
안녕하세요. LINE에서 모바일 게임을 개발하고 있는 김선태입니다. 이번 글에서는 오픈소스 모바일 게임엔진 중에서 전세계 시장 점유율 25%로 1위를 차지하고 있는 Cocos2d-x의 멀티 스레드 병렬처리 기법을 소개하고자 합니다. 기존에 싱글 스레드 기반으로 동작하는 물리 연산을 멀티 스레드 기법을 적용하여 병렬 처리를 함으로써 구조를 개선하고 성능을 향상시키는 방법에 대해서 설명하겠습니다.
멀티 스레드 기반의 물리 연산 병렬처리 구조 설계
먼저 멀티 스레드 기반의 물리 연산 병렬처리 구조를 설명하기 전에 기존 싱글 스레드 기반의 Cocos2d-x 업데이트 루프부터 설명하겠습니다.
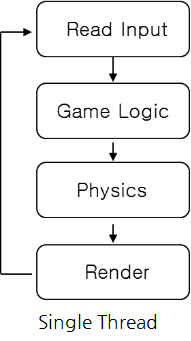
[그림 1]은 기존 Cocos2d-x의 업데이트 루프입니다. 단계를 설명하면 먼저 사용자 입력을 받고, 게임 로직을 수행한 다음 물리 업데이트를 하고 최종적으로 렌더링을 하게 됩니다. 여기서 중요한 점은 싱글 스레드 기반이기 때문에 물리 연산이 완료된 후에야 렌더링을 할 수 있다는 것입니다. 즉 물리 연산이 끝나기 전까지는 렌더링을 할 수 없습니다. 만약 물리 시뮬레이션에 많은 연산이 필요한 경우에는 렌더링이 딜레이되고 결국에는 FPS가 저하되면서 화면이 부자연스럽고 끊어져 보이게 됩니다.
반대의 경우도 마찬가지입니다. 렌더링 연산이 많은 경우에는 다음 번 사용자 입력에서 기다리게 되고 결국 물리 업데이트까지 딜레이가 발생하게 됩니다. 원인은 이 모든 처리가 하나의 루프에서 동작하기 때문입니다. 연산량이 적고 처리할 것이 많지 않은 상황이라면 싱글 스레드로 처리해도 문제가 없겠지만 과부하 상황에서는 이런 문제가 발생하기 쉽습니다.
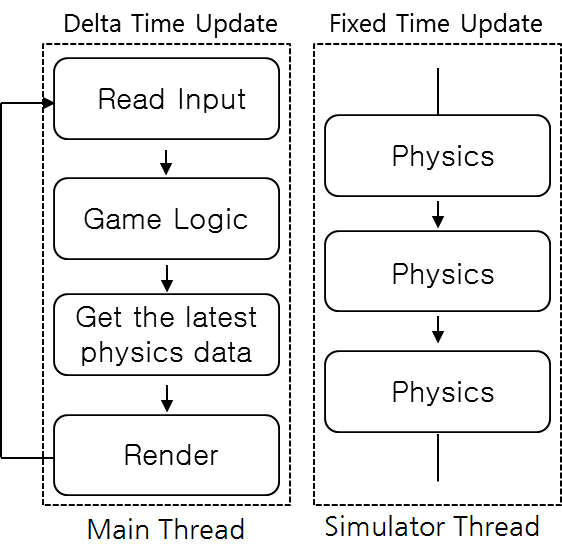
[그림 2]는 Cocos2d-x에서 멀티 스레드 기반으로 동작 가능한 물리 연산 병렬처리 설계도입니다. 그림에서 달라진 부분은 물리 부분이 다른 스레드에서 동작한다는 것이고, 메인 스레드에서는 가장 최근에 계산한 물리 데이터만 읽어서 렌더링합니다. 기존의 싱글 스레드 기반에서는 물리 연산이 끝날 때까지 기다렸다가 렌더링했습니다.
하지만, 새롭게 설계한 이 구조에서 가장 중요한 것은 물리 연산은 다른 스레드에서 병렬로 계속 계산하고 있고, 메인 스레드에서 물리 연산이 끝날 때까지 기다릴 필요 없이 가장 최근에 계산된 결과만으로 렌더링한다는 것입니다. 또한 렌더링에 과부하가 걸려서 느려지는 상황에서도 물리 연산은 다른 스레드에서 독립적으로 일정한 tick1을 유지하며 병렬처리가 가능합니다.
업데이트 방식은 메인 스레드에서는 게임 플레이 시간에 의해서 결과를 보여줘야 하기 때문에 Delta Time 업데이트2 방식으로 하고, Simulator 스레드에서는 물리 연산의 정확도를 높이기 위헤서 고정된 시간으로 Fixed Time 업데이트3를 하게 됩니다. 이렇게 되면 Unity처럼 물리 연산이 병렬로 처리되기 때문에 개발자는 Fixed Time 값을 변경해가며, 즉 게임에 적합한 물리 연산의 정확도를 조절해가면서 시뮬레이션할 수 있게 됩니다.
