
들어가며
안녕하세요. 저는 Graylab에서 LINE의 보안 관련 업무를 담당하고 있는 신종호입니다. 저희 Graylab에서는 여러 보안 팀과 함께 LINE의 전반적인 보안을 강화하기 위해 다양한 노력을 기울이고 있습니다. 최근 LINE의 성장과 함께 사업 영역과 서비스가 확장되면서 저희가 보호해야 할 영역도 함께 넓어지고 있습니다. 특히 중요한 서비스에 대해서는 더욱 주의를 기울이고 있는데요. 일례로 시스템 접속 로그 모니터링도 진행 중입니다. 그런데 모니터링해야 할 로그가 쌓여가는 양이 많아 수많은 로그를 효과적으로 관리할 방법이 필요하게 되었습니다. 그래서 이번에 머신러닝을 활용하여 모니터링 업무의 효율을 높여보기로 하였습니다.
우선 저희와 비슷한 다른 기업의 사례를 살펴보면, Google은 오래전부터 다양한 보안 팀을 운영해 오고 있습니다. 그중에서 Google Security Monitoring Tools group에선 구글러들과 내부 네트워크에 대한 모니터링을 강화해 왔습니다. 개인적으로 대학원 수업1에서 Massimiliano Poletto(당시 Google Security Monitoring Tools group의 리더)의 프레젠테이션을 듣고 Google에서 머신러닝을 어떻게 내부 모니터링에 사용하고 있는지 자세히 알 수 있는 기회가 있었습니다. 이를 참고로 하여 저희도 모니터링 시스템에 머신러닝을 적용해 보기로 하였습니다.
머신러닝으로 이상 탐지(anomaly detection)를?
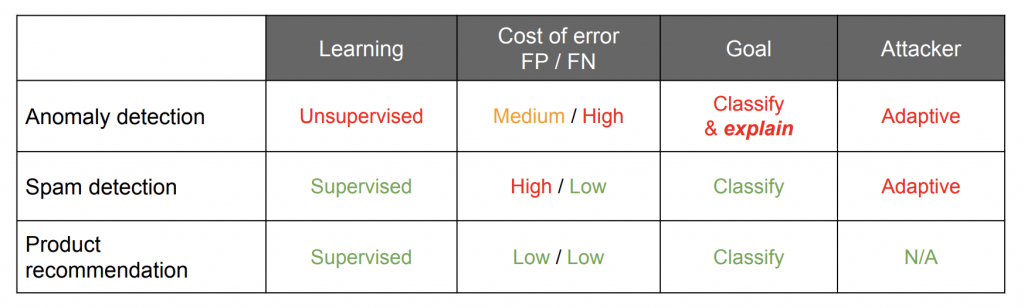
앞서 말씀드린 강의에서도 설명하지만, 이상 탐지는 머신러닝으로 해결하기 어려운 문제 중 하나입니다. 일단 머신러닝은 큰 그림을 보고 비슷한 것을 찾거나 만드는 것을 더 잘 합니다. 최근에 딥러닝의 GAN이나 Autoencoder를 보면 특히 더 그런 모습을 볼 수 있습니다. 반면에 아웃라이어(outlier)와 같이 미세한 차이를 찾는 것에는 비교적 약한 모습을 보입니다. 게다가 이상 탐지에 지도 학습(supervised learning)을 사용하기는 더더욱 어렵습니다. 한 번도 본 적이 없는 아웃라이어에 대해서는 레이블링(labeling)도 불가능합니다. 또한 아웃라이어는 그 샘플의 수가 매우 적기 때문에 전체적인 훈련 데이터(training data)가 굉장히 편향됩니다. 이렇게 훈련 데이터가 편향되면 모델을 제대로 훈련시키기도 어렵고 결과의 신뢰도도 매우 떨어지게 됩니다. 이러한 이유 때문에 Massimiliano Poletto는 Google도 상당 부분 룰 기반의 전문가 시스템에 의존하고 있다고 밝혔습니다. 또한 아래 표에서 보듯이 이상 탐지는 머신러닝을 적용하기도 힘들고(unsupervised learning) FP(False Positive)와 FN(False Negative)에 따른 비용도 높습니다. 하지만 이러한 어려움에도 불구하고 우선 모니터링해야 할 로그의 수를 대폭 줄이는 데에 목표를 두고 다양한 머신러닝 알고리즘을 적용해 보기로 하였습니다.
