
안녕하세요. LINE에서 데이터 엔지니어로 일하고 있는 이명훈입니다. 빅데이터와 데이터 분석이라는 단어가 유행한 지도 꽤 오래 되었고, 이제 어떤 서비스든지 데이터 분석은 선택이 아닌 필수가 되었습니다. 모두 열심히 데이터를 수집하고 그 속에서 의미 있는 정보를 찾기 위해 노력합니다. 유의미한 정보를 찾기 위해서는 분석 환경이 필요한데요. 오늘은 LINE에서 게임의 분석 환경 구축과 관련하여 어떤 고민을 했는지 공유해 보고자 합니다.
LINE 게임의 분석 환경
분석 환경은 좁게는 Tableau와 엑셀, R과 같은 툴에서부터 넓게는 데이터 설계, 수집, 처리, 분석까지 모두 포함합니다. 이 글에서는 넓은 범위의 분석 환경에 대해 다룹니다. 분석 환경을 구축할 때는 구글이나 아마존처럼 상용화된 환경을 사용하는 경우도 있고, 오픈 소스를 사용해서 직접 구축하는 경우도 있습니다. 규모와 목적에 따라 조금씩 다르겠지만 보통 Hadoop ecosystem, NoSQL, Kafka, Elastic, R 등을 이용해 구축합니다.
다음 그림은 LINE의 분석 환경을 간단하게 표현한 것입니다.

LINE 게임도 오픈 소스를 사용해 분석 환경을 구축했습니다. SDK에서 전송한 데이터를 콜렉터로 수집해서 Log 파이프라인을 거쳐 Hadoop 클러스터에 저장한 후, Hive와 Impala를 통해 데이터를 추출하고 R, Tableau, 자체 BI(Business intelligence) 도구를 사용해 지표와 분석 서비스를 제공하고 있습니다. LINE 게임 분석 환경의 차별점을 7가지 키워드로 정리하여 차근차근 설명해 보겠습니다.
Catalog
첫 번째 키워드는 데이터에 대한 카탈로그입니다. 카탈로그라는 용어가 낯설게 느껴지신다면 데이터 명세서나 설계서라고 이해하셔도 좋습니다. 데이터 카탈로그가 분석 환경과 무슨 관계인지 궁금하실 수도 있겠지만, 넓은 범위로 봤을 때 데이터를 분석하기 위해서는 먼저 데이터를 수집해야 하고, 이를 위해서는 데이터를 정의하는 설계 작업부터 필요합니다. LINE 게임의 분석 환경에서 데이터 카탈로그는 2가지 내용을 담고 있습니다.
- Log Design: 어떤 데이터를 어느 시점에 전송하는가
- DW(Data warehouse) Design: 수집된 데이터가 어떤 형태로 가공, 저장되는가
데이터 카탈로그는 데이터 로깅부터 수집, 처리, 저장, 지표 제공 등 모든 곳에 참조되는 매우 중요한 정보입니다. 하지만 게임에서는 사실 핵심 기능이 아니라 상대적으로 소홀하게 관리되는 편이고, 데이터를 어떻게 남겨야하는지에 대해서만 가이드되는 편입니다. LINE 게임에서는 모든 데이터 카탈로그를 분석 팀에서 직접 관리하고 있습니다. 수집, 저장 환경만 제공하는 것이 아닌 분석 서비스도 함께 제공하기 때문인데요. 데이터 카탈로그는 템플릿으로 만들어서 크게는 서비스별로, 작게는 데이터 종류별로 관리합니다. 예를 들어 게임에서 재화의 획득과 사용에 대한 재화 템플릿을 만들고, 이를 게임별로 재화 종류와 변동 사유를 커스터마이징해서 사용합니다. 템플릿을 사용하면 모든 게임에서 동일 컬럼에 동일한 의미의 데이터가 남겨지므로 데이터를 적재하는 과정과 통합 분석하는 데 큰 장점이 있습니다.
Quality
두 번째 키워드는 데이터의 품질입니다. 데이터의 품질을 유지하는 것이 중요하다는 이야기를 많이 들으셨을 텐데요. 이상치가 섞인 데이터가 집계에 포함되면 엉뚱한 결과를 얻게 되고, 그 원인을 찾기도 쉽지 않습니다. 그러면 데이터의 품질을 언제, 누가 체크해야 할까요?
