
들어가며
안녕하세요. Security R&D 팀에서 보안 연구 및 보안 컨설팅을 담당하고 있는 김도연입니다. 애플리케이션의 크기가 점점 커지고 다양해지면서 애플리케이션에 존재하는 버그도 많아지고 있습니다. 버그는 사용자들을 불편하게 하며 자칫하면 개인 정보 유출과 같은 큰 사고로 이어질 수도 있는데요. 이번 글에서 다룰 퍼징1(fuzzing) 또는 퍼즈 테스팅(fuzz testing)은 자동으로 버그를 찾는 소프트웨어 테스팅 기법 중 하나로 프로그램에 예상치 않은 데이터를 무작위로 입력해 본 후 프로그램 내에 버그가 있는지 확인하는 테스팅 기법[1]입니다. 보안 연구 분야에서 가장 인기 있는 주제 중 하나이며 Google[2, 3]이나 Microsoft[4, 5]와 같은 굴지의 기업에서도 관련 연구를 활발히 진행하고 있습니다. LINE Security R&D 팀 역시 LINE에서 제공하는 애플리케이션의 보안을 강화하기 위해 퍼징을 포함한 다양한 분야에 힘쓰고 있습니다[6, 7, 8, 9, 11]. 이번 글에서는 그중 하나인 REST API 퍼징을 소개하려고 합니다.
LINE에서 사용자에게 제공하는 서비스는 주로 웹 애플리케이션 형태입니다. 웹 애플리케이션은 REST API 형식으로 서버 요청 및 응답을 주고받는 경우가 많습니다. 이 과정에서 버그가 발생하는지 파악하기 위해 LINE의 많은 전문가들이 직접 살펴보고 있는데요. LINE이 지속적으로 성장함에 따라 제공하는 웹 서비스의 크기가 계속 커지면서 모든 요청 및 응답을 살피는 것이 상당히 힘든 작업이 되고 있습니다. 이에 저희 팀은 자동으로 웹 서비스에 예상치 않은 요청을 무작위로 보내서 부적절한 응답이 반환되는지 살펴보는 REST API 퍼저2(fuzzer)를 만들고 있습니다. 지금부터 저희가 개발하고 있는 REST API 퍼저를 간략하게 설명하겠습니다.
REST API 퍼징 과정 소개
기존 퍼징은 바이너리를 대상으로 하는 경우가 대부분이지만 REST API 퍼징은 이와는 사뭇 다릅니다. REST API는 무상태(stateless) 특성을 가지는 HTTP와는 다르게 상태(state)를 유지하면서 입력값으로 요청 시퀀스(sequence of requests)를 받습니다. 그래서 특정 요청에 도달하기 위해서는 이전 요청이 성공해야만 하는 경우가 많습니다. 일반적인 바이너리 퍼징은 코드 커버리지(code coverage) 정보를 중점적으로 활용하기 때문에 상태 정보를 크게 다루지 않습니다. 따라서 바이너리 퍼징 방법을 REST API 퍼징에 그대로 적용하는 것은 어렵습니다.
저희 팀이 REST API 퍼징을 제일 먼저 시도한 것은 아닙니다. 2019년 ICSE(International Conference on Software Engineering)에서 발표된 RESTler[5, 13]가 학계에서 처음으로 언급된 REST API 퍼저인데요. 이 논문에서 REST API 퍼징을 진행할 때 고려해야 하는 사항들을 전반적으로 다루긴 했지만, 특별한 기술 없이 아주 기본적인 방법만 제시했기 때문에 개선할 부분이 많았습니다.
REST API 퍼징 관련 용어
본격적으로 REST API 퍼징 과정을 말씀드리기 전에 간단히 용어를 정리하면 좋을 것 같습니다.
앞서 말씀드린 것처럼 REST API 퍼징의 입력값은 요청 시퀀스, 즉 순서가 있는 일련의 요청입니다. 테스트 케이스(test case) 또는 시드(seed)라고 부르기도 합니다. 멱등성3(idempotent)을 갖는 API들은 요청 시퀀스를 입력값으로 퍼징하는 것이 의미 없는 것처럼 보일 수 있습니다. 이를 고려해서 저희가 만든 퍼저는 요청 시퀀스를 전략적으로 퍼징하는 것뿐만 아니라 단일 API에 대해서도 여러 가지 뮤테이션(mutation) 방법을 적용해서 퍼징합니다.
