
오픈챗이란
오픈챗(OpenChat)은 LINE 친구를 맺지 않고도 관심사가 비슷한 익명의 사용자들과 함께 대화를 나눌 수 있는 오픈 채팅방 서비스입니다. 각 채팅방에서 서로 다른 프로필을 사용할 수 있고, 내가 가입하기 전의 오픈챗 대화 내용도 볼 수 있는 것이 특징입니다. 오픈챗은 LINE Square라는 이름으로 2017년에 인도네시아, 2018년에 태국에서 먼저 서비스를 시작했고, 2019년 8월에 오픈챗으로 이름을 바꿔서 일본에서, 그리고 2020년 6월부터는 대만에서도 서비스하고 있습니다.
오픈챗 클린 스코어
다음으로 오픈챗 클린 스코어를 개발하게 된 배경과 개발 과정을 말씀드리겠습니다.
개발 배경
LINE 친구가 아닌 사용자들과 익명으로 대화할 수 있다는 점이 오픈챗의 특징인데요. 이런 특징은 장점인 동시에 단점이 될 수 있습니다. 욕설이나 광고, 성인 이미지 등의 부적절한 콘텐츠에 노출될 수 있고, 오프라인 만남 등을 목적으로 하는 오픈챗이 많이 생겨날 수도 있기 때문입니다. 특히 사용자들이 오픈 초기, 서비스의 성격이 완전히 자리 잡기 전에 이런 단점들에 많이 노출되는 것은 좋지 않습니다. 서비스에 대해 잘못된 인식을 심어줄 수 있는 것은 물론, LINE 메신저 서비스 전체에 대해 나쁜 인상을 줄 수도 있기 때문입니다. 이런 이유로 일본에서는 서비스를 오픈한 뒤 부적절한 오픈챗을 확실하게 걸러낼 수 있는 방법이 생기기 전까지 몇 달간, 서비스 홈에서 새로운 채팅 방을 탐색할 수 있는 검색과 같은 기능을 모두 제거하고 초대 링크를 통한 가입만 가능한 상태로 운영했습니다.
오픈챗 클린 스코어는 이런 배경에서, 서비스 메인 페이지에 노출해도 될 만한, 최대한 깨끗한 소수의 '화이트' 오픈챗을 찾아낼 목적으로 개발되었습니다.
서비스 요구 사항
서비스 요구 사항은 아래 두 가지였습니다.
- 개수가 많지 않더라도 확실히 클린한 오픈챗만 찾아낼 것
- 문제가 발생하면 준 실시간으로 필터링 가능할 것
오픈챗의 주제 자체가 문제인 경우는 이미 운영 팀에서 전수 검사를 통해 삭제하거나 비활성화 처리를 하고 있었습니다. 따라서 클린 스코어의 목표는 정상적인 오픈챗이지만 지금 당장 사용자가 불쾌한 경험을 할 가능성이 높은 오픈챗을 실시간으로 찾아서 노출에서 제외하고, 만약 문제를 일으킨 사용자가 채팅방을 나가거나, 관리자가 강제 퇴장시키거나, 문제가 되는 콘텐츠가 삭제될 경우엔 다시 사용자에게 노출 가능한 상태로 만드는 것이었습니다.
문제 정의
클린한 오픈챗은 다음과 같이 정의했습니다.
- 부적절한 콘텐츠가 발생하지 않음
- 나쁜 사용자가 활동하고 있지 않음
- 잘 관리되고 있거나 사용자 신고가 활발히 이뤄지는 곳
이와 같은 정의를 기반으로, 저희는 오픈챗에서 향후 n시간 동안 징계가 발생할 확률을 예측하는 모델을 개발하기로 방향을 정했습니다.
