
안녕하세요, LINE에서 광고 플랫폼 개발을 맡고 있는 1년차 신입사원 Kunihiko Sato입니다.
이번 블로그에서는 Python을 사용해서 임의의 Signal-to-Noise ratio(SN비)를 가진 음성 파형을 만드는 방법을 소개하겠습니다. 참고로 이 포스팅의 내용은 Clova 등 LINE의 음성 사업과는 관련이 없습니다.
음성 처리 분야에서의 딥 러닝
오래 전 딥 러닝이 이미지 처리 분야에서 기술 혁신을 일으켰는데, 음성 처리 분야에서도 비슷한 일이 벌어지고 있습니다. 딥 러닝으로 음석 인식의 정밀도가 크게 향상되면서, Amazon Echo나 Google Home, LINE Clova와 같은 AI 스피커가 개발되어 시장에 보급되었습니다. 또, 컴퓨터로 음성을 생성하는 문자 음성 변환(Text-to-Speech)의 정밀도도 높아져서 실제 사람의 목소리와 분간하기 힘들 정도의 음질이 되었습니다.
음원 분리에 적용된 딥 러닝
위에서 언급한 사례 외에도 딥 러닝을 통해 정밀도 측면에서 많은 발전을 이룬 음성 처리 분야들이 있는데요. 그 중 하나가 음원 분리입니다.
음원 분리란 여러 개의 음원이 섞여 있는 입력 파형을 개별 음원의 파형으로 분리하는 것을 말합니다. 예를 들어 음성 강조 혹은 잡음 제거라고 말하는, 음성과 잡음이 섞여 있는 입력 파형을 음성 파형과 잡음 파형으로 각각 분리해내는 것이 음원 분리에 해당됩니다. 또는 피아노, 트럼펫, 기타 소리가 섞여 있는 입력 음원을 3개의 파형으로 분리하는 것도 음원 분리라고 부릅니다. 아래 그림은 음원 분리를 이미지로 나타낸 그림입니다.

아래는 딥 러닝을 통해 음원 분리 정밀도가 대폭 향상된 사례들입니다.
딥 러닝에 필요한 훈련 데이터 제작
딥 러닝으로 음원 분리를 구현하려면 학습용 데이터 세트를 준비해야 합니다. 이 포스팅을 보시면 추후 학습용 훈련 데이터 세트가 필요할 때 도움이 될 수 있습니다.
이해를 돕기 위해 이 포스팅에서는 음성 파형에서 잡음을 제거하여 음성만 추출하는 '음성 강조(잡음 제거)' 음원 분리에 대해 살펴 보겠습니다. 먼저, 신경 회로망의 학습을 도식화하면 아래와 같습니다.
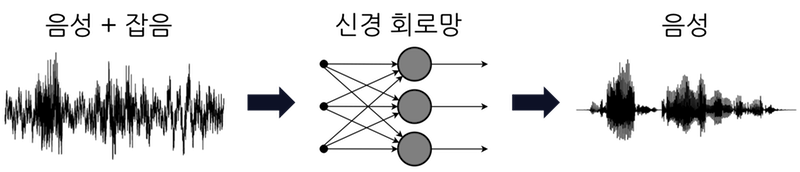
훈련 데이터(training data)에는 음성과 잡음이 섞여 있는 파형이 필요합니다. 또, 교사 데이터(teacher data)에는 음성만 있는 파형이 필요합니다. 이 데이터들을 이용해 신경 회로망은 잡음이 섞여 있는 음성 파형에서 음성만 추출하도록 훈련됩니다.
음성만 있는 데이터 세트로는 TIMIT 코퍼스 등을 비롯해 유명한 음성 코퍼스(말뭉치)들이 여럿 있지만, 잡음이 포함된 음성 데이터와 음성만 있는 데이터를 쌍으로 갖추고 있는 데이터 세트는 별로 없습니다. 따라서, 이미 나와있는 데이터 세트를 활용하는 것만으론 부족할 수 있습니다. 만약 개발자가 임의의 SN비를 가진 파형을 합성할 수 있게 되면, '음성과 잡음' 뿐만 아니라 여러 악기 소리가 혼합된 데이터 세트까지 만들 수 있습니다. 그러면 개발 요건에 맞는 데이터 세트를 각각 필요에 따라 만들 수 있게 되니 이번 기회에 직접 만들 수 있는 방법을 익혀두면 좋을 것 같습니다.
