
Introduction
Hello. My name is JY and I am an engineer on the LINE Rangers development team. I wonder if the readers out there have ever played LINE Rangers? It is one of the many popular LINE Games serviced through LINE, while also being an in-house developed game.
[caption align="aligncenter" width=500]
 Some screenshots from LINE Rangers.
It sure is fun freezing enemies and attacking them while they're helpless![/caption]
Some screenshots from LINE Rangers.
It sure is fun freezing enemies and attacking them while they're helpless![/caption]
LINE Rangers is a lane defense game where various LINE characters become your units. The game can be downloaded from the links below. Google Play App Store
I am currently working on server development on the LINE Rangers team; I still have much to learn. I'm also very new to the company since I have just joined in early 2014. I used to wonder what kind of server engineers would be working at a company that provided services more than five hundred million users. I also wondered about things such as how skilled they would be, and what kind of environment they would be working in. Now, I'm working amongst those very engineers. I've learned a lot after I have started server development, and I would like to share some of my experiences in this post.
This post will be about "A Rookie Engineer's Analysis on the Server of LINE Rangers." And it will be divided into the two parts you see below.
- Development Environment
- Infrastructure Environment
Development Environment
First, I would like to talk about the LINE Rangers server development environment. I will introduce the tools we use, how we work, and how our source codes are managed, combined, and distributed. FYI, this post may not be very in-depth. Some readers may already know everything that I'm going to write down here. I'm not here to amaze you with never-before-seen technology or a deep understanding of the subject matter. Consider this post as a record of my struggles as a rookie engineer; an engineer who had to spend a full day just installing an IDE and getting the Local Server up and running.
IDE
Do you remember the tools you used when you first started learning how to develop? While there are many more, I believe most of you would be familiar with IDEs (Integrated Development Environments). These let you code, debug, compile, and distribute in an all-in-one package.
 The latest version of Eclipse is LUNA. (As of March, 2015)
The latest version of Eclipse is LUNA. (As of March, 2015)
When talking about IDEs, Eclipse is probably the first thing that comes to mind. While being free, it's as powerful as any paid software is. Anyone who studied Java would have used Eclipse at one point or another. The LINE Rangers server development team also uses Eclipse. I have always wondered about what kind of IDEs would be used in the actual field, just imagine my joy when I found out that the tool I've been using since my school days was used here as well. Eclipse is not the only IDE in use here. We also use other more recently developed IDEs as well, such as IntelliJ.
 A screenshot from IntelliJ.]
A screenshot from IntelliJ.]
IntelliJ is a commercial IDE tool that has two different versions. The Community version is free for use and available to anyone, while the Ultimate version must be purchased. The Community version is open source, allowing engineers to download the source code and modify it to fit their needs. The Ultimate version is the Community version with more added functionality. Compared to the Community version, the Ultimate version near-perfectly supports more languages and frameworks.