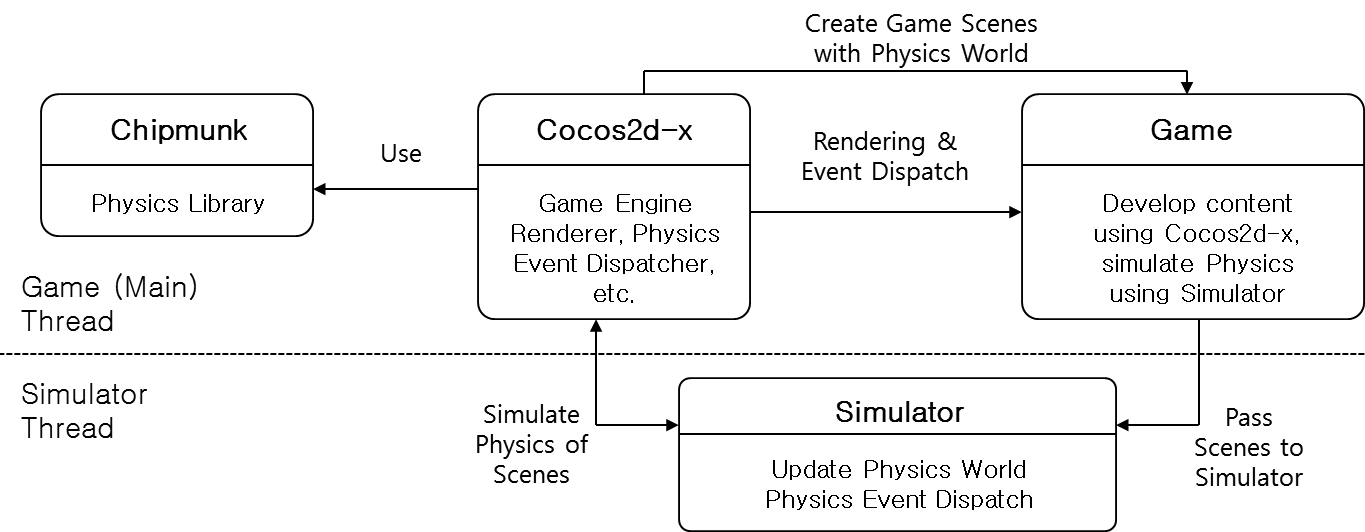
[그림 3]은 Cocos2d-x의 멀티 스레드로 물리 연산의 병렬처리가 가능한 시스템 아키텍처입니다. 이 시스템에는 다음과 같이 크게 4개의 모듈이 있습니다.
- Cocos2d-x
- Chipmunk Physics Library
- Game
- Simulator
먼저 Cocos2d-x에는 Chipmunk Physics Library라는 2D 물리 라이브러리가 기본 탑재되어 연동되고 있으며, Game은 Cocos2d-x를 이용하여 게임에 필요한 Scene을 구성하고 각종 콘텐츠를 개발하게 됩니다. 이때 Scene 정보를 다른 스레드인 Simulator에게 전달하면 Simulator는 Cocos2d-x에 접근할 수 있게 되고, Cocos2d-x를 통해서 최종 Chipmunk 라이브러리의 물리 연산을 동적으로 컨트롤할 수 있게 됩니다. 여기서 Cocos2d-x와 Chipmunk, Game은 메인 스레드에서 동작하며 Simulator는 다른 스레드에서 동작하게 됩니다. 즉 Game과 물리 연산이 병렬로 처리되는 구조입니다.
1: tick은 update 함수가 호출되는 것을 의미하며, tick count는 update 함수가 호출되는 횟수를 의미합니다. 이전 업데이트와 현재 업데이트까지의 시간 차이를 Delta Time이라고 하는데, Delta Time 값이 작으면 업데이트 주기가 빠른 것이고 이것은 업데이트 tick이 더 많이 발생한다고 표현할 수 있습니다.
2: Delta Time 업데이트는 업데이트 단위를 이전 프레임과 현재 프레임간의 시간 차이, 즉 Delta Time(1/FPS)으로 업데이트하는 방식입니다.
3: Fixed Time 업데이트는 업데이트 단위를 고정된 시간으로 업데이트하는 방식입니다.
멀티 스레드 기반의 물리 Simulator 설계
물리 연산을 멀티 스레드로 처리하기 위해서는 물리 Simulator의 설계가 매우 중요한 요소입니다.

[그림 4]는 기존 Cocos2d-x에서의 물리 구조입니다. 그림에서 노드와 PhysicsBody가 1:1(일대일) 관계이고 Scene과 PhysicsWorld가 1:1 관계입니다. Scene은 여러 개의 자식 노드를 가질 수 있으며 PhysicsWorld 또한 여러 개의 PhysicsBody를 가질 수 있습니다. 이처럼 Game의 장면을 담는 최상위 객체인 Scene은 여러 물리 객체를 담는 최상위 객체인 PhysicsWorld와 1:1 구조입니다. 그리고 이벤트 핸들링을 위한 EventDispatcher 변수 1개를 전역으로 사용하고 있습니다.