When?
'언제'에 대한 답은 비교적 쉽게 찾을 수 있습니다. 분석 시점에서 매번 품질이 낮은 데이터를 걸러내는 작업을 진행하는 것은 번거롭고 쉽지 않습니다. 따라서 당연히 데이터를 수집하는 시점, 더 나아가서는 데이터를 남기는 시점인 개발 단계에서 정확한 데이터가 수집되어야 합니다.
Who?
그러면 데이터는 '누가' 확인하는 것이 좋을까요? 앞서 개발 시점의 데이터를 남겨야 한다고 했기 때문에, 데이터 카탈로그를 기반으로 데이터를 남기는 일은 개발자의 손에 달렸다고 생각합니다. 사실 개발 과정과 QA 과정에서 이를 확인하기란 현실적으로 어렵습니다. 개발자와 게임 QA는 담당 업무를 처리하는 데에도 바쁘고, 게임 QA를 진행하는 과정에서는 이 데이터가 맞는지 틀리는지에 대한 배경 지식이 부족할 수 있습니다.
그래서 LINE 게임에서는 데이터 품질을 검수하는 데이터 퀄리티 매니지먼트 조직을 운영하여 데이터 QA를 진행합니다.

LINE 게임의 데이터 QA 담당자는 개발 과정부터 함께 참여합니다. 그렇기 때문에 데이터의 변경 이력을 파악할 수 있는 장점이 있습니다. 또한 실제 게임 QA 기간에는 게임 QA 담당자와 협업하며 데이터를 검증합니다. 게임 오픈 후에는 지속적으로 데이터를 모니터링하며 잘못된 데이터가 들어오는 경우를 체크해서 이슈로 등록합니다. 만약 콘텐츠 업데이트로 새로운 데이터가 추가된다면 오픈 때와 동일한 프로세스를 진행합니다. 이렇게 지속적으로 데이터 품질을 관리함으로써 신뢰할 수 있는 분석 결과를 만들어냈습니다.
데이터 QA 효율화를 위해 SDK에서 자동으로 생성된 기본 로그는 데이터 QA 시스템이 자동으로 검증하고 리포트합니다. 게임별 커스텀 데이터는 데이터 QA팀에서 관리하는 약 1,000개의 테스트 케이스를 사용해 체계적으로 관리합니다. 추후에는 데이터 QA 시스템과 연계하여 사용자 커스텀 데이터 QA까지 자동화하는 것이 목표입니다.
Open
세 번째 키워드는 데이터의 공개(open), 한 발 더 나아가서 데이터 분석 환경의 공개입니다. LINE 게임은 퍼블리셔이므로 내부 사업팀과 외부 개발사에 분석 데이터를 제공합니다. 이때 단순히 요청받은 데이터만을 전달하는 것이 아닌, 외부에서도 직접 데이터를 핸들링해서 분석할 수 있는 환경 자체를 공개하고 있습니다. 분석 환경을 공개하기 위해서는 데이터를 저장할 공개용 클러스터가 필요한데, 이를 구축하면서 발생했던 이슈와 해결 방법에 대해 이야기해 보겠습니다.
분석 환경을 공개하기 전에는 콜렉터에서 수집한 데이터를 Fluentd를 거쳐 지표 서비스와 내부 분석용으로 사용하는 100대 이상의 클러스터에 저장했습니다. 이 클러스터를 외부 개발사에 분석 환경 용도로 그대로 제공할 수는 없었습니다. 보안 문제도 있었고, 무엇보다도 데이터가 게임별로 분할되어 저장된 것이 아닌 로그별로 구분되어 저장된 상황이었기 때문입니다. 따라서 기존 클러스터의 절반 규모로 게임별로 데이터가 저장되는 클러스트를 하나 더 만들기로 결정했습니다. 이 때 두 가지 이슈가 있었습니다.
- 게임별로 데이터를 분할하는 작업을 어디서 할 것인가?
- 데이터에 포함된 개인 정보 이슈를 어떻게 해결할 것인가?
이 과정에서 LINE 게임은 오픈 소스인 Fluentd를 사용했는데요. Fluentd는 인풋에서 데이터를 받아 가공 처리를 하고 아웃풋으로 전송하는 데이터 파이프라인입니다. Elastic의 Logstash와 비슷합니다.