다음으로 요청 타겟(target request)이란 시퀀스의 마지막 요청을 뜻합니다. 의미 있는 시퀀스(meaningful sequence)란 요청 타겟을 버그가 발생할 수 있는 상태로 만드는 요청 시퀀스를 의미합니다. 저희의 목표는 의미 있는 시퀀스를 가능한 많이 찾아내서 요청 타겟에 버그가 존재하는지 찾는 것입니다. 시드 풀(seed pool)은 퍼저 알고리즘에 의해서 선택된 의미 있는 시퀀스일 확률이 높은 요청 시퀀스들의 집합입니다. 퍼저는 해당 시드 풀에서 요청 시퀀스를 하나씩 꺼내서 다양한 방법의 퍼징을 시도합니다.
REST API 퍼징 과정
이제 REST API 퍼징 과정을 말씀드리겠습니다. 퍼징 과정은 크게 세 단계로 나눌 수 있습니다.
- OpenAPI 분석
- 시드 풀 초기화
- 퍼징
이제 각 단계를 자세히 살펴볼 텐데요. 만약 아래 설명이 이해하기 어렵다면 REST API 퍼징 과정 예제 섹션으로 건너 뛰어 예제와 함께 보시면 좀 더 수월하게 이해하실 수 있습니다.
OpenAPI 분석
퍼저는 가장 먼저 OpenAPI(구 Swagger)[15]를 분석합니다. OpenAPI의 역할 중 하나는 REST API를 문서화하는 것인데요. 저희 퍼저는 자동으로 이를 파싱하면서 서버 요청 시 사용될 값(consumed objects)과 서버 응답으로 반환된 값(produced objects)을 찾습니다. 요청 타겟 이전 API들의 응답으로 반환된 값들은 요청 타겟을 보낼 때 적절하게 사용해 서버 상태를 취약하게 바꿀 수 있기 때문에 의미 있는 시퀀스를 추론하는데 아주 유용한 정보가 될 수 있습니다.
시드 풀 초기화
앞서 본 퍼저는 시드 풀에서 요청 시퀀스를 하나씩 꺼내서 퍼징을 시도한다고 언급했는데요. 제일 처음 시드 풀은 어떻게 형성되는 걸까요? 저희 퍼저는 효율적인 퍼징을 하기 위해 OpenAPI를 분석해서 얻은 정보들을 십분 활용하여 시드 풀을 초기화합니다. 본 퍼저는 OenAPI에 기록된 모든 API가 요청 타겟이 될 수 있다고 가정합니다. 그 후 각 요청 타겟이 적절히 실행되기 위해 사용될 값들이 있는지 살펴봅니다. 만약 사용될 값이 없다면 선행 API 없이 독립적으로 호출해도 상관없기에 이를 시드 풀에 넣습니다. 반면에 사용될 값이 있다면 선행되면 좋을 API가 있을 수 있다는 뜻입니다. 그렇기에 OpenAPI를 분석해서 얻은 정보를 사용해서 선행되면 좋을 API들을 찾은 후에 요청 타겟 앞에 하나씩 붙입니다.
OpenAPI를 분석해 얻은 요청 시퀀스들은 시드 풀에 들어가기 전에 디폴트 값으로 세팅됩니다(숫자는 0, 문자열은 'TestString', 불리언은 False, ...). 디폴트 값으로 세팅된 요청 시퀀스가 실제로 의미 있는 시퀀스인지는 실행해 봐야 알 수 있습니다. 시드 풀을 초기화할 때 만들어진 요청 시퀀스들은 실행해 보면서 만든 것이 아니라 오직 API 문서에 의존해서 만든 것이기 때문입니다.
퍼징
본 퍼저는 시드 풀에서 요청 시퀀스를 차례대로 하나씩 꺼내서 퍼징을 시도합니다. 각 요청 시퀀스에 퍼징을 시도할 때 기본적으로 10번 퍼징하는데요. 5번은 상태를 고려해서 각 요청의 응답값을 전부 반영한 요청 시퀀스들을 실행하고, 나머지 5번은 시퀀스 뮤테이션을 포함한 랜덤 뮤테이션을 적용해서 실행합니다. 만약 해당 요청 시퀀스가 의미 있는 시퀀스라면 다시 시드 풀에 넣어서 계속 퍼징을 시도합니다. 그리고 버그가 발생하면 해당 버그가 발생한 경위를 기록합니다.