이 구조에서 어떻게 하면 멀티 스레드가 가능한 구조가 될까요? [그림 5]를 보면 Simulator가 추가된 것을 확인할 수 있습니다. Simulator는 Scene 객체와 EventDispatcher 객체를 가지고 있습니다. Simulator는 Scene 객체를 통해서 PhysicsWorld에 접근하고 최종적으로 PhysicsBody에 접근하여 물리 데이터에 접근이 가능해집니다. 여기서 PhysicsBody는 Chipmunk 물리 라이브러리에서 제공하는 실질적인 물리 Rigid Body 객체인 cpBody를 래핑한 클래스입니다. Cocos2d-x에서는 PhysicsBody 객체가 내부적으로 Chipmunk 물리 라이브러리의 값을 접근하고 있는 것입니다. 즉 Cosos2d-x에서 물리 연산을 병렬처리하려면 Cocos2d-x 소스 코드뿐만 아니라 Chipmunk 물리 라이브러리 소스 코드에도 동기화 로직을 추가해야 합니다.
동기화 작업을 위해서 Chipmunk 물리 라이브러리의 소스 코드를 다운로드해서 cpBody 값이 변경되는 부분에 Mutex 동기화 로직을 추가하고, Cocos2d-x에서도 cpBody를 사용하는 PhysicsBody에 동기화 로직을 추가했습니다. 특히 Read일 경우에는 TryLock을 이용하여 이미 Lock이 걸렸는지 체크하고, Lock이 걸린 상태라면 릴리스될 때까지 더 이상 기다리지 않고 최근에 계산된 값을 읽어서 바로 렌더링하고 다른 일을 처리할 수 있게 하였습니다. 또한 Cocos2d-x에서는 이벤트 핸들링을 EventDispatcher 변수 1개로 처리합니다. 그렇기 때문에 메인 스레드에서 EventDispatcher가 발생했을 때 Simulator 스레드에서 접근한다면 프로그램에 오류가 발생할 수 있습니다.
이 문제를 해결하려면 두 가지 방법이 있습니다. 첫 번째는 Mutex를 사용하여 임계영역을 설정하는 것이고 두 번째는 Simulator 스레드에 EventDispatcher 변수를 독립적으로 하나 더 생성하는 것입니다. 이 설계에서는 성능 향상을 위해서 Mutex를 최대한 쓰지 않으며, 무엇보다 물리 충돌 이벤트를 Simulator 스레드에서 바로 핸들링할 수 있도록 Simulator에 EventDispatcher 변수를 선언해서 메인 스레드와 충돌 없이 독립적으로 핸들링할 수 있게 하였습니다. 결론적으로 Chipmunk 소스에 동기화 로직을 추가하고 빌드하여 libchipmunk.a 라이브러리 파일을 생성하였으며, 이 라이브러리를 수정된 Cocos2d-x 소스 코드와 함께 빌드하고 링크하여 최종 libgame.so 파일을 만들었습니다. 이렇게 되면 최종적으로 libgame.so 파일을 이용해서 게임을 구동할 수 있게 됩니다.
테스트 환경
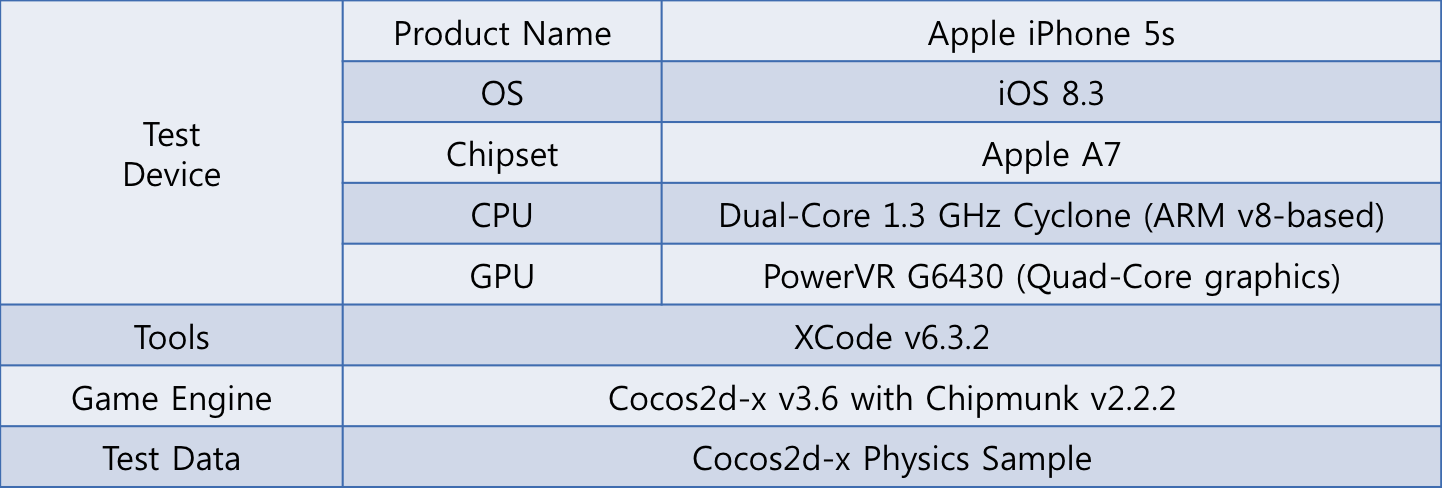
설계한 멀티 스레드 기반의 물리 시뮬레이션 결과가 싱글 스레드일 때보다 성능이 얼마 만큼 향상되었는지 테스트해보았습니다. 아래는 테스트 환경으로, 디바이스는 iPhone 5s를 사용했으며 Cocos2d-x 버전은 3.6, Chipmunk 라이브러리 버전은 2.2.2를 사용했습니다.