Signal-to-Noise ratio란
Signal-to-Noise ratio(SN비, 신호 대비 잡음 비)란 신호의 크기가 잡음의 크기보다 얼마나 큰지 나타내는 비율입니다. 음성 신호에서 SN비의 단위는 dB(데시벨)입니다. 이 포스팅에서는 Signal을 음성, Noise를 그 외의 소리(화이트 노이즈, 환경음 등)로 설명하겠습니다.
SN비 수치가 높을수록 음성이 잡음보다 크다는 것을 의미합니다. 예를 들어, 5dB일 때보다 20dB일 때가 음성은 크게, 잡음은 작게 들리는 상태입니다. 0dB은 음성과 잡음의 크기가 동일하다는 의미입니다. 음성보다 잡음이 더 큰 경우에는 -10dB과 같은 마이너스 수치가 나옵니다.
'임의의 Signal-to-Noise ratio를 가진 음성 파형을 만든다'는 것은 원하는 dB 비율로 음성과 잡음이 섞여 있는 음성 파형을 만든다는 의미입니다.
Signal-to-Noise ratio 계산 방법
SN비는 다음 계산식으로 구할 수 있습니다.

Asignal와 Anoise는 각각 음성과 잡음의 '크기' 혹은 '세기'를 나타냅니다. '세기'의 정의에는 몇 가지가 있는데, 이 포스팅에서는 진폭값의 평균 제곱근(Root Mean Square, RMS)을 각 소리의 세기로 정의하겠습니다.
진폭값의 평균 제곱근은 다음과 같은 순서로 구할 수 있습니다.
- 먼저, 아래 그림처럼 음성의 진폭값이 마이너스 수치로 나올 수도 있으니 진폭값을 제곱합니다.
- 제곱한 값을 더한 뒤 그 값의 평균을 구합니다.
- 마지막으로 평균한 값의 제곱근을 계산하면 소리의 세기를 구할 수 있습니다.

파형 내의 모든 진폭값을 이용한 평균 제곱근 값은 파형에 무음 구간이 많거나 특정 구간만 비정상적으로 진폭값이 큰 경우엔 소리의 세기로 사용할 수 없습니다. 이런 경우, 진폭값의 평균 제곱근이 나타내는 값과 사람이 지각하는 소리의 세기간에 차이가 발생하기 때문에, 무음 구간을 제거하거나 짧은 간격으로 SN비를 계산해야 합니다. 여기에서 소개한 방법 외에도 SN비를 구하는 다른 방법이 있을테니 꼭 조사해 보시기 바랍니다.
Python으로 임의 Signal-to-Noise ratio의 음성 파형 제작
그럼 실제로 음성에 임의 크기의 잡음을 중첩시키는 프로그램을 Python으로 구현해 보겠습니다.
먼저 완성된 코드의 링크를 걸어 두겠습니다.
https://github.com/Sato-Kunihiko/audio-SNR
위 코드에 따라 생성된 음성 예시는 아래와 같습니다.
왼쪽 위부터 차례대로 SN비가 -20, -5, 0, 5, 20dB인 음성 파형입니다. 수치가 커질수록 잡음이 작아지고 음성이 잘 들리게 됩니다.
※위 프로그램을 실행해도 동영상 파일은 생성되지 않으며 음성 파일이 생성됩니다. 이 블로그 사양상 포스팅에 음성 파일을 삽입할 수 없어서 YouTube에 업로드한 동영상을 게재했습니다.
준비
실행 환경 준비
- Python3.x 버전
- MacOS
음성 파일 포맷 확인
음성 파일은 반드시 확장자가 .wav인 파일을 사용해야 합니다. wav 파일의 포맷은 아래와 같이 설정하기 바랍니다.