게임별로 분할하여 데이터 저장하기
첫 번째 이슈를 해결하기 위해 Fluentd에서 직접 게임별로 데이터를 분할하여 새로운 공개 클러스터로 전송했는데 또 다른 문제가 발생했습니다. 바로 Fluentd의 전송 지연 현상이었습니다. 원인은 Fluentd의 설정 문제였습니다. 새로운 공개 클러스터의 전송 주기를 기존 클러스터와 동일하게 10초로 설정했는데, 공개 클러스터는 100개 이상의 게임별로 버퍼를 관리해야 했기 때문에 데이터별 아웃풋의 스레드 수가 문제가 되었습니다. 이것도 심지어 1개의 데이터에 대한 이야기이고 데이터 종류별로 생각하면 10초 안에 수백 개의 스레드를 처리하지 못하기 때문에 지연이 발생하는 것이었습니다.
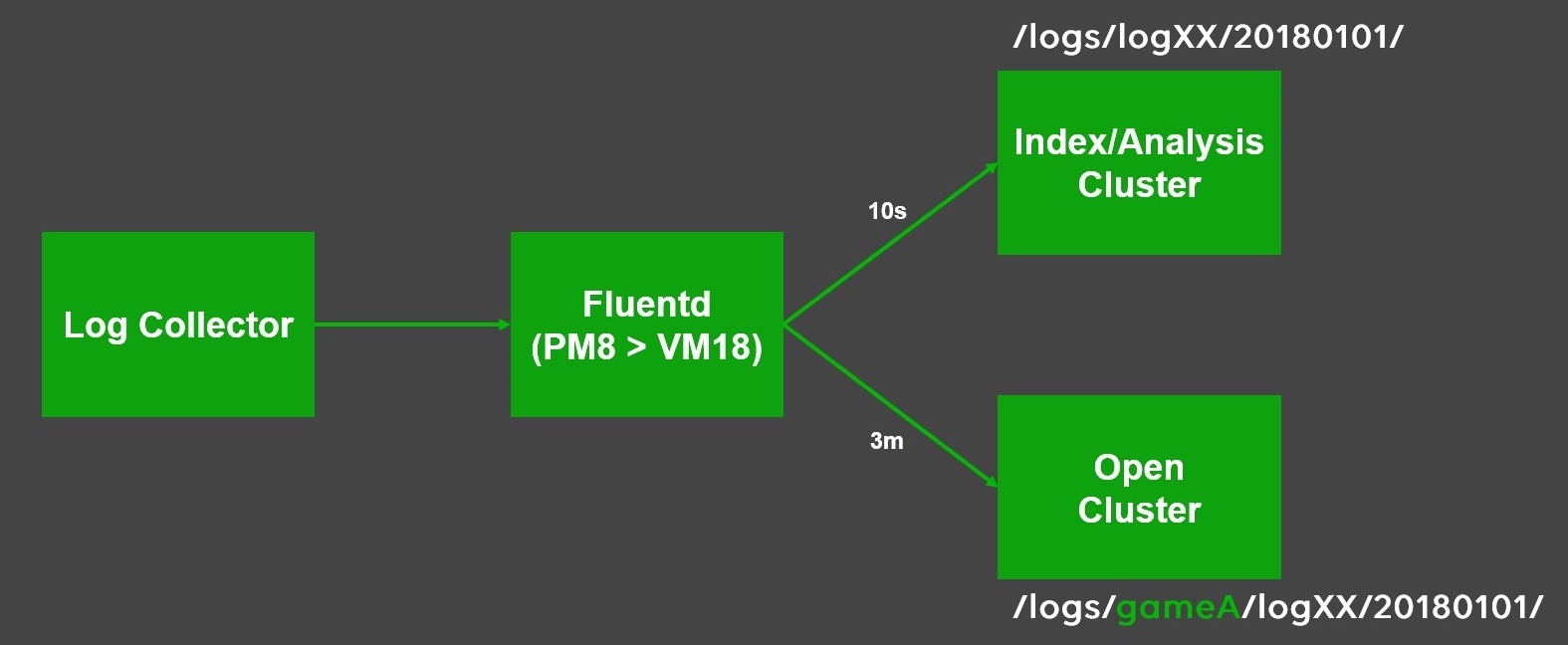
이 문제를 해결하기 위해 두 가지 방법을 적용했습니다. 첫째, 안정성을 위해 동시 전송 스레드 수를 줄이고 전송 주기를 늘리는 방향으로 튜닝을 진행했습니다. 최종 튜닝된 시간은 3분 주기였으며 공개 클러스터를 실시간으로 사용하는 경우는 없었기 때문에 여유로워 졌습니다. 둘째, Fluentd 서버를 물리 머신 8대에서 가상 머신 18대로 변경하여 스펙은 조금 낮추고 병렬성을 높였습니다. 이렇게 두 클러스터 모두 안정적으로 데이터를 전송할 수 있게 되었습니다.
