LINEの開発組織のそれぞれの部門やプロジェクトについて、その役割や体制、技術スタック、今後の課題やロードマップなどを具体的に紹介していく「Team & Project」シリーズ。
今回は、プライバシー保護型機械学習技術の研究開発を行っているML Privacyチーム、ならびにAIの信頼性を担保する技術の研究開発を行っているTrustworthy AIチームを紹介します。
両チームのマネージャーを務める高橋翼、エンジニア/リサーチャーの長谷川聡(ML Privacyチーム)、綿岡晃輝(Trustworthy AIチーム)に話を聞きました。

まず、自己紹介をお願いします。
高橋:2018年12月にLINEに中途入社した高橋翼です。前職は電機メーカーの中央研究所です。ML PrivacyチームとTrustworthy AIチームのマネージャー兼リサーチャーです。ユーザーとデベロッパーの双方が安心してデータやAIを活用できる基盤作りが目標です。
長谷川:2021年7月に中途で入社した長谷川聡です。前職は通信会社の研究所で、プライバシー保護に関する技術のリサーチャーを7年ほどやっておりました。LINEでは、心機一転、エンジニアとしてML Privacyチームに所属しております。
綿岡:2021年4月に新卒で入社した綿岡晃輝です。大学院では機械学習の公平性について研究をしてきました。入社後2ヶ月間の研修期間を経て、6月からTrustworthy AIチームに所属しています。主な業務内容は、言語モデルの倫理的問題点を探索しそれらを解消するための技術開発を行うことです。
皆さんが入社を決めたきっかけ、理由を教えてください。
高橋:現在は基礎研究から応用まで携わっていますが、入社のきっかけは、LINEが基礎研究チーム(現、AI Researchチーム)を新しく立ち上げると聞いて、その挑戦に魅力を感じたことです。LINEを通して研究成果を数千万を超える国内のユーザーにデリバリできる可能性にも魅力を感じていました。また採用面接を通して、意思決定の速さ、先端技術に精通したエンジニアが多数在籍していることを知り、そういった刺激的な環境に身を置いてみたいと感じました。人柄がよく信頼できる人が多いこと、柔軟な働き方ができること、オフィスがキレイでカフェの居心地もよかったこと、など些細な理由はたくさんあります。
長谷川:新しい技術・古い技術問わず、何かしらプログラミングでモノを作るのが好きで、リサーチャーだけでなくいずれはエンジニアとしてのキャリアも歩んでみたいと思っておりました。カジュアル面談や採用面接を通して、すごいエンジニアがたくさん在籍していること、社員はVerdaという社内で構築されたプライベートクラウドを自由に使えたりと計算機資源が豊富なこと、何よりも数千万を超えるユーザに直接価値を提供できることに魅力を感じた点が、入社を決めたきっかけでした。
綿岡:理由はたくさんありますが、最も大きな理由はLINE CLOVAにあります。個人的に、VUIと言われる音声でコンピュータを操作する方式はこの先の未来で広く使われ、さらには人間のアシスタントとして一人一人の意思決定を支える極めて重要なものになると考えてきました。LINEは、日本における音声アシスタント(AIアシスタント)市場でのシェア獲得を目指して様々な展開をしていくための資金力や技術力、また応用可能性を持ち合わせたとても魅力的な企業に思えたので、就職活動を始めた時からLINEを第一志望にしていました。

今の仕事のやりがいを教えてください。
高橋:LINEという巨大なプラットフォーム、ユーザベースの上で、洗練されたプライバシー保護やデータの取り扱い、AIに求められる倫理基準等の近未来に必要な議論を実用性を考えながら真剣にできること、壮大かつ重要な取り組みに参加できることが最大の魅力です。R&Dチームと事業開発チームとの距離が近く、開発課題や事業課題を研究開発の議論に常に取り込むことができる点も魅力です。