- 양자화 bit수는 16bit
- 음성용 파일과 잡음용 파일의 샘플링 레이트(sampling rate)를 통일
양자화 bit수는 16bit가 기본값으로 설정되어 있는 경우가 많습니다. 샘플링 레이트는 파일별로 다른 경우가 많으니 유의하시기 바랍니다. (16000Hz나 44100Hz, 48000Hz로 되어 있는 경우가 많습니다.) 샘플링 레이트의 변경은 SoX 등의 음성 편집 소프트웨어를 사용하면 커맨드라인에서도 실행할 수 있습니다.
사용할 데이터 세트 준비
이번 구현에서는 음성만 있는 wav 파일과 잡음만 있는 wav 파일을 사용합니다.
음성만 있는 파일은 CMU ARCTIC 코퍼스를 사용했습니다.
잡음만 있는 파일은 DEMAND를 사용했습니다. DEMAND는 18가지의 환경음이 수록된 데이터 세트입니다.
실행
wav 파일 로딩하기
먼저 wav 파일을 읽어들이도록 구현합니다. Python에서 wav 파일을 취급하기 위한 라이브러리는 몇 가지가 있는데, 이번에는 wave 라이브러리를 사용합니다.
import argparse
import array
import math
import numpy as np
import random
import wave
def get_args():
parser = argparse.ArgumentParser()
parser.add_argument('--clean_file', type=str, required=True)
parser.add_argument('--noise_file', type=str, required=True)
parser.add_argument('--output_clean_file', type=str, default='')
parser.add_argument('--output_noise_file', type=str, default='')
parser.add_argument('--output_noisy_file', type=str, default='', required=True)
parser.add_argument('--snr', type=float, default='', required=True)
args = parser.parse_args()
return args
if __name__ == '__main__':
args = get_args()
clean_file = args.clean_file
noise_file = args.noise_file
snr = args.snr
clean_wav = wave.open(clean_file, "r")
noise_wav = wave.open(noise_file, "r")
위 Python 코드를 실행할 때는, 아래 인수들이 필요합니다.
- 음성만 있는 파일의 절대 경로--
clean_file - 잡음만 있는 파일의 절대 경로--
noise_file - 처리 완료된 음성만 있는 파일의 절대 경로(옵션)--
output_clean_file - 처리 완료된 잡음만 있는 파일의 절대 경로(옵션)--
output_noise_file - 임의 SN비의 음성 파일의 절대 경로--
output_noisy_file - 합성하려는 SN비의 크기--
snr
실제 실행되는 스크립트는 아래와 같습니다. 파일명과 폴더 경로는 각자 환경에 맞는 값으로 바꿔 주세요.
python3 create_noisy_minumum_code.py --clean_file ~/Desktop/test_source/arctic_b0001.wav --noise_file ~/Desktop/test_noise/0ch01.wav --output_clean_file ~/Desktop/clean.wav --output_noise_file ~/Desktop/noise.wav --output_noisy_file ~/Desktop/noisy.wav --snr 0
음성 파형의 진폭값 취득하기
wav 파일을 읽어들여 해당 파일의 진폭값을 얻습니다.
def cal_amp(wf):
buffer = wf.readframes(wf.getnframes())
amptitude = (np.frombuffer(buffer, dtype="int16")).astype(np.float64)
return amptitude
if __name__ == '__main__':
(중략)
clean_amp = cal_amp(clean_wav)
noise_amp = cal_amp(noise_wav)
wf.readframes(n)는 최대 n개의 오디오 프레임을 읽어들여 bytes 객체로 반환합니다. wf.getnframes()는 오디오 프레임 수를 반환합니다. 즉, wf.readframes(wf.getnframes())함수로 wav 파일의 모든 진폭값을 취득할 수 있습니다.마지막으로 bytes 객체를 (np.frombuffer(buffer, dtype="int16")).astype(np.float64)함수를 사용해 np.float64에 캐스팅합니다.
진폭값의 평균 제곱근(Root Mean Square, RMS) 구하기
진폭값의 RMS를 구하기 전에 주의할 점이 있습니다.
DEMAND의 잡음 데이터는 한 파일당 길이가 5분이고, CMU 코퍼스의 음성 데이터는 한 파일당 길이가 2~5초입니다. 따라서 잡음 데이터 파형을 음성 데이터 파형 길이로 잘라야 합니다. 그리고 아래 그림처럼 원본 잡음 파일에서 잘라낸 파형과 음성 데이터 파형의 RMS를 각각 계산하여 임의 SN비가 나오도록 중첩합니다.
