何謂 PyCon PyCon 最初於 2003 成立於北美,現在世界各地皆有以 PyCon 精神成立的會議。PyCon Taiwan 則在 2012 年開始,固定舉辦年度聚會,讓大家一起討論並提倡使用 Python 程式語言,聚焦在 Python 技術與其多樣應用的交流。
重要議程分享 人工智慧民主化在台灣 第一天的 Keynote 請到台灣人工智慧學校執行長陳昇瑋來做開場,主題是人工智慧民主化在台灣,在演講中舉了很多人工智慧的例子,例如: Deepmind 的 AlphaGo 和 AlphaZero,在圖像辨識的領域中也提到 Polanyi’s Paradox (博藍尼理論):我們懂的事情比我們能表達出來的更多。也就是說我們擁有的許多知識,多數是難以完整說明的內隱知識,就像是我們不可能用明確的指令教導另一個人如何學習騎腳踏車或是辨識朋友的臉孔,所以機器學習正在克服這些限制,在不同例子中學習,利用回饋的意見解決本身的問題。另外,也說明不是每個任務都適合用在機器學習,前提需要有足夠的樣本進行分析跟反饋,且能進行大量的模擬,不需要豐富知識背景、或很複雜的邏輯、以及容錯率要高。例如德州撲克、金融方面的投資決策,因為有很多歷史資料跟結果可以進行訓練,所以適合機器學習,進而進行預測,但第三次世界大戰和七級以上的地震預測就不適合,因為樣本不夠多。演講中還有提到目前有一些初學熱門的研究項目:
Classification : 自動上色,可以將黑白照片自動上色成為彩色照片(參考網址 )。 GAN, Generative Adversarial Network (生成對抗網路) : AI 可以自動生成動畫人物(參考網址 )。 最後結論提到,今天的 AI 如同 1994 年的 WWW, 今天學 Machine Learning 如同 1994 年學 CGI/HTML。十年內,Machine Learning 會是軟體工程師必備技能,學 Python 是不會錯的,因為大家都用它學 Machine Learning。所有人都相信 AI 現在才剛起步,因此建議初學者往 semi-supervised learning, transfer learning 與 reinforcement learning 等方向發展,若 Convolutional neural network (CNN), Recurrent neural network (RNN)… 等基本模型已經了解的人可以往 GAN、Transfer Learning 和 Reinforcement Learning 學習,因為這是趨勢也比較多殺手級應用,AI 技術可能有機會像 10~20 年前大家學 HTML 一樣,不過學習門檻確實比較高,但機會相對也更多。目前台灣正在起步階段,各公司幾乎是沒有人才,就算有人才也不知道怎麼做,所以當他們去導入時候發現,就算找到公司適合導入 AI 的項目(例如:瑕疵檢測),也會因為人才不足無法規模化,因此延伸出要培養更多的 AI 人才的目標,創立了台灣人工智慧學校 (
http://aiacademy.tw/ ),目前已經陸續有畢業生及新的招生計畫。
初學者聯盟 The Beginners:超級英雄也是從初心者練起 雖然整場演講和 Python 的應用與技術沒有太大關連,但可能對於寫程式有瓶頸的人來說,提供了一些思考的方向。大部分時間講者分享他多年在專案與寫程式的經驗,主要是希望幫助初學者在學習的路上走得更順利,不是鼓勵大家成為超級英雄或是教大家如何變成超級英雄,因為現實生活中超級英雄只有在好萊塢電影裡面才有,單獨的英雄無法把事情做好,反而是需要有一個團隊,由不同專業跟程度的人所組成的。現實生活中常常只有一人在努力,其他人只是在看。其實健康的團隊會是像西遊記那樣,有一個理念高深的領導人,還有功力高強的大師兄,但可能跟領導人的理念不同,還有只會發號施令的二師兄,所以超級英雄是假的,但團隊會產生 Leader 是真的。真實世界的常態分配,工程師跟高手並不是那麼多,講者分為以下幾個層次
(資料來源:
https://morethancoding.com/2011/05/22/the-programmer-pyramid/ )打字猿:花很多時間打程式但程式對公司可能是沒有幫助的,若是沒有上進心就要小心碼農:可能因為經驗或技能不足,會想認真的把程式整理好,但通常會遇到瓶頸,會需要人來帶領才會成長靠譜工程師:會自我要求把測試寫完,確保公司內的系統可以運作工程師:是公司的主力,有能力可以撰寫延展性高而且可以重複利用的架構大師:程式可以以簡馭繁,也可以指導其他人提升講者問:寫程式需要天份嗎?他認為寫程式這動作,所有人都在做,大師這位子,可不是每個人都能坐。當過程式設計師的人都知道,讓程式會動很簡單,但要寫得讓每個接手的人都能輕易維護不是件簡單的事,沒有天份的話可以走寫程式這條路嗎?當然可以,平庸工程師的自白這篇文章 (