Databases
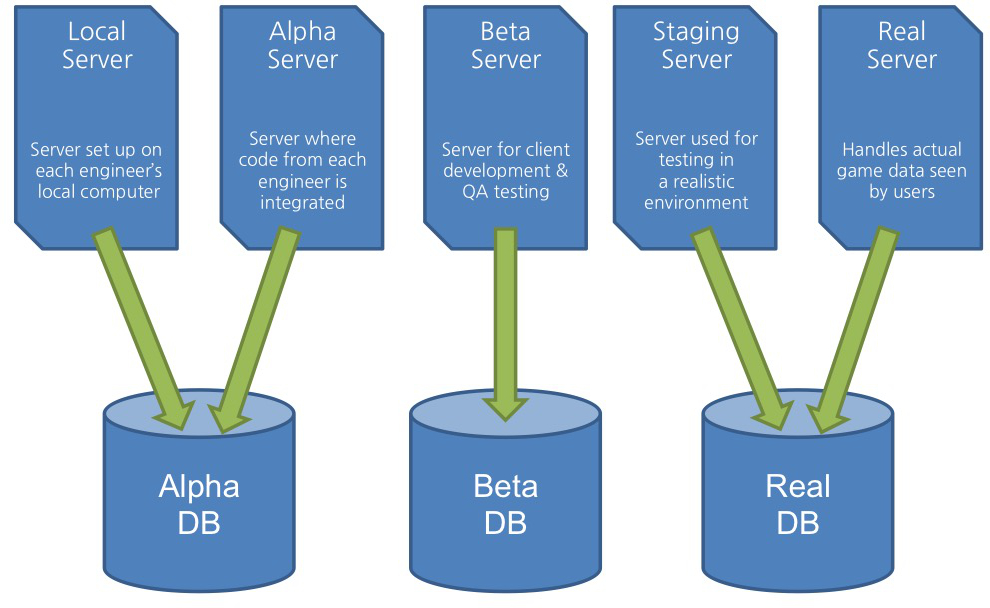
You can't talk about games without mentioning databases. With so many users that need to be managed, the importance of databases cannot be stressed enough. The DB of LINE Rangers is managed by professional DBAs (Database Administrators) who are more adept at managing DBs than the ordinary engineer. While the engineers still write query statements, they can request assistance from the DBAs if they have a query that needs to be more fine-tuned. The DBA will analyze the tables and fields of multiple DBs, revise the query and reflect the changes made to the Real DB. The LINE Rangers DB is divided into multiple phases: Alpha, Beta, and Real. We engineers handle the queries in the Alpha and Beta phases, but the Real DB is strictly restricted to the DBAs. There are different data and separate connected servers for each phase. Some of you might be wondering why we have multiple DBs when we only work on one game. Each DB phase closely relates to each development phase. The Alpha DB exists so that engineers can freely change anything during development. The Beta DB is where QA (Quality Assurance) testing is done in a realistic environment. Finally, the Real DB is where data for actual users is stored.
 The roles of a DBA during each phase
The roles of a DBA during each phase
Servers
Our DBs are divided into three phases, but how about the servers? Servers have two more phases than the DBs, divided into five phases: Local, Alpha, Beta, Staging, and Real. The first phase is the Local Server, where each engineer can develop and test their code on their local computers. In other words, running a WAS (Web Application Server) on each engineer's PC. While the Alpha Server is also used for development purposes, it differs from the Local Server. The Alpha Server is where code from each engineer is integrated into one and analyzed to find any overlaps. Also, the WAS is tested to see if it runs correctly before going to the Beta phase. The Beta Server is for QA testing, and communicating with the game client. Once the server engineers create an API, the client engineers can connect to the API to develop the client. Also, the Beta Server functions as a testing environment for QAEs (Quality Assurance Engineers) before actual release. The Staging Server provides a testing environment identical to the Real Server. Testing is done in the Staging Server before distributing to the Real Server. Since a single issue can lead to malfunction in the Real Server, a virtual version of the Real environment is used during testing. Lastly, the Real Server: the server that handles actual user data. Since this server is used to process massive amounts of data, it is physically divided into many parts. Due to the importance of this server, it is always monitored in real-time with a monitoring tool. We have gone over the databases and servers of Rangers, learning what they do in each phase. In a way, the two are inseparable. The diagram below depicts how each server is connected to each DB; five servers and three DBs forming the backend structure of LINE Rangers.
Versioning
Numerous engineers work on the LINE Rangers server, and managing code is a very important matter. A history must be kept of who did what to which module. This is known as "revision control" or "versioning." The LINE Rangers server uses SVN for versioning. We use an internal repository that allows each engineer to use SVN commands such as checkout, add, commit and revert directly from their IDE. Using the SVN features in IDE should be faster and easier than manually inputting SVN commands. Source code revisions can be safely kept under control this way.
Building/Distribution
Next, I would like to talk about the final destination of development: building and distribution. Rangers uses an internal automated system. The details are confidential so I will only describe them briefly.
Building
Our internal automated system can handle the whole process of building to distribution with a press of a button. It also displays the progress of each step in real-time. I will briefly explain the workflow below. First, you must build the source code using Maven; a convenient all-in-one tool that can compile, package, test, and distribute.