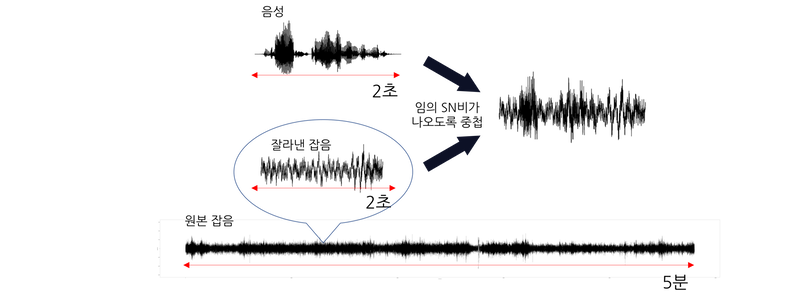
실제 코드에서는 잡음을 자를 위치를 랜덤으로 정해서 음성의 길이만큼 잘라냅니다.
def cal_rms(amp):
return np.sqrt(np.mean(np.square(amp), axis=-1))
if __name__ == '__main__':
(중략)
start = random.randint(0, len(noise_amp)-len(clean_amp))
clean_rms = cal_rms(clean_amp)
split_noise_amp = noise_amp[start: start + len(clean_amp)]
noise_rms = cal_rms(split_noise_amp)
Signal-to-Noise ratio 계산식을 이용해 임의 크기로 파형 합성하기
위에서 말씀드린 것과 같이, SN비 계산식은 다음과 같습니다.
위 계산식을 이용해서 음성에 대해 임의의 SN비가 나오도록 잡음의 RMS를 구합니다. 잡음의 RMS는 위 계산식을 변형한 아래의 계산식으로 구할 수 있습니다.
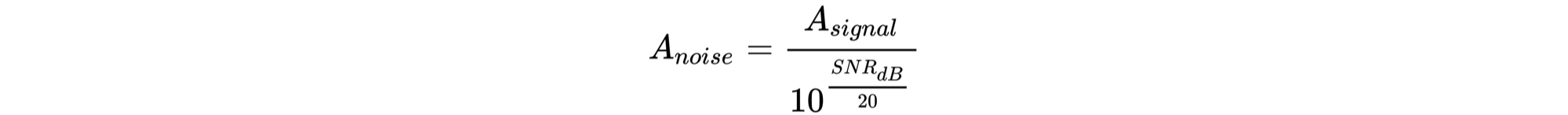
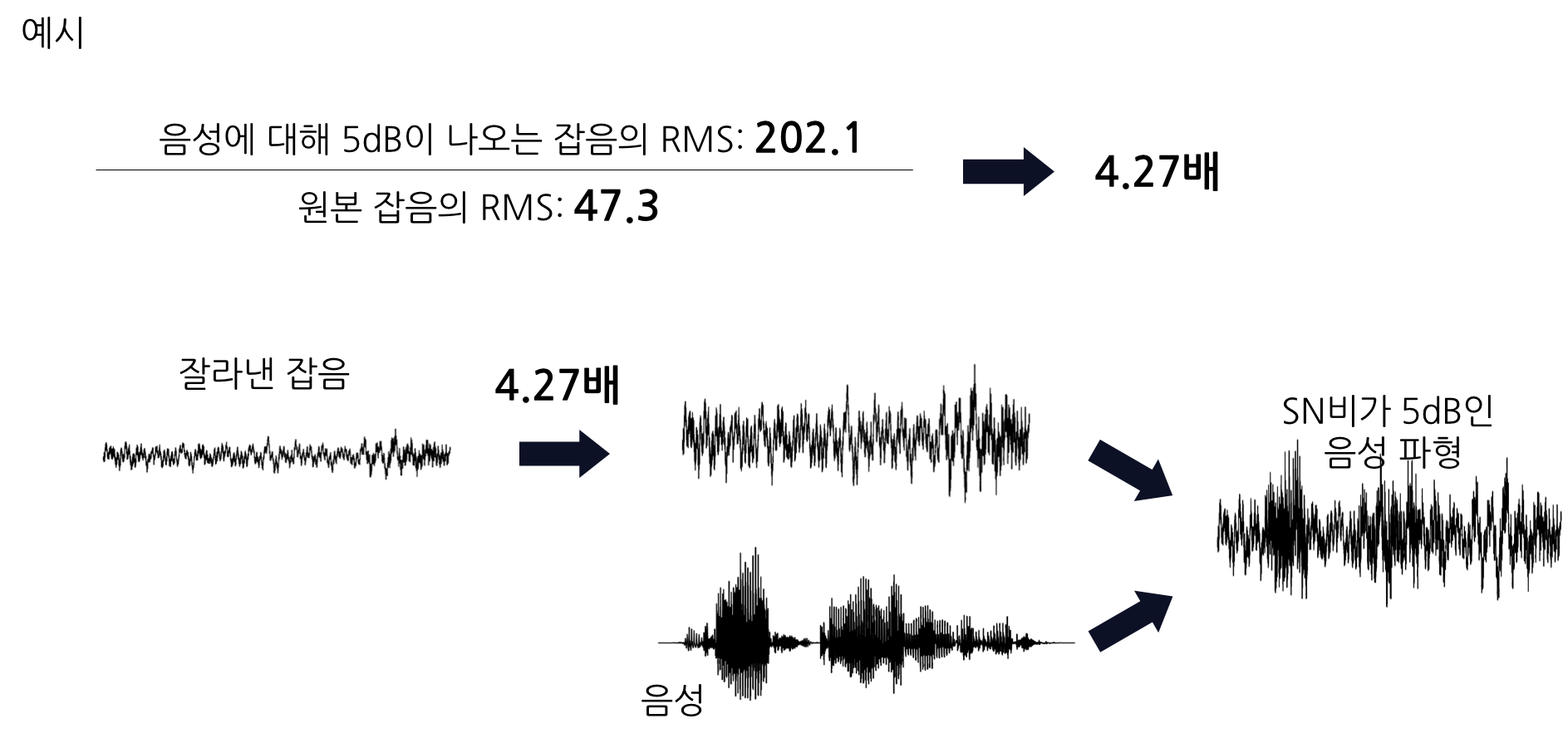
아래 그림과 같이, 위 계산식으로 도출한 RMS(Anoise)와 원본 잡음의 RMS의 비율을 계산하여 그 비율만큼 원본 잡음의 진폭값을 조정합니다. 그 후 조정한 잡음의 진폭과 음성 단독의 진폭을 더합니다.
def cal_adjusted_rms(clean_rms, snr):