모델 선정
우선 현재 로그 데이터의 레코드가 악성인지 아닌지 알 수 있는 방법도 없기 때문에 레이블링이 불가능한 상황이라 비지도 학습(unsupervised learning) 알고리즘을 사용하기로 하였습니다. 개별 로그 대상으로는 클러스터링(clustering) 알고리즘을 이용하고 전체 로그 데이터의 추세에 대해서는 시계열 예측(time-series prediction) 알고리즘을 사용하였습니다. 이번에 사용한 모델과 각각을 사용한 이유에 대해서 간단히 설명하겠습니다.
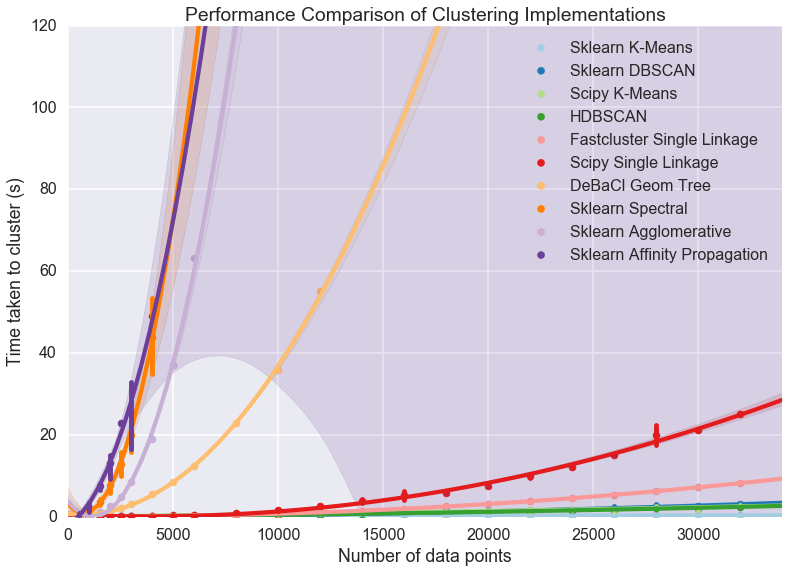
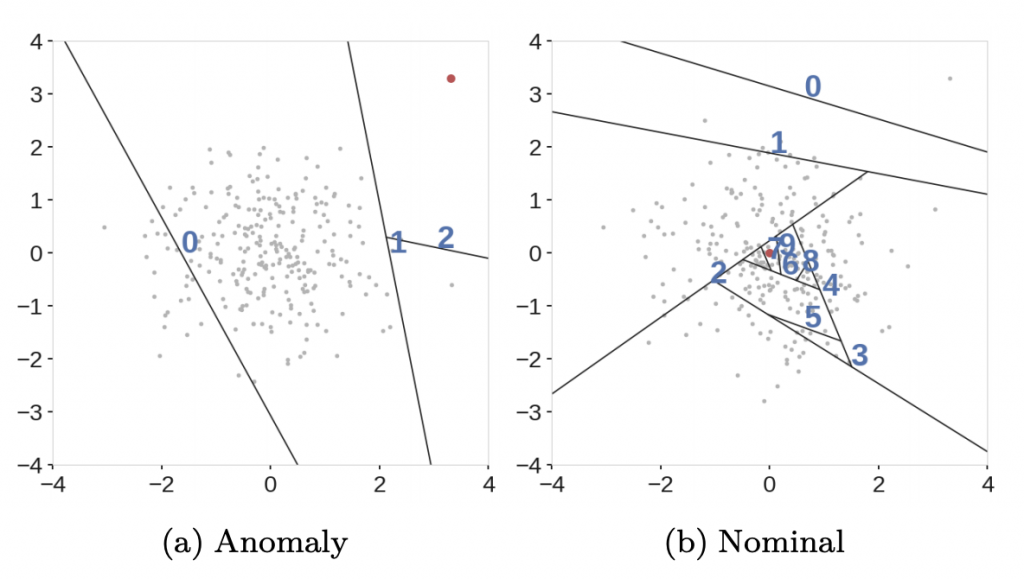
클러스터링 알고리즘의 경우 HDBSCAN2과 Extended isolation forest3를 결합하여 사용하기로 하였습니다. HDBSCAN은 DBSCAN 알고리즘과 같은 밀도(density) 기반 클러스터링인데요. 클러스터별로 다양한 밀도를 가질 수 있으며 Single-linkage 클러스터링을 이용하여 클러스터 간 위계(hierarchy)를 구성, 더 높은 유연성을 제공하고 있습니다. 접속 로그는 사용자별로 혹은 요일별로 다양한 빈도를 보여주게 됩니다. 따라서 업무 주기나 특정 조건에 따라 빈도가 집중될 수 있어 단순한 DBSCAN 알고리즘보다 HDBSCAN 알고리즘이 좀 더 정확한 결과를 보여줄 것이라고 생각했습니다. 또한 아래 그래프에서 볼 수 있듯이 머신러닝에서 가장 많이 사용되는 기존의 scikit-learn 라이브러리의 DBSCAN에 비해 훨씬 뛰어난 성능을 보여주기 때문에 향후 적용 대상을 확장할 때 확장성 측면에서 유리합니다.