데이터 셋과 피처
먼저, 사용할 수 있는 데이터 중에서 위 조건을 판별하는 데 도움이 될 만한 피처(feature)들을 찾아보고 각 오픈챗의 특성과 오픈챗에 가입한 사용자들의 특성, 그리고 오픈챗 관리자의 특성을 피처로 사용해서 모델을 개발했습니다. 오픈챗의 특성으로는, 카테고리와 같은 오픈챗 자체에 대한 정보와 전체 가입자 수, 최근 신규 가입자 수, 최근 활동 중인 사용자 수 등 가입한 사용자 관련 피처를 다양하게 사용했습니다. 또한 오랫동안 꾸준히 잘 운영되고 있는 오픈챗과 지금 막 새로 생긴 오픈챗은 위험도가 다를 것으로 판단해서 오픈챗 생성 후 경과 일수도 포함했습니다. 오픈챗의 사용자에 대해서는 가입자들의 성과 연령의 추정 값과 과거 징계 내역을 기본으로 사용했고, 가입자들이 몇 개의 오픈챗을 가입하고 탈퇴했는지, 몇 개의 오픈챗에서 강퇴당했는지, 오픈챗 서비스를 얼마나 자주 사용하는지 등도 사용했습니다. 또한 계정 생성 후 경과 일수와 LINE 앱 설치 후 경과 일수 등 스패머를 찾는 데 도움이 되는 것으로 알려진 정보도 함께 사용했습니다. 좋은 관리자가 잘 관리하는 오픈챗은 클린할 것이라는 판단 아래, 관리자에 대한 신뢰도를 가늠할 수 있도록 관리자가 생성한 총 오픈챗 수와 그중 현재 삭제된 오픈챗 수, 관리자가 서비스 사용 중 징계를 받은 횟수 등의 정보를 추가했습니다.
이렇게 모은 수백 개의 피처를 기계 학습에 사용하기 위한 하나의 데이터 셋으로 만들기 위해서는 다양한 전처리 과정이 필요합니다. 예를 들어, 클린 스코어의 핵심 피처 중 하나인 징계 정보는 범주형(categorical) 자료로 언제든 새로운 징계 코드가 추가될 수 있습니다. 원-핫 인코딩(one-hot encoding) 등의 방식으로 처리하면 피처 길이가 달라져서 관리하기가 힘들어집니다. 그래서 저희는 징계 코드 값을 해싱(hashing)해서 해시 값을 피처 인덱스로 사용하도록 구현했습니다. 또한 해시 값이 충돌하는 것을 방지하기 위해 해시 차원은 10만 단위로 아주 크게 잡았고, 사용할 때는 실제로 값이 들어있는 인덱스만 사용하도록 만들었습니다. 수치형(numerical) 자료는 분포를 확인한 뒤 적합한 정규화(normalization)와 스케일링(scaling)을 활용하거나 전체 분포에 대한 백분위수(percentile)를 기반으로 데이터 비닝(binning)을 통해 다루기 쉬운 값으로 변환하는 등 각 데이터의 형태와 특성에 적합한 방식으로 전처리를 수행했습니다.
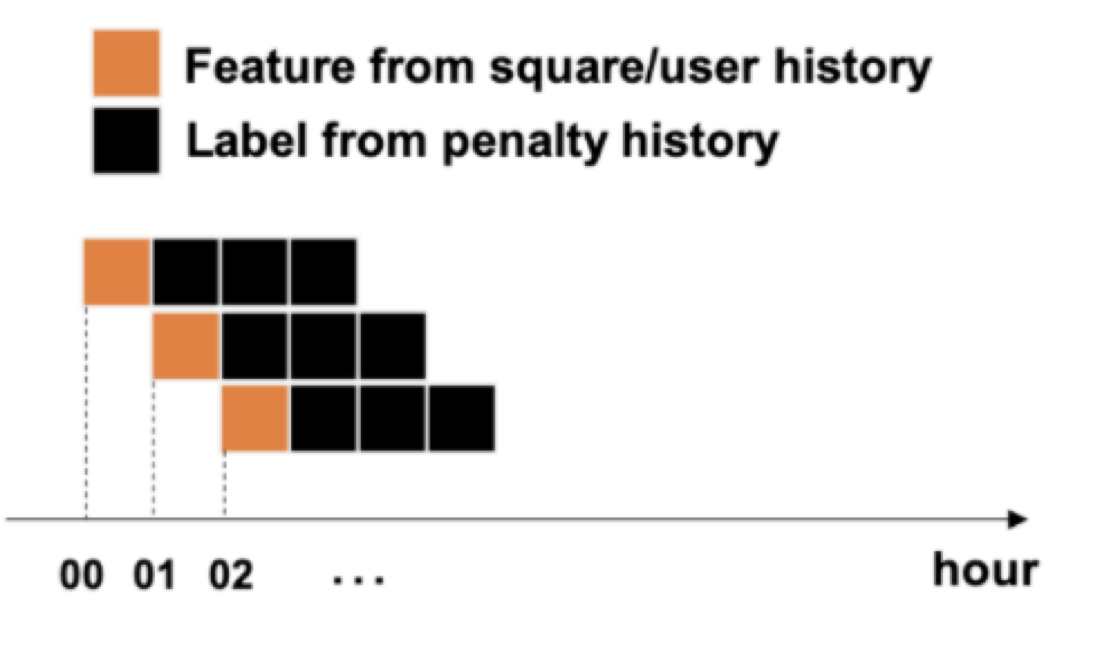
학습과 테스트 데이터 셋의 기간을 정할 때, 모델 개발 단계에서는 최근 한 시간 동안의 오픈챗 활동 내역을 사용해 향후 n 시간 이내에 오픈챗에서 징계가 발생했는지의 여부를 학습하도록 설정했는데요. 사용자의 활동이 줄어드는 새벽 시간대에는 데이터 셋이 너무 작아지는 문제가 발생해서 24시간 동안의 데이터로 학습하고 n 시간에 대해서 테스트하도록 수정했습니다.