長谷川:プライバシー保護に関する技術は、論文のみ公開されているケースが多く、その論文の中にはそもそも実装した結果が含まれていないケースも多々あります。まだ世の中で公開されていないもの・実装されていないものを一から作っていくこと、それがいずれLINEという巨大なユーザープラットフォーム内で使われる可能性があるということを考えると、非常にやりがいを感じます。
綿岡:現在LINEでは、HyperCLOVAという大規模汎用言語モデルの開発を行っています。言語モデルは自然な会話ができるのですが、その中で不適切発言などの倫理的問題点も懸念されています。Trustworthy AIチームでは、それらの問題を抑制するための技術開発を行っています。入社前は「LINE CLOVAの近くで仕事ができればそれでいい」くらいに思っていましたが、幸運にもそのLINE CLOVAの応答をより高いレベルに押し上げるためのプロジェクトに携わることができています。近年の大規模汎用言語モデルの進化は目覚ましく、毎日論文を読み、最新の技術に触れることができています。
チームの構成・役割などについて教えてください。
高橋:現在、Trustworthy AIチームは4人、ML Privacyチームは3人体制で、兼務者がいるため両チーム合わせて5人です。各チームにプロトタイプ開発を担うR&Dエンジニア、論文採択を目指すリサーチャーが在籍しています。
プロジェクトには、エンジニアとリサーチャーが一緒に参画しています。エンジニアとマネージャーがプロジェクト進行の中心的役割を担い、リサーチャーに技術支援をしてもらっています。リサーチャーには、チームの技術水準のトップラインの引き揚げを期待しているため、方向性を理解してもらうことが重要です。
領域の特性とも関係しますが、AIサービスの開発組織や機械学習開発組織をはじめ、情報セキュリティや品質に関連する他のチームとも協働することが多いです。どちらのテーマもLINEの中で重要性の高いトピックと認識されており、注目度も高いと感じます。

チームメンバーや雰囲気を紹介してください。
高橋:現在の両チームのメンバーは、大学でコンピュータサイエンスや物理学を専攻していました。担当業務的にも多様なバックグラウンドの方にジョインして欲しいです。
ML Privacyチームの長谷川さんは、匿名化技術の専門家です。NeurIPS2020 Hide-and-Seek Privacy Challengeで世界一に輝いたチームのメンバーでした。
チームの雰囲気は、適度なワイワイ感と緊張感がうまくバランスされているように感じます。メンバーに実直かつオープンな人な人が多いことが要因でしょうか。
リサーチの実績として、ICDEやBigData、IUIでの論文採択があります。機械学習やセキュリティのトップカンファレンスへも鋭意挑戦中です!
- (参考)チームメンバーによる国際学会の採択論文
利用技術・開発環境について教えてください。
高橋:MLU Jutopiaという社内のGPUクラスタを利用して、開発や実験を行っています。必要なときに潤沢なリソースをすぐに確保できるのでとても便利です。VMや共有ストレージなどのインスタンスも、Verdaという社内のプライベートクラウドでいつでも払い出してもらえます。計算機リソースは比較的潤沢で、手続きのコストも小さいです。
プログラミングはPythonとPyTorchを使うメンバーが多いです。私はJupyterで開発や実験をしていますが、他のメンバーはCode ServerやVS Codeを利用しているようです。