a = float(snr) / 20
noise_rms = clean_rms / (10**a)
return noise_rms
if __name__ == '__main__':
(중략)
adjusted_noise_rms = cal_adjusted_rms(clean_rms, snr)
adjusted_noise_amp = split_noise_amp * (adjusted_noise_rms / noise_rms)
mixed_amp = (clean_amp + adjusted_noise_amp)
두 진폭을 서로 더한 후에 주의할 점이 있습니다. 각각의 진폭을 더한 진폭값이 wav 파일의 양자화 bit수, 16bit의 최대값(이진수로 32767)을 넘어 버릴 수 있기 때문입니다. 이렇게 되면 최대값을 넘는 파형은 소위 '절단 현상(breaking)을 초래합니다. 따라서, 서로 더한 값이 16bit의 최대값을 넘을 경우, 서로 더한 값의 최대가 32767 안에 들어오도록 정규화합니다.

if (mixed_amp.max(axis=0) > 32767):
mixed_amp = mixed_amp * (32767/mixed_amp.max(axis=0))
clean_amp = clean_amp * (32767/mixed_amp.max(axis=0))
adjusted_noise_amp = adjusted_noise_amp * (32767/mixed_amp.max(axis=0))
파형을 wav 파일로 저장하기
마지막으로 파형을 wav 파일로 저장합니다. wav 파일로 저장할 때도 wave 라이브러리를 사용합니다.