학습 모델 선정
베이스 라인 모델로는 로지스틱 회귀(logistic regression)를 사용했고, 딥 러닝(deep learning) 모델과 그래디언트 부스팅(gradient boosting) 디시전 트리(decision tree) 모델들을 실험해 봤습니다.
딥 러닝 모델 중에서는 DNN(Deep Neural Network)과 Wide & Deep[1], Deep & Cross Network (DCN)[2], DCN with focal loss[3], 이렇게 네 가지를 테스트해 봤는데요. 전체 오픈챗 중 징계가 발생하는 오픈챗은 극소수여서 정답으로 사용할 블랙(black) 오픈챗이 아주 적었기 때문에 오버 피팅(overfitting)이 심했습니다. 샘플링 주기를 낮춰서 데이터 셋의 불균형(imbalanced) 문제를 해결하려고 했지만, 뒤에 설명할 그래디언트 부스팅 모델이 메모리를 훨씬 더 적게 차지하면서도 성능이 좋았기 때문에 결과적으로 딥 러닝 모델은 사용하지 않았습니다.
그래디언트 부스팅 모델은 CatBoost와 LightGBM[4], 두 가지를 실험해 봤습니다. 둘의 성능은 거의 비슷한 수준이었는데요. 사용한 피처들이 대부분 수치형이었기 때문에 범주형 피처에 최적화되어 있는 CatBoost보다는 LightGBM이 더 적합하다고 판단했습니다. 또한 결정적으로 LightGBM의 학습 시간이 더 짧아서, 거의 실시간으로 빠르게 학습되어야 한다는 조건에 잘 부합해 LightGBM을 최종 선택했습니다.
LightGBM은 이름처럼 가벼운 모델입니다. 속도도 빠르고 메모리도 적게 차지하면서 성능이 나쁘지 않은 것으로 유명합니다.
- 속도와 메모리 사용 최적화: 다른 디시전 트리 학습 알고리즘들은 미리 정렬하는 방식(pre-sort-based)을 주로 사용하지만, LightGBM은 연속적인(continuous) 피처들을 미리 여러 개의 분산(discrete) 버킷(bucket)으로 나누어 두는 히스토그램(histogram) 기반 알고리즘입니다. 그래서 학습 속도가 빠르고 메모리도 적게 사용할 수 있습니다.
- 정확도(accuracy) 최적화: 디시전 트리 모델, 예를 들어 기존의 XGBoost 같은 경우에는 각 레벨(depth)을 전부 채우면서 트리를 균형 있게 채워 나가는 'level-wise growth' 방식을 사용하지만, LightGBM은 균형을 상관하지 않고 손실(loss)값을 최대로 줄일 수 있는 리프(leaf)를 먼저 채워 넣는 'leaf-wise growth' 방식을 사용합니다. 리프의 개수가 같은 조건이라면, leaf-wise 방식이 level-wise 방식보다 손실 값이 낮게 나오는 경향이 있다고 합니다.
모델 성능 평가
모델 간의 성능을 비교하고 평가하기 위한 측정 기준(measure)으로는 '평균 Top-K 리콜(recall)'이라는 개념을 정의해 사용했습니다. Top-K 리콜이란, 모델로 예측한 징계 확률이 가장 높은 K 개를 블랙 오픈챗으로 분류했을 때, 실제 블랙 오픈챗 중 몇 개를 성공적으로 찾아낼지의 재현율 값입니다. 모델의 성능은 K 값을 어떻게 정하는지에 따라서 특정 모델이 다른 모델보다 성능이 더 좋을 수도 있고 나쁠 수도 있기 때문에, 여러 모델 간의 성능을 하나의 숫자로 비교하기 위해 K 값이 1,000일 때부터 2,000, 3,000, ..., 10,000일 때의 리콜 값을 평균 내서 사용했습니다. AUC(Area Under the ROC Curve) 값과 비슷한 개념이라고 볼 수 있습니다.
