
以通訊軟體為核心,LINE 持續發展圍繞用戶生活的各種服務,同時也抱持著開放的態度,積極與不同的平台或開發工具串聯。因此,我們鼓勵、更贊助 LINE 的工程師參與各式各樣的外部研討會,激發更多創意或合作的可能性,並於會後撰寫見聞,分享給 LINE Engineering Blog 的讀者們
《LINE 強力徵才中!》與我們一起 Close the Distance 串聯智慧新世界 >> 詳細職缺訊息
大家好,我們是 LINE SHOPPING 的資料工程師 Joseph 與 Responder,很高興這次能參加 Microsoft DevDay Asia 2019 亞太技術年會,以下是我們針對一些議程的分享。
背景
提起 Microsoft 這個名字,相信有在接觸電腦相關領域的人,都不否認它在近代個人電腦的發展上,具有舉足輕重的角色。但隨著人們口中 PC 時代逐漸沒落,大家將焦點轉到 mobile device,或近幾年 cloud/edge device 的興起,總覺得 Microsoft 的能見度及影響力遠不及其他競爭對手。大家是不是也曾跟筆者一樣感嘆,昔日的軟體巨人在作業系統、智慧型裝置、雲端平台、人工智慧等領域的發展上,有種『長江後浪推前浪,前浪死在沙灘上』的感覺呢? 但這一切在現任 CEO Satya Nadella 於 2014 年上任後,有了全面性的改變。他大刀闊斧的整頓 Microsoft 的企業文化,不再只強調 Windows 和 Office 這兩個 Microsoft 有史以來最成功也最知名的產品。退出手機市場,擁抱雲端、競爭對手,以及 open source。這些改變成功地讓 Microsoft 走出谷底,短短五年時間,它的 Office 365 訂閱數已超過 Netflix,雲端業務也超越 Google,緊追 Amazon (AWS) 。 (Some interesting references : Microsoft Annual Report - 2018, WSL 2。老實說,筆者有一陣子沒關心 Windows 平台,前陣子看到這個真的發出一聲 WOW!)
在這樣的時空背景下,Microsoft 從 2016 年開始在台灣舉辦 DevDay Asia 亞太技術年會 (2016),邀請 Microsoft 總部專家及產業夥伴一同登台,傳授最新的第一手訊息與技術分享。今年的 DevDay Asia (2019) 照慣例,也從西雅圖的 2019 Microsoft Build 大會帶來了最新技術的交流分享,針對 AI 人工智慧、資料分析、Office 365 開發與產業解決方案、企業生產力、資訊安全保護、最新技術發展六大主題,帶來一系列的議程、Hands-on Labs 與 Hackathon。礙於時間的關係,我們這次僅參加了 AI/Data 相關的部份議程,在這推薦大家有機會也可以參加 Hands-on Lab 與 Hackathon,相信會有更多收穫!
AI 人工智慧
Cognitive Services
首先分享的是 Microsoft Azure 旗下 "AI + Machine Learning" 分類中 "Cognitive Services" 的最新動態, 主體的架構還是跟之前一樣,依功能切分成五大類:Vision、Speech、Language、Knowledge、Search。每一類皆有許多服務 (如圖一的投影片) 已實際應用在生活中。大家可以在官方頁面得到最新的 API 列表、文件、demo 和 tutorial,在此便不一一列出。

這次主講人帶來的 demo 是 Computer Vision 下 Analyze Image 的功能,在網頁上傳圖片後,就可以得到在圖片中的 objects 座標、各 objects 的 tags,以及整張圖片的 tags 與 description,像圖二中的 description 是 "people waiting at a train station"。
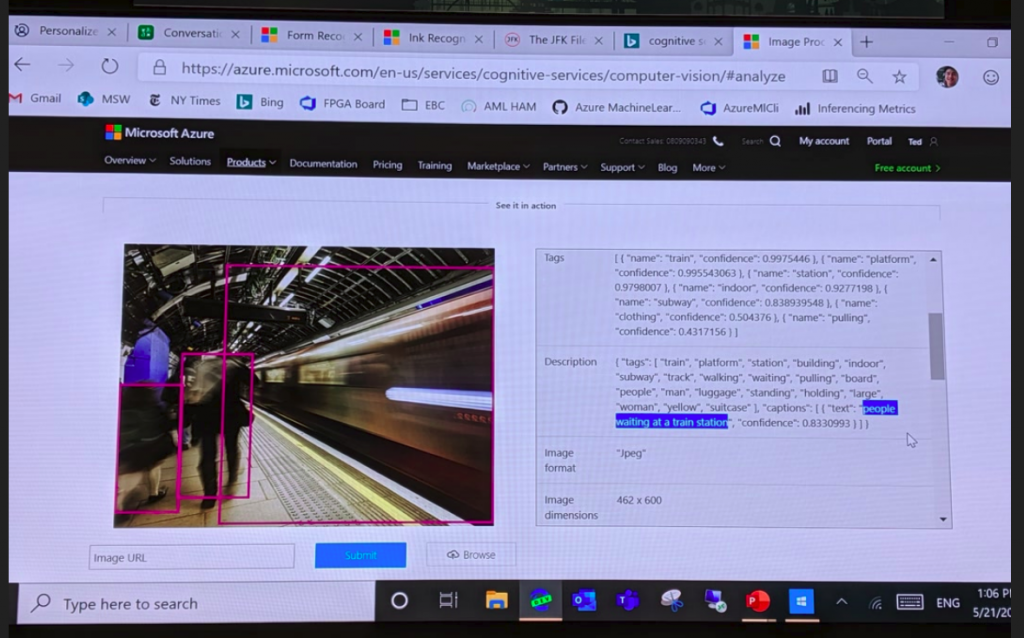
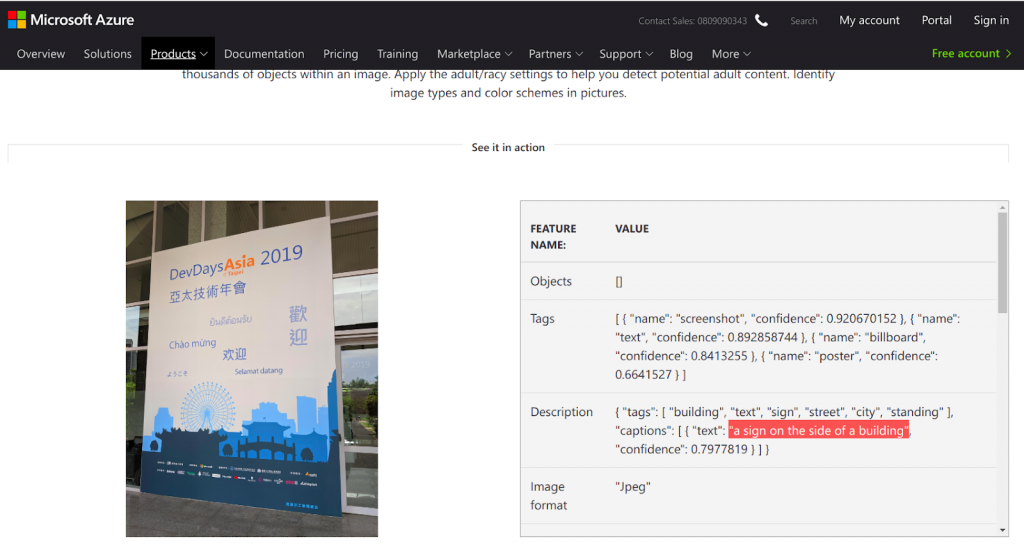
網頁下方也提供數張不同場景的 demo,筆者實際上傳了一張門口拍的海報,從圖三中可看到,判別出來的 description 是 "a sign on the side of a building",辨識效果還滿不錯的!