동기화 및 이벤트 핸들링 테스트
물리 연산을 멀티 스레드로 병렬처리했을 때 동기화 및 이벤트 핸들링이 제대로 동작하는지 확인하기 위해서 테스트 프로그램을 개발하였습니다. 테스트 프로그램은 Cocos2d-x에서 기본으로 제공하는 Contact test 예제를 활용하였습니다.

[그림 6]은 테스트 프로그램에서 삼각형, 사각형 물체를 다량으로 생성한 모습입니다. 이때 물체들끼리 서로 충돌하면 바운싱되고, 화면 스크린 영역에는 투명으로 처리된 벽이 있어서 이 벽과도 충돌하면 바운싱이 됩니다. 동기화 및 이벤트 핸들링 테스트를 위해서 각 오브젝트들이 충돌할 때마다 콜백 함수에서 오브젝트의 색을 녹색으로 변하도록 하였습니다.

싱글 스레드일 때와 멀티 스레드일 때 모두 동일한 조건으로 시뮬레이션했습니다. 결과는 [그림 7] (a), (b)처럼 싱글 스레드일 때와 멀티 스레드일 때 모두 동일하게 점차 녹색으로 변하는 것을 확인할 수 있었습니다. 물체들이 서로 충돌해서 바운싱된다는 것은 동기화 처리가 되었다는 것이며, 이때 충돌된 물체가 녹색으로 변했다는 것은 이벤트 핸들링이 정상 동작하여 콜백함수에서 오브젝트의 색을 녹색으로 변경시켰다는 것입니다. 이렇게 동기화 및 이벤트 핸들링이 정상 동작하는 것을 확인하였고, 다음에는 성능 측정 결과를 소개하겠습니다.
성능 측정 결과
현재까지 개발한 멀티 스레드 기반의 물리 연산이 기존 싱글 스레드 방식보다 과연 얼마 만큼 성능이 향상되었는지 측정해 보았습니다.
게임 과부하에 따른 성능 측정 결과
게임을 개발하다 보면 게임 자체가 느려지거나 과부하가 걸리는 경우가 있습니다. 이 경우에 멀티 스레드 기반의 물리 연산이 어떤 영향을 주는 지 먼저 테스트해보았습니다. 게임에 과부하가 걸리면 CPU 연산량이 늘어나므로 과부하 정도를 아래처럼 Matrix를 여러 번 곱하는 것으로 정의하였습니다.
MAX_UPDATE_COUNT = 300000
updateForOverhead()
for i ← 1 to MAX_UPDATE_COUNT
do dstMatrix ← dstMatrix * srcMatrix
이렇게 되면 MAX_UPDATE_COUNT라는 변수로 게임 과부하 정도를 정량적인 수치로 표현할 수 있습니다.
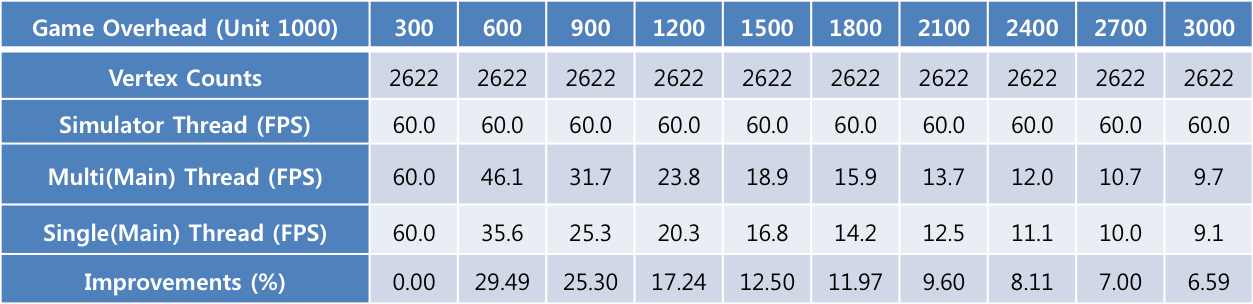
실험을 위해서 시뮬레이션되는 오브젝트 수는 360개로 고정시키고 게임 과부하 정도를 최소 30만에서 최대 300만까지 늘리면서 테스트했습니다. [표 2]에서 보듯이 게임 과부하 정도가 30만일 때에는 싱글 스레드와 멀티 스레드[Multi(Main) Thread, Simulator Thread]에서 모두 최대 FPS로 설정한 60 FPS까지 나왔습니다. 그러나 300만일 때를 보면 싱글 스레드는 9.1 FPS이고 멀티 스레드일 때의 메인 스레드는 9.7 FPS로 거의 비슷한 수치였습니다. 하지만 멀티 스레드일 때의 Simulator 스레드를 보면 60 FPS로 측정됐습니다.