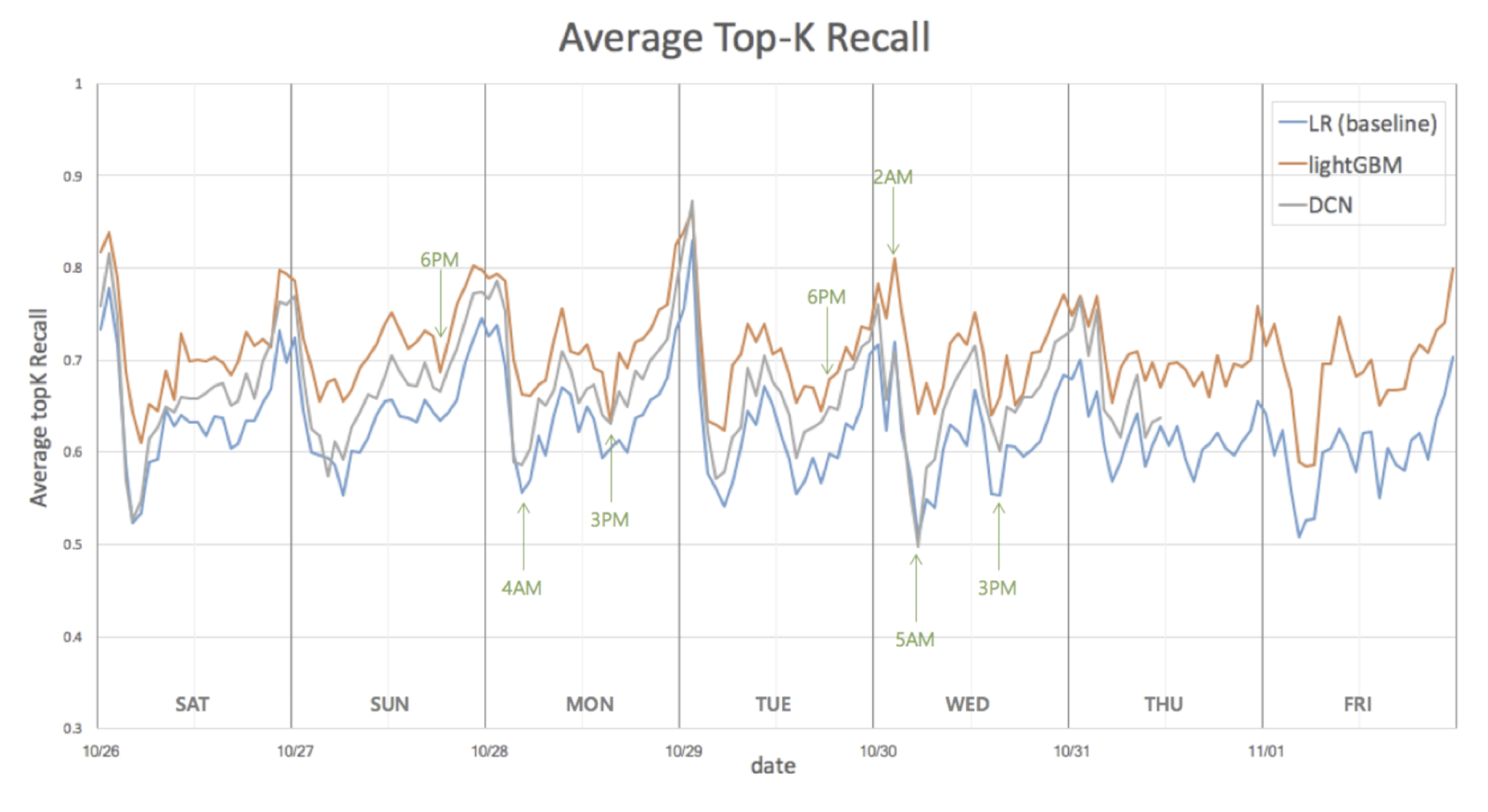
위 그래프는 딥 러닝 모델에서 가장 성능이 좋았던 DCN 모델과 최종 선택한 LightGBM 모델의 성능을 베이스 라인과 비교한 그래프입니다. 이 그래프를 보면 클린 스코어의 특징을 알 수 있는데요. 클린 스코어는 사용량이 적은 새벽 시간과 이른 오후에는 성능이 떨어지다가, 사용량이 많아지는 점심시간과 늦은 밤 시간에는 성능이 좋아집니다.