https://www.inside.com.tw/2015/06/12/i-am-a-mediocre-programmer ) 做了很好的鼓勵。既然天份不是太重要,所以學習最重要是動機。講者建議或許可以換個角度去思考如何學得更好,重點不是在學程式本身,可以多花點心思在其他方面,要選擇哪種程式語言反而不是太大重點,因為很多資源或新科技都是在英文網站或是社群上,如果能加強英文能力更是事半功倍。第二要學會如何問問題,有些人把社群軟體 Facebook 當作問問題的媒介,雖然會有很多熱心的人提供解答,但講者認為 Facebook 本身不是一個好的問問題的環境,尋找適合的社群發問,是很重要的。另外,台灣學生比較不擅長問問題,學會怎樣拆解問題也很重要,這會是另一個社會文化的挑戰。雖然寫程式本身是為了解決問題,但很可惜是程式語言本身就是一個很大的問題,所以為何 Python 會適合當作第一個程式語言,因為 Python 可以讓你專注在原始的問題上面,降低問題的複雜度。
Python實作運彩下注策略 作者的應用靈感來源在於過去與朋友在玩運彩的時候,因為在下注時不夠客觀,通常十賭九輸。於是作者想利用建構模型分析的方法,以科學的方式來制定下注策略,以極大化投資報酬率。本次作者以美國職籃 NBA 作為例子來進行分析,目前所有的體育賽事數據越來越複雜,而且在取得上也變得越來越方便,最後也會想找一些有趣的因子,包含使用 PTT NBA 板裡面的一些指標作為因子,如知名球評 LYS 的文章等,就是著名的反指標。接著作者也會分享如何從這些數以萬計的資訊當中獲取到真正重要的黃金資訊,這個篩選的方式則會使用 Python 基因演算法的 DEAP 套件來進行特徵的篩選,最後再依據調整出來的模型與運彩的賭盤 PK,透過調整下注策略,極大化下注報酬率。首先,整個資料來源的收集是最重要的,作者一開始的目標先以 2013 - 2017 完整賽季的比賽資料當作訓練資料,大約 6 千多筆資料,包含了:NBA 官網、PTT NBA 版、運動彩券官網。NBA 官網的資料收集是比較方便的,因為它提供了 API 的資料擷取,而 PTT 的部分是因為 LYS 的反指標理論,造成了一個值得參考的因子,該因子對於我們而言真的非常有創意。最後,運動彩券的官網並沒有提供 API 可以收集資料,所以講者利用網頁抓取工具 Beautiful Soup 來進行資料收集。有了資料後,該怎麼分類資料?作者大致上分為:
時間上的分類,大致分為一場、十場,及一年的時間區間,再分別將球員每一場的比賽資料,球員的個人能力以及球隊的基本數據放入時間的 data set。基本上這些數據是沒問題的,但是 PTT NBA 發文這個該怎麼處理?其實整個發文文章內容分佈是非常不平均的,文章大部分都座落在大市場球隊,例如:湖人隊或是勇士隊。作者就把每篇文章歸屬至球隊,再根據文章 Title 給予指標包含 「推」,「噓」,「一般回文」以及作者給予的正向或負向指標。有了這些資料的分類及準備,接下來就是透過演算法來選擇最適合的變數。
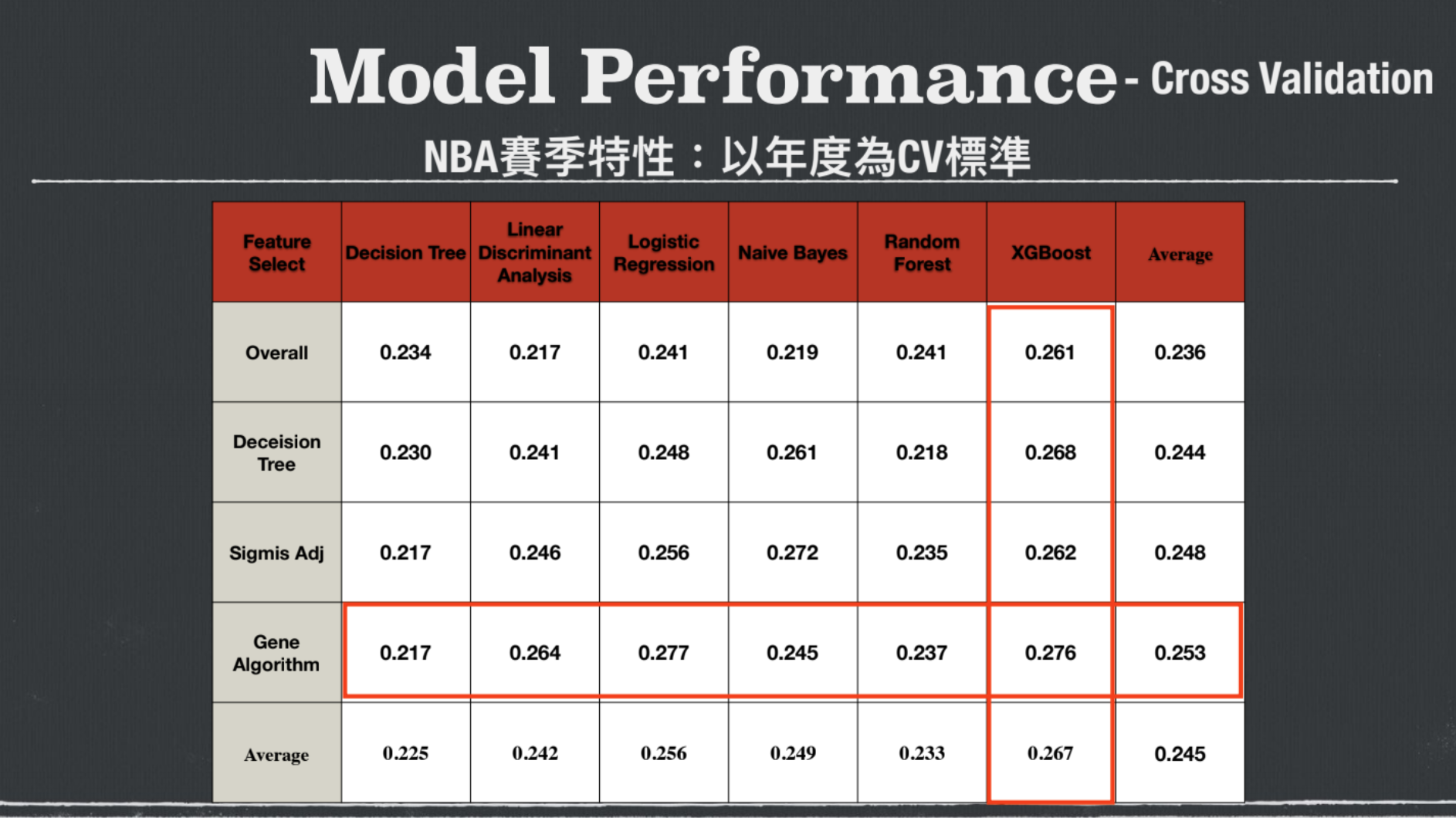
基因演算法 - 其主要目的就是為了找出最適合的變數因子以及評估函數,透過不斷進化使其獲得最佳的參數組合,最後利用基因演算法從 600 多個特徵值中找出 200 多個出來訓練模型。 決策樹分類 - 主要是用來計算每個變數的重要性. 特徵選擇 - 主要是以統計變數與目標的相關性,或以疊代排序變數來找尋具目標影響力變數,以此來排除與目標較不相關的變數,留下與目標最相近的變數,使判斷準確率能夠提升。 建立模型 - 講者利用許多的模型方法來測試與上述特徵選出的變數來交配進行運算,找出最佳方式,由下圖可知透過基因演算法搭配 XGboost 模型運算期望值最高。 有了模型後,講者開始進行下注測試,講者把投資方式大致上分成:
隨機買 只買主場 完全信任模型 加入贏球機率判斷 從期望值判斷 (將賠率考慮進來) 結論:
應用面上算是分析期望值較為適合,但是資料數據上還是不夠多或是不夠精準,例如:球員健康狀況,上場狀況等。 加強各個模型的比較、參數最佳化,以利找出最佳的模型以及結果。 球隊的變因,也還未考慮進來,例如:選秀強化了球隊戰力等。 土炮一個 LINE 股票機器人 一個有趣的分享,兩位講者透過 LINE bot 來達成選股的目的,相信非常貼近有在投資的大眾。分享主要分成兩個階段:
第一階段:講者沈弘哲主要一步一步的說明利用 Python + Flask 架構來建置整個過程。何謂 Flask? 簡言之就是一個使用 Python 撰寫的輕量級 Web 應用程式框架,由於其輕量特性,也稱為 microframework(微框架)。Flask 核心十分簡單,主要是由 Werkzeug WSGI 工具箱和 Jinja2 模板引擎所組成,Flask 和 Django 不同的地方在於 Flask 給予開發者非常大的彈性,可以選用不同的 extension 來增加其功能。講者也建議應用輕量化框架就可以滿足開發需求。