他方、プライバシーや信頼性の領域では実用的なコードや資料が十分に公開されていないことから、リファレンス実装やライブラリ、解説資料の整備を進めています。社内でもチームメンバーが講師となり、情報セキュリティや品質管理系部門向けに勉強会等を開催しています。我々の領域は社内で理解を浸透していくことも課題の一つですので、勉強会の開催にも力を入れています。これらの機会や蓄積は、新メンバーの方々にも活用していただけますので、MLやAIの経験がある方であればすぐにキャッチアップできると思います。
- (参考)現在、ML Privacyチームで研究開発しているプライバシー保護技術について、最新動向をまとめた資料です
今のチームの課題や、解決に向けた取り組みを教えてください。
長谷川:ML Privacyチームの課題はいくつかあるのですが、ここでは2つ紹介します。
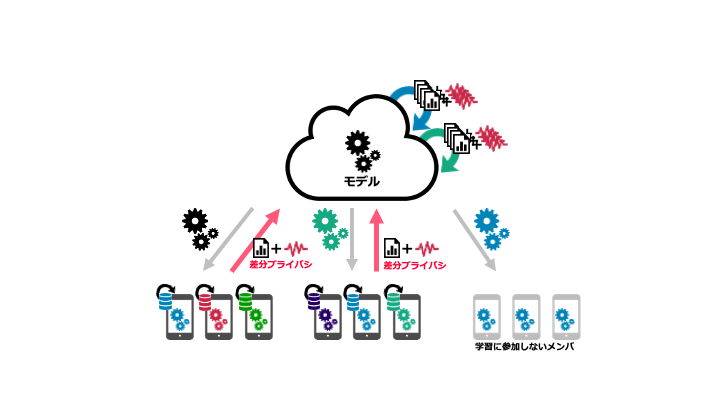
1つ目は、「プライバシー保護技術を利用する人に安全性を理解してもらうこと」です。どういった意味で安全であるかわからないと利用には躊躇してしまうかと思います。特に、差分プライバシーというノイズを加えることでプライバシーを保護する技術は、数学的に厳密に定義されたプライバシー指標であり、リサーチコミュニティだけでなく一部企業でも利用が始まっており、我々も注目しているのですが、難解で理解するのが大変と言われております。
この解決のために、差分プライバシーの解釈性に関する技術調査やそこで出てきた課題に関する研究を実施しています。また、社内でセミナーを開き調査結果を共有するなどの啓蒙活動を行ったりしています。解釈性に関しては、例えばMLエンジニアの方々は、統計学やベイズ推定と言った技術には馴染みが深く、差分プライバシーをそういった技術で解釈する方法を紹介することで、理解をしてもらえました。
2つ目は、「安全なプライバシー保護機械学習技術の提供」です。プライバシー保護機械学習技術を使いたいとなったとしても、なにも考慮せずに実装をしてしまいますと、プライバシー情報が意図しない形で漏洩してしまう恐れがあります。そういったこともあり、セキュアな実装を行うことが大切ではあるのですが、皆が意識してできるものでもありません。またプライバシー保護技術特有の脆弱性も報告されており、通常のセキュアプログラミングだけではカバーできないことも多々あります。
この課題に対しては、安全なプライバシー保護機械学習技術のリファレンス実装に取り組んでいます。模範となるセキュアな実装を行うことで、プライバシー保護機械学習技術を利用したいユーザにとって、安全に扱えるようなリファレンス実装を整えたいと考えています。
また、分析者はプライバシー保護技術を適用したことによる、分析精度への影響が気になるかと思います。分析精度も同時に測ることができるシミュレーション環境の開発も行っており、総じて安心して扱えるプライバシー保護機械学習技術の提供を目指し、開発に取り組んでいます。

綿岡:Trustworthy AIチームでは現在、HyperCLOVAの不適切発言を検知するための機械学習モデルを構築しています。機械学習モデル構築のためには当然大量のデータが必要となり、そのデータを効率的に収集するツールの開発も行ってきました。そういったデータ収集ツールのメンテナンスや、不適切発言以外の問題点に対する調査など、多くの課題が存在します。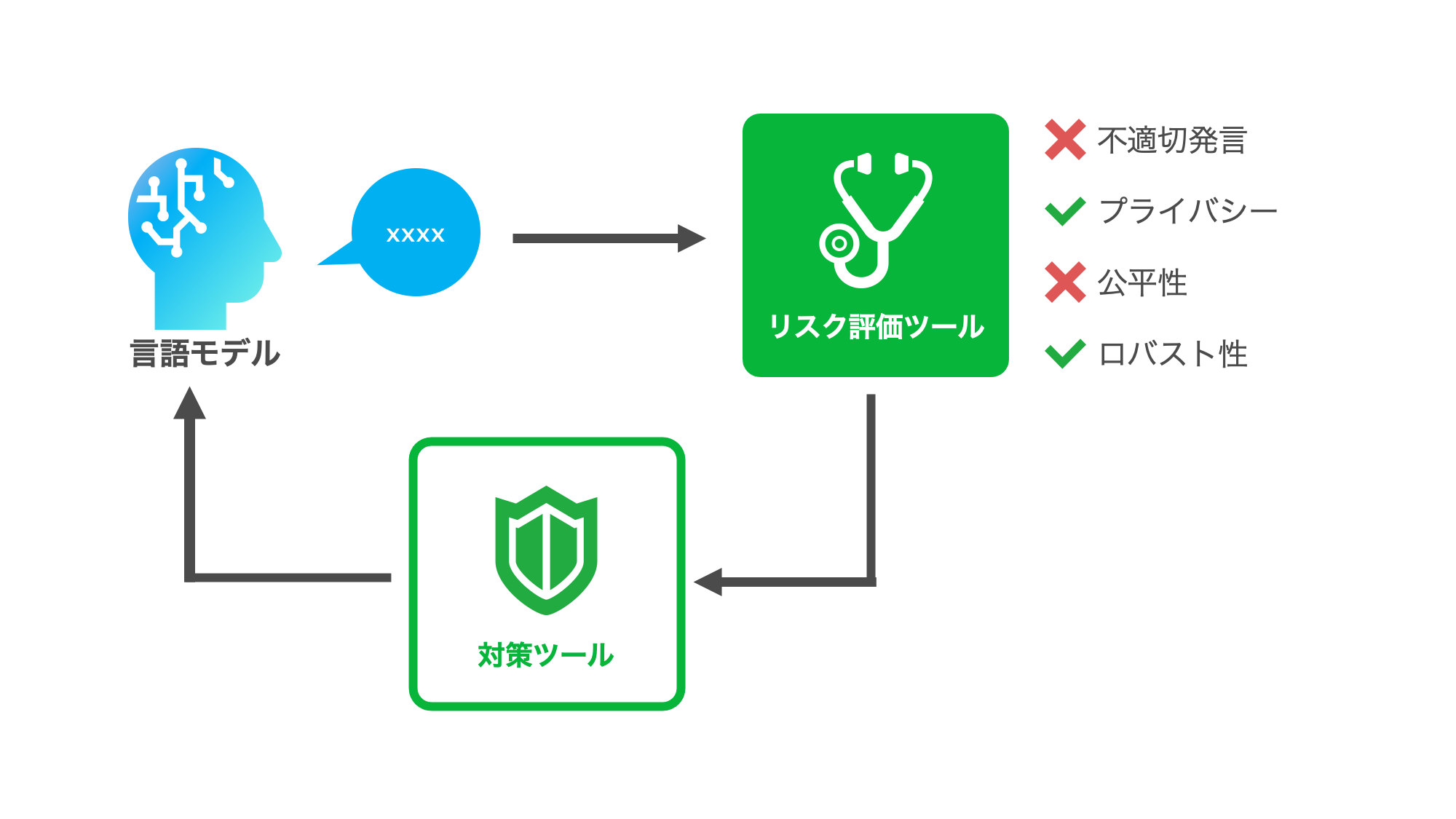
まず、データ収集については、現在チームで小規模サンプルに対してラベル付けを行い、そこから実行可能性の検証を進めています。ある程度のプロトタイプを完成させた後に、大規模サンプルに対するラベル付けの発注を行う計画を進めています。