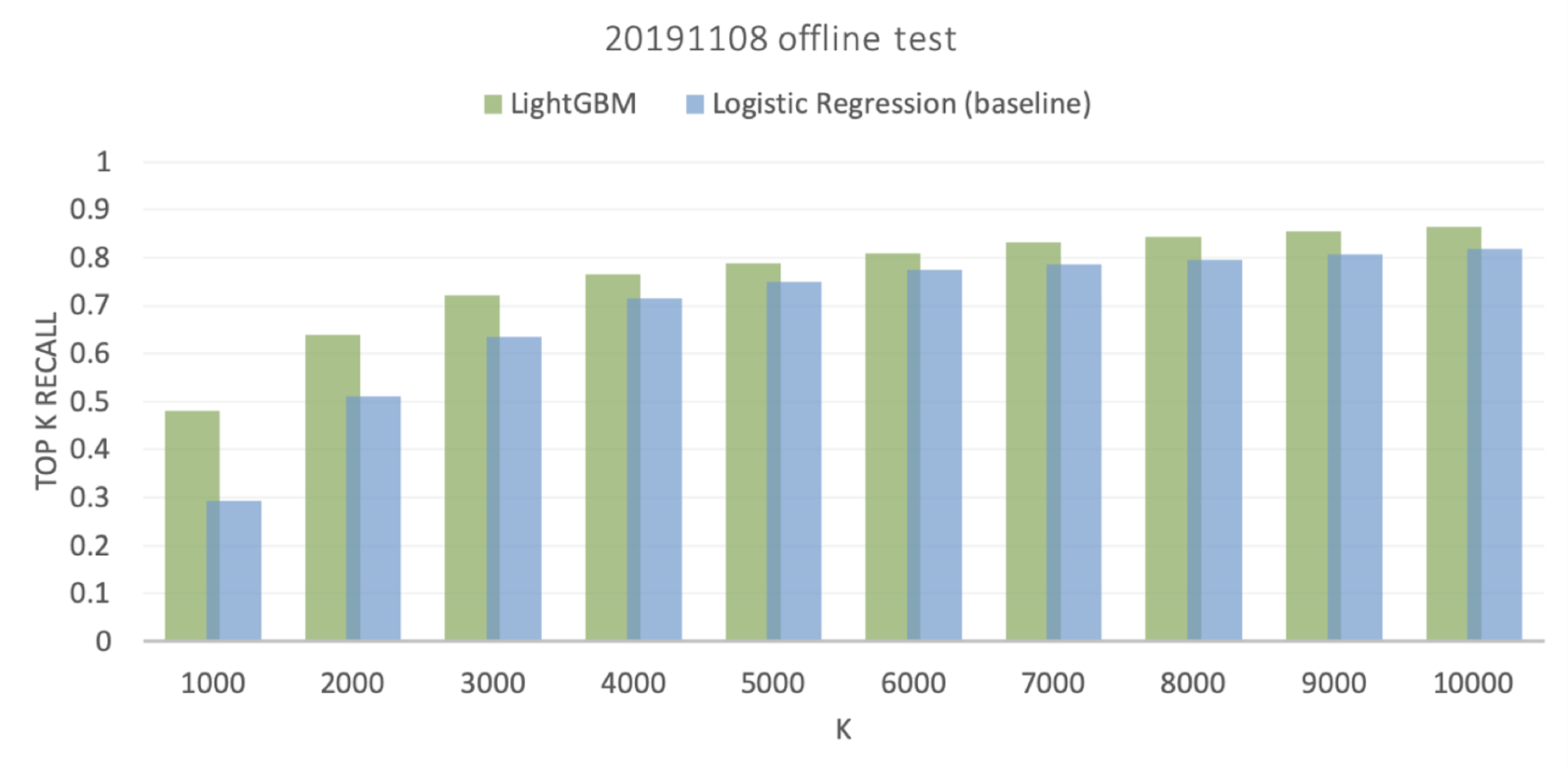
앞에서 설명한 평균 Top-K 리콜이 존재하는 모든 오픈챗에 대한 징계 예측 성능을 나타낸다면, 위 그래프는 징계가 발생할 오픈챗을 실제 서비스 노출에서 얼마나 잘 걸러낼지에 대한 성능을 보여주는 그래프입니다. 일주일 동안 오픈챗 사용자들의 검색 결과에 노출되었던 오픈챗 중 검색 시점 이후 n 시간 이내에 징계가 발생한 오픈챗을 얼마나 찾아냈는지를 노출 횟수로 가중치(weight)를 줘서 Top-K 리콜 값을 계산했습니다. 매 시간마다 징계 확률이 높은 상위 5,000개 정도의 오픈챗을 검색 결과에서 제외하면, 사용자 입장에서는 블랙 오픈챗의 80% 가까이가 제거된 효과가 있을 것입니다. K 값이 커질수록 베이스 라인 모델과의 차이가 줄어들고, K 값이 작을수록 LightGBM 모델의 성능이 월등히 뛰어난 것을 확인할 수 있습니다.