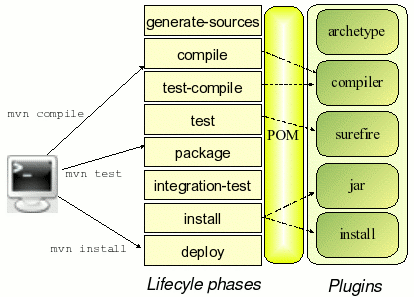 (Source: Javaworld)
(Source: Javaworld)
The diagram above depicts each phase Maven goes through. These build phase clusters called "build life cycles" each present a set of tasks that need to be done.
Distribution
Once the build is complete, it is distributed as the latest version. Below is a distribution scenario. Jenkins will create the final build going through the phases above through Maven. The build will then be uploaded to the automated system server. Jenkins is no longer required after this step as the automated system will go through the rest of the process with its predefined tasks. These tasks then divide the server distribution process into more detailed steps. The steps are as follows.
First, stop the web server and then the WAS on the machine that you want to distribute to. Second, package and distribute the build. This is the step where you will distribute the build package to a predetermined directory. Last, restart the WAS and then the web server.
Each step is written in a shell script and then sequentially run by the automated system. The results can be seen in real-time through a web browser Build/distribution is configured for all environments except for the Local Server that we discussed above in the five phases of the "Servers" section. Thanks to the automated build/distribution system, Rangers server engineers can save time and focus more on development.
Up to this point, I've explained about what kind of environment we LINE Game engineers work in. We've gone over how LINE Rangers is developed from the perspective of a server engineer. Next we will take a look at the the server structure of LINE Rangers.
Server Structure and Infrastructure Environment
 A structure diagram of the LINE Rangers server.
A structure diagram of the LINE Rangers server.
As you can see in the diagram above, the LINE Rangers server can be divided into four parts: Front, Middle, Data, External. The External part on the right represents the external common infrastructure of LINE Rangers. LINE Rangers has a system that lets you purchase in-game currency called "Rubies" with real money, and this requires a payment infrastructure set up. We could have set up our own, but we could have much more easily just used one of the existing payments modules from LINE. Using an already existing system from our platform not only saved us time, but it was much safer. We also rely on external infrastructure for LINE authentication, push notifications, team leaderboard tabulation among others. The same infrastructure supports every other LINE game as well. In other words, for anything that needs to be repeatedly implemented with each new game, we utilize what we can from the LINE platform. That's about it for the External part. Next, we'll go over the Front, Middle, and Data parts.
Front
The Front part of LINE Rangers can be divided into the Logic server and Static server. The Logic server is where requests from the client are calculated and returned or stored. Since it is often used by the client to call the API, it is sometimes called the API server. The Static server stores static files, such as images and sounds used in the game. These can also be processed in the Logic server, but LINE Rangers has a separate Static server because divvying it between the two ensures better performance. The Static server is in use when the progress bar fills up while LINE Rangers is loading the game.
LINE Rangers has an enormous player base. Everything that goes on in the game must be sent to and processed in the server, resulting in millions of requests being made if each player starts the game. That's why the LINE Rangers server, especially the API server, was designed to resist the workload.
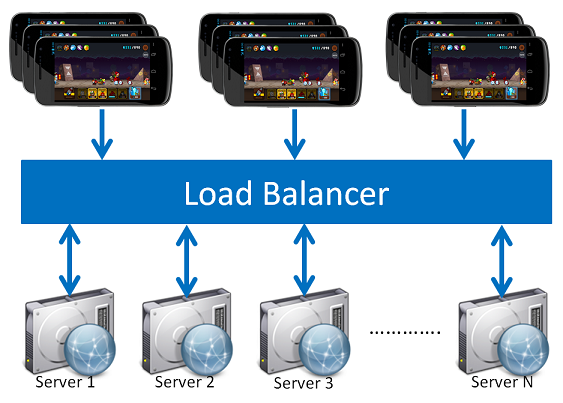 Server workload being distributed to
an indefinite amount of servers.