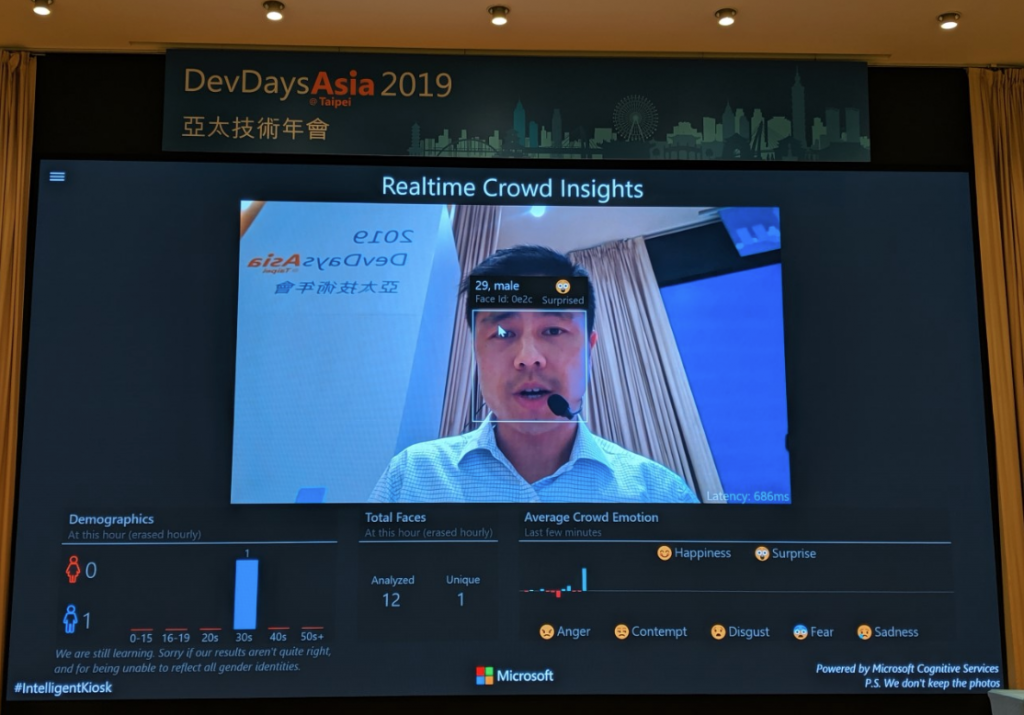
Microsoft 還提供了官方的 APP 範例 - Intelligent Kiosk,方便使用者快速體驗各種功能的 demo showcase 及程式範例,圖四便是現場 demo 的即時影像辨識,可以顯示年齡、性別與心情。可惜這個 App 只支援 Windows 10 1809 or later,其他系統的使用者算是無福消受囉!
再來是幾個最新進入 Preview 階段的 API 介紹與 demo。據講者的說法,Cognitive Services API 有四個階段:
- 第一個階段:僅提供給合作廠商與特定開發者的 Private Preview
- 第二階段:(Public) Preview
- 第三個階段:所謂的 Generally Available (GA)
- 第四個階段:Retiring
Decision API - Personalizer
個人化推薦在最近幾年的 ML/AI 領域上已成為一門顯學。如圖五講者舉出了傳統的 ML 中,監督式學習 (supervised learning) 常以線性迴歸 (linear regression) 相關數學式來表達目標變數 y 與特徵 x1,x2,x3x1,x2,x3 之間的關係,但最大問題在於 model 