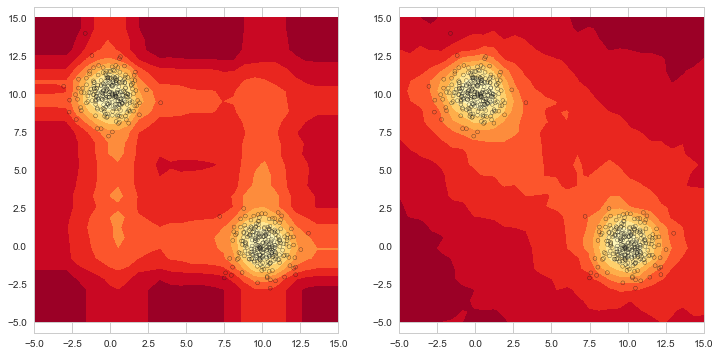
Extended isolation forest는 기존의 isolation forest 방법에서 발생하던 문제점을 해결한 알고리즘입니다. 기존의 isolation forest는 수직, 수평 방향으로만 자르기(slicing) 때문에 score map 그림에서와 같이 상관관계(correlation) 때문에 잘못된 scoring이 발생할 수 있습니다. Extended isolation forest는 기존의 방법과 다르게 랜덤한 방향으로 잘라서 이러한 문제를 해결하였습니다. 예제 로그 그래프에서 볼 수 있듯이 접속 로그의 특성상 흔히 격자 형태의 구조를 가지게 됩니다. 보통 개인 단위로 볼 때 개인별 업무 특성에 따라 반복적인 패턴이 지속되기 때문인데요. 이런 경우 기존의 isolation forest 알고리즘은 상관관계 때문에 정확도가 떨어지고 결과의 신뢰성이 낮아지게 됩니다. 단순화된 예를 들어보면, 월요일에는 1번 오피스만 사용하고 금요일에는 2번 오피스만 사용하던 계정이 갑자기 월요일에 2번 오피스를 통해 접속을 한다면 기존의 isolation forest의 경우 높은 score 때문에 지나칠 수 있게 됩니다. 따라서 랜덤한 방향으로 자르는 extended isolation forest 알고리즘이, 비록 연산량은 더 많지만 더 적합하다고 판단했습니다.
- 시계열 예측
위에서 언급한 클러스터링 알고리즘과 더불어 전체적인 시스템 접속 로그의 추세를 확인하기 위해 Facebook의 Prophet 라이브러리4를 사용하였습니다. 해당 라이브러리는 아래 수식과 같이 trend, seasonality, holidays로 구분되는 additive model을 사용한 시계열 예측을 제공하여 비선형(non-linear) 추세를 예측하는데 효과적이고 Stan 기반으로 개발되어 속도도 빠른 것으로 알려져 있습니다.
y(t) = g(t) + s(t) + h(t) + εt.