개인정보 이슈 해결하기
공개 클러스터에 저장되는 데이터 중 ID는 개인 정보 이슈로 직접 제공이 불가능하지만, 데이터 분석에는 꼭 필요한 정보이므로 제외할 수는 없었습니다. 따라서 ID 정보를 암호화해야 했는데요. Fluentd에서 암호화 로직을 추가하려면 플러그인을 추가로 개발하는 공수가 들었고, 클러스터에 이미 저장된 데이터를 다시 읽어 암호화하는 것은 비효율적이라 판단했습니다. 결국 로그 콜렉터 수집 시점에 암호화를 진행하게 되었습니다. 암호화된 ID는 기존 클러스터에는 불필요한 데이터이므로 Fluentd의 설정을 통해 공개 클러스터로만 전송되도록 설정했습니다.
Deep
네 번째 키워드는 원천 데이터를 분석에 직접 사용할 수 있다는 의미의 Deep입니다. LINE 게임의 분석 환경에서는 SQL을 사용하여 게임 오픈 1년 이내부터 3분 전까지의 원천 데이터를 조회할 수 있도록 지원합니다. 조회 서비스에 SQL을 사용한 이유는 기획부터 분석가, 개발자까지 모두 접근 가능한 진입 장벽이 낮은 언어라고 생각했기 때문입니다. 또한 Hadoop에 데이터가 저장되다보니 훌륭한 SQL on Hadoop 기술인 Hive와 Impala를 사용할 수 있었습니다. 사실 Cloudera package에는 이미 Hive와 Impala를 지원하는 Apache Hue라는 서비스가 있었지만 LINE 게임에서는 이를 사용하지 않고 별도의 공개용 웹 서비스를 구축했는데요. Hue를 사용하지 않은 이유는 두 가지가 있었는데요. 첫째, 제공 범위를 넘어서는 불필요한 기능이 많았고 둘째, Hue는 LDAP(Lightweight Directory Access Protocol) 인증을 지원하는데 이를 사용하면 계정 관리에 들어가는 운영 리소스가 크다고 생각했기 때문입니다.
다음은 공개용 웹 서비스의 초기 버전 화면입니다. 간단하게 DB, 테이블을 선택해서 스키마 확인이 가능하고, 쿼리창에 Hive 쿼리를 입력하여 실행하면 결과를 확인할 수 있었습니다. CSV로 내려 받을 수 있는 기능까지 제공했습니다.

하지만 여기에서도 4가지 이슈가 남아 있었습니다.
Security
공개 클러스터에는 게임별로 데이터가 저장되어 있기 때문에, 타 개발사의 데이터가 보이지 않도록 데이터를 격리해야 했습니다. 뒤에서 Security 키워드를 다룰 때 함께 설명하겠습니다.
Resource
개발사별로 Hive 쿼리를 안정적으로 수행할 수 있도록 리소스를 관리하는 이슈인데요. 클러스터가 보유한 리소스를 단일 풀로 사용하면 특정 개발사에서 발생시킨 다수의 작업이 풀의 리소스를 모두 점유해버릴 수도 있습니다. 공개 분석 환경이므로 여러 개발사의 사용자가 공평하게 리소스를 사용할 수 있도록 개발사별로 리소스 풀을 분리하는 방법을 사용했습니다.