更新使用者的操作行為,資料用 batch 的模式估計其模型參數,加上傳統模型背後統計,理論大多以預測目標變數的平均趨勢,或平均可能性為主,故當一個 model 被建立後,並不會因少許使用者的行為,帶來即時產生的變化,即每次輸入差不多的特徵數據,model 帶來的預測結果差異不大。因此,對於個人化推薦系統而言,一些傳統 ML 的模型並不能直接有效應用在即時性和差異性需求極高的個人化推薦系統上 (註:圖五中的 b 應該為待訓練的參數而非特徵,這應是講者的筆誤) 。

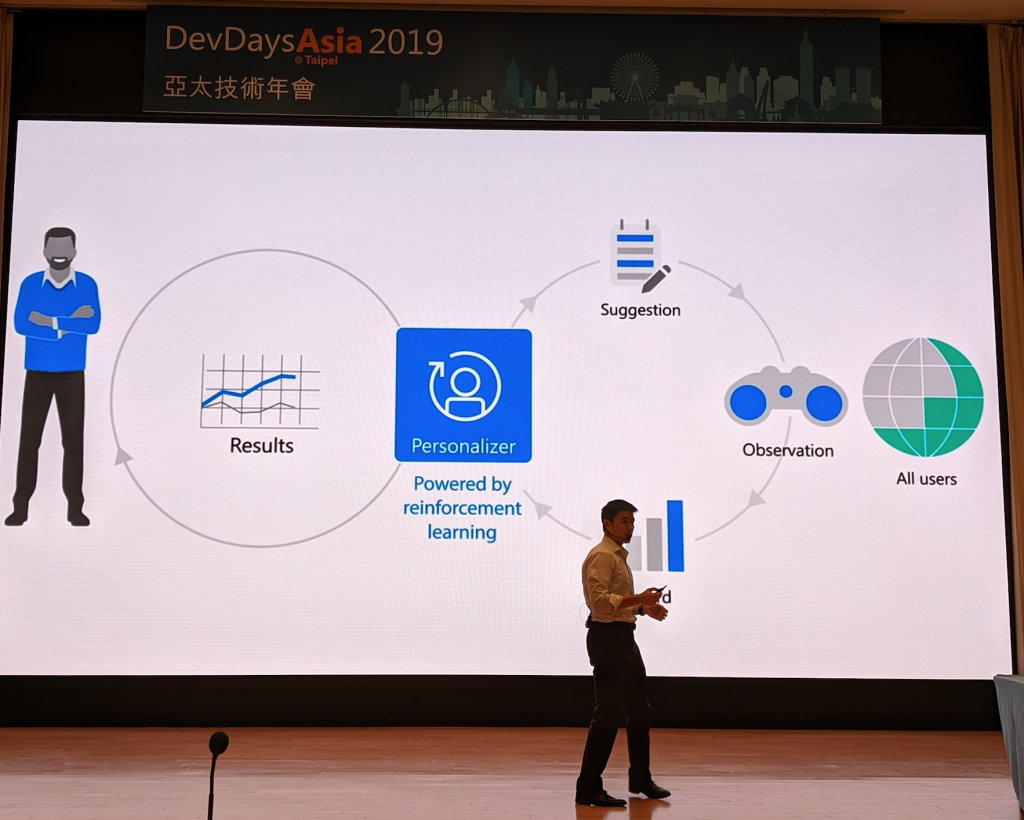
圖六表示 Personalizer 是為了解決即時個人化推薦的問題而開發的。它結合 Windows Azure 的環境與 Reinforcement Learning (RL) ,讓使用者不需花太多心力在後端系統的建置、開發與維護,只要在後台進行基本的參數設定,在 AP 內插入對應的 API call,就可以享受由 Personalizer 帶來的個人化體驗。
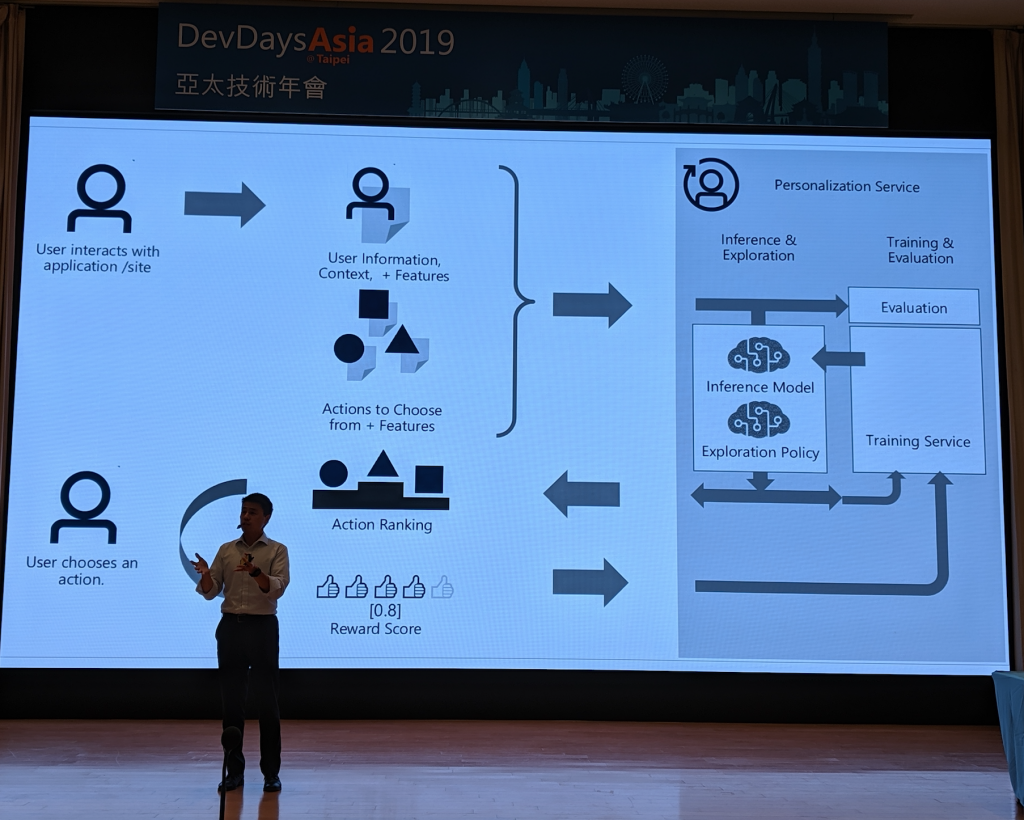
光是紙上談兵當然是沒辦法滿足台下的聽眾,再來便是實際演練的 live demo (見圖七)。在講者點擊了幾次不同的文章後,果然馬上就可以看到推薦的文章出現變化。