서비스 요구 사항 변경
모델 개발 후 성능 측정과 최적화까지 완료하고 서비스 팀에 최종 정성적 평가를 요청했는데 큰 문제가 발생했습니다. 서비스 오픈 직후에는 갑자기 많은 관심이 쏠리면서 리스크가 높아져 채팅방 탐색과 관련된 많은 기능을 제한할 수밖에 없었지만, 오픈 후 몇 달이 지나자 초기에 비해 사용자 수나 생산되는 콘텐츠 양이 줄어들었고, 운영 및 검수 인력도 많아져 모니터링 여력이 늘어났습니다. 또한 스팸이나 어뷰징을 모니터링하면서 자동으로 처리해 주는 도구에 상황에 맞는 다양한 규칙이 계속 추가되면서 문제 상황이 발생했을 때 바로 처리할 수 있게 되어, 사용자가 체감할 수 있는 문제 상황 자체도 많이 줄어들었습니다. 이렇게 리스크가 줄어들면서 롤 아웃(roll out) 방식으로 조심스럽게 검색 기능이 재활성화되었고, 이후 메인 페이지 역시 서비스가 재개되었습니다. 문제가 되는 오픈챗을 보여주지 않아야 한다는 기본 조건엔 변함이 없었지만, 필터링 없이도 이미 서비스가 큰 문제 없이 잘 돌아가는 상황이 되면서 조건이 바뀌게 된 것입니다.
처음 프로젝트를 시작할 때는 '리콜을 많이 희생해서라도 화이트 오픈챗에 대한 정확도가 높은 모델'이 필요했는데요. 개발 완료 시점에는 높은 정확성보다는 최대한 많은 오픈챗을 사용자들에게 보여줄 수 있는 모델이 필요하게 되었습니다. 현지 서비스 운영 팀에서 n 시간 이상 연속으로 징계 확률이 높게 예측되는 오픈챗 수십여 개를 정성적으로 평가해서 네 가지 그룹으로 나누어 표시해 주었는데요. 꼭 보여줘야 하는 오픈챗은 'must-show', 논란의 여지가 있지만 그레이(gray)로 분류할 수 있는 오픈챗은 'no problem', 명확한 그레이 오픈챗은 'so so', 마지막으로 확실히 문제가 있는 오픈챗은 'real-bad'로 분류했습니다. 그런데 위에서 설명드린 바와 같이 최대한 많은 오픈챗을 사용자들에게 보여주기 위한 목적에 따라, 다른 일반적인 오픈챗에 비해서 징계나 신고가 훨씬 더 많이 발생한 오픈챗임에도 운영 팀에서 'must-show'로 표시한 경우가 20% 가까이 되었습니다. 운영 팀에서 남긴 몇 가지 피드백을 살펴보면, '문제가 되는 행동이 발생하긴 했지만 이후 사용자들이 신고했거나 콘텐츠를 삭제했기 때문에 문제없는 오픈챗이다'라거나, '오프라인 만남을 유도하는 오픈챗만 아니면 신고가 아주 많더라도 사용자들에게 보여줘도 괜찮다'라는 의견이 있었습니다. 징계를 예측하는 모델을 만들었지만, 징계가 발생해도 주제 자체에 문제가 없으면서 인기가 많고 활동적인 오픈챗은 검색 노출에서 제외하면 안 되는 것입니다. 정석대로라면 새로운 문제에 맞게 정답 세트부터 새로 만들어 새로운 모델을 개발해야 했지만, 전수 검사 없이 징계가 있어도 노출을 허용해야 하는 오픈챗의 정답 세트를 확보하는 것은 어려운 상황이었습니다. 그래서 저희는 새로운 요구 사항에 최대한 맞출 수 있게 후처리를 하기로 결정했습니다.