次に、不適切発言以外の問題に対する調査については、次なる対象としてプライバシー侵害問題についての調査を開始しました。週に一度のチームミーティングで、調査した内容を共有し、さらなる調査に向けた議論や解決案の議論などを行っています。もちろん先行研究があれば参考にすることもありますが、言語モデルの倫理的問題の分野は非常に発展途上であり、かつ我々が扱っている言語モデルは日本語であるという局所的な内容となっています。なので時には、HyperCLOVAと何度も会話をして自ら問題点を探索し、発見したものを報告し合ったりすることもあります。
Trustworthy AIチームは、新規発足したばかりということもあり、メンバー数が少なく兼務も多いため、新しいメンバーを探しています。組織の規模を大きくしながら、多くの課題を効率的にこなしていくことも、課題のひとつだと思います。

今後のロードマップを教えてください。
長谷川:LINEでの分析用途に応じたリファレンス実装のさらなる拡充です。現在作成中のリファレンス実装は、限られたユースケースでのみ利用できるものしか開発ができていません。さまざまなユースケースに応じたリファレンス実装を準備することで、LINE内でのプライバシー保護技術の利用のハードルを下げ、利活用を促していきたいと考えています。
また、このリファレンス実装の拡充にあたっては、基礎技術の研究開発は欠かせません。プライバシー保護技術の適用による分析精度への影響を極力減らすことや、LINEでの分析用途に応じたプライバシー保護機械学習の適用は、既存の技術の適用だけでなく新技術の研究開発が伴うことも多々あると考えており、リファレンス実装と並行して進めていきたいと考えています。
綿岡:まずは現在開発中の不適切発言検知モデルの構築です。それに向けて私たちが開発したデータセット作成ツールのメンテナンスや大規模データセットの作成などが直近のすべきこととなります。また、それと並行して言語モデルに内在する他の倫理的問題点の探索も重要となります。プライバシー侵害の可能性、ロバスト性、公平性など考慮すべき点は数多く存在します。それぞれの問題点を整理し、検証方法を確立し、その方法を実装していくことが今後のすべきことになります。
もちろん、それらのツールをただ実装して終わるのではなく、効率的かつ効果的に適用していくことも重要なタスクになります。適用に至るには、他チームとの連携が必須になりますので、LINE内での横断的なコミュニケーションを図っていきたいと考えています。
最後に、ML Privacyチーム・Trustworthy AIチームに興味を持ってくれた人にメッセージをお願いします。
高橋:ML Privacy、Trustworthy AIともに、まだまだ未成熟かつ明確な正解が示されていない領域です。あるべき姿を思い描き、壮大な実験を重ねていくような、チャレンジングでやりがいのある仕事だと思います。また、議論の幅と深さを担保する観点からも多様なバックグラウンドの方々にジョインしていただきたいです。熱意のある方をお待ちしております!
長谷川:ML Privacyチームは、機械学習 x プライバシー(セキュリティ)という2つの技術を業務で扱うことができる、国内ではなかなか見当たらないお得なチームだと思っています。少しでもML Privacyチームに興味を持っていただいた方は応募していただけますと幸いです。一緒にお仕事できる人を楽しみに待っています。
綿岡:私達の業務は成長目まぐるしい分野で、これから起きる問題に先回りして議論し、対策を練ることです。それらは非常に創造性あふれる貴重な体験かと思います。もし、少しでもTrustworthy AIチームに興味を持っていただけたなら、是非応募をご検討ください。これを読んでいる皆さんと一緒に未来を作れる日を楽しみに待っています。
ML Privacyチーム・Trustworthy AIチームではメンバーを募集しています。
▼募集ポジション