ARMA나 ARIMA와 같은 generative model은 시간 값에 종속적이지만, additive model은 좀 더 유연하여 새로운 컴포넌트를 쉽게 추가할 수 있어서 다양한 주기성을 포함하기에 좋습니다. 즉, 종속적인 값에서 얻을 수 있는 정보를 포기하는 대신 더 큰 유연성을 갖게 됩니다. 아무래도 업무 수행을 위한 접속에 대한 로그이다 보니 주기성(특히 주 단위의 주기성)을 가질 수 밖에 없고, 따라서 이런 시계열 예측을 적용하기에 적합하다고 생각했습니다. 또한 글로벌 오피스가 많은 LINE의 특성상 다양한 나라에서 접속하다 보니 공휴일이 다양하기 마련입니다. 이러한 부분도 해당 모델에서는 holidays part(h(t))로 표현이 가능하기 때문에 다른 시계열 모델에 비해 더 잘 모델링할 수 있을 것으로 예상했습니다.
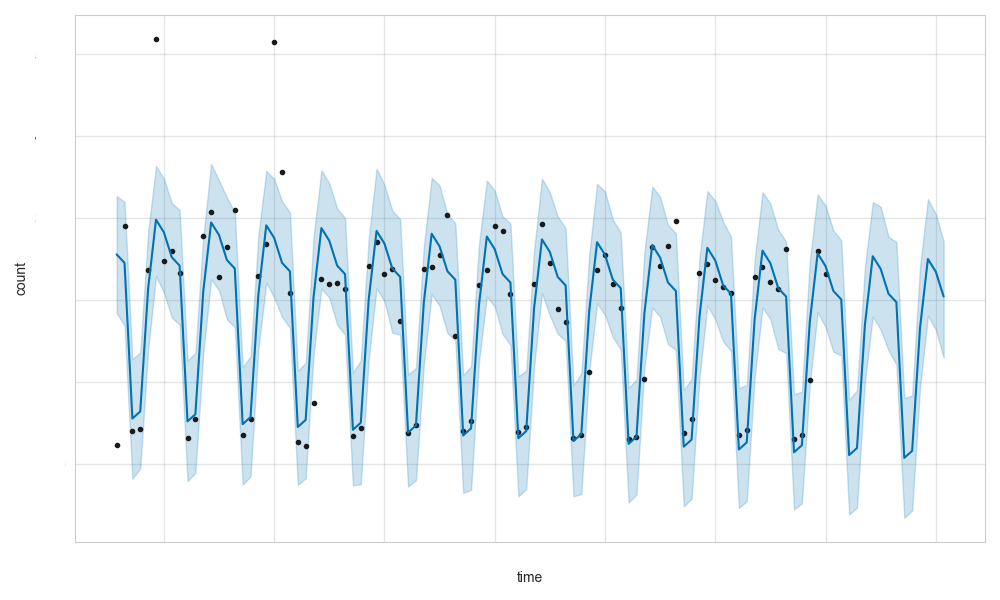
적용 결과
아래 그래프에서 볼 수 있듯이 해당 알고리즘을 적용하여 모니터링해야 할 로그의 양이 대폭 감소했습니다. 테스트 기간 동안 약 90.6%의 로그를 필터링하였습니다. 물론 여전히 상당 부분의 로그가 악성 로그이므로 좀 더 많은 개선이 필요할 것으로 보이는데요. 아쉽게도 이러한 이상 탐지 분야에서는 처음에 말씀드렸던 여러 이유 때문에 레이블링도 힘들고 FP/FN 분석도 현실적으로 매우 어렵습니다. 따라서 결과를 정확하게 평가하기는 어렵지만, 우선 1차 필터링으로는 활용할 수 있을 것이라고 생각합니다. 더불어 단순 로그 모니터링으로는 쉽게 눈에 띄지 않았던 거시적인 추세를 확인할 수 있게 된 것도 훌륭한 성과입니다.