이 현상을 분석해보면 물리 연산과 상관없이 게임 과부화는 메인 스레드에 걸리기 때문에 싱글 스레드와 멀티 스레드일 때의 메인 스레드 모두 성능 저하가 있었습니다. 반면에 물리 연산은 다른 스레드(Simulator 스레드)에서 동작하므로 게임 과부하에 대한 영향은 받지 않았으며, 30만일 때와 300만일 때 모두 60 FPS가 나온 것을 확인할 수 있었습니다.
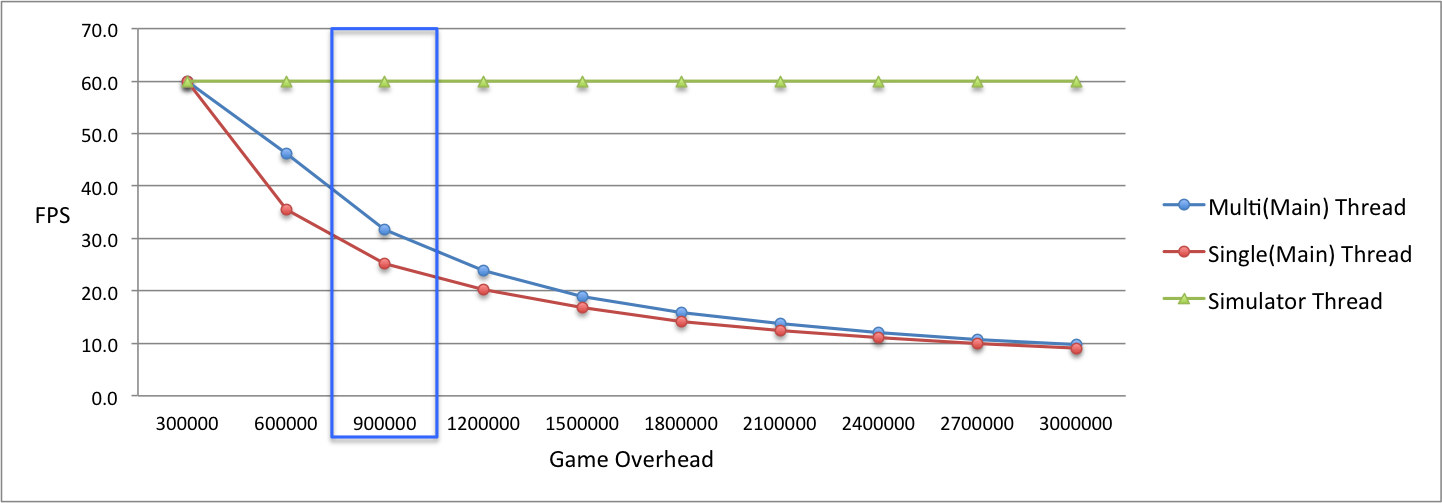
[그림 8]은 게임 과부하 정도에 따른 성능 측정결과를 그래프로 표시한 것입니다. 싱글 스레드일 때와 멀티 스레드일 때의 메인 스레드 기울기를 보면(파란색과 빨간색), 멀티 스레드일 때의 메인 스레드가 성능이 덜 급격하게 감소되는 것을 확인할 수 있습니다. 이것을 분석해보면 싱글 스레드일 때는 물리 연산과 렌더링을 하나의 루프에서 같이 처리하지만, 멀티 스레드일 때에는 물리 연산을 Simulator 스레드에서 처리하게 됩니다. 이렇게 되면 물리 연산에 대한 처리를 Simulator 스레드에서 하기 때문에 성능 저하가 싱글 스레드처럼 급격하게 내려가지 않는 것을 확인할 수 있습니다.
위의 측정 결과는 스트레스 테스트에서의 수치이고 의미있는 실제 적용 가능한 수치는 어느 구간일까요? 현실적으로 적용 가능한 수치는 30 FPS로 게임 과부하가 90만일 때의 구간입니다([그림 8]에서 파란색 사각형 부분). 이때 수치를 보면 싱글 스레드에서는 25.3 FPS이고 멀티 스레드에서의 메인 스레드는 31.7 FPS, 그리고 Simulator 스레드에서는 60 FPS입니다.