LINE 게임에서 새로 구축한 공개 분석용 웹 서비스는 외부에 서비스하는 지표 서비스와 동일한 인증 서비스를 사용하고 있었는데요. 이 인증 서비스로부터 사용자의 회사 코드를 확인할 수 있었고 쿼리 실행 시 Pool Name에 회사 코드를 지정하는 방식으로 리소스 풀을 분리했습니다. 다만 분석 서비스를 사용하는 회사가 늘어날수록 한정적인 풀이 잘게 나누어지기 때문에 열심히 사용하는 회사는 리소스가 부족하고 잘 사용하지 않는 회사의 풀은 낭비되는 문제점도 있습니다. 이 부분은 동적으로 풀을 관리할 수 있도록 개선해 보고자 합니다.
Not only SELECT but also CREATE
쿼리를 이용해 본 분이라면 아시겠지만 복잡한 쿼리를 작성할 때 중간 결과를 테이블로 생성해서 사용하면 효율적으로 작업할 수 있습니다. 초기의 공개 분석용 웹 서비스에서는 View에 대한 SELECT 권한만 허용하다 보니 중간 결과를 만들어 내는 쿼리를 내부에 포함하게 되어 무거운 쿼리를 반복 수행하는 문제가 있었습니다. 이는 사용자별 private DB를 제공해 주는 방법으로 해결했습니다. 사용자는 View를 통한 SELECT 결과를 private DB에 테이블로 생성하고 이를 재사용할 수 있습니다. 또한 사용하지 않는 데이터가 적재되지 않도록 테이블의 보관 기간은 30일로 정했습니다.
Slow, Too Slow
Hive 쿼리의 수행 속도가 느린 이유는 사실 Hive의 구조적인 문제가 가장 큰 원인입니다. 그래서 Impala를 추가 지원하는 것으로 어느 정도 속도를 개선할 수 있었습니다.
Security
다섯 번째 키워드는 Security인데요. 클러스터의 보안과 게임별 데이터 격리에 대해 설명하겠습니다. LINE 게임의 공개 분석 환경에는 Kerberos, LDAP, 그리고 Apache Sentry가 적용되어 있습니다. 예를 들면 A라는 사용자가 Hive 쿼리를 수행할 때 자신의 Kerberos 계정으로 인증하고, 인증이 완료되면 연동된 LDAP 계정으로 자신을 식별 후 쿼리를 실행하게 됩니다. Impala와 Hive의 DB, 테이블 권한을 제어하기 위해서는 인가 서비스가 필요한데 이 역할을 해주는 것이 바로 Sentry입니다.
Sentry는 롤과 그룹을 기반으로 오브젝트의 권한을 관리하는 서비스로 LDAP 그룹과 연동됩니다. 동작 원리를 간단히 설명하자면, Sentry는 Hive와 Impala에 플러그인 형태로 지원되며 쿼리 실행 전에 플러그인이 동작하여 쿼리를 실행한 사용자의 LDAP 그룹이 쿼리 내 오브젝트에 접근할 수 있는 권한이 있는지 검증합니다. 이를 서비스에 실제 적용하면 다음 그림과 같은 관계도를 그릴 수 있습니다.

복잡하게 느껴질 수 있겠지만 실제 공개 분석 환경의 Admin에서 클릭 몇 번으로 자동으로 진행되도록 구성되어 있습니다.
Wizard
여섯 번째 키워드는 Wizard입니다. 게임이 오픈된 이후에는 운영과 분석을 위한 데이터 추출 요청이 발생합니다. 데이터 요청자는 결과를 받을 때까지 작업을 하지 못한 채 대기하게 되고, 데이터 팀에서는 서비스하는 게임이 많아질수록 요청 처리량이 늘어납니다. 그래서 사용자들이 직접 데이터를 추출할 수 있도록 도와주는 Wizard 기능을 공개 분석 환경에 추가했습니다. Wizard 기능을 만들기 위해 최근 1년간의 추출과 분석 요청을 조사했는데요. 자주 발생한 요청과 조건들을 정리하여 SQL 템플릿으로 만들었습니다.
Wizard에서 가장 강력한 기능은 바로 템플릿을 직접 관리할 수 있는 기능입니다. 조건이 추가되거나 변경되면 언제든지 템플릿 수정이 가능하고, 새롭게 템플릿을 만들어야한다면 언제든지 쉽게 추가할 수 있습니다. Wizard 오픈 후 6개월 정도가 지났는데 이 글을 작성할 시점까지 108명의 사용자가 3412건을 실행했습니다. 1건당 10분 정도로만 계산해도 약 570시간이므로 요청하는 사람과 처리하는 사람 모두의 리소스를 크게 절감시켰습니다.