후처리
후처리에 사용할 정답 세트는 운영 팀에서 표시해 준 라벨 중에서 'must-show'와 'real-bad', 이 두 그룹을 사용했습니다.
첫 번째로 시도한 것은 간단히 임곗값(threshold)을 조정하는 것이었습니다. must-show 오픈챗의 징계 확률 예측값이 real-bad 오픈챗보다 낮을 것이라는 가정에서 시도한 방법입니다. 실험 결과, 임곗값을 어느 쪽으로 움직이든 must-show와 real-bad가 비슷하게 줄거나 늘어나는 것을 확인했습니다.
두 번째는 ‘가석방 로직'이라고 이름 붙인 방법입니다. 어느 정도 이상의 기간 동안 블랙 오픈챗으로 분류되었지만, 해당 기간 동안 실제로 징계가 발생하지 않은 오픈챗은 ‘가석방’하여 화이트 오픈챗으로 바꿔주는 로직입니다. 이 방식 역시 여러 가지 파라미터를 바꿔가며 테스트해 봤지만 결과는 좋지 않았습니다.
세 번째는 점수 자체를 바꿔주는 방법입니다. 그중 '확률 교정(probability calibration)' 방식은, 클린 스코어를 만들 때 negative sampling을 사용했고 징계의 경중은 고려하지 않았기 때문에, 모델의 결과가 실제 분포와는 차이가 있을 수 있어서 오픈챗 가입자 수를 기반으로 수정한 실험입니다. 하지만 이 방식 역시 결과는 좋지 않았습니다.
최종 선택한 방법은 '조정 클린 스코어(adjusted clean score)'라고 이름 지었는데요. 오픈챗의 규모와 가입자 중 징계를 받은 적이 있는 사용자의 비율을 모두 고려한 방식입니다. 운영 팀에서 must-show로 표시한 오픈챗들을 살펴보니 모두 규모가 큰 오픈챗들이었습니다. 전체 오픈챗의 98.8%가 가입자 수가 50명 미만이었던 것에 비해 must-show 오픈챗들은 가입자가 100명에 이르거나 100명을 훨씬 넘기도 했습니다. 가입자가 많고 활동성이 높은 오픈챗은 아무래도 문제가 발생할 확률도 높기 때문에, 그중에서 징계를 받은 사용자의 비율이 낮은 오픈챗은 기준을 완화할 수 있는 후 보정을 시도했습니다.
조정 클린 스코어는 오리지널 클린 스코어에 '징계 받은 사용자 비율(penalized users ratio)' 값을 곱한 점수입니다. 징계 받은 사용자 비율은 전체 사용자 중에서 과거 n 일 동안 징계를 받은 사용자의 비율을 평활화(smoothing)해서 계산한 값입니다. 평활화 처리를 통해 규모가 큰 오픈챗일수록 징계 받은 사용자 비율의 영향을 적게 받아 결과적으로 더 좋은 점수를 받을 수 있도록 설계했습니다. 실험 결과, 아래와 같이 조정 클린 스코어를 사용하면 must-show와 real-bad를 비교적 잘 구분해 낼 수 있는 것을 확인했습니다.
| % filtered in search | % filtered in category | |||
|---|---|---|---|---|
| MUST-SHOW | REAL-BAD | MUST-SHOW | REAL-BAD | |
| As is | 100.00% | 100.00% | 100.00% | 100.00% |
| To be | 32.78% | 98.11% | 32.99% | 77.08% |
온라인 테스트
조정 클린 스코어를 실제 서비스에 적용, AB 테스트를 통해서 성능을 측정했습니다. 클린 스코어가 목적을 잘 달성했는지 확인할 수 있도록 섹션 별로 노출되는 오픈챗 중 블랙 오픈챗의 비율을 BRI(black rate by impression)라는 이름으로 정의해 사용했고, 위에서 설명한 징계 받은 사용자 비율을 BRI 값에 곱한 ABRI(adjusted BRI) 값도 사용했습니다. 또 상위에 노출된 오픈챗을 클린 스코어로 필터링한 결과가 서비스 메인 페이지의 클릭률과 가입률에 미치는 영향도 함께 지켜봤습니다.