以下說明動手建立 bot 的步驟: 註冊 LINE@ 帳號 LINE bot 會自動加入自己為好友 打開 webhook 設定 LINE bot Token and Secret 設定 webhook URL Deploy 到 Heroku(自帶HTTPS) 安裝 Heroku CLI 進入 LINE bot api 設定介面,設定 hook url 使用 pgAdmin4 連結 PostgreSQL 這樣便可以透過 Flask-Migrate 管理資料庫了 第二階段:該講者就依據原本架構好的環境進行資料抓取的說明,以及如何應用,大致分為五個部分: 抓取資料:到台灣證券交易所抓取即時交易資訊以及歷史交易股價。如何抓取呢? 請參考網址 繪圖:利用 MatPlotLib Artist Layer 來繪製股價線圖,但是這樣的圖該怎麼傳到 LINE 訊息呢? 講者提供了一個有趣的方式,將圖片存放到 imgur 上面,架構如下圖:(reference: https://bit.ly/2kGkOxq ) 四大賣點分析:在上方所提供的工具,有四大股票賣點分析功能 財經新聞:新聞的抓取是利用 Beautiful Soup 爬台股新聞資料 使用者資料存取:透過 LINE 提供的 API 來獲得 user_id,便可以針對不同的使用者提供個人化資料,例如個人的股票資料。 這場分享利用了 LINE API 以及許多 open source tool 的組合搭起了一個類似 AI 的機器人的應用,利用 LINE 來達到個人化的服務,證明 LINE bot 的確是一個很好的開發平台。
Crossing the Python 3 Rubicon "Cross the rubicon" 是一個英文的諺語,指的是破釜沈舟,沒有退路。Python 2.7 即將在 2020 年 1 月 1 日中止更新 (EOL),這位在美國矽谷公司 Zapier 工作的講者 Claudiu Popa,來台灣分享他們把程式碼從 Python 2.7 升級到 3.x 的心得。相較於過去的 3.x 版本來說,3.6 已經是一個很棒的版本了,相當值得升級!例如有 f-string,你可以用更簡潔的方式對字串做格式化,有 async / await 可以做更直覺的非同步處理...。既然還剩一年多,大家何不現在開始去熟悉 Python 3 的變動、將程式碼改寫成 2/3 相容的版本 (2/3 compatibility),再慢慢一個一個模組升級上去呢?可以想像到,如果我們等到最後一個月才在倉皇升級,可能會影響現有的服務營運,不是一個好的做法。將現在的程式碼轉成 2/3 相容的版本,你會需要 future 或是 six 這些
墊片 (shim),等於是中間多包一層。這些墊片在執行時期根據現在的環境版本,呼叫正確的函式版本。舉個例子,在 Python 2 常用的 urllib2.urlopen,在 Python 3 根本不存在,應該是要用 urllib。利用 six 的包裝 (wrapping),執行過 from six.moves import urllib,它幫你把 Python 2 的 urllib、urllib2、urlparse 都拉進來,一樣的程式碼在 Python 3 環境執行也不會出錯。
從 2 到 3,最需要注意的是字串的型別與處理,講者花了很大的篇幅解釋差別,還有一些小技巧。Python 2 的字串是 byte string,unicode 需要特別用 u 去修飾,如 u"unicode string"。而 Python 3 預設的字串就是 unicode,你不用特別在前面加上 u 做修飾。這件事也造成了用 Python 2 開發的程式碼在 Python 3 上面執行遇到問題。其中一個方法是,用 from __future__ import unicode_literals 的引用,將程式碼中所有出現的字串轉為 unicode 類型。
了解差別以後,難道我們要一行一行檢查、修正,程式碼有沒有符合 Python 2/3 的相容性嗎?現階段已經有幾個工具可以用了:futurize 與 modernize 都可以幫你做程式碼的升級,另外用 pylint --py3k 可以找到一些容易被前兩個工具忽略掉的相容問題,或是內建的 python -3、python -b 也可以找出一些該注意的問題。
Python 3 已經要問世 10 週年了,在此鼓勵大家檢視 Python 3 的功能、語法,除了擴展你的 Python 視野,也能用新版本帶來的語法糖 (syntactic sugar),讓你的程式碼更好讀、更容易維護。
這樣的開發環境沒問題嗎? 這個分享的講者是 MacDown 的作者 TP,除了這個 markdown 的編輯器以外,他在好幾個 Python 的開發工具上也都有貢獻。他請大家要好好的檢查自己的開發環境,避免因為疏忽、不注意,建置了一個容易發生問題的環境。工欲善其事,必先利其器,環境要穩固,我們開發才會順利。平常可能都好好的,但突然發生錯誤,你又沒有把細節摸清楚,很容易卡住無法繼續開發。首先是 dependency。我們會把開發需要用到的套件標註在 requirements.txt 裡面。有兩種策略:
(下圖左邊)abstract dependency:只有指定重要的套件,也不指定具體的版本,這樣的方式方便人工維護。 (下圖右邊)concrete dependency:列出所有的套件與指定版本,這樣的目的是可以複製出一模一樣的環境,可以降低因為環境差距而產生的問題。 你可以選擇適合的方法,或是採用這個折衷方法:人工維護一份 abstract 的 requirements.txt,但把最終環境用到的套件匯出到另一份 requirements.lock.txt:
pip freeze > requirements.lock.txt
另外,講者強力建議大家開發的時候要用虛擬環境 (virtualenv),不要把套件裝到系統全域位置,更不要用 sudo 的方式安裝,這可是有風險的!但是透過執行 bin/activate 來使用虛擬環境的方式,被很多人詬病。我們可以用別人包裝好的工具,像是
Pipenv 。Pipenv 可以一次搞定套件與虛擬環境的管理。而且,講者也是 Pipenv 的貢獻者,在分享時更是鼓勵大家使用。這衍生一個雞生蛋、蛋生雞的問題:我們一定要用虛擬環境,那麼這個管理虛擬環境的 Pipenv 工具,要不要裝在虛擬環境呢?講者建議我們遵循一個 practice:先起一個虛擬環境,然後在裡面安裝 Pipenv,最後用 symbolic link 的方式把 Pipenv 連結到使用者目錄下面。
再來是你的 Python 直譯器 (interpreters)。以 MacOS 來說,我們應該要自己編譯一份 Python 直譯器,而不該用系統內建,或是用 Homebrew 安裝的,這兩個版本都有很多問題。自己編譯沒有想像中那麼難,我們可以用
pyenv 這個工具裡面附帶的 python-build 幫你把整件事做完,裝完後一樣用 symbolic link 的方式把執行檔連結到你的預設資料夾。
Windows 沒有預設的 Python。我們自己去官網下載、安裝執行環境。但如果你想要自動安裝、並管理系統內的多個 Python 版本,你可以使用作者寫的
PythonUp :
如果想要自己硬派地編譯出最新的 Python 3.7,你需要安裝 Visual Studio 2015 或是 2017,這就工程浩大了。當你完成這些基礎工作、準備好你的開發環境,就可以繼續無憂無慮地開發 Python 了!
基本多文種平面外的溝通策略 (Communication strategies beyond the Basic Multilingual Plane) 第二天的 Keynote 請到在 Emoji 領域有多年經驗的 Katie McLaughlin 分享在人類溝通中 Emoji 是如何成為阻礙,造成誤會。隨著通用字集的標準化,世界各地的電腦能自由地互相交換資料,但身處其中的 Emoji,即便有共用的編碼,卻因為圖像沒有通用的標準而導致在不同設備上會顯示出不同的結果,這種現象將會令人誤解了語意,因而造成溝通上的不便,以下會使用幾種 Emoji 當作範例實際溝通上可能會遇到的範例。
講者首先以龍的 Emoji 來解釋發送方及接收方看到的圖像不一致可能產生的誤解,若是發送方送出圖一的 Emoji 希望表示很有力量, 但在不同設備上顯示出的 Emoji 可能像圖二這樣線條簡單而且一點也感覺不出氣勢及力量,如此一來接收方將有可能感到一頭霧水,不明白收到的 Emoji 想表達的含義是什麼。除此之外,生長背景或國家文化的差異也將導致解讀 Emoji 的不同,講者使用幾種不同的表情符號來解釋不同背景的人如何看待相同的 Emoji,以笑臉為例,在西方人的觀點中,圖三裡的兩個 Emoji 幾乎沒有任何差別,原因是西方人對於表情的解讀來源於嘴的變化而非眼睛的變化,。另一個可能導致誤解的因素是 Emoji 在大多時候看起來很小,類似的 Emoji 就有可能造成混淆,舉例來說,圖五裡的兩個 Emoji 同樣眉毛眼睛都皺在一起,嘴巴張開,有水從眼睛流下來,如果螢幕太小,在手機上看起來可能會較難辨認。對於通用的符號來說,不同文化的人通常也有可能使用不同的表示方式, 如圖六所示,日本習慣以圓圈表示OK,而在西方國家習慣以打勾表示OK。講者提到文化差異的部分其實也表現在手勢上面,不同隻手指在不同地區或不同情況下將有不同的含義。舉例來說,豎起大拇指可能表示很棒,但在潛水時表示需要上到水面。豎起大拇指在德國表示數字一,但在日本表示數字五,在澳洲可以表示需要搭便車,而在英國人眼中這個手勢則非常沒有禮貌含有鄙視的意味。Emoji隨著時間常會有新的變化,2018年的趨勢是將不同設備上的 Emoji 開始朝向通用化邁進,最好的範例就是跳舞的 Emoji,這個 Emoji 到了2017年在不同設備上已經趨向於類似的圖像,如圖七所示。但 Emoji 本身在不同設備上的差異或誤用還是時有發生,講者舉例水餃的 Emoji (圖八),在不同平台/設備上出現的可能是小籠包,可能是燒賣,這都取決於平台/設備供應商如何顯示這個圖像。最後講者提到目前依然有很多 Emoji 是日常生活中可能會用到但缺失的部分,都還有待所有人的貢獻來一起完善它,對於任何跟 Emoji 相關的資訊或是有心想要貢獻的人都能在以下的連結內找到資訊:
整場演說講者以另一種角度切入,剖析了人與人的溝通過程中會因各種因素導致的誤會及誤解,是一場非常精彩且值得令人省思的演講。
洞見驅動創新:利用 Keras,打造遊戲直播精彩剪輯 講者的公司主要產品為遊戲直播平台,為了解決影片回放率不佳的問題,講者與他的同事們希望透過 Keras 以機器學習的技術來快速剪輯影片,促進影片的回放率也進一步提升商業邏輯上的效益。一開始講者就敘述了當他們採用了這樣子的新方式之後所帶來的效益:
用戶參與度成長了兩倍 、
每週節省了 20 個小時的剪輯影片時間 ,這樣可觀的效果再再顯示了講者的團隊一開始的初衷以及方向是正確的,利用 Keras 能快速訓練模型的特性來調整參數,達到在短時間內驗證想法的可行性。講者第一個拿來當作剪輯對象的是「傳說對決」這款遊戲,該遊戲有非常清楚分明的事件畫面以及場景供講者團隊做機器學習的分類學習。
在訓練模型部分,講者團隊採用了 Transfer Learning 的方式來達到不斷訓練改進模型的預測精準度,當預測不精準時就回歸到人工標記的手法重新餵進正確的資料訓練,長久之下模型預測將越發精確。
為了達到快速驗證的效果,在分析方式上,講者團隊採用了圖像分析而非帶有時間參數的影片分析,在模型選擇上,講者團隊使用了 SqueezeNet 這樣一個高性價比的建模方式作為第一個樣板,相較於精準度較高的 MobileNet 以及 Inception V3,SqueezeNet 的成本非常低,在類別不多的分類精準度上又能與其他兩種建模方式比肩而立。講者團隊將 SqueezeNet 的輸出階層抽換成團隊自定義的分類器,得到圖像分類的結果,再根據分類結果後處理 (post-processing) 剪出一段影片。但結果常不盡如人意,遊戲操作過程中總會錄到不預期的畫面,講者團隊沒預先過濾的狀況下,有時會剪輯出非遊戲畫面或不精彩的場景。為了解決這個問題,講者團隊透過一些條件設定以及定義不同的類別,來區分真正符合商業邏輯的影片片段。
透過這樣不斷調整模型修改參數的方式,講者團隊在「傳說對決」這款遊戲的影片剪輯準確率高達 98%,市場營銷部門也藉由這項新的功能節省大量人力並且帶來很好的效益。講者團隊目前已將同樣模式套用到不同款遊戲之上繼續開發;在開發規劃上,未來將會加入語音辨識當作特徵向量、防止非遊戲畫面的影像剪輯、提供即時回饋給玩家。
結語 這次的議程大量的分享 AI 的成長趨勢。透過 Python 實作,應用在股票的推薦、自動錄影剪輯,甚至是台灣流行的運動彩券分析等。這似乎是大勢所趨,工程師們都應該要學習相關知識,並累積開發經驗。LINE Taiwan 的工程師會持續參加 PyCon Taiwan,或是其他國家的 PyCon,與其他會眾交流,了解更多技術的更新與時事的應用。這次的參與學到很多有用的知識,並且可以應用在我們的工作上,可謂收穫滿滿。


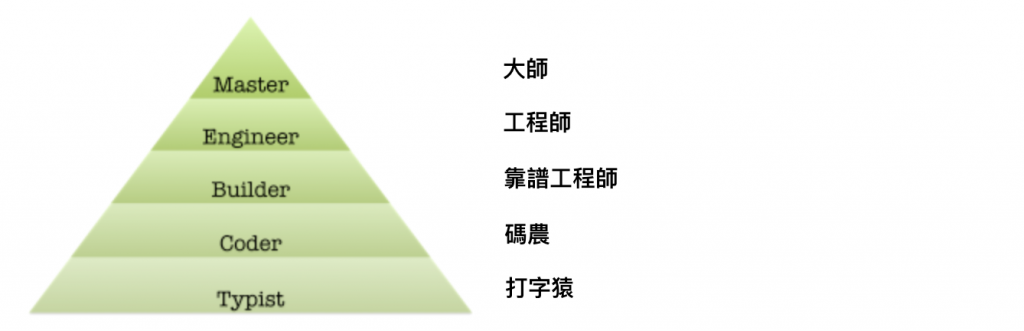 (資料來源:https://morethancoding.com/2011/05/22/the-programmer-pyramid/)打字猿:花很多時間打程式但程式對公司可能是沒有幫助的,若是沒有上進心就要小心碼農:可能因為經驗或技能不足,會想認真的把程式整理好,但通常會遇到瓶頸,會需要人來帶領才會成長靠譜工程師:會自我要求把測試寫完,確保公司內的系統可以運作工程師:是公司的主力,有能力可以撰寫延展性高而且可以重複利用的架構大師:程式可以以簡馭繁,也可以指導其他人提升講者問:寫程式需要天份嗎?他認為寫程式這動作,所有人都在做,大師這位子,可不是每個人都能坐。當過程式設計師的人都知道,讓程式會動很簡單,但要寫得讓每個接手的人都能輕易維護不是件簡單的事,沒有天份的話可以走寫程式這條路嗎?當然可以,平庸工程師的自白這篇文章 (https://www.inside.com.tw/2015/06/12/i-am-a-mediocre-programmer) 做了很好的鼓勵。既然天份不是太重要,所以學習最重要是動機。講者建議或許可以換個角度去思考如何學得更好,重點不是在學程式本身,可以多花點心思在其他方面,要選擇哪種程式語言反而不是太大重點,因為很多資源或新科技都是在英文網站或是社群上,如果能加強英文能力更是事半功倍。第二要學會如何問問題,有些人把社群軟體 Facebook 當作問問題的媒介,雖然會有很多熱心的人提供解答,但講者認為 Facebook 本身不是一個好的問問題的環境,尋找適合的社群發問,是很重要的。另外,台灣學生比較不擅長問問題,學會怎樣拆解問題也很重要,這會是另一個社會文化的挑戰。雖然寫程式本身是為了解決問題,但很可惜是程式語言本身就是一個很大的問題,所以為何 Python 會適合當作第一個程式語言,因為 Python 可以讓你專注在原始的問題上面,降低問題的複雜度。