Index
일곱 번째 키워드는 LINE 게임의 분석 노하우가 담긴 지표와 지표를 서비스하는 BI 도구를 의미하는 Index입니다. LINE 게임에서 개발한 자체 BI 도구의 가장 큰 특징은 바로 pivot 기능입니다. Pivot 기능이 있으면 지표 데이터를 사용자가 원하는 형태로 볼 수 있어 훨씬 깊이 있는 분석이 가능합니다.
Prepared vs On demand
지표 서비스에서 pivot 기능을 제공하려면 데이터 구조와 제공 방식도 중요합니다. 2가지 방식이 있는데 미리 만들어 둔 데이터를 제공하는 'Prepared 방식'과, 제공 시점에 데이터를 생성하는 'On demand 방식'입니다. 첫 번째 Prepared 방식은 차원이 적거나 고정되어 있는 경우에 빠르게 결과를 제공할 수 있는 장점이 있습니다. 두 번째 On demand 방식은 별도로 데이터를 준비할 필요가 없고 모든 차원, 모든 필터에 대해 질의가 가능한 장점이 있습니다. LINE 게임의 지표는 보통 7~10개의 차원을 가지므로 경우의 수를 모두 만들어 둘 수 없어 On demand 방식으로 서비스합니다.
Exact vs Approximate
또 하나 pivot 기능에서 중요한 점은 정확한 값을 제공하느냐, 근사치를 다뤄야 하느냐입니다. Pivot을 써보신 분은 아시겠지만 sum과 같은 계산 값은 어떤 차원 구성으로 조회하더라도 정확하게 맞아떨어져야 합니다. 따라서 빠른 성능을 위해 매 조회시마다 근사치를 제공한다면 정확한 결과를 만들기 어렵습니다. 따라서 LINE 게임의 BI 도구에서는 on demand 방식으로 정확한 데이터 계산과 대용량 데이터 처리를 위해 질의 엔진으로 Impala를 사용하고 있습니다.
DW 데이터
사실 지표 서비스의 기능보다 더욱 중요한 건 잘 만들어진 DW 데이터입니다. 데이터가 부실하면 BI 도구로 나온 결과를 제대로 반영할 수 없기 때문입니다. 고품질의 데이터를 수집해 DW를 잘 구축하는 것이 좋은 BI 도구 개발의 선행 과제라고 생각합니다.
마치며
이렇게 LINE 게임 분석 환경의 7가지 키워드를 모두 말씀드렸습니다. 정리하자면 LINE 게임의 분석 환경은 데이터 카탈로그를 직접 관리하고 고품질 데이터를 유지하기 위해 데이터 QA를 운영하며, 외부에서 원천 데이터를 핸들링해 직접 분석할 수 있는 공개 분석 환경을 제공합니다. 보안 역시 철저하게 관리하고 있고, 사용자의 데이터 추출과 분석을 도와주는 wizard 도구와 pivot 기능을 이용해 대용량 데이터의 지표를 제공하는 BI 도구를 운영하고 있습니다.
아직 진행 중인, 마지막 키워드로 Integration이 있습니다. 바로 데이터 카탈로그 통합인데요.

데이터 카탈로그를 통합하면 등록된 데이터 설계 정보를 기반으로 각각을 연계하여 아래와 같은 작업 자동화가 가능합니다.
- Collector: 데이터 수집 여부 자동 판단
- Data QA: 사용자가 전송한 커스텀 데이터 자동 검증
- Ingestion: 클러스터에 데이터를 적재하는 과정에서 카탈로그에 설계된 대로 데이터 자동 가공
- DW: DW 구축 자동화
- Index: 카탈로그와 DW 정보를 기반으로 지표 생성 자동화
마지막 키워드인 Integration이 완성되면 정말 어디에도 없는 분석 환경이 될 것이라고 자신합니다. 이 작업은 올해 상반기를 목표로 진행되고 있으며 함께 하실 분은 언제든 환영입니다. 아래 링크 확인해주세요!