the same notebook. This allows us to, for example, let SparkR process the operation result from PySpark, and get the final result using SparkSQL onto a graph. We can use three programming languages to handle the same data set.
- If you want to reference a result of running a Spark SQL query on the same notebook, you can use the memory caching on Apache Spark. First, cache the query result and access the cache from the other query to retrieve data fast. This enables you to create notebooks in an efficient manner; for example, for aggregating the same data source in various dimensions or generating graphs.
- Saving a notebook saves the result of Apache Spark applications (Spark SQL, PySpark, SparkR) and running Presto queries. When reading a notebook, the content gets displayed without accessing the Hadoop cluster.
- You can set a notebook to run on a certain date or by a set period, allowing you to maintain the notebook content up to date or implement a simple ETL module.
- Results of running SparkSQL presentable in tables, bar graphs or line graphs.
- Results of running SparkSQL are downloadable as CSV/TSV files.
- HDFS can be manipulated, for example, uploading or downloading files. (You can use the features of Ambari Files View)
- You can see Hive database, table list, and table definitions.
- You can create notebook access in the following three levels:
- Private: Authors only
- Space Public: Users with an access to the space the notebook is in can access the notebook.
- Space Public (Read Only): Users with an access to the space the notebook is in can access the notebook, but only the user who has updated the notebook the last time can edit the notebook.
- You can copy or overwrite notebooks. For example, if you need to edit and update a notebook that is already shared as a report, you can make a copy first, make modifications, and then copy it again to overwrite the original notebook to release it.
OASIS system structure
Here is an overview of the OASIS as a system. Main components are Frontend/API, Job Scheduler, and Spark/Presto Interpreter. If we experience an increase in user numbers, we can scale out all the three components.
The modifications made on Apache Spark applications and result of Presto queries that are yet to be saved are stored in Redis, the result of running applications and queries and the content of the notebook are saved in MySQL.
We've left out from the following diagram for simplicity; we are using LINE's single sign-on and we have an API server just for HDFS.

The specification of the Hadoop cluster LINE Data Labs manages at the point of writing this article is as follows:
- Number of data nodes, node managers: 500
- HDFS size: Approximately 20PB
- Number of Hive database: Approximately 70 (A database per service)
- Number of Hive tables: Approximately 1,300
Result of OASIS
In April 2018, after we've opened data to all Liners, we are actively expanding the target services and teams. As of writing this article, about 20 services and teams are using OASIS. Our monthly user count is 200. OASIS is used for various means; visualizing KPI, setting up a dashboard to view AB test progress and status, running simple ETL with scheduler, and monitoring and detecting errors on certain data (for example, notify on LINE if a service threshold is exceeded). In two months after the release, some teams are making a good use of OASIS, and some are even making reports on their own.
Since Liners can obtain what they need when they need by themselves, we are seeing people speeding things up. Also we've seen some relieved of pressure they felt in asking LINE Data Labs for data they need and some doing spot analysis. A new era has begun; self-driven data utilization is becoming common in LINE.
Ending notes
So, here was our report on 'Setting up an environment where any Liner can analyze data' which began from the end of 2017. We plan to share this story in the following two conferences:
- DataEngConf Europe, 2018/09/25–26, Barcelona
- Spark + AI Summit Europe, 2018/10/02–04, London
For your information, LINE Data Labs is seeking those of you who are interested in supporting LINE's services in terms of data analysis and utilization. New services and projects get started frequently, which means there will be an increase in requiring data analysis and related tasks. Please checkout the following links to see if any position might interest you. We look forward to having you with us!
- [LINE PLUS] Big data platform Operation/Development - Korea
- [LINE PLUS] Game data analysis - Korea
- [LINE PLUS] LINE Data analysis & Anomaly Detection - Korea
- Machine learning engineer - Tokyo
- Project manager (Machine learning) - Tokyo
- Project manager (Data analysis) - Tokyo
- Data scientist/Data analyst - Tokyo
- Data planner - Tokyo
- Front-end engineer - Tokyo
- Server engineer/Data engineer - Tokyo