Server workload being distributed to
an indefinite amount of servers.
The diagram on the right is a simplified depiction of how the servers distribute the workload from numerous clients. A single server can only handle a finite number of requests at once, and that is why LINE Rangers utilizes several tens of servers. Providing a service on multiple servers like this is known as "load balancing" or "horizontal scaling." This method improves performance by using several mid-tier systems rather than using a single high-tier system. The client does not need to know the individual addresses of each server in this case. An L4 Switch device, or Load Balancer, receives requests from the clients and then hands them off to the servers in the back-end. The client only needs to know the address of this L4 Switch. The requests are distributed in a round-robin method, sequentially allocating requests to servers registered in the Load Balancer. This is how we keep the server workload in check: by keeping a Load Balancer between the client and the servers. Exactly how many servers are being used by LINE Rangers? LINE Rangers is running 85 API servers. Then are all these 85 servers physical, you may ask. The LINE Rangers server is entirely virtualized, so a single physical device can run several Logic servers.
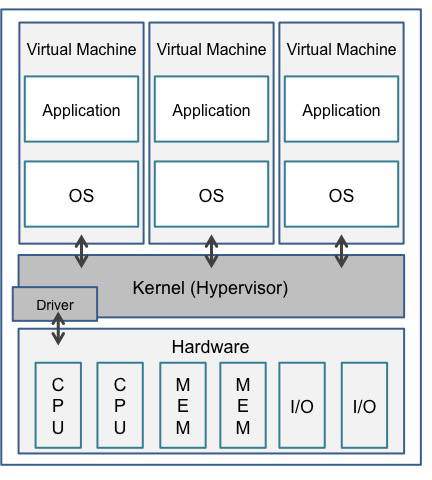 Server Virtualization
(Source: Introduction to Network Virtualization [Japanese])
Server Virtualization
(Source: Introduction to Network Virtualization [Japanese])
Simply put, server virtualization is a method of using a single physical device as several logic devices. As you can see in the diagram above, a single device can run several virtual machines. Only one actual device is needed to run several logically partitioned servers independently. Server virtualization ensures more expandability. In instances where an additional server is needed, you do not need any additional physical equipment to respond to that demand. The LINE Rangers API server is run by these 85 virtual machines. It was necessary to handle the millions of players, though it wasn't always like this from the beginning. We did not need many servers immediately after launch since there were only a small amount of players. As we expanded and gained more users, we needed a way to handle all the requests. We were able to provide service for LINE Rangers without any major issues by using server virtualization. We used the same method for all servers running LINE Rangers, including the API servers.
Middle
This part is comprised of the Queue server, Batch server, and Callback server. The Queue server exists to deal with failover, which is a backup operational mode in which the functions of a system component are assumed by secondary system components when the primary component becomes unavailable through either failure or scheduled down time. For example, if an update to the DB cannot be processed because the DB equipment is malfunctioning, the data can be sent to the Queue server and where it will be sent back later one by one once the DB is in working order. It may not be processed in real-time, but accurate recovery is guaranteed. The Batch server is where various batch jobs needed in LINE Rangers are run. The Callback server is mostly used for payment. Once payments are processed through Google or Apple's payment modules, the LINE Rangers Callback server is called, saving the results to the internal DB.
Data
This is the server that stores various data created and used in LINE Rangers. Depending on the type, data can be stored in the RDBMS or the NoSQL DB. LINE Rangers uses MySQL as an RDBMS. Out of the 19 MySQL devices in total, one set is used to store metadata. Metadata refers to the basic information used in-game, such as unit attack power and health. The location where this data is stored is called the Info DB. Another ten sets are used to store information on each user. These sets are called the User DB. You should see the Info DB and User DB in the "LINE Rangers Server Structure" diagram above. Excluding these two DBs, there are an additional 8 sets that exist to store historical data. Historical data refers to things such as coin usage records or battle result records. LINE Rangers also uses NoSQL in addition to RDBMS; an open source server called redis in particular. To be more exact we are using a modified version of redis called nBase-ARC, courtesy of LINE's parent company. ARC stands for Autonomous Redis Cluster. It is a distributed storage platform made by clustering sever redis servers, providing more ease of use. LINE Rangers puts nBase-ARC at the front-end of MySQL, using it as a cache. As seen in the "LINE Rangers Server Structure" diagram, the User Cache and Info Cache are what make up the nBase-ARC cache storage. The User Cache collects frequently used data from the User DB and then stores it on the memory. The Info Cache does the same, but it caches data from the Info DB instead.