(資料來源:https://morethancoding.com/2011/05/22/the-programmer-pyramid/)打字猿:花很多時間打程式但程式對公司可能是沒有幫助的,若是沒有上進心就要小心碼農:可能因為經驗或技能不足,會想認真的把程式整理好,但通常會遇到瓶頸,會需要人來帶領才會成長靠譜工程師:會自我要求把測試寫完,確保公司內的系統可以運作工程師:是公司的主力,有能力可以撰寫延展性高而且可以重複利用的架構大師:程式可以以簡馭繁,也可以指導其他人提升講者問:寫程式需要天份嗎?他認為寫程式這動作,所有人都在做,大師這位子,可不是每個人都能坐。當過程式設計師的人都知道,讓程式會動很簡單,但要寫得讓每個接手的人都能輕易維護不是件簡單的事,沒有天份的話可以走寫程式這條路嗎?當然可以,平庸工程師的自白這篇文章 (https://www.inside.com.tw/2015/06/12/i-am-a-mediocre-programmer) 做了很好的鼓勵。既然天份不是太重要,所以學習最重要是動機。講者建議或許可以換個角度去思考如何學得更好,重點不是在學程式本身,可以多花點心思在其他方面,要選擇哪種程式語言反而不是太大重點,因為很多資源或新科技都是在英文網站或是社群上,如果能加強英文能力更是事半功倍。第二要學會如何問問題,有些人把社群軟體 Facebook 當作問問題的媒介,雖然會有很多熱心的人提供解答,但講者認為 Facebook 本身不是一個好的問問題的環境,尋找適合的社群發問,是很重要的。另外,台灣學生比較不擅長問問題,學會怎樣拆解問題也很重要,這會是另一個社會文化的挑戰。雖然寫程式本身是為了解決問題,但很可惜是程式語言本身就是一個很大的問題,所以為何 Python 會適合當作第一個程式語言,因為 Python 可以讓你專注在原始的問題上面,降低問題的複雜度。
 透過函數計算後,得到了重要變數大部分都落於球隊過去的交手紀錄,而球員數據的重要性或是 PTT NBA 版的 LYS 反指標分析是相對的低很多。
透過函數計算後,得到了重要變數大部分都落於球隊過去的交手紀錄,而球員數據的重要性或是 PTT NBA 版的 LYS 反指標分析是相對的低很多。



 從 2 到 3,最需要注意的是字串的型別與處理,講者花了很大的篇幅解釋差別,還有一些小技巧。Python 2 的字串是 byte string,unicode 需要特別用 u 去修飾,如 u"unicode string"。而 Python 3 預設的字串就是 unicode,你不用特別在前面加上 u 做修飾。這件事也造成了用 Python 2 開發的程式碼在 Python 3 上面執行遇到問題。其中一個方法是,用 from __future__ import unicode_literals 的引用,將程式碼中所有出現的字串轉為 unicode 類型。
從 2 到 3,最需要注意的是字串的型別與處理,講者花了很大的篇幅解釋差別,還有一些小技巧。Python 2 的字串是 byte string,unicode 需要特別用 u 去修飾,如 u"unicode string"。而 Python 3 預設的字串就是 unicode,你不用特別在前面加上 u 做修飾。這件事也造成了用 Python 2 開發的程式碼在 Python 3 上面執行遇到問題。其中一個方法是,用 from __future__ import unicode_literals 的引用,將程式碼中所有出現的字串轉為 unicode 類型。
 了解差別以後,難道我們要一行一行檢查、修正,程式碼有沒有符合 Python 2/3 的相容性嗎?現階段已經有幾個工具可以用了:futurize 與 modernize 都可以幫你做程式碼的升級,另外用 pylint --py3k 可以找到一些容易被前兩個工具忽略掉的相容問題,或是內建的 python -3、python -b 也可以找出一些該注意的問題。
了解差別以後,難道我們要一行一行檢查、修正,程式碼有沒有符合 Python 2/3 的相容性嗎?現階段已經有幾個工具可以用了:futurize 與 modernize 都可以幫你做程式碼的升級,另外用 pylint --py3k 可以找到一些容易被前兩個工具忽略掉的相容問題,或是內建的 python -3、python -b 也可以找出一些該注意的問題。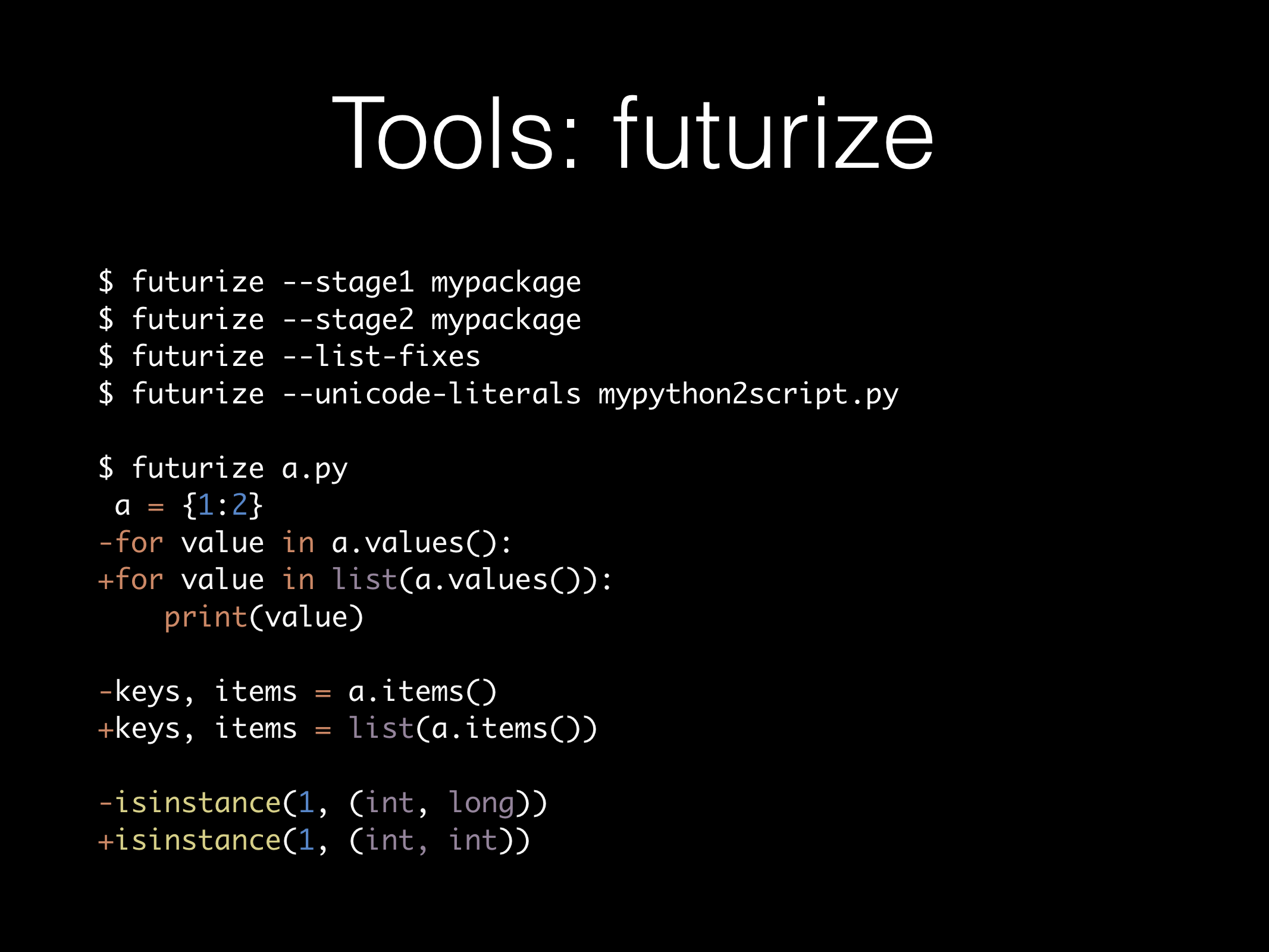

 Python 3 已經要問世 10 週年了,在此鼓勵大家檢視 Python 3 的功能、語法,除了擴展你的 Python 視野,也能用新版本帶來的語法糖 (syntactic sugar),讓你的程式碼更好讀、更容易維護。
Python 3 已經要問世 10 週年了,在此鼓勵大家檢視 Python 3 的功能、語法,除了擴展你的 Python 視野,也能用新版本帶來的語法糖 (syntactic sugar),讓你的程式碼更好讀、更容易維護。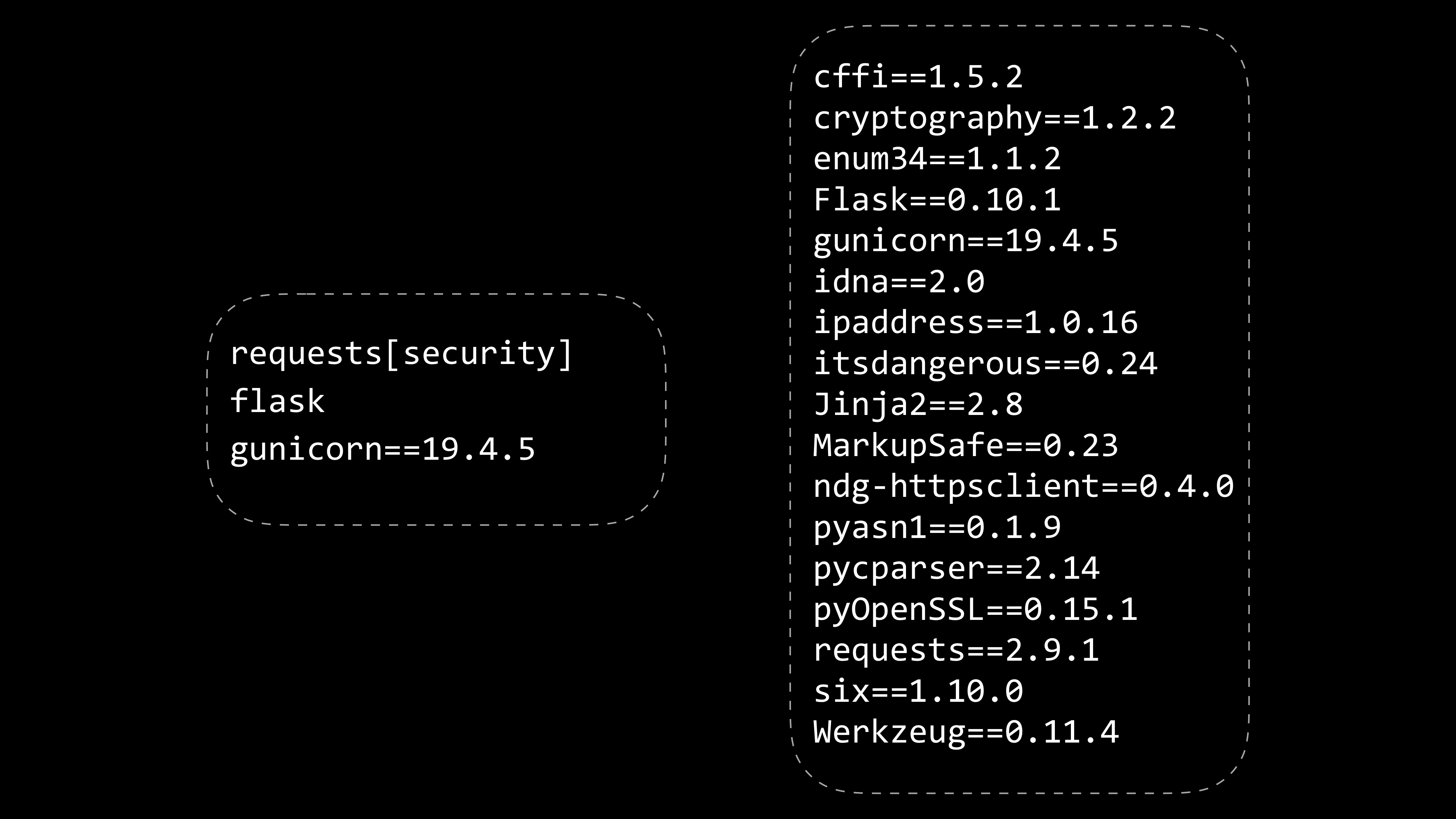 你可以選擇適合的方法,或是採用這個折衷方法:人工維護一份 abstract 的 requirements.txt,但把最終環境用到的套件匯出到另一份 requirements.lock.txt:
你可以選擇適合的方法,或是採用這個折衷方法:人工維護一份 abstract 的 requirements.txt,但把最終環境用到的套件匯出到另一份 requirements.lock.txt: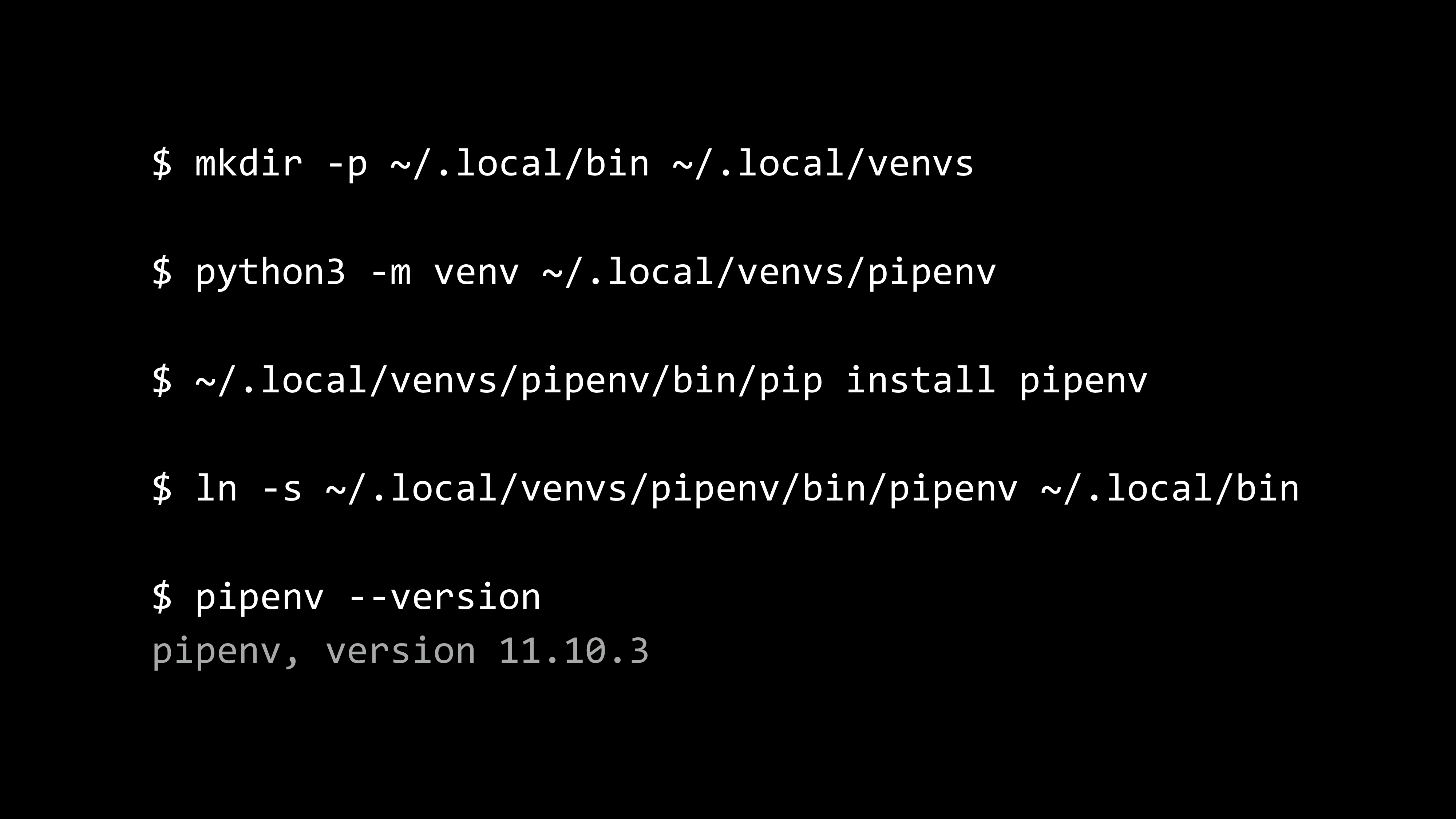 再來是你的 Python 直譯器 (interpreters)。以 MacOS 來說,我們應該要自己編譯一份 Python 直譯器,而不該用系統內建,或是用 Homebrew 安裝的,這兩個版本都有很多問題。自己編譯沒有想像中那麼難,我們可以用 pyenv 這個工具裡面附帶的 python-build 幫你把整件事做完,裝完後一樣用 symbolic link 的方式把執行檔連結到你的預設資料夾。
再來是你的 Python 直譯器 (interpreters)。以 MacOS 來說,我們應該要自己編譯一份 Python 直譯器,而不該用系統內建,或是用 Homebrew 安裝的,這兩個版本都有很多問題。自己編譯沒有想像中那麼難,我們可以用 pyenv 這個工具裡面附帶的 python-build 幫你把整件事做完,裝完後一樣用 symbolic link 的方式把執行檔連結到你的預設資料夾。 Windows 沒有預設的 Python。我們自己去官網下載、安裝執行環境。但如果你想要自動安裝、並管理系統內的多個 Python 版本,你可以使用作者寫的 PythonUp:
Windows 沒有預設的 Python。我們自己去官網下載、安裝執行環境。但如果你想要自動安裝、並管理系統內的多個 Python 版本,你可以使用作者寫的 PythonUp: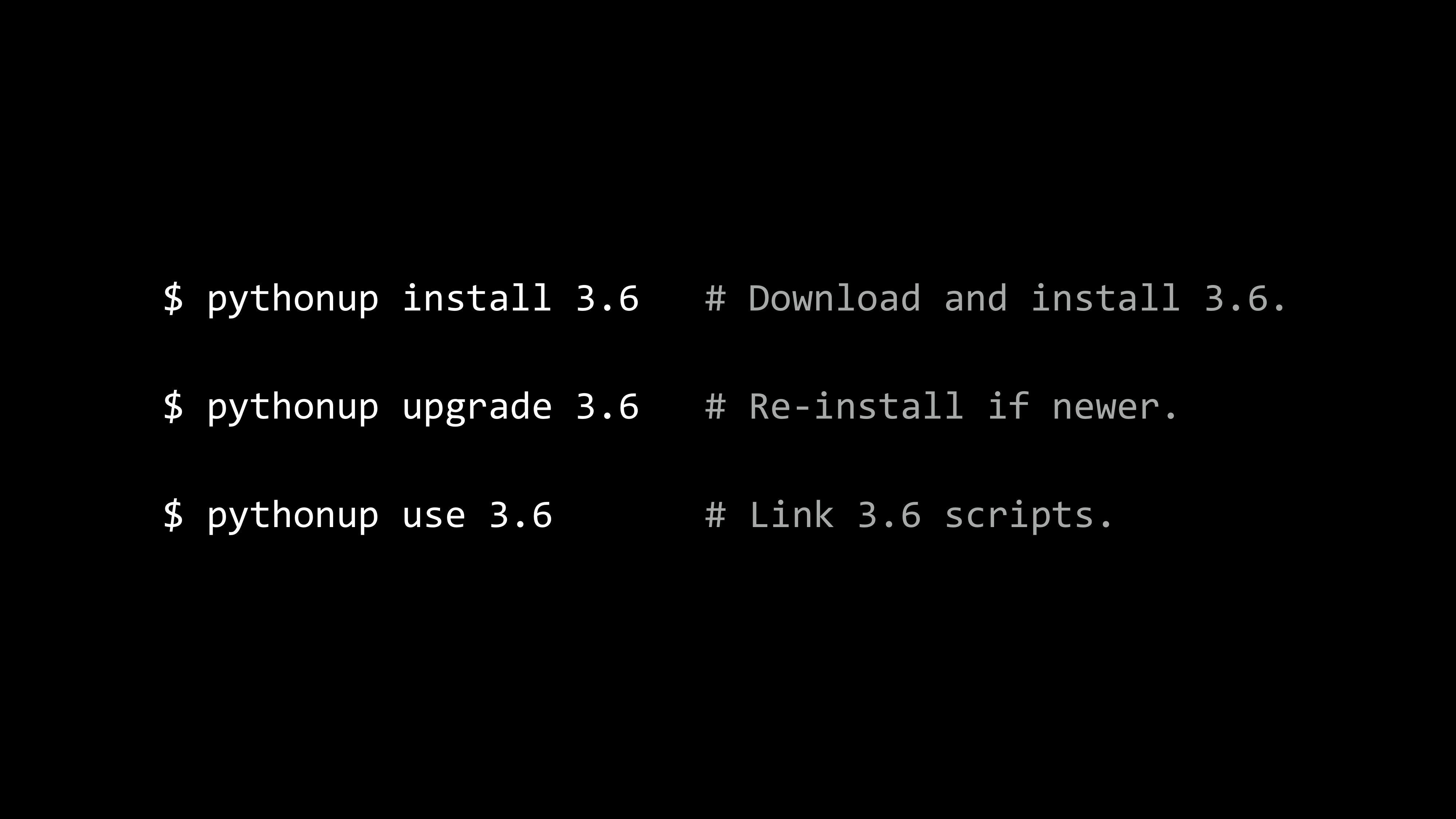 如果想要自己硬派地編譯出最新的 Python 3.7,你需要安裝 Visual Studio 2015 或是 2017,這就工程浩大了。當你完成這些基礎工作、準備好你的開發環境,就可以繼續無憂無慮地開發 Python 了!
如果想要自己硬派地編譯出最新的 Python 3.7,你需要安裝 Visual Studio 2015 或是 2017,這就工程浩大了。當你完成這些基礎工作、準備好你的開發環境,就可以繼續無憂無慮地開發 Python 了! 講者首先以龍的 Emoji 來解釋發送方及接收方看到的圖像不一致可能產生的誤解,若是發送方送出圖一的 Emoji 希望表示很有力量, 但在不同設備上顯示出的 Emoji 可能像圖二這樣線條簡單而且一點也感覺不出氣勢及力量,如此一來接收方將有可能感到一頭霧水,不明白收到的 Emoji 想表達的含義是什麼。除此之外,生長背景或國家文化的差異也將導致解讀 Emoji 的不同,講者使用幾種不同的表情符號來解釋不同背景的人如何看待相同的 Emoji,以笑臉為例,在西方人的觀點中,圖三裡的兩個 Emoji 幾乎沒有任何差別,原因是西方人對於表情的解讀來源於嘴的變化而非眼睛的變化,比較不容易造成誤解的笑臉則像圖四的 Emoji。另一個可能導致誤解的因素是 Emoji 在大多時候看起來很小,類似的 Emoji 就有可能造成混淆,舉例來說,圖五裡的兩個 Emoji 同樣眉毛眼睛都皺在一起,嘴巴張開,有水從眼睛流下來,如果螢幕太小,在手機上看起來可能會較難辨認。對於通用的符號來說,不同文化的人通常也有可能使用不同的表示方式, 如圖六所示,日本習慣以圓圈表示OK,而在西方國家習慣以打勾表示OK。講者提到文化差異的部分其實也表現在手勢上面,不同隻手指在不同地區或不同情況下將有不同的含義。舉例來說,豎起大拇指可能表示很棒,但在潛水時表示需要上到水面。豎起大拇指在德國表示數字一,但在日本表示數字五,在澳洲可以表示需要搭便車,而在英國人眼中這個手勢則非常沒有禮貌含有鄙視的意味。Emoji隨著時間常會有新的變化,2018年的趨勢是將不同設備上的 Emoji 開始朝向通用化邁進,最好的範例就是跳舞的 Emoji,這個 Emoji 到了2017年在不同設備上已經趨向於類似的圖像,如圖七所示。但 Emoji 本身在不同設備上的差異或誤用還是時有發生,講者舉例水餃的 Emoji (圖八),在不同平台/設備上出現的可能是小籠包,可能是燒賣,這都取決於平台/設備供應商如何顯示這個圖像。最後講者提到目前依然有很多 Emoji 是日常生活中可能會用到但缺失的部分,都還有待所有人的貢獻來一起完善它,對於任何跟 Emoji 相關的資訊或是有心想要貢獻的人都能在以下的連結內找到資訊:整場演說講者以另一種角度切入,剖析了人與人的溝通過程中會因各種因素導致的誤會及誤解,是一場非常精彩且值得令人省思的演講。