REST API 퍼징 비교 실험 및 결과
저희가 만든 퍼저의 성능을 평가하기 위해 앞서 언급했던 RESTler[5, 13]와 비교 실험을 진행했습니다. 실험을 위해 제작한 데모 서버를 소개하고 퍼저가 어떻게 동작하는지 간단하게 설명한 후 실험 결과를 말씀드리겠습니다.
데모 서버 소개
퍼징 성능을 평가하기 위해서 Flask[16]로 간단한 블로그 서비스를 제공하는 서버를 만들었습니다. 아래 [그림 1]은 게시글(post)과 관련된 API 정보를, [그림 2]는 답글(reply)과 관련된 API 정보를 요약한 대화형(interactive) API 문서를 캡처한 것입니다.
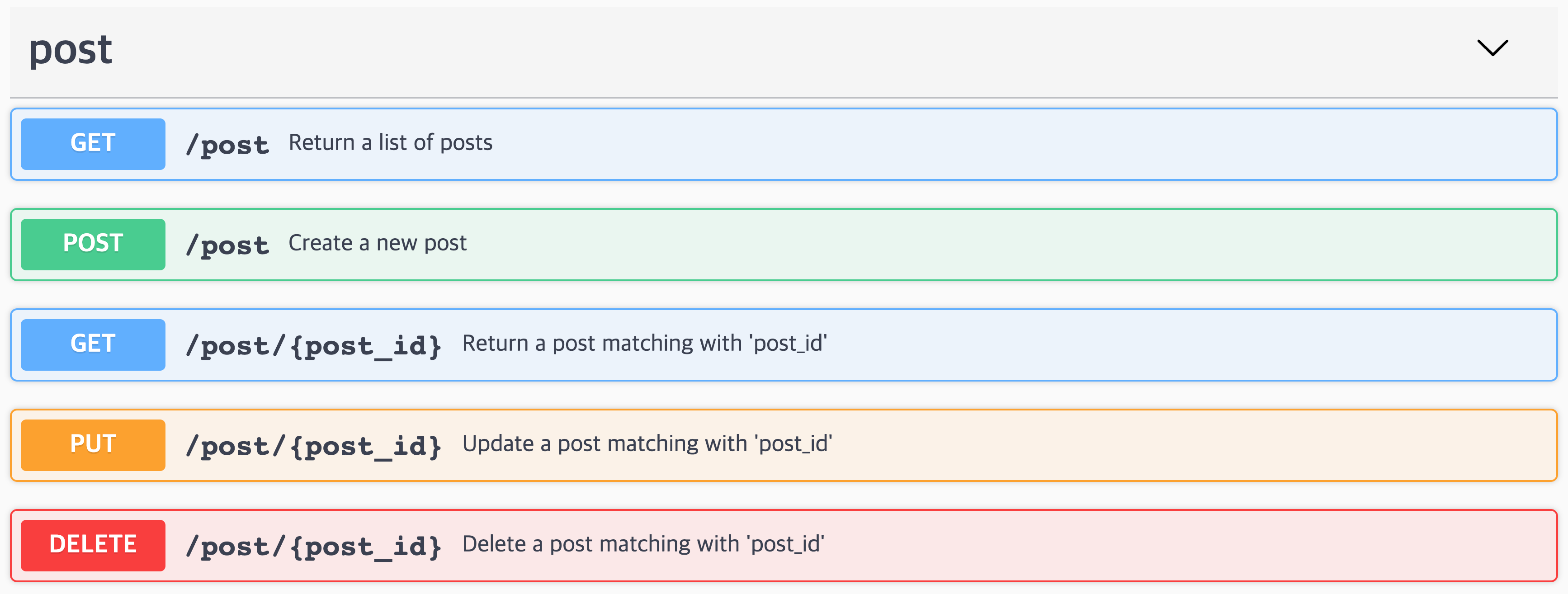
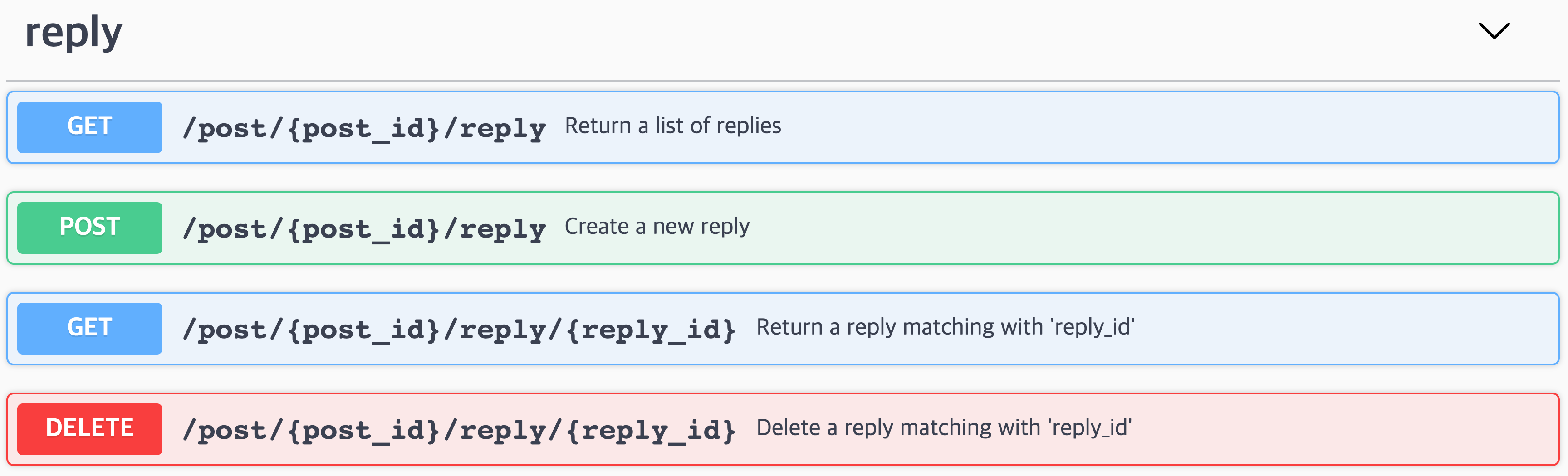
[그림 1]과 [그림 2]의 API가 각각 어떤 기능을 하는지 요약하면 다음과 같습니다. 여기서 각 메소드에 부여된 번호를 주목해주세요. 이 번호는 아래 [그림 3]에서도 사용됩니다.
POST /post: 게시글을 생성합니다.GET /post: 블로그에서 만든 게시글 목록을 반환합니다.GET /post/{post_id}:post_id를 가지고 있는 게시글을 반환합니다.DELETE /post/{post_id}:post_id를 가지고 있는 게시글을 삭제합니다.PUT /post/{post_id}:post_id를 가지고 있는 게시글을 수정합니다.GET /post/{post_id}/reply:post_id를 가지고 있는 게시글에 존재하는 답글 리스트를 반환합니다.POST /post/{post_id}/reply:post_id를 가지고 있는 게시글에 답글을 생성합니다.GET /post/{post_id}/reply/{reply_id}:post_id를 가지고 있는 게시글에 달려있는reply_id답글을 반환합니다.DELETE /post/{post_id}/reply/{reply_id}:post_id를 가지고 있는 게시글에 달려있는reply_id답글을 삭제합니다.
위와 같이 간단한 데모 서버를 제작한 뒤에 실험을 위해 인위적으로 DELETE /post/{post_id}/reply/{reply_id}를 실행할 때 실제로 존재하는 reply_id를 가지는 답글을 삭제할 때 내부 서버 오류(HTTP 코드: 500)가 발생하도록 만들었습니다.
API 관계 그래프
아래 [그림 3]은 각 API 간의 관계를 나타낸 그래프입니다.