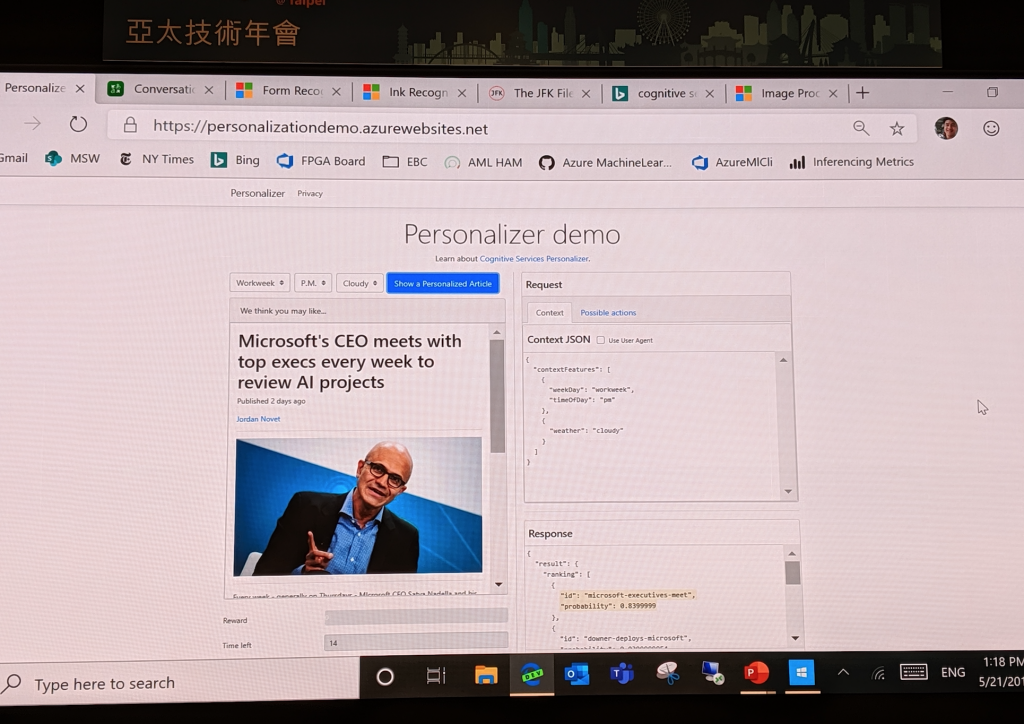
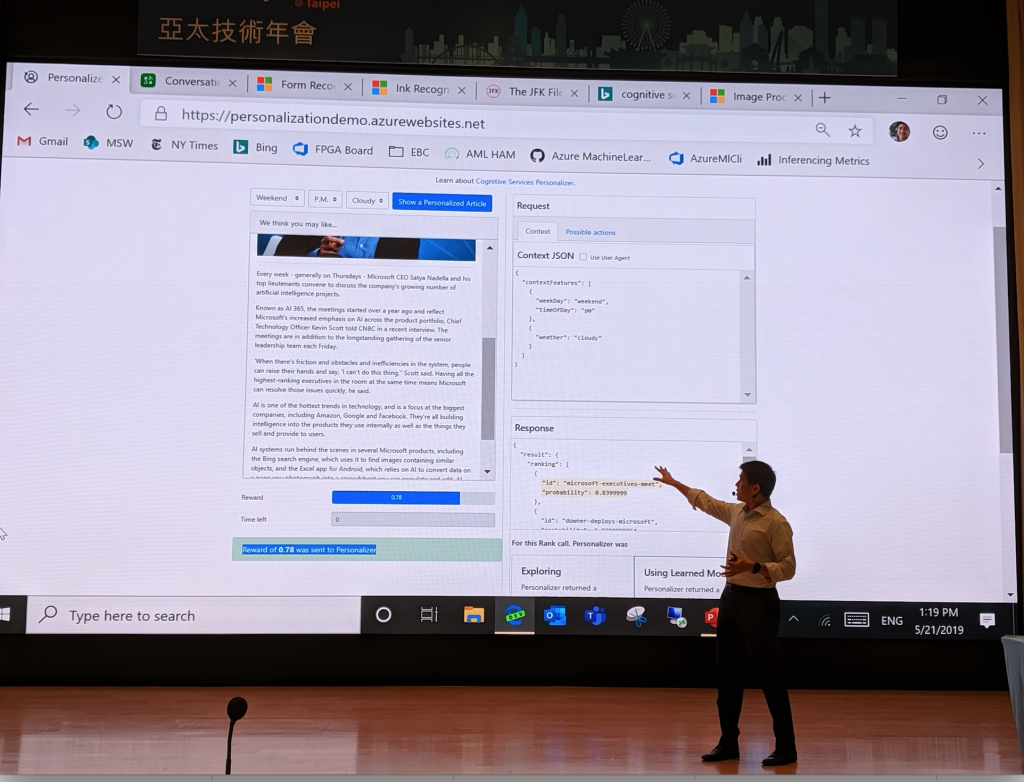
看到這,大家是不是覺得這根本就是神奇海螺翻版呢?當然所有的技術,都還是有它的限制在,節錄一段官方的 Pitfall to avoid 供大家參考:
Don't use Personalizer where the personalized behavior isn't something that can be discovered across all users but rather something that should be remembered for specific users, or comes from a user-specific list of alternatives.
Speech API - Conversation Transcription
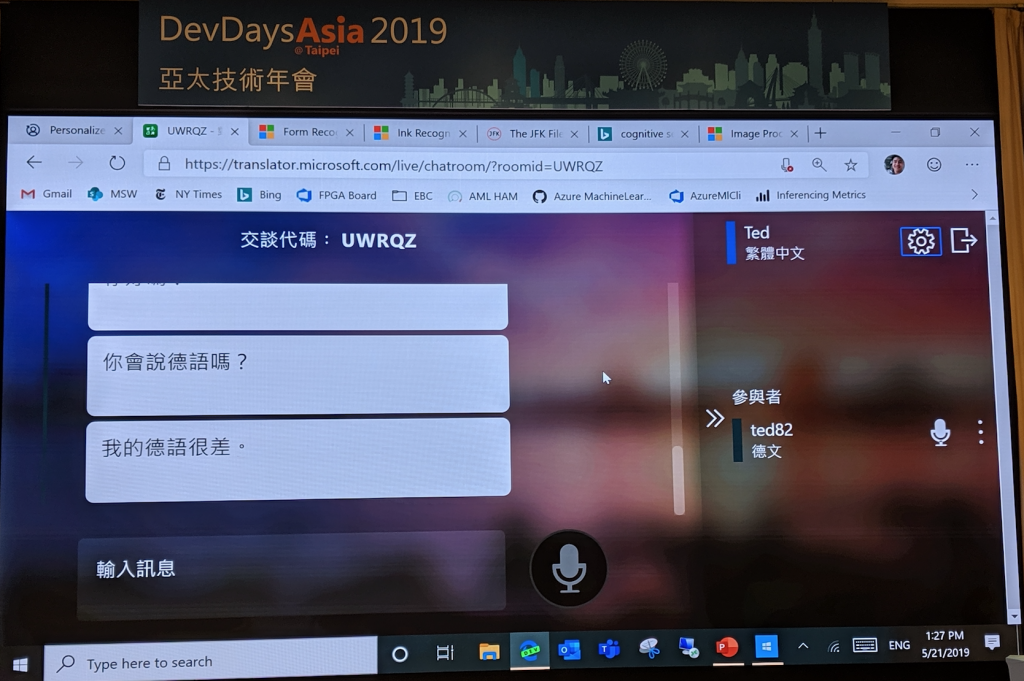
再來登場的是 Conversation transcription (見圖八) ,經過輸入使用者的音頻訓練後,它可以辨識出現在正在說話的人,做出即時多語口譯並產生翻譯稿,這對時常要進行多國會議的人來說,真是再實用不過的功能了!