물리 연산을 Delta Time으로 업데이트하는 경우를 분석해보면, 싱글 스레드에서는 약 0.0395초(25.3 FPS)마다 물리 연산을 하고 렌더링하는 반면에 멀티 스레드에서는 0.0167초(60 FPS)마다 물리 연산을 수행하고 0.0315초(31.7 FPS)마다 렌더링하게 됩니다. 즉 멀티 스레드일 때가 물리 연산을 약 2.4배 더 작은 값으로 세밀하게 수행하기 때문에 충돌체크가 더 정확하게 이루어지며, 렌더링도 더 높은 FPS로 부드럽게 하게 되므로 퀄리티 측면에서 아주 확연한 차이를 보입니다. 또한 Fixed Time 값을 0.0167초로 설정하고 Fixed Time으로 업데이트하는 경우를 분석해 보면, 싱글 스레드에서는 약 0.0395초(25.3 FPS)마다 0.0167의 값으로 step4하면서 충돌처리 및 시뮬레이션합니다.
반면에 멀티 스레드에서는 약 0.0167초(60 FPS)마다 0.0167의 값으로 step하면서 충돌처리 및 시뮬레이션합니다. 이 경우 시뮬레이션하는 step 값은 동일하기 때문에 정확도는 같겠지만, 멀티 스레드일 때가 tick이 약 2.4배 더 많이 발생하게 되므로 싱글 스레드 보다 더 빠르게 시뮬레이션되는 것을 확인할 수 있습니다.
4: step은 업데이트와 같으며 업데이트는 물리에서 시뮬레이션한다는 의미입니다. '한 단계씩 업데이트한다'라는 것을 '한 단계씩 step한다'라고도 표현합니다.
물리 연산 과부하에 따른 성능 측정 결과
게임을 개발하다 보면 게임 로직 혹은 그래픽 이슈보다는 물리 연산 자체가 느려지는 경우가 있는데요. 바로 이 물리 연산 자체에 과부하가 걸린 상황에서 어떤 변화가 있는지 테스트해보았습니다.
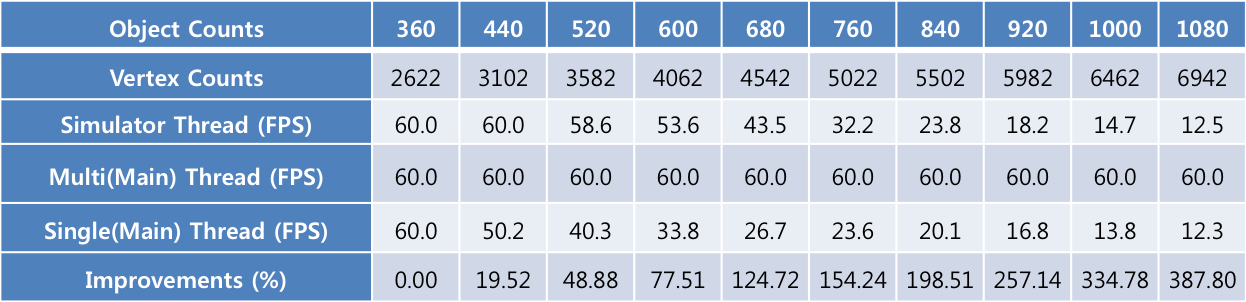
실험을 위해서 게임 과부하 정도는 30만으로 고정시키고 시뮬레이션하는 오브젝트 수는 최소 360개에서 최대 1,080개까지 늘리면서 테스트했습니다. [표 3]에서 보듯이 오브젝트 수가 360개일 때에는 싱글 스레드와 멀티 스레드[Multi(Main) Thread, Simulator Thread]에서 측정 결과 수치가 모두 최대 FPS로 설정한 60 FPS입니다. 그러나 1,080개일 때를 보면 싱글 스레드는 12.3 FPS이고 멀티 스레드일 때의 메인 스레드는 60 FPS입니다. 하지만 멀티 스레드일 때의 Simulator 스레드를 보면 12.5 FPS이며 이는 싱글 스레드와 비슷한 수치입니다.
이 현상을 분석해보면 물리 연산에 과부하를 주었기 때문에 싱글 스레드와 멀티 스레드일 때의 Simulator 스레드 모두 성능 저하가 있었습니다. 그렇지만 멀티 스레드에서의 메인 스레드의 경우 게임 로직 및 렌더링은 Simulator 스레드와 별개로 동작하므로 물리 연산에 대한 비용이 발생하지 않으며 360개일 때와 1,080개일 때 모두 성능 측정 결과 수치가 60 FPS인 것을 확인할 수 있습니다.