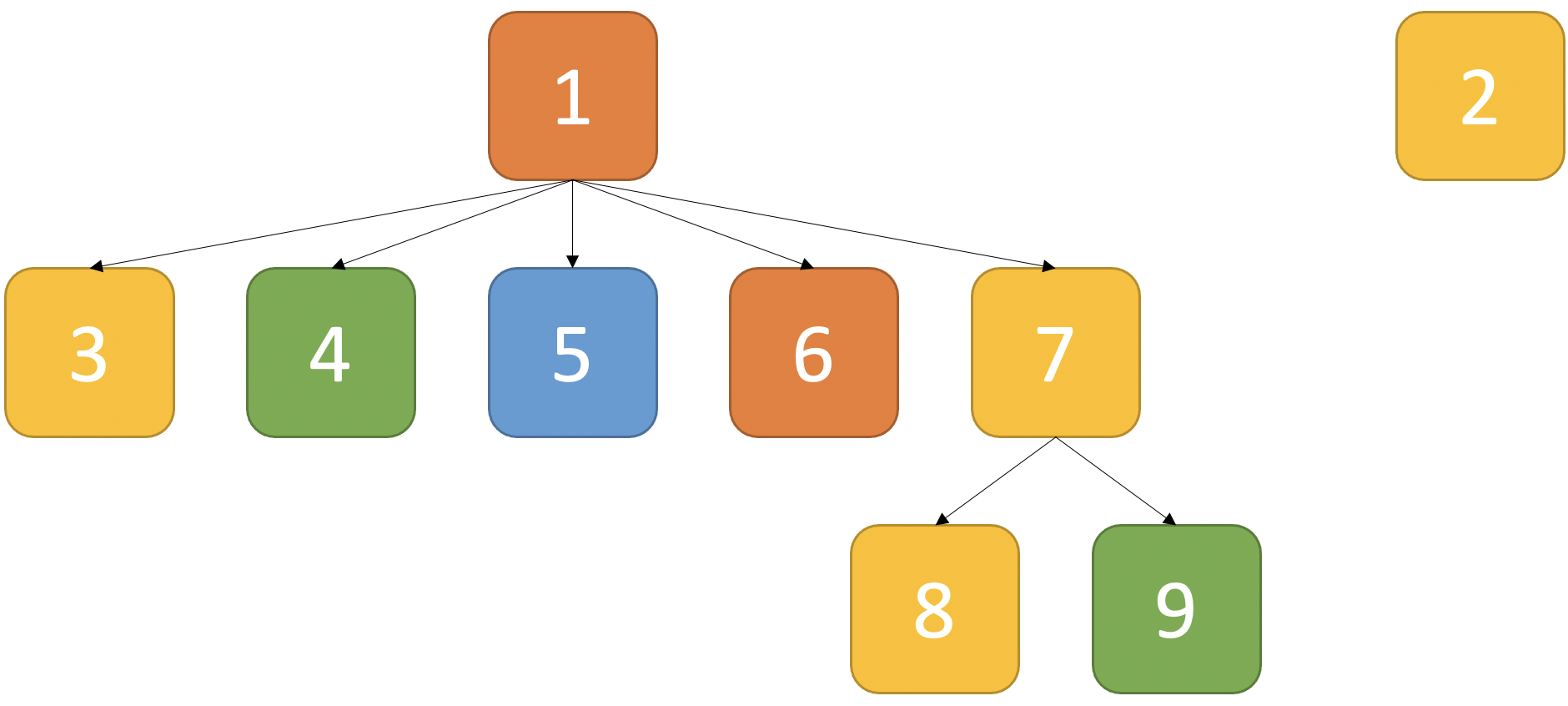
위 그래프에 대해서 간단하게 설명드리겠습니다. 1번 API(POST /post)는 유일하게 post_id를 반환하는 API입니다. 따라서 post_id가 필요한 모든 API(3, 4, 5, 6, 7, 8, 9)는 1번 API가 선행되어야 합니다. 저희가 인위적으로 심은 버그를 트리거하려면 반드시 1 → 7 → 9 순서로 API가 실행되어야 하며, 이때 모두 같은 post_id가 입력값으로 들어가야 합니다. 예를 들어 1번 API에서 post_id가 1인 게시글을 생성했다면, 7번 API에서 post_id가 1인 게시글에 답글을 생성해야 합니다. 생성된 답글은 9번 API를 이용해 삭제할 수 있습니다.