講者首先以龍的 Emoji 來解釋發送方及接收方看到的圖像不一致可能產生的誤解,若是發送方送出圖一的 Emoji 希望表示很有力量, 但在不同設備上顯示出的 Emoji 可能像圖二這樣線條簡單而且一點也感覺不出氣勢及力量,如此一來接收方將有可能感到一頭霧水,不明白收到的 Emoji 想表達的含義是什麼。除此之外,生長背景或國家文化的差異也將導致解讀 Emoji 的不同,講者使用幾種不同的表情符號來解釋不同背景的人如何看待相同的 Emoji,以笑臉為例,在西方人的觀點中,圖三裡的兩個 Emoji 幾乎沒有任何差別,原因是西方人對於表情的解讀來源於嘴的變化而非眼睛的變化,比較不容易造成誤解的笑臉則像圖四的 Emoji。另一個可能導致誤解的因素是 Emoji 在大多時候看起來很小,類似的 Emoji 就有可能造成混淆,舉例來說,圖五裡的兩個 Emoji 同樣眉毛眼睛都皺在一起,嘴巴張開,有水從眼睛流下來,如果螢幕太小,在手機上看起來可能會較難辨認。對於通用的符號來說,不同文化的人通常也有可能使用不同的表示方式, 如圖六所示,日本習慣以圓圈表示OK,而在西方國家習慣以打勾表示OK。講者提到文化差異的部分其實也表現在手勢上面,不同隻手指在不同地區或不同情況下將有不同的含義。舉例來說,豎起大拇指可能表示很棒,但在潛水時表示需要上到水面。豎起大拇指在德國表示數字一,但在日本表示數字五,在澳洲可以表示需要搭便車,而在英國人眼中這個手勢則非常沒有禮貌含有鄙視的意味。Emoji隨著時間常會有新的變化,2018年的趨勢是將不同設備上的 Emoji 開始朝向通用化邁進,最好的範例就是跳舞的 Emoji,這個 Emoji 到了2017年在不同設備上已經趨向於類似的圖像,如圖七所示。但 Emoji 本身在不同設備上的差異或誤用還是時有發生,講者舉例水餃的 Emoji (圖八),在不同平台/設備上出現的可能是小籠包,可能是燒賣,這都取決於平台/設備供應商如何顯示這個圖像。最後講者提到目前依然有很多 Emoji 是日常生活中可能會用到但缺失的部分,都還有待所有人的貢獻來一起完善它,對於任何跟 Emoji 相關的資訊或是有心想要貢獻的人都能在以下的連結內找到資訊:整場演說講者以另一種角度切入,剖析了人與人的溝通過程中會因各種因素導致的誤會及誤解,是一場非常精彩且值得令人省思的演講。 在訓練模型部分,講者團隊採用了 Transfer Learning 的方式來達到不斷訓練改進模型的預測精準度,當預測不精準時就回歸到人工標記的手法重新餵進正確的資料訓練,長久之下模型預測將越發精確。
在訓練模型部分,講者團隊採用了 Transfer Learning 的方式來達到不斷訓練改進模型的預測精準度,當預測不精準時就回歸到人工標記的手法重新餵進正確的資料訓練,長久之下模型預測將越發精確。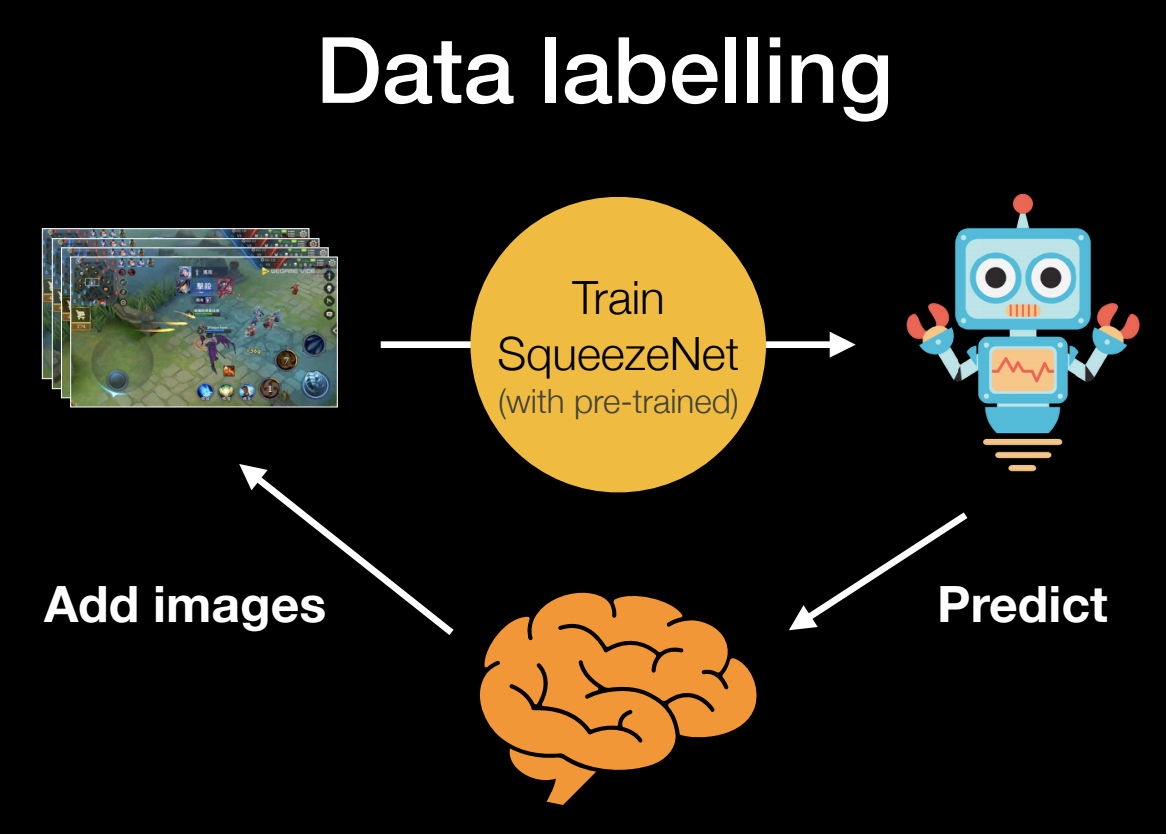 為了達到快速驗證的效果,在分析方式上,講者團隊採用了圖像分析而非帶有時間參數的影片分析,在模型選擇上,講者團隊使用了 SqueezeNet 這樣一個高性價比的建模方式作為第一個樣板,相較於精準度較高的 MobileNet 以及 Inception V3,SqueezeNet 的成本非常低,在類別不多的分類精準度上又能與其他兩種建模方式比肩而立。講者團隊將 SqueezeNet 的輸出階層抽換成團隊自定義的分類器,得到圖像分類的結果,再根據分類結果後處理 (post-processing) 剪出一段影片。但結果常不盡如人意,遊戲操作過程中總會錄到不預期的畫面,講者團隊沒預先過濾的狀況下,有時會剪輯出非遊戲畫面或不精彩的場景。為了解決這個問題,講者團隊透過一些條件設定以及定義不同的類別,來區分真正符合商業邏輯的影片片段。
為了達到快速驗證的效果,在分析方式上,講者團隊採用了圖像分析而非帶有時間參數的影片分析,在模型選擇上,講者團隊使用了 SqueezeNet 這樣一個高性價比的建模方式作為第一個樣板,相較於精準度較高的 MobileNet 以及 Inception V3,SqueezeNet 的成本非常低,在類別不多的分類精準度上又能與其他兩種建模方式比肩而立。講者團隊將 SqueezeNet 的輸出階層抽換成團隊自定義的分類器,得到圖像分類的結果,再根據分類結果後處理 (post-processing) 剪出一段影片。但結果常不盡如人意,遊戲操作過程中總會錄到不預期的畫面,講者團隊沒預先過濾的狀況下,有時會剪輯出非遊戲畫面或不精彩的場景。為了解決這個問題,講者團隊透過一些條件設定以及定義不同的類別,來區分真正符合商業邏輯的影片片段。 透過這樣不斷調整模型修改參數的方式,講者團隊在「傳說對決」這款遊戲的影片剪輯準確率高達 98%,市場營銷部門也藉由這項新的功能節省大量人力並且帶來很好的效益。講者團隊目前已將同樣模式套用到不同款遊戲之上繼續開發;在開發規劃上,未來將會加入語音辨識當作特徵向量、防止非遊戲畫面的影像剪輯、提供即時回饋給玩家。
透過這樣不斷調整模型修改參數的方式,講者團隊在「傳說對決」這款遊戲的影片剪輯準確率高達 98%,市場營銷部門也藉由這項新的功能節省大量人力並且帶來很好的效益。講者團隊目前已將同樣模式套用到不同款遊戲之上繼續開發;在開發規劃上,未來將會加入語音辨識當作特徵向量、防止非遊戲畫面的影像剪輯、提供即時回饋給玩家。