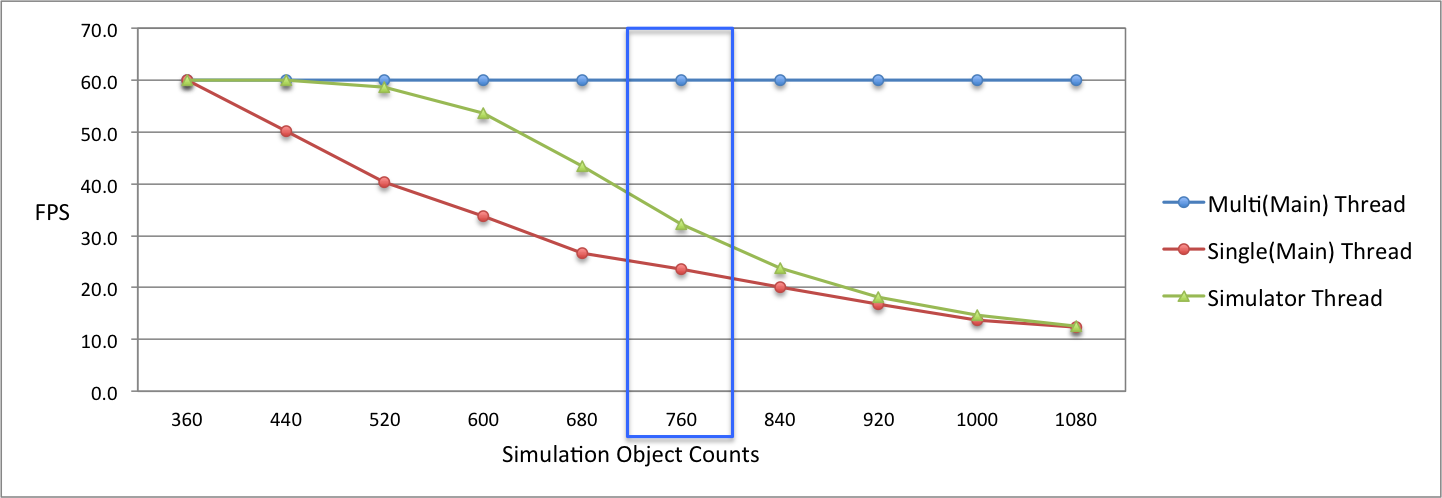
[그림 9]는 물리 연산 과부하 정도에 따른 성능 측정결과를 그래프로 표시한 것입니다. 싱글 스레드일 때와 멀티 스레드일 때의 메인 스레드 기울기를 보면(파란색과 빨간색), 싱글 스레드일 때에는 성능이 급격하게 하락한 반면에 멀티 스레드의 메인 스레드에서는 최대 FPS인 60 FPS를 유지하고 있는 것을 확인할 수 있습니다. 그리고 Simulator 스레드를 보면 성능 하락은 있지만 싱글 스레드처럼 급격하게 하락하지 않는 것을 볼 수 있습니다. 이것을 분석해 보면 싱글 스레드일 때는 물리 연산과 렌더링을 같이 하기 때문에 성능이 급격하게 떨어지지만, Simulator 스레드에서는 물리 연산만 하게 되므로 싱글 스레드보다는 완만하게 성능이 하락하게 되는 것으로 확인할 수 있습니다.
위의 측정 결과는 스트레스 테스트에서의 수치이고 의미 있는 실제 적용 가능한 수치는 어느 구간일까요? 오브젝트 수가 760개일 때 현실적으로 적용 가능한 수치는 30 FPS입니다([그림 9]에서 파란색 사각형 부분). 이때 수치를 보면 싱글 스레드에서는 23.6 FPS이고 멀티 스레드에서의 메인 스레드는 60 FPS, 그리고 Simulator 스레드에서는 32.2 FPS입니다. 물리 연산을 Delta Time으로 업데이트하는 경우를 분석해보면, 싱글 스레드에서는 약 0.0424초(23.6 FPS)마다 물리 연산을 하고 렌더링도 하지만, 멀티 스레드에서는 0.0311초(32.2 FPS)마다 물리 연산을 수행하고 0.0167초(60 FPS)마다 렌더링을 하게 됩니다.
더 자세히 설명하면 멀티 스레드일 때에는 다른 스레드에서 0.0311초마다 물리 연산을 병렬로 처리하면서 메인 스레드에서는 0.0167초마다 이미 계산된 물리 시뮬레이션 값으로 렌더링만 하기 때문에 성능 측면에서 충돌처리가 정확하고 훨씬 더 부드럽게 연출되는 것을 확인할 수 있습니다. 또한 Fixed Time 값을 0.0167초로 설정하고 Fixed Time으로 업데이트하는 경우를 분석해 보면, 싱글 스레드에서는 약 0.0424초(23.6 FPS)마다 0.0167의 step으로 충돌처리 및 시뮬레이션한 다음에 렌더링하고, 멀티 스레드에서는 약 0.0311초(32.2 FPS)마다 0.0167의 step으로 충돌처리 및 시뮬레이션하면서 0.0167초(60 FPS)초마다 이미 계산된 값으로 렌더링하게 됩니다. 이 경우 멀티 스레드가 싱글 스레드일 때보다 더 정확하고 빠르기도 하지만 렌더링 FPS가 약 2.5배 높기 때문에 훨씬 부드럽게 연출되는 것을 확인할 수 있습니다.