Vision API - Form Recognizer and Ink Recognizer
有用過 OCR 的人都知道,如圖九所示其最大的痛點,便是針對表格與手寫體的辨識。為了解決這兩類問題,Cognitive Services 分別推出了 Form Recognizer 和 Ink Recognizer。

首先登場的是 Form Recognizer (見圖十) ,它的重點在於如何從各式各樣的資料元與字體,正確地解析出所要的 table、Key 與 Value pairs。圖十 (a) 表示這邊應用到 unsupervised learning 的技巧,使用者須先提供不同形式的表格作為 training set,經過 cluster → discover → extract 的流程,便可將表格裡的資料擷取出來 (如圖十 (b) ) 。


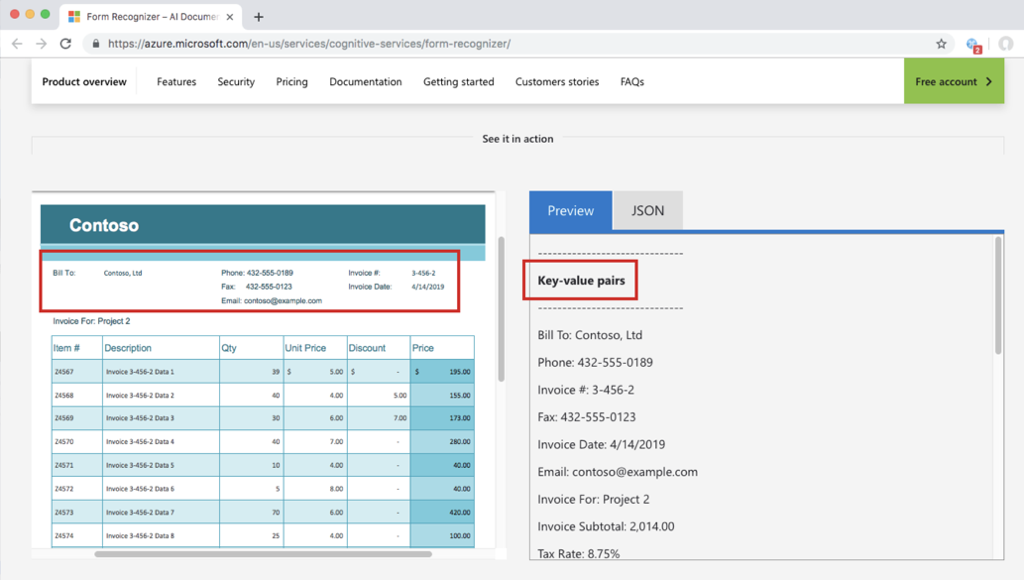
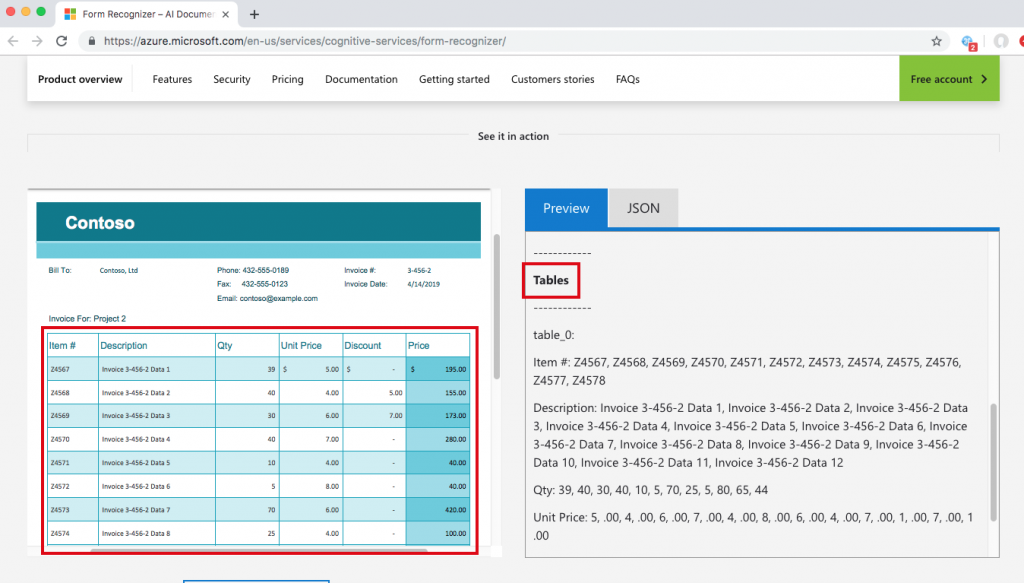
來看看 demo 的結果,可以看到一個 form 被正確的切分出 Key-value pairs (見圖十一 (a) ) 及 Tables (見圖十一 (b) ) 兩個部分,結果的確很讓人驚艷,且據講者表示,每一種 form 只需要提供 5 筆 sample,就可以達到這樣的辨識率。
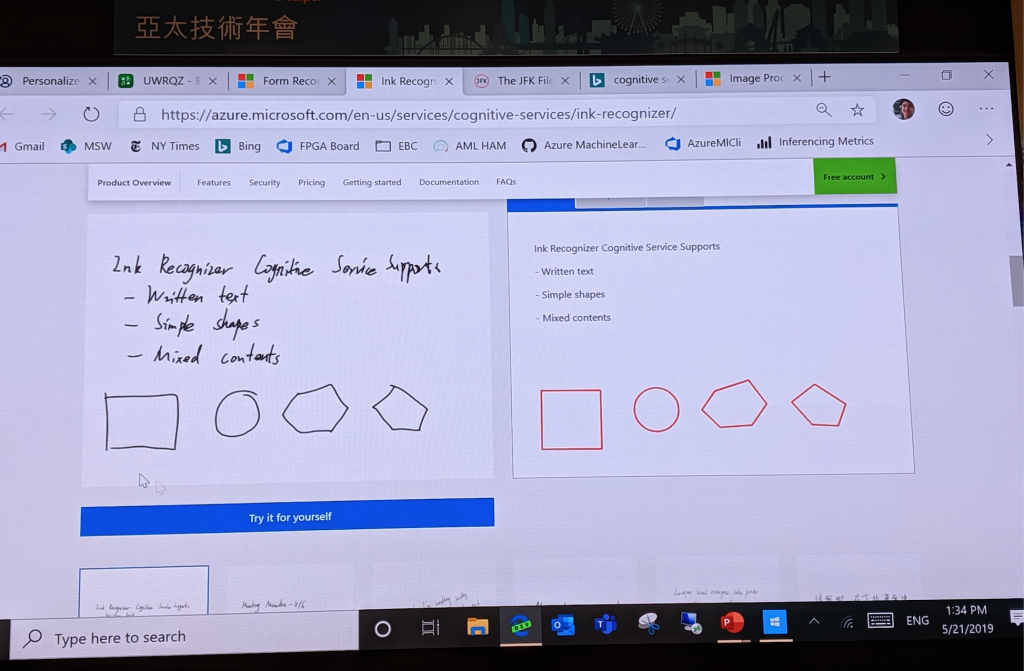
圖十二是最後一個 demo:Ink Recognizer。這部分特別的地方在於,它會將辨識的區域區分成 Writing Area 與 Drawing Area,再分別辨識內容。從下圖可以看到,不管是奇怪的形狀、草寫、多語的內容,它都可以應付。
Container Support
聽完了 Preview API demo,大家心中的 OS 是不是跟我一樣?『雖然公有雲已經提供了這服務,但很遺憾礙於公司規範,我們不能將資料傳出我們的 IDC 』- comment from security team。再 fancy 的服務,我們只能流流口水,參考一下相關資料,埋起頭來繼續開發自己的。為了這類使用情境,Cognitive Services 還提供了 Container Support,讓使用者可以在自己的環境下使用,甚至可以在 Azure 的競爭對手:AWS or GCP 下使用,真是佛心來著 (如圖十三 (a)、(b) ) 。


Session 到這時間已經不夠了,講者並沒有敘述的很清楚,不過似乎不是所有的 service 都可以在 container 上執行,如圖十四所示 (沒 Personalizer),不過,光是有 Container Support 這點,就讓人有想要嘗試的動力。

Generally Available (GA)
最後是最新進入 GA 的 service 列表 (見圖十五) ,大家有興趣可以查閱官網的資訊。

同場加映
- ”Actions speaks louder than words.“ - 聽了這麼多,總是會手癢想試試。Azure 現在提供免費的帳號申請,一年內有固定的 quota 可以使用,還有一些標榜 Always Free 的服務,有興趣請參考官網 FAQ。
- 這陣子正好在 survey Computer Vision 相關的資料,提供給大家當延伸閱讀:
- LINE AI Demo 、 LINE AI API Document (Power by LINE Dalian AI Team - internal only)
- Advancing state-of-the-art image recognition with deep learning on hashtags (FB)
- Facebook’s mass outage gave us a peek at the way its AI catalogues pictures
知識挖掘 (Knowledge Mining)
大部分人的 80% 以上的工作資訊是屬於非結構化的資料
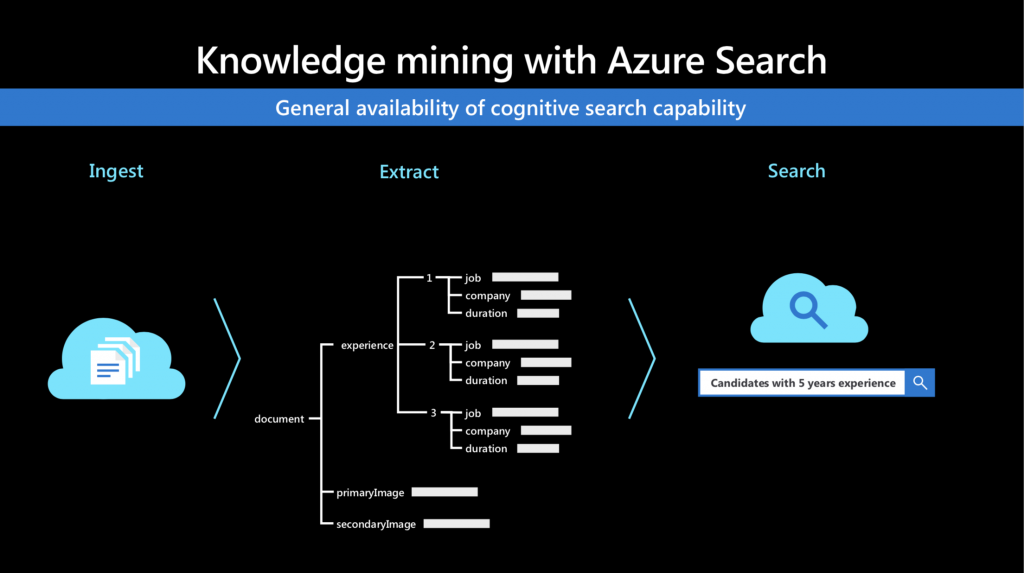
許多企業的領域知識 (domain knowledge) 時常是透過不同的檔案格式紀錄 (如影像、或是不同的文件格式),因爲搜尋困難造成知識、經驗難以傳遞;檔案格式差異過大則增加數據挖掘的困難度。這場 session 的講者 Darwin Schweitzer 介紹如何利用 Azure AI 解決非結構化資料帶來的困難 - 對非結構化資料挖掘隱藏在內容的有價值的資訊。圖十六所展示的是 Azure search 利用這些非結構性的資料進行認知處理 (cognitive processing),最後匯集成一張大型的知識圖譜 (Knowledge graph) 進行搜尋。當中的認知處理,可因應文件格式或商業問題差異,而有不同類型的功能,例如對不同文件中的重要標記 (如 hashtag) 萃取出來、紙本文件辨識、人臉辨識、重要語句萃取等。

Darwin Schweitzer 介紹了一些可利用 Azure search 的場景如下:
I 人力資源 (Human Resource, HR)
每間公司的人力資源部門都會遇到敏感且機密的招募資料 (recruiting data) 以及相關組織員工資料 (employee data),許多都只是紙本紀錄或以文件檔案格式 (如 .pdf, .docx) 個別儲存。然而隨著公司規模增大,這些資料的數量都可能達到要花上大量人力來進行整理方能進行分析運用,例如在一個新的部門成立之餘,如何在合適的時間,將合適的人員,安排在合適的職務上。Azure search 提供解決方案在人才分析 (Talent Analytics) 上。從圖十七可看出:第一步我們將我們所有的人才資料讓 Azure search 讀取 (例如放入 Azure Blob Storage),Azure 會將資料裡面重要特徵 (如過去工作經驗、個人影像) 進行分析萃取特徵。最後我們只需在 Azure search bar 上打入候選人特性,就可快速找到我們想要的候選人。進一步地,若想做公司內部候選人的推薦系統,也可結合 Azure search 的結果與 Azure machine learning 來實現 (延伸閱讀)。
II 大都會博物館 (The Metropolitan Museum of Art)
We’re in the midst of a renaissance right now, using AI to bring art and science together in a way that will help online visitors develop a deeper and more personally relevant connection to art.