BRI = # black impressions / # page view
ABRI = # adjusted black impressions / # page view
Adjusted black impression = 1 ×ws,
ws=(# of penalized users within N days+C)/(total joined users+2C)
with constant C.
| Section | BRI | ABRI |
| Category | -11.56% | -43.12% |
| Search result | -16.08% | -42.86% |
실험 결과 카테고리 지면에 노출된 블랙 오픈챗의 비율이 11.56% 줄어들었고, 검색 결과에 노출된 블랙 오픈챗의 비율은 16.08% 줄어들었습니다.
| CVR lift(=join/click) | CTR lift(click/PV) | CPI lift(join/PV) | |
| Category | -0.84% | -0.48% | -1.32% |
| Search | 0.53% (*) | -2.08% | -1.56% |
(*) statistically insignificant
메인 지표는 약 0.5~2% 정도 하락이 있었지만 이 정도는 수용 가능한 범위에 있다고 판단하여, 클린 스코어를 서비스에 적용하는 데에는 문제가 없음을 확인했습니다. 추가로 조정 클린 스코어가 아닌 오리지널 클린 스코어도 오프라인 시뮬레이션을 통해 같은 방식으로 효과를 측정해 봤는데요. 카테고리 지면에서 89.02%, 검색 지면에서 84.52%의 BRI 개선 효과가 있었습니다.
향후 계획
온라인 테스트까지 성공적으로 마치고 서비스에 적용했지만, 아직 개선의 여지가 많이 남아 있습니다.
페널티의 경중과 횟수를 반영
가장 먼저 개선하고 싶은 부분은 페널티의 종류와 횟수를 피처와 정답 세트에 반영하는 것입니다. 최근의 서비스 상황에 맞게, 보여줘도 되는 것은 최대한 보여주면서 꼭 숨겨야 할 것들만 숨기기 위해선 아무래도 후처리만으로는 한계가 있습니다. 기회가 된다면 페널티를 조금 더 세분화하여 모델 성능을 개선하고, 후처리했던 내용을 모델 자체에 녹여내고 싶은 욕심이 있습니다.
페널티와 상관없는 추천 적합성 점수
서비스가 안정화되고 LINE 앱 이곳저곳에 오픈챗을 노출하는 등 적극적으로 서비스를 확장하면서 클린 스코어와는 조금 다른, 새로운 점수가 필요하게 되었습니다. 바로 '오픈챗 추천 적합성 점수'입니다. ‘보여줘도 되는 것’과 ‘서비스 이름을 걸고 적극적으로 추천하고 싶은 것'에는 차이가 있습니다. 개인 맞춤형 추천이 아닌 이상, 특정 지역이나 특정 직업에만 한정되는 오픈챗보다는 많은 사람이 관심 가질 법한 오픈챗을 보여주는 것이 좋고, 특정 브랜드나 상품의 마케팅 혹은 이벤트를 위한 오픈챗을 굳이 홍보해 줄 필요도 없기 때문입니다. 이런 배경에서 오픈챗 주제 자동 분류나 오픈챗 품질 점수 모델 등의 다양한 아이디어가 나왔고, 기회가 된다면 이런 것들을 추가로 개발해 보고 싶습니다.
마치며
우여곡절이 많았던 프로젝트였지만 성공적으로 릴리스해 현재 일본 오픈챗에 적용, 서비스 중입니다. 이 자리에서 자세한 내용을 공개할 수는 없지만 앞으로 오픈챗의 다른 영역에서도 사용할 수 있도록 진행 중이고, 대만 등 다른 국가로 확장하는 것도 준비하고 있습니다. 앞으로 꾸준히 개선해서 오픈챗 서비스의 여러 지면에서 다양한 형태로 사용자 경험을 높이는 데 기여하기를 기대합니다.
참고 문헌
[1] Cheng, Heng-Tze, et al. "Wide & deep learning for recommender systems." Proceedings of the 1st workshop on deep learning for recommender systems. 2016.
[2] Wang, Ruoxi, et al. "Deep & cross network for ad click predictions." Proceedings of the ADKDD'17. 2017. 1-7.
[3] Lin, Tsung-Yi, et al. "Focal loss for dense object detection." Proceedings of the IEEE international conference on computer vision. 2017.
[4] https://github.com/microsoft/LightGBM/blob/master/docs/Features.rst