REST API 퍼징 과정 예제
OpenAPI 분석
먼저 OpenAPI를 분석해서 다음 정보를 얻을 수 있습니다.
post_id를 반환하는 1번 APIpost_id를 사용하는 3, 4, 5, 6, 7, 8, 9번 APIreply_id를 반환하는 7번 APIreply_id를 사용하는 9, 9번 API
시드 풀 초기화
본 퍼저는 위 정보를 이용해 시드 풀을 초기화합니다. 9번 API가 요청 타겟인 경우를 예로 들어보겠습니다. post_id와 reply_id가 있어야 한다는 것을 OpenAPI 분석으로 알 수 있습니다. 따라서 post_id와 reply_id를 반환하는 1번과 7번 API가 선행되어야 한다는 것을 알 수 있습니다. 그런데 7번 API는 post_id가 필요하기 때문에 1번 API가 선행되어야 하므로, 최종적으로 1 → 7 → 9 순서의 요청 시퀀스가 시드 풀에 들어오게 됩니다.
퍼징
퍼저는 1 → 7 → 9 순서인 요청 시퀀스를 퍼징합니다. 제일 먼저 1번 API를 서버에 보내면 post_id가 1인 블로그 포스트가 생성되어 응답으로 옵니다. 그다음 7번 API를 서버에 보낼 때 1번 API 응답에서 반환된 post_id의 값을 넣어서 서버에 요청합니다(POST /post/1/reply). 7번 API의 응답으로 온 reply_id가 1인 경우, 마지막 9번 API를 호출할 때 reply_id에 1을 넣어 서버에 요청합니다(DELETE /post/1/reply/1). 그리고 버그가 트리거되는지 확인합니다.
실험 결과
RESTler는 데모 서버에서 1시간 동안 5번 실험했을 때 버그를 찾지 못했습니다. 특히 [그림 3]과 같은 API 관계 그래프를 제대로 찾지 못했습니다. 반면 저희가 만든 퍼저는 동일하게 1시간 동안 5번 실험했을 때 10분 내에 버그를 찾았습니다. 시드 초기화 과정에서부터 이미 버그에 도달할 수 있는 요청 시퀀스가 적절하게 생성돼 버그에 아주 빨리 도달할 수 있었습니다.
마치며
간단한 실험을 통해서 RESTler와 저희가 만든 퍼저를 비교해 보았습니다. 앞으로 이 퍼저를 이용해 더욱 신속하고 정확하게 버그를 찾아내서 LINE 애플리케이션을 지속적으로 개선해 나갈 예정입니다. 이번 실험에서는 내부 서버 오류(HTTP 코드: 500)만 소개했는데요. 다양한 버그 오라클4을 추가하고 여러 가지 기법들을 추가하여 더 많은 버그를 찾을 수 있도록 개선할 것입니다. Security R&D 팀에서는 지속해서 다양한 보안 연구를 진행하고 있으며 추후 LINE Engineering 블로그를 통해 또 소개드릴 예정이니 많은 관심 부탁드립니다.
참고 문헌
[1] "The Art, Science, and Engineering of Fuzzing: A Survey," https://ieeexplore.ieee.org/document/8863940
[2] https://github.com/google/honggfuzz
[3] https://github.com/google/oss-fuzz
[4] https://github.com/microsoft/onefuzz
[5] https://github.com/microsoft/restler-fuzzer
[6] "LINE Encryption Overview," https://d.line-scdn.net/stf/linecorp/en/csr/line-encryption-whitepaper-ver2.1.pdf
[7] "Cross-platform Mobile Security at LINE," https://linedevday.linecorp.com/2020/en/sessions/8802
[8] "Cross-domain meta-learning for bug finding in the source codes with a small dataset," https://dl.acm.org/doi/abs/10.1145/3424954.3424957
[9] "FIDO," https://linedevday.linecorp.com/2021/en/sessions/37/
[10] https://github.com/line/line-fido2-server
[11] "SMARTIAN: Enhancing Smart Contract Fuzzing with Static and Dynamic Data-Flow Analyses," https://softsec.kaist.ac.kr/~jschoi/data/ase2021.pdf
[12] https://github.com/SoftSec-KAIST/Smartian
[13] "REST-ler: Stateful REST API Fuzzing," https://ieeexplore.ieee.org/document/8811961
[14] https://developer.mozilla.org/ko/docs/Glossary/Idempotent
[15] https://swagger.io/
[16] https://flask.palletsprojects.com/en/2.0.x/