Maria Kessler, Senior Program Manager for Digital Partnerships
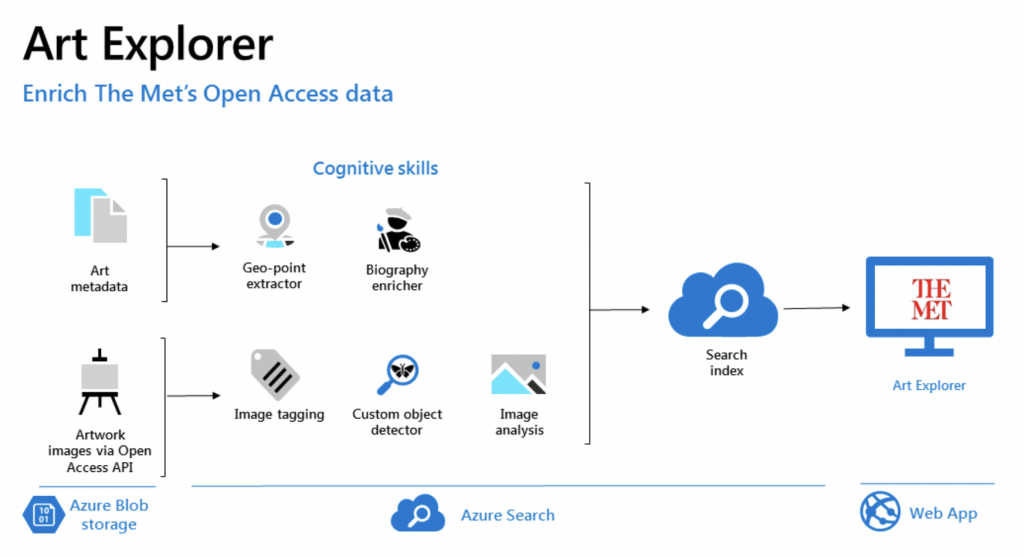
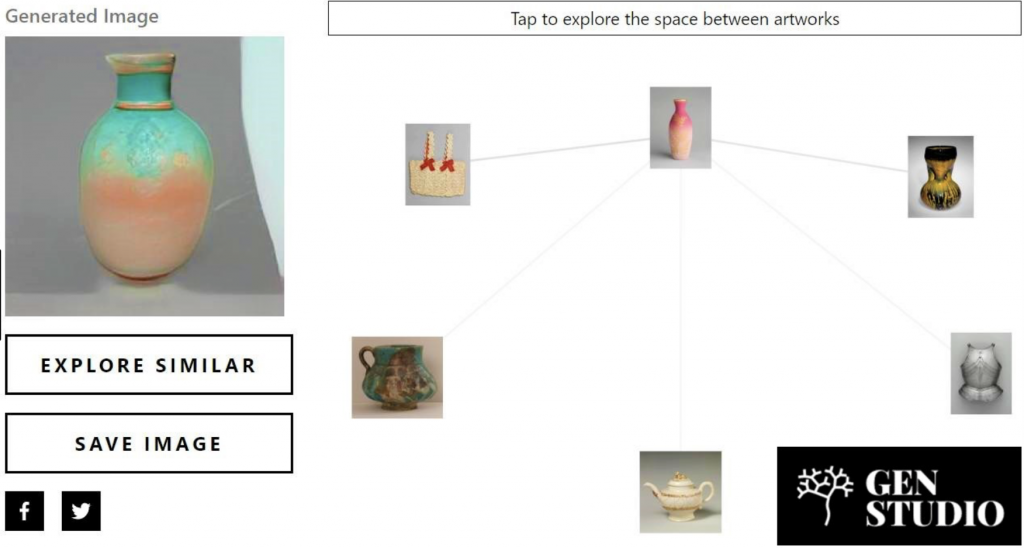
接下來的案例是關於世界三大博物館之一的大都會博物館。為了讓線上使用者與博物館內收藏的近兩百萬件藝術品拉近距離,大都會博物館長期已經與 Google 合作,如 Google Arts & Culture 提供了知識圖譜讓使用者可以用不同的方式瞭解藝術品。微軟在藝術品上的Computer Vision 這塊也正追趕著。今年微軟與 MIT 合作,將大都會博物館提供的公開資料放到 Azure Blob Storage 進行認知處理,如圖十八 (a) 的架構圖。醞釀出 Gen Studio 這個 project,可以讓使用者將大都會博物館的真實藝術品進行隨機創作、真偽辨識以及相似藝術品。例如:圖十八 (b) 呈現利用隨機生成的花瓶找到相似的藝術的關聯。其中,Gen Studio 在技術上運用了深度學習中的生成對抗網路 (GAN, Generative Adversarial Networks) 進行模型訓練。而這些 AI 的應用彷彿讓藝術品掀起另一場的文藝復興 (延伸閱讀)。
這場知識挖掘的 session 還有其他 demo 能讓我們更了解 Azure search 的能力,有興趣的讀者可以在 Darwin Schweitzer 提供的 GitHub repository 了解更多: https://github.com/liamca/build2019aidemos
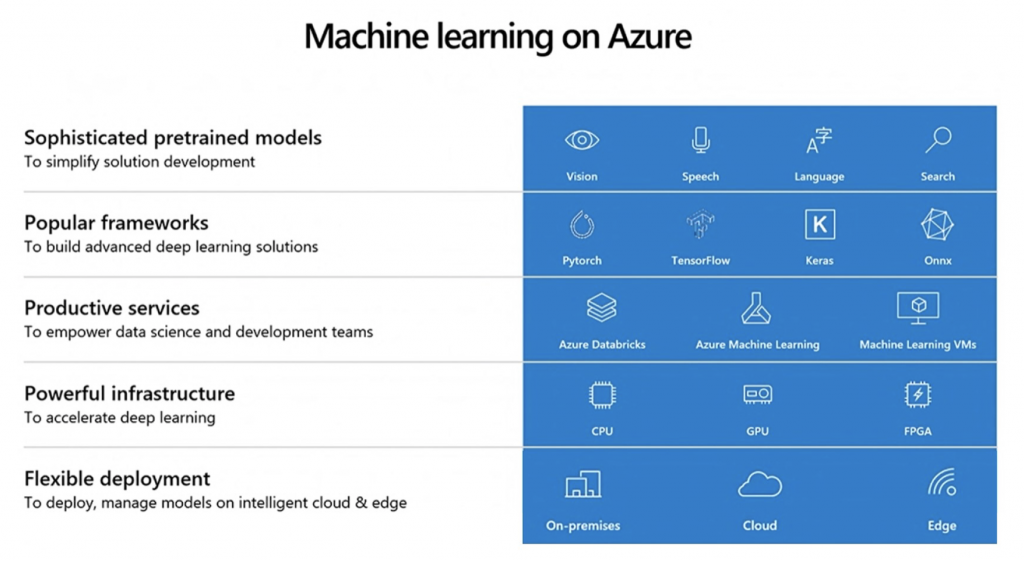
機器學習與資料科學平台 (Azure Machine Learning and Data Science Platform)
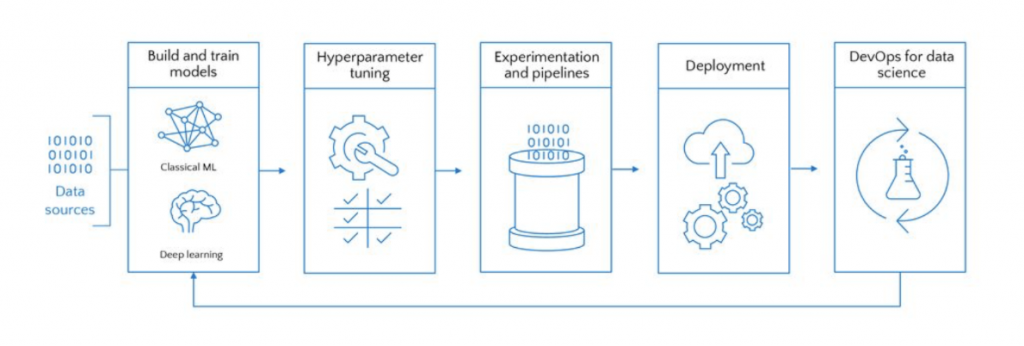
緊接著 Ted Way 提到在Azure上建立資料科學專案的流程 (見圖二十):將資料放入模型進行一連串的參數調整,到最後模型上線及對建立好的模型進行 DevOps,當中的實驗階段較類似為了檢測或是優化模型的預測能力上所建立的流程,如我們可對資料做隨機擾動 (random disturbance) 進行測試模型穩健度 (robustness)。值得說明的是,圖九的流程是站在工程角度,讓一個 AI 模型能穩健地被執行及監控所簡化的作業流程,若沒有在現場聽到講者的說明,可能會讓人誤以為建立一個 AI 模型只需透將收集到的資料放入這幾個簡單步驟即可達成。事實上,資料科學真正費盡心力的是在資料前處理 (包含資料清洗、遺失值及異常值檢查等) 及資料探勘 (data exploratory) 上。講者也有說明在 Azure 平台上可以透過 dashboard 快速了解資料輪廓 (data profile),了解各個特徵的分佈情況,也有相對應的服務來進行遺失值處理。