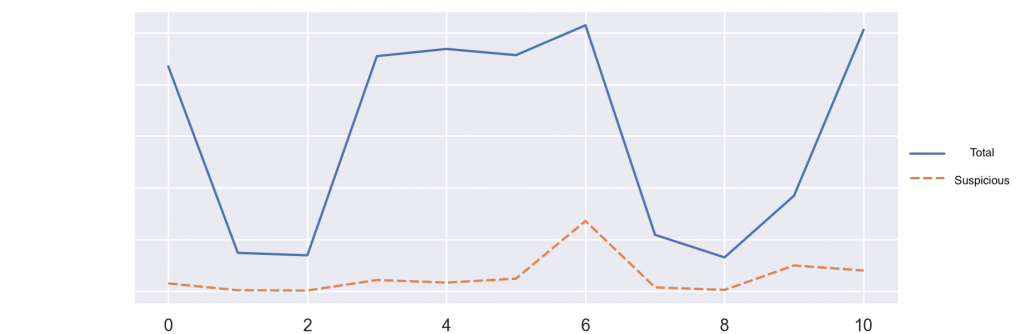
일단 로그의 양이 많이 줄었지만, 이제 막 시작한 단계이기 때문에 개선 가능한 부분이나 확장해야 할 부분이 많이 남아 있습니다. 개발하면 할수록 TODO 리스트가 늘어나는 것 같습니다. 요새 한창 주목받고 있는 딥 러닝 관련 알고리즘을 적용해 볼 수도 있을 것 같습니다(최근에는 로그가 시계열 데이터라는 데 착안하여 LSTM을 사용하거나 주기성 패턴을 이용하기 위해 CNN을 사용하려는 연구가 진행되고 있습니다). 또한 보안 문제로 본문에 적지는 못했지만 데이터 정규화(data normalization)와 feature set 구성은 머신러닝에서 가장 핵심적인 부분 중에 하나인데요. 앞으로 더 많은 feature set을 발굴하거나, 탐지 결과를 통해 하이퍼 파라미터(hyperparameter) 최적화하는 부분도 필요할 것 같습니다. 또한 다른 시스템의 로그에도 추가로 적용하기 위해 확장성을 높일 수 있는 방안도 고려해야 할 것입니다.
마지막으로 저희는 업무 성격상 공격자 입장에서도 많이 살펴보기 때문에 Adversarial machine learning도 고민하지 않을 수 없습니다. 아직 초기 단계이기 때문에 본격적인 방어 기법들을 추가하지는 못했지만, 여러 머신러닝 알고리즘을 복합적으로 연계해서 사용하는 이유도 'poisoning attack'과 같은 여러 공격 기법의 성공 확률을 낮추기 위해서입니다. 향후 이 부분에 대한 추가 연구도 진행하면 좋을 것 같습니다.
마치며
이번 글에서는 보안 모니터링을 위해 머신러닝 알고리즘을 사용하면서 진행하고 있는 내용에 대해 알아보았습니다. 아직 분석을 막 시작한 단계라 향후 더 많은 연구와 개발이 필요할 것으로 보이지만, 이번 Advent Calendar 이벤트가 내용을 공유하기 좋을 것 같아 현재 시점에서 글을 한번 작성해 보았습니다. 또한 이 자리를 빌려 LINE 인프라 보호를 위한 로깅 시스템을 구성하고 운영하고 있는 인프라 프로텍션 팀에도 감사드립니다. 평소에도 업무에 많은 도움을 받고 있는데요. 잘 구성된 로깅 시스템 덕분에 이러한 머신러닝 프로젝트도 진행할 수 있었습니다.
정보 보안은 거의 모든 영역에 걸쳐 있어서, 넓고 방대한 영역에 대한 심도 있는 이해와 전문성이 요구됩니다. 게다가 하루가 다르게 급변하는 IT 기술에 대한 대응도 필요합니다. 이를 위해 Graylab에서는 최고의 전문가들이 함께 모여 LINE의 다양한 서비스의 보안을 강화하기 위해 시너지를 만들어 내고 있으며, 더욱 다양해지고 있는 공격 벡터와 여러 기술에 효율적으로 대응하기 위해 많은 노력을 기울이고 있습니다. 앞으로도 다양한 기술적 시도와 함께 LINE의 보안을 강화하고 발전시켜 나가는 모습을 보여 드리겠습니다. 긴 글 읽어주셔서 감사합니다.
참고문헌
- https://web.stanford.edu/class/cs259d
- Campello, Ricardo JGB, Davoud Moulavi, and Jörg Sander. "Density-based clustering based on hierarchical density estimates." Pacific-Asia conference on knowledge discovery and data mining. Springer, Berlin, Heidelberg (2013).
- Hariri, Sahand, Matias Carrasco Kind, and Robert J. Brunner. "Extended Isolation Forest." arXiv preprint arXiv:1811.02141 (2018).
- Taylor, Sean J., and Benjamin Letham. "Forecasting at scale." The American Statistician 72.1 (2018): 37-45.