충돌체크 정확성 테스트
위에서 싱글 스레드일 때 물리 연산을 Delta Time으로 하는 경우, 게임에 과부하가 발생하면 tick이 불안정해져서 충돌체크가 정확히 안 될 수도 있다고 설명했습니다. 멀티 스레드 기반으로 물리 연산을 했을 때 충돌체크 정확성이 얼마나 향상되었는지 테스트를 해보았습니다. 테스트 조건은 현실적으로 적용 가능한 수치인 멀티 스레드 기반에서 메인 스레드와 Simulator 스레드가 모두 30 FPS가 되는 상황으로 설정하였습니다. 업데이트 방식은 싱글 스레드에서는 Delta Time 방식으로 업데이트되고 멀티 스레드에서는 메인 스레드가 Delta Time, Simulator 스레드가 Fixed Time으로 각각 업데이드되도록 설정하였습니다. 물체가 벽(Bound Box)에 부딪히면 바운싱되어야 하는데 뚫고 지나가는 경우가 있는지 체크하였고, 시뮬레이션을 시작한 후 시간에 따른 오브젝트의 수를 관찰하였습니다.
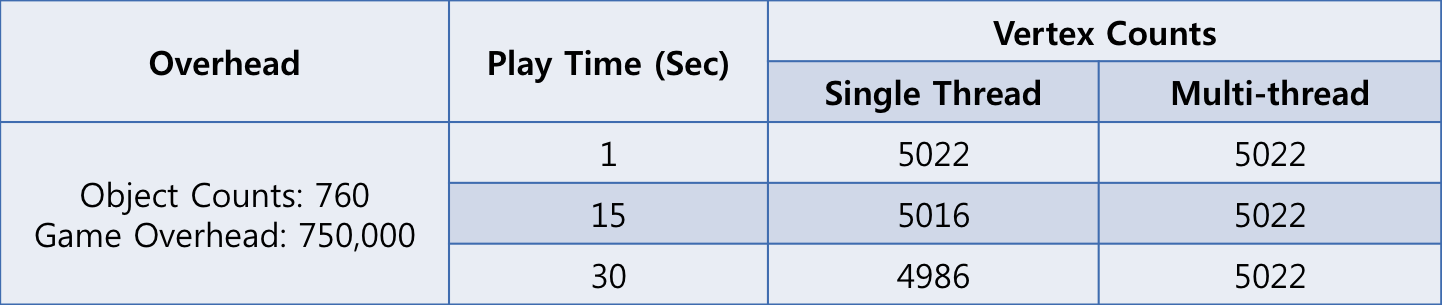
[표 4]는 멀티 스레드 기반으로 물리 연산을 했을 때 충돌체크 정확성이 얼마나 향상되었는지 측정한 표입니다. 처음에는 Vertex 수가 5,022개로 싱글 스레드와 멀티 스레드일 때 모두 동일하게 시작되다가, 15초 후에는 싱글 스레드에서 Vertex 개수가 6개 감소하였습니다. 이것은 삼각형 하나가 Vertex 3개이므로 삼각형 2개가 사라진 것으로 분석할 수 있습니다. 그리고 30초 후에는 4,986개로 36개가 감소했으며 이는 삼각형 12개가 사라진 것으로 추정할 수 있습니다. 그러나 멀티 스레드의 경우를 보면 시간이 지나도 5,022개로 벽을 뚫고 사라진 오브젝트 없이 정확하게 충돌체크되고 있는 것을 확인할 수 있습니다.
결론 및 향후 과제
지금까지 싱글 스레드 기반으로 동작하는 물리 연산을 멀티 스레드 기법을 적용하여 병렬처리하는 방법에 대해서 알아보았습니다. 크게 보면 물리 연산을 멀티 스레드로 병렬처리함으로써 구조적, 성능적 측면에서 개선되었다고 볼 수 있습니다. 구조적인 측면에서는 기존에 물리 연산하는 부분을 스레드로 분리함으로써 메인 스레드와 독립적으로 Fixed Time 값, 즉 정확도를 조절해가며 시뮬레이션할 수 있습니다. 성능적인 측면에서는 멀티 스레드일 때가 충돌체크가 더 정확하고 빠르며 자연스럽게 연출되는 것을 확인하였습니다. 일반적으로 게임을 개발하다 보면 물리 연산이 느려서 해당 기능을 빼거나 아니면 편법을 사용하여 해당 기능을 구현하곤 합니다. 하지만 이렇게 물리 연산을 병렬처리함으로써 기존에 기술적 한계 때문에 개발하지 못했던 장르나 새로운 콘텐츠에 대해서 개발할 수 있는 가능성을 보여주었다고 생각합니다.
현재는 시뮬레이터가 클라이언트에서만 동작하지만 이것을 서버에서 분산 처리되게 한다면 대규모 시뮬레이션이 가능할 수 있을 것입니다. 또한 물리 연산뿐만 아니라 게임 로직까지 병렬처리해서 대규모 분산 게임 시뮬레이터를 개발해보는 것도 재미있는 과제가 될 것 같습니다. 이렇게 되면 렌더링과 별개로 데이터 중심으로 게임을 시뮬레이션할 수 있는 게임 벨런싱 툴 개발에도 활용될 수 있을 것입니다.
위 블로그의 내용은 필자의 논문 "게임엔진의 실시간 물리 시뮬레이션을 위한 멀티스레드 병렬처리 기법(Multi-threaded Parallel Processing Technique for Real-time Physics Simulation in Game Engine), 연세대학교, 2016"에서 일부 발췌하거나 각색하였습니다.