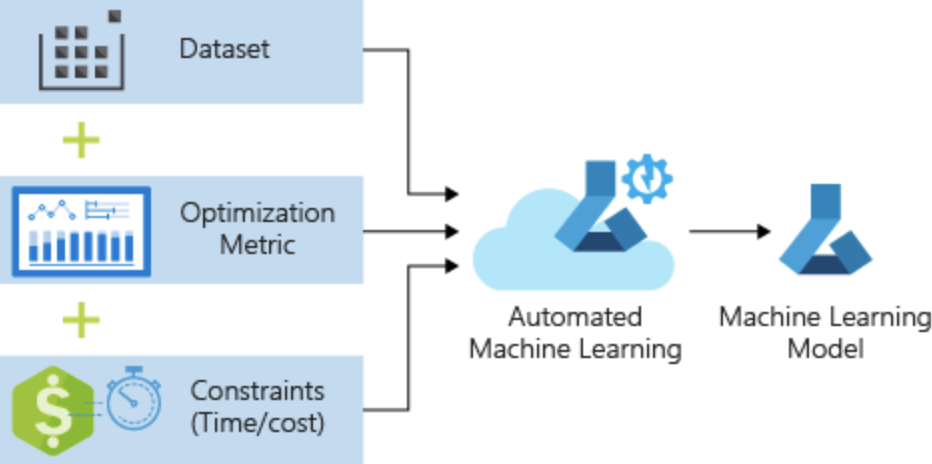
另一個重點:自動化機器學習 (Automated Machine Learning, autoML) 主要解決的痛點是傳統機器學習服務模型開發耗時間,執行步驟中有許多重複的程序等。只需透過一個預先對資料及模型條件的設定檔 (configuration),即可啟動 autoML 服務,讓資料開發人員能縮短一定的時程,且建置一致性的模型 (model consistency)。其中,設定檔包含 (1) 哪種類型的 ML 問題 (如監督式學習中的分類、迴歸);(2) 資料的來源及格式;(3) 計算的環境 (如:本機端或是遠端 VM);(4) 設定相關 ML 模型參數。圖二十一 (a) 顯示的是將資料及相關設定輸入後,autoML 自動地將各式不同的訓練模型進行測試,選出在這次資料之下最好的模型進行預測。
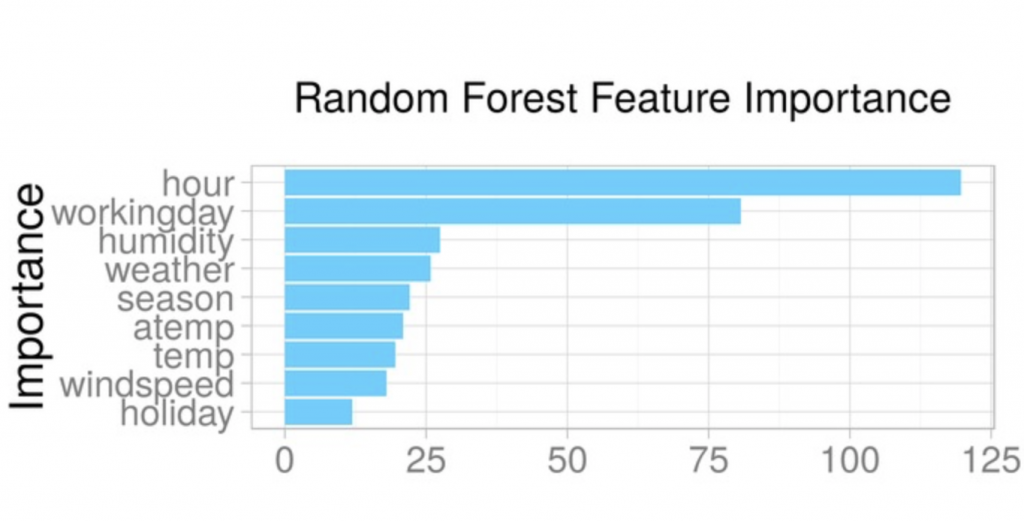
autoML 的優點除了省去很多在建立模型之下的重複動作以外,對於模型的重複使用性 (reusable) 也是另一個優點 (延伸閱讀) 。圖二十一 (b) 則是 autoML 提供的特徵重要性 (feature importance),用來了解 autoML 選出模型相對的重要特徵分佈。
Ted Way 最後也提到在 Azure Machine Learning 上對模型做管理,對機器學習模型做 MLOps 有興趣的可以閱讀相關文件;若對 Azure Machine Learning 有興趣的讀者,可以參考官方文件。
結語
從微軟舉辦的 DevDays Asia 2019 中,不難看出微軟在 Azure Machine Learning/AI 相關的服務上整合性又提高不少,讓進入資料科學或是機器學習的門檻降低不少,也讓許多開發後的模型能夠走向更容易維護和管理。就功能及服務的豐富度上有漸漸追上其他競爭對 Google Cloud Platform 或是 Amazon Web Services 提供的相關服務。除此之外,在這次會議中的另一個主軸:Office 365,微軟也花了滿多時間在推銷 Office 365 結合 Azure 相關的 AI 技術,試圖傳達以提升行政辦公效率,來改變使用者在傳統 Office Word 或 Office Excel 等 Office 產品的操作方式,進而創造新一代工作模式。值得一提的是微軟 2018 年最大的營收項目為 Office 業務 [1],而市場的高接受度也讓我們可以期待未來 Office 365 持續結合 Azure AI 帶來的新穎服務。
References
蕭瑟寡人 (2018) . 論一家公司的蛻變,微軟精彩程度一點也不輸亞馬遜, 數位時代