Databases are obviously very important for data storage. However, the actual storage is done through servers, which is why the two are so closely connected. Then how are the DB and servers of LINE Rangers connected?
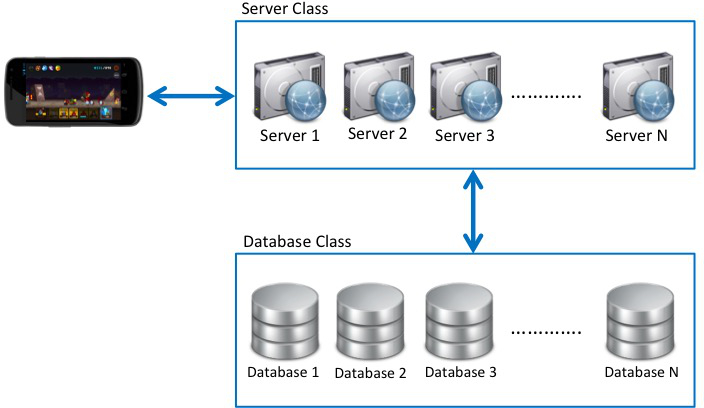 Diagram of a DB Multiplex.
Diagram of a DB Multiplex.
As you can see in the diagram above, there are multiple servers and databases. A single DB will inevitably have lower read/write performance as it needs to store data in one location, using multiple DBs can improve performance by distributing data across multiple locations. This method is known as DB Sharding, which I will go into more detail in my next post. For now, you only need to know that it's a method of distributing and storing data.
Now, let's think of a hypothetical worst-case scenario. What if one of the DB equipment malfunctions? What would happen if you cannot access any of the data stored on that DB? Obviously, the game wouldn't run. A user that has their data on a DB that is still in working order would have no problems at all, but a user that has their data in the malfunctioning DB would experience server issues. That user would be greeted with strange errors or have their game crash. Since game servers should be kept out of the average player's view as much as possible, the situation would be dire.
 Diagram of a Master-Slave Structure.
Diagram of a Master-Slave Structure.
Replicating the DB to prepare for malfunctions is known as a Master-Slave structure. By having both a Master DB and a Slave DB, the Slave can replace the Master if any problems occur. Once the Master is back in working order, it can return. There can be one or several Slaves. The important part is that there must be one Master and it must be managed separately from the Slave DB. The Slave acts as a replacement for the Master, since it should have identical data. Of course, the Slave isn't always idly waiting. The Slave DB is mostly used for data lookup. It is inefficient to read and write on a single DB since normally, it takes more time to write than read. That's why the Master DB takes care of the writing while the Slave DB is used for reading. Data written to the Master is immediately replicated to the Slave, keeping the data synced between both databases. The reason I referred to the databases as "sets" is because they are sets of Masters and Slaves. The LINE Rangers MySQL DB is comprised of the same Master-Slave structure, the Info DB in particular having one Master paired with three Slaves. The reason to this is because a lot of SELECT queries are sent to the Info DB because it stores basic information used throughout the game. In order to ensure a more stable and reliable service, we decided to place three Slave databases dedicated to reading.
Conclusion
In this post, we have gone over the following parts of the LINE Rangers server development environment.
- How we code and what IDE we use
- How we deal with versioning
- How we have structured the servers and databases
- How we build and distribute
We have also seen how the LINE Rangers server and infrastructure is designed to handle hundreds and millions of players.
- External : LINE Rangers External Infrastructure
- Front : API & Static Servers
- Middle : Failover, Callback, Batch Servers
- Data : RDBMS, NoSQL DB