noisy_wave = wave.Wave_write(args.output_noisy_file)
noisy_wave.setparams(clean_wav.getparams())
noisy_wave.writeframes(array.array('h', mixed_amp.astype(np.int16)).tostring() )
noisy_wave.close()
clean_wave = wave.Wave_write(args.output_clean_file)
clean_wave.setparams(clean_wav.getparams())
clean_wave.writeframes(array.array('h', clean_amp.astype(np.int16)).tostring() )
clean_wave.close()
noise_wave = wave.Wave_write(args.output_noise_file)
noise_wave.setparams(clean_wav.getparams())
noise_wave.writeframes(array.array('h', adjusted_noise_amp.astype(np.int16)).tostring() )
noise_wave.close()
setparams()는 wav 파일의 포맷을 지정하는 메서드입니다. 특별한 문제가 없으면 입력에 사용한 음성 파일 포맷을 그대로 사용해도 됩니다.writeframes()로 진폭값을 지정합니다. String에 캐스팅해야 합니다.
전체 코드
마지막으로 전체 코드를 공개합니다. Gihub에도 올려두었습니다.
# -*- coding: utf-8 -*-
import argparse
import array
import math
import numpy as np
import random
import wave
def get_args():
parser = argparse.ArgumentParser()
parser.add_argument('--clean_file', type=str, required=True)
parser.add_argument('--noise_file', type=str, required=True)
parser.add_argument('--output_clean_file', type=str, default='')
parser.add_argument('--output_noise_file', type=str, default='')
parser.add_argument('--output_noisy_file', type=str, default='', required=True)
parser.add_argument('--snr', type=float, default='', required=True)
args = parser.parse_args()
return args
def cal_adjusted_rms(clean_rms, snr):
a = float(snr) / 20
noise_rms = clean_rms / (10**a)
return noise_rms
def cal_amp(wf):
buffer = wf.readframes(wf.getnframes())
amptitude = (np.frombuffer(buffer, dtype="int16")).astype(np.float64)
return amptitude
def cal_rms(amp):
return np.sqrt(np.mean(np.square(amp), axis=-1))
if __name__ == '__main__':
args = get_args()
clean_file = args.clean_file
noise_file = args.noise_file
snr = args.snr
clean_wav = wave.open(clean_file, "r")
noise_wav = wave.open(noise_file, "r")
clean_amp = cal_amp(clean_wav)
noise_amp = cal_amp(noise_wav)
start = random.randint(0, len(noise_amp)-len(clean_amp))
clean_rms = cal_rms(clean_amp)
split_noise_amp = noise_amp[start: start + len(clean_amp)]
noise_rms = cal_rms(split_noise_amp)
adjusted_noise_rms = cal_adjusted_rms(clean_rms, snr)
adjusted_noise_amp = split_noise_amp * (adjusted_noise_rms / noise_rms)
mixed_amp = (clean_amp + adjusted_noise_amp)
if (mixed_amp.max(axis=0) > 32767):
mixed_amp = mixed_amp * (32767/mixed_amp.max(axis=0))
clean_amp = clean_amp * (32767/mixed_amp.max(axis=0))
adjusted_noise_amp = adjusted_noise_amp * (32767/mixed_amp.max(axis=0))
noisy_wave = wave.Wave_write(args.output_noisy_file)
noisy_wave.setparams(clean_wav.getparams())
noisy_wave.writeframes(array.array('h', mixed_amp.astype(np.int16)).tostring() )
noisy_wave.close()
clean_wave = wave.Wave_write(args.output_clean_file)
clean_wave.setparams(clean_wav.getparams())
clean_wave.writeframes(array.array('h', clean_amp.astype(np.int16)).tostring() )
clean_wave.close()
noise_wave = wave.Wave_write(args.output_noise_file)
noise_wave.setparams(clean_wav.getparams())
noise_wave.writeframes(array.array('h', adjusted_noise_amp.astype(np.int16)).tostring() )
noise_wave.close()
마치며
딥 러닝을 통해 다양한 음성 처리의 정밀도가 향상되었지만, 아직 이 분야는 복잡한 사전 지식이 필요하고 참고할만한 문서도 많지 않다고 느껴집니다. 이 포스팅을 보시고 더 많은 분들이 음성 처리에 관심 갖게 되면 좋겠습니다.
포스팅 내용에 오류가 있거나, 다른 의견이 있으시면 Github나 twitter로 연락 부탁드립니다.
긴 글 읽어주셔서 감사합니다.